秋招笔记-8.3
我决定从今天开始每天写一篇笔记,记录自己的秋招状况,以及学习到的相关知识,这个阶段也都是回顾整理性质的了,也算是安抚一下自己焦虑的心情吧。
C++
- 以下代码的输出是什么?
unsigned int a = 10;
int b = -20;
printf("%d", a + b > 0 ? 1 : 0);这里其实主要涉及的问题就是一个有符号数和无符号数计算的问题。当有符号数与无符号数混合运算时,有符号数会隐式转换为无符号数。所以在示例中对于 b = -20,其补码表示(假设 32 位系统)为 4294967276(即 UINT_MAX - 20 + 1)。
- 以下代码的输出是什么?
int x = 2, y = 4;
printf("%d", x & y == 0); // 输出0(先执行`y == 0`,再按位与)[1](@ref)这里主要涉及的知识点就是C++中各个运算符的优先级:
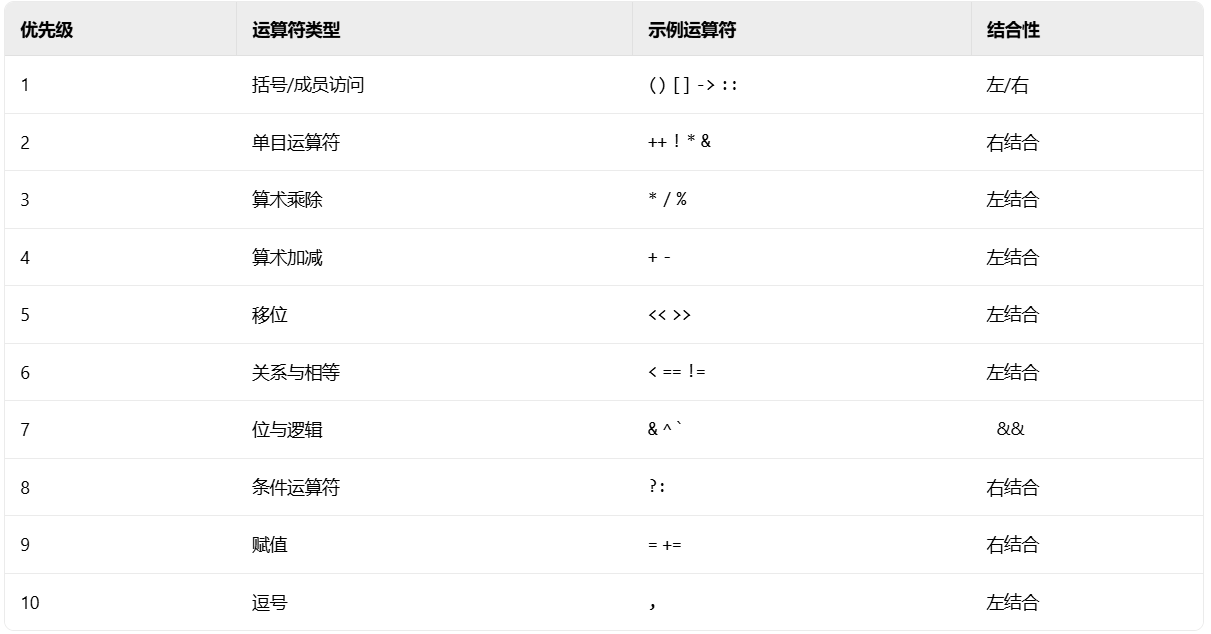
大体上来说,C++中位运算符(&,^,|)的优先级低于关系运算符(==,>,<等)和算术运算符(加减乘除)而高于逻辑运算符(&&等)。(算术 > 移位 > 关系 > 位运算 > 逻辑)
- 如何用位操作设置、清除和检查特定位?
switch语句中case的取值可以是哪些类型?
switch的case只能是枚举变量和整型常量(整型常量是编译期确定的固定整数值)以及其他可以隐式转换成整型常量的类型(int、char、short、long及其unsigned版本)。
- 以下代码的问题是什么?如何修正?
char* create_str() { char str[] = "Hello"; return str; }
int main() { char *s = create_str(); printf("%s", s); }显然,这段代码存在悬空指针的问题:str是create_str()函数的返回值,其生命周期只有在函数执行时,当我们使用指针指向局部变量时就会出现悬空指针的问题,也就是指针指向了已经被释放的对象。
解决方法是用静态关键字修饰相关的对象:
char* create_str() {static char str[] = "Hello"; // 静态存储期,生命周期持续到程序结束return str;
}- 数组名和指针的区别是什么?以下代码的输出是什么?
int arr[5] = {1,2,3,4,5};
int *ptr = (int*)(&arr + 1);
printf("%d %d", *(arr + 1), *(ptr - 1));数组名确实在某些特定情况下会退化成指针来使用,但是本质上数组名和指针还是不同:
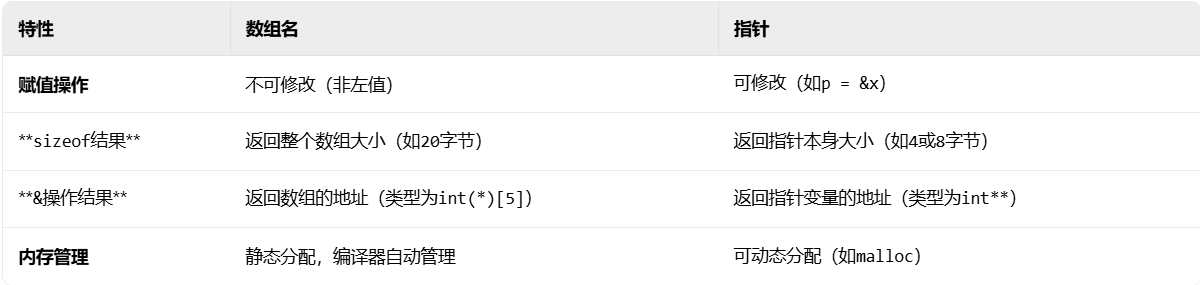
最根本的区别在于数组名是数组的标识符,指针只是其中一种表示数组的方式。
上述的代码中&arr取的是整个数组的地址,所以&arr+1指向的是整个数组地址的下一个地址,而arr就是数组名退化成指向第一个元素指针的用法,所以arr+1指向的是arr数组的第二个元素也就是2,ptr-1指向整个数组的最后一个元素也就是5(如果直接解引用ptr会导致未定义行为)。
#pragma once和#ifndef的区别?
二者都是为了防止头文件被重复包含的预处理命令,但是底层的原理不同。ifndef是C/C++标准的预处理指令,所有符合标准的编译器均支持,兼容性极强,但是需要指定具体的宏名,比如#ifndef MY_HEADER_H;pragma once则是无需定义宏名,仅需一行指令。

这里补充一下头文件重复包含的概念,应该不只我一个人第一次看的时候不理解吧:
相同源代码文件中多次直接包含同一头文件:
// main.c
#include "myheader.h" // 第一次包含
#include "myheader.h" // 第二次包含相同源代码文件中多次间接包含同一头文件:
// a.h
#include "common.h" // b.h
#include "common.h" // main.c
#include "a.h"
#include "b.h" // 间接包含两次common.h头文件之间循环嵌套:
// a.h
#include "b.h" // b.h
#include "a.h" 相同的头文件多次包含会导致重定义问题。
- 如何声明和使用函数指针?以下代码的输出是什么?
int (*funcs[2])(int, int) = {add, sub};
printf("%d", funcs[1](10, 5));声明函数指针的一般格式就如同代码中所写:
// 声明一个函数指针,指向返回int且接受两个int参数的函数
int (*funcPtr)(int, int); 使用的话就只需要在对应的函数参数列表中放入函数指针之后就可以通过指针具体调用函数了。代码中我们是一个包含两个函数指针的数组,这两个函数指针指向的函数都接受两个Int类型的数据作为参数,这两个函数分别是add和sub,虽然看不到具体的函数实现,假设这两个函数的功能就是返回两个Int参数的和和差的话,那么printf的就是10和5的差也就是5。
- 关于const
const我们都很熟悉,用于修饰常量,我们在C++中常常拿const和constexpr来作比较,会说一个要求编译时确定值一个则是编译或者运行时确定值都可以,也就是编译时常量或者运行时常量。但是这里会涉及到一个问题是:初始化的问题。
对于constexpr修饰的变量来说初始化比较死板,因为我们总是要求编译器在编译到具体这一行代码时就能确定相关的常量,所以一般来说constexpr修饰的常量在声明的时候必须初始化;但对于const来说,我们是可以实现一定程度的延迟初始化的:
#include <iostream>
#include <string>// 测试1:全局const变量(必须初始化)
const int GLOBAL_CONST = 42; // 正确:声明时初始化
// const int GLOBAL_NO_INIT; // 错误:全局const未初始化 [8](@ref)class TestClass {
public:// 测试2:类内const成员(必须通过构造函数初始化列表)const int memberConst;TestClass(int val) : memberConst(val) {} // 必须通过初始化列表 [4,7](@ref)// 测试3:static const成员(类内声明,类外初始化)static const int staticConstMember; // 声明
};
const int TestClass::staticConstMember = 100; // 类外初始化 [7](@ref)// 测试4:函数内局部const变量(可延迟到运行时初始化)
void testLocalConst() {int runtimeValue;std::cout << "Enter a number: ";std::cin >> runtimeValue;const int localConst = runtimeValue; // 合法:运行时初始化 [8](@ref)std::cout << "Local const: " << localConst << std::endl;// const int localNoInit; // 错误:局部const未初始化 [6](@ref)
}int main() {// 测试全局和静态conststd::cout << "Global const: " << GLOBAL_CONST << std::endl;std::cout << "Static const member: " << TestClass::staticConstMember << std::endl;// 测试类成员constTestClass obj(50);std::cout << "Class member const: " << obj.memberConst << std::endl;// 测试局部consttestLocalConst();return 0;
}可以看到对于全局常量来说必须声明的同时初始化有值,类中成员常量必须通过构造函数初始化列表,静态常量则是可以在类中声明而在类外赋予值,局部常量可以延迟到函数运行时再具体获取值。总的来说,关键在于const的“不可修改性”从初始化完成后生效,因此必须在首次使用前完成初始化。
- 关于常量指针和指针常量的记忆方法:
这东西实在是非常绕啊,大家应该都有自己的记忆方法,我分享一下我的。

我的记忆方法是,我首先从右往左读,对于第一行就是先有*再有const,那就是先有指针再有常量,也就是指针常量,指针常量就是指针是常量,也就是指针指向的地址不能修改;第二行是常量指针,常量指针是指向常量的指针,也就是指向的地址的变量值不可以修改。
- 原子操作的底层
对于atomic类型我们都已经很熟悉了,原子操作的含义就是保证操作要么不做要么完全完成,不存在中间状态,这里补充一下底层具体的实现,也就是CAS指令。
原子操作的核心是硬件提供的 CAS 指令(如 x86 的 cmpxchg)。该指令比较内存中的值与预期值,若匹配则更新为新值,否则失败。这一过程在硬件层面保证原子性,避免多线程竞争。
但这样会引起一个ABA问题,也就是若值从 A→B→A,CAS 无法感知中间变化。解决方案是 版本号机制(如 AtomicStampedReference),核心思想是为共享变量附加一个单调递增的版本号(或时间戳),使得每次修改不仅更新值,同时递增版本号。这样即使变量的值被改回原值,版本号的变化也能让 CAS 操作识别出中间状态的变化。
- 关于dynamic_cast类型转换
C++的四种类型转换我们都已经非常熟悉了,这其中的dynamic_cast比较特殊:要求必须转换的对象类型必须具有继承关系,那么假如使用对象类型不具有继承关系会怎样呢?
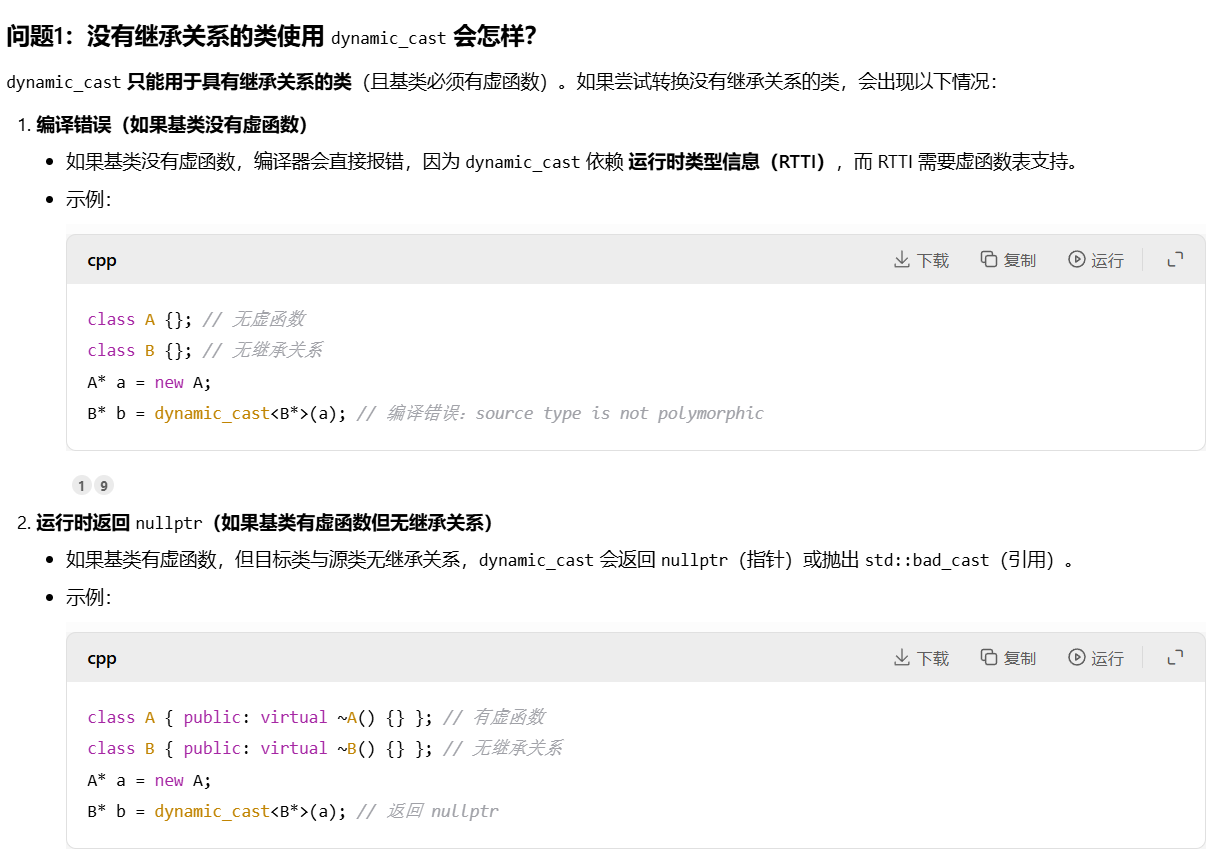
这个RTTI(运行时类型信息)具体来说是 C++ 提供的一种机制,允许程序在运行时动态获取对象的类型信息,主要用于支持多态场景下的类型识别和安全类型转换。其核心功能由两个运算符实现:typeid 和 dynamic_cast。
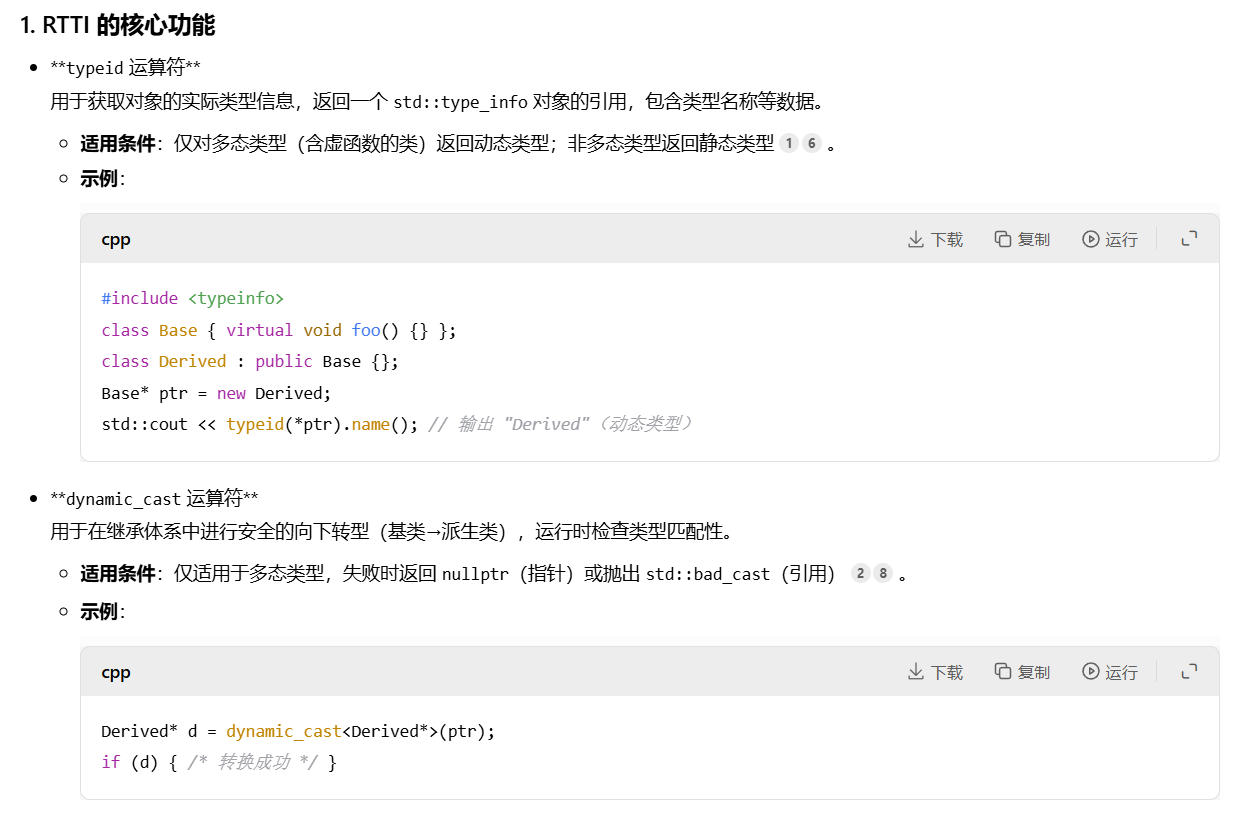
我们之前也聊到了RTTI依赖于虚函数表,多态类的虚函数表中会存储指向 type_info 对象的指针,dynamic_cast 和 typeid 通过查询此信息实现运行时类型判断。
- 关于大端小端
大端(Big-Endian)和小端(Little-Endian)是计算机中两种不同的多字节数据存储顺序方式,主要区别在于字节在内存中的排列顺序。(所谓的大端小端主要针对数值类型的存储有影响,对于诸如字符串等没有影响)
具体来说,大端就是将最高有效字节放在低位地址而把最低有效字节放在高位地址,如1234,1就是最高有效字节(对数值影响最大的那个字节),那么我们会把1放在较低的内存地址,小端模式则是反过来。
这里先复习一下内存地址的概念,内存地址就是一个一定长度的二进制数,长度和计算机的系统位数相关:

为什么要分这两种存储数据的方式,总结来说就是大端更具有可读性而小端方便计算机读取内存。
- 关于共享式指针
我们都知道共享式指针通过引用计数来决定释放内存的时机,但是其实这有个非常具体的问题是,引用计数是存储在哪的呢?
在C++的std::shared_ptr中,引用计数存储在一个独立的控制块(Control Block)中,该控制块与管理的对象分开分配在堆内存上。

当我们第一次调用make_share函数的时候,我们不仅会生成共享式指针,还会同时在堆内存上生成一个控制块,控制块上包含引用计数记录指向该内存的共享式指针数量,还有我们的删除器,当我们的控制块引用计数归零后就会删除内存。我们每个共享式指针也相当于有两个指针,一个指向具体的对象一个指向控制块。
- delete和free
这里有个小细节要补充的是,delete和free相比除了会自动调用析构函数以外,delete还会自动将指针指向nullptr而free不会。大体上来说,free几乎只执行释放内存的操作。
- 内存对齐
我们知道类和结构体要考虑内存对齐的问题(为什么需要内存对齐,因为内存对齐可以避免访问数据时多次访问同一内存块),基本的成员变量内存对齐规则我们已经熟悉了,一是每一个成员变量的起始地址需要是该成员数据类型大小的整数倍,二是总大小得是类或者结构体中最大成员的数据类型的大小的整数倍。
但是我们似乎忽略了一个问题:对于函数来说呢?
在C++中,成员函数(包括普通成员函数、虚函数和静态成员函数)的代码都存储在程序的全局代码段(text段)中,不会占用类或结构体实例的内存空间,所有实例共享同一份函数代码。当调用非静态成员函数时,编译器会自动将当前对象的地址作为this指针隐式传递给函数,函数内部通过this指针加上编译时确定的成员变量偏移量来访问实例中的具体成员变量。对于虚函数,对象实例中会存储一个指向虚函数表的指针(vptr),虚函数表包含了虚函数的实际地址,调用时通过vptr间接跳转,但虚函数代码本身仍存储在代码段。静态成员函数则完全不需要this指针,属于类而非实例。因此,讨论类和结构体的内存对齐时,只需要关注成员变量的排列和对齐规则,成员函数本身不会影响实例的内存布局,它们通过代码段共享和this指针机制与实例关联,实现了代码复用和高效调用。
- stack和queue的底层实现是什么?
stack和queue的底层都是基于deque实现的,stack通过关闭deque关于队列尾部相关操作的API实现而queue则通过关闭push_front和pop_back实现。
C#
- foreach底层
我们都说foreach是一个只读循环,如果我们在foreach中尝试对遍历的元素进行修改就会抛出异常,那么让人不禁想问,foreach的底层是什么才会导致这样呢?
在C#中,foreach循环确实依赖于实现了IEnumerable或IEnumerable<T>接口的数据容器(如List<T>、Dictionary<TKey, TValue>等),其底层通过迭代器模式(IEnumerator)实现遍历。无论遍历的是值类型还是引用类型集合,迭代变量(即循环中的临时变量)始终是元素的副本:对于值类型,获取的是值的副本;对于引用类型,获取的是对象引用的副本(即引用副本,而非原始引用本身)。这意味着通过迭代变量修改值类型(如int)会直接操作副本,而修改引用类型的对象属性(如class的字段)则会影响原始对象,但无法通过迭代变量替换引用本身(如重新赋值对象)。编译器在语法层面禁止直接修改迭代变量(如num = 10),既是为了避免混淆(尤其是值类型的副本修改无效),更是为了防止在遍历过程中因集合结构变化(如增删元素)导致迭代器失效。这种失效会触发InvalidOperationException,因为迭代器内部会检查集合的版本号(version字段),若发现版本不一致(即集合被修改),则立即抛出异常以确保数据一致性。因此,foreach的设计本质是通过限制修改来保证遍历的安全性和可预测性,若需修改集合结构,应改用for循环或先复制集合再操作