7.14.散列表的基本概念(散列表又名哈希表,Hash Table)
一.散列表、散列函数:

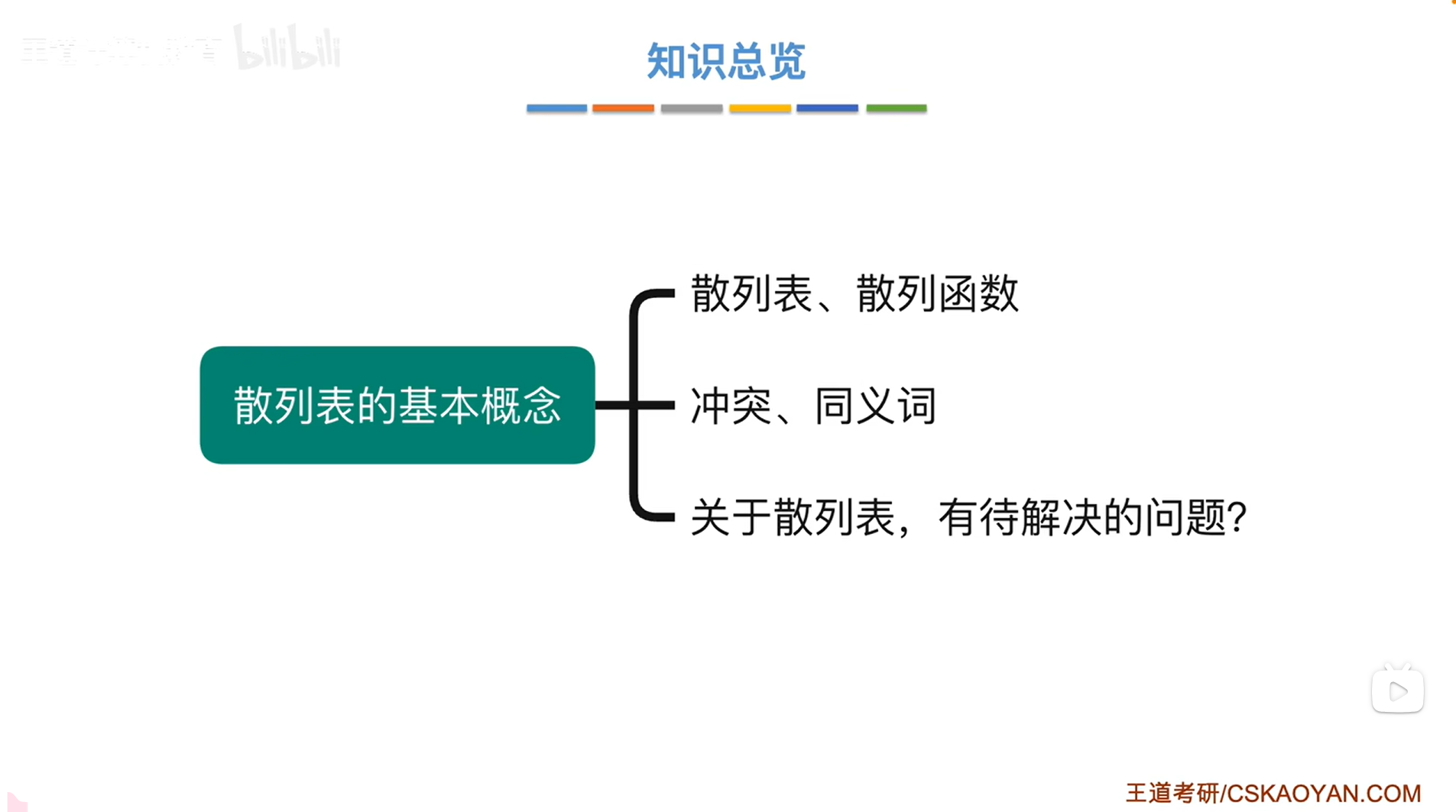
如上图,
散列表是一种数据结构,它的思想比较特别,每一个散列表都会配套一个散列函数,而散列函数的作用就是可以根据数据元素的"关键字"来计算出这个数据元素在散列表中的"存储地址",
以下述图片为例:

如上图,
假设现有一个长度为13的散列表,这个散列表配套的散列函数H(key)=key%13,就是根据数据元素的关键字对13取余,用这样的方式来计算出一个数据元素在散列表中的"存储地址",比如现在有三个数据元素19、14、23需要插入该散列表,
第一个数据元素为19,19应该存储在哪儿呢?把19带入散列函数H(key)=key%13即19%13=6,因此数据元素19应该存储在散列表中下标为6的位置;
第二个数据元素为14,14应该存储在哪儿呢?把14带入散列函数H(key)=key%13即14%13=1,因此数据元素14应该存储在散列表中下标为1的位置;
第三个数据元素为23,23应该存储在哪儿呢?把23带入散列函数H(key)=key%13即23%13=10,因此数据元素23应该存储在散列表中下标为10的位置,
如下图:
如上图,
至此可以得出:散列函数建立了"关键字"->"存储地址"的映射关系,根据散列函数就可以直接计算出一个数据元素在散列表中的存储地址,这样带来的好处显而易见:
如果在散列表中查找某一个数据元素,理想状态下,查找操作的时间复杂度为O(1),
比如现在要在上述图片里的散列表中查找数据元素19是否存在,首先要计算19应该存储在该散列表的哪个位置,根据散列函数H(key)=key%13即19%13=6可知如果19存在于该散列表中,19应该存储在该散列表下标为6的位置,因此接下来要在该散列表下标为6的位置进行查找,发现该散列表中原有的下标为6的数据元素刚好就是19,至此,查找成功,意味着19在该散列表中存在;
再比如现在要在上述图片里的散列表中查找数据元素16是否存在,首先要计算16应该存储在该散列表的哪个位置,根据散列函数H(key)=key%13即16%13=3可知如果16存在于该散列表中,16应该存储在该散列表下标为3的位置,因此接下来要在该散列表下标为3的位置进行查找,发现该散列表中原有的下标为3的位置并没有存储数据元素即为NULL,至此,查找失败,意味着16在该散列表中不存在,
通过刚才的例子可以得出散列表中查找操作的时间复杂度为O(1)->因为不需要遍历,先根据散列函数计算出目标元素在散列表中的存储地址,然后检查该存储地址,就可以知道是否查找成功,当然,这只是在理想的情况下,
还有一些不理想的情况有可能导致查找很复杂,这个之后会介绍。
二.冲突(又名碰撞)、同义词:

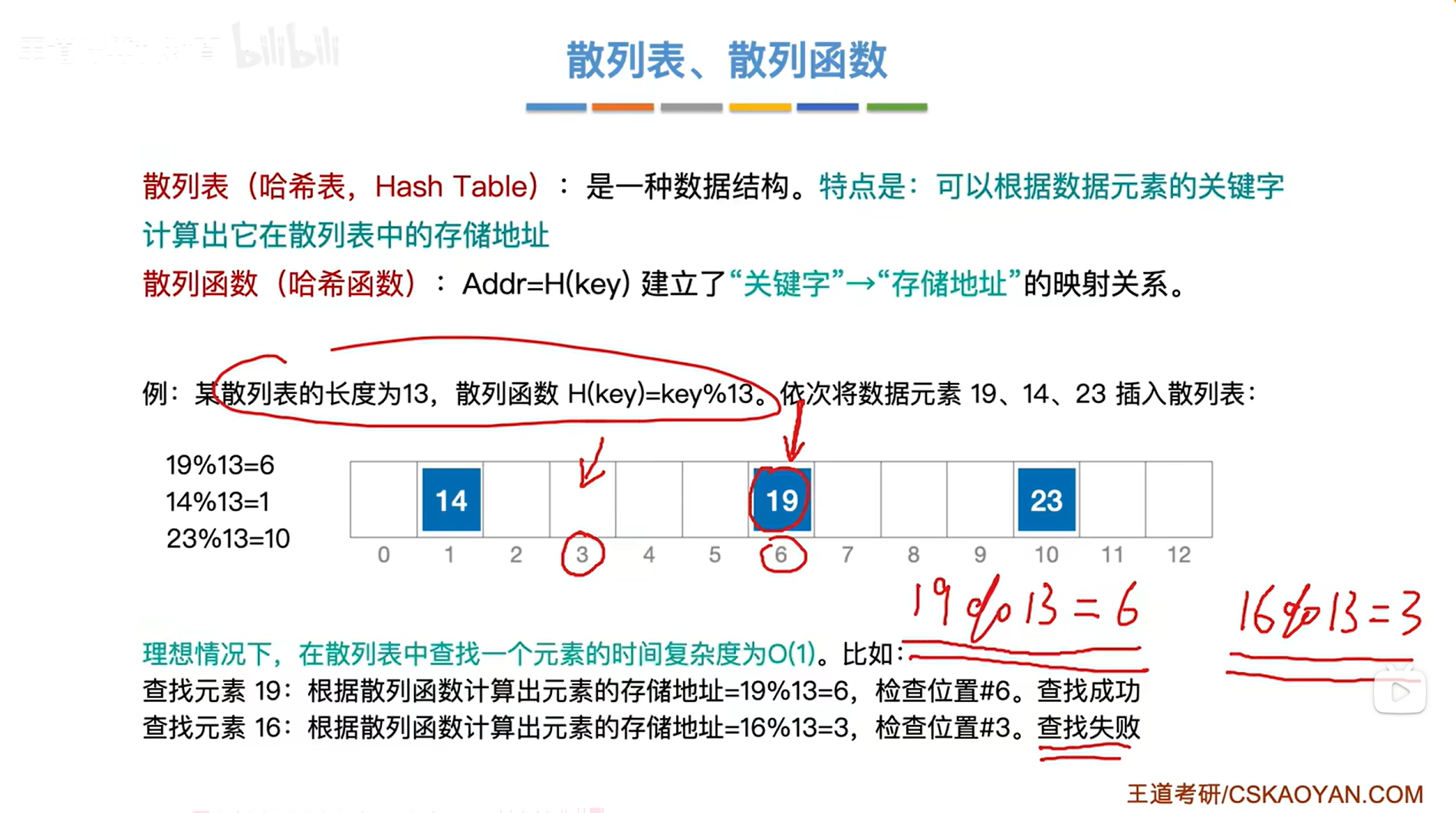
以上述图片的散列表为例,
现在要插入数据元素1,把1带入散列函数H(key)=key%13即1%13=1,因此数据元素1应该存储在该散列表中下标为1的位置,
如下图:

如上图,
该散列表中下标为1的位置原本已有数据元素14,这种情况就称为"冲突",
如下图:

如上图,
如果要在散列表中插入一个新的数据元素,首先需要根据该数据元素的关键字的值并结合散列函数来算出新元素应该存储的地址,如果该存储地址已经存储了其他元素,这种情况称为"冲突(又名碰撞)",
上述图片中出现的"碰撞",1和14这两个关键字被映射到同一个存储地址,这种情况下称1和14是"同义词",也就是两个关键字是否为"同义词",取决于散列函数到底是什么,
如果换一个散列函数,那么1和14就有可能不是"同义词"。
显然,实际中并不希望"冲突"频繁的发生,"冲突"发生的越少,散列表的性能也就越高。
三.如何减少"冲突"?->只需要构造更合适的散列函数即可

以上述图片的散列表为例,
此时1和14发生"冲突",因此1和14互为"同义词",如何减少"冲突"呢?
不难想到,1和14发生冲突是因为1和14在该散列函数H(key)=key%13下被映射到同一个存储地址,也就是说在散列函数H(key)=key%13下1和14是"同义词",如果能够构造一个更合适的散列函数,让各个关键字尽可能地映射到不同的存储地址,这样就可以减少"冲突",
比如把散列函数改为H(key)=key%12,
如下图:

如上图,
此时19、14、23、1分别对12取余,可知19、14、23、1依次存储在散列表中下标为7、2、11、1的位置,
这些关键字19、14、23、1此时被映射到不同的存储地址,显然在这种情况下就不会发生"冲突",
因此如果构造了更合适的散列函数,就可以减少"冲突"的发生,
关键的问题就是:如何构造更合适的散列函数呢?这个之后会介绍。
显而易见的是,无论散列函数构造的再怎么精妙,有时候"冲突"都是难以避免的,比如在刚才的散列函数H(key)=key%12下,如果要插入一个新的数据元素13,把13带入散列函数H(key)=key%12即13%12=1,可知数据元素13应该存储在散列表中下标为1的位置,此时13和之前的数据元素1发生了"冲突",
所以"冲突"很多时候难以避免。
四.若"冲突"无可避免,如何处理"冲突"?

1.解决方案一:拉链法(又称链接法、链地址法)->把所有"同义词"存储在一个链表中
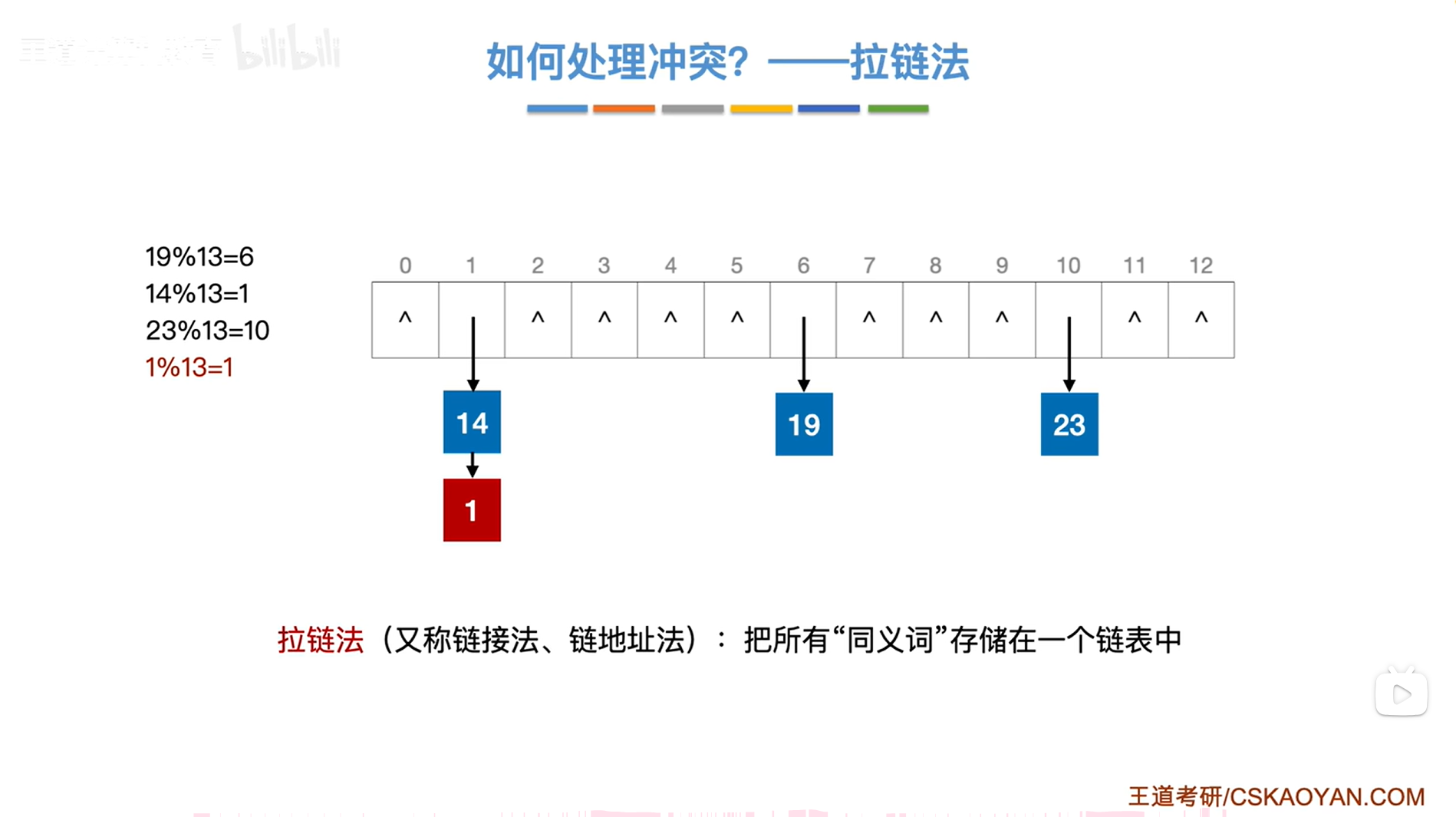
思路:拉链法解决"冲突"的办法就是会把所有的"同义词"用一个链表存储起来,这样的话无论有多少个关键字映射到同一个存储地址,始终都能用一个链表把他们都存储起来。
2.解决方案二:开放定址法
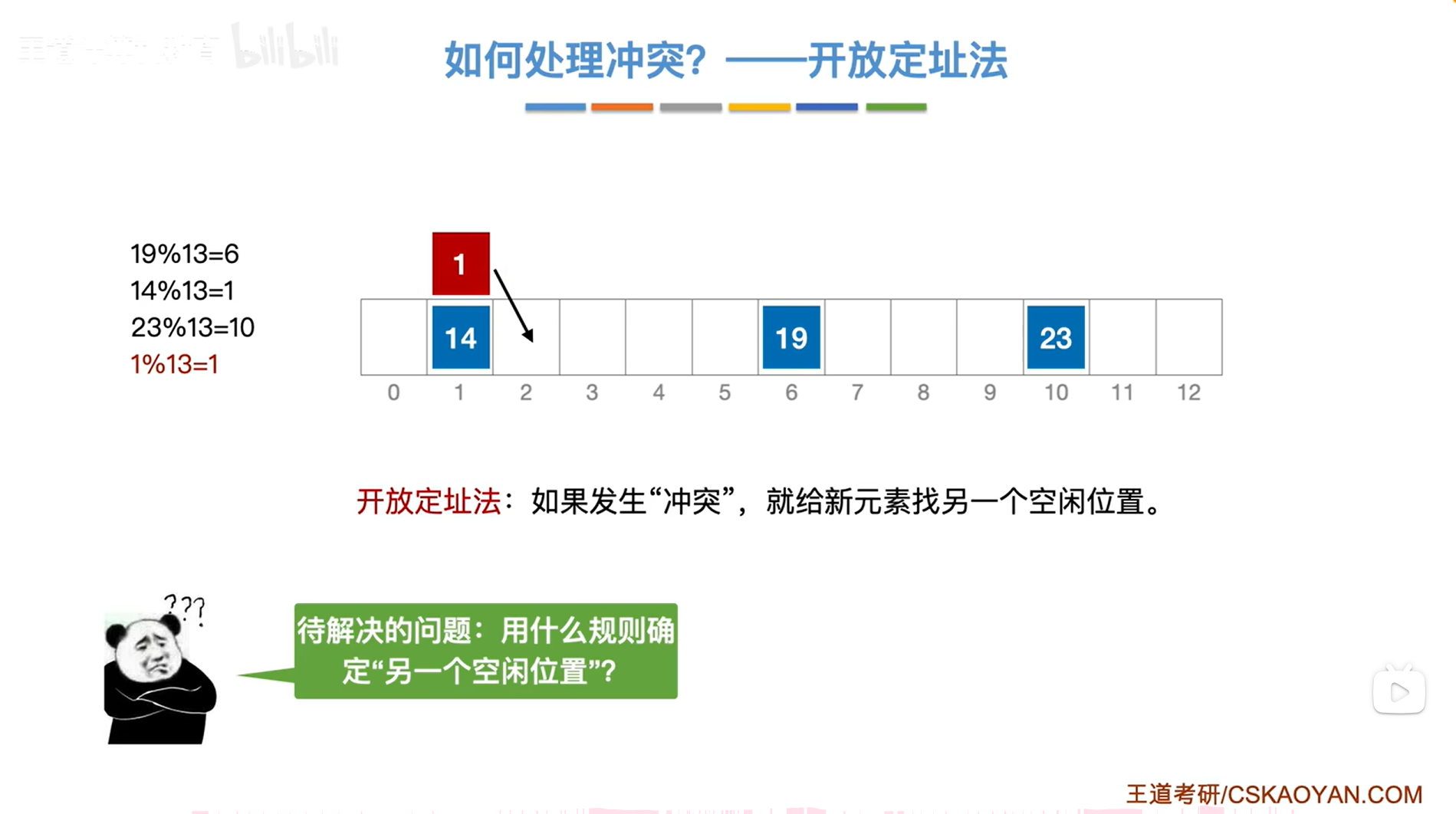
思路:当两个关键字发生"冲突"时,会给这个新插入的关键字另外找一个空闲的位置进行插入,
新的问题就是:采用"开放定址法"时一旦发生"冲突",应该用什么样的规则去确定另一个空闲位置呢?这个问题之后会介绍。
五.总结:
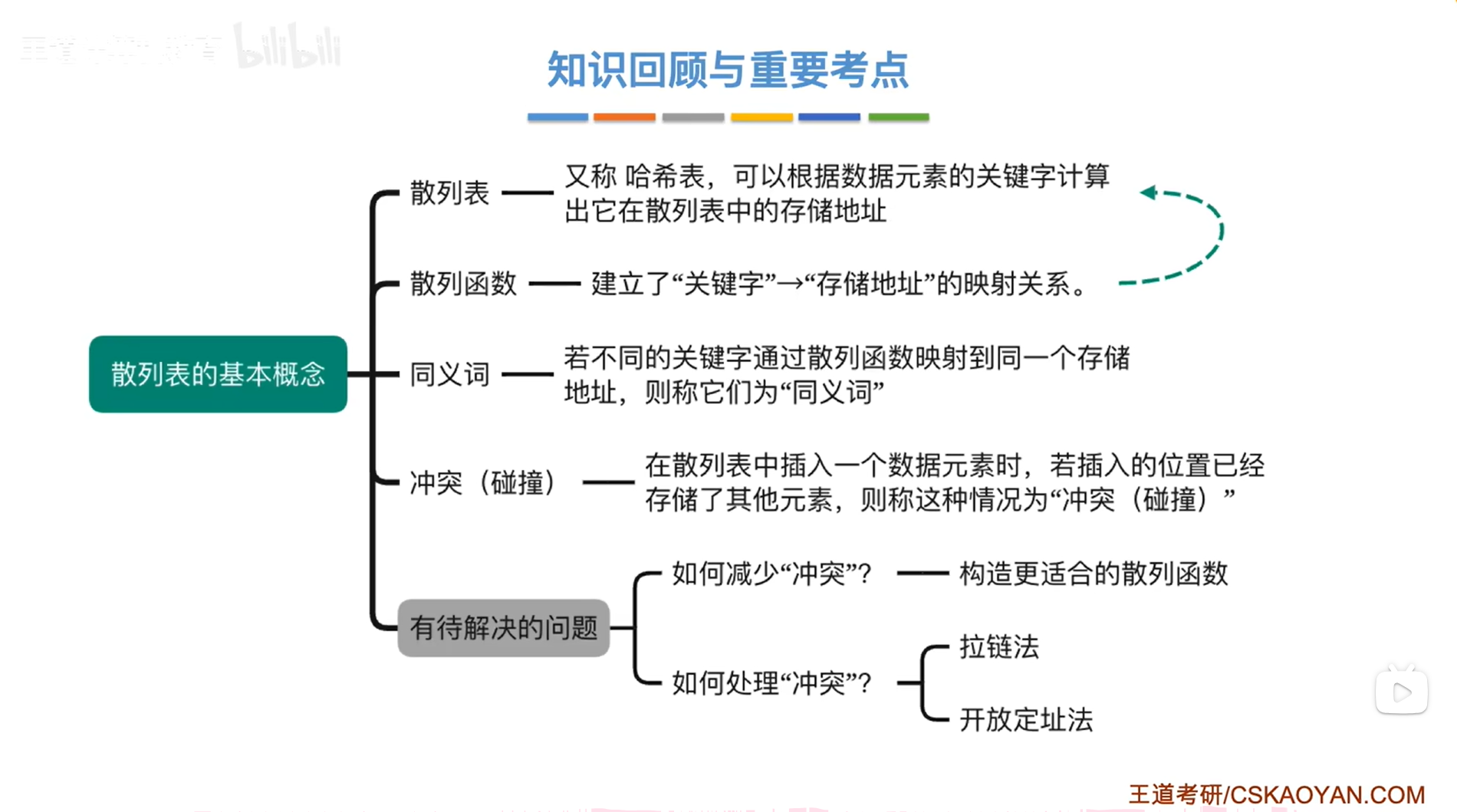
设计散列表时,对应的要给该散列表设计一个散列函数