李宏毅深度学习教程 第6-7章 自注意力机制 + Transformer
强烈推荐!台大李宏毅自注意力机制和Transformer详解!_哔哩哔哩_bilibili
目录
1. 词嵌入&问题情形
2. self-attention 自注意力机制
3. 自注意力的变形
3.1 多头注意力(multi-head)
3.2 位置编码
3.3 截断自注意力(truncated)
3.4 与CNN对比
3.5 与RNN对比
4. Transformer架构
4.1 编码器 Encoder
4.2 自回归解码器
4.3 非自回归解码器
5. Transformer训练过程与技巧
1. 词嵌入&问题情形
词嵌入(word embedding) 用一个有语义信息的向量表示每个词,意思相关的会靠的近
词嵌入的训练基于分布式假说:"单词的语义由其上下文决定"。通过分析单词在文本中的共现模式,模型学习用向量表示单词的语义和语法特征。
比如用“开心”的场景 都可以替换为“高兴” 这两个词的上下文很像 说明他们语义很像;
“苹果”的上下文 和“梨”的上下文也很像,可能他们是同类型的
情形1:输入等于输出 如给一个句子输出每个单词的词性(动词名词这些)都一一对应
情形2:多对一 给一段文字打标签 输出这段话是正面还是负面的
情形3:Seq2Seq序列到序列 如语言翻译 语音识别,输入的字符长度无法知道输出的字符长度
聊天机器人:我和他说话 输入一个序列 机器人返回一个序列
QA问答问题:所有任务都可以转化为 给材料给任务序列,返回答案序列
给文章打一个标签是 多对一问题;给文章打多个标签 就是多对多问题
2. self-attention 自注意力机制
 三个向量&三个步骤
三个向量&三个步骤
![]()

![]()
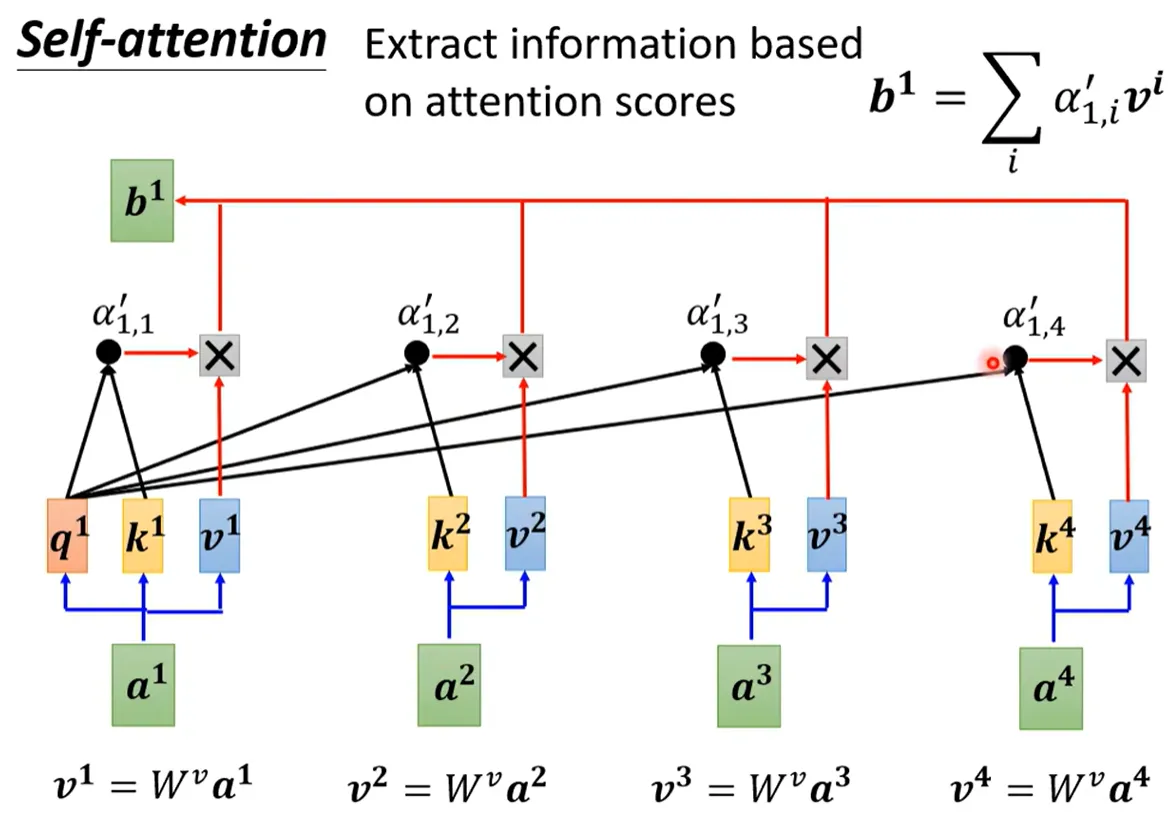
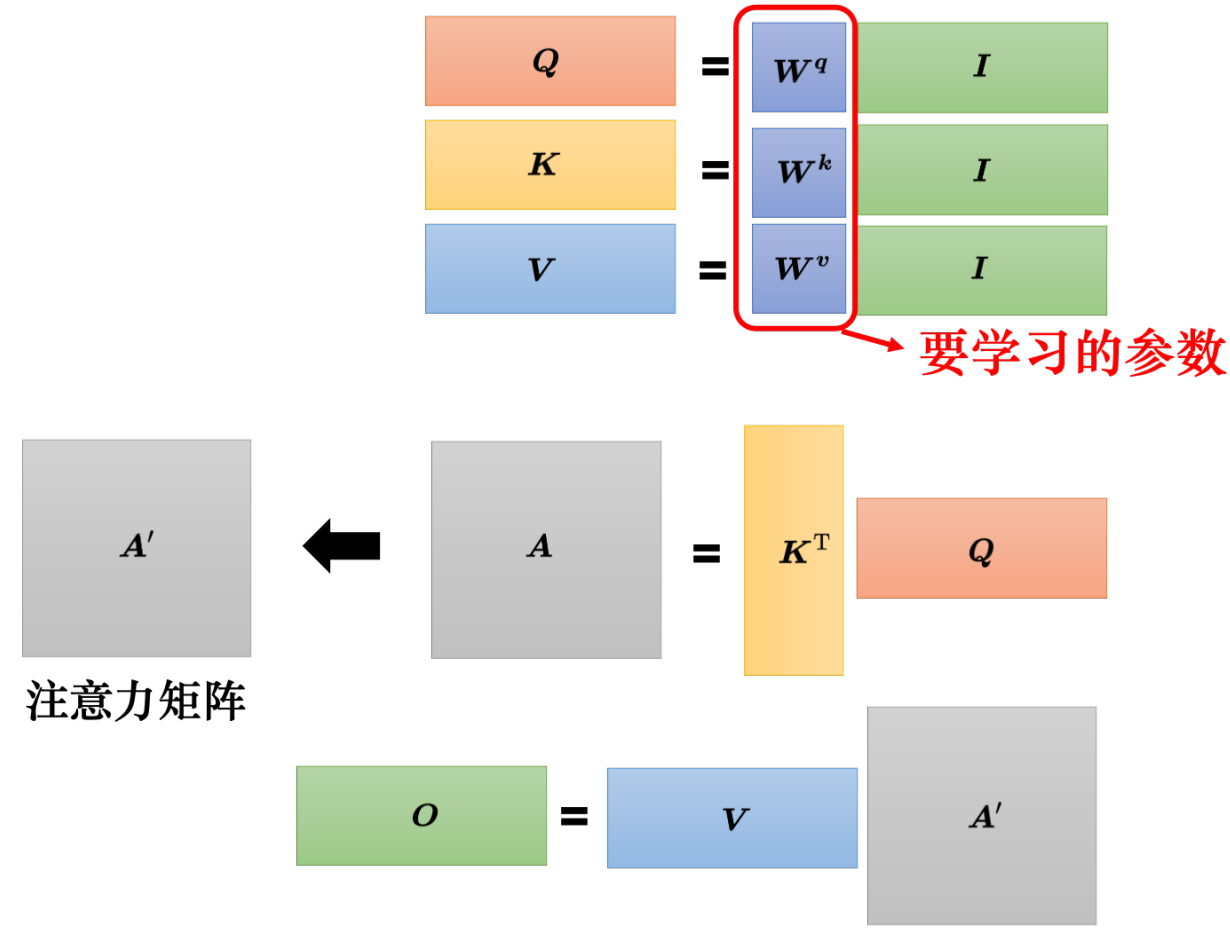
Q K V 三个向量需要 X分别乘以矩阵W;这三个矩阵W 需要训练得到
我要问位置1的注意力值是多少,就拿Q1 和所有位置的K相乘后softmax 得到A'
再用A'V 得到自注意力 b1。 用矩阵乘法可以写成
3. 自注意力的变形
3.1 多头注意力(multi-head)
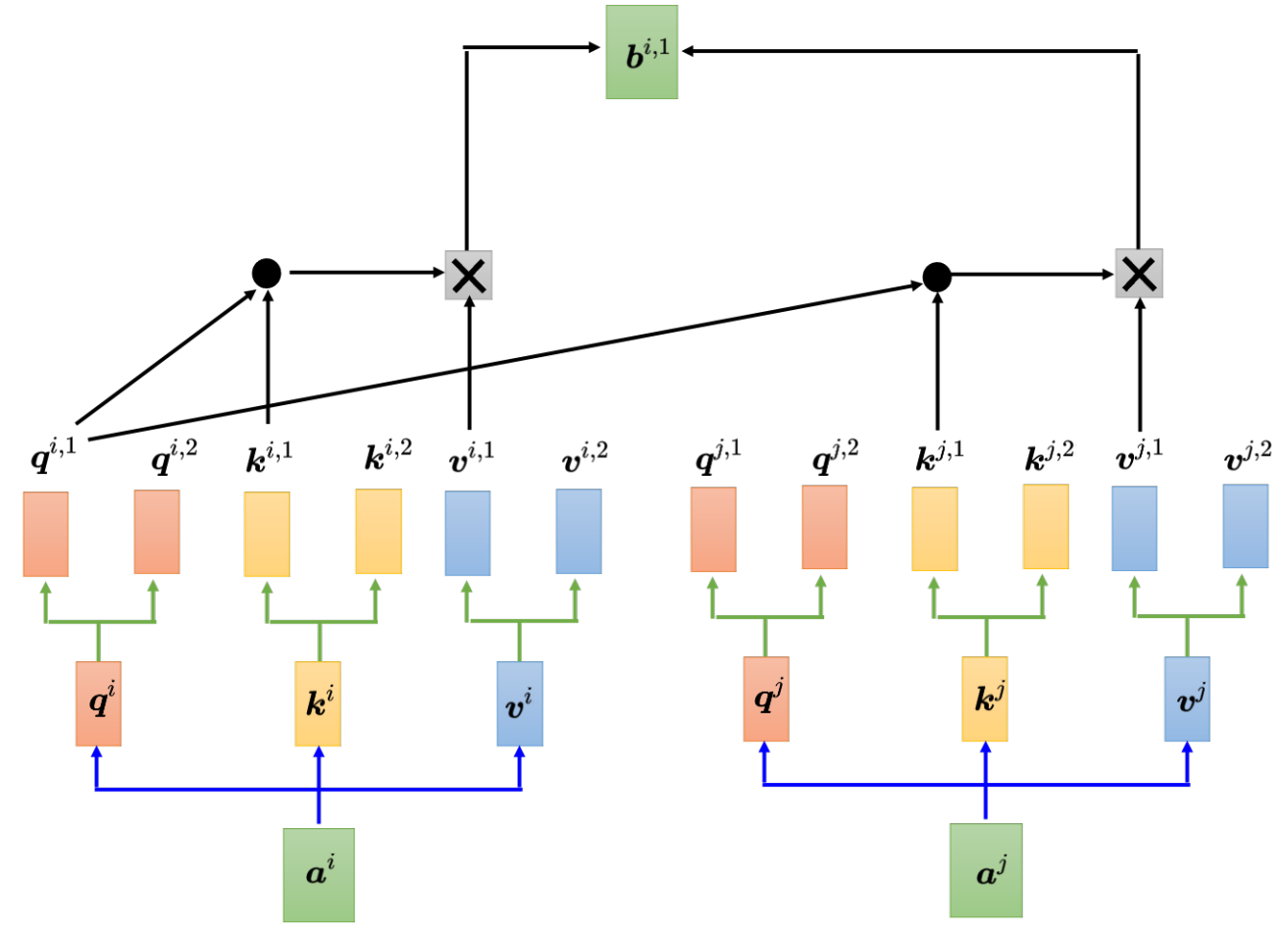
每个位置 多个q k v,类似CNN中的通道提取不同视觉特征,提取多种语义/语法特征
捕捉更多样、复杂的依赖关系。而且因为可以GPU并行计算 效率相近但建模能力显著提升
3.2 位置编码
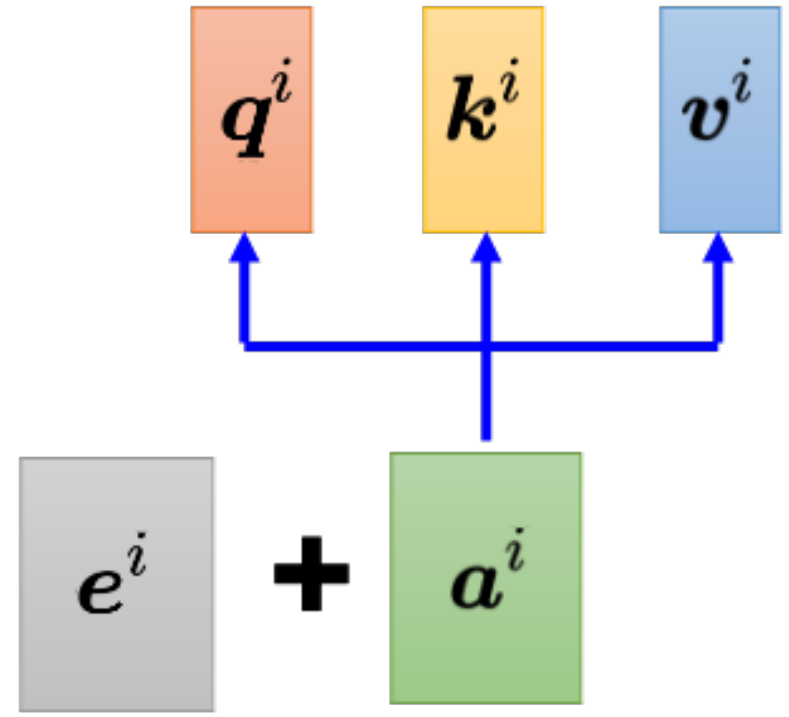
对于自注意力而言 注意力值与位置无关。但是像一段话中 词的位置也是很重要的信息。
比如说句首的词是动词的概率特别小。 实现方法为 在每个位置加一个专属的e。
3.3 截断自注意力(truncated)
原来的自注意力 是和整句话的所有发生关系。
如果一段话太长太长 可以设置一个范围,只看这个范围前后的。
3.4 与CNN对比
CNN 需要人为设定 滤波器、感受野;每个神经元仅考虑感受野内的信息。
自注意力 是自己去学习像素之间的关系,考虑身边哪些像素是相关的。
所以CNN可看做特殊的自注意力机制,作为有限制的模型,适合数据较小的时候使用。
而自注意力更灵活,需要更多的数据否则容易过拟合。
3.5 与RNN对比
1) 自注意力看全局,RNN只看左边的。Bi-RNN双向版本也看全局但仍有差异,因为自注意力在最右边 看最左边的词可以一步到位,而RNN需要从最左边一步一步将记忆(隐状态)传递过来。
2) 自注意力可以并行 而RNN需要传递串行 所以自注意力更高效。
自注意力也可运用在图的问题上 每个节点 连边就是需要有关系 连着边才计算注意力分数
4. Transformer架构
4.1 编码器 Encoder
add&norm加入残差连接的设计,对a自注意力算出b之后 b+a再层归一化
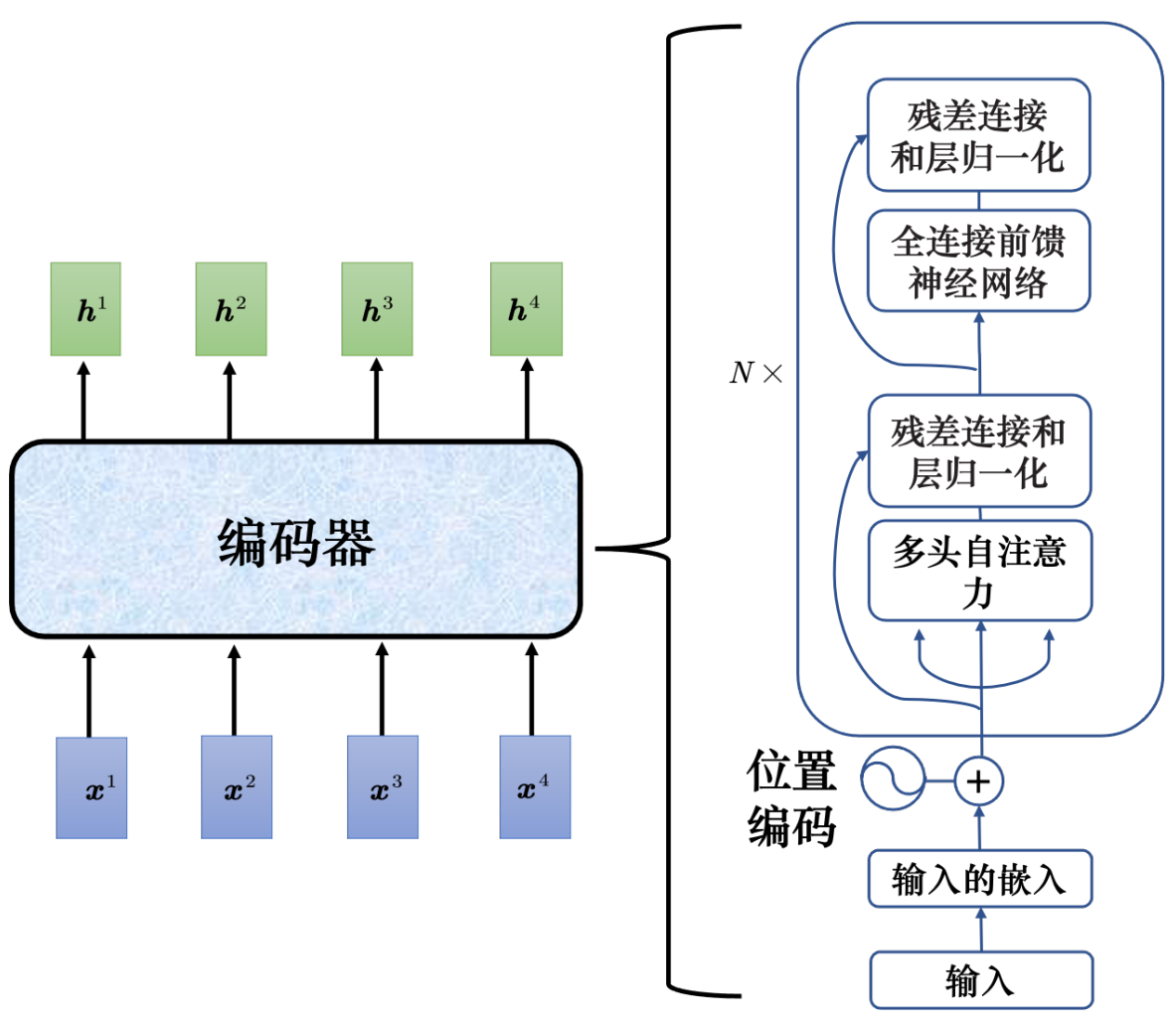
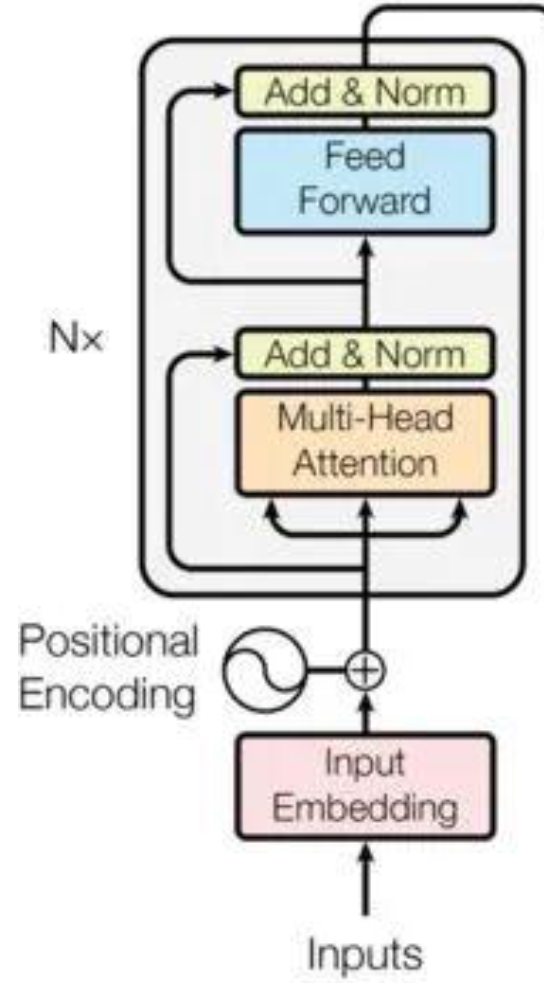
4.2 自回归解码器
先输入 <BOS>,输出 w1,再把 w1 当做输入,再输出 w2,直到输出 <EOS> 为止。
除了常规字符外还要 开始字符<BOS> 结束字符<EOS> 代表句子的开始和结束。
解码器就是在编码器的基础上 层的开始加上掩码自注意力(masked 因为输出是一个一个输出的 阻止每个位置选择其后面的输入信息)
最终目的是要输出下一个词 就对结果向量进行线性映射+softmax 找最大概率的那个
解码器多头注意力那里 是编码器和解码器的桥梁;K和V来自编码器,Q来自解码器的上一层
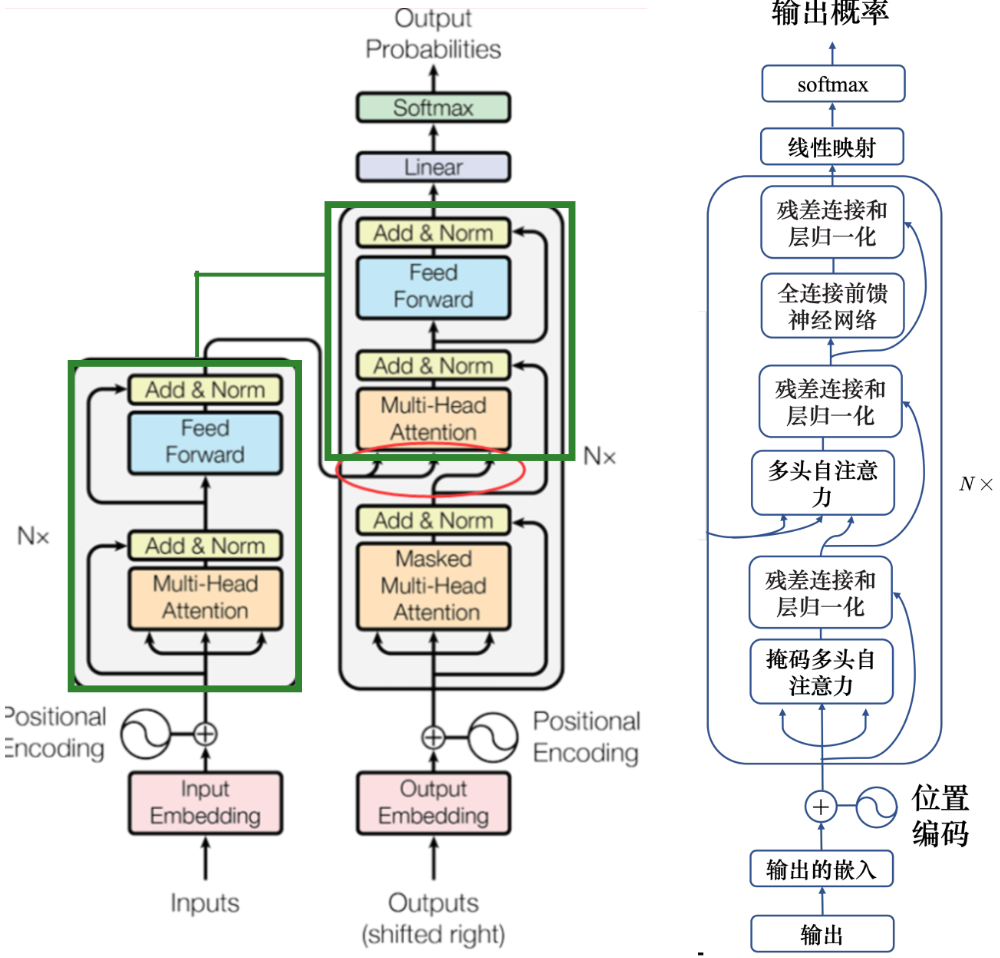
4.3 非自回归解码器
非自回归不是一次产生一个字,而是一次把整个句子都产生出来;给多少<BOS> 就输出多少字
优势1是可以做到并行输出 效率更高,但性能会差一些。
优势2是可以控制输出的长度。
5. Transformer训练过程与技巧
实际与期望结果向量的交叉熵(比如输入一段语音 期望输出“机器学习<EOS>”)
训练时用交叉熵,评估翻译结果时的标准是 解码器先产生一个完整的句子,再去跟正确的答案一整句做比较,两个句子算出 BLEU 分数(训练时不用BLEU因为计算复杂 且无法做微分)
1. 复制机制:解码器直接从输入中复制一些有用的东西
比如对话问题中,用户给的比较生僻的输入可以在回答中直接复制原问题里的词
比如段落摘要问题中,很多原文的词都可以直接复制信息
2. 引导注意力:当我们对一个问题有一定理解的时候 可以要求机器做注意力时以一定方向
如语音提取时让它从左到右效果更好 如果顺序胡乱结果就会有问题
3. 束搜索: 根据softmax的概率一个一个输出 这是贪心的思想,再往后延伸效果不一定好
如果要后面的效果好 穷举搜索 再分支往后看 分叉太多情况太多会导致也往后看不了多少
beam search束搜索 用于自回归生成任务(即每一步依赖前一步的输出)
维护一个有限的候选序列集合 平衡计算复杂度和结果质量,
在生成序列的每一步,不保留所有可能的候选,而是仅保留概率最高的 K 个。
4. 加入噪声/随机性:
训练时加噪声,让机器看过更多不同的可能性,让模型比较鲁棒,比较能够对抗它在测试的时候没有看过的状况。
测试的时候加一些噪声,用正常的解码的方法产生出来的声音听不太出来是人声,也不一定是最好的结果,产生比较好的声音需要一些随机性。
5. 计划采样(训练集加入错误 提高容错)
曝光偏差:训练时看到的是完全正确的 测试时解码器看到自己的输出 所以会看到一些错误信息。
如果看到错误信息 后面会出现不堪设想的一步错步步错,
比如“机器学习”的qi 输出成了 “气” 因为是串行一个一个生成的 所以后续跟着错很多。
所以我们考虑在训练集中 加一些错误的信息 期望使得它看到错误的信息 也能有一定容错。