快速搭建一个非生产k8s环境
目录
- 摘要
- Docker 的崛起与衰落:Kubernetes 背后的权谋故事
- Containerd
- Containerd 安装
- 🗃️ Containerd 的存储路径解析
- 🧠 OOM 配置:守护进程也要自保!
- ⚙️ Systemd 配置 Containerd 守护进程
- containerd&docker
- Kind、Minikube 和 kubeadm
- Sealos
- Kind快速搭建k8s
- 快速开始
- 创建基础集群
- Create ha cluster
- 实现原理
- 注意事项
- minikube快速搭建k8s
- 快速开始
- 创建单例节点
- 创建集群
- 实现原理
- 注意事项
- kubeadm快速搭建k8s
- 快速开始
- 搭建基础集群
- 初始化控制平面节点
- 安装 Pod 网络附加组件
- 添加工作节点
- 创建高可用集群
- 实现原理
- 注意事项
- 裸金属部署k8s
- Sealos快速搭建k8s
- 快速开始
- 安装 K8s 单机版
- 安装 K8s 集群
- 安装各种分布式应用
- 实现原理
- ⚠️ 注意事项
摘要
在 Kubernetes 的快速演进中,曾经的知识体系已难以应对今天的实际需求。笔者最早学习 Kubernetes 时,版本还停留在 1.17,那时集群搭建严重依赖 Docker。而如今,Kubernetes 已发展至 1.33,默认移除了 Docker shim,全面支持更轻量、标准化的容器运行时(如 containerd),并引入了大量关键特性,运行效率和生态资源均大幅提升。
如果仍停留在旧版本的思维模式中,无疑将被现代云原生体系抛在身后。
过去几个版本,K8s 不仅更新频繁,且每个大版本都引入了重要特性与架构革新,以下是一些里程碑版本:
-
1.20:宣布废弃 Docker shim,推动 containerd 成为主流运行时;引入 Immutable ConfigMap / Secret。
-
1.22:Ingress API 与 CronJob 正式 GA,同时大批旧版 API 被移除(如
extensions/v1beta1)。 -
1.24:彻底移除 Docker 支持;kubelet 身份认证流程插件化。
-
1.25~1.27:PodSecurityAdmission(PSA)取代旧的 PodSecurityPolicy;支持 Windows 容器隔离。
-
1.28:支持 sidecar 容器生命周期;NodeSystemLoad 指标增强调度智能。
-
1.30~1.33:
- 多调度器支持(Multi-Scheduler)增强;
- JobTrackingWithFinalizers 改进批任务可观测性;
- WebAssembly runtime 初步探索;
- KMS v2 正式 GA,加强集群数据加密能力;
- Alpha 支持动态 Node 扩容 API。
这些变更不仅改善了性能与安全性,也为构建更灵活、可扩展的云原生基础设施打下基础。简而言之,现在的 Kubernetes 已完全不同于几年前的样子,是时候重新学习一遍了。
本文将手把手采用一台 Linux(CentOS 7 虚拟机)搭建一个1 主 1 从节点架构的非生产环境的 Kubernetes 集群,帮助你快速实践和理解核心概念。并将详细介绍并和比以下四种部署方式:
- Kind:基于容器的轻量集群,适合快速测试;
- Minikube:本地单节点 K8s,支持丰富运行时与驱动;
- kubeadm:官方推荐的标准安装方式,最贴近生产;
- Sealos:自动化部署新秀,快速构建多节点甚至高可用集群。
结合笔者的经验对比其使用场景与优缺点,帮助读者选择最适合自己的入门方式。
Docker 的崛起与衰落:Kubernetes 背后的权谋故事
很久以前,Docker 强势崛起,以「镜像」这个大招席卷全球,对其他容器技术进行致命的降维打击,使其毫无招架之力,就连 Google 也不例外。
Google 为了不被拍死在沙滩上,被迫拉下脸面希望 Docker 公司和自己联合推进一个开源的容器运行时,作为 Docker 的核心依赖。否则——走着瞧!
Docker 公司觉得自己的智商被侮辱了:走着瞧就走着瞧,谁怕谁啊!
很明显,Docker 的这个决策断送了自己的大好前程,也埋下了今天悲剧的伏笔。
紧接着,Google 联合 Red Hat、IBM 等几位巨佬,连哄带骗忽悠 Docker 公司将 libcontainer 捐给了中立社区 —— OCI(Open Container Initiative),并将其改名为 runc,不留一点 Docker 公司的痕迹。
这还不够。
为了彻底扭转 Docker 一家独大的局面,几位大佬合伙成立了一个基金会:CNCF(Cloud Native Computing Foundation)。
这个名字大家都很熟了,目标也非常明确:
既然在当前容器运行时的维度上干不过 Docker,那就往上爬一个维度,搞大规模容器编排系统(Orchestration),彻底干掉 Docker!
Docker 公司当然不甘示弱,推出 Swarm 与 Kubernetes 正面对抗。结果大家都知道了:
Swarm 战败。
为了自救,Docker 公司耍了个小聪明——将自己的核心依赖 Containerd 捐给 CNCF,以此来标榜自己是个「PaaS 平台」。
结果?
这个小聪明反而大大加速了自己的灭亡。
巨佬们一边冷笑:
当初我们找你合作搞中立运行时,你死要面子不同意;
现在你倒自己搞了一个,还亲手捐出来了,这是什么操作?
那就省事了,我们直接拿 Containerd 开搞。
首先,为了表示 Kubernetes 的中立性,必须搞一个统一的容器运行时接口 ——这就是后来大家熟知的:
CRI(Container Runtime Interface)
只要容器运行时实现了 CRI 接口,Kubernetes 都可以支持你。而第一个原生支持的运行时当然就是 Containerd 啦。
不过,为了不让 Docker 公司察觉被抛弃,Kubernetes 暂时“委屈自己”:
- 在 kubelet 中内置了一个叫
dockershim的垫片 - 用来将 CRI 调用翻译成 Docker 的 API
- 让 Docker 也能继续“愉快地玩耍”
- 温水煮青蛙,养肥了再杀……
就这样,Kubernetes 一边假装和 Docker 玩得开心,一边背地里不断优化 Containerd 的健壮性与 CRI 的兼容性。
等到 Containerd 翅膀硬了,Kubernetes 终于露出真面目:
卸下 shim 伪装,和 Docker 说再见。
- Docker 这项技术,改变了世界。
- Docker 这家公司,却输在格局与战略上。
容器时代的权谋戏码,就此落幕。
Containerd
时至今日,Containerd 已经成长为一个工业级的容器运行时,甚至连官方口号都喊出来了:
超简单!超健壮!可移植性超强!
当然,为了让 Docker 安心、以为自己不会抢饭碗,Containerd 一开始嘴上是这么说的:
“我们只是为了嵌入到更大的系统中,比如 Kubernetes,不是给开发人员或终端用户直接用的。”
这句话翻译一下其实是:
“我不是针对谁,我只是说你不配。”
事实上,现在的 Containerd,已经基本无所不能:
- 在宿主机上直接运行容器
- 管理镜像的传输与存储
- 控制容器的执行、生命周期
- 管理存储、网络资源
无论你是 Dev、Ops、SRE,甚至是搞嵌入式系统的工程师,都可以直接拿 Containerd 当主力工具来用了。
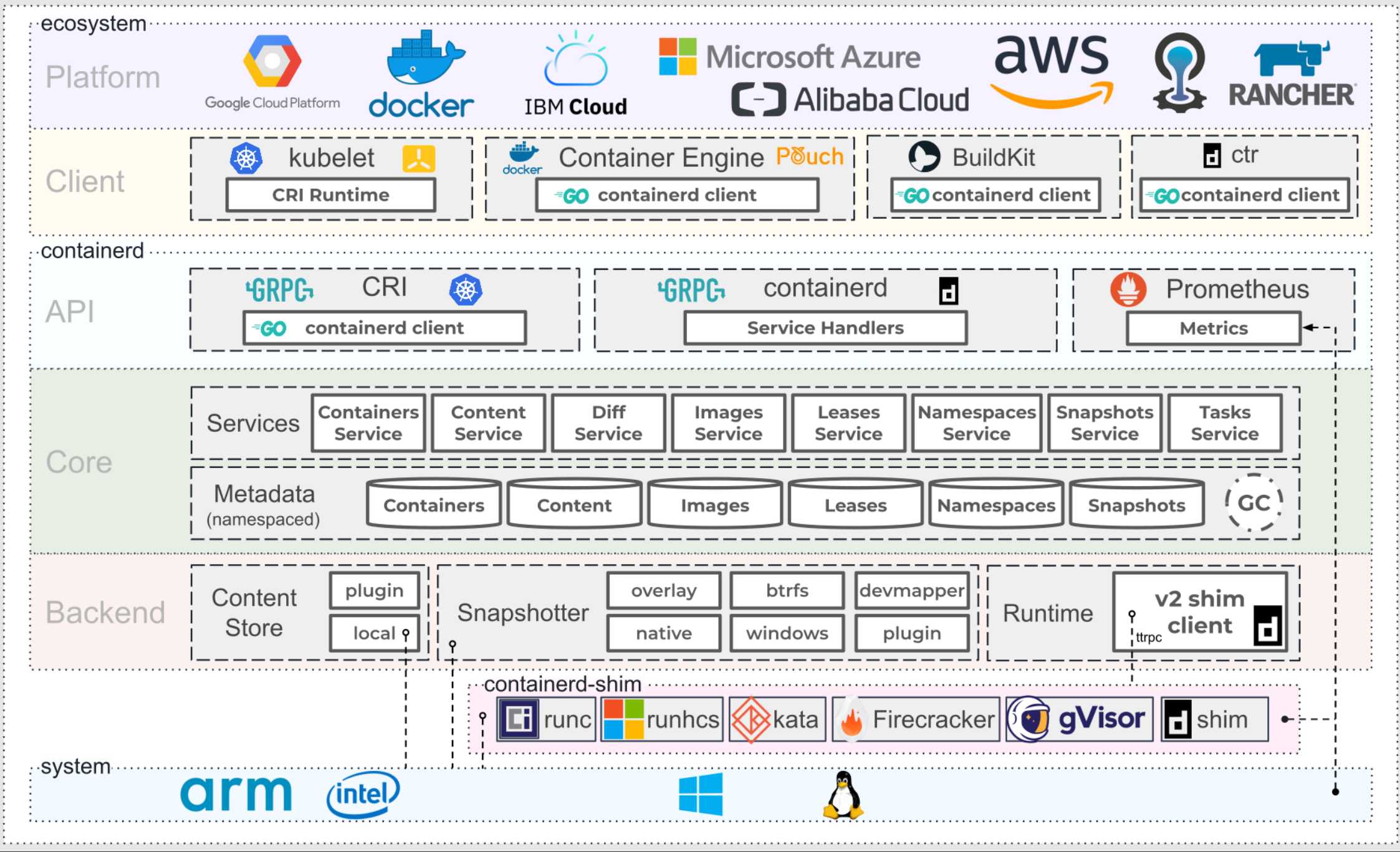
Containerd 采用标准的 C/S 架构,服务端通过 gRPC 协议对外提供稳定的 API,客户端则通过这些 API 执行镜像管理、容器运行、存储操作等高级任务。
为了实现高度解耦与模块化,Containerd 将各个职责划分为不同的“子系统”,并通过插件机制(Plugin System来组织这些功能模块。每个“子系统”可以理解为一个职责域,而内部由多个插件协作完成。例如:
- Bundle:在容器运行时上下文中,Bundle 通常包含容器的配置、元数据与根文件系统(rootfs),它可被视作从镜像中解压出的可执行容器快照。
- Runtime:负责执行 Bundle,包括容器的创建、运行与终止。其内部通过 shim 进程与具体的低层 runtime(如 runc)解耦。
Containerd 中所有功能都是通过插件实现的,包括 Service Plugin(如容器/镜像服务)、Metadata Plugin(存储容器元数据)、Runtime Plugin(运行容器)、GC Plugin(垃圾回收)、Snapshot Plugin(管理文件系统)等。插件之间互相依赖、组合,组成一个完整的服务链。
这些插件按照类型注册进 Containerd 的核心(Core),通过统一的初始化流程加载。在架构图中,每个大虚线框代表一种插件类型,每个小方块代表一个具体插件实例。例如,Metadata Plugin 依赖 Containers Plugin、Content Plugin 等底层服务,而 Service Plugin 又会依赖它们。
一句话总结:在 Containerd 中,万物皆插件,插件就是模块,模块决定能力。这套设计使得 Containerd 具备了极高的扩展性和可组合性,也使它从一个“嵌入式运行时”蜕变为如今广泛用于 Kubernetes 的主力容器运行平台。
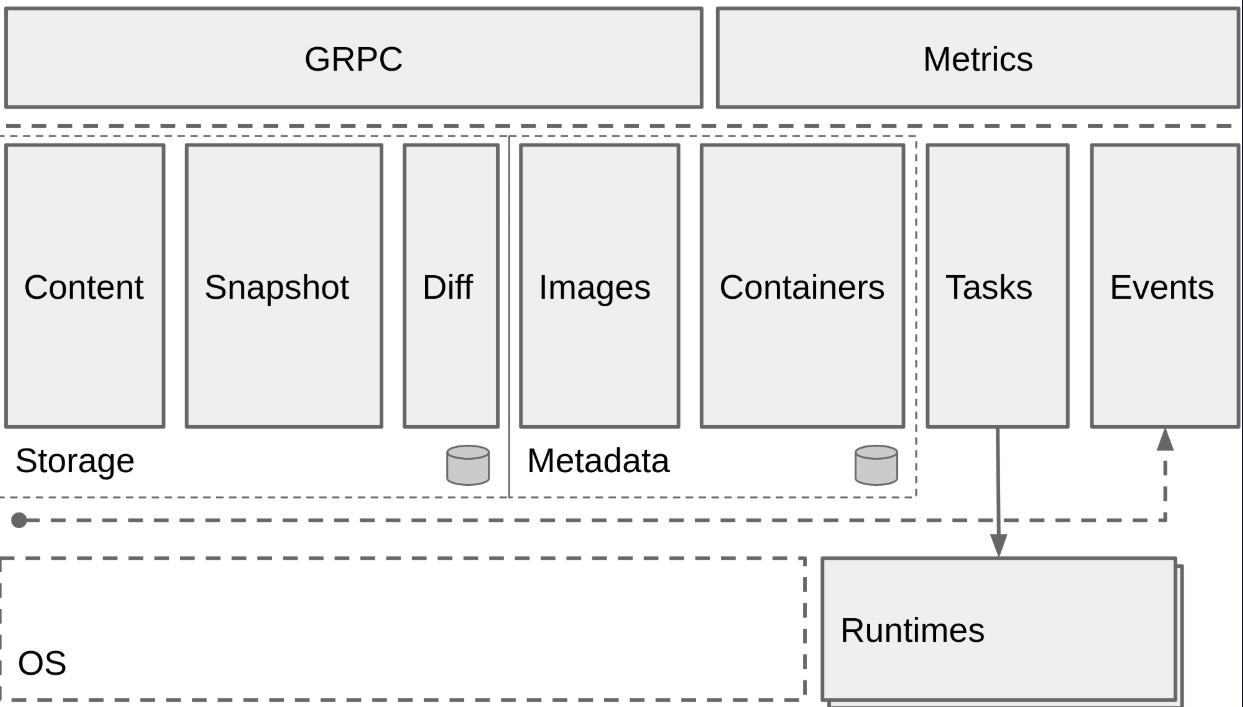
从总体来看,Containerd 被分为三个大块:Storage、Metadata 和 Runtime,可以将上面的架构图提炼一下:
Containerd 安装
containerd 官方二进制发布包支持 amd64(也称 x86_64)和 arm64(也称 aarch64)架构。
通常,你还需要从各自的官方网站安装 runc 和 CNI 插件。
你可以从 官网页面 下载最新版本的压缩包,目前最新版本(最新发布的稳定版本)为:2.0.0。
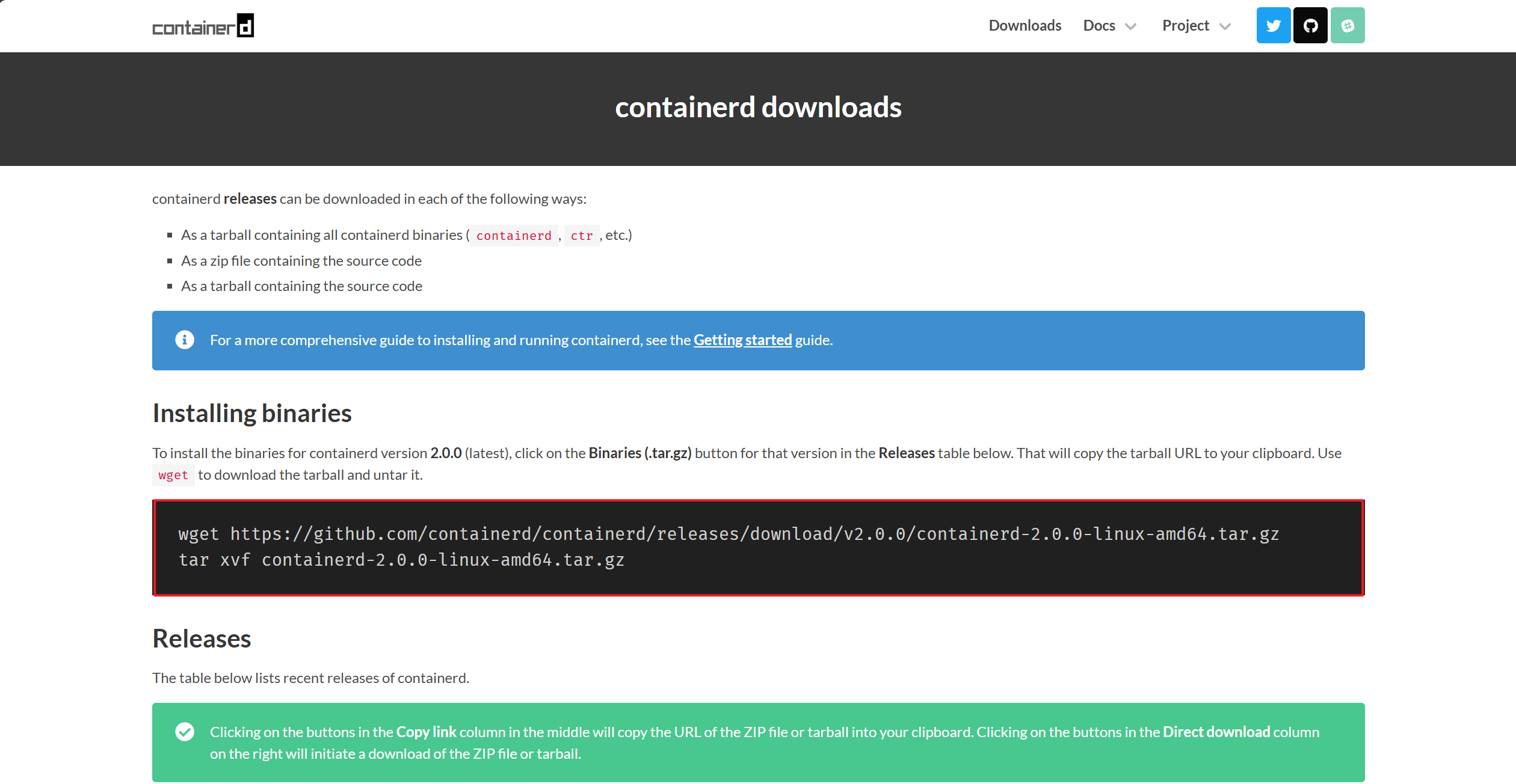
校验 sha256sum 后,将其解压到 /usr/local 目录下:
$ tar Cxzvf /usr/local containerd-1.6.2-linux-amd64.tar.gz
bin/
bin/containerd-shim-runc-v2
bin/containerd-shim
bin/ctr
bin/containerd-shim-runc-v1
bin/containerd
bin/containerd-stress
containerd 二进制文件针对基于 glibc 的 Linux 发行版(如 Ubuntu 和 Rocky Linux)动态编译,可能不适用于基于 musl 的发行版(如 Alpine Linux)。这类发行版的用户可能需要从源码或第三方包安装 containerd。
Kubernetes 是否需要额外下载 cri-containerd-(cni-)--.tar.gz?
答:不需要。
Kubernetes CRI 功能已内置于 containerd-<VERSION>-<OS>-<ARCH>.tar.gz 中,无需额外下载 cri-containerd 包。cri-containerd 包已被废弃,不兼容旧版 Linux,且将在 containerd 2.0 中移除。
如果你打算使用 systemd 启动 containerd,还需从 https://raw.githubusercontent.com/containerd/containerd/main/containerd.service 下载 containerd.service 单元文件,放置到 /usr/local/lib/systemd/system/containerd.service,然后执行:
systemctl daemon-reload
systemctl enable --now containerd
第二步:安装 runc
从 https://github.com/opencontainers/runc/releases 下载对应架构的 runc.<ARCH> 二进制文件,校验 sha256sum,安装到 /usr/local/sbin/runc:
$ install -m 755 runc.amd64 /usr/local/sbin/runc
该二进制为静态编译,应兼容所有 Linux 发行版。
第三步:安装 CNI 插件
从 https://github.com/containernetworking/plugins/releases 下载 cni-plugins-<OS>-<ARCH>-<VERSION>.tgz,校验 sha256sum,解压到 /opt/cni/bin:
$ mkdir -p /opt/cni/bin
$ tar Cxzvf /opt/cni/bin cni-plugins-linux-amd64-v1.1.1.tgz
./
./macvlan
./static
./vlan
./portmap
./host-local
./vrf
./bridge
./tuning
./firewall
./host-device
./sbr
./loopback
./dhcp
./ptp
./ipvlan
./bandwidth
这些插件均为静态编译,适用于所有 Linux 发行版。
第四步:生成配置文件
Containerd 的默认配置文件为 /etc/containerd/config.toml,我们可以通过命令来生成一个默认的配置:
🐳 → mkdir /etc/containerd
🐳 → containerd config default > /etc/containerd/config.toml
第五步:镜像加速
由于某些不可描述的原因,在国内从公共镜像仓库拉取镜像的速度非常慢。为了节省镜像拉取时间,我们通常需要为 Containerd 配置镜像加速器(mirror)。
与 Docker 相比,Containerd 的镜像加速配置有两个重要区别:
-
只对 CRI 接口生效 : Containerd 的镜像 mirror 仅在通过 CRI 拉取镜像时生效,也就是说:
- 使用
crictl或通过 Kubernetes 调用时,mirror 会被正确使用; - 使用
ctr命令拉取镜像时,mirror 不会生效。
- 使用
-
支持任意镜像仓库配置 : Docker 只能为 Docker Hub 配置镜像加速,而 Containerd 支持为任意镜像仓库地址配置 mirror,灵活性更强。
在实际部署 Kubernetes 时,建议优先设置 Containerd 的镜像加速源,确保关键系统组件(如 pause、coredns、kube-proxy 等)可以顺利拉取。
配置镜像加速之前,先来看下 Containerd 的配置结构,乍一看可能会觉得很复杂,复杂就复杂在 plugin 的配置部分:
[plugins][plugins."io.containerd.gc.v1.scheduler"]pause_threshold = 0.02deletion_threshold = 0mutation_threshold = 100schedule_delay = "0s"startup_delay = "100ms"[plugins."io.containerd.grpc.v1.cri"]disable_tcp_service = truestream_server_address = "127.0.0.1"stream_server_port = "0"stream_idle_timeout = "4h0m0s"enable_selinux = falsesandbox_image = "k8s.gcr.io/pause:3.1"stats_collect_period = 10systemd_cgroup = falseenable_tls_streaming = falsemax_container_log_line_size = 16384disable_cgroup = falsedisable_apparmor = falserestrict_oom_score_adj = falsemax_concurrent_downloads = 3disable_proc_mount = false[plugins."io.containerd.grpc.v1.cri".containerd]snapshotter = "overlayfs"default_runtime_name = "runc"no_pivot = false[plugins."io.containerd.grpc.v1.cri".containerd.default_runtime]runtime_type = ""runtime_engine = ""runtime_root = ""privileged_without_host_devices = false[plugins."io.containerd.grpc.v1.cri".containerd.untrusted_workload_runtime]runtime_type = ""runtime_engine = ""runtime_root = ""privileged_without_host_devices = false[plugins."io.containerd.grpc.v1.cri".containerd.runtimes][plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc]runtime_type = "io.containerd.runc.v1"runtime_engine = ""runtime_root = ""privileged_without_host_devices = false[plugins."io.containerd.grpc.v1.cri".cni]bin_dir = "/opt/cni/bin"conf_dir = "/etc/cni/net.d"max_conf_num = 1conf_template = ""[plugins."io.containerd.grpc.v1.cri".registry][plugins."io.containerd.grpc.v1.cri".registry.mirrors][plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]endpoint = ["https://registry-1.docker.io"][plugins."io.containerd.grpc.v1.cri".x509_key_pair_streaming]tls_cert_file = ""tls_key_file = ""[plugins."io.containerd.internal.v1.opt"]path = "/opt/containerd"[plugins."io.containerd.internal.v1.restart"]interval = "10s"[plugins."io.containerd.metadata.v1.bolt"]content_sharing_policy = "shared"[plugins."io.containerd.monitor.v1.cgroups"]no_prometheus = false[plugins."io.containerd.runtime.v1.linux"]shim = "containerd-shim"runtime = "runc"runtime_root = ""no_shim = falseshim_debug = false[plugins."io.containerd.runtime.v2.task"]platforms = ["linux/amd64"][plugins."io.containerd.service.v1.diff-service"]default = ["walking"][plugins."io.containerd.snapshotter.v1.devmapper"]root_path = ""pool_name = ""base_image_size = ""
每一个顶级配置块的命名都是 plugins.“io.containerd.xxx.vx.xxx” 这种形式,其实每一个顶级配置块都代表一个插件,其中 io.containerd.xxx.vx 表示插件的类型,vx 后面的 xxx 表示插件的 ID。可以通过 ctr 一览无余:
🐳 → ctr plugin ls
TYPE ID PLATFORMS STATUS
io.containerd.content.v1 content - ok
io.containerd.snapshotter.v1 btrfs linux/amd64 error
io.containerd.snapshotter.v1 devmapper linux/amd64 error
io.containerd.snapshotter.v1 aufs linux/amd64 ok
io.containerd.snapshotter.v1 native linux/amd64 ok
io.containerd.snapshotter.v1 overlayfs linux/amd64 ok
io.containerd.snapshotter.v1 zfs linux/amd64 error
io.containerd.metadata.v1 bolt - ok
io.containerd.differ.v1 walking linux/amd64 ok
io.containerd.gc.v1 scheduler - ok
io.containerd.service.v1 containers-service - ok
io.containerd.service.v1 content-service - ok
io.containerd.service.v1 diff-service - ok
io.containerd.service.v1 images-service - ok
io.containerd.service.v1 leases-service - ok
io.containerd.service.v1 namespaces-service - ok
io.containerd.service.v1 snapshots-service - ok
io.containerd.runtime.v1 linux linux/amd64 ok
io.containerd.runtime.v2 task linux/amd64 ok
io.containerd.monitor.v1 cgroups linux/amd64 ok
io.containerd.service.v1 tasks-service - ok
io.containerd.internal.v1 restart - ok
io.containerd.grpc.v1 containers - ok
io.containerd.grpc.v1 content - ok
io.containerd.grpc.v1 diff - ok
io.containerd.grpc.v1 events - ok
io.containerd.grpc.v1 healthcheck - ok
io.containerd.grpc.v1 images - ok
io.containerd.grpc.v1 leases - ok
io.containerd.grpc.v1 namespaces - ok
io.containerd.internal.v1 opt - ok
io.containerd.grpc.v1 snapshots - ok
io.containerd.grpc.v1 tasks - ok
io.containerd.grpc.v1 version - ok
io.containerd.grpc.v1 cri linux/amd64 ok
顶级配置块下面的子配置块表示该插件的各种配置,比如 cri 插件下面就分为 containerd、cni 和 registry 的配置,而 containerd 下面又可以配置各种 runtime,还可以配置默认的 runtime。
配置文件说明文档:https://github.com/containerd/containerd/blob/main/docs/cri/registry.md
注意: 之前文档中提到的
registry.mirrors和registry.configs配置方式 已被弃用。
从现在开始,应根据 CRI 插件的配置使用如下方式:
✅ 在 containerd 2.x 中:
[plugins."io.containerd.cri.v1.images".registry]config_path = "/etc/containerd/certs.d"
✅ 在 containerd 1.x 中:
[plugins."io.containerd.grpc.v1.cri".registry]config_path = "/etc/containerd/certs.d"
你需要将镜像加速或私有仓库的相关配置文件(如 hosts.toml)放在 /etc/containerd/certs.d/<registry> 目录下,比如:
/etc/containerd/certs.d/docker.io/hosts.toml
这样才能生效,k8s中涉及到的仓库有如下
docker.elastic.co
docker.io
gcr.io
ghcr.io
k8s.gcr.io
registry.k8s.io
mcr.microsoft.com
nvcr.io
quay.io
创建配置文件:
touch /etc/containerd/certs.d/docker.io/hosts.toml
touch /etc/containerd/certs.d/registry.k8s.io/hosts.tomlcat>/etc/containerd/certs.d/docker.io/hosts.toml<<EOF
server = "https://docker.io"[host."https://docker.m.daocloud.io"]capabilities = ["pull", "resolve"]
[host."https://dockerproxy.com/"]capabilities = ["pull", "resolve"]
EOFcat>/etc/containerd/certs.d/registry.k8s.io/hosts.toml<<EOF
server = "registry.k8s.io"[host."k8s.m.daocloud.io"]capabilities = ["pull", "resolve"]
EOF
重启containerd
systemctl restart containerd.service
测试拉取:
crictl pull busybox
或者采用传统配置(需要重启containerd):
version = 3[plugins."io.containerd.cri.v1.images".registry][plugins."io.containerd.cri.v1.images".registry.mirrors][plugins."io.containerd.cri.v1.images".registry.mirrors."docker.io"]endpoint = ["https://registry-1.docker.io"][plugins."io.containerd.cri.v1.images".registry.mirrors."gcr.io"]endpoint = ["https://gcr.io"][plugins."io.containerd.cri.v1.images".registry.configs][plugins."io.containerd.cri.v1.images".registry.configs."gcr.io".auth]username = "_json_key"password = '<jq 命令生成的单行 JSON key 内容>'
🗃️ Containerd 的存储路径解析
Containerd 使用两个不同的路径分别存储持久化数据和运行时状态:
root = "/var/lib/containerd" # 持久化数据目录
state = "/run/containerd" # 临时运行状态目录
📦 root = /var/lib/containerd用于保存 Containerd 的持久化数据,包括:
- 镜像内容(Content)
- 快照数据(Snapshots)
- 元数据(Metadata)
- 插件自己的数据(如 CRI、Runtime、Snapshotter 等)
Containerd 本身不存储任何业务数据,它的功能完全来自于加载的插件,每个插件在 root 目录下都有独立的子目录。
🐳 → tree -L 2 /var/lib/containerd//var/lib/containerd/
├── io.containerd.content.v1.content # 镜像内容存储
│ ├── blobs
│ └── ingest
├── io.containerd.grpc.v1.cri # CRI 插件的容器 & sandbox 管理
│ ├── containers
│ └── sandboxes
├── io.containerd.metadata.v1.bolt # 元数据数据库
│ └── meta.db
├── io.containerd.runtime.v1.linux # v1 runtime(已废弃)
│ └── k8s.io
├── io.containerd.runtime.v2.task # v2 runtime(推荐)
├── io.containerd.snapshotter.v1.aufs # aufs 快照插件(已废弃)
│ └── snapshots
├── io.containerd.snapshotter.v1.btrfs # btrfs 快照插件
├── io.containerd.snapshotter.v1.native # native 快照插件
│ └── snapshots
├── io.containerd.snapshotter.v1.overlayfs # overlayfs 快照插件(默认)
│ ├── metadata.db
│ └── snapshots
└── tmpmounts # 临时挂载目录
总计:18 个目录,2 个文件
⚙️ state = /run/containerd 用于保存运行时的临时数据,包括:
- socket 通信文件
- PID 进程信息
- 容器运行状态
- sandbox 状态
- 挂载点
- 不需要持久化的插件运行数据
🐳 → tree -L 2 /run/containerd//run/containerd/
├── containerd.sock # GRPC socket
├── containerd.sock.ttrpc # TTRPC socket
├── io.containerd.grpc.v1.cri # CRI 插件的运行时数据
│ ├── containers
│ └── sandboxes
├── io.containerd.runtime.v1.linux # v1 runtime 的运行状态
│ └── k8s.io
├── io.containerd.runtime.v2.task # v2 runtime 的运行状态
└── runc # runc 的临时状态└── k8s.io
总计:8 个目录,2 个文件
| 目录路径 | 说明 |
|---|---|
/var/lib/containerd | 持久化数据,插件存储、镜像、元数据等 |
/run/containerd | 临时运行状态,socket、pid、挂载点等 |
Containerd 设计得非常模块化且灵活,几乎所有的功能都通过插件扩展,插件即功能,万物皆插件。熟悉这些存储结构,有助于我们深入理解容器运行时的底层机制。
🧠 OOM 配置:守护进程也要自保!
在配置 Containerd 时,有一个容易被忽视但非常重要的设置项:
oom_score = 0
Containerd 作为容器的守护者,如果发生内存不足(Out Of Memory,简称 OOM),我们希望优先杀掉的是运行中的容器,而不是 Containerd 本身。一旦 Containerd 被 OOM Killer 干掉,集群调度和容器生命周期都会受到影响。
为此,应当调整 Containerd 的 OOM 权重(oom_score_adj),让它在 OOM 情况下尽可能“保命”。
📌 Linux 中的 OOM 分数机制
-
OOM 权重配置文件为:
/proc/<pid>/oom_score_adj -
配置值范围:从
-1000到+1000-1000: 永远不会被 OOM Killer 杀死0: 默认值,中性权重+1000: 极容易被 OOM Killer 杀死
在旧版 Linux 中曾用
oom_adj表示这个值,现在统一为oom_score_adj。
系统在进行 OOM 杀时会计算每个进程的 badness score,而这个分数 = 系统评估值 + oom_score_adj。
-
所以:
oom_score_adj = -1000→ badness 永远为 0 → 永不被杀oom_score_adj = 500→ 更容易被杀oom_score_adj = -999 ~ 0→ 较低的风险等级
✅ 建议配置
| 场景 | 建议值 |
|---|---|
| 一般环境 | oom_score = 0 |
| 保守策略 | oom_score = -500 |
| Kubernetes Worker 节点 | oom_score = -999(强烈推荐) |
注意:此配置最终会被转换为
/proc/<pid>/oom_score_adj的值,在系统层面生效。
设置好 OOM 权重后,Containerd 在面对系统内存压力时就能优先存活下来,继续保障集群中容器的调度与恢复,真正做一个“守护者”而不是“先死者”。
⚙️ Systemd 配置 Containerd 守护进程
为了确保 Containerd 稳定运行,建议通过 systemd 启动并管理它。解压出的 systemd 配置文件路径如下:
🐳 → cat /etc/systemd/system/containerd.service
# Copyright The containerd Authors.
# Licensed under the Apache License, Version 2.0[Unit]
Description=containerd container runtime
Documentation=https://containerd.io
After=network.target local-fs.target[Service]
ExecStartPre=-/sbin/modprobe overlay
ExecStart=/usr/local/bin/containerdType=notify
Delegate=yes
KillMode=process
Restart=always
RestartSec=5# 建议不显式设置资源限制,避免内核开销
LimitNPROC=infinity
LimitCORE=infinity
LimitNOFILE=1048576
TasksMax=infinityOOMScoreAdjust=-999[Install]
WantedBy=multi-user.target
📝 关键参数说明
🔹 Delegate = yes
- 启用此参数后,允许 Containerd 管理其自身的 cgroups。
- 若未启用,systemd 会将容器进程归入其自身的 cgroup,导致资源统计不准确,影响容器运行时的隔离和监控。
🔹 KillMode = process
- 控制当 containerd 服务终止时,如何处理其子进程。
- 可选项说明:
| 值 | 说明 |
|---|---|
control-group(默认) | 杀死该服务控制组下的所有进程 |
process ✅ | 只杀主进程(推荐设置) |
mixed | 主进程收到 SIGTERM,子进程收到 SIGKILL |
none | 不发送信号,仅执行 stop 命令 |
- 设置为
process可避免重启 Containerd 时误杀已有容器。
🚀 启动 Containerd
配置好 systemd 服务后,通过如下命令立即启用并启动:
🐳 → systemctl enable containerd --now
关于ctr,ctr 目前很多功能做的还没有 docker 那么完善,但基本功能已经具备了。但这里不打算赘述,因为正如开头所说,containerd是作为一个runtime嵌入到更大的系统中的,不是给开发人员单独拿出来使用的。
虽然,docker在这场容器之争失败了,但在单容器的使用上docker还是一哥。你会想用不完善的ctr命令去使用containerd吗? 你会因为containerd打包dockerfile吗(不完全支持dockerfile)?
containerd&docker
这张图显示了 Docker、Kubernetes、CRI、OCI、containerd 和 runc 在这个生态系统中是如何结合的。

其整体工作流程可以简要概括如下:
-
上层工具调用容器运行时
- 如:Docker、Kubernetes 等容器管理工具,在需要运行容器时,会调用容器运行时(如 containerd、CRI-O)。
-
容器运行时负责实际操作
- 容器运行时负责容器的创建、运行、销毁等实际工作。
-
Docker 与 Kubernetes 的关系
- Docker 使用的是 containerd 作为其默认的容器运行时。
- Kubernetes 支持多种容器运行时,包括 containerd、CRI-O 等。
-
标准化规范
- 这些容器运行时均遵循 OCI(Open Container Initiative)规范。
- 最终通过 runc 与操作系统内核交互,实现容器的生命周期管理(创建、运行等)。
Docker 可以轻松地构建容器镜像,从 Docker Hub 中拉取镜像,创建、启动和管理容器。实际上,当你用 Docker 运行一个容器时实际上是通过 Docker 守护程序、containerd 和 runc 来运行它。

如果你使用Docker作为K8S容器运行时的话,kubelet需要先要通过dockershim去调用Docker,再通过Docker去调用containerd。

如果你使用containerd作为K8S容器运行时的话,由于containerd内置了CRI插件,kubelet可以直接调用containerd。

实际上,Docker 与 Containerd 是可以共存使用的。不过需要注意的是,Docker 默认使用的 Containerd 命名空间并不是 default,而是 moby。
从其他安装了 Docker 的机器或者 GitHub 上下载 Docker 的二进制文件后,使用以下命令启动 Docker,并指定使用已有的 containerd:
dockerd --containerd /run/containerd/containerd.sock --cri-containerd
🚀 使用 Docker 运行容器
docker run -d --name nginx nginx:alpine
🔍 查看 Containerd 的命名空间
ctr ns ls
输出结果:
NAME LABELS
default
moby
查看 moby 命名空间下的容器
ctr -n moby c ls
输出示例:
CONTAINER IMAGE RUNTIME
b7093d7aaf8e1ae161c8c8ffd4499c14ba635d8e174cd03711f4f8c27818e89a - io.containerd.runtime.v1.linux
由此可以证明,Docker 与 Containerd 是可以同时运行的,Docker 所管理的容器实际上存储在 Containerd 的 moby 命名空间中。
Kind、Minikube 和 kubeadm
这三种工具 —— Kind、Minikube 和 kubeadm —— 都可以用来搭建 Kubernetes 集群,但适用场景、使用方式、集群运行环境差异很大,适合不同的用户需求。下面是对它们的详细对比:
✅ 1. Kind(Kubernetes IN Docker)
简介:
- 用 Docker 容器来运行 Kubernetes 的控制平面和节点。
- 每个节点其实就是一个 Docker 容器,适合 本地开发与测试。
特点:
| 特性 | 描述 |
|---|---|
| 运行环境 | Docker 容器内部 |
| 安装依赖 | 仅需 Docker |
| 使用场景 | CI/CD 测试、快速验证 Kubernetes 配置、运行轻量级集群 |
| 支持多节点 | ✅ 支持(模拟节点) |
| 性能 | 高(仅用于测试),资源隔离性差 |
| 生产可用性 | ❌ 不适合生产环境 |
优点:
- 启动快、销毁快、可脚本化集成。
- 不需要虚拟机,适合容器化环境。
✅ 2. Minikube
简介:
- 用于本地搭建单节点 Kubernetes 集群的工具。
- 会在本地创建一个虚拟机或容器,运行 Kubernetes 节点。
特点:
| 特性 | 描述 |
|---|---|
| 运行环境 | 虚拟机或容器(Docker、Podman、VirtualBox等) |
| 安装依赖 | 虚拟化或容器运行时 |
| 使用场景 | 本地开发、学习 Kubernetes |
| 支持多节点 | ✅(较新版本支持) |
| 性能 | 中等 |
| 生产可用性 | ❌ 不适合生产环境 |
优点:
- 适合学习和验证 Kubernetes 的操作。
- 提供 Dashboard、ingress 插件、文件共享等功能,比较“全家桶”。
✅ 3. kubeadm
简介:
- 官方推荐的 生产级部署工具。
- 提供 kubeadm init/join 命令帮助初始化和扩展集群。
特点:
| 特性 | 描述 |
|---|---|
| 运行环境 | 真实主机/云服务器/虚拟机 |
| 安装依赖 | 操作系统、容器运行时(如 containerd)、网络插件等 |
| 使用场景 | 构建生产环境、多节点 Kubernetes 集群 |
| 支持多节点 | ✅(物理或虚拟机真实节点) |
| 性能 | 高(接近真实生产环境) |
| 生产可用性 | ✅ 官方推荐方式 |
优点:
- 更贴近生产环境,完全控制安装过程。
- 能自定义组件版本、网络插件、安全配置。
🚀 总结对比:
| 对比项 | Kind | Minikube | kubeadm |
|---|---|---|---|
| 是否生产可用 | ❌ 仅测试 | ❌ 学习与测试用 | ✅ 生产部署 |
| 节点运行环境 | Docker 容器 | 虚拟机或容器 | 实体机/虚拟机/云服务器 |
| 是否支持多节点 | ✅(容器模拟) | ✅(支持,但复杂) | ✅(真实节点) |
| 安装复杂度 | ⭐ 简单 | ⭐⭐ 简单 | ⭐⭐⭐⭐ 复杂(需要手动配置) |
| 启动速度 | 🚀 极快 | 🚀 快 | 🐢 慢(看节点数量和配置) |
| 适合谁 | Dev / CI/CD 工程师 | 初学者 / 本地开发者 | SRE / 运维 / 架构师 |
✅ 总结建议:
| 使用目的 | 推荐工具 |
|---|---|
| 本地快速测试 CI 环境 | Kind |
| 学习 Kubernetes、图形界面操作 | Minikube |
| 构建真实的生产环境 | kubeadm |
如果你是开发者想做快速本地验证,用 Kind;如果是初学者想上手用图形界面,选 Minikube;如果你是运维团队想部署生产集群,那就必须熟悉 kubeadm。
关于这三个工具的搭建原理,以及是否都依赖 Docker?
这个问题非常关键:
-
Kind:必须依赖 Docker
- 原理:Kind 本质上是“用 Docker 容器模拟 Kubernetes 节点”。
- 所以你没有 Docker 是绝对不能用的。
- 它的每个“节点”其实是一个运行了 Kubernetes 的容器。
-
Minikube:可选依赖 Docker
-
Minikube 本质上是创建一个“虚拟机”或“容器”来运行 K8s。
-
支持多种后端驱动,包括:
- Docker(用 Docker 容器跑整个集群)
- VirtualBox、KVM(跑虚拟机)
- containerd、podman 等
-
如果你选择 Docker 作为驱动,就必须安装 Docker;否则不需要。
-
-
kubeadm:不依赖 Docker,但需有容器运行时
- kubeadm 是最贴近生产的一种方式,它本身不需要 Docker,但它需要 CRI(容器运行时)。
- 在过去,Docker 是最常用的容器运行时(也就是 kubelet 默认调用 Docker 来跑 Pod)。
- 但现在 Kubernetes 已经弃用 Docker,转向更轻量级的 containerd、CRI-O 等。
✅ 那么,真正的生产环境 K8s 是怎么搭建的?
真正的搭建 Kubernetes,是在物理机或虚拟机上,手动安装并组装各个组件。
🔧 核心组件包括:
| 组件 | 作用 |
|---|---|
| kubelet | 每个节点上的核心 agent,负责运行 Pod |
| kubeadm | 用来初始化和配置整个集群 |
| kube-apiserver | 控制面核心,提供 REST 接口 |
| kube-controller-manager | 管理副本数、自动扩缩容等 |
| kube-scheduler | 决定 Pod 运行在哪个节点 |
| etcd | 存储集群状态(K8s 的数据库) |
| containerd / CRI | 容器运行时,实际跑 Pod 的容器 |
| CNI 插件 | 网络插件(Flannel、Calico、Cilium) |
这些东西要你逐一配置、启动、联通,才能组成一个“真正的集群”。
-
如果你想了解 Kubernetes 真正是怎么搭起来的,建议:
- 使用多台虚拟机(或物理机);
- 安装
containerd、kubeadm、kubelet、kubectl; - 自己动手运行
kubeadm init和join; - 配置 CNI 网络插件、CoreDNS 等组件。
你就会对 Kubernetes 整个架构和运作机制有深入理解。(“Kubernetes The Hard Way”很复杂,也很耗时间,更多是为了深入理解 Kubernetes 内部原理和组件关系。)
Kubernetes 作为一个云原生容器编排平台,由多个核心组件组成:
- etcd:集群数据存储
- kube-apiserver:集群入口和 API 网关
- kube-controller-manager、kube-scheduler:控制器和调度器
- kubelet、kube-proxy:节点代理和网络代理
- 容器运行时(containerd):负责运行容器
-
手动部署(The Hard Way)
- 下载官方二进制包,逐个配置和启动以上所有组件
- 手动生成和分发 TLS 证书,保证组件安全通信
- 写 systemd 服务文件,管理生命周期
- 手动配置网络插件(Flannel、Calico 等)
- 适合学习 Kubernetes 架构和底层机制,难度高,容易出错
-
kubeadm 自动化部署
- 官方推荐的“半自动化”工具,帮你自动生成证书、配置文件、启动组件
- 只需执行
kubeadm init和kubeadm join,快速搭建标准化集群 - 默认使用 containerd 作为容器运行时,轻量且性能好
- 适合生产环境及运维快速部署和管理
- 方便集群扩容、升级和维护
为什么生产环境更喜欢 kubeadm + containerd?
- containerd 是 CNCF 认可的轻量级容器运行时,和 Kubernetes 深度集成,稳定性和性能优秀
kubeadm简化了繁琐配置,让运维节省大量时间- 易于管理集群生命周期、证书更新、安全加固
- 可扩展性好,支持多节点多 Master 集群
Sealos
Sealos 是一款以 Kubernetes 为内核的云操作系统发行版。它以云原生的方式,抛弃了传统的云计算架构,转向以 Kubernetes 为云内核的新架构,使企业能够像使用个人电脑一样简单地使用云。

我们主要使用他的命令行:https://github.com/labring/sealos/releases/tag/v5.0.1
该项目旨在做一个简单干净轻量级稳定的 kubernetes 安装工具,一条命令,离线安装,包含所有依赖,内核负载不依赖 haproxy keepalived,纯 golang 开发,99 年证书,反正就是很牛逼。
🐳 → wget -c https://sealyun.oss-cn-beijing.aliyuncs.com/latest/sealos
🐳 → chmod +x sealos && mv sealos /usr/bin
后续他将作为我们搭建k8s的一种参考。
Kind快速搭建k8s
Kind 是一个使用 Docker 容器“节点”来运行本地 Kubernetes 集群的工具。
Kind 主要设计用于测试 Kubernetes 本身,但也可以用于本地开发或持续集成(CI)。
如果你安装了 Go 1.17 及以上版本,并且有 Docker、Podman 或 Nerdctl,
只需运行 go install sigs.k8s.io/kind@v0.29.0 然后执行 kind create cluster 就可以轻松创建集群!
Kind 由以下部分组成:
- 实现集群创建、镜像构建等功能的 Go 包。
- 基于这些包构建的命令行工具(kind)。
- 用于运行 systemd、Kubernetes 等的 Docker 镜像。
- 基于这些包构建的 kubetest 集成(正在开发中)。
注意:kind 通过 kubeadm 来引导每个“节点”。
快速开始
创建基础集群
kind 只是一个二进制文件,因此下载下来放到 bin 目录即可。
curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.29.0/kind-linux-amd64
chmod +x ./kind
sudo mv ./kind /usr/local/bin/kind
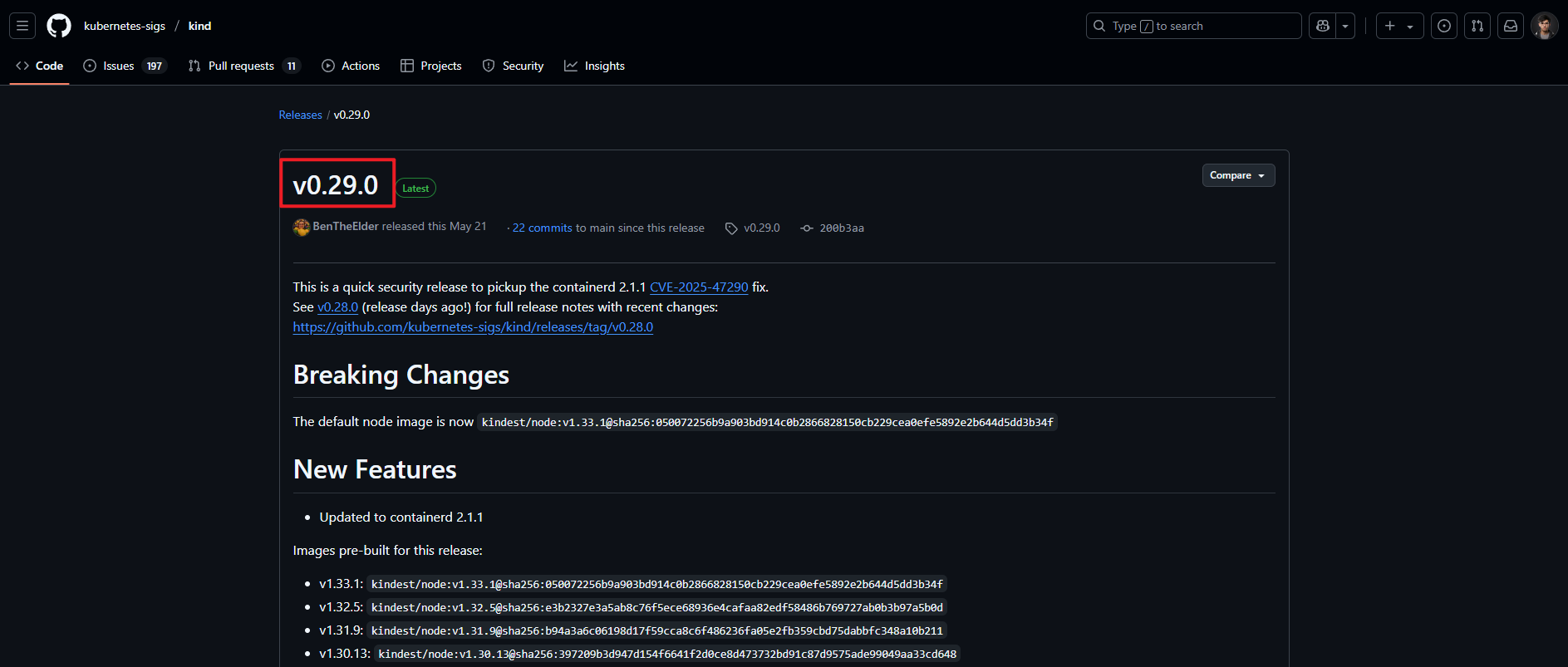
Kind 只负责创建集群(会配置好 kubeconfig),后续操作集群的话需要手动安装 kubectl.
curl -LO "https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl"
chmod +x kubectl
sudo mv kubectl /usr/local/bin
一切就绪之后,使用 kind 创建集群即可。
kind 0.29.0 默认用的是 v.1.30.x 版本 k8s,可以先手动拉镜像,因为默认的镜像地址不一定能拉下来。
docker pull kindest/node:v1.30.0
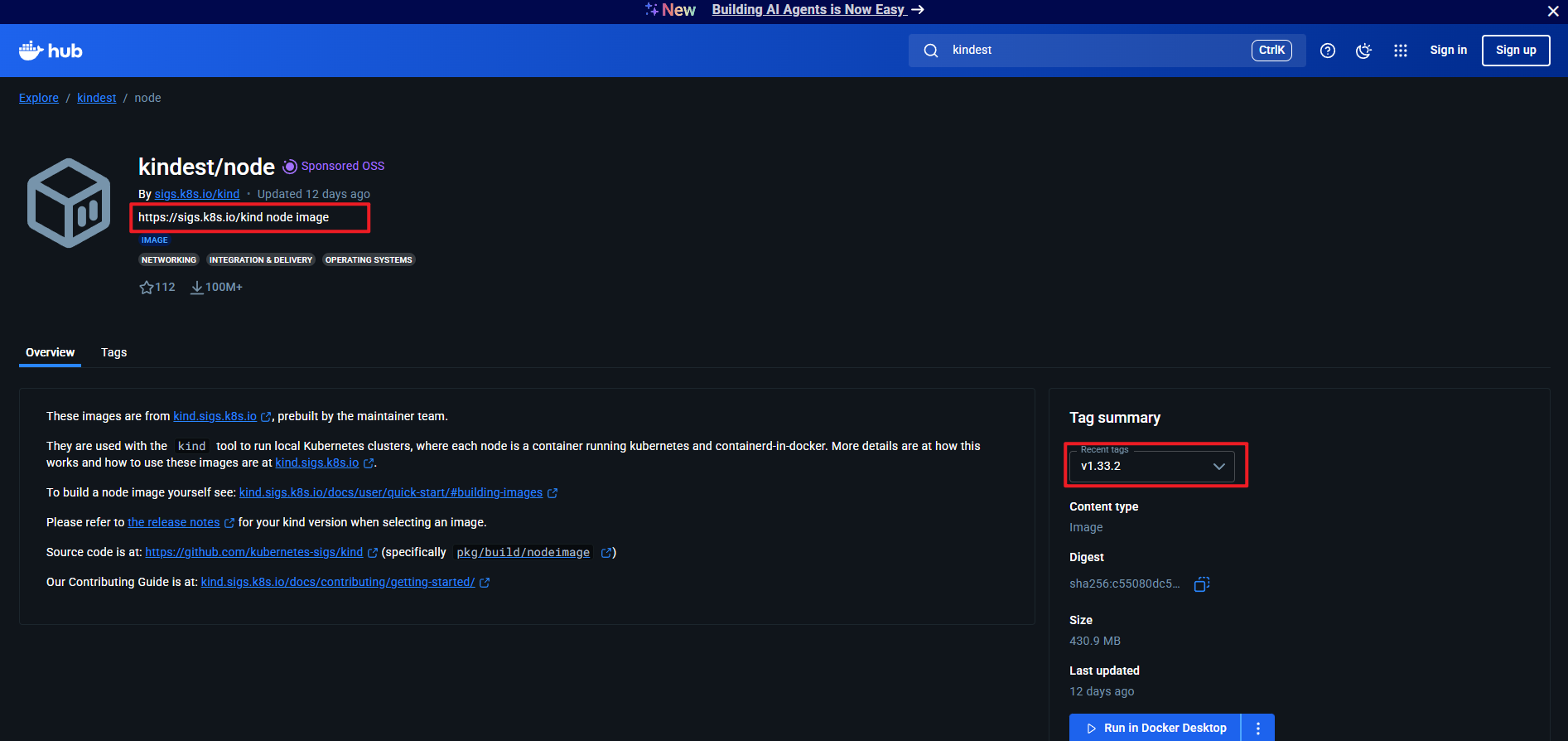
然后创建集群时指定刚才拉下来的镜像:
kind create cluster --image kindest/node:v1.30.0 --name aio -v 5
这条命令的作用是:
- 使用
kind创建一个名为aio的 Kubernetes 集群。 - 指定使用镜像
kindest/node:v1.30.0作为节点镜像,也就是说,这个集群里的 Kubernetes 版本是 1.30.0。 - 通过
-v 5参数设置日志输出详细级别为 5(详细调试信息),方便排查问题和观察执行细节。
不出意外的话,一两分钟就可以创建好。
创建好之后就可以使用 kubectl 进行操作了,kind 会把 kubeconfig 也配置好,使用起来和真正的集群基本一致。
这条命令会使用预构建的节点镜像来引导 Kubernetes 集群。预构建镜像托管在 kindest/node,但要查找适合某个版本的镜像,最好查看对应版本的发布说明(用 kind version 查看),里面会列出该版本 kind 创建的所有镜像。
如果想指定其他镜像,可以用 --image 参数,例如:kind create cluster --image=...。
使用不同的镜像,可以改变创建集群时 Kubernetes 的版本。
如果你想自己构建带自定义版本的节点镜像,请参考“构建镜像”章节。
默认情况下,集群名称为 kind。你可以用 --name 参数为集群指定不同的上下文名称。
如果想让 create cluster 命令阻塞直到控制平面准备好,可以使用 --wait 参数并指定超时时间。使用 --wait 时需要指定时间单位,例如等待 30 秒写作 --wait 30s,等待 5 分钟写作 --wait 5m。
更多用法可以通过 kind create cluster --help 查看。
kind 能自动检测已安装的 Docker、Podman 或 Nerdctl,并选择可用的容器运行时。如果想关闭自动检测,可以通过设置环境变量 KIND_EXPERIMENTAL_PROVIDER=docker、podman 或 nerdctl 来指定运行时。
创建集群后,可以通过 kubectl 使用 kind 生成的配置文件与集群交互。
默认情况下,集群访问配置保存在 ${HOME}/.kube/config,如果没有设置 $KUBECONFIG 环境变量。
如果设置了 $KUBECONFIG,它会作为路径列表(根据操作系统的路径分隔规则)进行合并。修改某个配置值时,会修改对应的文件;新建配置值时,会写入列表中第一个存在的文件;如果列表中没有存在的文件,则会创建最后一个文件。
创建集群时,可以使用 --kubeconfig 参数指定配置文件路径,这样只加载该文件,不进行合并。此参数只能设置一次。
查看已创建的所有集群,可以用 kind get clusters。
举例来说,创建两个集群:
kind create cluster # 默认集群上下文名为 `kind`
kind create cluster --name kind-2
列出所有 kind 集群时,会显示:
kind
kind-2
要与指定集群交互,只需在 kubectl 命令中使用对应的上下文名称:
kubectl cluster-info --context kind-kind
kubectl cluster-info --context kind-kind-2
如果是用 kind create cluster 创建的集群,删除同样简单:
kind delete cluster
如果不指定 --name 参数,kind 会删除默认上下文名为 kind 的集群。
注意:设计上,请求删除不存在的集群不会报错,这是为了保证操作的幂等性,方便清理资源。
Create ha cluster
默认创建的集群只有一个 master 节点,不过可以通过配置文件创建 HA 集群。
使用以下命令生成一个 kind-ha.yaml 配置文件:
配置文件内容很简单,nodes 字段里多指定几个节点就行:
cat <<EOF > kind-ha.yaml
# a cluster with 3 control-plane nodes and 3 workers
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: control-plane
- role: control-plane
- role: worker
- role: worker
- role: worker
EOF
以上配置文件指定了创建一个 3 master 3 worker 的 k8s 集群。同时,在 HA master 下, 它还额外部署了一个 Nginx,用来提供负载均衡 vip。
注意:这里的 HA 并不是真正意义上的 HA,毕竟所有 node 都跑在一个节点上的,如果底层的硬件或者 Docker
出问题那么整个集群都会挂掉。
创建时通过 --config 指定该配置文件:
kind create cluster --image kindest/node:v1.25.3 --name ha --config kind-ha.yaml
实现原理
Kind 使用一个docker 容器来模拟一个 node,在 docker 容器里面跑 systemd ,并用 systemd 托管 kubelet 以及 containerd,然后通过容器内部的 kubelet 把其他 K8s 组件,比如 kube-apiserver、etcd 等跑起来,最后在部署上 CNI 整个集群就完成了
Kind 的核心实现原理确实类似“容器中嵌套容器(容器嵌容器)”,但它并不是传统意义上的 Docker-in-Docker,而是采用了更轻量的方式来模拟 Kubernetes 节点和集群运行环境。下面给你详细讲讲:
一句话理解: Kind 利用一个 Docker 容器模拟一个 K8s 节点,容器内运行 kubeadm + systemd + kubelet + containerd,最终实现一个本地的 Kubernetes 集群。
-
每个节点 = 一个 Docker 容器
Kind 创建的每个 “节点” 实际上就是一个特殊构建的 Docker 容器(镜像为
kindest/node:xxx),这个容器内部预装了:systemd(作为 init 系统)kubeadm(用于初始化 Kubernetes)kubeletcontainerd
这些程序都运行在这个容器内部,用于模拟一个真实的 K8s 节点。
-
容器中的 kubelet 运行 Pod(嵌套)
容器里的
kubelet使用内部的containerd来创建 Pod。这些 Pod 实际上是由 宿主机的 Docker 守护进程托管的容器。也就是说:- 外面是一个容器(Kind 节点)
- 里面的 kubelet 启动的 Pod 又会创建 子容器
- 这些子容器也是在宿主机 Docker 中以兄弟容器的形式存在的
所以从结构上可以理解为:
宿主机 └── Docker 容器(Kind 节点)└── kubelet└── containerd└── Pod 容器(kube-apiserver, etcd 等)这确实是一种**“容器中的 kubelet 启动容器”**的嵌套结构,但不是用的
docker-in-docker技术,而是借助 host Docker 的机制来实现的。
📌 Kind 不是传统的 Docker-in-Docker(DinD)
- DinD 是容器中直接跑 Docker 守护进程,再通过它起其他容器,复杂且容易出问题;
- 而 Kind 利用了
containerd与宿主机共享的 Linux namespace(如 PID、network)方式来更高效地实现这一过程,避免了 DinD 的开销和网络难题。
Kind 使用的是一种轻量的“容器中嵌容器”结构(更准确地说是容器内的 kubelet 调用 containerd 启动其他容器),并借助宿主机 Docker 实现 K8s 节点和集群模拟。这是它能快速启动多节点、支持 CI 环境、保持高效隔离的核心能力之一。
然后 cni 的话 kind 使用的是自己实现的一个简单的 cni,叫做 kindnet。
注意事项
由于 Kind 是通过 Docker 容器模拟 Node 的方式来部署 Kubernetes 集群,因此在使用方式和底层实现上与物理或云上部署的集群存在一些差异,主要体现在以下几个方面:
📁 文件系统限制
-
不能直接访问宿主机文件:
Kind 中的容器节点是隔离的,无法直接读取或挂载宿主机上的任意路径。 -
不能直接使用宿主机上的镜像:
宿主机 Docker 中已有的镜像在 Kind 节点中是不可见的,需要显式导入。
🌐 网络通信限制
- 宿主机无法直接访问 Kind 集群中的服务:
Kind 集群节点运行在 Docker 网络中,与宿主机网络隔离,不能直接通过 ClusterIP、Pod IP 等访问服务。
为解决上述限制,Kind 提供了以下机制:
-
镜像导入:
可通过kind load docker-image <image>将宿主机上的镜像导入到 Kind 集群中。 -
端口映射:
在创建集群时通过配置映射宿主机端口到容器端口,使得宿主机可以访问集群中暴露的服务。 -
目录挂载:
可以在kind配置文件中指定 volumeMounts,将宿主机目录挂载到 Kind 节点容器中,实现文件共享。
其他内容请参考:https://kind.sigs.k8s.io/docs/user/quick-start/
Kind 是一个用 Docker“伪装”出来的 Kubernetes,它的设计初衷就是为了轻量、临时、易于销毁。但你在它身上要完成“生产级”的体验,那你就得接受它带来的“曲线救国”:自己导入镜像、手动转发端口、映射路径……
minikube快速搭建k8s
minikube 是本地 Kubernetes,专注于让学习和开发 Kubernetes 变得简单。
你只需要一个 Docker(或类似兼容的)容器环境,或者一个虚拟机环境,Kubernetes 就只需一个命令即可启动:
minikube start
你需要准备的环境:
-
至少 2 个 CPU
-
2GB 以上的可用内存
-
20GB 以上的可用磁盘空间
-
可访问互联网
-
一个容器或虚拟机管理器,例如:
- Docker
- QEMU
- Hyperkit
- Hyper-V
- KVM
- Parallels
- Podman
- VirtualBox
- VMware Fusion / Workstation
快速开始
创建单例节点
minikube也是一个二进制的文件,可以直接下载安装:
curl -LO https://github.com/kubernetes/minikube/releases/latest/download/minikube-linux-amd64
sudo install minikube-linux-amd64 /usr/local/bin/minikube && rm minikube-linux-amd64
或者下载指定版本的minikube:
sudo curl -LO https://storage.googleapis.com/minikube/releases/v1.XX.X/minikube-linux-amd64 && sudo install minikube-linux-amd64 /usr/local/bin/minikube
从具有管理员权限的终端中运行以下命令(无需以 root 用户登录):
minikube start
如果需要换源:
minikube start --force --image-mirror-country='cn' --kubernetes-version=v1.XX.X
如果 minikube 启动失败,请参阅 drivers 页面 获取如何配置兼容的容器或虚拟机管理器的帮助。
如果你已经安装了 kubectl(参见官方文档),现在可以使用它来访问你刚创建的集群:
kubectl get po -A
或者,minikube 也可以自动下载合适版本的 kubectl,你可以通过以下命令使用它:
minikube kubectl -- get po -A
为了简化使用体验,你还可以在 shell 配置文件中添加以下 alias:
alias kubectl="minikube kubectl --"
⚠️ 注意:在集群启动初期,某些服务(例如 storage-provisioner)可能还未处于 Running 状态。这是正常现象,通常几分钟后会自动恢复。
为了更方便地查看集群状态,minikube 自带了 Kubernetes Dashboard,你可以通过以下命令启动它,快速熟悉环境:
minikube dashboard --url
该URL只能在宿主机内部访问。如果需要在宿主机之外访问,需要设置kubectl proxy代理或其他方式。
minikube kubectl -- proxy --address='0.0.0.0' --accept-hosts='^*$'&
然后修改ECS防火墙规则,允许入方向的8001端口通行。在宿主机之外的浏览器中访问:
http://ECS公网IP:8001/api/v1/namespaces/kubernetes-dashboard/services/http:kubernetes-dashboard:/proxy/。
其他操作诸如销毁集群:
# 查看集群的所有资源
kubectl get all#查看minikube的版本
minikube version# 进入节点服务器
minikube ssh# 执行节点服务器命令,例如查看节点 docker info
minikube ssh -- docker info# 删除集群, 删除 ~/.minikube 目录缓存的文件
minikube delete# 关闭集群
minikube stop## 销毁集群
minikube stop && minikube delete#显示虚拟机地址
minikube ip#显示minikube的log
minikube logs#启动minikube dashboard
minikube dashboard
创建集群
minikube 默认只启动 单节点 Kubernetes 集群,但它确实支持通过 “多节点”模式 启动包含多个节点(1个 control-plane + 多个 worker)的集群。你可以使用 --nodes 参数指定节点数量,例如:
minikube start --nodes 3 -p multinode
这个命令的意思是:
- 启动一个名为
multinode的 minikube 集群; - 集群中包含 3 个节点(默认是 1 个 control-plane 和 2 个 worker);
- 节点实际上会分别创建为多个容器(Docker 驱动)或虚拟机(VM 驱动)。
创建完成后,节点名称类似于:
multinode
multinode-m02
multinode-m03
第一个是主节点(control-plane),其余是 worker 节点。
可以通过以下命令查看节点:
kubectl get nodes
🚫 限制提示
- 多节点功能仅在 某些驱动(如 Docker、KVM2、VirtualBox)下可用;
- 某些驱动不支持多节点(如 Hyper-V、VMware Fusion);
- 如果你发现启动失败,请检查你使用的驱动是否支持多节点;
- 需要较多资源(如至少 4 CPU、4GB+ 内存)以保障多个节点运行。
其余参考:https://minikube.sigs.k8s.io/docs/tutorials/multi_node/
实现原理
Minikube 本质上是一个本地 Kubernetes 集群管理工具,它使用 容器 或 虚拟机(根据驱动)创建并管理一个本地的 K8s 单节点或多节点集群。
架构核心:
+---------------------+| Your Host OS |+---------+-----------+|+-------+--------+| Container/VM | ← 通过 Driver 启动(Docker/Podman/KVM 等)+-------+--------+|+----------+-------------+| Minikube node | ← 本质是一个全功能 K8s 节点| (runs systemd/kubelet) |+----------+-------------+|+----------+-------------+| Kubernetes Control || (API Server, Scheduler) |+-------------------------+
核心机制:
-
Minikube 启动后会:
- 创建一个或多个 node 实例(Docker 容器或虚拟机);
- 在其中安装并启动 containerd、kubelet;
- 用 kubeadm 初始化集群;
- 默认开启一些插件(如 dashboard、metrics-server);
- 配置 kubectl 访问该集群;
-
用户通过
kubectl或minikube kubectl与其交互; -
通过端口转发、镜像导入、文件挂载等机制与宿主机交互。
注意事项
🚧 1. 驱动选择至关重要
- Docker(默认,推荐):快速,适合大多数机器;
- Podman:类似 Docker,但有兼容问题;
- VirtualBox、KVM、Hyperkit、Hyper-V:适合没有 Docker 环境的系统;
- 建议使用
minikube config set driver docker显式指定驱动。
🚧 2. 资源限制配置
默认只给 2 CPU / 2GB RAM,有些组件跑不动,建议启动时设置:
minikube start --cpus 4 --memory 8192
🚧 3. 镜像管理
Minikube 自建了 container runtime,有 自己独立的镜像存储:
- 本地宿主机的镜像在 minikube 中不可见;
- 使用
minikube image load导入宿主机镜像; - 使用
minikube cache add离线缓存镜像; - 查看当前镜像仓库:
minikube ssh -- docker images
🚧 4. 网络访问问题
由于是 VM/容器嵌套,服务网络访问有一些特殊性:
-
不能直接通过
localhost访问 Pod 服务; -
建议使用:
minikube service <svc>打开浏览器自动访问;minikube tunnel创建宿主机与集群的路由通道;kubectl port-forward显式暴露服务端口;
🚧 5. 启动失败排查
- 查看日志:
minikube logs - 诊断环境:
minikube doctor - 查看状态:
minikube status - 启动失败多半是驱动问题或网络超时
✅ 额外建议
- 使用
minikube addons list激活额外功能(如 Ingress、Metrics、Dashboard); - 多节点启动:
minikube start --nodes 3 -p mycluster; - 创建不同版本的集群:
minikube start --kubernetes-version=v1.29.4;
Minikube 虽然是为了开发体验优化的本地 Kubernetes 集群,但在镜像和网络上仍然和生产环境有所区别,有几个容易踩坑的关键点:
Minikube 的集群运行在 虚拟机或容器内的环境 中,它的容器运行时(如 Docker、containerd)和你宿主机的环境是 隔离的:
- 你在宿主机
docker build的镜像,在 Minikube 里不可见。 kubectl apply的镜像如果在 Minikube 内没有,会尝试从公网拉取,而默认是拉不到你本地 build 的镜像的。
✅ 解决方法:
-
推荐:
minikube image load把你宿主机的镜像导入到 Minikube 中:
docker build -t myapp:latest . minikube image load myapp:latest -
也可以使用
minikube cache add预加载:minikube cache add nginx:latest -
或者你把 Pod 指向远程私有仓库,但就没法断网开发了。
Minikube 的网络访问问题:Minikube 的服务运行在“虚拟机/容器”的网络中,并不总是和你的宿主机共网。
kubectl port-forward虽然能访问单个 Pod,但不是长久方案;- 你创建了一个
NodePort服务,却无法在浏览器localhost:<port>打开; - 宿主机和 Minikube 集群“看似一台机器”,其实网络隔离。
✅ 正确访问方式:
-
推荐:
minikube service <svc> --url或--web它会解析
NodePort服务的真实地址:minikube service my-nginx --url -
使用:
minikube tunnel启动一个类似 VPN 的通道,让你访问 LoadBalancer 服务:
sudo minikube tunnel然后访问服务的 Cluster IP 即可。
-
也可以用端口转发:
kubectl port-forward svc/my-nginx 8080:80
Minikube 虽然非常方便,但它不是宿主机原生环境,你看到的是一个“虚拟”Kubernetes 环境,镜像和网络都需要**“桥接”手动处理**。
Minikube 和 Kind 本质上都属于“在本地虚拟/容器环境中运行 Kubernetes”,所以它们面临的问题高度相似。
Kind vs Minikube 核心对比表:
| 特性 | Kind | Minikube |
|---|---|---|
| 底层运行环境 | Docker 容器 | Docker 或 虚拟机(VirtualBox、Hyperkit、KVM 等) |
| K8s 安装方式 | 使用 kubeadm 安装,模拟每个节点 | 自己控制集群生命周期,也可以选择容器或 VM |
| 多节点支持 | 原生支持多节点(用多个容器模拟) | 需要指定 --nodes 或 --nodes <num>(但功能较基础) |
| 网络访问 | 容器网络,与宿主机隔离,需端口映射或 kubectl port-forward | 网络隔离,需 minikube service 或 minikube tunnel |
| 镜像管理 | 宿主机镜像不可直接用,需要 kind load docker-image | 同样需要 minikube image load 或 cache add |
| 资源占用 | 相对轻量,适合 CI/CD 流程 | 相对重,功能更全面,适合开发调试 |
| GUI 支持 | 无 Dashboard 自带支持,需要自己安装 | 自带 Web UI Dashboard,一键开启 |
| 用途场景 | 测试、CI、快速本地集群模拟 | 本地开发、K8s 学习与实验 |
| 运行稳定性 | 完全容器化,易于控制 | 容器 or 虚拟机,因驱动可能更复杂 |
| 支持 Kubernetes 版本 | 通过镜像选择,需预构建的版本 | 自动下载,支持很多版本 |
kubeadm快速搭建k8s
快速开始
以 Kubernetes 1.33 为例,如果你想使用其他 Kubernetes 版本,请参考以下页面:
- 安装 kubeadm (Kubernetes v1.32)
- 安装 kubeadm (Kubernetes v1.31)
- 安装 kubeadm (Kubernetes v1.30)
- 安装 kubeadm (Kubernetes v1.29)
设备要求:
-
一台兼容的 Linux 主机。Kubernetes 项目为基于 Debian 和 Red Hat 的 Linux 发行版以及一些不提供包管理器的发行版提供通用的指令。
-
每台机器 2 GB 或更多的 RAM(如果少于这个数字将会影响你应用的运行内存)。
-
控制平面机器需要 CPU 2 核心或更多。
-
集群中的所有机器的网络彼此均能相互连接(公网和内网都可以)。
-
节点之中不可以有重复的主机名、MAC 地址或 product_uuid。
-
开启机器上的某些端口。
-
交换分区的配置:
- kubelet 的默认行为是在节点上检测到交换内存时无法启动。
- 如果 kubelet 未被正确配置使用交换分区,则你必须禁用交换分区。例如,
sudo swapoff -a将暂时禁用交换分区。要使此更改在重启后保持不变,请确保在如/etc/fstab、systemd.swap等配置文件中禁用交换分区,具体取决于你的系统如何配置。
kubeadm 的安装是通过使用动态链接的二进制文件完成的,安装时假设你的目标系统提供 glibc。这个假设在许多 Linux 发行版(包括 Debian、Ubuntu、Fedora、CentOS 等)上是合理的,但对于不包含默认 glibc 的自定义和轻量级发行版(如 Alpine Linux),情况并非总是如此。预期的情况是,发行版要么包含 glibc,要么提供了一个兼容层以提供所需的符号。
你需要在每台机器上安装以下的软件包:
-
kubeadm:用来初始化集群的指令。
-
kubelet:在集群中的每个节点上用来启动 Pod 和容器等。
-
kubectl:用来与集群通信的命令行工具。
kubeadm 不能帮你安装或者管理 kubelet 或 kubectl, 所以你需要确保它们与通过 kubeadm 安装的控制平面的版本相匹配。 如果不这样做,则存在发生版本偏差的风险,可能会导致一些预料之外的错误和问题。 然而,控制平面与 kubelet 之间可以存在一个次要版本的偏差,但 kubelet 的版本不可以超过 API 服务器的版本。 例如,1.7.0 版本的 kubelet 可以完全兼容 1.8.0 版本的 API 服务器,反之则不可以。
强烈建议使用托管在 pkgs.k8s.io 上的新软件包仓库来安装 2023 年 9 月 13 日之后发布的 Kubernetes 版本。 旧版软件包仓库已被弃用,其内容可能在未来的任何时间被删除,恕不另行通知。新的软件包仓库提供了从 Kubernetes v1.24.0 版本开始的下载。
搭建基础集群
将 SELinux 设置为 permissive 模式(以下指令适用于 Kubernetes 1.33)
# 将 SELinux 设置为 permissive 模式(相当于将其禁用)
sudo setenforce 0
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
注意:
通过运行
setenforce 0和sed ...将 SELinux 设置为 permissive 模式相当于将其禁用。
这是允许容器访问主机文件系统所必需的,例如,某些容器网络插件需要这一能力。
你必须这么做,直到 kubelet 改进其对 SELinux 的支持。
如果你知道如何配置 SELinux,则可以将其保持启用状态,但可能需要设定部分 kubeadm 不支持的配置。
添加 Kubernetes 的 yum 仓库
在仓库定义中的
exclude参数确保了与 Kubernetes 相关的软件包在运行yum update时不会升级。
升级 Kubernetes 需要遵循特定的过程。
此仓库仅包含适用于 Kubernetes 1.33 的软件包;若需其他版本,需更改 URL 中的版本号,并确认所用文档版本匹配。
# 此操作会覆盖 /etc/yum.repos.d/kubernetes.repo 中现存的所有配置
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.33/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.33/rpm/repodata/repomd.xml.key
exclude=kubelet kubeadm kubectl cri-tools kubernetes-cni
EOF
安装组件并启用 kubelet
sudo yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
sudo systemctl enable --now kubelet
kubelet 现在每隔几秒就会重启,因为它陷入了一个等待 kubeadm 指令的死循环。
初始化控制平面节点
控制平面节点是运行控制平面组件的机器,包括:
etcd(集群数据库)API Server(命令行工具kubectl与之通信)
建议设置共享控制平面端点
- 如果计划将 单个控制平面 kubeadm 集群升级为高可用,推荐添加以下参数:
--control-plane-endpoint
- 用于为所有控制平面节点设置共享端点。该端点可以是负载均衡器的 DNS 名称或 IP 地址。
配置 Pod 网络插件
- 选择一个 Pod 网络插件,并验证是否需要为
kubeadm init传递参数。 - 根据所选的第三方网络插件,可能需要设置以下参数:
--pod-network-cidr=<CIDR>
- 参阅文档:安装 Pod 网络附加组件
配置容器运行时(可选)
-
kubeadm默认通过已知端点列表检测容器运行时。 -
如果使用 不同容器运行时 或 节点预安装了多个容器运行时,建议指定:
--cri-socket=<路径> -
参阅文档:安装运行时
初始化控制平面节点:
kubeadm init <args>
安装 Pod 网络附加组件
你必须部署一个基于 Pod 网络插件的 容器网络接口(CNI),以便 Pod 之间可以互相通信。
在安装网络插件之前,集群 DNS(CoreDNS)不会启动。
注意事项
-
Pod 网络不能与主机网络重叠:
-
如果存在重叠,将可能导致网络问题。
-
如发现网络插件默认的 Pod 网络与主机网络冲突:
- 修改插件 YAML 文件中 CIDR;
- 使用
--pod-network-cidr=<CIDR>参数运行kubeadm init。
-
-
RBAC 支持:
- 默认情况下,
kubeadm会启用 RBAC(基于角色的访问控制); - 请确保你选择的 网络插件支持 RBAC,且安装 YAML 也配置了相关权限。
- 默认情况下,
-
IPv6 支持:
- 如需启用 IPv6(单栈或双栈),确保网络插件支持;
- IPv6 支持从 CNI v0.6.0 开始添加。
CNI 插件说明
kubeadm本身与 CNI 无关;- CNI 驱动不在 Kubernetes 官方端到端测试范围内;
- 如果发现插件相关问题,应在该插件的 Issue Tracker 中报告,不是
kubeadm或 Kubernetes 项目。
推荐操作
- 查阅 Kubernetes 支持的网络插件清单:安装插件页面
- 查看实现 Kubernetes 网络模型的插件:Kubernetes 网络模型实现列表
安装命令示例
在控制平面节点或有 kubeconfig 凭据的节点上执行:
kubectl apply -f <add-on.yaml>
说明:
- 每个 Kubernetes 集群只能安装 一个 Pod 网络插件;
- 仅部分插件支持 Windows,详见:添加 Windows 工作节点
验证网络插件是否生效
安装网络后,执行以下命令检查 CoreDNS 状态:
kubectl get pods --all-namespaces
确认 CoreDNS Pod 状态为 Running。一旦正常运行,即可继续加入其他节点。
故障排查
如果:
- Pod 网络不通;
- CoreDNS 不是
Running状态;
请参阅 kubeadm 故障排查指南。
添加工作节点
-
通过 SSH 或其他方式连接到目标机器。
-
运行
kubeadm init输出的kubeadm join命令,例如:
sudo kubeadm join --token <token> <control-plane-host>:<control-plane-port> --discovery-token-ca-cert-hash sha256:<hash>
kubeadm join 额外信息
-
IPv6 地址注意事项:
若指定
<control-plane-host>:<control-plane-port>为 IPv6,IPv6 地址必须用方括号括起来,例如:[2001:db8::101]:2073
获取令牌(Token)
- 如果没有令牌,可以在控制平面节点上运行:
sudo kubeadm token list
- 输出示例:
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
8ewj1p.9r9hcjoqgajrj4gi 23h 2018-06-12T02:51:28Z authentication, The default bootstrap system:signing token generated by bootstrappers:'kubeadm init'. kubeadm:default-node-token
- 默认节点加入令牌在 24 小时后过期。若令牌过期,可在控制平面节点创建新令牌:
sudo kubeadm token create
- 输出示例:
5didvk.d09sbcov8ph2amjw
获取 --discovery-token-ca-cert-hash
- 如无具体值,可在控制平面节点运行:
sudo cat /etc/kubernetes/pki/ca.crt | openssl x509 -pubkey | openssl rsa -pubin -outform der 2>/dev/null | \
openssl dgst -sha256 -hex | sed 's/^.* //'
- 输出示例:
8cb2de97839780a412b93877f8507ad6c94f73add17d5d7058e91741c9d5ec78
kubeadm join 命令示例输出
[preflight] Running pre-flight checks... (join workflow 日志输出) ...Node join complete:
* Certificate signing request sent to control-plane and responsereceived.
* Kubelet informed of new secure connection details.Run 'kubectl get nodes' on control-plane to see this machine join.
几秒钟后,运行以下命令应能看到新节点加入:
kubectl get nodes
说明
- 集群节点通常按顺序初始化,CoreDNS Pods 可能全部运行在第一个控制平面节点上。
- 为保证高可用,至少有一个新节点加入后,运行:
kubectl -n kube-system rollout restart deployment coredns
重新平衡 CoreDNS Pods。
创建高可用集群
参考:https://kubernetes.io/zh-cn/docs/setup/production-environment/tools/kubeadm/high-availability/
实现原理
- 基于系统服务的集群搭建工具
kubeadm 通过在每台物理机或虚拟机上安装和配置 Kubernetes 关键组件(如 kubelet、kube-apiserver、etcd、kube-proxy 等)来搭建集群。 - 组件启动依赖 systemd
kubelet 作为系统服务启动,负责节点管理和调度。 - 证书与密钥管理
kubeadm 自动生成集群所需的 TLS 证书,保证节点间安全通信。 - 集群初始化和节点加入
使用kubeadm init初始化控制平面节点,kubeadm join将工作节点加入集群。 - 集成容器运行时管理
依赖 containerd 或 Docker 作为容器运行时来管理 Pod 容器。 - 网络插件自定义
不包含默认网络方案,需用户根据需求安装和配置 CNI 网络插件(如 Calico、Flannel 等)。
注意事项
- 环境准备要求高
需要准备兼容的 Linux 主机,合理的 CPU、内存,关闭交换分区,网络互通等。 - 容器运行时配置
需先安装配置 containerd 或 Docker,且与 kubelet 配合使用。 - 证书和安全配置
需要正确管理证书和 token,保证节点安全加入集群。 - 网络插件必须手动安装
需要额外配置 Pod 网络插件,否则 Pod 之间无法通信,CoreDNS 无法启动。 - 多节点和高可用配置复杂
多控制平面和高可用需配置共享负载均衡器和端点,配置较复杂。 - 系统调优
包括关闭交换分区、调整内核参数、开启必要端口等,保证 Kubernetes 组件正常运行。 - 故障排查门槛较高
由于细节较多,出现问题时排查和定位相对复杂。
总的来说,kubeadm 是一个“半自动化”的工具,兼顾了安装自动化和环境灵活性,适合用于真实生产环境的集群搭建,但需要较强的系统和 Kubernetes 基础知识。
裸金属部署k8s
裸金属上真实部署 Kubernetes,就是所谓的“The Hard Way”(完全手动部署),需要:
- 下载所有 Kubernetes 组件的二进制文件(如 kube-apiserver、kube-controller-manager、kube-scheduler、kubelet、kubectl、etcd 等)
- 手动配置各组件的配置文件(如证书、kubeconfig、启动参数等)
- 使用 systemd 或其他方式逐个启动这些服务
- 自己配置网络插件(CNI)、存储、负载均衡等
主要步骤大致如下:
-
准备机器环境
- 确保硬件满足资源需求,网络互通
- 关闭交换分区,调优内核参数
- 安装基础依赖(containerd 或 Docker,openssl,ipvs等)
-
下载 Kubernetes 和 etcd 二进制包
- 从官方 release 页面下载对应版本二进制
- 放置到指定路径,并设置执行权限
-
生成证书和 kubeconfig 文件
- 使用 openssl 或 cfssl 手动生成 CA、服务器、客户端证书
- 生成各组件的 kubeconfig 文件,实现安全通信
-
配置和启动 etcd 集群
- 配置 etcd 集群成员和启动参数
- 以 systemd 服务启动 etcd
-
配置和启动控制平面组件
- kube-apiserver
- kube-controller-manager
- kube-scheduler
配置对应的 systemd 服务文件,并启动
-
安装和配置 kubelet 与 kube-proxy
- 配置 kubelet 配置文件和启动参数
- 启动 kubelet
- 配置 kube-proxy 并启动
-
部署网络插件(CNI)
- 手动下载和部署网络插件 YAML(Calico、Flannel 等)
- 确保 Pod 网络正常
-
验证集群状态
- 使用 kubectl 检查节点和 Pod 状态
- 验证各组件运行正常
参考资源:
-
官方“The Hard Way”教程(英文,Google Cloud 出品):
https://github.com/kelseyhightower/kubernetes-the-hard-way
这是一套非常详细且权威的“从零开始手动搭建 Kubernetes”的教学方案。 -
裸金属真实部署 Kubernetes 是一个非常复杂且细节丰富的过程,适合深入学习和生产环境极度定制需求。
-
需要对 Linux 系统、网络、安全证书管理有较高掌握度。
-
如果只想快速搭建生产环境,推荐用 kubeadm 等工具;如果想理解底层细节,The Hard Way 是最佳选择。
一些误区:
-
裸金属部署 Kubernetes 性能
- 理论上裸金属部署(直接运行二进制)能带来最高性能,因为没有额外容器运行时的开销,所有组件直接作为系统进程运行。
- 但实际差异通常非常小,尤其现代容器运行时(containerd、CRI-O)开销已极低。
-
kubeadm 是怎么部署的?
- kubeadm 本质上是自动化安装和配置工具,它会帮你部署 Kubernetes 组件,但组件不一定都“跑在容器里”。
- 事实上,kubeadm 默认部署 kubelet 为宿主机的 systemd 服务,kubelet 再启动管理 Pod。
- 重要的控制平面组件(kube-apiserver、controller-manager、scheduler)默认也是作为静态 Pod 运行在节点上的,这些 Pod 是由 kubelet 管理的,底层容器运行时(containerd 或 Docker)负责运行这些容器。
-
为什么 kubeadm 没有 minikube 和 kind 的问题?
- minikube 和 kind 是为了快速开发、测试而设计的,它们是在单台机器上用容器(Docker 或 VM)模拟多个节点,属于“模拟环境”,所以涉及“容器中嵌套容器”、网络隔离、镜像导入、端口映射等复杂问题。
- 这些“问题”是因为它们试图在一台机器上“虚拟”多节点,做了很多特殊处理。
- 而 kubeadm 是面向真实多台机器的生产环境,不需要做容器嵌套,也不存在端口映射这些问题。各个节点是物理机或虚拟机,网络互通,组件直接运行在宿主机(或其容器运行时)中,环境更纯粹自然。
总结:
| 工具 | 组件运行方式 | 适用场景 | 主要问题 |
|---|---|---|---|
| 裸金属部署 | 二进制作为系统进程直接运行 | 最高性能,极端定制 | 配置复杂,维护难度高 |
| kubeadm | 控制平面组件作为静态 Pod 运行,kubelet systemd管理 | 企业级生产环境 | 稳定,无容器嵌套问题 |
| kind/minikube | 在单机 Docker 或 VM 容器中模拟节点 | 本地开发测试 | 容器嵌套,端口映射,镜像导入复杂 |
所以,kubeadm 本身并不“把所有组件跑在容器里”,而是用 kubelet 管理控制平面静态 Pod,运行在真实机器或 VM 上,避免了 kind/minikube 那些容器嵌套带来的复杂问题。
Sealos快速搭建k8s

使用Sealos快速部署Kubernetes集群,支持在线和离线安装,适用于amd64和arm64架构。轻松管理节点,安装分布式应用,支持Containerd和Docker运行时。
官方文档:https://sealos.run/docs/k8s/quick-start/deploy-kubernetes
Sealos 所有的集群镜像都可以在 cluster-image-docs 仓库里找到。除了推送到 Docker Hub 之外,这些镜像还被同步到了阿里云的镜像仓库。
Docker Hub 上可以通过以下链接查看 Sealos 所有的集群镜像:https://hub.docker.com/u/labring。
使用 Registry Explorer 可以查看 K8s 集群镜像的所有版本,直接输入 registry.cn-shanghai.aliyuncs.com/labring/kubernetes,然后点击“Submit Query”:
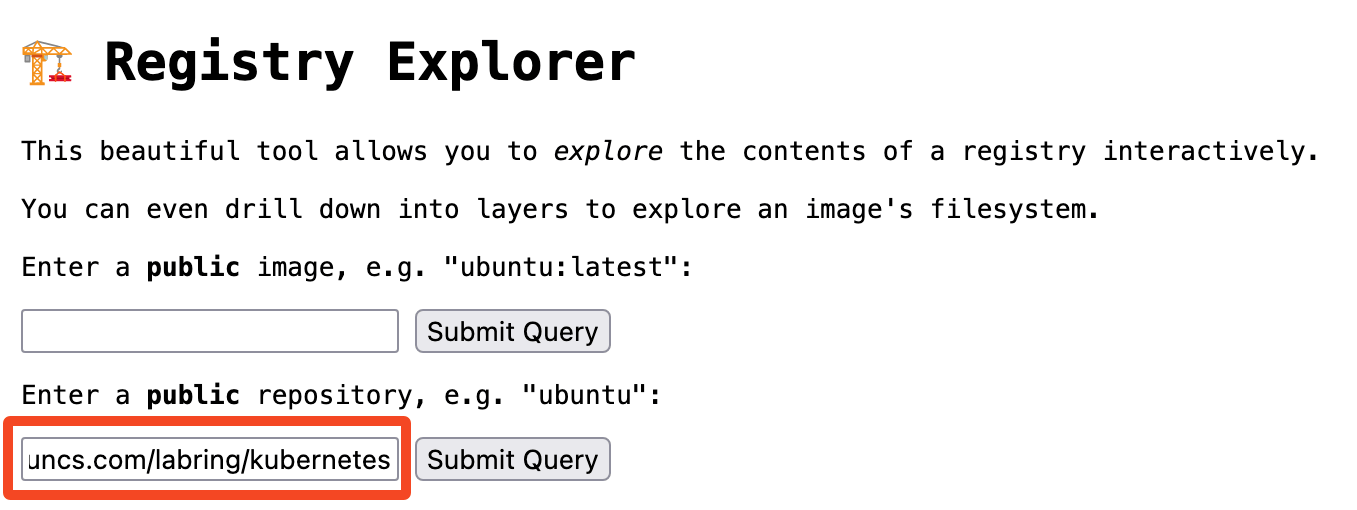
就会看到这个集群镜像的所有 tag。
Docker Hub 同理,输入 docker.io/labring/kubernetes 即可查看所有 tag。
快速开始
安装 K8s 单机版
$ sealos run registry.cn-shanghai.aliyuncs.com/labring/kubernetes:v1.29.9 registry.cn-shanghai.aliyuncs.com/labring/helm:v3.9.4 registry.cn-shanghai.aliyuncs.com/labring/cilium:v1.13.4 --single
安装 K8s 集群
$ sealos run registry.cn-shanghai.aliyuncs.com/labring/kubernetes:v1.29.9 registry.cn-shanghai.aliyuncs.com/labring/helm:v3.9.4 registry.cn-shanghai.aliyuncs.com/labring/cilium:v1.13.4 \--masters 192.168.64.2,192.168.64.22,192.168.64.20 \--nodes 192.168.64.21,192.168.64.19 -p [your-ssh-passwd]
注意:
labring/helm应当在labring/cilium之前。
参数说明:
| 参数名 | 参数值示例 | 参数说明 |
|---|---|---|
| –masters | 192.168.0.2 | K8s master 节点地址列表 |
| –nodes | 192.168.0.3 | K8s node 节点地址列表 |
| –ssh-passwd | [your-ssh-passwd] | SSH 登录密码 |
| kubernetes | labring/kubernetes:v1.25.0 | K8s 集群镜像 |
在干净的服务器上直接执行上面命令,不要做任何多余操作,即可安装一个高可用 K8s 集群。
安装各种分布式应用
sealos run registry.cn-shanghai.aliyuncs.com/labring/helm:v3.9.4 # install helm
sealos run registry.cn-shanghai.aliyuncs.com/labring/openebs:v3.9.0 # install openebs
sealos run registry.cn-shanghai.aliyuncs.com/labring/minio-operator:v4.5.5 registry.cn-shanghai.aliyuncs.com/labring/ingress-nginx:4.1.0
这样高可用的 Minio 等应用都有了,不用关心所有的依赖问题。
增加 node 节点:
$ sealos add --nodes 192.168.64.21,192.168.64.19
增加 master 节点:
$ sealos add --masters 192.168.64.21,192.168.64.19
删除 node 节点:
$ sealos delete --nodes 192.168.64.21,192.168.64.19
删除 master 节点:
$ sealos delete --masters 192.168.64.21,192.168.64.19
清理 K8s 集群
$ sealos reset
实现原理
Sealos 是一个基于 Kubernetes 的轻量级云操作系统,旨在简化 Kubernetes 集群的部署和管理。它通过封装 Kubernetes 的复杂性,使开发者能够像操作本地应用一样,轻松地在各种环境中部署和管理云应用。
Sealos 的核心功能是通过 sealos run 命令实现 Kubernetes 集群的快速部署。其工作流程包括以下九个主要步骤:
-
执行命令:用户通过执行
sealos run命令启动部署过程。 -
执行 Pipeline:Sealos 开始执行一系列操作,包括节点检查、镜像拉取、配置渲染和镜像分发等。
-
执行 InitMaster0:在第一个 Master 节点上执行
kubeadm init,初始化控制平面。 -
执行 JoinMaster:将其他 Master 节点加入集群。
-
执行 JoinNode:将 Worker 节点加入集群。
-
同步 IPVS:同步负载均衡规则。
-
执行 Guest 阶段:执行集群镜像命令。
-
写入 Clusterfile:记录集群配置信息。
-
完成部署:部署完成后,用户可以通过 Sealos 提供的界面进行管理和操作。
⚠️ 注意事项
在使用 Sealos 部署 Kubernetes 时,需要注意以下几点:
-
操作系统要求:建议使用 Ubuntu 22.04 LTS 或其他支持的 Linux 发行版,确保系统内核版本在 5.4 及以上。
-
网络配置:所有节点之间需要网络互通,且时间同步。
-
域名和证书:需要配置域名和 SSL/TLS 证书,确保通信安全。
-
资源要求:Master 节点建议配置 8 核 CPU、16GB 内存和 100GB 存储;Node 节点建议配置 1 核 CPU、1GB 内存和 20GB 存储。
-
集群规模:Sealos 支持大规模集群部署,但在部署前需要进行充分的资源评估和规划。
Sealos 通过简化 Kubernetes 集群的部署过程,使开发者能够更专注于应用的开发和管理。它适用于希望快速搭建 Kubernetes 环境的开发者和团队,特别是在资源有限或对 Kubernetes 不熟悉的情况下。通过 Sealos,用户可以轻松实现 Kubernetes 集群的部署、管理和扩展。