Dify知识库分段策略详解:通用分段 vs 父子分段
Dify知识库分段策略详解:通用分段 vs 父子分段
文本分段是构建高效知识库的核心环节。Dify提供两种分段策略:通用分段(扁平式)和父子分段(层级式),本文将深入解析其差异与选型指南。
一、核心工作逻辑对比
| 特性 | 通用分段 | 父子分段 |
|---|---|---|
| 存储结构 | 独立扁平片段 | 树状层级结构(父块+子块) |
| 检索单元 | 分段本身 | 子块 |
| 返回内容 | 命中的独立分段 | 子块关联的父块全文 |
| 上下文关联 | 可能割裂跨片段逻辑 | 保留“父-子”从属关系 |
二、技术参数配置
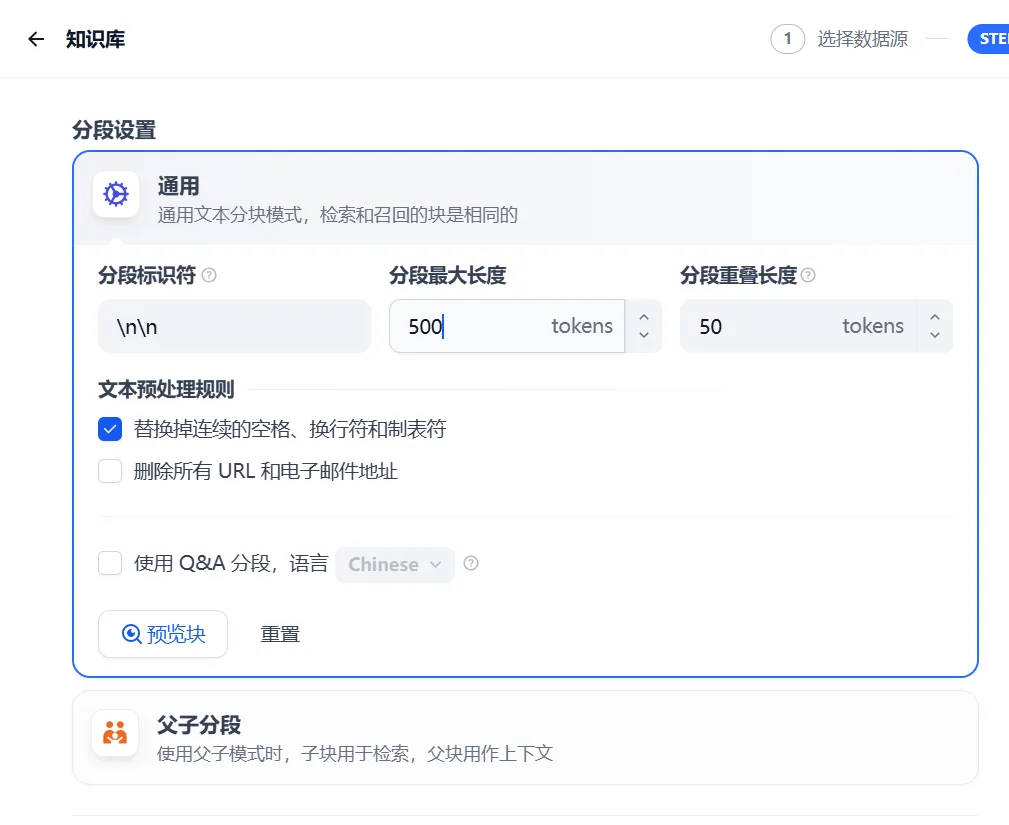
1. 通用分段(通用文本分块模式)
- 分段标识符:
\n\n(空行) - 分段最大长度:
500 tokens(约300汉字) - 分段重叠长度:
50 tokens - 工作流程:
- 遇到两个连续换行符时触发分段
- 检查当前分段是否≤500 tokens
- 若超过500 tokens:
- 截取前500 tokens作为独立分段
- 下一分段头部重复前段末尾50 tokens
- 循环直到文本处理完毕
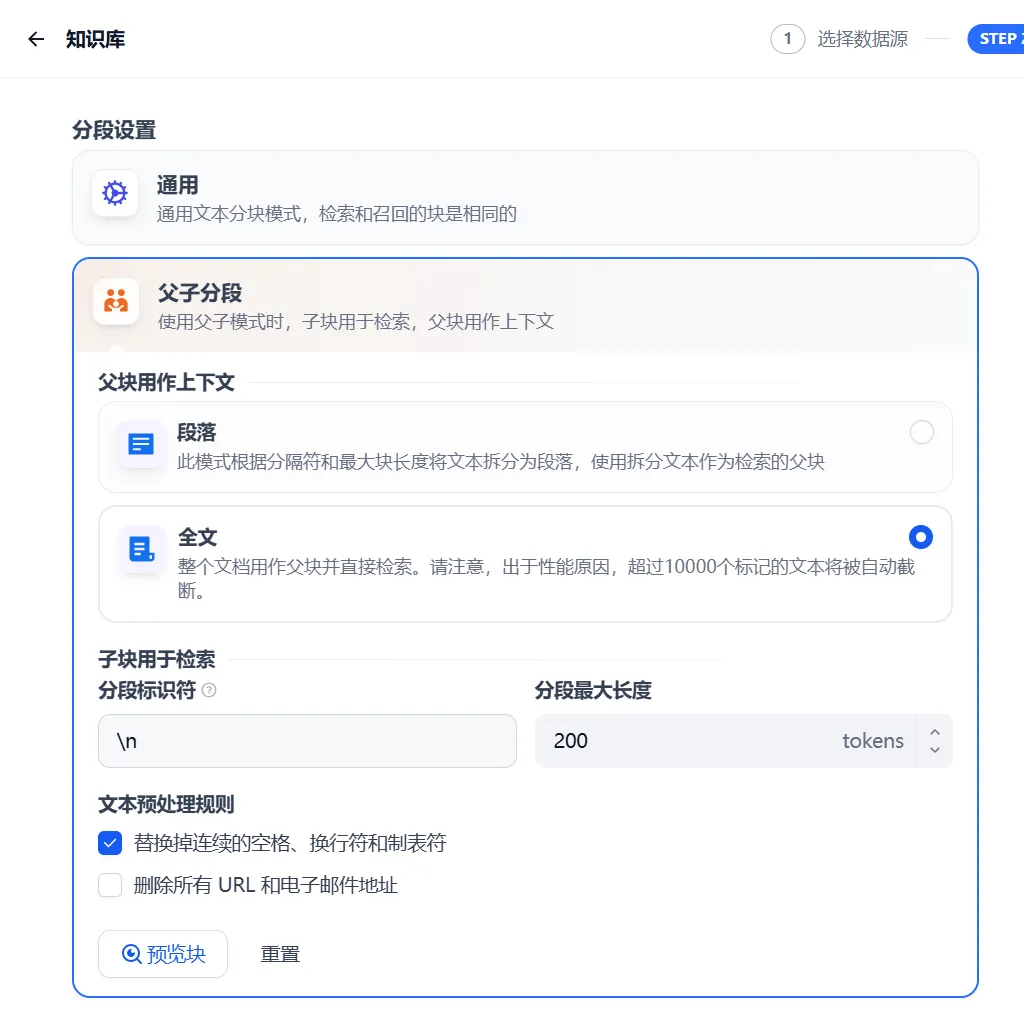
2. 父子分段(层级检索模式)
父块配置(上下文容器):
| 模式 | 标识符 | 最大长度 | 作用 |
|---|---|---|---|
| 段落模式 | \n\n | 500 tokens | 按逻辑段落存储 |
| 全文模式 | 无 | 10,000 tokens | 整个文档作为单一块 |
子块配置(检索单元):
- 标识符:
\n(换行符) - 最大长度:
200 tokens(约120汉字)
工作流程:
- 子块拆分:按换行符切割文本,每块≤200 tokens
- 父块拆分:
- 段落模式:按空行分隔,每块≤500 tokens
- 全文模式:整文档作为父块(超10k tokens自动截断)
- 检索时:
- 通过子块匹配问题 → 定位关联父块 → 返回父块全文
- 通过子块匹配问题 → 定位关联父块 → 返回父块全文
三、四大维度选型指南
| 评估维度 | 通用分段 | 父子分段 |
|---|---|---|
| 知识结构适配性 | ✅ 无层级文本(短新闻/用户评论) | ✅ 强结构文本(手册/论文/API文档) |
| 上下文完整性 | ❌ 可能割裂跨片段逻辑 | ✅ 保留“父-子”从属关系 |
| 检索精准度 | ⭐ 短句/关键词检索高效 | ⭐ 需层级定位的问题(如“XX章节下的YY功能”) |
| 信息冗余度 | ❌ 按长度切割可能含无关信息 | ✅ 父块预过滤减少噪声 |
四、实战选型建议
优先通用分段的场景:
- 处理社交媒体内容、用户评论等碎片化文本
- 文档无显著章节结构(如随笔、短篇新闻)
- 需求为简单关键词匹配
必用父子分段的场景:
- 构建技术文档/产品手册/法律条款等结构化内容
- 需回答“XX章节中关于YY的说明”类问题
- 长文档检索需减少噪声干扰
💡 经验法则:
- 带章节编号的文档 → 父子分段(段落模式)
- 用户生成内容/短文本 → 通用分段
五、关键注意事项
-
父子分段性能限制:
- 全文模式父块超过10,000 tokens会自动截断
- 复杂手册建议使用段落模式避免截断风险
-
重叠机制的双面性:
- 通用分段的50 tokens重叠可缓解截断问题
- 可能引入重复内容,需根据文本特征调整长度