pytorch 学习笔记3-利用框架内网络训练糖尿病数据集
利用框架内网络训练一个简单的二分类糖尿病数据集,糖尿病数据集是一个经典的入门级二分类学习数据集。
网络为4层线性网络。
import numpy as np
import torch
import matplotlib.pyplot as pltimport os
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'# Prepare the dataset
class DiabetesDateset():# 加载数据集def __init__(self, filepath):xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32, encoding='utf-8')self.len = xy.shape[0] # shape[0]是矩阵的行数,shape[1]是矩阵的列数self.x_data = torch.from_numpy(xy[:, :-1])self.y_data = torch.from_numpy(xy[:, [-1]])# 获取数据索引def __getitem__(self, index):return self.x_data[index], self.y_data[index]# 获得数据总量def __len__(self):return self.lendataset = DiabetesDateset(os.path.join('data', 'diabetes.csv'))# Define the model
class simpleNN(torch.nn.Module):def __init__(self):super(simpleNN, self).__init__()self.linear1 = torch.nn.Linear(8, 6) # 输入数据的特征有8个,也就是有8个维度,随后将其降维到6维self.linear2 = torch.nn.Linear(6, 4) # 6维降到4维self.linear3 = torch.nn.Linear(4, 2) # 4维降到2维self.linear4 = torch.nn.Linear(2, 1) # 2w维降到1维self.sigmoid = torch.nn.Sigmoid() # 可以视其为网络的一层,而不是简单的函数使用def forward(self, x):#x = self.sigmoid(self.linear1(x))x = torch.relu(self.linear1(x)) # 隐藏层用ReLU激活x = self.sigmoid(self.linear2(x))x = self.sigmoid(self.linear3(x))x = self.sigmoid(self.linear4(x))return xmodel = simpleNN()# Define the criterion and optimizer
criterion = torch.nn.BCELoss(reduction='mean') # 返回损失的平均值 # 二分类交叉熵损失
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)epoch_list = []
loss_list = []# Training
if __name__ == '__main__':for epoch in range(500):# i是一个epoch中第几次迭代,一共756条数据,每个mini_batch为32,所以一个epoch需要迭代23次# data获取的数据为(x,y)labels = dataset.y_datay_pred = model(dataset.x_data)loss = criterion(y_pred, labels)optimizer.zero_grad()loss.backward()optimizer.step()loss_list.append(loss.item())epoch_list.append(epoch)print('Epoch[{}/{}],loss:{:.6f}'.format(epoch + 1, 500, loss.item()))# Drawingplt.plot(epoch_list, loss_list)plt.xlabel('epoch')plt.ylabel('loss')plt.show()# 测试模型model.eval()with torch.no_grad():# 加载测试数据并使用相同的标准化器test_dataset = DiabetesDateset(os.path.join('data', 'test.csv'))test_data = torch.from_numpy(test_dataset.x_data.numpy()).float()predictions = model(test_data)# 转换为类别(0或1),使用0.5作为阈值predicted_classes = (predictions >= 0.5).float()print("预测概率:", predictions.squeeze().numpy())print("预测类别:", predicted_classes.squeeze().numpy())输出损失函数是降低的。但是预测概率全部是一样的数。看来直接拿来一个最简单的实际的数据库用最简单的网络还不能学习啊。
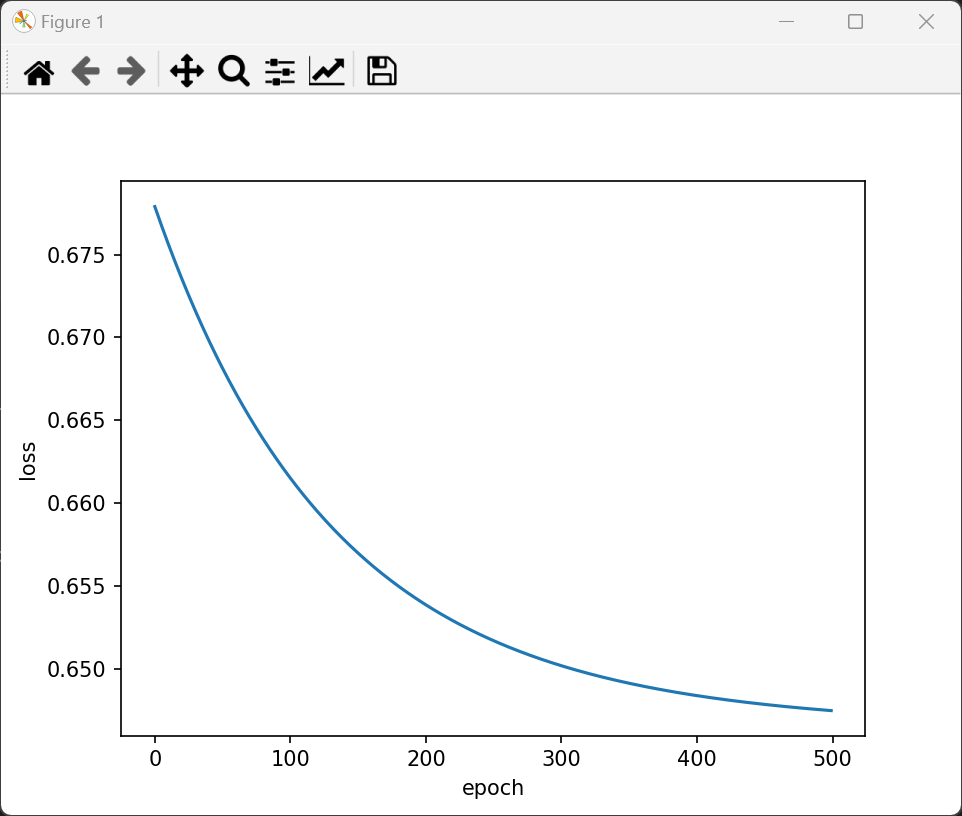
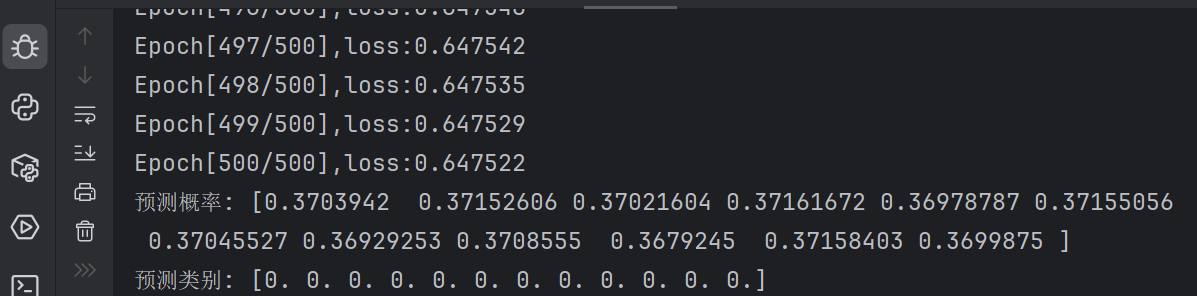
分析原因,模型预测结果都是接近 0.37 的相同数值,这通常表明模型没有有效学习到数据中的模式,可能的原因包括数据处理不当、模型结构问题或训练过程存在问题。
主要改进点说明:
-
数据处理方面:
-
对训练集和测试集使用相同的标准化参数,避免数据分布不一致
-
将数据集划分为训练集和验证集,便于监控过拟合情况
-
保持目标变量的维度一致性,便于损失计算
-
-
模型结构方面:
-
增加了网络宽度(从 6 增加到 16),增强学习能力
-
添加了批量归一化层,加速训练并提高稳定性
-
-
训练过程方面:
-
添加了 L2 正则化(weight_decay)防止过拟合
-
监控验证集损失,便于判断模型是否正常学习
-
修改后代码如下:
import torch
import numpy as np
import matplotlib.pyplot as plt
from torch import nn, optim
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import os# 解决matplotlib可能的冲突问题
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'class simpleNN(nn.Module):def __init__(self):super(simpleNN, self).__init__()# 调整网络结构,增加批量归一化层帮助训练self.fc1 = nn.Linear(8, 16)self.bn1 = nn.BatchNorm1d(16)self.fc2 = nn.Linear(16, 8)self.bn2 = nn.BatchNorm1d(8)self.fc3 = nn.Linear(8, 4)self.fc4 = nn.Linear(4, 1)# 删除过多的sigmoid,避免梯度消失self.relu = nn.ReLU()self.sigmoid = nn.Sigmoid()def forward(self, x):x = self.relu(self.bn1(self.fc1(x)))x = self.relu(self.bn2(self.fc2(x)))x = self.relu(self.fc3(x))x = self.sigmoid(self.fc4(x)) # 输出层使用sigmoid得到0-1之间的概率return xclass DiabetesDataset():def __init__(self, filepath):xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32, encoding='utf-8')self.x_data = torch.from_numpy(xy[:, :-1])self.y_data = torch.from_numpy(xy[:, -1:]) # 保持维度一致,便于计算self.len = xy.shape[0]def __getitem__(self, index):return self.x_data[index], self.y_data[index]def __len__(self):return self.lenif __name__ == '__main__':# 加载数据dataset = DiabetesDataset(os.path.join('data', 'diabetes.csv'))# 划分训练集和验证集train_dataset, val_dataset = train_test_split(dataset.x_data, test_size=0.2, random_state=42)train_dataset_y, val_dataset_y = train_test_split(dataset.y_data, test_size=0.2, random_state=42)# 数据标准化 - 只使用训练集的统计量,避免数据泄露scaler = StandardScaler()x_train_np = train_dataset.numpy()scaler.fit(x_train_np) # 仅用训练数据拟合标准化器# 对训练集和验证集进行标准化x_train = torch.from_numpy(scaler.transform(x_train_np)).float()y_train = train_dataset_y.float()x_val = torch.from_numpy(scaler.transform(val_dataset.numpy())).float()y_val = val_dataset_y.float()# 创建模型、损失函数和优化器model = simpleNN()criterion = nn.BCELoss()optimizer = optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-5) # 增加L2正则化# 训练模型losses = []val_losses = []epochs = 500 # 增加训练轮次for epoch in range(epochs):# 训练模式model.train()output = model(x_train)loss = criterion(output, y_train)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 记录训练损失losses.append(loss.item())# 验证模式model.eval()with torch.no_grad():val_output = model(x_val)val_loss = criterion(val_output, y_val)val_losses.append(val_loss.item())# 打印训练信息if (epoch + 1) % 10 == 0:print(f"Epoch [{epoch + 1}/{epochs}], "f"Train Loss: {loss.item():.4f}, "f"Val Loss: {val_loss.item():.4f}")# 绘制损失曲线plt.plot(losses, label='Training Loss')plt.plot(val_losses, label='Validation Loss')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.show()# 测试模型model.eval()with torch.no_grad():# 加载测试数据并使用相同的标准化器test_dataset = DiabetesDataset(os.path.join('data', 'test.csv'))test_data = torch.from_numpy(scaler.transform(test_dataset.x_data.numpy())).float()predictions = model(test_data)# 转换为类别(0或1),使用0.5作为阈值predicted_classes = (predictions >= 0.5).float()print("预测概率:", predictions.squeeze().numpy())print("预测类别:", predicted_classes.squeeze().numpy())
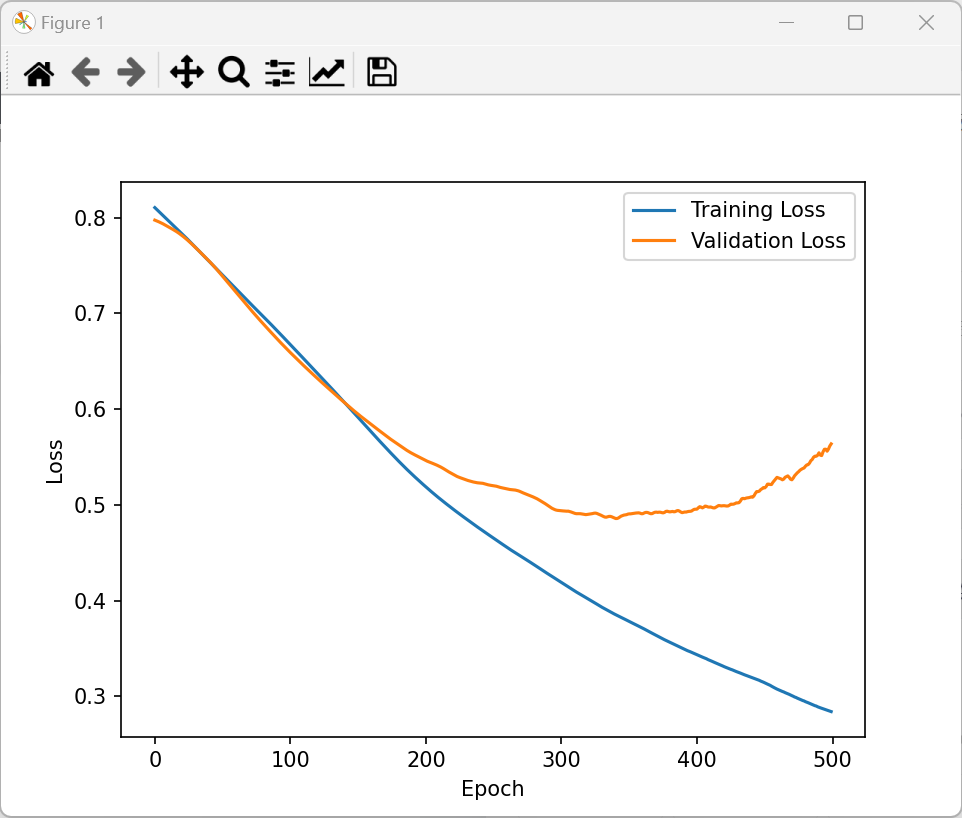
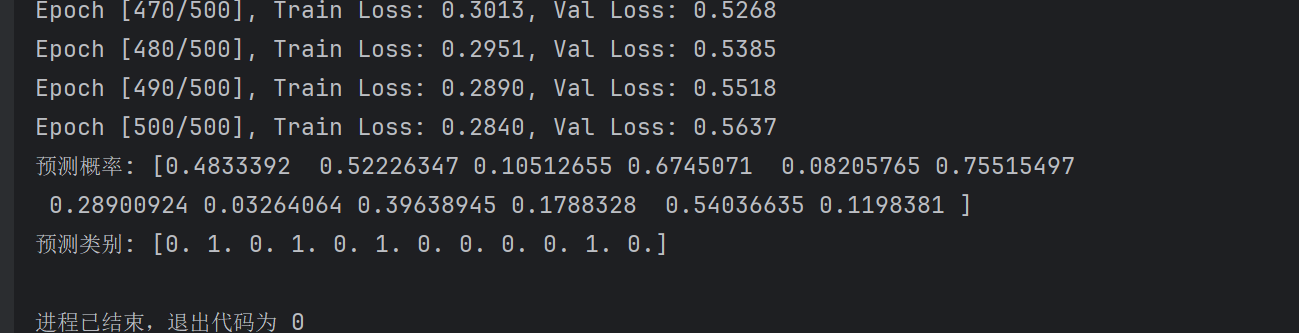
预测结果还不错!
数据集找不到可以从这下载,地址:
糖尿病数据集,分了训练和测试资源-CSDN下载