Lecture 7: Processes 4, Further Scheduling
回顾:
- 线程是执行轨迹的抽象。
- 线程与进程。
- 线程实现-用户,内核和混合。
- PThreads。
本章小结:
- 多级反馈队列。
- Windows 7中的调度。
- Linux中的调度。
- 负载平衡。
- 调度相关进程/线程。
多级反馈队列 Multi-level Feedback Queues
回顾:优先级队列
任务可以有不同的优先级级别。
相同优先级的任务会以循环(轮询)的方式运行。
通常通过使用多个队列来实现,每个队列对应一个优先级级别。
多级反馈队列:超越优先级队列
可以为各个队列使用不同的调度算法(例如,轮询、SJF、FCFS)
反馈队列允许动态更改优先级。作业可以在队列之间移动:
- 如果使用过多的CPU时间,移动到较低优先级队列(优先考虑I/O和交互进程)
- 移动到更高优先级的队列以防止饥饿和避免控制反转(Inversion of Control)

Spring第一课:IOC控制反转,什么是反转,什么又是控制?_spring框架中的控制反转ioc是指-CSDN博客![]() https://blog.csdn.net/qq_41376740/article/details/82454121#:~:text=Ioc%E2%80%94Inversion%20of%20Control%EF%BC%8C%E5%8D%B3%E2%80%9C%E6%8E%A7%E5%88%B6%E5%8F%8D%E8%BD%AC%E2%80%9D%EF%BC%8C%E4%B8%8D%E6%98%AF%E4%BB%80%E4%B9%88%E6%8A%80%E6%9C%AF%EF%BC%8C%E8%80%8C%E6%98%AF%E4%B8%80%E7%A7%8D%E8%AE%BE%E8%AE%A1%E6%80%9D%E6%83%B3%E3%80%82,%E5%9C%A8Java%E5%BC%80%E5%8F%91%E4%B8%AD%EF%BC%8CIoc%E6%84%8F%E5%91%B3%E7%9D%80%E5%B0%86%E4%BD%A0%E8%AE%BE%E8%AE%A1%E5%A5%BD%E7%9A%84%E5%AF%B9%E8%B1%A1%E4%BA%A4%E7%BB%99%E5%AE%B9%E5%99%A8%E6%8E%A7%E5%88%B6%EF%BC%8C%E8%80%8C%E4%B8%8D%E6%98%AF%E4%BC%A0%E7%BB%9F%E7%9A%84%E5%9C%A8%E4%BD%A0%E7%9A%84%E5%AF%B9%E8%B1%A1%E5%86%85%E9%83%A8%E7%9B%B4%E6%8E%A5%E6%8E%A7%E5%88%B6%E3%80%82%20%E5%A6%82%E4%BD%95%E7%90%86%E8%A7%A3%E5%A5%BDIoc%E5%91%A2%EF%BC%9F%20%E7%90%86%E8%A7%A3%E5%A5%BDIoc%E7%9A%84%E5%85%B3%E9%94%AE%E6%98%AF%E8%A6%81%E6%98%8E%E7%A1%AE%E2%80%9C%E8%B0%81%E6%8E%A7%E5%88%B6%E8%B0%81%EF%BC%8C%E6%8E%A7%E5%88%B6%E4%BB%80%E4%B9%88%EF%BC%8C%E4%B8%BA%E4%BD%95%E6%98%AF%E5%8F%8D%E8%BD%AC%EF%BC%88%E6%9C%89%E5%8F%8D%E8%BD%AC%E5%B0%B1%E5%BA%94%E8%AF%A5%E6%9C%89%E6%AD%A3%E8%BD%AC%E4%BA%86%EF%BC%89%EF%BC%8C%E5%93%AA%E4%BA%9B%E6%96%B9%E9%9D%A2%E5%8F%8D%E8%BD%AC%E4%BA%86%E2%80%9D%EF%BC%8C%E9%82%A3%E6%88%91%E4%BB%AC%E6%9D%A5%E6%B7%B1%E5%85%A5%E5%88%86%E6%9E%90%E4%B8%80%E4%B8%8B%EF%BC%9A反馈队列的定义特征包括:
https://blog.csdn.net/qq_41376740/article/details/82454121#:~:text=Ioc%E2%80%94Inversion%20of%20Control%EF%BC%8C%E5%8D%B3%E2%80%9C%E6%8E%A7%E5%88%B6%E5%8F%8D%E8%BD%AC%E2%80%9D%EF%BC%8C%E4%B8%8D%E6%98%AF%E4%BB%80%E4%B9%88%E6%8A%80%E6%9C%AF%EF%BC%8C%E8%80%8C%E6%98%AF%E4%B8%80%E7%A7%8D%E8%AE%BE%E8%AE%A1%E6%80%9D%E6%83%B3%E3%80%82,%E5%9C%A8Java%E5%BC%80%E5%8F%91%E4%B8%AD%EF%BC%8CIoc%E6%84%8F%E5%91%B3%E7%9D%80%E5%B0%86%E4%BD%A0%E8%AE%BE%E8%AE%A1%E5%A5%BD%E7%9A%84%E5%AF%B9%E8%B1%A1%E4%BA%A4%E7%BB%99%E5%AE%B9%E5%99%A8%E6%8E%A7%E5%88%B6%EF%BC%8C%E8%80%8C%E4%B8%8D%E6%98%AF%E4%BC%A0%E7%BB%9F%E7%9A%84%E5%9C%A8%E4%BD%A0%E7%9A%84%E5%AF%B9%E8%B1%A1%E5%86%85%E9%83%A8%E7%9B%B4%E6%8E%A5%E6%8E%A7%E5%88%B6%E3%80%82%20%E5%A6%82%E4%BD%95%E7%90%86%E8%A7%A3%E5%A5%BDIoc%E5%91%A2%EF%BC%9F%20%E7%90%86%E8%A7%A3%E5%A5%BDIoc%E7%9A%84%E5%85%B3%E9%94%AE%E6%98%AF%E8%A6%81%E6%98%8E%E7%A1%AE%E2%80%9C%E8%B0%81%E6%8E%A7%E5%88%B6%E8%B0%81%EF%BC%8C%E6%8E%A7%E5%88%B6%E4%BB%80%E4%B9%88%EF%BC%8C%E4%B8%BA%E4%BD%95%E6%98%AF%E5%8F%8D%E8%BD%AC%EF%BC%88%E6%9C%89%E5%8F%8D%E8%BD%AC%E5%B0%B1%E5%BA%94%E8%AF%A5%E6%9C%89%E6%AD%A3%E8%BD%AC%E4%BA%86%EF%BC%89%EF%BC%8C%E5%93%AA%E4%BA%9B%E6%96%B9%E9%9D%A2%E5%8F%8D%E8%BD%AC%E4%BA%86%E2%80%9D%EF%BC%8C%E9%82%A3%E6%88%91%E4%BB%AC%E6%9D%A5%E6%B7%B1%E5%85%A5%E5%88%86%E6%9E%90%E4%B8%80%E4%B8%8B%EF%BC%9A反馈队列的定义特征包括:
- 队列的数量
- 用于各个队列的调度算法
- 队列之间的迁移策略
- 对队列的初始访问
反馈队列具有高度的可配置性,并提供了极大的灵活性。
Windows 7中的调度
一种采用抢占式调度器并具有动态优先级级别的交互式系统
存在两个优先级类别,每个类别包含 16 个不同的优先级等级
- “实时”进程/线程具有固定的优先级等级
- “可变”进程/线程可以暂时提升其优先级
队列内部使用轮询算法
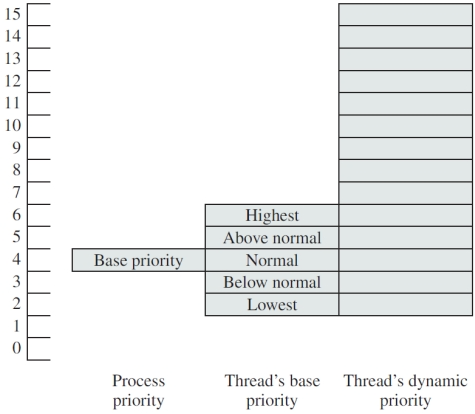
优先级是基于进程基础优先级(范围在 0 到 15 之间)和线程基础优先级(相对于进程优先级上下 ±2)来确定的。
线程在执行过程中其优先级会动态变化,介于其基础优先级和其所属类别的最大优先级之间。
- 交互式 I/O 受限进程(例如键盘)会获得更大的提升。
- 提高优先级可以避免饥饿现象和优先级反转。
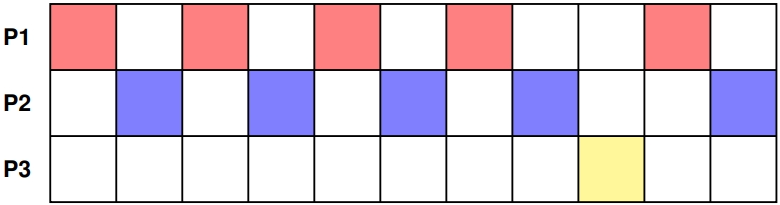
我们考虑在一台单核计算机上运行的三个进程:
- 进程 P1 和 P2 初始优先级均为 1(优先级更高!)。
- 进程 P3 初始优先级为 2(优先级更低!)
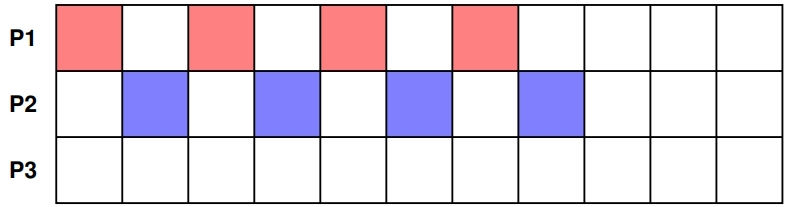
- 调度器得出P3的CPU时间不足的结论。
- 进程 P3 的优先级暂时被提升,以避免出现饥饿现象。
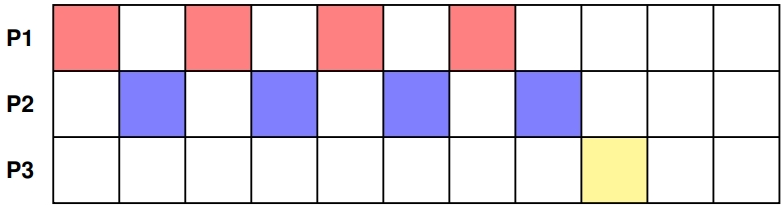
- 计算仍按原样进行。
Linux中的调度
完全公平调度器
进程调度在不同版本的Linux上得到了发展,以有效地利用多个处理器/内核
Linux区分了两种类型的调度任务:
- 实时任务(POSIX兼容),分为:实时FIFO任务 & 实时轮询任务
- 使用类似于Windows中的变量的抢占式方法时间共享任务。
Linux中用于时间共享任务的最新调度算法是完全公平调度(completely fair scheduler,CFS)。
实时任务
实时先进先出(Real time FIFO)任务具有最高优先级,并采用先到先服务(FCFS)的方式进行调度,若出现更高优先级的任务则会进行抢占。
实时轮询任务可被时钟中断抢占,并且每个任务都有一个对应的执行时间片。
这两种方法都无法保证严格的截止时间。
时间共享任务
理想状态:理想的公平调度器
我们设想一个假设的理想场景:
- 我们的 CPU 允许所有当前的 N 个任务同时运行,每个任务都能获得 CPU 资源的 1/N 分配量。
- 例如,如果有 5 个任务想要运行,那么每个任务将获得可用计算能力的 20%。
- 不幸的是,实际的 CPU 并不能以这种方式并行运行任意数量的任务——但我们能否接近这个理想状态呢?
CFS
决定如何分配 CPU 时间
我们选择一个目标延迟-这是每个任务访问CPU之前的时间量。目标延迟也限制了我们偏离公平的程度。
为了达到这个目标延迟,对于N个任务,每个任务允许运行1/N次的目标延迟。
为了避免在N较大时过度切换上下文,我们还选择了最小粒度——在考虑替换之前,我们允许任务在CPU上运行的最小时间。
近似公平性
我们记录每个任务在 CPU 上运行所占用的虚拟时间,并按照这些虚拟 CPU 时间对任务进行排序。
任务按照所使用的虚拟时间的递增顺序进行排列,其排列方式是通过红黑树实现的。
在 CPU 上占用虚拟时间最少的任务被认为处理得不够公平,因此它将被选为下一个在 CPU 上运行的任务。
在完成该任务所占用虚拟时间中1/N的目标延迟后,我们会将其替换为虚拟运行时间最短的下一个任务。
注意 - 系统调用可能会导致任务实际使用的时间少于其预先分配的全部时间。这意味着它们将更快地重新获得 CPU 的使用权。
优先事项的考量
采用了一种权重方案来考虑不同的优先级因素——我们假设权重就是任务的优先级——这是一种简化处理方式!
在 CPU 上记录的虚拟时间实际上是经过权重调整后的 CPU 实际运行时间。在实际计算时间为 100 毫秒之后:
- 优先级为 1(优先级较高)的进程被认为使用了 100 毫秒的虚拟时间。
- 优先级为 2(优先级较低)的进程被认为使用了 200 毫秒的虚拟时间。
不同优先级的进程其虚拟时间的运行速度是不同的!
请注意,任务将获得不同的运行时间窗口——这与传统的时间分割方式不同。
例子:假设T1、T2和T3三个任务,优先级分别为1、2和3,目标延迟为300ms。写T(v,r)来表示任务T有v个单位的虚拟运行时间和r个单位的实时运行时间。每隔100ms虚拟时间后的状态为:
- CPU: T1(0,0), queue: T2(0,0),T3(0,0)
- CPU: T2(0,0), queue: T3(0,0),T1(100,100)
- CPU: T3(0,0), queue: T1(100,100),T2(100,50)
- CPU: T1(100,100), queue T2(100,50),T3(100,33)
- CPU: T2(100,50), queue T3(100,33),T1(200,200)
- ...
进一步的优化
为避免可能出现的异常行为:
新任务的虚拟运行时间将设置为当前的最小虚拟运行时间——想想看,如果将其设置为零,它们可能会处于多么不公平的优势地位啊!
被阻塞的任务的虚拟运行时间将设置为以下最大值:
- 当前的最小虚拟运行时间减去一个小的偏移量——以确保其能够运行。
- 其原有的虚拟运行时间——在这种情况下,它已经在充分利用 CPU 资源了。
——想想看,如果一个长时间被阻塞的任务没有这个设置,它在 CPU 上运行的时间会有多长啊!
调度决策
单核处理器计算机:接下来应运行哪个线程?(which)
多核计算机的调度决策包括:何时运行哪个线程?(when)在何处运行哪个线程?(where)
负载平衡
共享队列
所有 CPU 共享的单级或多级队列
优点:自动负载均衡
缺点:
- 对队列的争夺。
- 无法充分利用当前 CPU 的状态:①当移动到不同的 CPU 时,缓存会失效。②转换后备缓冲区(Translation look aside buffers,TLB - 处于内存管理单元一部分的组件)会失效。
私有队列
每个CPU都有一个或多个私有队列。
优点:
- 通常可以重用现有的CPU状态,如缓存和TLB
- 共享队列的争用被最小化
缺点:负载不均衡
为了减轻cpu之间缺乏负载平衡的迁移是可能的
相关线程与无关线程
线程种类
相关:多个线程相互通信,理想情况下一起运行(例如搜索算法)
无关:例如,独立的进程线程,可能由不同的用户运行不同的程序启动
调度相关线程:共同合作
例如,线程属于同一个进程并且相互协作,例如它们会交换消息或共享信息,例如
- 进程 A 拥有线程 A0 和 A1,A0 和 A1 互相协作
- 进程 B 拥有线程 B0 和 B1,B0 和 B1 也互相协作
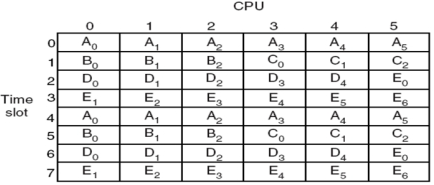
- 调度程序首先选择 A0 和 B1 运行,然后是 A1 和 B0,接着是 A0 和 A1,以及 B0 和 B1 在不同的 CPU 上运行
- 它们试图向其他线程发送消息,而这些线程仍处于就绪状态
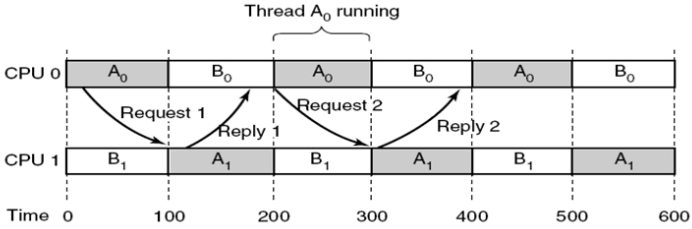
其目的是让协作线程尽可能多地在多个cpu上同时运行
方法包括:
- 空间分享 Space sharing
- 组调度 Gang scheduling
空间分享
被称为“空间共享调度”的方法:
- 当有足够的 CPU 可用时,与 N 个相关线程(通常来自同一个进程)相关的线程会被分配到 N 个专用的 CPU 上。
- 与 M 个相关线程(通常来自另一个进程)相关的线程则会一直等待,直到有 M 个 CPU 可用。
- 在任何时候,可用的 CPU 都会被划分成与相关线程相关的块。
- 当线程完成时,它们所对应的专用 CPU 会被归还给可用 CPU 的集合。
- 这些 CPU 不会进行多程序调度,以保持相关线程一起运行。这意味着阻塞调用会导致 CPU 闲置。
组调度
空间共享调度通过空间(CPU)来分配工作
- 使相关线程能够一起运行。
- 缺乏多程序设计会避免上下文切换的开销,但会导致 CPU 周期的浪费。
- 组调度是一种尝试,在“时间和空间”两个维度上进行调度,以避免这种 CPU 时间的浪费。
调度器将相关的线程组在一起,在不同的cpu上同时运行。
这是一种抢占式算法,时间片在所有节点上同步cpu。
阻塞线程导致cpu空闲
- 如果一个线程阻塞,由于时间片在所有cpu之间同步,其余的时间片将被闲置。