机器学习(8):线性回归
一系列概念
1、回归
标称型数据:是统计学和数据分析中的一种数据类型,它用于分类或标记不同的类别或组别,数据点之间并没有数值意义上的距离或顺序。例如,颜色(红、蓝、绿)、性别(男、女)或产品类别(A、B、C)。
连续性数据:表示在某个范围内可以取任意数值的测量,这些数据点之间有明确的数值关系和距离。例如,温度、高度、重量等
回归:回归的目的是预测数值型的目标值y。最直接的办法是依据输入x写出一个目标值y的计算公式。 求这些回归系数的过程就是回归。
2、线性回归
线性回归:线性回归意味着可以将输入项分别乘以一些常量,再将结果加起来得到输出。线性回归是机器学习中一种有监督学习的算法,回归问题主要关注的是因变量(需要预测的值)和一个或多个数值型的自变量(预测变量)之间的关系.
人工智能中的线性回归:数据集中,往往找不到一个完美的方程式来100%满足所有的y目标
我们就需要找出一个最接近真理的
例:
有这样一种植物,在不同的温度下生长的高度是不同的,对不同温度环境下,几颗植物的环境温度(横坐标),植物生长高度(纵坐标)的关系进行了采集,并且将它们绘制在一个二维坐标中,其分布如下图所示:
坐标分别为[4.2, 3.8],[4.2, 2.7],[2.7, 2.4],[0.8, 1.0],[3.7, 2.8],[1.7, 0.9],[3.2, 2.9]。
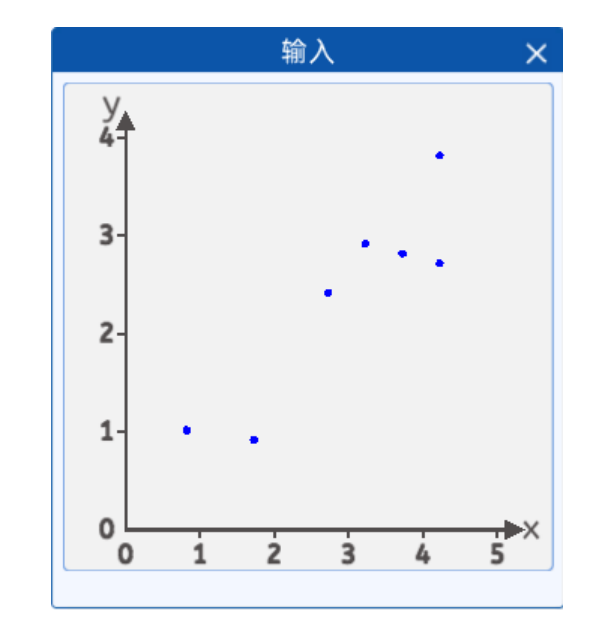
我们发现这些点好像分布在一条直线的附近,那么我们能不能找到这样一条直线,去“拟合”这些点,这样的话我们就可以通过获取环境的温度大概判断植物在某个温度下的生长高度了。
于是我们的最终目的就是通过这些散点来拟合一条直线,使该直线能尽可能准确的描述环境温度与植物高度的关系。
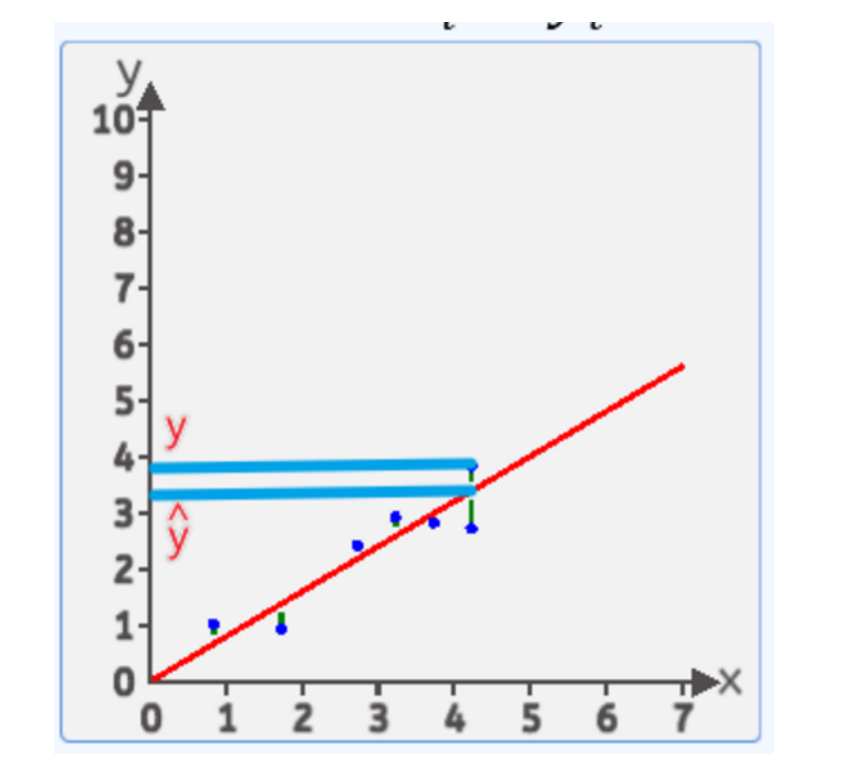
3、损失函数
loss = [(y1-y1^)^2+(y2-y2^)^2+...+(yn-yn^)^2]/n
均方差:就是每个点到线的竖直方向的距离平方 求和 在平均 最小时 这条直接就是最优直线
y-y^
4、多参数回归
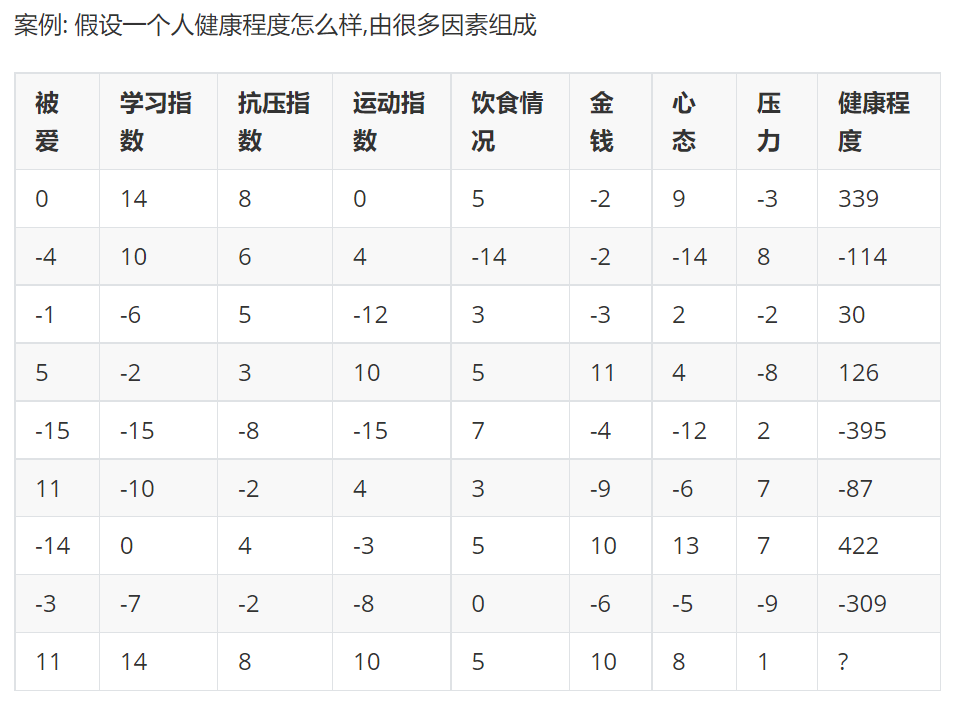
根据每个参数的影响结果程度,设立的权重不一样,我们需要算出模型的每个w,就求出了模型
根据损失最小的思路求权重
这里即八元一次方程求解
14w_2+8w_3+5w_5+-2w_6+9w_7+-3w_8=399
-4w_1+10w_2+6w_3+4w_4+-14w_5+-2w_6+-14w_7+8w_8=-144
-1w_1+-6w_2+5w_3+-12w_4+3w_3+-3w_6+2w_7+-2w_8=30
5w_1+-2w_2+3w_3+10w_4+5w_5+11w_6+4w_7+-8w_8=126
-15w_1+-15w_2+-8w_3+-15w_4+7w_5+-4w_6+-12w_7+2w_8=126
11w_1+-10w_2+-2w_3+4w_4+3w_5+-9w_6+-6w_7+7w_8=-87
-14w_1+4w_3+-3w_4+5w_5+10w_6+13w_7+7w_8=422
-3w_1+-7w_2+-2w_3+-8w_4+-6w_6+-5w_7+-9w_8=-309
5、最小二乘法MSE
高斯利用最小二乘法解出了八元一次方程,这里不对它作详细解释
6、API
sklearn.linear_model.LinearRegression()
功能: 普通最小二乘法线性回归, 权重和偏置是直接算出来的,对于数量大的不适用,因为计算量太大,计算量太大的适合使用递度下降法
参数:
fit_intercept bool, default=True
是否计算此模型的截距(偏置)。如果设置为False,则在计算中将不使用截距(即,数据应中心化)。
属性:
coef_ 回归后的权重系数
intercept_ 偏置
print("权重系数为:\n", estimator.coef_) #权重系数与特征数一定是同样的个数。
print("偏置为:\n", estimator.intercept_)
from sklearn.linear_model import LinearRegression
import numpy as np
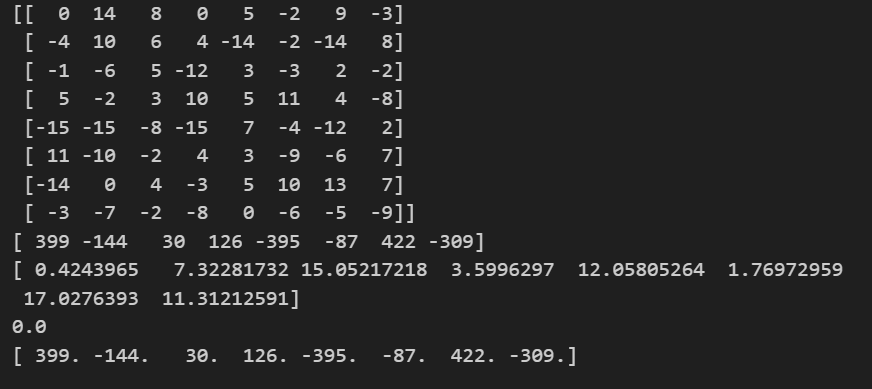
data=np.array([[0,14,8,0,5,-2,9,-3,399],[-4,10,6,4,-14,-2,-14,8,-144],[-1,-6,5,-12,3,-3,2,-2,30],[5,-2,3,10,5,11,4,-8,126],[-15,-15,-8,-15,7,-4,-12,2,-395],[11,-10,-2,4,3,-9,-6,7,-87],[-14,0,4,-3,5,10,13,7,422],[-3,-7,-2,-8,0,-6,-5,-9,-309]])
x = data[:,:-1]
y = data[:,-1]
print(x)#得到x
print(y)#得到y
model = LinearRegression(fit_intercept=False)
model.fit(x,y)#训练
print(model.coef_)#每个w的权重系数
print(model.intercept_)y_pred=model.predict([[0,14,8,0,5,-2,9,-3],[-4,10,6,4,-14,-2,-14,8],[-1,-6,5,-12,3,-3,2,-2],[5,-2,3,10,5,11,4,-8],[-15,-15,-8,-15,7,-4,-12,2],[11,-10,-2,4,3,-9,-6,7],[-14,0,4,-3,5,10,13,7],[-3,-7,-2,-8,0,-6,-5,-9]])
print(y_pred)#根据训练集来测试结果是否对