Class28批量归一化
Class28批量归一化

批量归一化
批量归一化(Batch Normalization,简称BN)是一种用于加速神经网络训练、稳定训练过程并提高模型性能的技术。它最早由Ioffe和Szegedy在 2015 年提出,在深度学习中非常常见。
使用批量归一化的原因
在训练神经网络时,随着层数加深,模型的输入分布会不断变化,这会导致:
梯度消失/爆炸
学习变慢,需要精细调整学习率
权重初始化敏感
BN要求在每一层的输入上进行规范化,使得它们的均值为 0,方差为 1,从而缓解内部协变量偏移。
批量归一化的核心
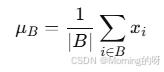

计算当前小批量(Batch)中输入特征的平均值,用来中心化数据。
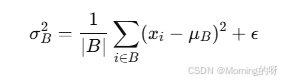

计算当前小批量中特征的方差,用于将数据缩放到单位方差,同时加上 ε 保证数值稳定。
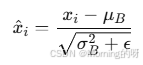
将输入𝑥𝑖变成了均值为 0,标准差为1的值。
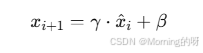
BN 又引入了 两个可学习参数:
𝛾:缩放系数
𝛽:平移系数
变为:
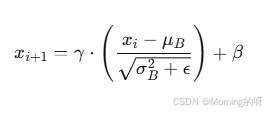
先把输入标准化成均值为0、方差为1的分布,再通过 γ 和 β 进行可学习的线性变换(恢复表达能力)
在神经网络中的位置
对于全连接层:通常放在线性层和激活函数之间
对于卷积层:通常放在卷积层和激活函数之间
BN 的优点
| 优点 | 说明 |
|---|---|
| 减轻内部协变量偏移 | 保持每层输入的稳定性 |
| 加速收敛 | 学习过程更平稳,学习率可以设得更大 |
| 减少对初始化的敏感性 | 权重初始化不需要特别精细 |
| 有一定的正则化效果 | mini-batch 的扰动有助于防止过拟合 |
BN 的局限性
| 局限 | 说明 |
|---|---|
| 对 batch size 敏感 | batch 太小统计量不稳定(如在 RNN、小模型或推理时) |
| 不适用于某些结构 | 如 RNN,不适合用 BN,这时可以考虑 LayerNorm 或 GroupNorm |
| 训练/推理两种模式差异 | 若处理不当(如未区分 train/test 模式),会导致结果异常 |