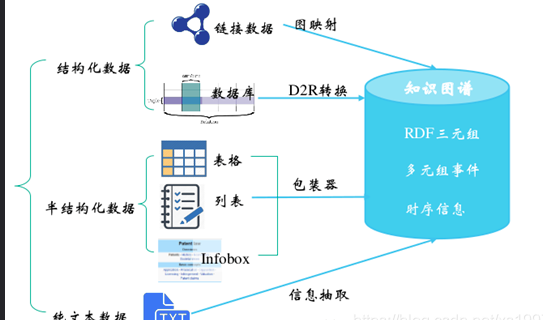
知识图谱的学习
参考:知识图谱构建(概念,工具,实例调研)-CSDN博客
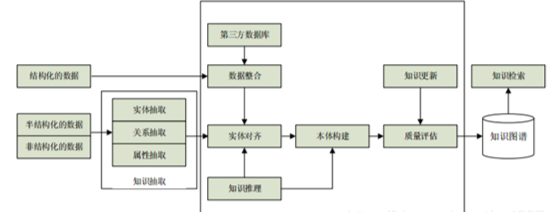
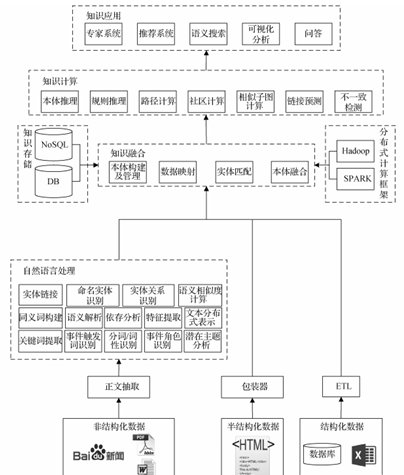
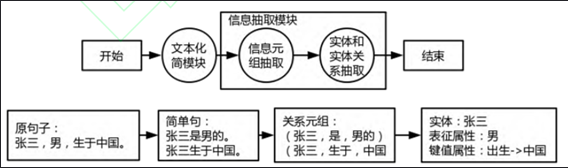
实体抽取,实体链接(两个实体同一个含义需要规整),目前最主流的算法就是CNN+LSTM+CRF进行实体识别。
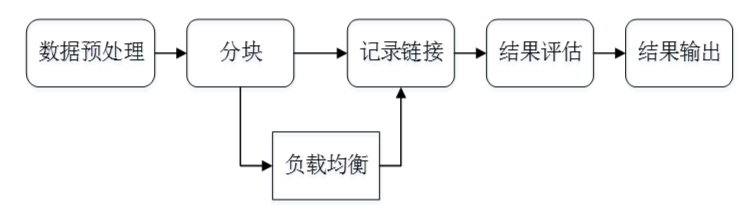
1.数据预处理
数据预处理阶段,原始数据的质量会直接影响到最终链接的结果,不同的数据集对同一实体的描述方式往往是不相同的,对这些数据进行归一化是提高后续链接精确度的重要步骤。常用的数据预处理有:
语法正规化:
语法匹配:如联系电话的表示方法
综合属性:如家庭地址的表达方式
数据正规化:
移除空格、《》、“”、-等符号
输入错误类的拓扑错误
用正式名字替换昵称和缩写等
属性相似度: 综合单个属性相似度得到属性相似度向量:
实体相似度: 根据属性相似度向量得到一个实体的相似度。
2.1属性相似度的计算
属性相似度的计算有多种方法,常用的有编辑距离、集合相似度计算、基于向量的相似度计算等。
(1)编辑距离: Levenstein、 Wagner and Fisher、 Edit Distance with Afine Gaps
(2)集合相似度计算: Jaccard系数, Dice
(3)基于向量的相似度计算: Cosine相似度、TFIDF相似度
2.2实体相似度的计算
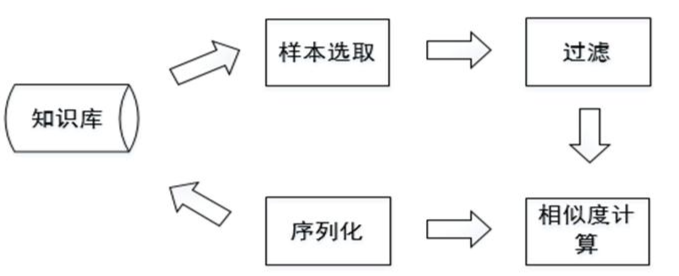
实体关系发现框架Limes
2.2.1聚合:
(1)加权平均:对相似度得分向量的各个分量进行加权求和,得到最终的实体相似度
(2)手动制定规则:给每一个相似度向量的分量设置一个阈值,若超过该阈值则将两实体相连
(3)分类器:采用无监督/半监督训练生成训练集合分类
2.2.2聚类:
(1)层次聚类:通过计算不同类别数据点之间的相似度对在不同的层次的数据进行划分,最终形成树状的聚类结构。
(2)相关性聚类:使用最小的代价找到一个聚类方案。
(3)Canopy + K-means:不需提前指定K值进行聚类
Limes是一个基于度量空间的实体匹配发现框架,适合于大规模数据链接,编程语言是Java。其整体框架如下图所示: