ShapeLLM-Omni 论文解读
目录
一、概述
二、方法
1、3D离散化表示
2、3D 多模态模型
3、3D-Alpaca数据集
三、训练过程
一、概述
动机:以往的GPT-4o等主流MLLMs仅支持图像和文本的理解和生成,缺乏对3D内容的原生理解和生成能力。现有3D生成方法依赖优化或分阶段流程,存在效率低、细节丢失问题。
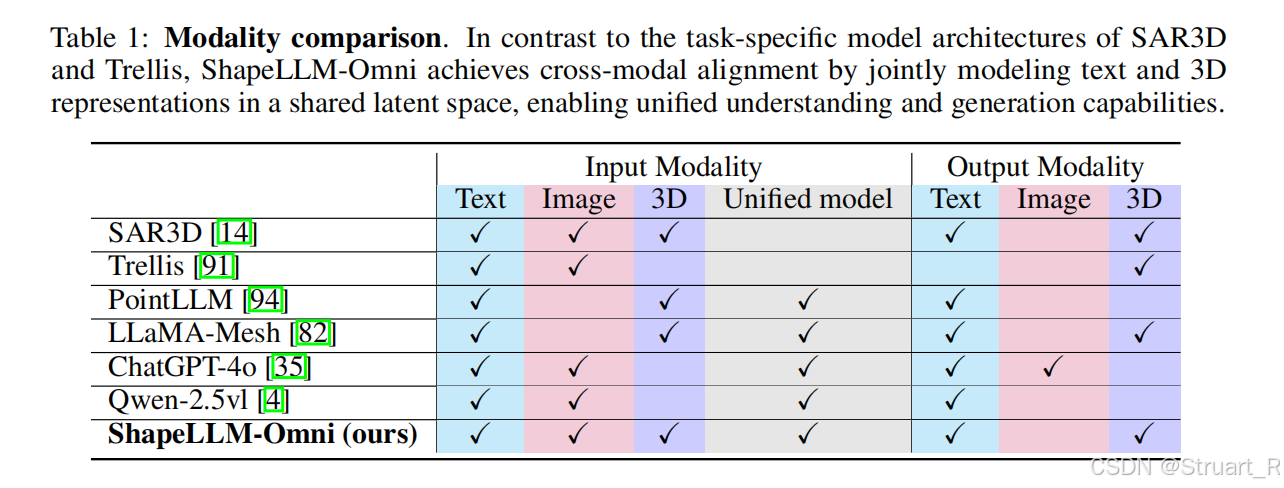
想法:利用自回归建模实现text/image->3D \3D->text/image \3d editing的端到端框架。
对标Trellis的3D生成,以及PointLLM的理解。
二、方法
ShapeLLM-Omni模型重点在于如果将3D离散化表示(3D VQVAE)、怎么搭建一个多模态统一架构、3D-Alpaca数据的建立。
1、3D离散化表示
输入:OBJ网格,并通过open3d转换为64x64x64体素网格,因为体素网格很好进行压缩得到离散tokens。
3D VQVAE是来自trellis论文的Sparse VQVAE,而ShapeLLM-Omni用于作为3D体素编码解码的部分。
具体来说首先输入一个OBJ网格,并通过open3d实现体素化处理,得到高维体素网格编码到更低维的
网格,也就是特征
,之后再通过解码重建
的网格。主要为了给后续的MLLM一个3D结构信息,网格也是不具有颜色信息的,纹理颜色信息完全依赖Visual Encoder部分。
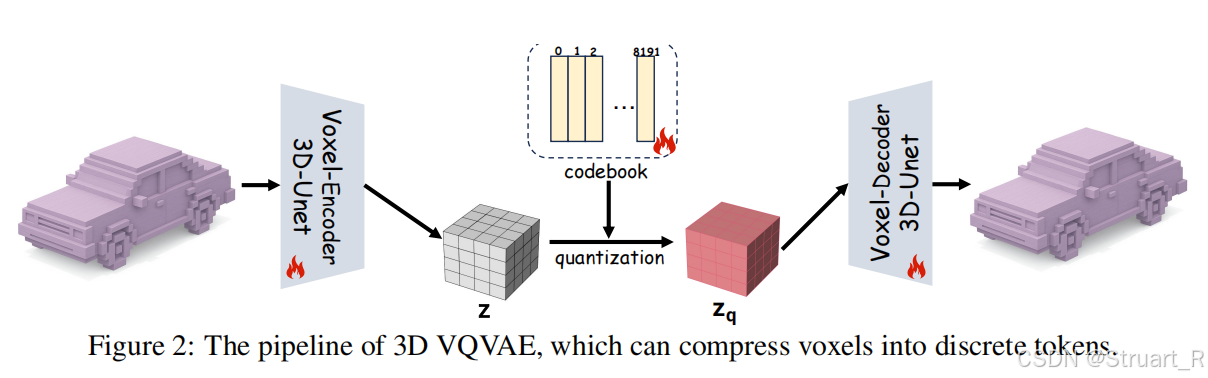
另外在3D VQVAE中提到,压缩到的信息作为序列还是有点长,需要4096个tokens,所以进行了拼接,将每4个tokens拼接在一起,转换为1024个tokens。
2、3D 多模态模型
同样是类似理解和生成解耦的方法,主干网络采用Qwen2.5-VL(包括Vision Encoder),冻结Vision Encoder,Text tokenizer。相当于只是在Qwen2.5-VL的基础上,加了一部分3D相关的tokens。
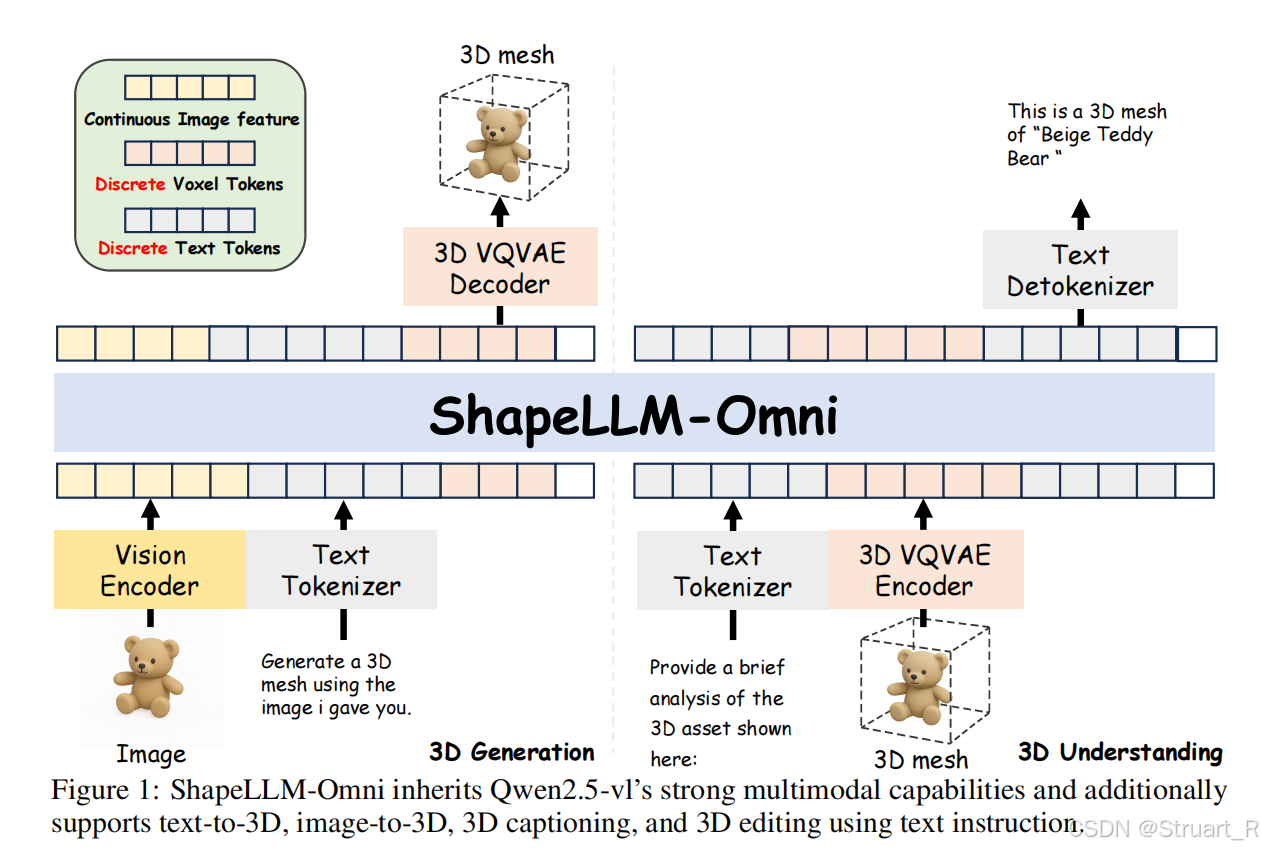
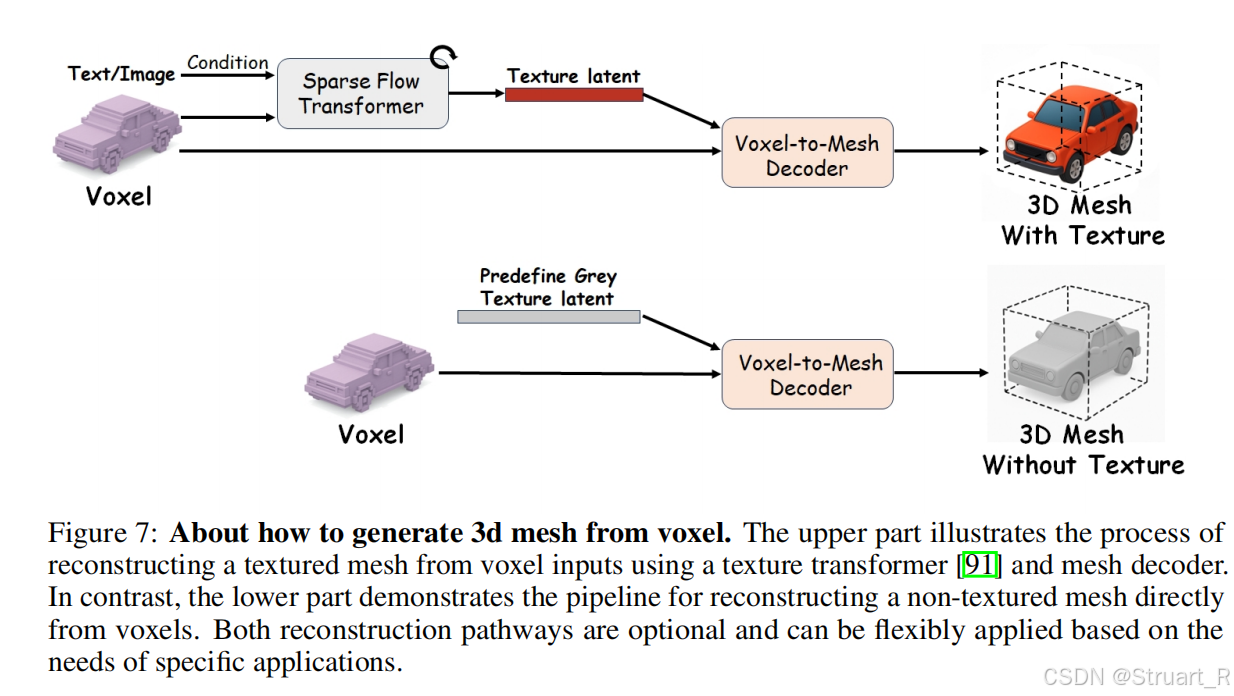
3D VQVAE Decoder部分则直接解码为网格模型,如果要进行下游任务需要手动拼接Sparse Flow Transformer,并引入相关的text or image,这也是Trellis做过的东西。根据Trellis论文,他的3D VQVAE是先通过了一个DINOv2语义提取,之后投影到Voxel中。
3、3D-Alpaca数据集
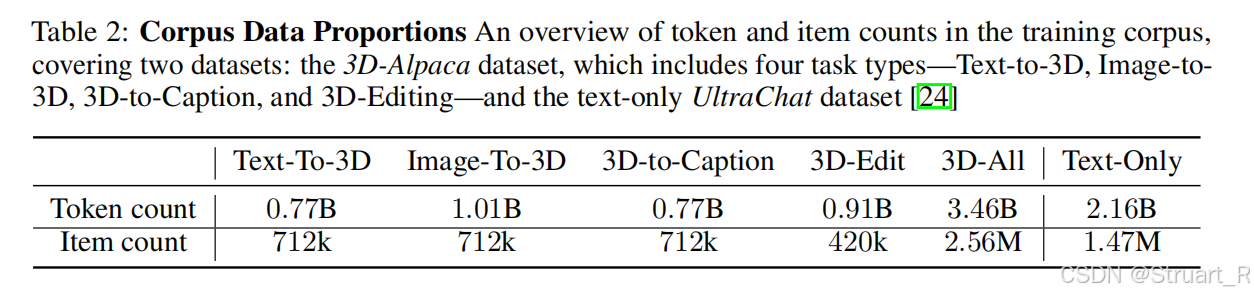
3D-Alpaca:3D内容生成、理解、编辑数据集
3D理解和生成数据:首先从Trellis数据集中精选712K高质量3D资产,并且为每个资产渲染正交四视图,并且输入到Qwen2.5-VL-Instruct模型中生成文本描述,作为3D-文本对的数据。
3D编辑数据集:参考Objaverse-XL分布,选定100个高频类别,并通过ChatGPT-4o对3D assets进行精细分类,筛选311K个目标类别资产。ChatGPT-4o为每个类别生成20条可行的编辑指令,人工审核筛选371条高质量指令。为每个指令分配200个资产,构建70K的编辑文本样本库。利用输入资产前视图+编辑指令生成编辑后的图像,并过滤错误样本,保留70K个有效图像对。
对话数据集:定义25个对话模板,共2.5M的对话。文本理解和生成的格式如下(Generate a 3D asset of prompt/images),编辑的没有给出
通用对话能力:UltraChat数据集引入147W高质量多轮文本对话,占比38.4%,防止丢失基础语言能力。(因为他没有单独微调)
三、训练过程
3DVQVAE二阶段训练,第一阶段冻结VAE训练codebook。第二阶段训练VAE和codebook。
MLLM微调则冻结3DVQVAE,训练3D token嵌入层,文本嵌入层,全参数微调Transformer。
训练效果上Text-to-3D和Image-to-3D上效果不如Trellis,但是作为一个开创性工作已经很不错了。
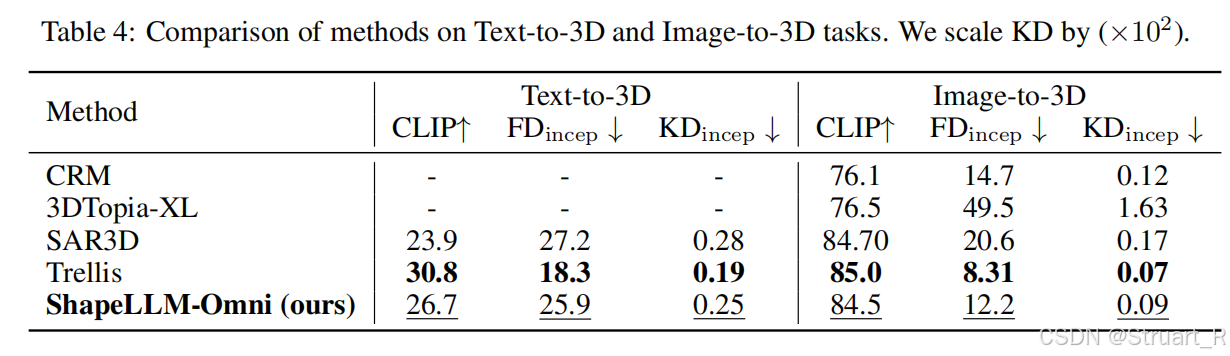
可以看到该方法,在Image-to-3D上存在语义失效问题,生成过程中同样的东西他的位置(比如窗户)会被移动。

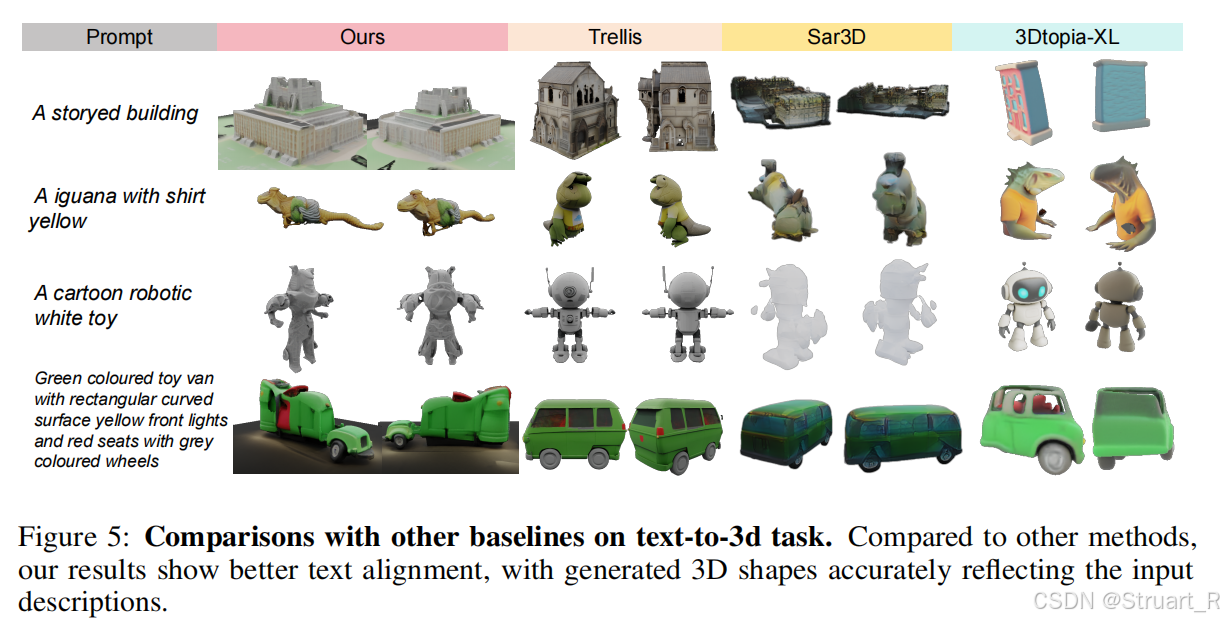
Text-to-3D上,或许是缺少视觉信息,效果有点不太行。
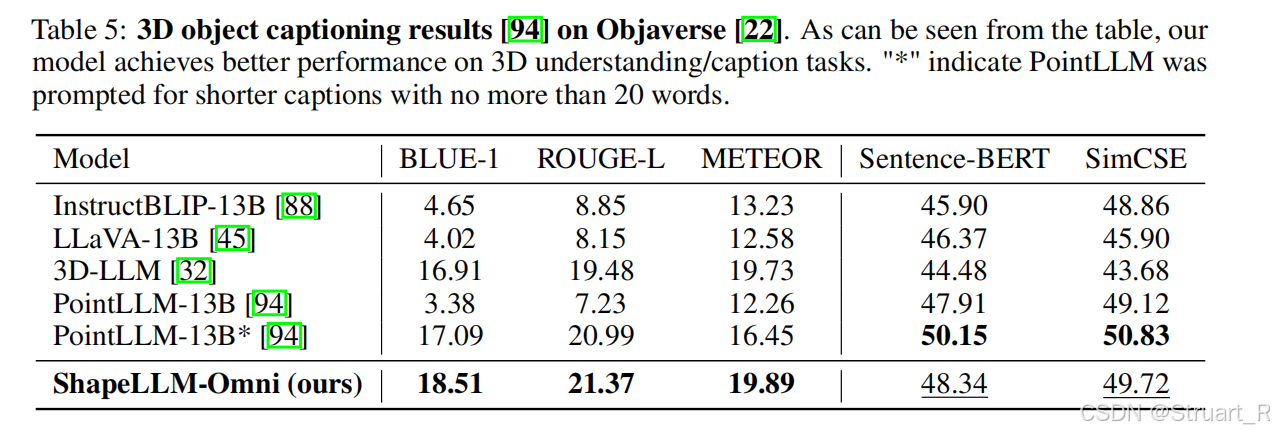
多模态理解上,效果接近PoinLLM
不能保持原有的图像,编辑过程覆盖了原模型。

参考论文:[2506.01853] ShapeLLM-Omni: A Native Multimodal LLM for 3D Generation and Understanding