Swin-Transformer从浅入深详解
第一部分:出现背景
在 Swin Transformer 出现之前,计算机视觉(Computer Vision, CV)领域主要由 CNN (卷积神经网络) 主导。后来,NLP(自然语言处理)领域的 Transformer 模型被引入 CV,诞生了 ViT (Vision Transformer)。
ViT 做了一件事:它将一张图片分割成多个“图块”(Patches),把这些图块当作句子里的“单词”,然后用标准 Transformer 模型来处理,取得了惊人的效果。
但是,ViT 存在两个核心问题:
1.计算复杂度过高:
标准的 Transformer 需要计算每个图块(Patch)与其他所有图块之间的“注意力”,这是一种全局(Global)注意力机制。如果一张图片有 N 个图块,计算复杂度就是 O(N*N)。当图片分辨率增大时,N 会急剧增加,导致计算量和显存消耗变得难以承受。
2.缺乏层次化结构:
CNN 的一大优势是它能通过逐层堆叠(卷积、池化),构建出从低级(边缘、纹理)到高级(物体部件、整体)的层次化特征。这种金字塔结构对于物体检测、语义分割等需要多尺度信息的任务至关重要。而 ViT 从始至终都保持着同样大小的图块序列,缺乏这种多尺度的能力。
Swin Transformer 的诞生,就是为了解决 ViT 的这两个核心痛点。 它的目标是:打造一个既有 Transformer 的强大建模能力,又有 CNN 的高效性和层次化结构优点的通用视觉骨干网络
注:部分图示出自论文原文与小绿豆老师的博客
第二部分:网络整体架构
在探讨Swin Transformer 的核心设计之前,我们先看一下他和Vision Transformer(VIT)的不同,这里引用小绿豆老师的博文和图来进行对比讲解:
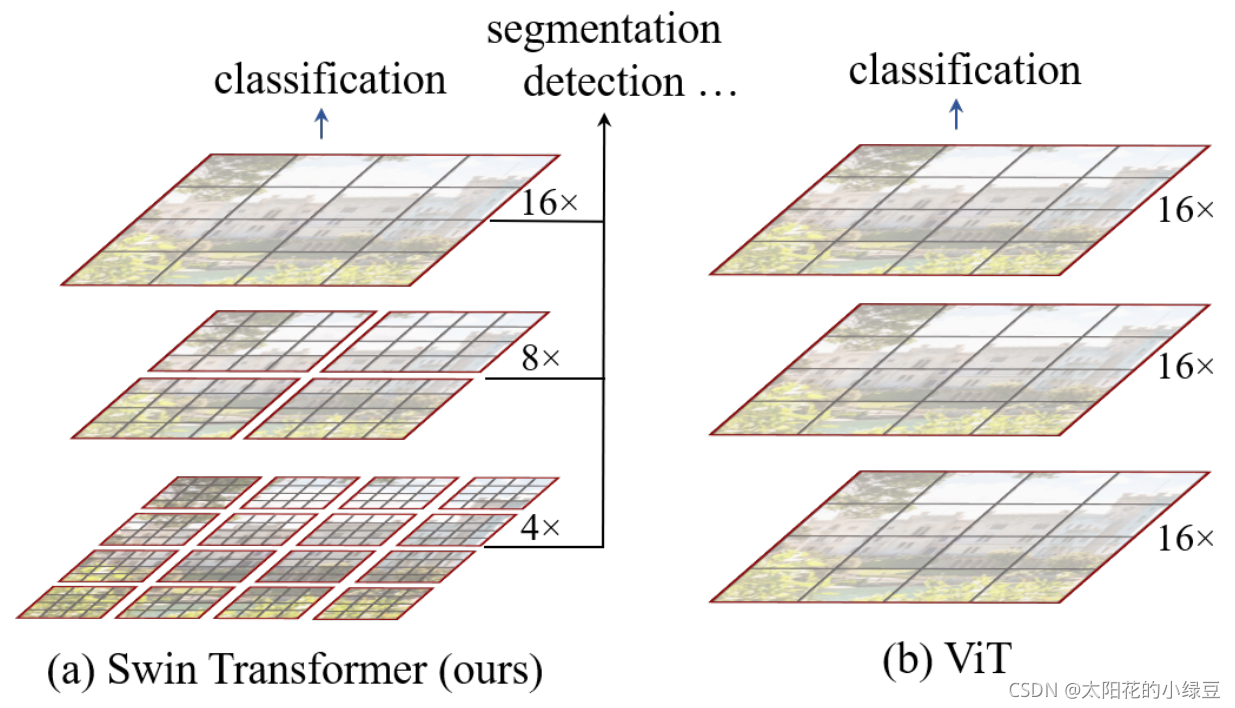
通过对比我们可以看出主要的不同:
Swin Transformer和CNN很类似,分层次构建的特征图,这样有助于各种任务的建立,而VIT主要还是比较单一的16倍下采样。
原论文中给出的关于Swin Transformer(Swin-T)网络的架构图:
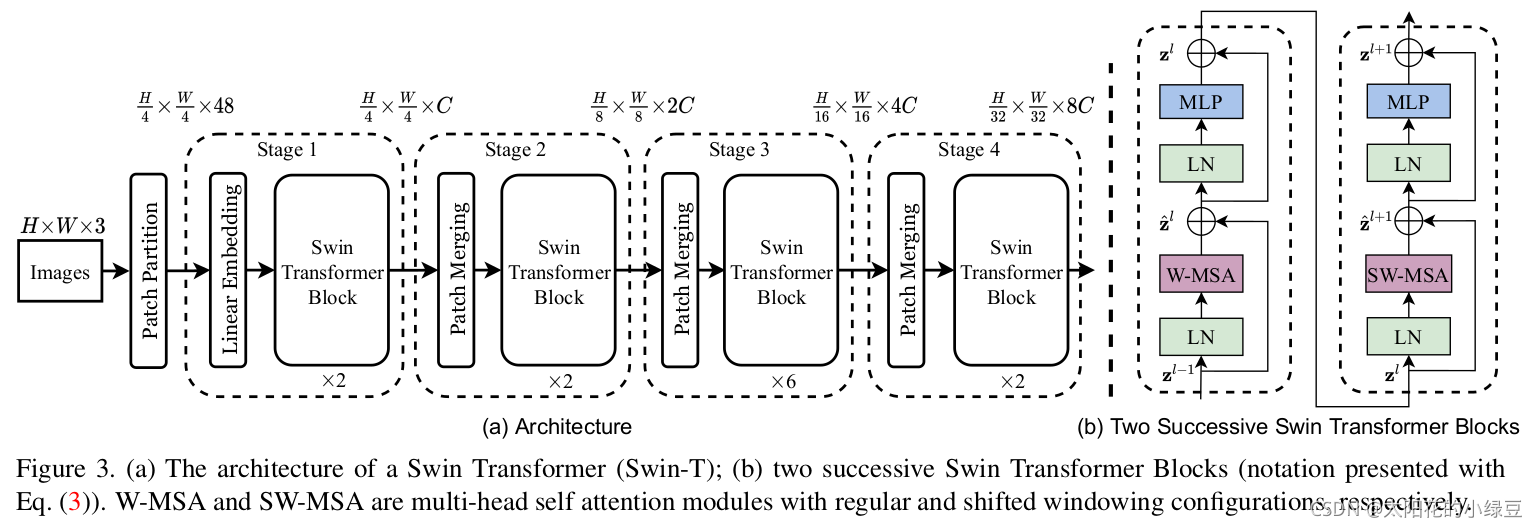
大家先简单看一下,在后面我会详细展开讲解各个模块的作用,Swin Transformer 的架构非常有 CNN 的风范,呈现出清晰的层次化结构。
整个网络主要分为 4 个阶段(Stage):
Stage 1: Patch Partition & Linear Embedding
1.输入:一张 H x W x 3 的 RGB 图像。
2.操作:
Patch Partition: 像 ViT 一样切块,但 Swin 的初始块非常小,比如 4 x 4 像素。这样每个图块就是一个 4 * 4 * 3 = 48 维的向量。
Linear Embedding: 通过一个线性层,将每个图块的维度映射到一个指定的维度 C(例如 96)。
3.输出:一个大小为 (H/4) x (W/4),通道数为 C 的特征图。
Stage 2: Swin Transformer Blocks
1.输入:Stage 1 的输出。
2.操作:
串联多个 Swin Transformer Block。这些 Block 成对出现:
第一个 Block 使用 W-MSA,第二个 Block 使用 SW-MSA...如此交替,注意:一定是成对的偶数出现!!!
3.输出:特征图大小不变,仍为 (H/4) x (W/4) x C。
Stage 3: Patch Merging & More Blocks
1.输入:Stage 2 的输出。
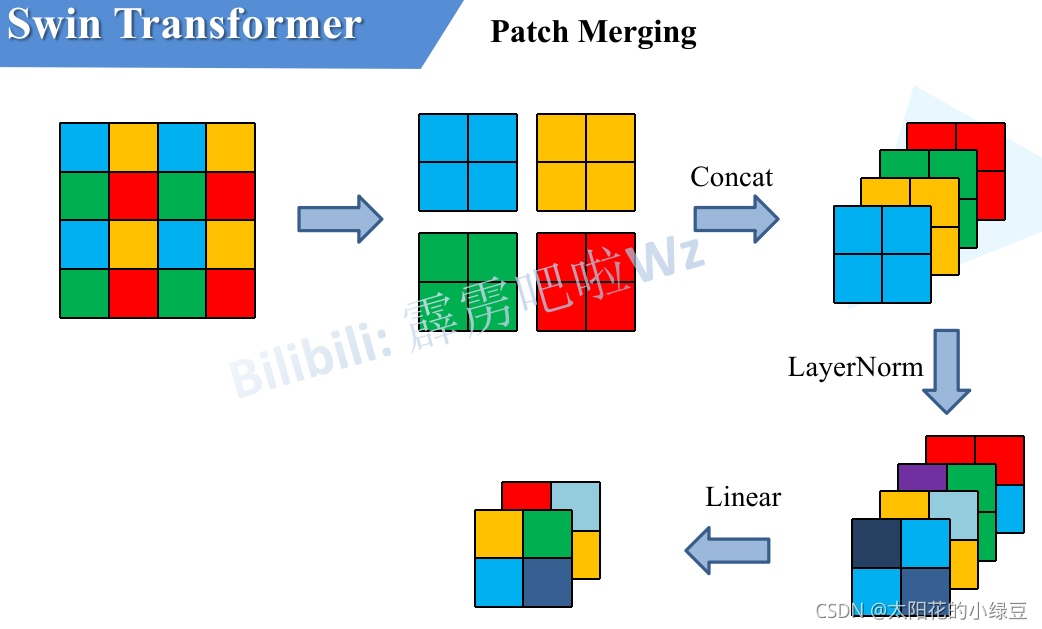
2.操作:Patch Merging (核心步骤):
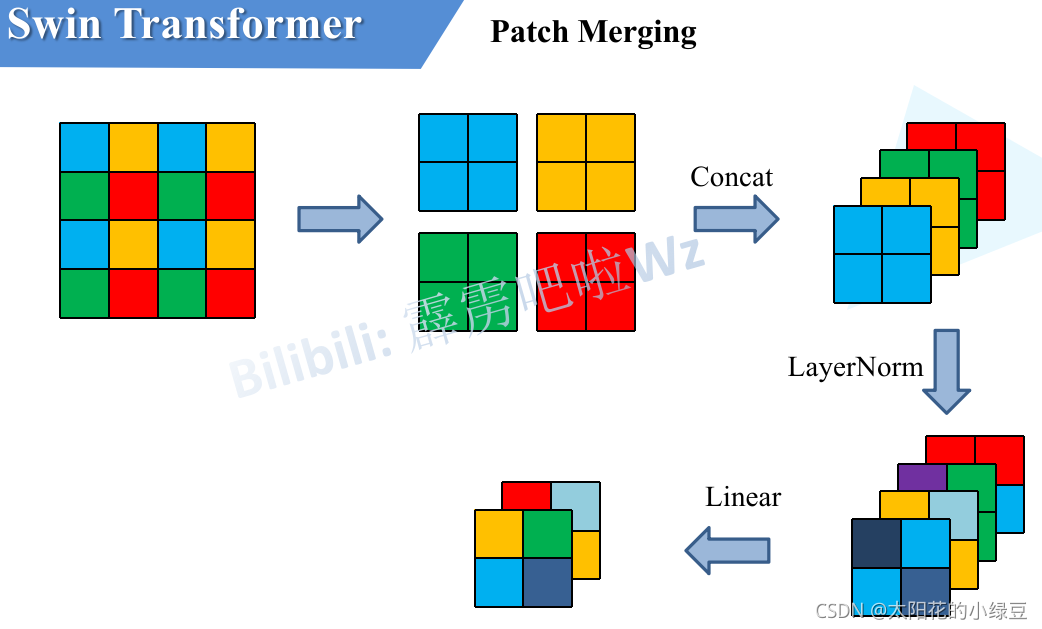
这是一个下采样层,作用类似于 CNN 中的池化层。它将特征图中每 2 x 2 相邻的四个图块拼接(Concatenate)在一起,这样通道数变为 4C,再通过一个线性层将通道数降为 2C。
我们可以把它看做,一个3x3的正方形网格,网格内像素值为1,对特征图进行采样,每次采样只保留正方形四个角的像素,这样我们就可以采样到4个新的特征图,随后将这四个新的特征图拼接到一起,这就是我们的Patch Merging
效果:特征图分辨率减半 ((H/8) x (W/8)),通道数翻倍 (2C)。这完美复刻了 CNN 的金字塔结构
Swin Transformer Blocks: 再次串联多个成对的 (W-MSA, SW-MSA) Block,对新的特征图进行处理。
3.输出:(H/8) x (W/8) x 2C 的特征图。
Stage 4 & Stage 5: 重复操作
继续重复 Patch Merging + Swin Transformer Blocks 的组合。
Stage 4 输出: (H/16) x (W/16) x 4C 的特征图。
Stage 5 输出: (H/32) x (W/32) x 8C 的特征图
最后,根据具体任务(如图像分类),在最后一层特征图后接上全局平均池化层和全连接层进行预测。
第二部分:核心模块讲解
模块一:窗口化多头自注意力 (W-MSA)
核心思想:在现实世界中,一个像素点和它周围的像素点的关系,远比和图像另一端的像素点的关系要密切。这是视觉最基本的物理常识。
既然全局注意力的计算量太大,一个自然的想法就是:我们能不能只在一个局部范围内计算注意力?左边为VIT的特征图,需要每个像素去乘以剩下的像素去计算注意力,就是16x16,而右边的SWIN,仅仅在4个窗口分别计算注意力,就成了4x4x4,一下就减少了这么多,更别提在高分辨率下1920x1080的图像了,那肯定计算资源减少的更多!
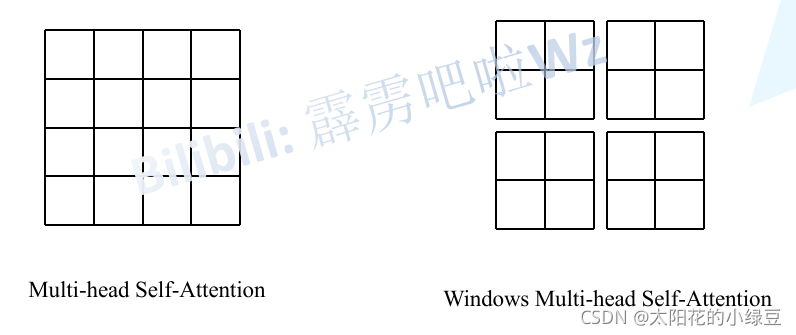
Swin Transformer 正是这么做的。它没有在整张特征图上计算注意力,而是:
1.划分窗口 (Window Partitioning):将特征图(Feature Map)划分为多个不重叠的窗口(比如每个窗口大小为 M x M 个图块)。
2.窗口内注意力 (Attention within Window):在每个窗口内部独立地进行自注意力计算。
这样做的好处立竿见影:
没有窗口的ViT 的全局注意力复杂度:O((h * w)²)
SWIN:假设特征图有 h x w 个图块,窗口大小为 M x M。
Swin 的窗口注意力复杂度:O(M² * h * w)
当 M 是一个固定的小常数(如 7)时,计算复杂度就从关于图块数量的二次方关系,变成了线性关系!这极大地降低了计算量,使得处理高分辨率图像成为可能。
但是,新问题来了:每个窗口都像一个信息孤岛,窗口之间无法进行信息交流。这样模型就无法学习到跨越窗口边界的全局特征。怎么办?这就引出了第二个核心模块。
模块二:“移位窗口”实现跨窗口连接 (Shifted Window Self-Attention, SW-MSA)
为了打破窗口间的壁垒,Swin Transformer 设计了一个绝妙的机制:移位窗口。
它的操作非常天才!:
通过前文的网络整体架构设计,我们知道W-MSA和SW-MSA一般成对出现,在连续的两个 Transformer Block 中,它会采用两种不同的窗口划分方式:
即:
1.在一个 Transformer Block 中,使用常规的 W-MSA。
2.在下一个连续的 Transformer Block 中,将窗口的划分方式进行移位(Shift)。具体来说,将窗口向右和向下移动半个窗口的距离,即 (M/2 向下取整, M/2 向下取整) 的距离。这里的M是4,于是我们向下向右移两个像素,这个简单的“移位”操作,带来了神奇的效果。在第 L 层还分属不同窗口、无法直接对话的图块,在第 L+1 层因为窗口的移动,被“划分”到了同一个新窗口中,从而可以进行信息交互了。
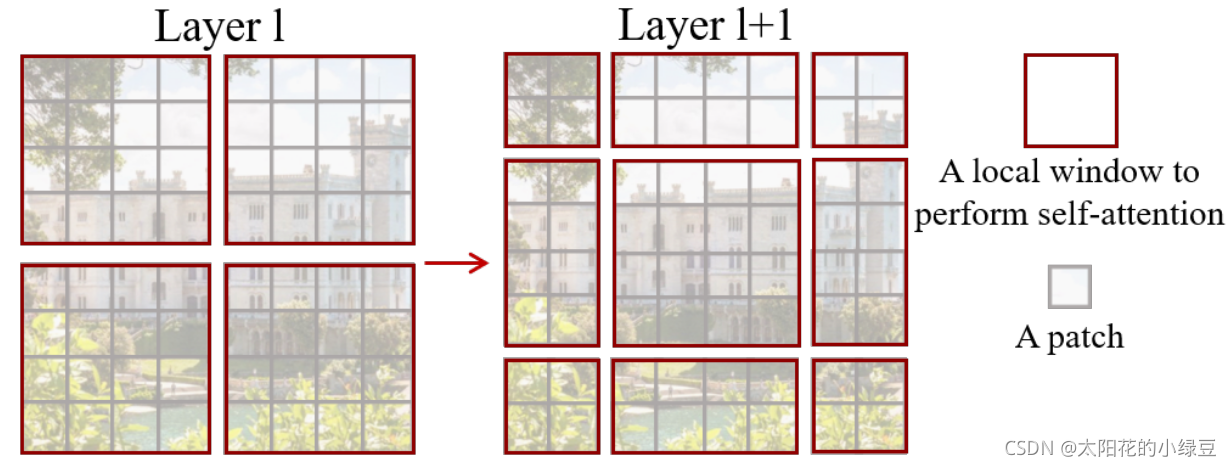
但是!!!如果真的按照移位后的样子去老老实实计算,会产生更多、大小不一的窗口,从而增加计算量并且难以并行处理。
但 Swin Transformer 的作者用了一个极其聪明的“障眼法”来解决这个问题,这个技巧叫做 循环移位 (Cyclic Shift) + 注意力掩码 (Masking)。它实现了“跨窗口交流”的效果,却没有增加一丁点计算量。所以我一直认为这个作者真的是天才,Swin的架构设计简直像一种艺术。接下来我来讲解一下这个技巧。
第一步:不创建新窗口,而是“滚动”特征图 它并不真的去切分出那些边边角角的小窗口。相反,它把整张特征图向上、向左进行“循环移位”(可以想象成把最左边的像素块移动到最右边,最上边的移动到最下边)。说白了,就是把通过移动特征图,把图里不同区域划分到格子里去。
效果:经过这个“滚动”操作后,原来那些因为移位而产生的零碎小窗口,被神奇地重新拼凑在了一起。最终,我们得到的仍然是和常规 W-MSA 数量相同、大小也完全相同的窗口。这样计算量就保持不变了!
第二步:解决“乱点鸳鸯谱”的问题 但是,这个“滚动”操作带来一个新问题:一些原本在图像中天各一方的区域被硬凑到了一个窗口里,比如最上面的一排像素,滚动到了最下面,这样他和之前最下面的像素没啥联系啊,计算注意力没必要啊。
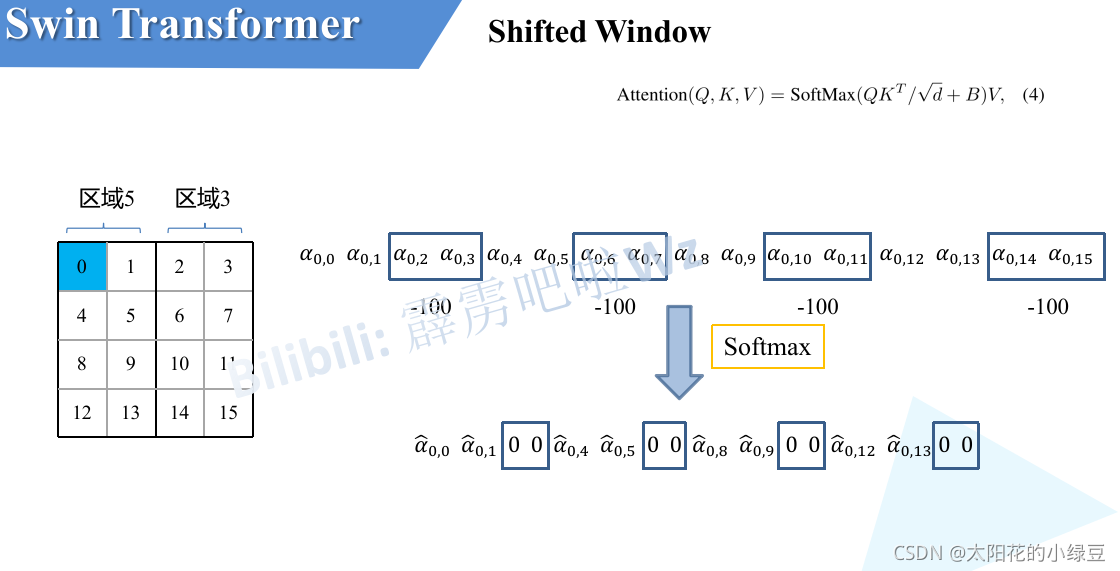
第三步:使用“注意力掩码” 为了解决这个问题,模型在计算注意力之前,会使用一个“掩码 (Mask)”。这个掩码会告诉模型:最下面一排像素和倒数第二排像素的图块是硬凑过来的,你们之间不准计算注意力 在计算时,它会给这些不该交流的图块组合一个极大的负值(比如 -100),这样经过 Softmax 之后,它们之间的注意力权重就几乎为 0 了。
比如,像素0属于区域5,当像素0计算注意力时,就把区域3内所有像素添加一个-100,这样就不会计算硬凑的模块注意力了
第四步:计算完毕,物归原主 在带有掩码的注意力计算完成之后,再把特征图“反向滚动”回去,恢复到它本来的样子。
通过 “循环移位 -> 带掩码计算 -> 逆向移位” 这一套流程,Swin Transformer 巧妙地在逻辑上实现了跨窗口的信息流动,但在实际计算时,处理的窗口数量和大小从未改变。
模块三:Patch Merging (图块合并)
一、设计的核心动机:为何不直接用 CNN 的池化 (Pooling)?
在深入了解 Patch Merging 的“如何做”之前,我们必须先明白“为什么这么做”。CNN 中最常见的降采样方法是最大池化 (Max Pooling) 或平均池化 (Average Pooling)。
池化的问题:池化操作非常粗暴。比如最大池化,在一个 2x2 的区域里,它只保留最大的那个值,其他三个值的信息就被完全丢弃了。这是一种不可逆的信息损失。虽然它在早期 CNN 中很有效,但对于需要精细建模的 Transformer 架构来说,这种信息损失是不可接受的。
Patch Merging 的设计:先保留全部,再学习如何提炼。 它认为,2x2 区域内的 4 个图块(像素)都包含了有用的信息,我们不应该武断地扔掉任何一个。正确的做法是,把这 4 份信息完整地“打包”在一起,然后通过一个可学习的网络层(线性层),让模型自己去决定如何从这包信息中提炼出最重要的部分。
我们可以把它看做,一个3x3的正方形网格,网格内像素值为1,对特征图进行采样,每次采样只保留正方形四个角的像素,这样我们就可以采样到4个新的特征图,随后将这四个新的特征图拼接到一起,再通过一个线性层将通道数降为 2C。
因此,Patch Merging 的本质是一种无损、可学习的降采样(下采样)方法。
总结:三大模块如何协同工作
Swin Transformer 的整个架构就是这三大原则的完美体现:
分阶段 (Stage) 设计:网络被划分为多个阶段,每个阶段的最后通过 Patch Merging(原则二)来降低分辨率、加深特征,构建层次。
阶段内 Block 设计:在每个阶段内部,多个 Transformer Block 成对出现,交替使用 W-MSA(原则一)和 SW-MSA(原则三),在当前尺度下高效地学习局部特征并进行跨窗口的信息融合。
最终,Swin Transformer :
W-MSA先在自己的窗口内学习。
通过SW-MSA跨区域学习,交换关键信息。
通过Patch Merging,进行多尺度层次融合
它既有 CNN 的结构效率和层次感,又有 Transformer 的动态关系建模能力,是一个真正集两者之长的天才杰作。