日志管理工具 ——ELK Stack
一、ELK Stack 概述
1.1 核心组件
ELK Stack(现更名为 Elastic Stack)是一套开源的日志收集、存储、分析和可视化平台,由三个核心组件构成:
- Elasticsearch:分布式搜索引擎,负责日志数据的存储、索引和快速查询
- Logstash:日志数据收集和处理管道,支持多种数据源和数据转换
- Kibana:日志数据可视化平台,提供丰富的图表和仪表盘
随着发展,ELK Stack 逐渐扩展为包含 Beats 的 Elastic Stack,形成更完整的日志管理生态:
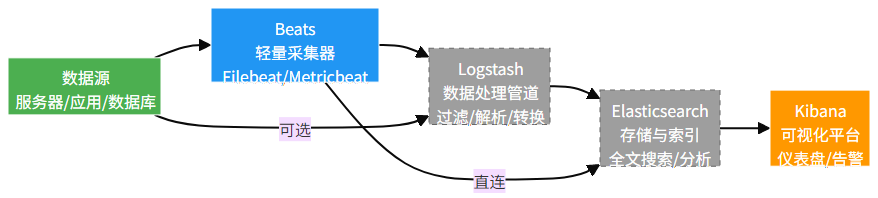
1.2 核心特性
- 分布式架构:可水平扩展以处理海量日志数据
- 实时处理:支持日志数据的实时收集、存储和分析
- 全文检索:强大的搜索功能,支持复杂查询和过滤
- 灵活的可视化:通过 Kibana 创建自定义仪表盘和报表
- 丰富的集成:支持与多种系统和工具集成(如 Docker、Kubernetes、AWS 等)
- 可扩展性:通过插件扩展功能,满足特定需求
1.3 应用场景
ELK Stack 适用于多种日志管理场景:
- 应用程序日志集中管理和分析
- 系统和基础设施监控
- 安全事件日志分析与审计
- 用户行为追踪与分析
- 业务数据可视化与报表
- 故障排查与问题定位
二、ELK Stack 安装与部署
2.1 环境准备
2.1.1 系统要求
组件 | 最低配置 | 推荐配置 |
Elasticsearch | 2CPU、4GB 内存 | 4CPU、16GB 内存 |
Logstash | 2CPU、4GB 内存 | 4CPU、8GB 内存 |
Kibana | 1CPU、2GB 内存 | 2CPU、4GB 内存 |
Beats | 1CPU、1GB 内存 | 2CPU、2GB 内存 |
2.1.2 操作系统支持
- Linux(推荐 CentOS 7/8、Ubuntu 18.04/20.04、Debian 10)
- Windows Server(有限支持)
- macOS(开发环境)
2.1.3 依赖项
- Java 8 或 11(Elasticsearch 和 Logstash 需要)
- 网络:各组件间需开放相应端口(9200、9300、5044、5601 等)
2.2 Elasticsearch 安装
2.2.1 安装 Java
# CentOS安装Java 11
yum install -y java-11-openjdk-devel# Ubuntu安装Java 11
apt update
apt install -y openjdk-11-jdk# 验证Java安装
java -version2.2.2 安装 Elasticsearch
# 导入Elasticsearch GPG密钥
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch # CentOS
# 或
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - # Ubuntu# 添加Elasticsearch仓库
# CentOS
cat > /etc/yum.repos.d/elasticsearch.repo << EOF
[elasticsearch-7.x]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF# Ubuntu
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic.list
apt update# 安装Elasticsearch
yum install -y elasticsearch # CentOS
# 或
apt install -y elasticsearch # Ubuntu2.2.3 配置 Elasticsearch
# 编辑配置文件
vim /etc/elasticsearch/elasticsearch.yml# 核心配置
cluster.name: elk-cluster # 集群名称
node.name: es-node-1 # 节点名称
path.data: /var/lib/elasticsearch # 数据存储路径
path.logs: /var/log/elasticsearch # 日志路径
network.host: 0.0.0.0 # 监听地址,0.0.0.0表示所有地址
http.port: 9200 # HTTP端口
discovery.seed_hosts: ["127.0.0.1"] # 种子节点
cluster.initial_master_nodes: ["es-node-1"] # 初始主节点# 可选性能配置
bootstrap.memory_lock: true # 锁定内存,防止swap配置系统参数:
# 配置内存锁定
vim /etc/elasticsearch/jvm.options
# 设置JVM堆大小(建议为物理内存的50%,不超过31GB)
-Xms4g
-Xmx4g# 配置系统限制
vim /etc/security/limits.conf
# 添加
elasticsearch soft memlock unlimited
elasticsearch hard memlock unlimited
elasticsearch - nofile 65536
elasticsearch - nproc 4096# 配置系统内核参数
vim /etc/sysctl.conf
# 添加
vm.max_map_count=262144# 应用配置
sysctl -p2.2.4 启动并验证 Elasticsearch
# 启动服务
systemctl start elasticsearch
systemctl enable elasticsearch# 检查服务状态
systemctl status elasticsearch# 验证服务
curl -X GET "http://localhost:9200/"# 预期输出
{"name" : "es-node-1","cluster_name" : "elk-cluster","cluster_uuid" : "xxxxxxxxxxxxxxxxxxxx","version" : {"number" : "7.14.0","build_flavor" : "default","build_type" : "rpm","build_hash" : "dd5a0a2acaa2045e41b5de95cb3e88ec9e074d","build_date" : "2021-07-29T20:49:32.864135063Z","build_snapshot" : false,"lucene_version" : "8.9.0","minimum_wire_compatibility_version" : "6.8.0","minimum_index_compatibility_version" : "6.0.0-beta1"},"tagline" : "You Know, for Search"
}2.3 Kibana 安装与配置
2.3.1 安装 Kibana
# CentOS安装
yum install -y kibana# Ubuntu安装
apt install -y kibana2.3.2 配置 Kibana
# 编辑配置文件
vim /etc/kibana/kibana.yml# 核心配置
server.port: 5601 # 端口
server.host: "0.0.0.0" # 监听地址
elasticsearch.hosts: ["http://localhost:9200"] # Elasticsearch地址
kibana.index: ".kibana" # Kibana索引名称2.3.3 启动并验证 Kibana
# 启动服务
systemctl start kibana
systemctl enable kibana# 检查服务状态
systemctl status kibana# 开放防火墙端口(如需要)
firewall-cmd --permanent --add-port=5601/tcp
firewall-cmd --reload通过浏览器访问 http://<kibana-host>:5601 验证 Kibana 是否正常运行。
2.4 Logstash 安装与配置
2.4.1 安装 Logstash
# CentOS安装
yum install -y logstash# Ubuntu安装
apt install -y logstash2.4.2 基本配置
创建一个简单的 Logstash 配置文件,从标准输入读取数据并输出到 Elasticsearch:
# 创建配置文件
vim /etc/logstash/conf.d/stdin_to_es.conf# 配置内容
input {stdin {codec => "json"}
}filter {# 可以添加过滤规则
}output {elasticsearch {hosts => ["http://localhost:9200"]index => "logstash-stdin-%{+YYYY.MM.dd}"}stdout { codec => rubydebug } # 同时输出到控制台
}2.4.3 启动并验证 Logstash
# 测试配置文件
/usr/share/logstash/bin/logstash --config.test_and_exit -f /etc/logstash/conf.d/stdin_to_es.conf# 启动Logstash(测试模式)
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/stdin_to_es.conf# 作为服务启动
systemctl start logstash
systemctl enable logstash# 检查服务状态
systemctl status logstash2.5 Filebeat 安装与配置
Filebeat 是轻量级日志收集器,用于替代 Logstash 在边缘节点的日志收集工作。
2.5.1 安装 Filebeat
# CentOS安装
yum install -y filebeat# Ubuntu安装
apt install -y filebeat2.5.2 配置 Filebeat
配置 Filebeat 收集系统日志并发送到 Elasticsearch:
# 编辑配置文件
vim /etc/filebeat/filebeat.yml# 配置输入
filebeat.inputs:
- type: logenabled: truepaths:- /var/log/messages- /var/log/securetags: ["system"]# 配置输出到Elasticsearch
output.elasticsearch:hosts: ["localhost:9200"]index: "filebeat-system-%{+YYYY.MM.dd}"# 可选:配置输出到Logstash
# output.logstash:
# hosts: ["localhost:5044"]# 启用Kibana仪表盘加载
setup.kibana:host: "localhost:5601"# 加载系统模块
setup.module:system:enabled: true2.5.3 启动并验证 Filebeat
# 加载仪表盘模板
filebeat setup --dashboards# 启动服务
systemctl start filebeat
systemctl enable filebeat# 检查服务状态
systemctl status filebeat三、ELK Stack 核心配置
3.1 Elasticsearch 核心配置
Elasticsearch 的主要配置文件为/etc/elasticsearch/elasticsearch.yml,关键配置项:
# 集群配置
cluster.name: elk-cluster
node.name: ${HOSTNAME}
node.master: true # 是否可作为主节点
node.data: true # 是否存储数据# 路径配置
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch# 网络配置
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300 # 节点间通信端口# 发现与集群形成
discovery.seed_hosts: ["es-node1.example.com", "es-node2.example.com"]
cluster.initial_master_nodes: ["es-node1.example.com"]# 安全配置(基础)
xpack.security.enabled: false # 生产环境建议开启
# xpack.security.transport.ssl.enabled: true# 索引生命周期管理
action.auto_create_index: .monitoring*,* # 自动创建索引规则# 内存配置
bootstrap.memory_lock: true3.2 Logstash 管道配置
Logstash 使用管道配置定义数据处理流程,由 input、filter 和 output 三部分组成:
3.2.1 多输入配置
# /etc/logstash/conf.d/multiple_inputs.conf
input {# 文件输入file {path => "/var/log/nginx/access.log"start_position => "beginning"sincedb_path => "/dev/null" # 每次重启都从头读取(测试用)tags => ["nginx", "access"]type => "nginx-access"}# 系统日志输入syslog {port => 514type => "syslog"}# Beats输入beats {port => 5044}
}filter {# 对nginx日志进行解析if [type] == "nginx-access" {grok {match => { "message" => '%{NGINXACCESS}' }}date {match => [ "timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]target => "@timestamp"}geoip {source => "clientip"}}
}output {# 根据类型输出到不同索引if [type] == "nginx-access" {elasticsearch {hosts => ["http://localhost:9200"]index => "nginx-access-%{+YYYY.MM.dd}"}} else if [type] == "syslog" {elasticsearch {hosts => ["http://localhost:9200"]index => "syslog-%{+YYYY.MM.dd}"}} else {elasticsearch {hosts => ["http://localhost:9200"]index => "logstash-%{+YYYY.MM.dd}"}}# 控制台输出(调试用)stdout { codec => rubydebug }
}3.2.2 常用过滤器
- Grok 过滤器:解析非结构化日志为结构化数据
filter {grok {match => { "message" => "%{COMBINEDAPACHELOG}" } # 匹配Apache日志# 自定义模式match => { "message" => "%{TIMESTAMP_ISO8601:logtime} %{LOGLEVEL:loglevel} \[%{DATA:thread}\] %{DATA:class} - %{GREEDYDATA:msg}" }patterns_dir => ["/etc/logstash/patterns"] # 自定义模式文件目录tag_on_failure => ["_grokparsefailure"] # 解析失败时添加标签}
}2. Date 过滤器:解析日志中的时间戳
filter {date {match => [ "logtime", "yyyy-MM-dd HH:mm:ss.SSS", "ISO8601" ] # 匹配多种格式target => "@timestamp" # 存储到@timestamp字段timezone => "Asia/Shanghai" # 指定时区}
}3. Mutate 过滤器:修改字段
filter {mutate {rename => { "old_field" => "new_field" } # 重命名字段add_field => { "new_field" => "static_value" } # 添加字段update => { "existing_field" => "new_value" } # 更新字段remove_field => [ "message", "logtime" ] # 删除字段convert => { "response_time" => "float" } # 转换字段类型gsub => [ "message", "password=\w+", "password=***" ] # 替换敏感信息}
}4. GeoIP 过滤器:根据 IP 地址添加地理位置信息
filter {geoip {source => "clientip" # 源IP字段target => "geo" # 结果存储字段database => "/etc/logstash/geoip/GeoLite2-City.mmdb" # 自定义数据库}
}3.3 Filebeat 配置详解
Filebeat 配置文件/etc/filebeat/filebeat.yml的核心配置:
# 输入配置
filebeat.inputs:
- type: log # 输入类型(log、stdin、tcp等)enabled: true # 是否启用paths: # 日志文件路径- /var/log/*.log- /var/log/nginx/*.logexclude_files: ['\.gz$'] # 排除的文件tags: ["system", "nginx"] # 标签fields: # 自定义字段environment: productionservice: webserverfields_under_root: false # 自定义字段是否在根级别scan_frequency: 10s # 扫描新文件的频率harvester_buffer_size: 16384 # 收割机缓冲区大小max_bytes: 10485760 # 单个日志条目最大字节数multiline.type: pattern # 多行日志处理multiline.pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}' # 多行匹配模式multiline.negate: true # 是否否定匹配multiline.match: after # 匹配后如何处理# 模块配置(预定义的日志类型处理)
filebeat.config.modules:path: ${path.config}/modules.d/*.yml # 模块配置路径reload.enabled: false # 是否自动重载# 输出配置
output.elasticsearch:hosts: ["localhost:9200"] # Elasticsearch地址index: "filebeat-%{[fields.environment]}-%{+YYYY.MM.dd}" # 索引名称username: ${ELASTICSEARCH_USERNAME} # 用户名password: ${ELASTICSEARCH_PASSWORD} # 密码ssl.enabled: true # 是否启用SSLssl.certificate_authorities: ["/etc/filebeat/certs/ca.crt"] # CA证书# 或输出到Logstash
# output.logstash:
# hosts: ["localhost:5044"]
# loadbalance: true # 是否负载均衡
# worker: 2 # 工作线程数# 处理器配置(在发送前处理事件)
processors:- add_host_metadata: # 添加主机元数据when.not.contains.tags: forwarded- add_cloud_metadata: ~ # 添加云服务元数据- add_docker_metadata: ~ # 添加Docker元数据- add_kubernetes_metadata: ~ # 添加Kubernetes元数据- drop_fields: # 删除字段fields: ["beat", "input", "source"]- dissect: # 解析字段tokenizer: "%{key1}=%{value1};%{key2}=%{value2}"field: "message"target_prefix: "dissect"# 日志配置
logging.level: info # 日志级别
logging.to_files: true # 是否输出到文件
logging.files:path: /var/log/filebeatname: filebeatkeepfiles: 7permissions: 0644# Kibana配置(用于设置仪表盘)
setup.kibana:host: "localhost:5601"username: ${KIBANA_USERNAME}password: ${KIBANA_PASSWORD}# 索引生命周期管理
setup.ilm:enabled: truepolicy_name: "filebeat-policy"rollover_alias: "filebeat"3.3.1 Filebeat 模块配置
Filebeat 提供多种预定义模块,简化常见日志类型的处理:
# 列出可用模块
filebeat modules list# 启用Nginx模块
filebeat modules enable nginx# 禁用Nginx模块
filebeat modules disable nginx配置模块:
# /etc/filebeat/modules.d/nginx.yml
- module: nginxaccess:enabled: truevar.paths: ["/var/log/nginx/access.log*"] # 日志路径error:enabled: truevar.paths: ["/var/log/nginx/error.log*"] # 日志路径ingress_controller:enabled: false # 禁用Ingress Controller日志收集3.4 Kibana 使用指南
3.4.1 索引模式创建
- 登录 Kibana 控制台(http://<kibana-host>:5601)
- 进入Management > Stack Management > Index Patterns
- 点击Create index pattern
- 输入索引模式(如nginx-access-*)
- 选择时间字段(通常为@timestamp)
- 点击Create index pattern
3.4.2 发现与搜索
在Discover页面可以搜索和浏览日志数据:
- 使用 KQL(Kibana Query Language)搜索:
- response:500 - 查找响应码为 500 的日志
- clientip:192.168.1.* - 查找特定 IP 段的客户端
- method:GET AND response:200 - 组合条件
- url:"/api/users/*" - 通配符匹配
- 时间范围过滤:通过右上角时间选择器设置
3.4.3 可视化创建
在Visualize Library页面创建可视化图表:
- 点击Create visualization
- 选择可视化类型(如 Line chart、Bar chart、Pie chart 等)
- 选择索引模式
- 配置 X 轴、Y 轴和聚合方式:
- 对于访问量趋势:X 轴选择@timestamp(按小时聚合),Y 轴选择Count
- 对于状态码分布:使用Terms聚合,字段选择response
5. 保存可视化
3.4.4 仪表盘创建
在Dashboard页面创建仪表盘:
- 点击Create dashboard
- 点击Add添加已创建的可视化
- 调整图表位置和大小
- 设置自动刷新时间
- 保存仪表盘
四、ELK Stack 安全配置
4.1 Elasticsearch 安全配置
启用 Elasticsearch 安全功能(X-Pack Security):
# /etc/elasticsearch/elasticsearch.yml
xpack.security.enabled: true
xpack.security.transport.ssl.enabled: true设置内置用户密码:
# 自动生成随机密码
/usr/share/elasticsearch/bin/elasticsearch-setup-passwords auto# 或手动设置密码
/usr/share/elasticsearch/bin/elasticsearch-setup-passwords interactive创建自定义用户:
# 使用Kibana控制台或API创建用户
# 示例:创建具有管理员权限的用户
curl -X POST "http://localhost:9200/_security/user/admin" \-H "Content-Type: application/json" \-u elastic:elastic_password \-d '{"password" : "admin_password","roles" : ["superuser"],"full_name" : "Administrator"}'4.2 Kibana 安全配置
配置 Kibana 使用 Elasticsearch 认证:
# /etc/kibana/kibana.yml
elasticsearch.username: "kibana_system"
elasticsearch.password: "kibana_system_password"
xpack.security.enabled: true
xpack.monitoring.ui.container.elasticsearch.enabled: true设置 Kibana 空间和角色:
- 登录 Kibana(使用 elastic 用户)
- 进入Management > Stack Management > Security > Spaces创建空间
- 进入Roles创建自定义角色,分配权限
- 进入Users创建用户并分配角色
4.3 加密通信配置
配置 Elasticsearch、Kibana 和 Filebeat 之间的 SSL/TLS 通信:
# 创建证书颁发机构
/usr/share/elasticsearch/bin/elasticsearch-certutil ca# 生成证书
/usr/share/elasticsearch/bin/elasticsearch-certutil cert --ca elastic-stack-ca.p12# 配置Elasticsearch SSL
cp elastic-certificates.p12 /etc/elasticsearch/certs/
chown elasticsearch:elasticsearch /etc/elasticsearch/certs/*
# Elasticsearch SSL配置
xpack.security.transport.ssl.keystore.path: certs/elastic-certificates.p12
xpack.security.transport.ssl.truststore.path: certs/elastic-certificates.p12
xpack.security.http.ssl.enabled: true
xpack.security.http.ssl.keystore.path: certs/elastic-certificates.p12
xpack.security.http.ssl.truststore.path: certs/elastic-certificates.p12
# Kibana SSL配置
server.ssl.enabled: true
server.ssl.certificate: /etc/kibana/certs/kibana.crt
server.ssl.key: /etc/kibana/certs/kibana.key
elasticsearch.ssl.certificateAuthorities: ["/etc/kibana/certs/ca.crt"]五、ELK Stack 实战案例
5.1 Nginx 日志分析平台
5.1.1 架构设计
Nginx服务器 → Filebeat → Logstash → Elasticsearch → Kibana5.1.2 配置 Filebeat 收集 Nginx 日志
# /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: logenabled: truepaths:- /var/log/nginx/access.logtags: ["nginx", "access"]fields:log_type: nginx_access- type: logenabled: truepaths:- /var/log/nginx/error.logtags: ["nginx", "error"]fields:log_type: nginx_erroroutput.logstash:hosts: ["logstash-host:5044"]5.1.3 配置 Logstash 处理 Nginx 日志
# /etc/logstash/conf.d/nginx.conf
input {beats {port => 5044}
}filter {if [fields][log_type] == "nginx_access" {grok {match => { "message" => '%{NGINXACCESS}' }}date {match => ["timestamp", "dd/MMM/yyyy:HH:mm:ss Z"]target => "@timestamp"}geoip {source => "clientip"}useragent {source => "agent"target => "user_agent"}mutate {convert => {"bytes" => "integer""response" => "integer""responsetime" => "float"}remove_field => ["message", "timestamp", "agent"]}} else if [fields][log_type] == "nginx_error" {grok {match => { "message" => '(?<timestamp>\d{4}/\d{2}/\d{2} \d{2}:\d{2}:\d{2}) \[%{LOGLEVEL:loglevel}\] %{NUMBER:pid:int}#%{NUMBER:tid:int}: %{GREEDYDATA:error_message}(?:, client: %{IP:clientip})?(?:, server: %{DATA:server})?(?:, request: "%{DATA:request}")?(?:, host: "%{DATA:host}")?(?:, referrer: "%{DATA:referrer}")?' }}date {match => ["timestamp", "yyyy/MM/dd HH:mm:ss"]target => "@timestamp"}mutate {remove_field => ["message", "timestamp"]}}
}output {elasticsearch {hosts => ["elasticsearch-host:9200"]index => "nginx-%{[fields][log_type]}-%{+YYYY.MM.dd}"user => "elastic"password => "elastic_password"}stdout { codec => rubydebug }
}5.1.4 创建 Kibana 可视化和仪表盘
- 创建索引模式nginx-*-*
- 创建访问量趋势图(Line chart):
- X 轴:@timestamp(按小时聚合)
- Y 轴:Count
3. 创建状态码分布(Pie chart):
- 聚合:Terms
- 字段:response
4. 创建客户端地理位置分布(Tile map):
- 坐标字段:geoip.location
5. 创建响应时间分布(Histogram):
- X 轴:responsetime
- 间隔:0.1
6. 将以上可视化添加到仪表盘
5.2 应用程序日志集中管理
5.2.1 架构设计
应用服务器 → Filebeat → Elasticsearch → Kibana5.2.2 配置 Filebeat 收集 JSON 格式日志
# /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: logenabled: truepaths:- /var/log/app/*.logjson.keys_under_root: true # JSON字段放在根级别json.overwrite_keys: true # 覆盖已有字段fields:service: myappenvironment: productionoutput.elasticsearch:hosts: ["elasticsearch-host:9200"]index: "app-%{[fields.service]}-%{+YYYY.MM.dd}"username: "filebeat_writer"password: "password"
setup.template.name: "app-logs"
setup.template.pattern: "app-*"
setup.template.enabled: false
setup.template.overwrite: true5.2.3 在 Kibana 中分析应用日志
- 创建索引模式app-*
- 设置日志等级过滤器:loglevel: ERROR
- 创建错误趋势图:按时间和日志级别聚合
- 设置告警:当 ERROR 级别日志在 5 分钟内超过 10 条时触发告警
六、ELK Stack 扩展与优化
6.1 Elasticsearch 集群扩展
配置 Elasticsearch 集群以提高可用性和性能:
# 节点1(主节点和数据节点)
cluster.name: elk-cluster
node.name: es-node-1
node.master: true
node.data: true
network.host: 192.168.1.101
discovery.seed_hosts: ["192.168.1.101", "192.168.1.102", "192.168.1.103"]
cluster.initial_master_nodes: ["es-node-1", "es-node-2"]# 节点2(主节点和数据节点)
cluster.name: elk-cluster
node.name: es-node-2
node.master: true
node.data: true
network.host: 192.168.1.102
discovery.seed_hosts: ["192.168.1.101", "192.168.1.102", "192.168.1.103"]
cluster.initial_master_nodes: ["es-node-1", "es-node-2"]# 节点3(仅数据节点)
cluster.name: elk-cluster
node.name: es-node-3
node.master: false
node.data: true
network.host: 192.168.1.103
discovery.seed_hosts: ["192.168.1.101", "192.168.1.102", "192.168.1.103"]检查集群健康状态:
curl -X GET "http://localhost:9200/_cluster/health?pretty" -u elastic:password6.2 索引生命周期管理
配置索引生命周期策略自动管理索引:
- 在 Kibana 中进入Management > Stack Management > Index Lifecycle Policies
- 创建策略:
- 热阶段:存储最新数据,允许写入和查询
- 温阶段:数据不再写入,仅查询,可压缩
- 冷阶段:很少查询的数据,进一步压缩
- 删除阶段:过期数据自动删除
3. 应用策略到索引模板
示例 ILM 策略配置:
{"policy": {"phases": {"hot": {"min_age": "0ms","actions": {"rollover": {"max_age": "1d","max_size": "50gb"},"set_priority": {"priority": 100}}},"warm": {"min_age": "7d","actions": {"shrink": {"number_of_shards": 1},"forcemerge": {"max_num_segments": 1},"set_priority": {"priority": 50}}},"cold": {"min_age": "30d","actions": {"freeze": {},"set_priority": {"priority": 10}}},"delete": {"min_age": "90d","actions": {"delete": {}}}}}
}6.3 性能优化
6.3.1 Elasticsearch 性能优化
- JVM 配置优化:
# /etc/elasticsearch/jvm.options
-Xms16g # 初始堆大小
-Xmx16g # 最大堆大小(不超过物理内存的50%,且不超过31GB)
-XX:+UseG1GC # 使用G1垃圾收集器
-XX:G1ReservePercent=25 # 保留内存百分比2. 索引优化:
# 索引模板优化
{"index_patterns": ["logs-*"],"settings": {"number_of_shards": 3, # 主分片数量(根据节点数调整)"number_of_replicas": 1, # 副本数量"refresh_interval": "30s", # 刷新间隔(提高写入性能)"translog.durability": "async", # 异步提交translog"translog.flush_threshold_size": "1gb" # translog刷新阈值}
}3. 操作系统优化:
# 禁用swap
swapoff -a
# 永久禁用swap(编辑/etc/fstab注释swap行)# 配置网络
echo "net.ipv4.tcp_tw_reuse = 1" >> /etc/sysctl.conf
echo "net.ipv4.tcp_tw_recycle = 1" >> /etc/sysctl.conf
sysctl -p6.3.2 Logstash 性能优化
# /etc/logstash/jvm.options
-Xms4g
-Xmx4g# 管道工作线程配置
pipeline.workers: 4 # 通常设置为CPU核心数
pipeline.batch.size: 1000
pipeline.batch.delay: 506.3.3 Filebeat 性能优化
# /etc/filebeat/filebeat.yml
filebeat.registry.flush: 5s # 注册表刷新间隔
queue.mem:events: 4096 # 内存队列大小flush.min_events: 512 # 刷新最小事件数flush.timeout: 5s # 刷新超时6.4 与其他工具集成
6.4.1 与 Kubernetes 集成
# Filebeat DaemonSet 配置示例
apiVersion: apps/v1
kind: DaemonSet
metadata:name: filebeatnamespace: kube-system
spec:selector:matchLabels:app: filebeattemplate:metadata:labels:app: filebeatspec:serviceAccountName: filebeatterminationGracePeriodSeconds: 30containers:- name: filebeatimage: docker.elastic.co/beats/filebeat:7.14.0args: ["-c", "/etc/filebeat.yml","-e",]volumeMounts:- name: configmountPath: /etc/filebeat.ymlsubPath: filebeat.yml- name: datamountPath: /usr/share/filebeat/data- name: varlibdockercontainersmountPath: /var/lib/docker/containersreadOnly: truevolumes:- name: configconfigMap:defaultMode: 0600name: filebeat-config- name: varlibdockercontainershostPath:path: /var/lib/docker/containers- name: datahostPath:path: /var/lib/filebeat-datatype: DirectoryOrCreate6.4.2 与 Prometheus 集成
# prometheus.yml 配置
scrape_configs:- job_name: 'elasticsearch'metrics_path: '/_prometheus/metrics'static_configs:- targets: ['elasticsearch-host:9200']- job_name: 'kibana'metrics_path: '/metrics'static_configs:- targets: ['kibana-host:5601']在 Kibana 中安装 Prometheus 插件,实现 metrics 数据可视化。
七、最佳实践与总结
7.1 最佳实践
- 部署架构:
- 小规模部署:单节点 ELK Stack
- 中大规模:Elasticsearch 集群 + 独立 Logstash 节点 + 独立 Kibana 节点
- 超大规模:引入 Kafka 作为缓冲层,实现解耦和峰值处理
2. 安全实践:
- 启用 X-Pack Security 保护敏感数据
- 配置 SSL/TLS 加密所有组件间通信
- 实施最小权限原则,为不同组件创建专用用户
- 定期轮换证书和密码
3. 数据管理:
- 使用索引生命周期管理自动处理过期数据
- 根据日志重要性设置不同的保留策略
- 对敏感日志数据进行脱敏处理
- 定期备份重要索引
4. 监控与告警:
- 监控 ELK Stack 自身健康状态
- 设置关键指标告警(如磁盘使用率、集群健康状态、错误率)
- 监控日志处理延迟,确保及时发现处理瓶颈
7.2 总结
ELK Stack 作为一套完整的日志管理解决方案,通过 Elasticsearch、Logstash、Kibana 和 Beats 的协同工作,提供了从日志收集、处理、存储到分析和可视化的全流程能力。其主要优势包括:
- 强大的全文检索能力,支持复杂查询和过滤
- 灵活的日志处理管道,可应对各种日志格式和转换需求
- 丰富的可视化选项,帮助用户从海量日志中发现有价值的信息
- 高度可扩展的架构,可从单节点部署扩展到大规模集群
- 活跃的社区和丰富的插件生态,不断扩展功能边界
在实际应用中,应根据业务需求和规模选择合适的部署架构,并遵循最佳实践进行配置和优化。随着云原生和微服务架构的普及,ELK Stack 与容器平台、云服务的集成将更加紧密,成为现代运维和监控体系中不可或缺的组成部分。
通过合理使用 ELK Stack,组织可以实现日志数据的集中管理,提高故障排查效率,增强系统安全性,为业务决策提供数据支持,最终提升整体 IT 运营效率和业务连续性。