Pytorch-02数据集和数据加载器的基本原理和基本操作
1. 为什么要有数据集类和数据加载器类?
一万个人会有一万种获取并处理原始数据样本的代码,这会导致对数据的操作代码标准不一,并且很难复用。

为了解决这个问题,Pytorch提供了两种最基本的数据相关类:
torch.utils.data.Dataset: 一个数据集对象,包含每个数据样本路径以及对应标签torch.utils.data.DataLoader:持有一个对Dataloader的迭代器,通过调用Dataset的__getitem__函数方便地获取实际的样本-标签对。
PyTorch 为不同的任务类型提供了方便的预加载数据集,例如 torchvision.datasets、torchaudio.datasets 等。这些数据集都是 torch.utils.data.Dataset 的子类,可以直接通过
dataset.数据集名称的方式来方便的下载经典的数据集,在下面你会看到它的使用例。
2. Dataset类的使用方法
2.1 加载一个Fashion-MNIST数据集
Fashion-MNIST 是一个来自 Zalando 的文章图像数据集,包含 60,000 个训练样本和 10,000 个测试样本。每个样本由一张 28×28 的灰度图像和其对应的 10 个类别中的一个标签组成。
这是一个使用TorchVision的预加载数据集类加载Fashion-MNIST 数据集的例子,如下是每个参数代表的意思:
- root:是存储训练/测试数据的路径。
- train:指定是训练数据集还是测试数据集。
- download=True:如果数据在 root 路径下不可用,则从互联网下载。
- transform 和 target_transform:分别指定特征和标签的转换。
import torch
from torchvision import datasets
from torchvision.transforms import ToTensor
import matplotlib.pyplot as plttraining_data = datasets.FashionMNIST(root="data", # 指定数据集实际存放的路径(相对于本代码文件)train=True, # 指定这是训练集还是测试集download=True, # 如果在root下没有数据,从网络上自动下载transform=ToTensor() # 给每一张图片转换为Tensor的数据类型
)test_data = datasets.FashionMNIST(root="data", # 指定数据集实际存放的路径(相对于本代码文件)train=False, # 指定这是训练集还是测试集download=True, # 如果在root下没有数据,从网络上自动下载transform=ToTensor() # 给每一张图片转换为Tensor的数据类型
)

2.2 遍历并可视化数据集
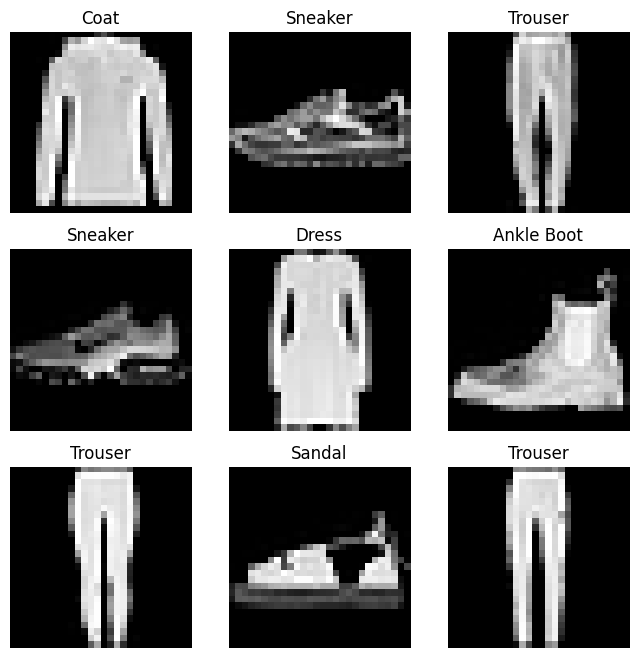
我们可以简单的使用training_data[index]来获取Datasets类中对应index的样本。通常可以用matplotlib来可视化我们的一些训练数据集:
labels_map = { # 定义一个标签映射字典0: "T-Shirt",1: "Trouser",2: "Pullover",3: "Dress",4: "Coat",5: "Sandal",6: "Shirt",7: "Sneaker",8: "Bag",9: "Ankle Boot",
}figure = plt.figure(figsize=(8, 8)) # 创建一个新的画布,大小为8x8英寸
cols, rows = 3, 3 # 定义展示网格尺寸 3x3的展示网格,每个网格展示i一个图片for i in range(1, cols * rows + 1): # plt的索引从1开始,配合一下sample_idx = torch.randint(len(training_data), size=(1,)).item() # 生成一个包含1个元素的张量,item()回python数据类型之后为0到数据集大小-1的随机整数img, label = training_data[sample_idx] # 本质上是在调用__getitem__函数figure.add_subplot(rows, cols, i) # 在之前创建的图形窗口中,添加一个子图(subplot),并将当前的画笔操作对象设置为当前子图plt.title(labels_map[label]) # 子图的标题设置为对应的标签字符串plt.axis("off") # 不显示坐标轴plt.imshow(img.squeeze(), cmap="gray") # 把当前网格画好
plt.show() # 展示画布
这里我并不知道为啥要使用img.squeeze()这个方法, 直到我把img的shape的打印出来:

现在img是一个3维的tensor,但是plt.imshow需要输入二维的tensor,所以使用squeeze的目的是把所有的尺寸为1的维度给挤压掉,将img维度降维到2维,然后就可以用plt可视化了。
2.3 进阶:如何制作一个自己的数据集类
自定义的 Dataset 类必须实现三个函数:__init__、__len__ 和 __getitem__。请看下面的实现示例:FashionMNIST 图像存储在 img_dir 目录中,而它们的标签则单独保存在 annotations_file 的 CSV 文件里。
import os
import pandas as pd
from torchvision.io import decode_imageclass CustomImageDataset(Dataset):def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):self.img_labels = pd.read_csv(annotations_file)self.img_dir = img_dirself.transform = transformself.target_transform = target_transformdef __len__(self):return len(self.img_labels)def __getitemm__(self, idx):img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0]) # iloc全写为“integer location”, 表明你要通过数据的行和列的整数索引来选择数据image = decode_image(img_path)label = self.img_labels.iloc[idx, 1]if self.transform:image = self.transform(image)if self.target_transform:label = self.target_transform(label)return image, label在接下来的部分将详细解释每个方法的作用。
__init__
def __init__(self, annotations_file, img_dir, transform=None, target_transform=None):self.img_labels = pd.read_csv(annotations_file)self.img_dir = img_dirself.transform = transformself.target_transform = target_transform
这个方法会在初始化数据集的时候调用。其主要完成如下工作:
- 读取标签文件
- 指定图片文件夹路径
- 指定样本和标签的transform(这个下面细讲)
一个Fashion-MNIST是一个分类任务,其标签文件annotations大概长这样:
tshirt1.jpg, 0 # 样本-标签对
tshirt2.jpg, 0
......
ankleboot999.jpg, 9
__len__
这个方法是简单返回数据集的样本数量:
def __len__(self):return len(self.img_labels)
__getitem__
这个方法是Dataset类的核心,当此方法被Dataloader调用,请求特定idx的数据时,Dataset会根据idx,读取对应的图片和标签,并对它们做出各自的transform之后,返回给Dataloader,让它把图片和标签搬运到内存.
def __getitem__(self, idx):img_path = os.path.join(self.img_dir, self.img_labels.iloc[idx, 0])image = read_image(img_path)label = self.img_labels.iloc[idx, 1]if self.transform:image = self.transform(image)if self.target_transform:label = self.target_transform(label)return image, label
3. Dataloader类的使用方法
3.1 对数据集对象配置Dataloader
当Dataset类的__getitem__方法被调用的时候,他会返回一个样本-标签对。
但是在实际的模型训练中,我们还有一些别的要求,例如:
- 以“小批量(minibatches)”的方式传递样本。(减少单样本噪声带来的震荡,让梯度更新的方向更加稳定)
- 在每个周期(epoch)对数据进行重新洗牌(reshuffle),以减少模型过拟合。
- 使用 Python 的多进程(multiprocessing)来加快数据检索速度。
以上的要求可以通过如下的参数设定来满足:
from torch.utils.data import DataLoader
train_dataloader = DataLoader(training_data, batch_size=64, shuffle=True, num_workers=5)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True, num_workers=5)
- batch_size=64 设定批量大小为64
- shuffle=True 指定一个epoch之后dataloader持有的索引要重新洗牌
- num_workers=5 指定dataloader会同时开启5个进程去调用dataset的
__getitem__方法
以上是
Dataloader最基本的用法,不过,当你有GPU的时候,我推荐你也把下面两个参数打开:
pin_memory=True 开启锁页内存,减少CPU到GPU的数据传递延迟
persistent_workers=True 每个epoch结束后不销毁dataloader所开启的worker进程,而是接着用,这样剩下了worker的初始化时间
3.2 使用Dataloader遍历数据集
给Dataset配置好对应的Dataloader后,就可以开始用dataloader遍历它了。每次遍历都会返回一个batch_size的训练图片和训练标签对(这里就是64个)。
# Display image and label.
train_features, train_labels = next(iter(train_dataloader)) # 先从train_dataloader中获得一个迭代器,然后调用next获取其下一个元素
print(f"Feature batch shape: {train_features.size()}")
print(f"Labels batch shape: {train_labels.size()}")
img = train_features[0].squeeze()
label = train_labels[0]
plt.imshow(img, cmap="gray")
plt.show()
print(f"Label: {label}")
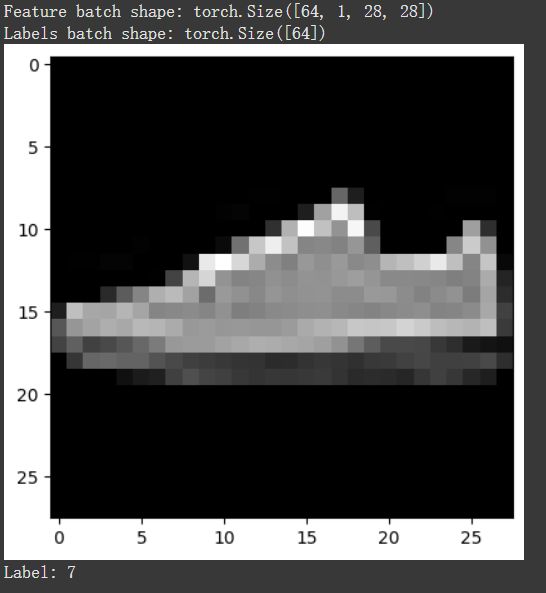
由于开启了shuffle=True,所以每次遍历完整个数据集后train_dataloader持有的索引会被打乱。