【人工智能agent】--服务器部署PaddleX 的 印章文本识别模型

github地址:https://github.com/PaddlePaddle/PaddleX/blob/release/3.0-beta1/README.md
目录
简介
1.安装python环境
2.安装 PaddlePaddle
3.安装PaddleX
4.命令行的使用
编辑5.印章文本检测模
6.服务器上面docker安装
B方案--PaddleX 服务化部署指南编辑
简介
PaddleX 3.0 是基于飞桨框架构建的低代码开发工具,它集成了众多开箱即用的预训练模型,可以实现模型从训练到推理的全流程开发,支持国内外多款主流硬件,助力AI 开发者进行产业实践。
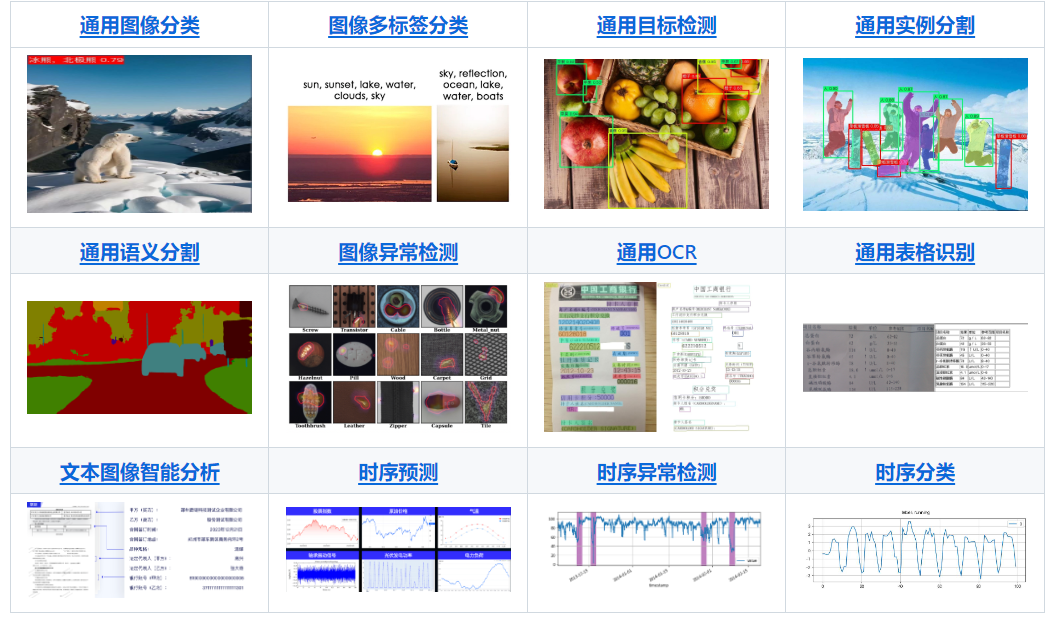
🎨 模型丰富一键调用:将覆盖文本图像智能分析、OCR、目标检测、时序预测等多个关键领域的 200+ 飞桨模型整合为 19 条模型产线,通过极简的 Python API 一键调用,快速体验模型效果。同时支持 20+ 单功能模块,方便开发者进行模型组合使用。
🚀 提高效率降低门槛:实现基于统一命令和图形界面的模型全流程开发,打造大小模型结合、大模型半监督学习和多模型融合的8 条特色模型产线,大幅度降低迭代模型的成本。
🌐 多种场景灵活部署:支持高性能部署、服务化部署和端侧部署等多种部署方式,确保不同应用场景下模型的高效运行和快速响应。
🔧 主流硬件高效支持:支持英伟达 GPU、昆仑芯、昇腾和寒武纪等多种主流硬件的无缝切换,确保高效运行。
🔠 模型产线说明
PaddleX 致力于实现产线级别的模型训练、推理与部署。模型产线是指一系列预定义好的、针对特定AI任务的开发流程,其中包含能够独立完成某类任务的单模型(单功能模块)组合。
| 模型产线 | 在线体验 | 快速推理 | 高性能推理 | 服务化部署 | 端侧部署 | 二次开发 | 星河零代码产线 |
|---|---|---|---|---|---|---|---|
| 通用OCR | 链接 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 文档场景信息抽取v3 | 链接 | ✅ | ✅ | ✅ | 🚧 | ✅ | ✅ |
| 通用表格识别 | 链接 | ✅ | ✅ | ✅ | 🚧 | ✅ | ✅ |
| 通用目标检测 | 链接 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 通用实例分割 | 链接 | ✅ | ✅ | ✅ | 🚧 | ✅ | ✅ |
| 通用图像分类 | 链接 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 通用语义分割 | 链接 | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| 时序预测 | 链接 | ✅ | 🚧 | ✅ | 🚧 | ✅ | ✅ |
| 时序异常检测 | 链接 | ✅ | 🚧 | ✅ | 🚧 | ✅ | ✅ |
| 时序分类 | 链接 | ✅ | 🚧 | ✅ | 🚧 | ✅ | ✅ |
| 小目标检测 | 🚧 | ✅ | ✅ | ✅ | 🚧 | ✅ | 🚧 |
| 图像多标签分类 | 🚧 | ✅ | ✅ | ✅ | 🚧 | ✅ | 🚧 |
| 图像异常检测 | 🚧 | ✅ | ✅ | ✅ | 🚧 | ✅ | 🚧 |
| 通用版面解析 | 🚧 | ✅ | 🚧 | ✅ | 🚧 | ✅ | 🚧 |
| 公式识别 | 🚧 | ✅ | 🚧 | ✅ | 🚧 | ✅ | 🚧 |
| 印章文本识别 | 🚧 | ✅ | ✅ | ✅ | 🚧 | ✅ | 🚧 |
| 通用图像识别 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 |
| 行人属性识别 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 |
| 车辆属性识别 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 |
| 人脸识别 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 | 🚧 |
1.安装python环境
❗安装 PaddleX 前请先确保您有基础的 Python 运行环境(注:当前支持Python 3.8 ~ Python 3.10下运行,更多Python版本适配中)。PaddleX 3.0-beta1 版本依赖的 PaddlePaddle 版本为 3.0.0b1。
conda create --name test_PaddleX python=3.10 //创建虚拟环境conda env list //所有环境conda activate test_PaddleX //激活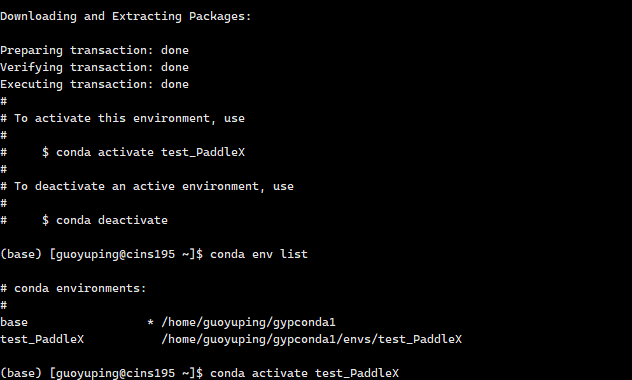
2.安装 PaddlePaddle
# cpu
python -m pip install paddlepaddle==3.0.0b1 -i https://www.paddlepaddle.org.cn/packages/stable/cpu/# gpu,该命令仅适用于 CUDA 版本为 11.8 的机器环境
python -m pip install paddlepaddle-gpu==3.0.0b1 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/# gpu,该命令仅适用于 CUDA 版本为 12.3 的机器环境
python -m pip install paddlepaddle-gpu==3.0.0b1 -i https://www.paddlepaddle.org.cn/packages/stable/cu123/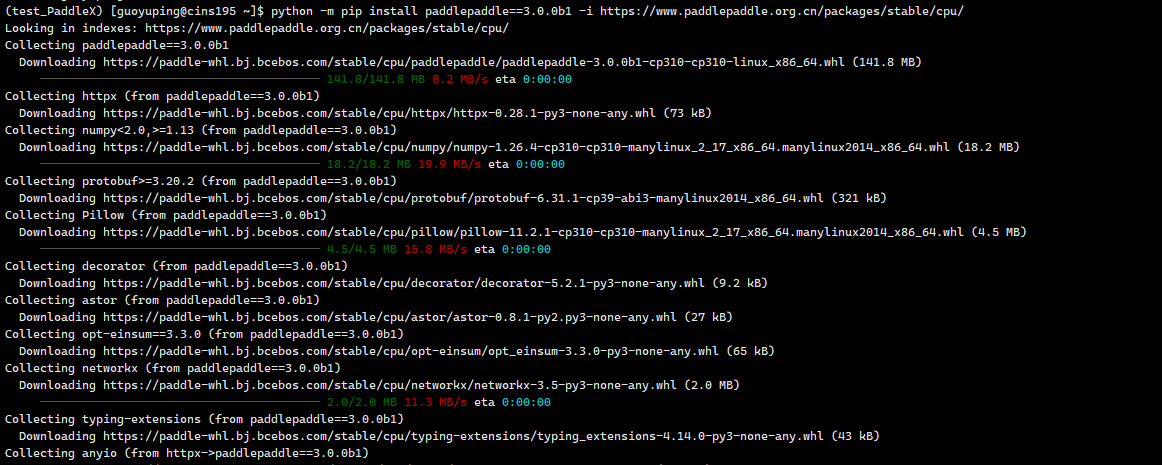
3.安装PaddleX
pip install https://paddle-model-ecology.bj.bcebos.com/paddlex/whl/paddlex-3.0.0b1-py3-none-any.whl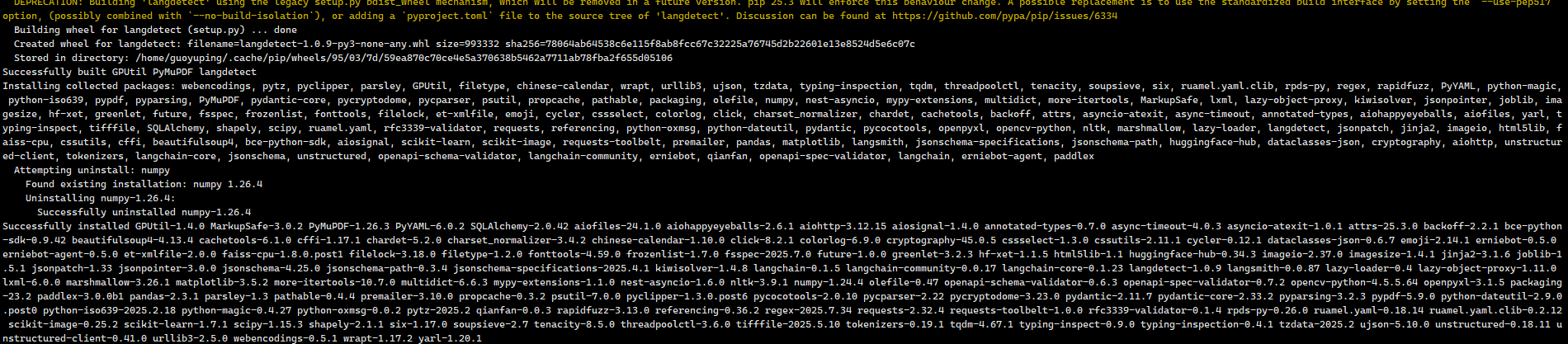
4.命令行的使用
一行命令即可快速体验产线效果,统一的命令行格式为:
paddlex --pipeline [产线名称] --input [输入图片] --device [运行设备]只需指定三个参数:
pipeline:产线名称input:待处理的输入文件(如图片)的本地路径或 URLdevice: 使用的 GPU 序号(例如gpu:0表示使用第 0 块 GPU),也可选择使用 CPU(cpu)
以通用 OCR 产线为例:
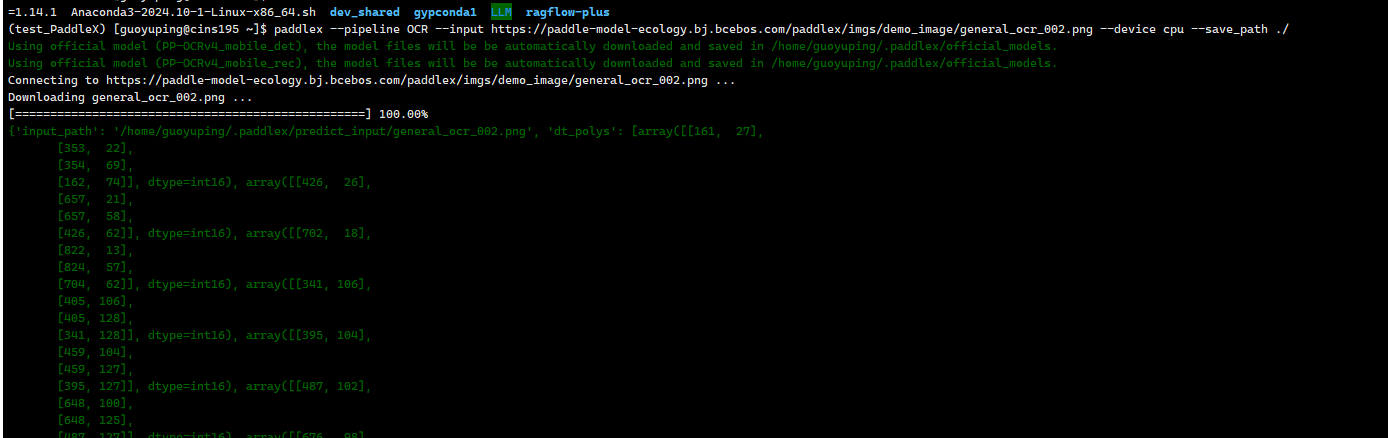
paddlex --pipeline OCR --input https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/general_ocr_002.png --device cpu --save_path ./
参数说明:
--pipeline:产线名称,此处为ocr测试
--input:待处理的输入图片的本地路径或URL
--device: 使用的GPU序号(例如gpu:0表示使用第0块GPU,gpu:1,2表示使用第1、2块GPU),也可选择使用CPU(--device cpu)
--save_path: 输出结果保存路径

 5.印章文本检测模
5.印章文本检测模
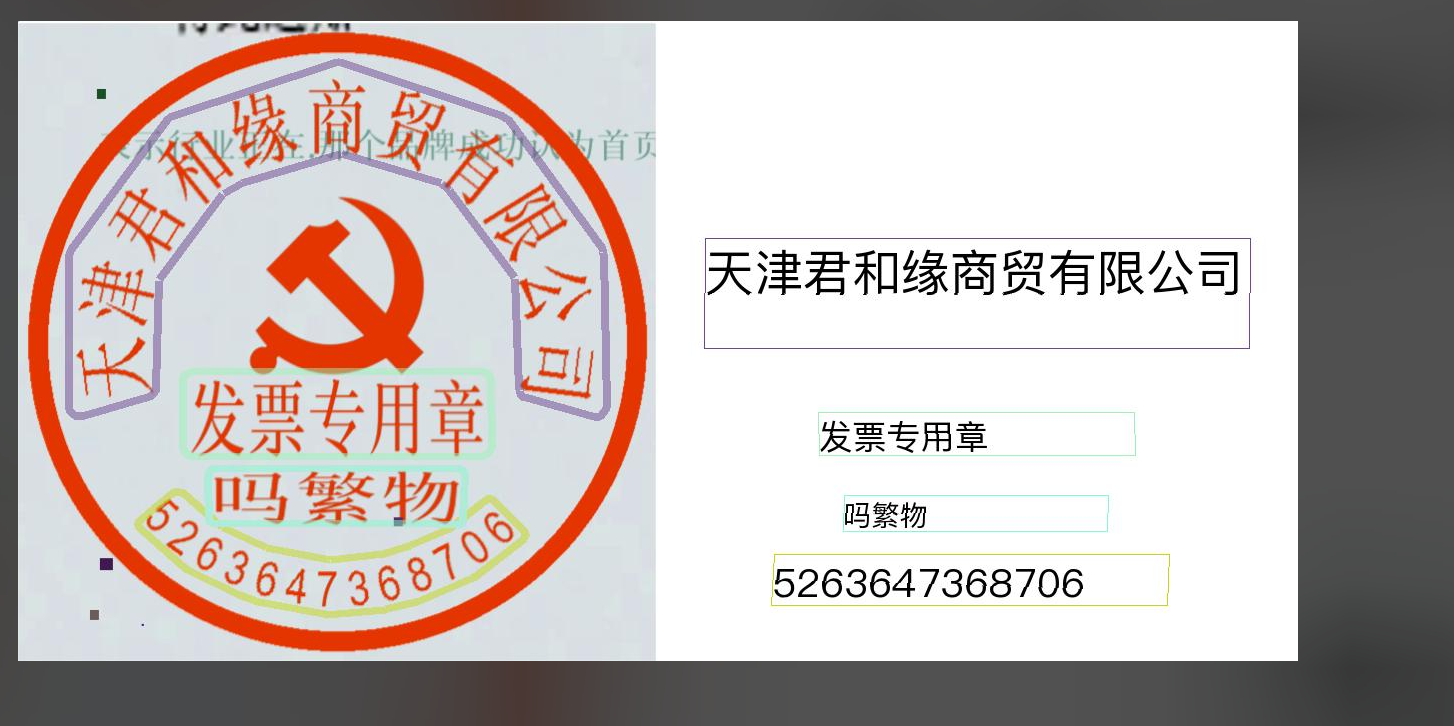
印章文本检测模块通常会输出文本区域的多点边界框(Bounding Boxes),这些边界框将作为输入传递给弯曲矫正和文本识别模块进行后续处理,识别出印章的文字内容。印章文本的识别是文档处理的一部分,在很多场景都有用途,例如合同比对,出入库审核以及发票报销审核等场景。印章文本检测模块是OCR(光学字符识别)中的子任务,负责在图像中定位和标记出包含印章文本的区域。该模块的性能直接影响到整个印章文本OCR系统的准确性和效率。
| 模型 | 检测Hmean(%) | GPU推理耗时(ms) | CPU推理耗时 (ms) | 模型存储大小(M) | 介绍 |
|---|---|---|---|---|---|
| PP-OCRv4_server_seal_det | 98.21 | 84.341 | 2425.06 | 109 | PP-OCRv4的服务端印章文本检测模型,精度更高,适合在较好的服务器上部署 |
| PP-OCRv4_mobile_seal_det | 96.47 | 10.5878 | 131.813 | 4.6 | PP-OCRv4的移动端印章文本检测模型,效率更高,适合在端侧部署 |
注:以上精度指标的评估集是自建的数据集,包含500张圆形印章图像。GPU 推理耗时基于 NVIDIA Tesla T4 机器,精度类型为 FP32, CPU 推理速度基于 Intel(R) Xeon(R) Gold 5117 CPU @ 2.00GHz,线程数为 8,精度类型为 FP32。
paddlex --pipeline seal_recognition \--input ./test7.31.png \--device cpu \--save_path ./
6.服务器上面docker安装
使用Linux安装PaddleX时,我们强烈推荐使用PaddleX官方Docker镜像安装,当然也可使用其他自定义方式安装。
当您使用官方 Docker 镜像安装时,其中已经内置了 PaddlePaddle、PaddleX(包括wheel包和所有插件),并配置好了相应的CUDA环境,您获取 Docker 镜像并启动容器即可开始使用。
当您使用自定义方式安装时,需要先安装飞桨 PaddlePaddle 框架,随后获取 PaddleX 源码,最后选择PaddleX的安装模式。
❗ 注:目前 PaddleX 仅支持 11.8 和 12.3 版本的 CUDA,请确保已安装的 Nvidia 驱动支持的上述 CUDA 版本。
若您使用的 Docker 版本 >= 19.03,请执行:
# 对于 CPU 用户
docker run -d \--name paddlex \--restart=always \--shm-size=8g \-v "$(pwd)":/paddle \-p 80:80 \ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/paddlex:paddlex3.0.0b1-paddlepaddle3.0.0b1-cpu \tail -f /dev/nulldocker run --name paddlex -v $PWD:/paddle --shm-size=8g --network=host -it ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/paddlex:paddlex3.0.0b1-paddlepaddle3.0.0b1-cpu /bin/bash# 对于 GPU 用户
# 对于 CUDA11.8 用户
docker run --gpus all --name paddlex -v $PWD:/paddle --shm-size=8g --network=host -it ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/paddlex:paddlex3.0.0b1-paddlepaddle3.0.0b1-gpu-cuda11.8-cudnn8.6-trt8.5 /bin/bash# 对于 CUDA12.3 用户
docker run --gpus all --name paddlex -v $PWD:/paddle --shm-size=8g --network=host -it ccr-2vdh3abv-pub.cnc.bj.baidubce.com/paddlex/paddlex:paddlex3.0.0b1-paddlepaddle3.0.0b1-gpu-cuda12.3-cudnn9.0-trt8.6 /bin/bash
docker ps -a
docker start paddlex # 启动容器
docker exec -it paddlex /bin/bash # 进入容器docker rm -f paddlex#移除容器打开容器的端口监听:
# 更新包列表
apt update# 安装 Nginx
apt install -y nginx# (可选)检查 Nginx 是否安装成功
nginx -v# 启动 Nginx
service nginx start# 或者使用
/etc/init.d/nginx start# 检查 Nginx 是否在运行并监听 80 端口
netstat -tuln | grep :80
# 或者
ss -tuln | grep :80
# 或者
ps aux | grep nginx
B方案--PaddleX 服务化部署指南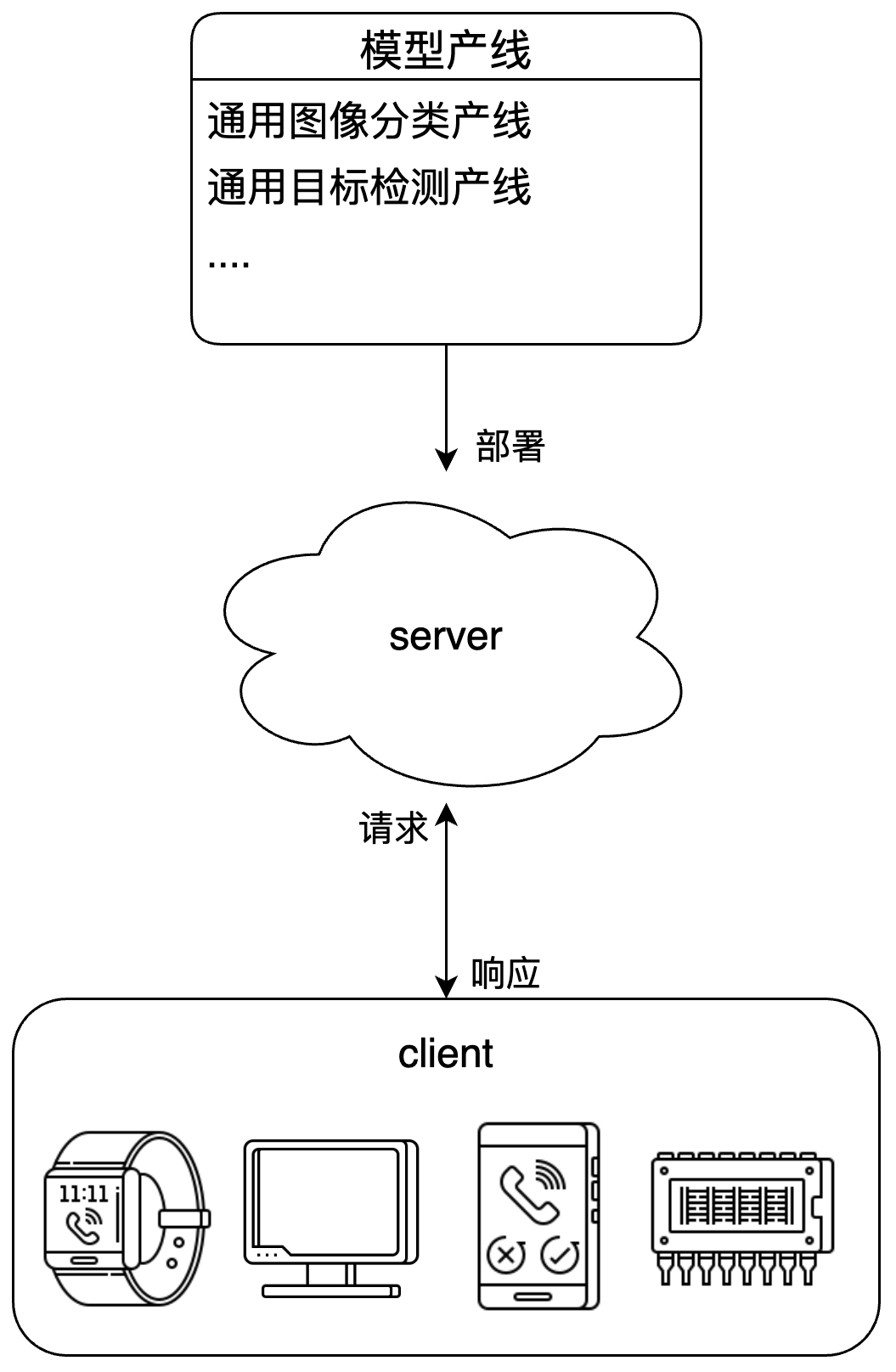
paddlex --install servingpaddlex --serve --pipeline {产线名称或产线配置文件路径} [{其他命令行选项}]以通用图像分类产线为例:
paddlex --serve --pipeline seal_recognition服务启动成功后,可以看到类似如下展示的信息:

| 名称 | 说明 |
|---|---|
--pipeline | 产线名称或产线配置文件路径。 |
--device | 产线部署设备。默认为 cpu(如 GPU 不可用)或 gpu(如 GPU 可用)。 |
--host | 服务器绑定的主机名或 IP 地址。默认为0.0.0.0。 |
--port | 服务器监听的端口号。默认为8080。 |
--use_hpip | 如果指定,则启用高性能推理插件。 |
--serial_number | 高性能推理插件使用的序列号。只在启用高性能推理插件时生效。 请注意,并非所有产线、模型都支持使用高性能推理插件,详细的支持情况请参考PaddleX 高性能推理指南。 |
--update_license | 如果指定,则进行联网激活。只在启用高性能推理插件时生效。 |
import base64
import requestsAPI_URL = "http://127.0.0.1:8080/seal-recognition" # 服务URL
image_path = "./印章.jpg"
layout_image_path = "./layout.jpg"# 对本地图像进行Base64编码
with open(image_path, "rb") as file:image_bytes = file.read()image_data = base64.b64encode(image_bytes).decode("ascii")payload = {"image": image_data} # Base64编码的文件内容或者图像URL# 调用API
response = requests.post(API_URL, json=payload)# 处理接口返回数据
assert response.status_code == 200
result = response.json()["result"]
with open(layout_image_path, "wb") as file:file.write(base64.b64decode(result["layoutImage"]))
print(f"Output image saved at {layout_image_path}")
print("\nDetected seal impressions:")
print(result["sealImpressions"])