音视频学习(四十四):音频处理流程
采集与数字化
将物理信号变成二进制数据。
一切都始于声音的捕捉。我们听到的声音其实是空气中振动产生的声波。麦克风就是捕捉这些声波的工具,它将声波的压力变化转换成相应的电压变化,形成模拟电信号。这个电信号是连续的、不间断的。
然而,计算机只能处理离散的、用0和1表示的数字信息。因此,我们需要一个“翻译官”——模数转换器(Analog-to-Digital Converter, ADC)。ADC的工作分为两步:
- 采样(Sampling): 这是第一步,也至关重要。采样就是以固定的频率,对连续的模拟信号进行“拍照”。这个“拍照”的频率就是采样率(Sample Rate),单位是赫兹(Hz)。根据奈奎斯特-香农采样定理,要完整地还原原始信号,采样率必须至少是信号最高频率的两倍。例如,人类能听到的最高频率约为20kHz,所以CD音质的采样率通常是44.1kHz,这保证了所有可听见的声音都能被捕捉。
- 量化(Quantization): 采样点只是一个瞬时的电压值,它仍然是连续的。量化就是将这些电压值映射到有限的整数值上。这个过程由**位深(Bit Depth)**决定,例如8位、16位或24位。位深越高,能表示的电压级数就越多,量化误差就越小,声音的动态范围就越大,听起来也越细腻。CD音质通常采用16位位深。
经过这两个步骤,我们就得到了由一系列整数组成的数字音频信号。这就是我们通常所说的“PCM(脉冲编码调制)”数据。
预处理
为模型“清理”数据。
原始的数字音频信号可能包含各种噪声和不一致性,就像一份没有整理过的原始数据。预处理就是为了消除这些问题,让数据更“干净”,更适合后续的分析。常见的预处理步骤包括:
- 分帧(Framing): 音频信号是时序的,但很多算法更适合处理短小的、相对稳定的数据片段。分帧就是将一个长长的音频信号切分成许多短小的帧,通常每帧的长度为10-30毫秒,并且帧之间会有一定程度的重叠(比如50%)。这样做可以捕捉到声音的局部特征,同时保证帧与帧之间的连续性。
- 加窗(Windowing): 分帧会产生一个问题:每一帧的开头和结尾处都有剧烈的截断,这会在频谱分析中引入不必要的失真(称为“频谱泄露”)。加窗就是通过一个“窗函数”(比如汉明窗、海宁窗)来平滑每一帧的开头和结尾,让信号从0开始,再回到0,从而减少这种失真。
- 去噪(Noise Reduction): 这是预处理的重要环节,目的是从音频中去除背景噪音。常见的去噪方法包括基于小波变换、谱减法或更复杂的深度学习模型,它们能识别并分离出我们想要的语音或音乐信号。
特征提取
将声音的本质量化。
预处理后的音频信号仍然是一系列离散的数值,对于计算机来说,直接处理这些原始数据效率很低。特征提取就是将这些原始数据转换成更紧凑、更有意义的数值表示,这些数值能更好地描述声音的本质。这是许多音频处理任务(如语音识别、音乐分类)成功的关键。
- 时域特征: 这些特征直接从音频波形上计算得到,反映了信号随时间的变化。例如:
- 短时能量(Short-Time Energy): 反映了每一帧声音的响度。
- 短时过零率(Short-Time Zero Crossing Rate): 反映了每一帧波形穿过零轴的次数,通常与音调的高低有关。
- 频域特征: 这些特征通过傅里叶变换将时域信号转换到频域,反映了不同频率成分的强度。这是分析声音音色和音调的关键。
- 短时傅里叶变换(STFT): 将每一帧信号都进行傅里叶变换,得到一个描述频率随时间变化的二维图,称为频谱图(Spectrogram)。频谱图是音频处理中最重要的可视化工具之一。
- 感知域特征: 这些特征更符合人类听觉的感知方式,因此在很多语音和音乐处理任务中表现更好。
- 梅尔频率倒谱系数(Mel-Frequency Cepstral Coefficients, MFCC): 这是语音处理中最常用的特征。它模仿了人耳对频率的非线性感知(人耳对低频更敏感),将频谱图映射到梅尔(Mel)刻度上,再进行一系列处理,最终得到一个紧凑的特征向量。MFCC非常适合描述语音的音色。
模型应用
让计算机理解声音。
有了提炼出的特征,我们就可以用各种模型来处理这些数据了。这个阶段是真正实现各种音频应用的核心。
- 语音识别(Speech Recognition): 将语音转换成文字。早期使用隐马尔可夫模型(HMM),现在则普遍采用基于循环神经网络(RNN)、长短期记忆网络(LSTM)和注意力机制的深度学习模型。
- 声学事件检测(Acoustic Event Detection): 识别声音中的特定事件,比如婴儿啼哭、玻璃破碎、警报声等。
- 音乐信息检索(Music Information Retrieval, MIR): 分析音乐的结构和内容,包括音乐流派分类、节奏识别、情感分析等。
- 声音合成(Speech Synthesis): 也叫文本转语音(Text-to-Speech, TTS),将文字转换成逼真的语音。
- 音频分离(Audio Source Separation): 从混合的音频信号中分离出不同的声音源,比如从一段有背景音乐的语音中提取出人声。
输出与回放
将数字信号变回声音。
经过模型的处理,我们可能得到了一些新的数字音频数据,比如去噪后的音频、合成的语音等。为了让人类再次听到这些声音,我们需要数模转换器(Digital-to-Analog Converter, DAC),它将数字信号反向转换成模拟电信号,再通过扬声器将电信号转换成声波,最终被我们听到。
音频数据流
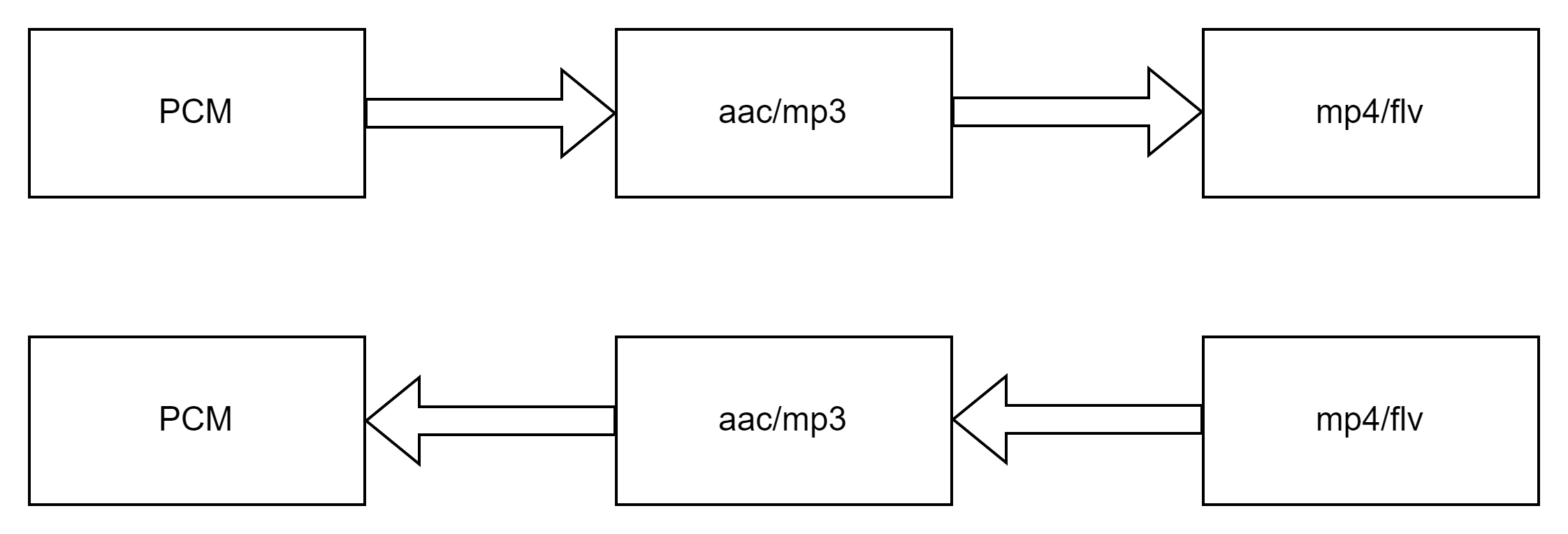
总结
音频处理是一个从物理振动到数字表示,再到智能理解和最终回放的完整闭环。它涉及信号处理、数学、计算机科学和人耳听觉心理学的交叉学科知识。从麦克风的物理捕捉,到ADC的数字化,再到复杂的特征提取和深度学习模型,每一个环节都扮演着不可或缺的角色,共同构成了这个将无形的声音世界变得可计算、可理解、可操控的过程。