Syzkaller实战教程6:[重要]初始种子加载机制剖析第二集
本文从新版syzkaller采用的Queue机制出发,对syzkaller加载初始种子的流程进行了细致剖析。
1. ⭐Queue机制
新版syzkaller以queue的形式取代了曾经用于执行的workcandidate,四种queue各种的功能如下所示
注意:所有的queue中存放的都是一个包装后的请求(request),而不只是一个种子(prog)
1. triageCandidateQueue&&CandidateQueue:
candidateQueue(候选程序队列)用于存储等待执行的候选程序。使用queue.Plain()实现,按照先进先出的顺序处理。为候选程序提供重试机制,处理不稳定的覆盖率。
包含的程序类型主要是通过AddCandidates()方法添加的候选程序以及需要重试的候选程序(如果第一次执行没有发现稳定信号,给予重试机会)。
1. 多队列任务调度机制
execQueues结构体包含多个优先级队列,实现任务分类处理:
type execQueues struct{triageCandidateQueue*queue.DynamicOrderer //高优先级候选分析candidateQueue*queue.PlainQueue //普通候选程序triageQueue*queue.DynamicOrderer //信号分析队列smashQueue*queue.PlainQueue //暴力变异队列
}
① 队列调度策略:通过queue.Alternate交替执行smashQueue和其他队列,避免资源过度集中于单一
测试模式”。
② 补丁测试优化:当Config.PatchTest为真时,调整队列跳过频率(skipQueue=2),侧重已有程序的变异而非新覆盖率收集”。
如上所示,triageCandidateQueue和CandidateQueue是一对在功能上相互承接的数据结构,处理的对象都是从corpus.db中加载的初始种子;
candidateQueue的内容为初始输入的种子,triageCandidateQueue处理candidateQueue中执行后具有新信号的初始输入程序。
在newExecQueues方法中,队列的优先级顺序被明确:
func newExecQueues(fuzzer *Fuzzer)execQueues{ret :=execQueues{triageCandidateQueue:queue.Dynamicorder(),candidateQueue: queue.Plain(),triageQueue:queue.Dynamicorder(),smashQueue:queue.Plain(),}ret.source queue.Order(ret.triageCandidateQueue,//1.最高优先级:候选程序分析ret.candidateQueue,//2.候选程序验证ret.triageQueue,//3.普通程序分析queue.Alternate(ret.smashQueue,3),//4.压力测试(每3次其他队列请求后执次)queue.Callback(fuzzer.genFuzz),//5,生成新请求的回调)return ret
}所有初始种子将一次性注入candidatequeue:
AddCandidates函数,该函数遍历所有候选,为每个候选创建一个请求,并调用enqueue方法,将请求提交到candidateQueue(类型为PlainQueue)。(在实现上,每个请求都会通过Submit方法添加到PlainQueue的队列中)
func (fuzzer *Fuzzer)AddCandidates(candidates []Candidate){fuzzer.statCandidates.Add(len(candidates))for_,candidate range candidates{req :&queue.Request(Prog:candidate.Prog,ExecOpts:setFlags(flatrpc.ExecFlagCollectSignal),Stat:fuzzer.statExecCandidate,Important:true,}fuzzer.enqueue(fuzzer.candidateQueue,req,candidate.FlagsprogCandidate,0)}
}2. 程序被加入triageCandidateQueue的具体流程:
AddCandidates() → candidateQueue → 执行 → 发现新信号 → triageCandidateQueue → 分类 → 确认有价值 → 添加到语料库 → 创建smashJob
1.候选程序执行发现新信号:
② 当通过AddCandidates()添加的程序执行后
② 在processResult函数中检测到新信号
③ 程序带有progCandidate标志
④ 创建triageJob并放入triageCandidateQueue
2.候选程序来源:
① 初始语料库加载:manager.LoadSeeds()加载的种子
② Hub同步:从hub获取的新程序
③ 用户手动添加的程序
与普通程序的区别:
候选程序(初始输入程序)使用triageCandidateQueue进行分类
普通程序(通过genFuzz生成或变异)在产生后会立刻执行,若产生新覆盖则进一步使用triageQueue进行分类
2. triagequeue:
① triageQueue则是用来对genfuzz新生成或突变得到并且有新覆盖的种子进行分析的队列。
通过对发现新信号的程序进行深入分析,确定哪些系统调用产生了新信号,为有价值的程序创建最小化版本。
② 包含的程序类型主要是执行过程中发现新信号的普通程序(非候选程序),以及通过变异或生成产生的有价值程序。
③ 当执行不带progCandidate标志的程序发现新信号时,程序被加入triageQueue
具体的处理流程如下:
1.执行deflake过程,确认信号是稳定的
2.对每个产生新信号的系统调用进行处理
3.如果程序未最小化,执行最小化
4.将最小化后的程序保存到语料库
5.可能启动smash、hints.或fault injection任务进一步探索
3. smashqueue:
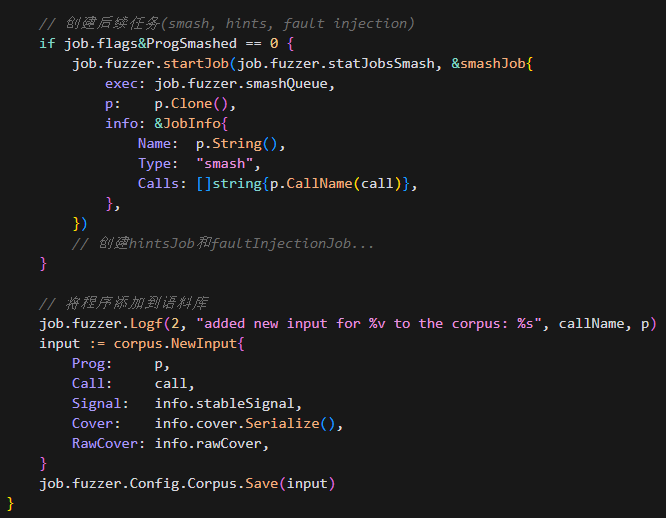
smashqueue的内容:在triageJob中,若一个程序有价值,则将它保存到corpus和对它创建smashJob是同时进行的。
首先创建smashJob任务(以及可能的hintsJob和faultInjectionJob),并在创建任务时直接获得了程序的克隆。
然后将程序保存到语料库。
这两个操作是顺序执行的,但在同一个函数中完成,没有依赖关系。
当创建smashJob时,它不会立即执行,而是通过startJob方法启动一个新的goroutine
在smashJob的run方法中,它会创建多个变异后的程序请求,并提交到smashQueue。
1.程序通过triage确认有价值后:
① 在triageJob.handleCall方法中处理
② 程序被最小化
③ 创建smashJob(以及可能的hintsJobi和faultInjectionJ
④ 将程序保存到corpus
2.smashJob的执行:
① smashJob在新的goroutinel中运行
② 直接使用传入的程序克隆,不需要从corpus获取
③ 对程序进行多次变异
④ 将变异后的程序提交到smashQueue执行
3.smashQueue的处里:
① smashQueue是一个FIFO队列
② 通过queue.Alternate机制限制执行频率
③ 当轮到smashQueue时,会取出一个请求执行
1. smashJob说明
smashQueue:类似地,当一个程序确认提供了新覆盖率并被添加到语料库后,系统会创建一个 smashJob。smashJob 也是作为独立任务运行,它会使用 smashQueue 作为执行器来提交变异后的程序。
1.smash:对已知有价值的程序进行深度变异,尝试发现新的执行路径
目的:
① 对已知有价值的程序进行集中探索
② 通过多次变异增加发现相关代码路径的机会
③ 利用已知的"好程序"作为基础,而不是随机生成
固定迭代次数:对同一个程序进行25次变异 深度变异:每次都克隆原始程序并应用变异 变异方法:使用Mutate()方法,与普通变异相同,但专注于特定程序 信号收集:设置ExecFlagCollectSignal标志收集覆盖率信号 统计跟踪:使用statExecSmash统计计数器
2.hints:操作利用内核比较指令的信息来指导程序变异,针对性地生成可能触发新路径的输入
目的如下:
① 利用内核比较指令信息指导变异
② 针对条件分支生成可能走向不同路径的输入
③ 提高发现新路径的效率,特别是对于复杂条件判断
比较指令收集:执行3次程序,收集内核中的比较指令信息 稳定性过滤:取多次执行的交集,过滤掉不稳定的比较 限制应用:使用hintsLimiter限制比较指令数量,避免资源浪费 定向变异:使用MutateWithHints()方法,根据比较指令定向变异 即时执行:每次变异后立即执行并收集信号
1.1为什么要执行3次:
内核执行的非确定性:相同程序在不同时间执行,由于调度、中断、内存布局等因素,可能触发不同的代码路径
比较操作的波动性:某些比较操作可能因为系统状态不同而时有时无。1.2取交集过滤的机制:
若3次执行的比较操作如下例所示:
第1次执行收集到:{(pc1, 100, 200), (pc2, 0x1000, fd), (pc3, 5, len)}
第2次执行收集到:{(pc1, 100, 200), (pc2, 0x1000, fd), (pc4, 999, tmp)}
第3次执行收集到:{(pc1, 100, 200), (pc2, 0x1000, fd), (pc5, 0xFF, flag)}
则最终稳定的比较操作:{(pc1, 100, 200), (pc2, 0x1000, fd)} // 只有这两个在3次执行中都出现
目的:过滤掉偶然或不稳定的比较值,只保留可重现的2.1hintsJob并不能“精准地生成能够触发特定代码路径的参数值”
特点在于:它不是盲目地修改参数值,而是基于程序实际执行过程中内核的条件分支逻辑,
p.MutateWithHints(job.call, comps, func(p *prog.Prog) bool {// 将comps中的值替换到系统调用参数中// 执行变异后的程序
})完善后的表述如下:
hintsJob通过对同一种子执行3次,只收集某个带来新覆盖的特定系统调用执行路径中的内核比较操作,取交集保留稳定出现的比较值,然后通过shrinkExpand算法的三种核心变换(位宽截取、符号扩展、字节序转换)将这些比较操作数只替换到对应特定系统调用的参数中完成变异。这种机制基于该系统调用当前覆盖路径中的条件判断逻辑,能够发现程序执行过程中涉及的边界值、常量和条件,通过单点突破的方式生成可能触发不同分支路径的参数组合,提高了变异的针对性和覆盖率发现效率,但并不具备主动发现未覆盖分支的能力。
特定系统调用:一个种子有新覆盖→通过triage→加入corpus并执行smash→执行hintsJob,此处指的是第一步中那个带来新覆盖的系统调用,而不是指的hintsJob中3次执行带来的新覆盖的系统调用,且如果有多个系统调用带来新覆盖,syzkaller会为每个系统调用创建独立的hintsJob实例并行处理。2.2 shrinkExpand算法的三种核心变换:
2.2.1 位宽截取(Shrink)
原始参数值: 0x12345678
8位截取(width=1): 0x12345678 & 0xFF = 0x78
CompMap中收集到:(pc, 0x78, 0xAB)
匹配成功!
生成替换值:
保留高位 | 替换低位 = (0x12345678 & 0xFFFFFF00) | 0xAB = 0x123456AB2.2.2 符号扩展(Expand)
原始参数值: 0xFF (8位的-1)
检查符号位: 0xFF & 0x80 != 0 (是负数)
16位符号扩展: 0xFF | 0xFF00 = 0xFFFF
CompMap中收集到:(pc, 0xFFFF, 0xFFFE)
匹配成功!
生成替换值:
低8位替换为0xFE: 0xFE (8位的-2)2.2.3 字节序转换(Endian Swap)
原始参数值: 0x0800 (小端序的ETH_P_IP)
小端序查找: 在compMap中查找0x0800 -> 未找到
大端序转换: swapInt(0x0800, 2) = 0x0008
大端序查找: 在compMap中查找0x0008 -> 找到匹配!
CompMap中收集到:(pc, 0x0008, 0x86DD) // IPv6协议号
匹配成功!
生成替换值:
转换回小端序: swapInt(0x86DD, 2) = 0xDD86
最终替换值: 0xDD86 (小端序的ETH_P_IPV6)3.fault injection:在系统调用执行过程中注入故障,模拟资源不足、权限问题等错误情况
目的:
① 测试内核对错误情况的处理能力
② 探索错误处理路径中的潜在漏洞
③ 模拟各种异常情况,提高测试覆盖面
逐步注入:从1到100,逐步增加故障注入点 设置FailNth:通过设置Props.FailNth属性指定故障注入点 执行检查:检查是否成功注入故障,如果未成功则停止 统计跟踪:使用statExecFaultInject统计计数器
2. 与genfuzz中突变模式的区别
不同点:
smash:通用变异,多次尝试,广泛探索
hints:定向变异,利用比较指令信息,精确探索
fault injection:错误注入,探索错误处理路径
共同点:
① 都是在有价值程序的基础上进行
② 都在triageJob的handleCall方法中触发
③ 都使用smashQueue执行,通过queue.Alternate机制控制频率
分析fuzzer.go和job.go,szkaller的程序生成和变异机制可以总结为:
① 生成源:
全新生成:使用目标规范和选择表生成随机程序
变异:从语料库选择程序进行变异
碰撞:将程序转换为并发执行版本
② 执行流程:
生成/变异的程序直接执行,不进入队列
执行结果由processResult处理
发现新信号的程序创建triageJob进入triageQueue
③ 分类处理(triagequeue及triagejob):
triageJob确认信号稳定性
最小化程序,保留产生新信号的部分
将有价值的程序添加到语料库
④ 进一步探索:
对添加到语料库的有价值的程序启动smash任务进行深度变异
编译任务包括启动hints,collide,fault injection三种smash任务
3. alternate机制:平衡探索与利用
alternate机制通过控制smashQueue的请求返回频率来防止其独占资源。
它不会影响其他队列的正常执行,只在轮到smashQueue时根据skipQueue参数决定是否返回请求。例如当skipQueue=3时,每3次轮到smashQueue会有1次返回nil,这确保了其他队列能获得足够的执行机会,同时smashQueue仍能定期执行以探索新输入。
Alternate机制的主要目的是控制队列访问频率,让某个队列不会过于频繁地被访问,从而给其他队列更多的执行机会:
资源分配平衡:通过每隔
nth次返回nil,强制系统跳过这个队列,转而去尝试其他队列或生成新的测试用例。探索与利用平衡:在fuzzing中,需要平衡"利用"(执行已知有效的测试用例变异,如smashQueue中的请求)和"探索"(生成全新的测试用例)。Alternate机制帮助维持这种平衡。
防止单一任务类型dominate:防止某些任务(如smash任务)由于数量多而占用所有资源,确保其他类型的任务也有机会执行。
跳过smashQueue后的执行流程如下:
在fuzzer.go中,队列的执行顺序是这样设置的:
ret.source queue.order(ret.triageCandidateQueue,ret.candidateQueue,ret.triageQueue,queue.Alternate(ret.smashQueue,skipQueue),queue.Callback(fuzzer.genFuzz),
}当Alternate机制决定跳过smashQueue (即当a.seq.Add(1)%int64(a.nth) == 0 为true
时):
1.a.Next()将返回nil
2.在orderImpl.Next()方法中,当一个source返回nil时,它会尝试下一个source
3.在这种情况下,下一个source是queue.Cal1back(fuzzer.genFuzz)
所以当smashQueue被跳过时,系统会转而执行fuzzer.genFuzz()来生成新的测试用
例。
被跳过的smashQueue任务会重新被执行,被跳过的smashQueue中的任务不会丢失,它们仍然保留在队列中等待下次机会执行。
关键要理解的是Alternate机制只是暂时跳过了对队列的访问,而不是跳过了队列中的特定任
务:
1.当a.Next()返回nil时,只意味着这一次不从smashQueue中获取任务
2.在下一次请求中,如果不触发跳过条件,系统会正常从smashQueue中获取任务
3.队列中的所有任务按照队列自身的顺序被处理,不会因为Alternate机制而改变顺序或丢弃任务
一个示例如下:
假设skipQueue = 3(每3次跳过一次),执行流程大致如下:
1.第1次尝试获取任务:检查smashQueue,获取一个任务并执行
2.第2次尝试获取任务:检查smashQueue,获取一个任务并执行
3.第3次尝试获取任务:计算seq%3=为true,跳过smashQueue,转而执行genFuzz()
4.第4次尝试获取任务:检查smashQueue,获取一个任务并执行
…以此类推
通过这种机制,系统在大部分时间执行smashQueuer中的任务,但也会定期(每nth次)跳过
smashQueue去执行genFuzz,生成全新的测试用例。
1.由于alternate机制的存在,syzkaller的执行流程并不严格遵循论文中所描述的"先完成所有种子的smash再进行常规突变"的模式。事实上,系统会在smash处理过程中就开始执行常规突变(通过genFuzz)。
2.fuzzer.Config.Corpus.ChooseProgram(rnd)从语料库中随机选择一个程序进行突变时,并不会检查该程序是否已经完成了smash处理。
因为sykaller引入了alternate机制,每3次smash都会跳过一次,然后去执行genfuzz,所以可能存在的情况是:corpus中的种子A对应的smash任务还没被执行就被暂时跳过,此时系统执行genfuzz任务,恰好从corpus中随机挑选A进行突变,然而此时A并没有经过smash。所以alternate机制的存在,使得这句话并不完全正确。
2. Job和queue的关系
1. job分析
triageJob 用于验证程序执行中发现的潜在新覆盖率(Coverage),并通过多次执行(Deflaking)确认其稳定性。主要流程包括:
1.信号收集与验证:通过多次执行程序(deflakeNeedRuns 和 deflakeMaxRuns 控制次数),提取稳定的信号(stableSignal)和新信号(newStableSignal)。
2.最小化测试用例:若程序未被最小化(ProgMinimized 标志未设置),调用 prog.Minimize 方法生成更简洁的测试用例,同时保留触发新覆盖的能力。
3.后续任务调度:根据配置启动 smashJob(程序变异探索)、hintsJob(基于比较操作数的变异)和 faultInjectionJob(错误注入测试),进一步挖掘潜在漏洞。
2. 其他 Job 类型的功能
1.smashJob
目标:通过随机变异(Mutate)和异步调用碰撞(AssignRandomAsync)生成新测试用例。
执行次数:默认 25 次(iters 常量),每次变异后执行并收集信号。
2. hintsJob
核心逻辑:利用 KCOV 收集的比较操作数(Comps),生成与原始参数相关的变异程序。
过滤机制:通过 hintsLimiter 限制无效变异,避免资源浪费。
3. faultInjectionJob
错误注入:在特定系统调用中注入失败(FailNth),验证程序的容错性。
终止条件:检测到错误未被触发时停止(CallFlagFaultInjected 标志)。
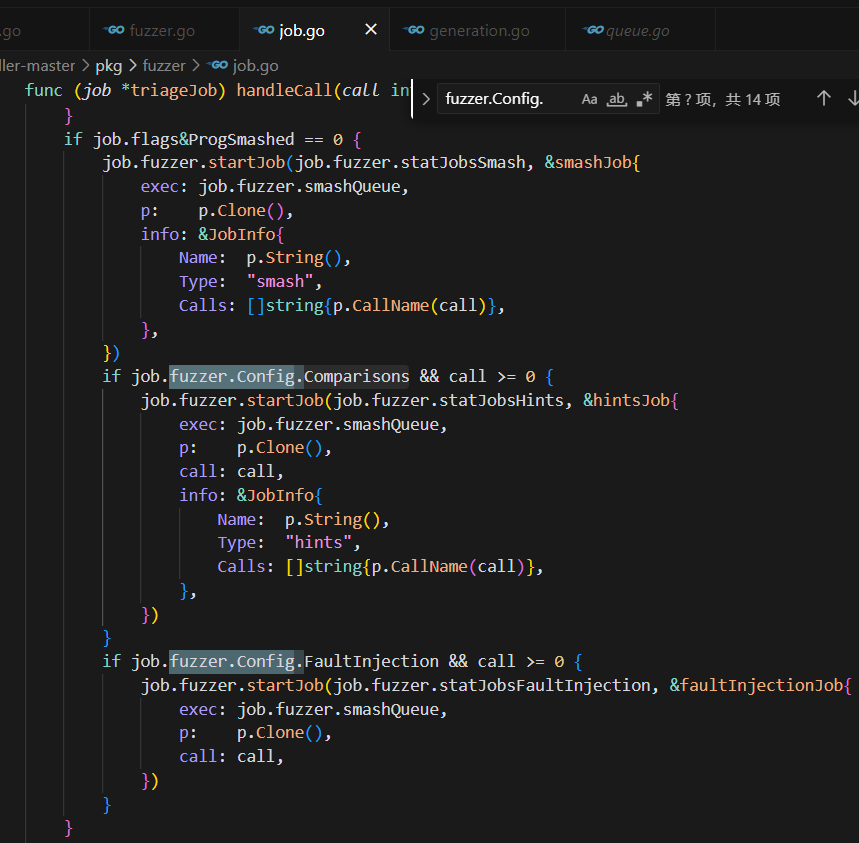
4. 执行逻辑:
① smashJob必定启动(如果程序未被smashi过)
② hintsJob条件启动(需要配置Comparisons=true且call>=g)
③ faultInjectionJob条件启动(需要配置FaultInjection=-true且cal1>=g)
这些条件是独立判断的,不互斥。也就是说,在完整配置下,一个高价值种子会同时触发这三个ob的启动,它们会被加入到工作队列中异步执行。
1. smashJob的三种具体操作
三种操作依据config定义的配置进行选择,smash的默认策略是针对固定种子的25次突变。
2. smashJob和smashQueue的关系:
① smashJob:是一个结构体,表示对已有程序进行"smash"(变异)的任务。在job.go中定义,其主要任务是多次变异同一个程序,然后执行它以查找新的覆盖率。
② smashQueue:是一个队列,用于存储smashJob任务。
③ 关系:当一个程序通过triage过程被确认为有价值(提供了新的覆盖率)后,系统会创建一个smashJob并提交到smashQueue中。smashJob会对原程序进行多次变异(约25次迭代),每次变异后执行以查找更多的覆盖率。这一点在triageJob.handleCall方法中可以看到。
3. triageJob和triageQueue的关系:
① triageJob:是一个结构体,表示对程序进行"triage"(分类筛选)的任务。其主要任务是确定一个程序是否真的提供了新的覆盖率,如果是,则进行最小化并添加到语料库。
② triageQueue:是一个队列,用于存储triageJob任务。当一个程序执行后发现潜在的新覆盖率时,系统会创建一个 triageJob,并将它作为一个任务放入队列执行系统中。这个任务会在后台执行,但不是直接放入任何队列中,而是作为一个独立的任务运行。triageJob 在执行过程中会使用 triageQueue.Append() 返回的执行器来提交请求,以确保在执行过程中产生的请求能够被处理。
③ 关系:当执行一个程序时,如果检测到可能的新覆盖率,系统会创建一个triageJob并提交到triageQueue或triageCandidateQueue中(取决于程序的来源)。triageJob会多次执行程序以确认覆盖率是否稳定,然后对程序进行最小化,最后决定是否将其添加到语料库中。这一点在Fuzzer.processResult方法中可以看到:
queue的优先级顺序只决定了"下一个从哪个队列获取请求",而不会阻塞后台任务的执行:
1.后台任务并行执行:当系统创建一个triageJob或smashJob时,它们作为独立的goroutine在后台运行,不会等待队列的执行顺序。这一点在fuzzer.startJob函数中可以看到:
2.请求执行顺序:当系统需要决定下一个执行什么时,它会按照上述优先级顺序从队列中获取请求。但这并不意味着后台任务会被阻塞等待。
问题自查
Q1.在运行开始时corpus.db中的种子会全部转为candidates,从而内存中corpus的数量为空,是否意味着初始corpus中的程序根本无法对新种子的生成产生任何影响?
Re:的确最开始的选择表无法对新种子产生影响,但以下机制确保初始种子在 较短时间内即可影响后续变异和生成
1.启动时:corpus.db → 加载为 Candidate → 加入 candidateQueue。
初始种子被加载为候选程序,并通过AddCandidates加入candidateQueue:
func (fuzzer *Fuzzer)AddCandidates(candidates []Candidate){fuzzer.statCandidates.Add(len(candidates))for,candidate :range candidates{req =&queue.Request{Prog:candidate.Prog,/初始种子程序ExecOpts:setFlags(flatrpc.ExecFlagCollectsignal),stat:fuzzer.statExecCandidate,Important:true,}fuzzer.enqueue(fuzzer.candidateQueue,req,candidate.Flags progCandidate,0)}
}作用是将corpus..db中的程序标记为候选(progCandidate),加入队列等待验证。
2.执行验证:候选程序被调度执行(candidateQueue 的 Submit 方法)。
验证逻辑(processResult方法):
候选程序执行后,通过processResult处理结果,验证通过后加入Config.Corpus:
func (fuzzer *Fuzzer)processResult(req *queue.Request,res *queue.Result,flags ProgFlags,attempt in//如果没有触发新信号(Len(triage),=0),且是来自corpus的候选程序if len(triage) == 0&& flags&ProgFromcorpus !=0 &attempt < maxcandidateAttempts{//重试候选程序(最多3次)fuzzer.enqueue(fuzzer.candidateQueue,req,flags,attempt+1)return false}//如果通过验证(不再重试),将程序保存到Config.Corpusif flags&progcandidate !=0{fuzzer.Config.Corpus.Save(req.Prog,,.,) //关键代码}return true
}关键条件:
① len(triage)==0:候选程序未触发新的覆盖信号(无需进一步分析)。
② flags&ProgFromCorpus!=0:程序来自初始语料库。
③ attempt>=maxCandidateAttempts:已达到最大重试次数(默认3次)
保存操作:
① fuzzer.Config.Corpus.Save
② 将程序加入内存中的正式语料库。
3.结果处理:
若程序未触发新覆盖信号(
len(triage) == 0),且重试次数耗尽(attempt >= 3),则调用Save加入Config.Corpus。(save函数的定义在corpus.go中,调用则是在pkg/fuzzer/job.go的func (job *triageJob) handleCall函数中)
保存到Corpus的代码(corpus.Corpus.Save)
在pkg/corpus包中,Save方法将已验证的程序加入内存:
//pkq/corpus/corpus.go
func (c *Corpus)Save(p *prog.Prog,...){c.mu.Lock()defer c.mu.Unlock()C.programs=append(c.programs,p) //加入内存//其他逻辑(如去重、持久化到corpus.db)
}作用:将程序添加到Config..Corpus.programs,后续变异和ChoiceTable更新会使用此列表。
Q2.执行过程中会在什么时候执行genfuzz生成或突变种子?
genfuzz()通过概率强制分配了突变和生成的比例,并在以下两个情况被启用:
① 队列空闲:当更高优先级的队列(triageCandidateQueue、candidateQueue 等)无任务时。
② 负载均衡:每完成 3 次 smashQueue 请求后强制穿插一次生成。
具体的说明如下:
1.队列调度触发
genFuzz是Syzkaller输入生成的核心入口,其触发与执行队列的调度策略直接相关:
① 队列优先级:在execQueues的初始化中,genFuzz被注册为queue.Callback类型的源(source)优先级低于其他队列(如triageCandidateQueue、candidateQueue等)。当高优先级队列(如候选程序复现、崩溃分析)无任务时,genFuzz会被调用以生成新输入。
② 交替策略:通过queue.Alternate函数,smashQueue(负责"暴力变异")与genFuzz交替执行,避免资源过度集中在单一生成策略上。
2.生成策略选择
在genFuzz内部,通过概率控制决定生成方式:
mutateRate := 0.95
if !fuzzer.Config.Coverage{mutateRate = 0.5
}
if rnd.Float64()<mutateRatereq = mutateProgRequest(fuzzer,rnd) //变异现有程序
} else {req = genProgRequest(fuzzer,rnd) //生成全新程序
}默认策略:95%的概率选择变异现有程序(mutateProgRequest),5%生成新程序( genProgRequest )。
覆盖率信号缺失时的调整:若未启用覆盖率反馈(Config.Coverage=-false),变异概率降至50%,以增加新程序生成频率,弥补弱信号下的探索不足5。
Q3. 新生成和突变种子的队列分配
简要处理流程表述如下:
1.生成变异的程序直接执行,不进入任何队列
2.执行后,如果发现新信号,会创建triage]ob并放入triageQueue
3.triageJob会进一步分析程序,确定哪些系统调用产生了新信号
4.只有经过triage确认有价值的程序才会被添加到语料库
较为具体的表述:
1.生成变异程序:
① genFuzz根据概率(通常是95%)决定是变异现有程序还是生成新程序
调用
②mutateProgRequest或genProgRequest生成请求对象
2.准备执行:
①调用fuzzer.prepare(req,6,B)为请求设置回调函数
② 这个回调函数是proce5 sResult,它会在执行完成后处理结果
3.返回情求:
①genFuzz返回准备好的请求对像
②这个请求会被Nxt()方法返回给调用者(通常是执行器)
4.执行程序:
①执行器执行程序并收集结果
②执行完成后触发processResult回调
5.处理结课:
①processResult分析执行结果
②如果发现新信号,创健triageJob并放入triageQueue
③这是程序首次进入队列系统的时刻
genfuzz函数中涉及突变的mutateProgRequest和涉及生成的genProgRequest函数在同路径的job.go下
1.先生成/变异程序,然后直接执行,而不是先分配队列。避免了在队列中积累大量无价值的程序。同时变异的程序是从当前的corpus而不是其它队列中选取程序作为变异素材。
2.执行后,如果发现新信号,会创建triageJob并放入triageQueue进一步分析程序,包括进行最小化和保存至corpus等操作。
3.只有经过triage确认有价值的程序才会被添加到语料库
1.genProgRequest函数分析
func genProgRequest(fuzzer *Fuzzer,rnd *rand.Rand)*queue.R{p := fuzzer.target.Generate(rnd,prog.RecommendedCalls,fuzzer.ChoiceTable())return &queue.Request{Prog: P,ExecOpts:setFlags(flatrpc.ExecFlagCollectSignal),Stat:fuzzer.statExecGenerate,}
}分析如下:
1.调用target.Generate()生成全新程序
2.使用三个关键参数:
- 随机数生成器(rnd)
- prog.RecommendedCalls-推荐的系统调用数量
- fuzzer.ChoiceTable()-基于语料库构建的选择表,指导系统调用选择概率
3.生成的请求特点
- 设置ExecF1 agCollectSignal标志,表示需要收集覆盖率信号
- 使用statExecGenerate统计计数器跟踪生成的程序执行次数
- 生成的程序直接返回执行,不进入任何队列
2.mutateProgRequest函数分析
func mutateProgRequest(fuzzer *Fuzzer,rnd *rand.Rand)*queup :fuzzer.Config.Corpus.ChooseProgram(rnd)if p =nil{return nil}newP :p.Clone()newP.Mutate(rnd,prog.RecommendedCalls,fuzzer.ChoiceTable(),fuzzer.Config.NoMutateCalls,fuzzer.Config.Corpus.Programs(),}return &queue.Request{Prog: newP,ExecOpts:setFlags(flatrpc.ExecFlagCollectSignal),Stat: fuzzer.statExecFuzz,}
}实现分析如下:
1.从语料库中随机选择一个程序:fuzzer.Config.Corpus.ChooseProgram(rnd)
- 如果语料库为空,返回nil
- 克隆选中的程序,避免修改原始程序
- 调用Mutate()方法进行变异,参数包括:
1.随机数生成器(rnd)
2.prog.RecommendedCal1s-推荐的系统调用数量
3.fuzzer.ChoiceTable()-选择表
4.fuzzer.Config.NoMutateCal1s-不应变异的调用列表
5.fuzzer.Config.Corpus.Programs()-所有语料库程序,用于交叉变异重点信息:
1. 调度过程的优先级
syzkaller默认的优先级是覆盖率信号的数量。详见pkg/corpus/prio.go:
func (pl *ProgramsList)saveProgram(p *prog.Prog,signal signal.Signal){prio:=int64(len(signal) //优先级=覆盖率信号数量if prio ==0{ //零信号保护机制prio = 1}pl.sumPrios +prio //更新总优先级pl.accPrios=append(pl.accPrios,pl.sumPrios) //记录累积值pl.progs=append(pl.progs,.p) //添加新程序
}选择策略也在该文件的chooseprogram函数中实现,即按照优先级高低随机选择。
2. 强制规定突变及生成比例
在fuzz.go中的genfuzz()通过概率强制分配了突变和生成两种任务的比例,但需要注意的是此处的突变仅包含mutate,不包含smash。
genFuzz方法实现输入生成决策:
func (fuzzer *Fuzzer)genFuzz()*queue.Request{mutateRate:=0.95 //默认95%概率变异现有程序if !fuzzer.Config.CoveragemutateRate=O.5/无覆盖率反馈附降低变异比例}//随机选择生成新程序或变异己有程序if rnd.Float64()<mutateRate{req mutateProgRequest(fuzzer,rnd)}else{req genProgRequest(fuzzer,rnd)}
}① 变异策略:包含类似文献”的位翻转(bitflip)和魔术值替换(magic number),通过prog.Mutate
实现结构化变异。
② 碰撞测试:
Config.Collide启用时,33%概率生成并发冲突场景(randomCollide),模拟真实环境竞态条件。
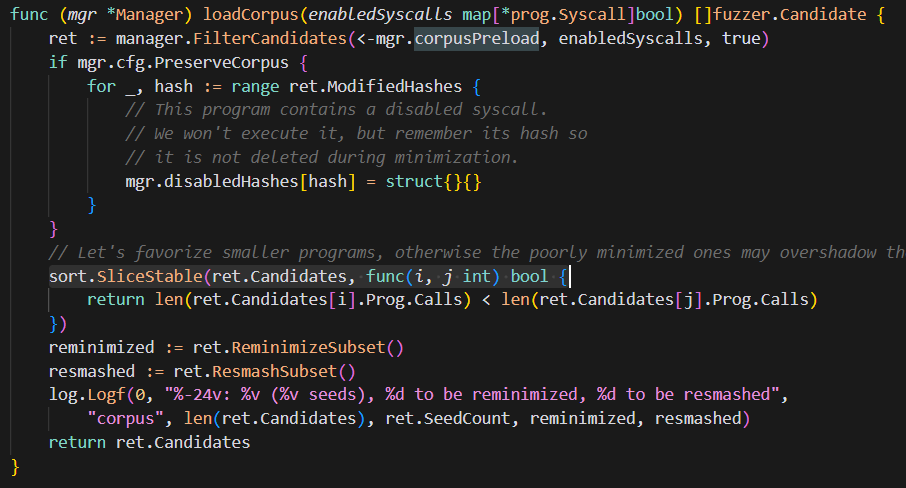
3. 初始种子稳定排序
corpu.db→candidate会经过一次稳定排序,按照系统调用数量排序,数量少的种子将被优先执行。这种排序处理具有以下好处:
调用次数少的程序优先执行
相同复杂度的程序保持原始发现顺序
通过稳定排序避免随机性干扰
优先选择较小的程序(即更简化的测试用例),避免那些未优化的复杂用例占据过多资源,影响整体测试效果。
4. 代码覆盖率统计规则
Syzkaller 与 AFL 一致,是使用边覆盖率来统计覆盖情况的,因此他会将实际记录得到的每个基本块的记录值 PC 和前一个基本块的 PC 值进行一个哈希之后的异或值来唯一标识一条边,将该值称为 signal ,这个过程中存在过滤函数和去重函数,会进行一定的筛选。然后 Syzkaller 通过维护一个字典,该字典的键是 signal 来判断每次执行是否有新覆盖产生。