逻辑回归算法 银行贷款资格判断案例,介绍混淆矩阵与正则化惩罚
目录
一.银行贷款资格判断案例
1.数据介绍与特征分析
2.数据标准化处理
3.数据切分
4.创建模型
5.模型训练与计算正确率
6.分类报告解读
二.介绍混淆矩阵
1.混淆矩阵
2.核心评价指标
三.正则化惩罚
1.正则化惩罚的目的与原理
2.正则惩化方法分类
3.正则化强度参数C
一.银行贷款资格判断案例
creditcard.csv文件部分内容如下:

1.数据介绍与特征分析
- 数据量为143兆,包含28万4808条真实银行贷款数据,每条数据代表一个用户。
- 特征包括V1-V28(脱敏处理后的特征)和amount(未脱敏的收入特征),共29个特征,最后一列为class(贷款结果:0可贷款,1不可贷款)。
- 数据脱敏处理的原因:防止黑客攻击泄露敏感信息(如年收入、婚姻状况等),脱敏后数据通过算法压缩为不易解读的形式(如V1-V28的值在-1到1之间)
2.数据标准化处理
- 问题:amount特征的值范围(0-500)远大于其他特征(-1到1),导致模型训练时权重分配不均。
- 解决方案:
- Z标准化:将数据压缩到均值为0、标准差为1的范围内(适合大部分特征,如V1-V28)。
- 01标准化:将数据压缩到0-1之间(适用于无负值的特征)。
- 选择Z标准化的原因:amount特征与其他特征(V1-V28)的分布更匹配(有正负值,大部分在-1到1之间)。
- 代码实现:使用
StandardScaler对amount列进行Z标准化,并删除无关的time列。
import pandas as pddata = pd.read_csv('creditcard.csv')
# 数据标准化
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
data['Amount']=scaler.fit_transform(data[['Amount']])
data=data.drop(['Time'],axis=1)3.数据切分
将数据切分为训练集(70%)和测试集(30%)。
X=data.iloc[:,:-1]
y=data.iloc[:,-1]
from sklearn.model_selection import train_test_split
train_x,test_x,train_y,test_y=train_test_split(X,y,test_size=0.3,random_state=500)4.创建模型
from sklearn.linear_model import LogisticRegression
lr=LogisticRegression(C=0.01)5.模型训练与计算正确率
将切分号的数据放入训练方法fit()中完成训练,通过predict()方法预测测试集的结果,并计算得分
lr.fit(train_x,train_y)
result=lr.predict(test_x)
score=lr.score(test_x,test_y)
print(score)0.9990988144142879计算得出准确率有0.999即1000人中仅1人判断错误,但我们可以发现模型将所有结果预测为零时,正确率仍为99.9%(28万4807条数据中仅492条类别为一,其余全为1)。
我们可以通过绘图展示数据分布:类别为零28万4315条,类别为一492条,极度不均衡。
import matplotlib.pyplot as plt
class_= pd.value_counts(data['Class'])
class_.plot(kind='bar')
plt.show() 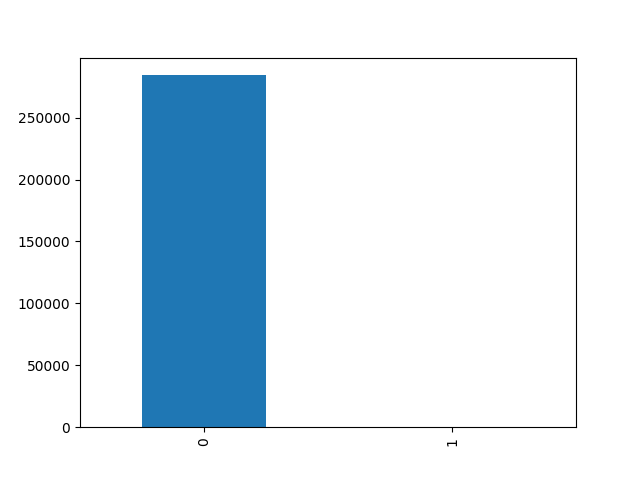
所以我们必须使用接下来的分类报告解读
6.分类报告解读
from sklearn import metrics
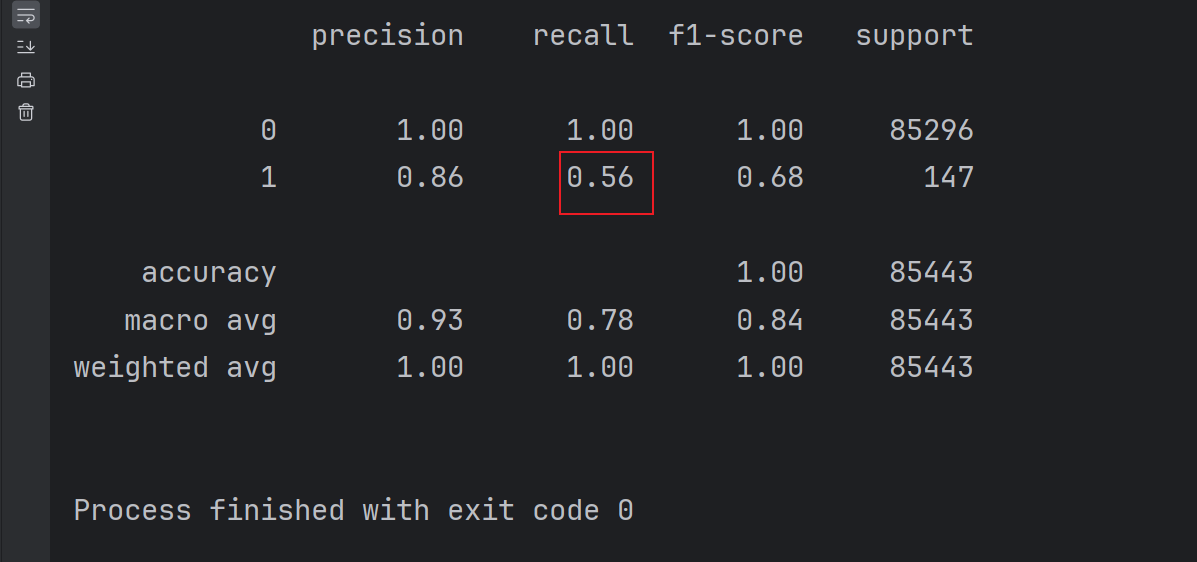
print(metrics.classification_report(test_y,result))
- 使用
classification_report显示:- 类别为零:精确率、召回率、F1值均为1(因模型全预测为零)。
- 类别为一:关键指标仅0.56,表明模型对少数类预测能力极差。
- 银行系统更关注少数类(如贷款违约)的识别,所以当前模型不达标有待后续优化。
二.介绍混淆矩阵
1.混淆矩阵
- 混淆矩阵:将预测结果与真实值分类为四类:
- TP(True Positive):真实为1,预测为1。
- FP(False Positive):真实为0,预测为1。
- FN(False Negative):真实为1,预测为0。
- TN(True Negative):真实为0,预测为0。
2.核心评价指标
- 准确率(ACC):主对角线预测正确的比例((TP+TN)/(TP+FP+FN+TN))。
- 精确率(Precision):预测为1的样本中实际为1的比例(TP/(TP+FP))。
- 召回率(Recall):真实为1的样本中被正确预测的比例(TP/(TP+FN)),银行/医疗等领域更关注此指标。
-
F1值:精确率与召回率的调和平均数(2PrecisionRecall/(Precision+Recall))。
三.正则化惩罚
1.正则化惩罚的目的与原理
- 正则化的核心目的是防止模型过拟合,通过引入惩罚项(L1或L2)使模型参数分布更均匀,避免极端值。
- 过拟合的表现:训练时正确率极高(如100%),但测试时正确率显著下降(如60%),模型泛化能力差。
- 正则化通过调整参数权重(如ω)的分布,抑制对单一特征的过度依赖,提升模型稳定性。
2.正则惩化方法分类
- L1正则化:惩罚项为参数绝对值之和(Σ|ω|),倾向于产生稀疏解(部分参数为0)。
- L2正则化:惩罚项为参数平方和(½Σω²),使参数分布更均匀,默认常用方法。
3.正则化强度参数C
- C是正则化系数λ的倒数(C=1/λ),控制惩罚力度:
- C越小(λ越大):惩罚力度越强,模型更简单,防止过拟合。
- C越大(λ越小):惩罚力度越弱,模型复杂度可能升高。
- 常用C值:0.01、0.1、1(默认)、10、100、1000,需通过调参(K折交叉验证方法)获取最优值
下一篇进行讲解进一步的优化如交叉验证方法和调整阈值等