MySQL--高可用MHA集群详解及演练
6.MySQL高可用之MHA
6.1.MHA概述
为什么要用MHA?
Master的单点故障问题
什么是 MHA?
- MHA(Master High Availability)是一套优秀的MySQL高可用环境下故障切换和主从复制的软件。
- MHA 的出现就是解决MySQL 单点的问题。
- MySQL故障切换过程中,MHA能做到0-30秒内自动完成故障切换操作。
- MHA能在故障切换的过程中最大程度上保证数据的一致性,以达到真正意义上的高可用。
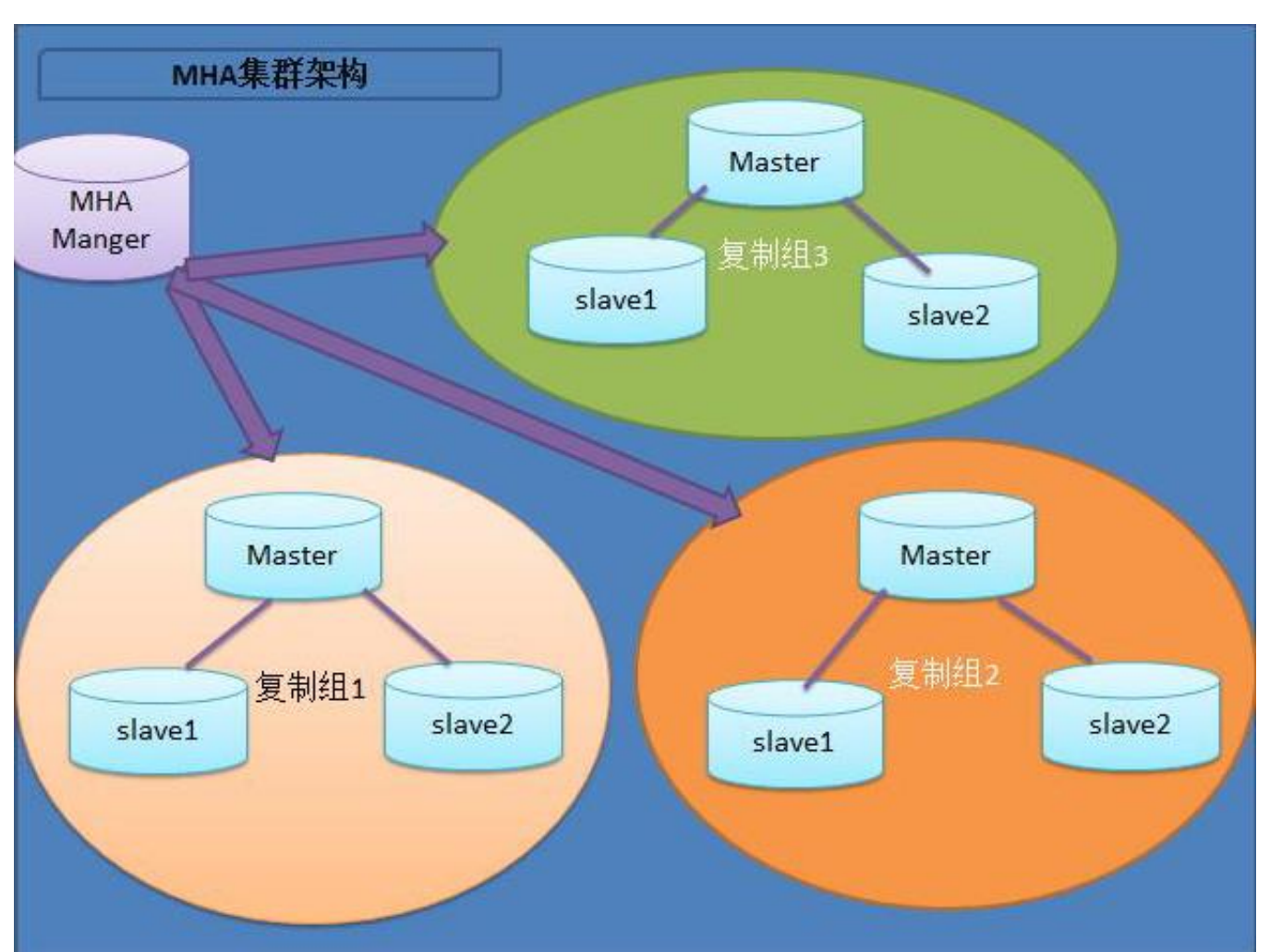
6.1.1 MHA 的组成
-
MHA由两部分组成:MHAManager (管理节点) MHA Node (数据库节点),
-
MHA Manager 可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台 slave 节点上。
-
MHA Manager 会定时探测集群中的 master 节点。
-
当 master 出现故障时,它可以自动将最新数据的 slave 提升为新的 master, 然后将所有其他的 slave 重新指向新的 master。
6.1.2 MHA的特点
- 自动故障切换过程中,MHA从宕机的主服务器上保存二进制日志,最大程度的保证数据不丢失
- 使用半同步复制,可以大大降低数据丢失的风险,如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性
- 目前MHA支持一主多从架构,最少三台服务,即一主两从
6.1.3 故障切换备选主库的算法
1.一般判断从库的是从(position/GTID)判断优劣,数据有差异,最接近于master的slave,成为备选主。
2.数据一致的情况下,按照配置文件顺序,选择备选主库。
3.设定有权重(candidate_master=1),按照权重强制指定备选主。
(1)默认情况下如果一个slave落后master 100M的relay logs的话,即使有权重,也会失效。
(2)如果check_repl_delay=0的话,即使落后很多日志,也强制选择其为备选主。
6.1.4 MHA工作原理
-
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群必须最少有3台数据库服务器,一主二从,即一台充当Master,台充当备用Master,另一台充当从库。
-
MHA Node 运行在每台 MySQL 服务器上
-
MHAManager 会定时探测集群中的master 节点
-
当master 出现故障时,它可以自动将最新数据的slave 提升为新的master
-
然后将所有其他的slave 重新指向新的master,VIP自动漂移到新的master。
-
整个故障转移过程对应用程序完全透明。
6.2 MHA部署实施
6.2.1 搭建主两从架构
#在master节点中
[root@mysqla ~]# /etc/init.d/mysqld stop
[root@mysqla ~]# rm -fr /data/mysql/*
[root@mysqla ~]# vim /etc/my.cnf
[mysqld]
server-id=10
datadir=/data/mysql
socket=/data/mysql/mysql.sock
default_authentication_plugin=mysql_native_password
log-bin=mysql-bin
gtid_mode=ON
enforce-gtid-consistency=ON
skip-name-resolve
binlog_format=ROW33[root@mysqla ~]# mysqld --user mysql --initialize
[root@mysqla ~]# /etc/init.d/mysqld start
[root@mysqla ~]# mysql_secure_installation
[root@mysqla~]# mysql -p123456mysql> CREATE USER IF NOT EXISTS 'dhj'@'%' IDENTIFIED BY '123456';mysql> GRANT REPLICATION SLAVE ON *.* TO dhj@'%';mysql> INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';mysql> SET GLOBAL rpl_semi_sync_master_enabled = 1;mysql> SET GLOBAL sql_slave_skip_counter = 1;
[root@mysqlb & c ~]# /etc/init.d/mysqld stop
[root@mysqlb & c ~]# rm -fr /data/mysql/*# 在slave1中
[root@mysqlb ~]# vim /etc/my.cnf
[mysqld]
server-id=20
datadir=/data/mysql
socket=/data/mysql/mysql.sock
default_authentication_plugin=mysql_native_password
log-bin=mysql-bin
gtid_mode=ON
enforce-gtid-consistency=ON
skip-name-resolve
binlog_format=ROW# slave2中
[root@mysqlc ~]# vim /etc/my.cnf
[mysqld]
server-id=30
datadir=/data/mysql
socket=/data/mysql/mysql.sock
default_authentication_plugin=mysql_native_password
log-bin=mysql-bin
gtid_mode=ON
enforce-gtid-consistency=ON
skip-name-resolve
binlog_format=ROW[root@mysqlb & c ~]# mysqld --user mysql --initialize
[root@mysqlb & c ~]# /etc/init.d/mysqld start
[root@mysqlb & c ~]# mysql_secure_installation
# slave两台主机里面都要进行操作!!!
[root@mysqlb & c ~]# mysql -p123456mysql> CHANGE MASTER TO MASTER_HOST='172.25.254.10', MASTER_USER='dhj', MASTER_PASSWORD='123456', MASTER_AUTO_POSITION=1;mysql> start slave;mysql> INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';mysql> SET GLOBAL rpl_semi_sync_slave_enabled =1;mysql> STOP SLAVE IO_THREAD;
mysql> START SLAVE IO_THREAD;mysql> SHOW STATUS LIKE 'Rpl_semi_sync%';
+----------------------------+-------+
| Variable_name | Value |
+----------------------------+-------+
| Rpl_semi_sync_slave_status | ON |
+----------------------------+-------+mysql> SET GLOBAL sql_slave_skip_counter = 1;
6.2.2 安装MHA所需要的软件
6.2.2.1 步骤
#在MHA中
[root@mha ~]# unzip MHA-7.zip[root@mha MHA-7]# scp mha4mysql-node-0.58-0.el7.centos.noarch.rpm root@172.25.254.10:/mnt/
[root@mha MHA-7]# scp mha4mysql-node-0.58-0.el7.centos.noarch.rpm root@172.25.254.20:/mnt/
[root@mha MHA-7]# scp mha4mysql-node-0.58-0.el7.centos.noarch.rpm root@172.25.254.30:/mnt/[root@mysqla ~]# yum install /mnt/*.rpm -y
[root@mysqlb ~]# yum install /mnt/*.rpm -y
[root@mysqlc ~]# yum install /mnt/*.rpm -y# 为所有节点之间建立免密认证的步骤
[root@mha ~]# ssh-keygen # 一路回车即可
# 在mha这台管理节点上生成一对RSA公钥/私钥,一路回车即不设置 passphrase[root@mysqla ~]# mkdir -p ~/.ssh && chmod 700 ~/.ssh
[root@mysqlb ~]# mkdir -p ~/.ssh && chmod 700 ~/.ssh
[root@mysqlc ~]# mkdir -p ~/.ssh && chmod 700 ~/.ssh
# 在mysqla/mysqlb/mysqlc三台MySQL 服务器上预先创建 .ssh 目录并设权限为 700(仅属主可读写执行)
# 目的:防止后续 scp/ssh-copy-id 因目录不存在或权限过宽导致失败[root@mha ~]# ssh-copy-id root@172.25.254.10
[root@mha ~]# ssh-copy-id root@172.25.254.20
[root@mha ~]# ssh-copy-id root@172.25.254.30
# 远程把 mha 的公钥追加到目标机 /root/.ssh/authorized_keys,同时修正权限。[root@mha ~]# scp /root/.ssh/id_rsa root@172.25.254.10:/root/.ssh/
[root@mha ~]# scp /root/.ssh/id_rsa root@172.25.254.20:/root/.ssh/
[root@mha ~]# scp /root/.ssh/id_rsa root@172.25.254.30:/root/.ssh/
# 把私钥 id_rsa 直接拷到远程 /root/.ssh/
# 介意安全性的话,可以传输公钥/root/.ssh/id_rsa.pub,而不是私钥
6.2.2.2 在软件中包含的工具包介绍
1.Manager工具包主要包括以下几个工具:
- masterha_check_ssh #检查MHA的SSH配置状况
- masterha_check_repl #检查MySQL复制状况
- masterha_manger #启动MHA
- masterha_check_status #检测当前MHA运行状态
- masterha_master_monitor #检测master是否宕机
- masterha_master_switch #控制故障转移(自动或者手动)
- masterha_conf_host #添加或删除配置的server信息
2.Node工具包 (通常由masterHA主机直接调用,无需人为执行)
- save_binary_logs #保存和复制master的二进制日志
- apply_diff_relay_logs #识别差异的中继日志事件并将其差异的事件应用于其他的slave
- filter_mysqlbinlog #去除不必要的ROLLBACK事件(MHA已不再使用这个工具)
- purge_relay_logs #清除中继日志(不会阻塞SQL线程)
6.2.3 配置MHA 的管理环境
[root@mysql-mha ~]# masterha_manager --help
Usage:masterha_manager --global_conf=/etc/masterha_default.cnf #全局配置文件,记录公共设定--conf=/usr/local/masterha/conf/app1.cnf #不同管理配置文件,记录各自配置See online reference(http://code.google.com/p/mysql-master-ha/wiki/masterha_manager) fordetails.
因为我们当前只有一套主从,所以我们只需要写一个配置文件即可
rpm包中没有为我们准备配置文件的模板
可以解压源码包后在samples中找到配置文件的模板文件
6.2.3.1 模版文件配置说明
# 以下为配置文件参数详解,主要实操配置在下面:
# 编辑配置文件
[root@mysql-mha ~]# vim /etc/masterha/app1.cnf
[server default]
user=root # mysql管理员用户,因为需要做自动化配置
password=lee # mysql密码
ssh_user=root # ssh远程登陆用户
repl_user=repl # mysql主从复制中负责认证的用户
repl_password=lee # mysql主从复制中负责认证的用户密码master_binlog_dir= /data/mysql # 二进制日志目录
remote_workdir=/tmp # 远程工作目录# 此参数使为了提供冗余检测,方式是mha主机网络自身的问题无法连接数据库节点,应为集群之外的主机
secondary_check_script= masterha_secondary_check -s 172.25.254.10 -s 172.25.254.11ping_interval=3 # 每隔3秒检测一次# 发生故障后调用的脚本,用来迁移vip
# master_ip_failover_script= /script/masterha/master_ip_failover# 电源管理脚本
# shutdown_script= /script/masterha/power_manager# 当发生故障后用此脚本发邮件或者告警通知
# report_script= /script/masterha/send_report# 在线切换时调用的vip迁移脚本,手动
# master_ip_online_change_script= /script/masterha/master_ip_online_changemanager_workdir=/etc/masterha # mha工作目录
manager_log=/var/etc/masterha/manager.log # mha日志[server1]
hostname=172.25.254.10
candidate_master=1 # 可能作为master的主机check_repl_delay=0 # 默认情况下如果一个slave落后master 100M的relay logs的话# MHA将不会选择该slave作为一个新的master# 因为对于这个slave的恢复需要花费很长时间# 通过设置check_repl_delay=0# MHA触发切换在选择一个新的master的时候将会忽略复制延时# 这个参数对于设置了candidate_master=1的主机非常有用# 因为这个候选主在切换的过程中一定是新的master[server2]
hostname=172.25.254.20
candidate_master=1 # 可能作为master的主机
check_repl_delay=0[server3]
hostname=172.25.254.30
no_master=1 # 不会作为master的主机
6.2.3.2 生成配置目录和配置文件
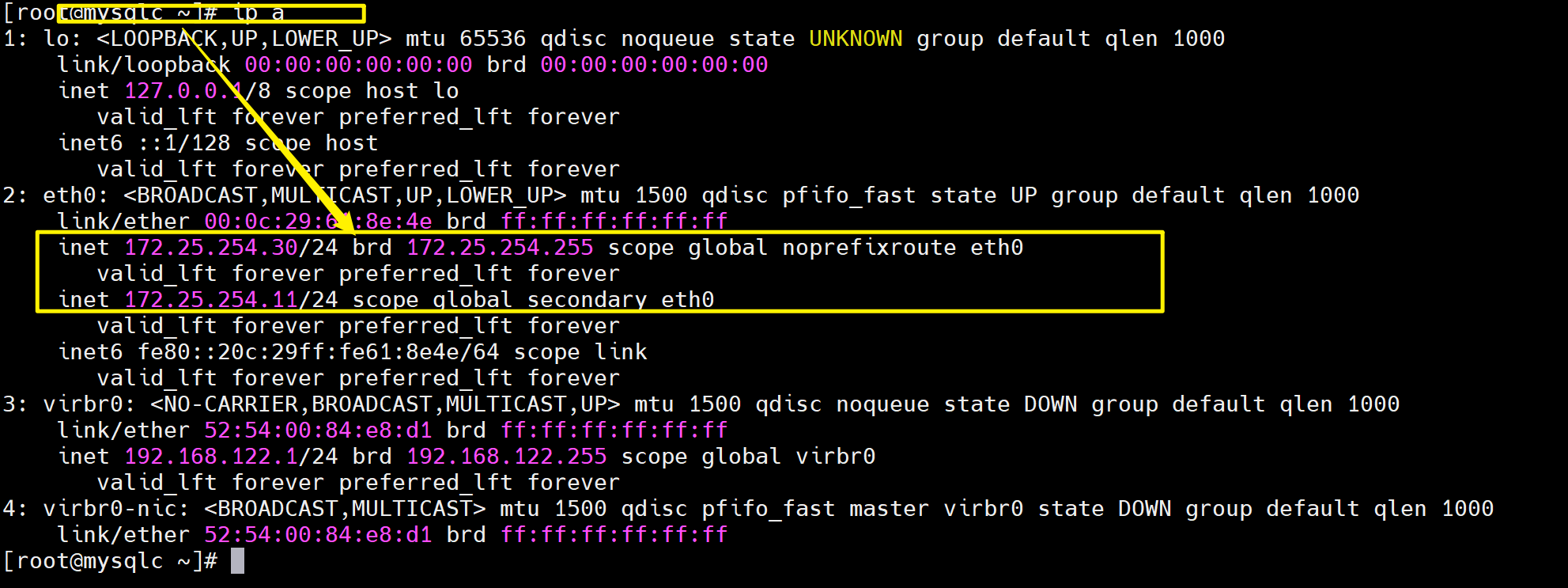
# 在任意slave节点加入测试ip(最好是no-master的那个主机)
[root@mysqlc ~]# ip a a 172.25.254.11/24 dev eth0
[root@mha ~]# cd MHA-7/
[root@mha MHA-7]# yum install *.rpm -y
[root@mha MHA-7]# tar zxf mha4mysql-manager-0.58.tar.gz
[root@mha MHA-7]# cd mha4mysql-manager-0.58/
[root@mha mha4mysql-manager-0.58]# cd samples/
[root@mha samples]# cd conf/[root@mha conf]# mkdir -p /etc/mha
[root@mha conf]# cat masterha_default.cnf app1.cnf >/etc/mha/mha.conf
[root@mha conf]# vim /etc/mha/mha.conf
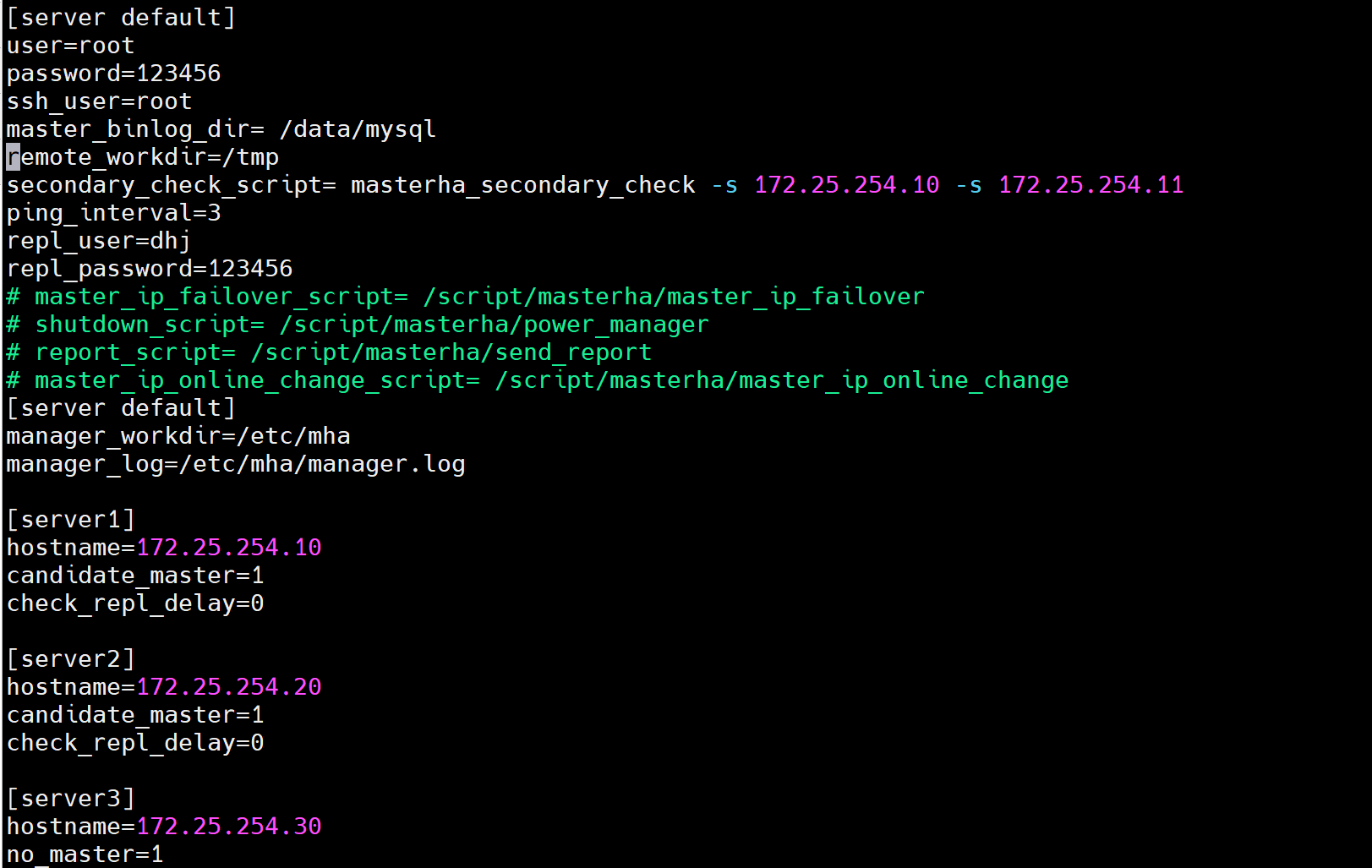
[root@mha conf]# cat /etc/mha/mha.conf
[server default]
user=root
password=123456
ssh_user=root
master_binlog_dir= /data/mysql
remote_workdir=/tmp
secondary_check_script= masterha_secondary_check -s 172.25.254.10 -s 172.25.254.11
ping_interval=3
repl_user=dhj
repl_password=123456
# master_ip_failover_script= /script/masterha/master_ip_failover
# shutdown_script= /script/masterha/power_manager
# report_script= /script/masterha/send_report
# master_ip_online_change_script= /script/masterha/master_ip_online_change
[server default]
manager_workdir=/etc/mha
manager_log=/etc/mha/manager.log[server1]
hostname=172.25.254.10
candidate_master=1
check_repl_delay=0[server2]
hostname=172.25.254.20
candidate_master=1
check_repl_delay=0[server3]
hostname=172.25.254.30
no_master=1
# 在主master中设定root远程登录功能
[root@mysqla ~]# mysql -p123456mysql> CREATE USER IF NOT EXISTS root@'%' identified by '123456';mysql> grant ALL ON *.* TO root@'%';
6.2.3.3 检测配置
# 在每一台主机中做如下内容:
[root@mha ~]# vim /etc/hosts
172.25.254.100 MHA.dhj.org
172.25.254.10 mysqla.dhj.org
172.25.254.20 mysqlb.dhj.org
172.25.254.30 mysqlc.dhj.org[root@mha ~]# scp /etc/hosts root@172.25.254.10:/etc/hosts
[root@mha ~]# scp /etc/hosts root@172.25.254.20:/etc/hosts
[root@mha ~]# scp /etc/hosts root@172.25.254.30:/etc/hosts

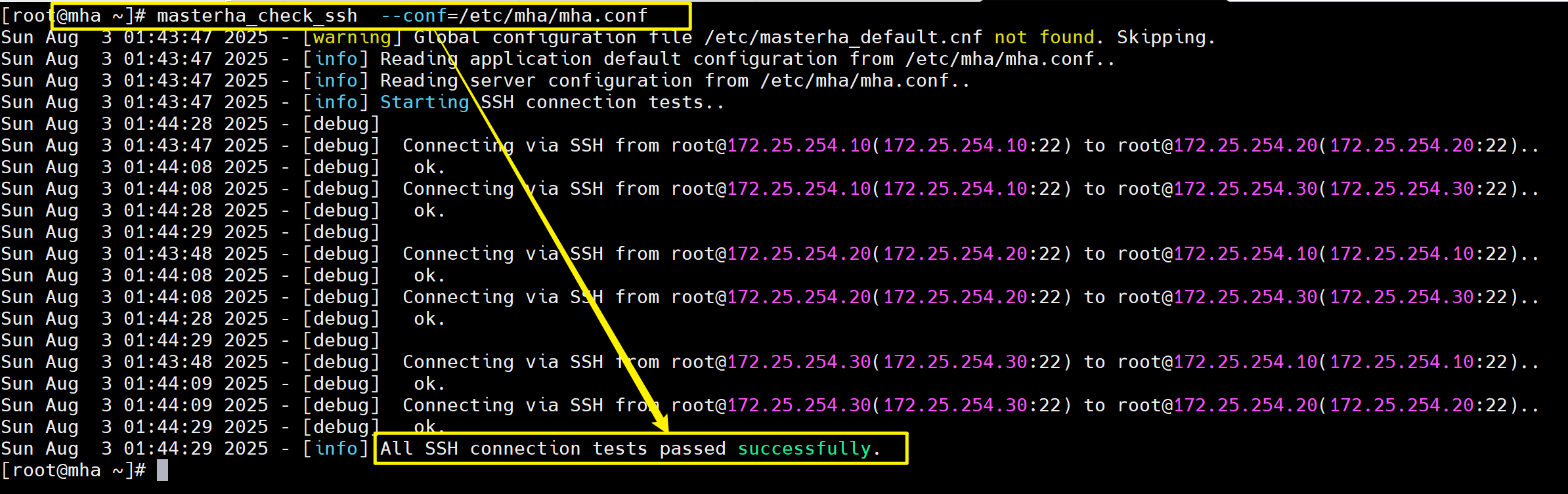
1.检测网络及ssh免密
[root@mha ~]# masterha_check_ssh --conf=/etc/mha/mha.conf
......
All SSH connection tests passed successfully.
2.检测数据主从复制情况
# 执行检测
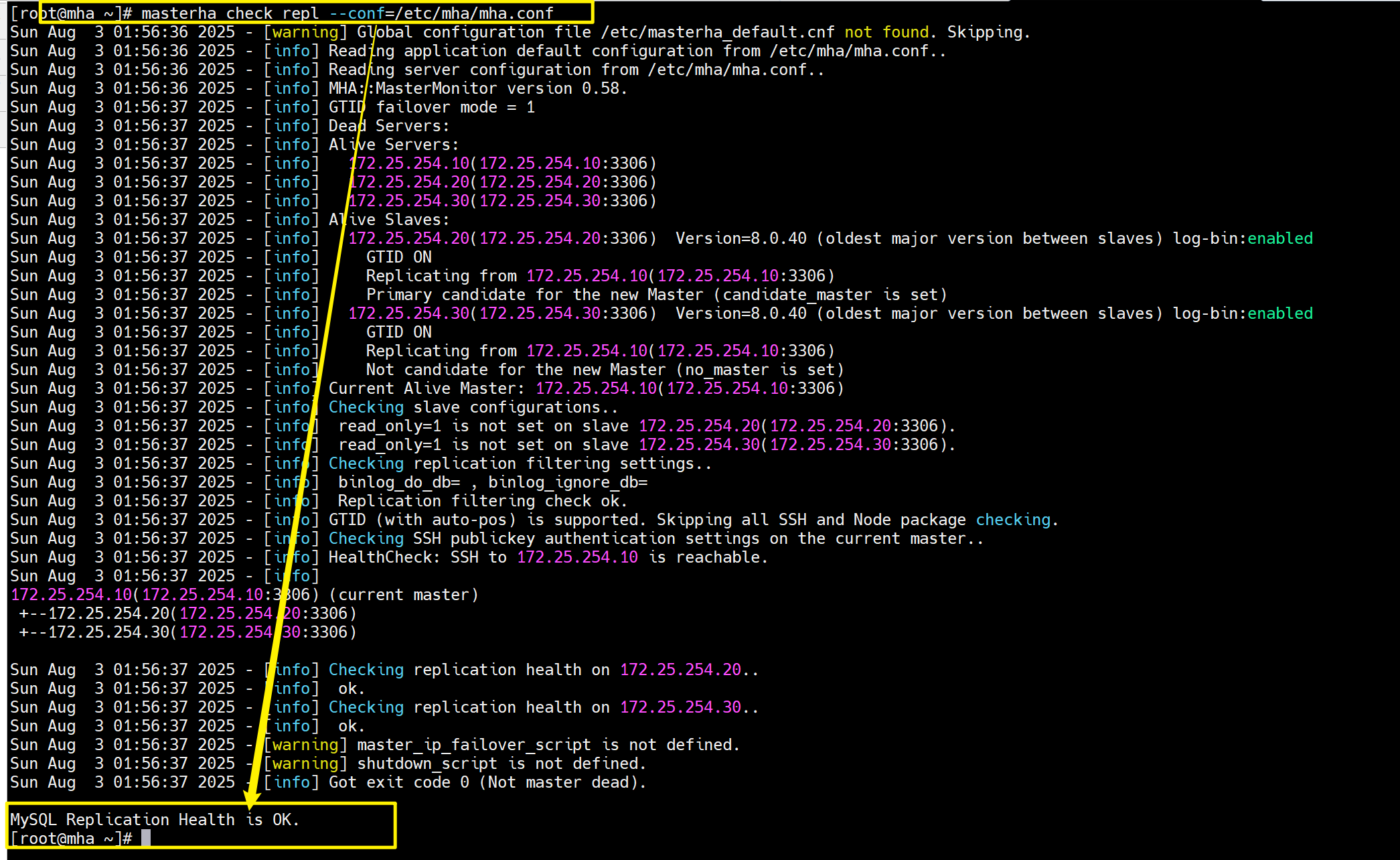
[root@mha ~]# masterha_check_repl --conf=/etc/mha/mha.conf
......
MySQL Replication Health is OK.
6.2.3 MHA的故障切换
6.2.3.1 MHA的故障切换步骤
1.配置文件检查阶段,这个阶段会检查整个集群配置文件配置
2.宕机的master处理,这个阶段包括虚拟ip摘除操作,主机关机操作
3.复制dead master和最新slave相差的relay log,并保存到MHA Manger具体的目录下
4.识别含有最新更新的slave
5.应用从master保存的二进制日志事件(binlog events)
6.提升一个slave为新的master进行复制
7.使其他的slave连接新的master进行复制
6.2.3.2 切换方式
1.master未出现故障手动切换
#在master数据节点还在正常工作情况下
[root@mysql-mha ~]# masterha_master_switch \
--conf=/etc/masterha/app1.cnf \ #指定配置文件
--master_state=alive \ #指定master节点状态
--new_master_host=172.25.254.20 \ #指定新master节点
--new_master_port=3306 \ #执行新master节点端口
--orig_master_is_new_slave \ #原始master会变成新的slave
--running_updates_limit=10000 #切换的超时时间
切换过程:
#切换过程如下:
[root@mysql-mha masterha]# masterha_master_switch --conf=/etc/mha/mha.conf --master_state=alive --new_master_host=172.25.254.20 --new_master_port=3306 --orig_master_is_new_slave --running_updates_limit=10000
# 一路yes即可
检测:
[root@mysql-mha masterha]# masterha_check_repl --conf=/etc/mha/mha.conf
MySQL Replication Health is OK.
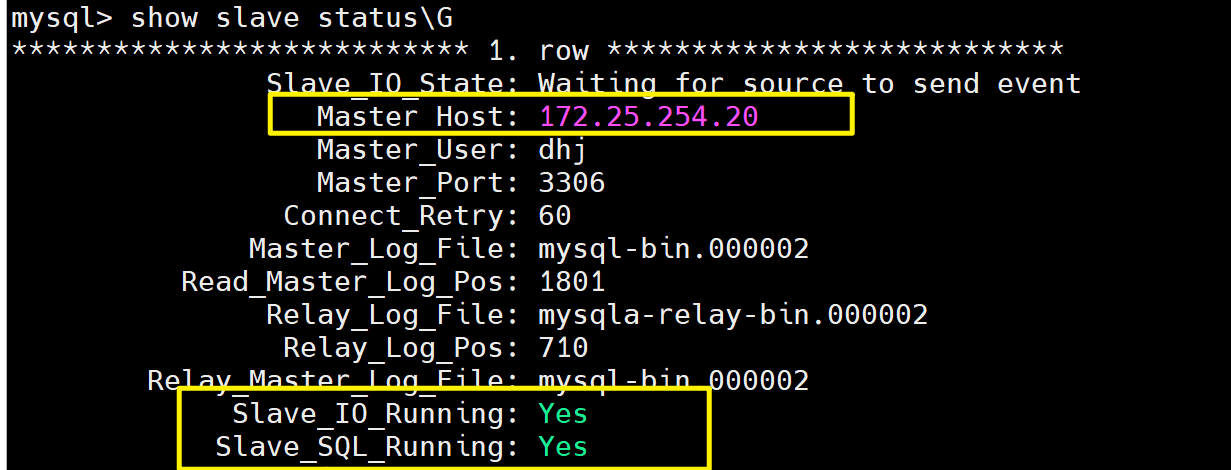
# 在原本的master的10主机上查看,发现10已经从master变为slave了
mysql> show slave status\G
*************************** 1. row ***************************Slave_IO_State: Waiting for source to send eventMaster_Host: 172.25.254.20 # 此处master已经从10迁移到20了Master_User: dhjMaster_Port: 3306Connect_Retry: 60Master_Log_File: mysql-bin.000002Read_Master_Log_Pos: 1801Relay_Log_File: mysqla-relay-bin.000002Relay_Log_Pos: 710Relay_Master_Log_File: mysql-bin.000002Slave_IO_Running: YesSlave_SQL_Running: Yes
2.master出现故障手动切换:
# 模拟master故障(此时master主机为172.25.254.20)
[root@mysqlb ~]# /etc/init.d/mysqld stop# 在MHA-master中做故障切换
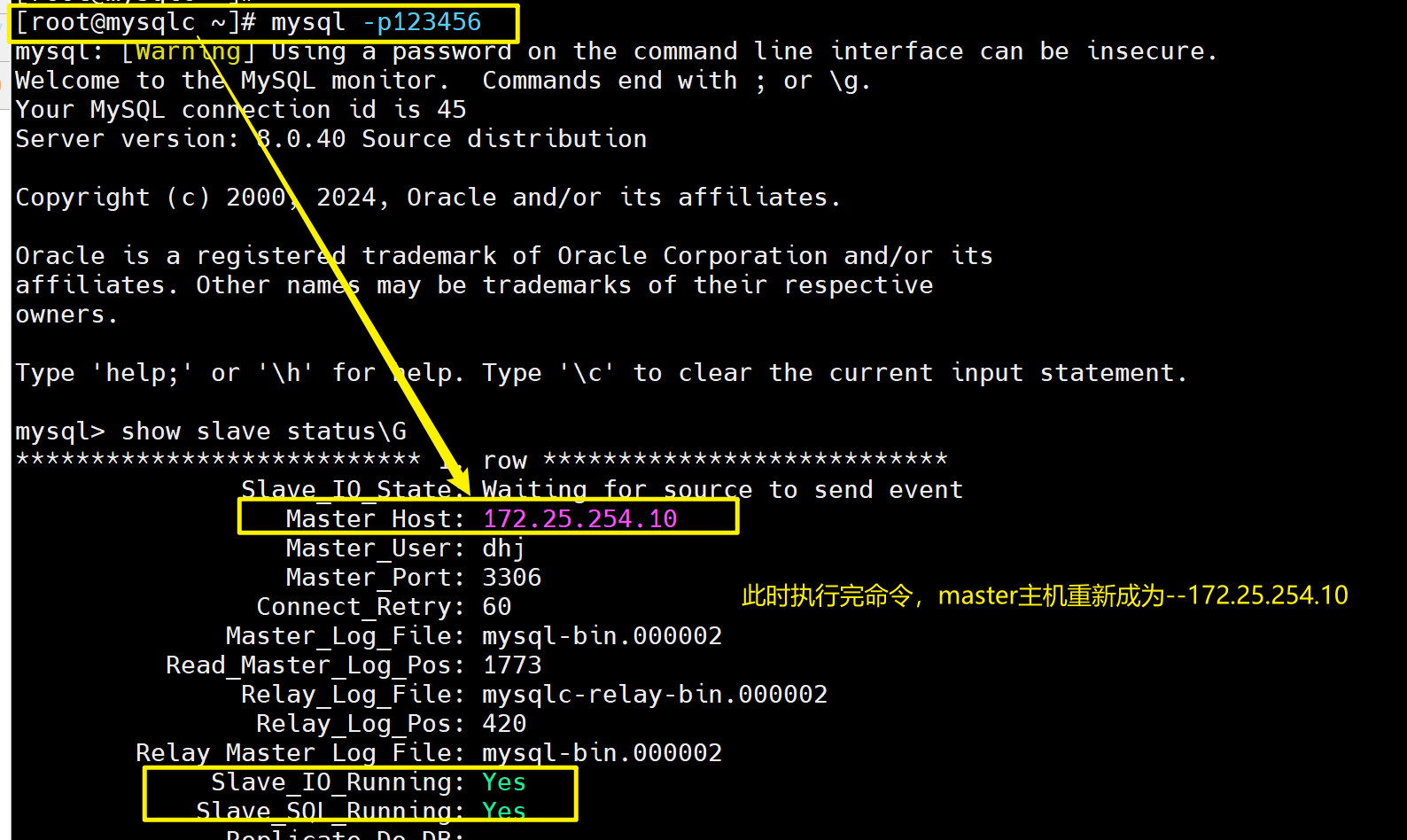
[root@mha ~]# masterha_master_switch --master_state=dead --conf=/etc/mha/mha.conf --dead_master_host=172.25.254.20 --dead_master_port=3306 --new_master_host=172.25.254.10 --new_master_port=3306 --ignore_last_failover# --ignore_last_failover 表示忽略在/etc/mha/目录中在切换过程中生成的锁文件# 执行完命令发现172.25.254.10已经重新成为master主机

# 此时原为master的172.25.254.20挂掉了
# 可以使用永不为master的30(mysqlc)去测试slave的状态
[root@mysqlc ~]# mysql -p123456
mysql> show slave status\G
*************************** 1. row ***************************Slave_IO_State: Waiting for source to send eventMaster_Host: 172.25.254.10 # 此处master已经从20迁移到10了Master_User: dhjMaster_Port: 3306Connect_Retry: 60Master_Log_File: mysql-bin.000002Read_Master_Log_Pos: 1773Relay_Log_File: mysqlc-relay-bin.000002Relay_Log_Pos: 420Relay_Master_Log_File: mysql-bin.000002Slave_IO_Running: YesSlave_SQL_Running: Yes
恢复故障mysql节点
[root@mysqlb ~]# /etc/init.d/mysqld start
[root@mysqlb ~]# mysql -p123456
mysql> stop slave;mysql> CHANGE MASTER TO MASTER_HOST='172.25.254.10', MASTER_USER='dhj', MASTER_PASSWORD='123456', MASTER_AUTO_POSITION=1;mysql> start slave;mysql> show slave status\G
*************************** 1. row ***************************Slave_IO_State: Waiting for source to send eventMaster_Host: 172.25.254.10Master_User: dhjMaster_Port: 3306Connect_Retry: 60Master_Log_File: mysql-bin.000002Read_Master_Log_Pos: 1773Relay_Log_File: mysqlb-relay-bin.000002Relay_Log_Pos: 420Relay_Master_Log_File: mysql-bin.000002Slave_IO_Running: YesSlave_SQL_Running: Yes# 测试一主两从是否正常
[root@mysql-mha masterha]# masterha_check_repl --conf=/etc/mha/mha.conf
......
MySQL Replication Health is OK.
3.自动切换
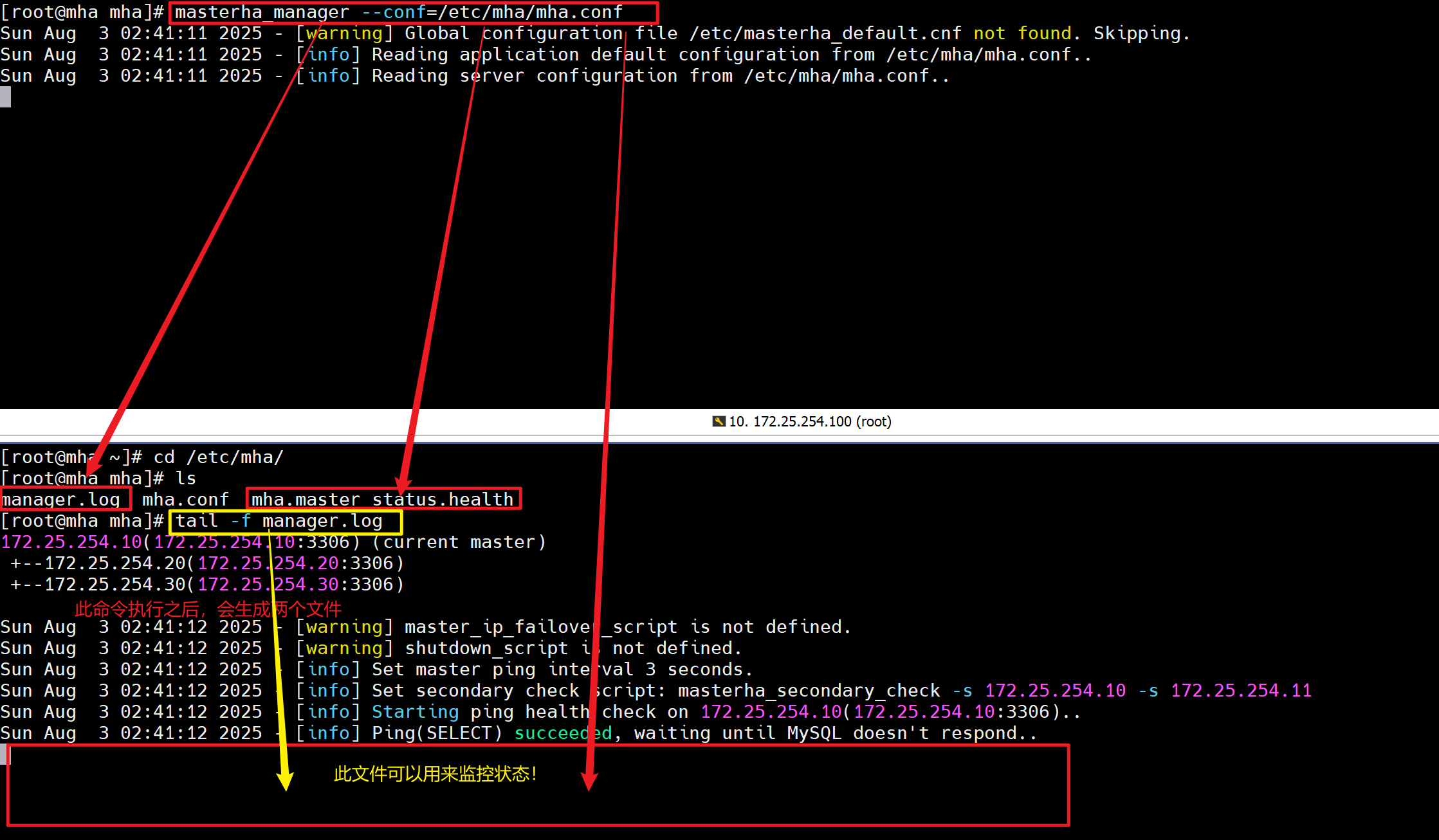
[root@mha ~]# cd /etc/mha/
[root@mha mha]# rm -rf mha.failover.complete # 删掉切换锁文件(没有就忽略)# 监控程序通过指定配置文件监控master状态,当master出问题后自动切换并退出避免重复做故障切换
[root@mha mha]# masterha_manager --conf=/etc/mha/mha.conf# 再开一个终端看看
[root@mha mha]# tail -f /etc/mha/manager.log
模拟故障
# 在slave2(172.25.254.30中查看一下此时谁为master)
mysql> show slave status\G
*************************** 1. row ***************************Slave_IO_State: Waiting for source to send eventMaster_Host: 172.25.254.20Master_User: dhjMaster_Port: 3306Connect_Retry: 60Master_Log_File: mysql-bin.000002Read_Master_Log_Pos: 1801Relay_Log_File: mysqlc-relay-bin.000002Relay_Log_Pos: 710Relay_Master_Log_File: mysql-bin.000002Slave_IO_Running: YesSlave_SQL_Running: Yes
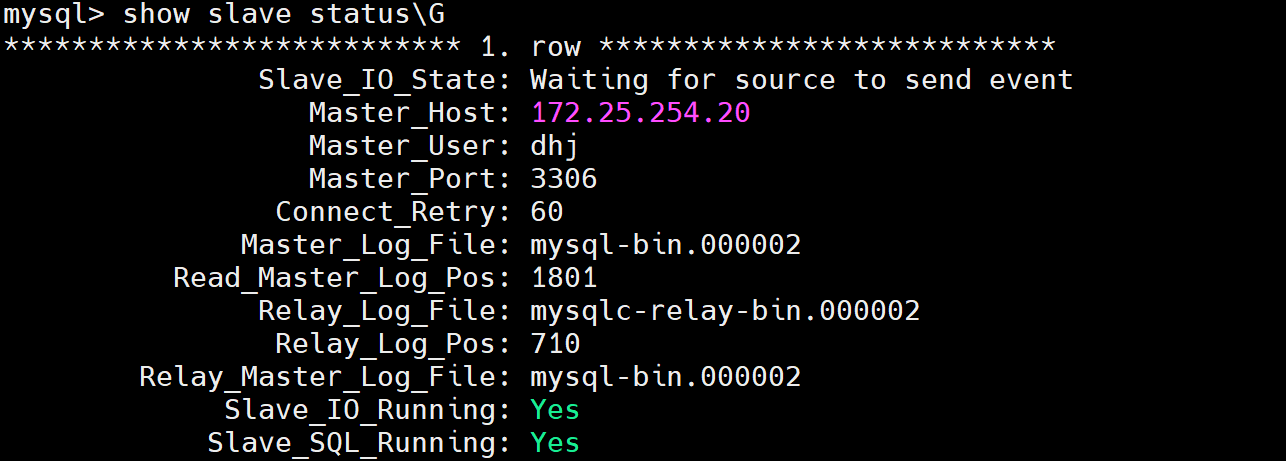
# 此时模拟故障,将master关闭,同时tail -f 查看mha的监控文件的变化(如下图所示)
[root@mysqlb ~]# /etc/init.d/mysqld stop# 此时将master关闭之后,会发现自动进行切换,切换到172.25.254.10上,将其切换为master主机
# 此时在slave2进行查看
mysql> show slave status\G
*************************** 1. row ***************************Slave_IO_State: Waiting for source to send eventMaster_Host: 172.25.254.10Master_User: dhjMaster_Port: 3306Connect_Retry: 60Master_Log_File: mysql-bin.000002Read_Master_Log_Pos: 1773Relay_Log_File: mysqlc-relay-bin.000002Relay_Log_Pos: 420Relay_Master_Log_File: mysql-bin.000002Slave_IO_Running: YesSlave_SQL_Running: Yes
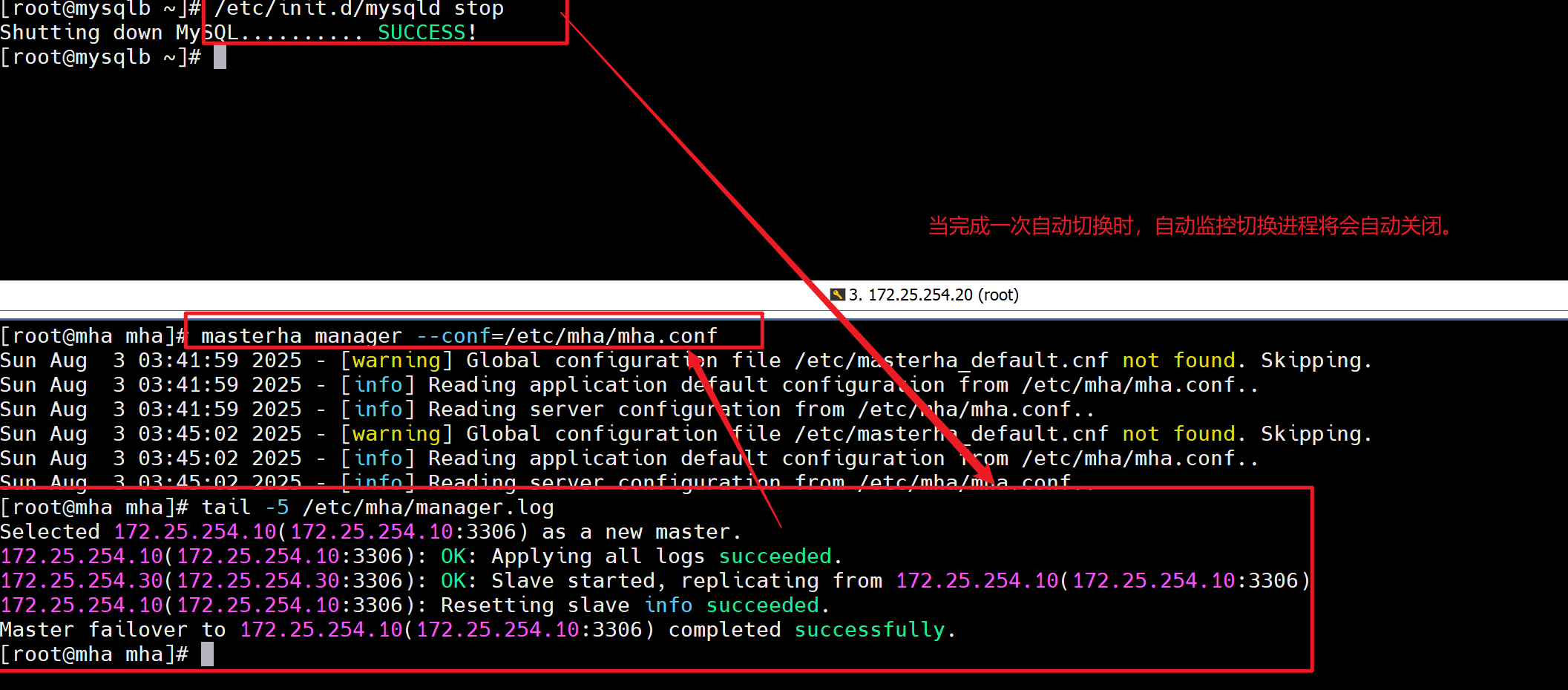
由于监控进程只触发一次,出发之后则退出;
此时应该有电话预警或者邮箱预警。
作为运维老鸟,应该起床,恢复故障节点了…
[root@mysqlb ~]# /etc/init.d/mysqld start
[root@mysqlb ~]# mysql -p123456mysql> CHANGE MASTER TO MASTER_HOST='172.25.254.10', MASTER_USER='dhj', MASTER_PASSWORD='123456', MASTER_AUTO_POSITION=1;mysql> start slave;mysql> show slave status\G
*************************** 1. row ***************************Slave_IO_State: Waiting for source to send eventMaster_Host: 172.25.254.10Master_User: dhjMaster_Port: 3306Connect_Retry: 60Master_Log_File: mysql-bin.000002Read_Master_Log_Pos: 1773Relay_Log_File: mysqlb-relay-bin.000002Relay_Log_Pos: 420Relay_Master_Log_File: mysql-bin.000002Slave_IO_Running: YesSlave_SQL_Running: Yes
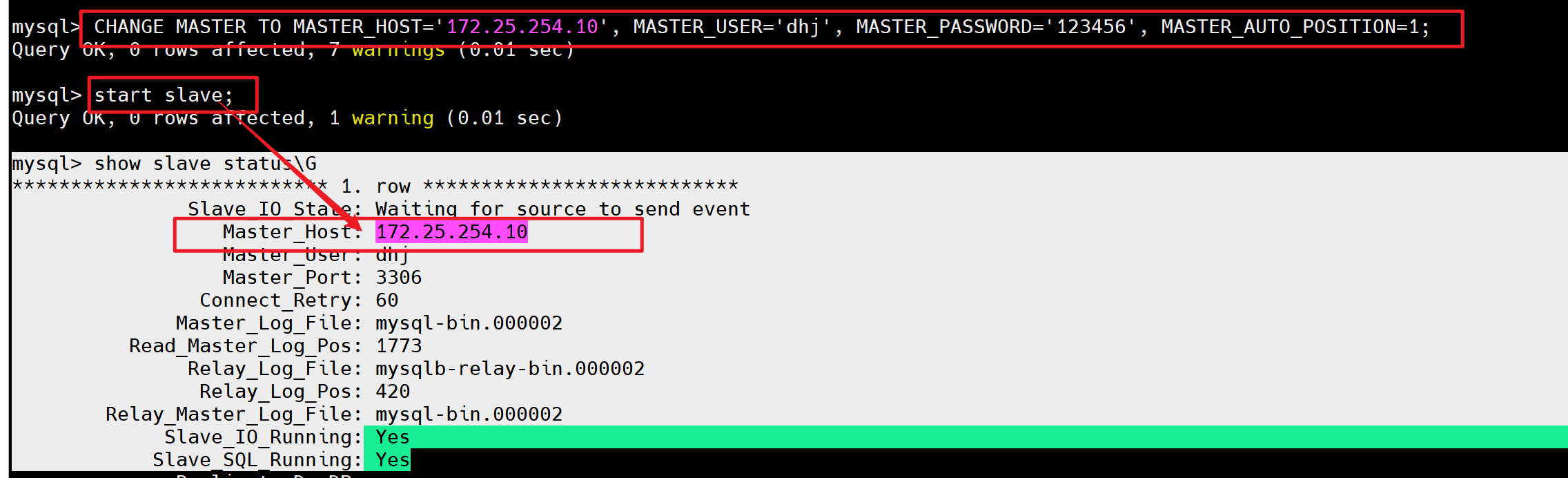
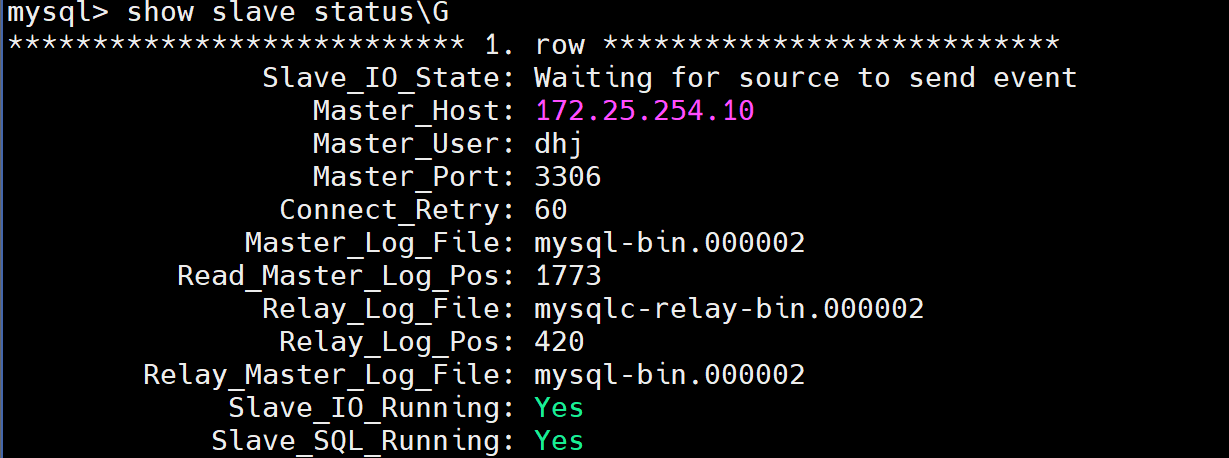
# 此时去slave2(30)中测试一下
mysql> show slave status\G
*************************** 1. row ***************************Slave_IO_State: Waiting for source to send eventMaster_Host: 172.25.254.10Master_User: dhjMaster_Port: 3306Connect_Retry: 60Master_Log_File: mysql-bin.000002Read_Master_Log_Pos: 1773Relay_Log_File: mysqlc-relay-bin.000002Relay_Log_Pos: 420Relay_Master_Log_File: mysql-bin.000002Slave_IO_Running: YesSlave_SQL_Running: Yes
清除锁文件
[root@mha mha]# rm -rf mha.failover.complete manager.log