C++音视频开发:基础面试题
音视频领域技术门槛高,学习资料稀缺,体系化书籍和开发工具有限,新手入门困难。
音视频开发涉及众多任务:音频(采集、编解码、降噪等)、视频(采集、编解码、图像处理)、实时传输(RTP/RTCP、RTMP、HLS)、存储与播放等,要求扎实的理论基础和工程经验,自学难度大。
本系列文章将围绕 “C++音视频流媒体高级开发面试题” 进行全面解析技术面试要点。由于篇幅限制,整个系列将分为多篇陆续发布,每篇为不同专题,本文为 第一篇 音视频基础面试题。
目录:
一、音频基础面试题
二、视频基础面试题
Part1音频基础面试题
1、声音采集的原理是什么,如何实现模数转换?
声音采集的基本原理涉及将自然界中的声波转换为电信号,再通过模数转换(ADC, Analog-to-Digital Conversion)将这些模拟信号转换为数字信号,以便计算机或其他数字设备进行处理。
声音采集的原理
麦克风捕捉声波:声音是一种机械波,它通过空气传播。当声波到达麦克风时,麦克风内部的膜片会根据声波的压力变化而振动。
声电转换:麦克风将膜片的机械运动转换成相应的电信号。不同类型的麦克风使用不同的机制来完成这个转换过程,如动圈式、电容式或驻极体等。
前置放大:由于从麦克风输出的电信号非常微弱,通常需要经过一个前置放大器来增强信号强度,以便后续处理。
滤波处理:为了去除可能干扰音频质量的不必要频率成分,通常会对信号进行滤波处理。
模数转换的实现
模数转换是将连续的模拟信号转换为离散的数字信号的过程,主要工作原理可以分为三个步骤:采样、量化和编码。
采样:按照一定的时间间隔对模拟信号进行测量,这个过程称为采样。采样的频率必须至少是原始信号最高频率的两倍(根据奈奎斯特-香农采样定理),以避免混叠现象的发生。
量化:将采样得到的每个样本值映射到最接近的可用数值上,这个过程会导致一定的误差,即量化噪声。选择更高的位深度可以减少这种噪声,提高音频质量。
编码:将量化的结果转化为二进制代码,以便于数字系统处理和存储。
2、为何高品质音频的采样率需达到 44.1KHz 及以上?
高品质音频采样率达到 44.1kHz(CD标准)及以上 的根本原因在于 奈奎斯特采样定理,但更深层次是为了无失真地捕捉人耳可听的全部频率范围,并为关键的抗混叠滤波提供设计余量。
人类对于音频信号听觉范围大致在20Hz到20kHz之间,为了捕捉到人耳能够听到的所有声音频率,采样率需要至少为20kHz的两倍,即40kHz。而44.1kHz作为一个标准值被广泛采用,
特别是在CD音质中,它不仅满足了奈奎斯特速率的要求,还提供了一些额外的空间来帮助简化抗混叠滤波器的设计(这种滤波器用于去除高于可接受范围的频率成分)。
选择44.1kHz作为标准还有历史原因,与早期数字音频系统的技术限制有关,包括视频记录设备的使用等。然而,随着技术的发展,现在有更高的采样率如48kHz、96kHz甚至192kHz被用于专业音频录制和回放,以进一步提高音质,尤其是在高端音频应用中。更高的采样率可以捕捉更精确的声音细节,并有助于减少数字化过程中可能出现的各种失真。
3、什么是 PCM(脉冲编码调制)?
PCM 是将模拟声音信号数字化最直接、最基础的方法,广泛应用于音频和电信领域。它通过采样(时间离散化)、量化(幅度离散化)和编码(二进制表示)三个步骤,将连续的声波转换为计算机可处理的 0 和 1 的序列。其核心参数是采样率(决定频率上限和时间精度)和位深度(决定动态范围和幅度精度)。作为未压缩的原始音频数据,PCM 提供了最高的保真度,是数字音频存储(如 WAV, AIFF, CD)、传输和处理的基石。后续的有损压缩(MP3, AAC)和无损压缩(FLAC, ALAC)都是在 PCM 的基础上进行的。
PCM 包含以下几个关键步骤:
采样:首先,模拟信号按照固定的时间间隔进行采样。根据奈奎斯特-香农采样定理,为了确保能够重建原始信号而不丢失信息,采样频率需要至少是信号最高频率的两倍。
量化:采样得到的数据值通常是一个连续范围内的数值,量化过程将这些值映射到一个有限数量的离散级别上。这个过程中会引入量化误差或称为量化噪声,它可以通过增加位深度(即每个样本使用的比特数)来减少。
编码:经过量化的样本值会被转换成二进制代码。编码不仅涉及到如何用二进制数表示量化后的值,还可能包括一些用于纠错或数据压缩的技术。
4、每个采样点需要用多少位来表示?
每个采样点所需的位数(即位深度或比特深度)决定了音频的动态范围和精度。常见的位深度包括:
16位(bit):这是CD音质的标准,提供了96dB的动态范围。这意味着它可以捕捉从非常安静到相对响亮的声音,足以满足大多数音乐和娱乐应用的需求。
24位:这种位深度常用于专业音频录制和处理,提供144dB的理论动态范围。更高的动态范围允许更精确地表示非常微小的声音细节以及更大范围的声音强度,适合需要高保真度的专业场合。
32位及更高:一些高端音频应用可能会使用32位甚至更高的位深度进行内部处理,以进一步提高精度和减少计算过程中的累积误差。不过,最终这些高分辨率的数据通常会被转换为较低位深度(如16位或24位)来分发给消费者,因为目前大部分消费级音频设备支持的最大位深度为24位。
位深度如何影响音质?
参数 | 影响 |
动态范围 | 每增加1位 ≈ 增加6dB动态范围(公式:动态范围(dB) ≈ 6.02 × 位深度 + 1.76) |
量化噪声 | 位深度越低 → 量化步长越大 → 本底噪声越高(听感为“沙沙声”) |
幅度精度 | 高位深度对小信号还原更精准(避免微弱细节被量化误差淹没) |
如何选择位深度?
应用场景 | 推荐位深度 | 理由 |
专业录音/混音 | 24-bit 或 32-bit | 保留最大动态余量,适配后期处理 |
CD/流媒体发布 | 16-bit | 符合消费端标准,文件体积适中 |
影视游戏音效设计 | 24-bit | 需处理极端动态(爆炸声+环境音) |
电话语音 | 8-bit (μ-law) | 压缩动态范围,优化带宽(实际使用对数量化) |
DSP内部处理 | 32-bit Float | 避免运算过程失真 |
5、采样值究竟该采用整数,还是浮点数?
这个问题其实隐含了多个子问题:整数和浮点数在音频处理中各有什么优劣?应用场景如何区分?为什么专业领域普遍用24-bit整数录音却用32-bit浮点数处理?
在音频开发中,采样值既可以使用整数也可以使用浮点数,具体选择取决于使用场景:
- 整数
(如 16-bit、24-bit)适合音频采集和播放,硬件兼容性好,占用资源少;
- 浮点数
(如 32-bit float)更适合音频处理阶段,动态范围大、精度高,能避免溢出和精度丢失;
实际开发中通常会结合使用,采集时用整数,处理时转为浮点,最终输出再转回整数。
核心区别与适用场景
特性 | 整数(如 16/24-bit) | 浮点数(32-bit Float) |
动态范围 | 有限(16-bit≈96dB,24-bit≈144dB) | 理论上无限(实际≈1500dB) |
超0dBFS处理能力 | ❌ 超过最大值直接削波(Clipping) | ✅ 可安全记录超0dBFS的信号(如+6dB) |
量化误差分布 | 全范围固定步长,小信号精度低 | 小信号精度高(对数分布特性) |
存储/带宽开销 | 较低(24-bit=3字节/采样点) | 较高(32-bit=4字节/采样点) |
硬件支持 | ✅ 所有ADC芯片、DAC芯片原生支持 | ❌ ADC/DAC需转换(实际硬件处理仍用整数) |
适用阶段 | 原始录音 & 最终分发 | 音频处理中间环节 |
为什么不同阶段需要不同格式?
1. 录音/采集阶段 → 必须用整数(24-bit为主)
物理限制: ADC(模数转换器)芯片硬件输出的是离散整数值,这是物理电路的量化结果。
动态范围优化: 24-bit整数提供≈144dB动态范围,远超高质量模拟设备本底噪声(-120dB),保留完整信号。
示例: 录制交响乐时,24-bit可同时捕捉细微的三角铁声(-50dB)和强烈的定音鼓(0dB)。
2. 音频处理阶段(DAW/混音) → 强烈推荐浮点数(32-bit Float)
防削波: 混音时叠加多个轨道易超0dBFS(如:鼓+贝斯+人声)。浮点允许临时超载,保留原始数据。
高精度运算: EQ、压缩等效果器涉及乘法运算,浮点减少舍入误差(避免“位数衰减”)。
灵活调参: 增益调整±20dB无需担心失真(整数需谨慎控制电平)。
关键决策因素
因素 | 选整数 | 选浮点数 |
直接连接ADC/DAC硬件 | ✅ 必须 | ❌ 不支持 |
处理多轨道/复杂效果链 | ❌ 易导致削波 | ✅ 首选(DAW内部格式) |
存储空间/带宽敏感 | ✅ 更紧凑(16-bit比32-bit小50%) | ❌ 体积大 |
需超0dBFS记录 | ❌ 不可能 | ✅ 唯一选择(如录制突发爆炸声) |
嵌入式设备(低算力) | ✅ 整数运算更快更省电 | ❌ 浮点计算开销大 |
6、音量大小与采样值之间存在怎样的关系?
音量大小与采样值之间的关系主要体现在音频信号的振幅上。在数字音频中,每一个采样值代表了音频波形在某一时刻的振幅大小。采样值越大(无论是正值还是负值),音频的振幅就越高,对应的主观听感就是音量越大。
具体来说:
振幅决定音量:采样值的绝对值越大,表示波形振幅越高,声音就越响亮。例如,在16位PCM中,采样值范围是-32768到32767,越接近这两个极限值,声音就越响。
增益控制的本质:我们可以通过对采样值进行乘法运算来调整音量。例如,将所有采样值乘以一个大于1的系数,可以提升音量;乘以一个小于1的系数,则降低音量。但需要注意避免溢出或削波失真。
浮点与整数表示的影响:在浮点数格式(如32-bit float)中,采样值通常归一化在[-1.0, 1.0]之间,便于进行音频处理。而在整数格式中,动态范围受限于位深度,因此在进行音量放大时更容易达到最大值而导致失真。
标准化与动态范围:在音频后期处理中,我们经常会对采样值进行归一化处理,使最大采样值达到满刻度(如0dBFS),从而充分利用动态范围,提高整体音量。
7、通常多少个采样点构成一帧数据?
从技术角度看,一帧(Frame)包含的采样点数没有绝对标准,其数量由 应用场景、系统设计需求和硬件限制 共同决定。
核心影响因素
因素 | 对帧大小的影响 | 典型场景示例 |
延迟要求 | 低延迟场景 → 小帧(更少采样点) | 实时通话、直播(10-30ms) |
算法处理需求 | 特定算法需固定帧长(如FFT要求2^N点) | 音频编解码(AAC:1024点) |
硬件缓冲区限制 | 匹配DMA传输块大小/内存对齐 | 嵌入式设备(64/128点) |
文件/网络协议封装 | 按协议定义帧结构(如MP3固定1152点) | 媒体容器(WAV无帧概念) |
行业常见帧大小参考
1. 实时音频流(低延迟优先)
采样率 | 帧时长 | 单通道采样点数 | 应用场景 |
48 kHz | 10 ms | 480 | VoIP、游戏语音 |
44.1 kHz | 20 ms | 882 | 直播推流 |
16 kHz | 30 ms | 480 | 电话会议 |
📌 为什么是这些值?
10ms帧:人耳可感知延迟的临界点(≤20ms无感)
480点:48kHz÷1000ms×10ms=480,计算直观
2. 音频编解码(算法固定帧)
编码格式 | 单帧采样点数 | 说明 |
AAC-LC | 1024 | 标准帧长,平衡延迟与压缩率 |
OPUS | 2.5-120ms可变 | 动态调整(默认20ms@48kHz=960点) |
MP3 | 1152 | MPEG标准固定值 |
G.711 | 80/160 | 传统电话编码(10ms/20ms) |
3. 硬件/驱动层(内存对齐优化)
系统平台 | 典型帧大小 | 设计原因 |
ALSA (Linux) | 256/512/1024 | 匹配DMA缓冲区大小(2^N对齐) |
Core Audio (macOS) | 64-1024可调 | 低延迟优先,默认256点 |
嵌入式DSP | 32/64/128 | 减少内存占用,适配缓存行 |
8、左右声道的采样数据又是如何排列的?
在音频处理中,立体声的左右声道数据主要有两种排列方式:
第一种是 交错排列(Interleaved),也就是左右声道的数据是交替存放的。比如一个立体声PCM音频,它的采样数据可能是这样排的:左声道第一个采样点,接着是右声道第一个采样点,然后是左声道第二个,再右声道第二个,依此类推。这种格式在音频播放和文件格式中非常常见,比如WAV文件默认就是这种格式,处理起来也比较直观。
第二种是 平面排列(Planar),也就是把左声道和右声道的数据分开存储。比如先把所有左声道的采样点放在一起,然后再放所有右声道的采样点。这种方式在音频处理中比较常见,比如在FFmpeg或者一些音频算法中,处理起来效率更高,特别是当你只想单独处理某一个声道的时候。
在音视频开发中,交错排列是存储和传输的主流标准,因为它结构紧凑,符合硬件和文件的自然组织方式。而平面排列是专业音频处理的“好帮手”,因为它让单声道数据的访问更连续,计算效率更高。实际开发时,我们常需要根据使用的API、库或硬件的要求,在两者之间进行转换。
9、音频编码的基本原理是什么?
音频编码的基本原理是将模拟音频信号转换为数字信号,并通过压缩技术减少数据量,便于存储和传输。
主要流程包括:
采样和量化:把声音从连续的模拟信号转为离散的数字信号;
PCM 编码:最原始的编码方式,数据量大但音质保留完整;
压缩处理:分为无损(如 FLAC)和有损(如 MP3、AAC)两种方式;
心理声学模型:用于有损编码,去掉人耳不敏感的声音信息;
变换编码(如 FFT):将信号转为频率域,提高压缩效率。
最终目标是在音质和压缩率之间取得平衡。
Part2视频基础面试题
1、RGB 色彩模式背后的原理是什么?
RGB模式通过独立控制红、绿、蓝三种色光的强度并进行叠加混合,在发光设备(屏幕)上再现人眼可见的各种颜色,其数值表示定义了每个像素点的具体颜色。它是数字成像和显示技术的核心基础。
生理基础:RGB模拟人眼三种视锥细胞(红/绿/蓝)感光特性。
混合原理:加色法 - 通过混合不同强度的红、绿、蓝光产生其他颜色(红+绿=黄,三色全开=白)。
数字表示:每种原色的强度用数值表示(如8位:0-255),一个像素颜色由
(R, G, B)三元组定义。位深度:决定每种颜色有多少级亮度(8位=256级)。
色彩空间:定义了R/G/B三原色的具体标准和白点(如sRGB, Adobe RGB)。
硬件实现:显示设备的物理像素由红、绿、蓝子像素构成,直接受RGB数值控制。
2、为什么在视频处理中,YUV 格式被广泛应用?
YUV 被广泛用于视频处理,主要有四个原因:
- 符合人眼感知
:人眼对亮度(Y)更敏感,对色度(U/V)敏感度低,便于压缩时减少色度数据而不影响观感;
- 利于压缩
:支持色度子采样(如 4:2:0),大幅减少数据量,提升编码效率;
- 兼容性强
:历史原因,很多视频标准(如 MPEG、H.264/265)都基于 YUV 设计。
编码优化:便于视频压缩算法处理,节省带宽和存储空间
YUV 通过 分离亮度与色度 + 智能降低色度分辨率,在几乎不损失人眼感知画质的前提下,大幅压缩视频数据量,是效率与观感的最佳平衡。
3、什么是像素,它在视频成像中扮演着怎样的角色?
像素(Pixel) 是图像显示的基本单位,是“图片元素”的简称。每个像素都是一个带有特定颜色和亮度值的小点,当大量这样的点按照一定的排列组合在一起时,就形成了我们看到的图像。在数字图像中,每一个像素的颜色通常由红(R)、绿(G)、蓝(B)三原色的不同强度组合而成。可以说像素是视频成像的基石,它的数量和颜色数据共同定义了画面的细节与色彩。
在视频中,像素的作用主要有:
- 构成画面
:视频由一帧帧图像组成,每帧由大量像素排列组成;
- 决定分辨率
:像素数量越多(如1920x1080),画面越清晰;
- 影响画质
:像素的颜色深度(如8bit、10bit)决定色彩丰富度;
- 影响压缩和传输
:像素越多,视频数据量越大,对编码和带宽要求越高。
4、分辨率、帧率、码率各自代表什么含义,它们之间又有怎样的关联?
分辨率:画面清晰度(像素数量,如1920x1080)。越高越清晰。
帧率:动作流畅度(每秒帧数/FPS,如30fps)。越高越流畅。
码率:数据量/带宽成本(每秒数据量/Mbps)。越高画质潜力越大,文件也越大。
三者的关系:
分辨率越高、帧率越高,数据量越大,需要更高的码率来保证画质;
在码率有限的情况下,提高分辨率或帧率可能会导致画面压缩过度、出现模糊或卡顿;
实际应用中,需要根据带宽和设备性能做权衡,比如直播会优先控制码率,本地播放可支持更高分辨率和帧率。
5、YUV 数据有哪些不同的存储格式,这些格式之间存在哪些差异?
YUV 数据的主要存储格式差异集中在两点:色度采样比例 和 内存排列方式
1. 色度采样比例
- YUV444
:每个像素都有独立的Y、U、V值,不进行任何子采样,提供最高质量。
- YUV422
:水平方向上色度子采样,每两个亮度样本共享一组色度样本,减少一半的色度信息。
- YUV420
:在水平和垂直方向上都进行色度子采样,每四个亮度样本共享一组色度样本,适合大多数应用场景,如H.264编码。
2. 内存排列方式
- Planar(平面)格式
:像I420这样的格式,将Y、U、V三个分量分别连续存储在一个平面上,便于某些类型的图像处理操作。
- Semi-planar(半平面)格式
:例如NV12或NV21,先存放全部的Y值,接着是交错的U和V值,这种格式有利于现代GPU加速处理,因为可以更高效地访问Y和UV数据。
- Packed(打包)格式
:比如YUYV或UYVY,亮度和色度值交错存储于同一行中,虽然占用更多内存但可能简化了某些硬件实现。
6、YUV 数据在内存对齐时,需要注意哪些问题?
1、起始地址对齐:
YUV 缓冲区的首地址必须按硬件要求对齐(通常 16/64/128 字节),避免访问异常或性能暴跌。
👉 操作:使用 aligned_alloc 等函数显式分配内存。
2、行跨距对齐 (Stride):
每行数据的实际字节数(Stride)需 ≥ 图像宽度字节数,并填充至对齐粒度(如 16/64 字节)。
必须用 Stride 而非图像宽度访问数据!
👉 原因:适配内存访问粒度,提升 SIMD/GPU 效率。
3、色度分辨率对齐:
对于
4:2:0/4:2:2格式,图像宽高必须是偶数(如 1920x1080✅,1921x1081❌)。U/V 平面需独立满足地址和 Stride 对齐(分辨率虽为 Y 的 1/2,对齐要求相同)。
👉 原因:防止色度采样错位导致的颜色异常(如绿屏)。
4、平台差异适配:
不同硬件(CPU/GPU/编解码芯片)或平台(Windows/iOS/Android)可能有特殊对齐要求(如 NVIDIA 要求 128 字节),需查阅文档适配。
7、画面出现绿屏现象的原因是什么?
绿屏现象在视频播放或处理过程中是一个比较常见的问题,其可能的原因有多种。以下是一些主要的可能原因:
编码格式不支持或解码错误:如果视频文件采用了一种播放器或处理软件不完全支持的编码格式,或者在解码过程中出现了错误,可能会导致显示异常,例如出现绿屏。
硬件加速问题:一些播放器使用硬件加速来提高性能,但如果硬件加速配置不正确,或者使用的显卡驱动程序有问题,可能导致视频无法正常渲染,进而出现绿屏。
内存对齐和数据损坏:在视频处理过程中,如果YUV等视频帧数据没有正确地进行内存对齐,或者数据在传输、处理过程中发生了损坏,也可能导致显示异常如绿屏。
色彩空间转换错误:视频帧通常需要从一种色彩空间(如YUV)转换到另一种色彩空间(如RGB)以便于显示。如果这个转换过程发生错误,比如参数设置不对,也可能导致显示异常。
源文件损坏:如果视频源文件本身已经损坏,无论是由于下载不完整、存储介质故障还是其他原因,都可能导致播放时出现问题,包括绿屏现象。
软件兼容性问题:有时特定版本的播放软件与操作系统或其他软件之间可能存在兼容性问题,这也可能是造成绿屏的原因之一。
解决这些问题通常涉及到检查并更新软件、确保编解码器正确安装、调整播放器设置(如关闭硬件加速)、验证源文件完整性等方面。根据具体情况的不同,解决方案也会有所不同。
8、H264 编码的工作原理是什么?
H.264通过 帧类型划分(I/P/B)→ 智能预测(帧内/帧间)→ 残差变换量化 → 熵编码 四步曲,在时间(运动预测)、空间(纹理预测)、频率(能量集中)、统计(概率编码)四个维度压缩冗余,实现高效编码。其核心是以计算换带宽,平衡效率与画质。
它的基本工作原理包括以下几个关键步骤:
帧类型划分:分为 I 帧(关键帧)、P 帧(前向预测帧)、B 帧(双向预测帧),利用帧与帧之间的相关性减少冗余数据。
宏块处理:将每一帧划分为 16x16 的宏块,作为编码的基本单元。
帧内/帧间预测:
帧内预测:利用当前帧内部已编码区域预测当前宏块。
帧间预测:通过运动估计和运动补偿,用参考帧预测当前帧内容,只编码差异部分。
变换与量化:对预测后的残差进行 DCT 变换和量化,压缩数据量。
熵编码:使用 CAVLC 或 CABAC 对量化后的数据进一步压缩。
去块滤波:减少块效应,提升图像质量。
9、H264 编码中的 I 帧、P 帧、B 帧之间存在怎样的关系?
依赖关系(谁需要谁?)
帧类型 | 依赖对象 | 可否独立解码? | 示例 |
I 帧 | 不依赖任何帧 | ✅ 是(关键帧) | 视频开头、场景切换点 |
P 帧 | 依赖前一帧(I 或 P 帧) | ❌ 否 | 参考前一帧预测运动物体 |
B 帧 | 依赖前后帧(I/P 帧) | ❌ 否 | 参考前后帧插值中间动作 |
- 解码顺序 ≠ 播放顺序:
B 帧需等待后续参考帧解码完成,因此传输顺序为:
I → P → B 但播放顺序为 I → B → P
例:播放顺序 I1, B2, B3, P4,传输顺序 I1, P4, B2, B3
压缩效率对比
帧类型 | 数据量 | 压缩原理 | 适用场景 |
I 帧 | 最大(100%) | 帧内预测 + 变换量化(类似JPEG) | 场景切换、随机访问 |
P 帧 | 中等(≈I帧30%) | 单向运动补偿 + 残差编码 | 普通运动画面 |
B 帧 | 最小(≈I帧10%) | 双向运动补偿 + 更小残差 | 慢动作、渐变镜头 |
✅ 压缩率排序:B帧 > P帧 > I帧
⚠️ 代价:B帧增加编解码延迟(需缓存前后帧)
协作模式
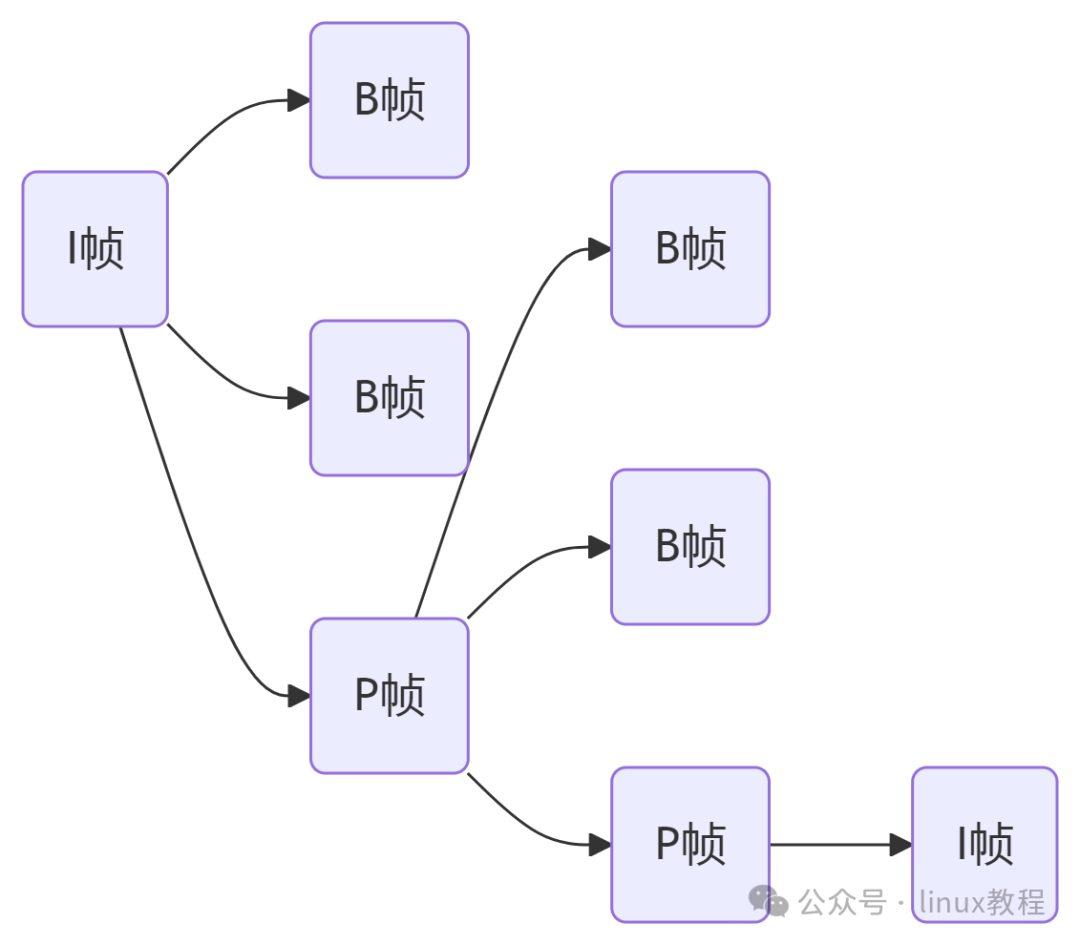
工程中的关键影响
设计选择 | 对帧类型的影响 | 应用案例 |
GOP长度 | I帧间隔越长 → 压缩率越高,但随机访问延迟越大 | 直播:GOP短(1-2s) |
B帧数量 | B帧越多 → 压缩率越高,编解码延迟越大 | 实时通话:禁用B帧 |
参考帧数量 | P帧可参考前多帧 → 提升遮挡场景精度 | 运动镜头:多参考帧 |
本期面试题就更新到这里了,下期更新解复用以及FFmpeg相关面试题~
点击下方关注【Linux教程】,获取编程学习路线、项目教程、简历模板、大厂面试题pdf文档、大厂面经、编程交流圈子等等。