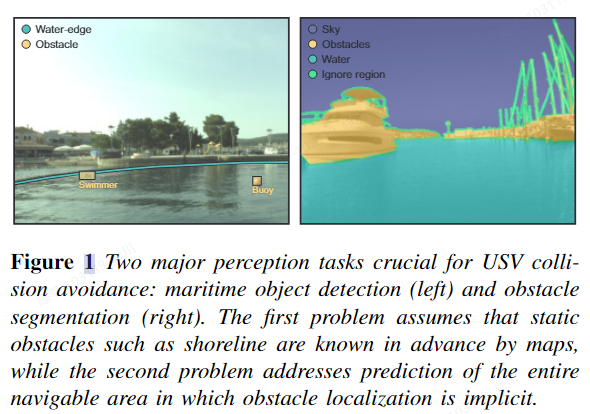
通用障碍物调研
背景分析
通用障碍物检测(General Obstacle Detection)由遥遥领先的华子提出,所谓通用障碍物检测即应检尽检,管你是什么,检测就完事了
而其目的无外乎识别,避障,规划。。。得到更加精准普适的结果为下游任务提供支持,针对GOD(以下代称),归结到根本,检测前景or检测背景(即freespace),对于我司来说,free-space的检测虽然不像道路的语义特征如此明显,但也算非常详尽,所以调研的方法暂时分为障碍物检测和free-space检测两类
另一个很重要的因素即传感器,不同的传感器很大程度上决定了方法选择的不同,目前涉及到检测的3d检测or Occupancy grid等, 多使用点云作为数据源之一,或依赖于高算力,从可行性角度考虑,以下调研不会涉及点云检测
方法调研
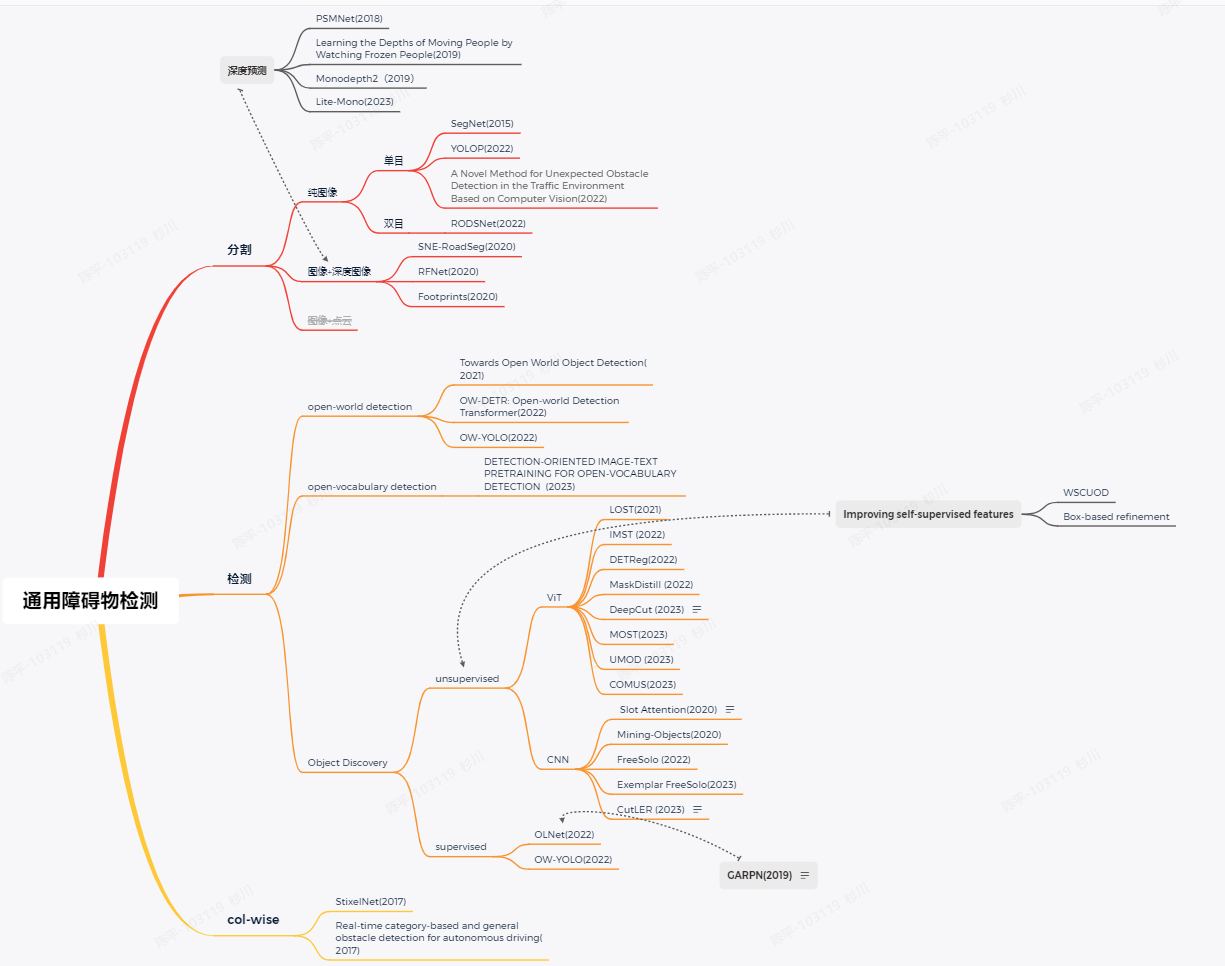
分割
对于free-space检测,由于其形状是不定的,且对于边缘的精度要求要更高,单纯的检测框根本无法满足,基本都是通过分割实现的。
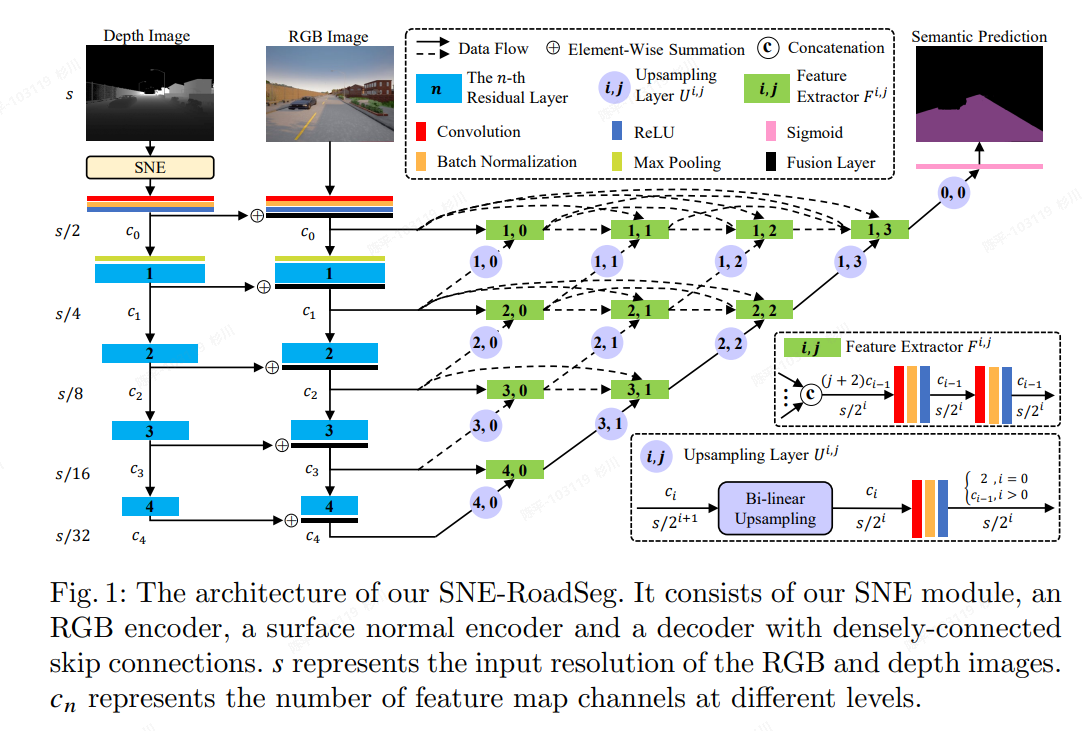
SNE-RoadSeg
- 论文https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123750341.pdf
- 源码https://github.com/hlwang1124/SNE-RoadSeg
- 特点
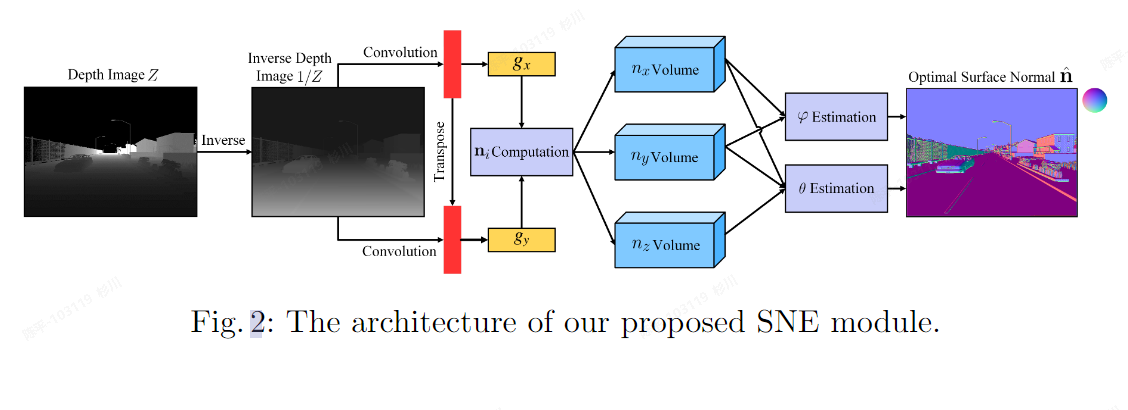
- 提出了surface normal estimator (SNE)模块,可以高效利用深度相机推理物体表面的法向量
- 可视化结果

- ** architecture **
SNE 模块:
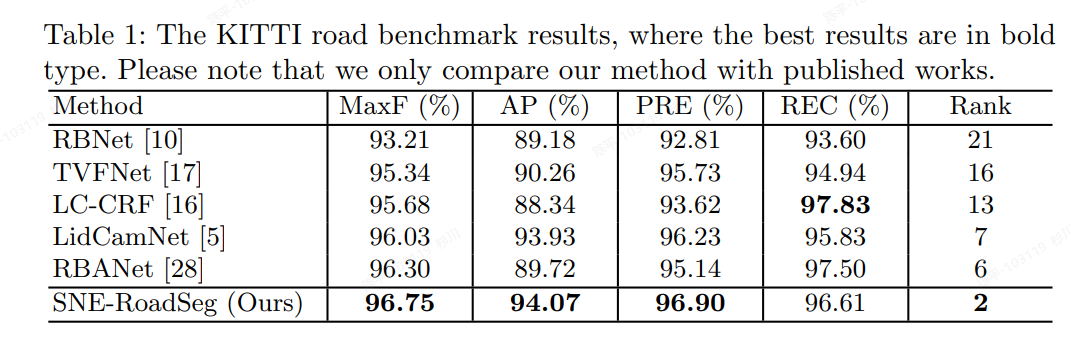
- metric
- 评价
- 直接将深度图作为数据源,并有对应的深度特征处理模块,可以借鉴该部分模型进行使用(如引用深度相机)
- 从可视化的结果来看,推理速度较快,但文中并未给出具体的指标
robot_freespace_seg_Isaac_TAO
- 源码https://github.com/NVIDIA-AI-IOT/robot_freespace_seg_Isaac_TAO/tree/main
- 特点:
- 使用nvidia的开源工具tao进行开发
- 可视化效果

- pipeline
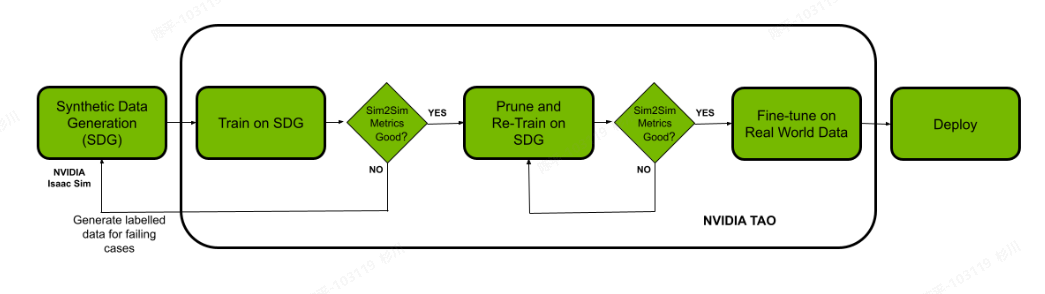
- 评价
- 直接使用NVIDIA的TAO工具,如果硬件支持会方便很多,很多细节优化nvidia已经做好了
- 使用仿真数据,且可以通过 TAO工具直接生成
- 后期模型调优和模块化改进会比较麻烦一些
- 直接使用NVIDIA的TAO工具,如果硬件支持会方便很多,很多细节优化nvidia已经做好了
YOLOP
- 论文:https://link.springer.com/article/10.1007/s11633-022-1339-y
- 源码:https://github.com/hustvl/YOLOP
- 特点:
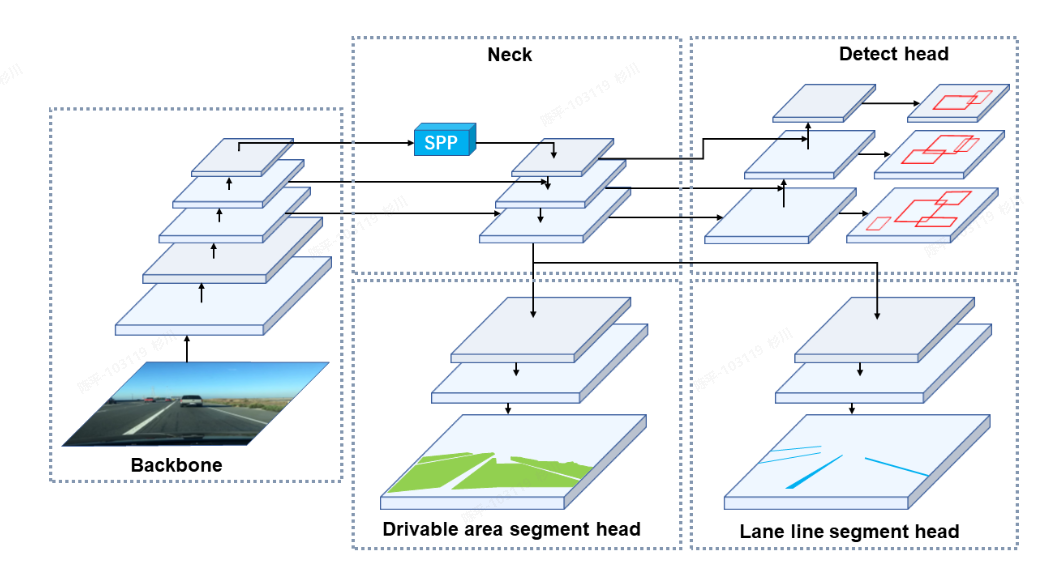
- end2end,快就一个字
- 集成了检测,和分割的多任务(现在的yolov8好像也可以了?)
- 可视化结果

- **architecture **
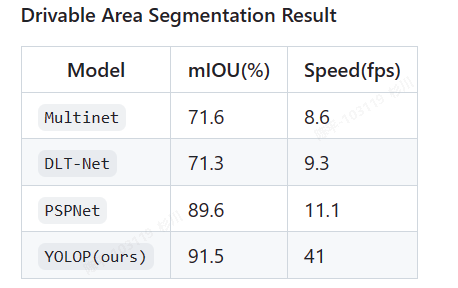
- metric
NVIDIA GeForce 3090
1280× 720×3 -> 640×384×3
- 评价
- 大道至简?重要是提供了一个很新的研究思路,基本是在yolov4的基础上进行二次开发的,速度值得保障~
- 目前基于yolop的二次开发也很多,重要的是确定技术路线
RFNet
- 论文:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9134735
- 代码:-
- 特点:
- 深度相机+特征融合
- 数据集多源融合
- 评价
为不同标注规则的多个数据集扩充提供了一种指导方案,可以在很大程度上节省数据成本

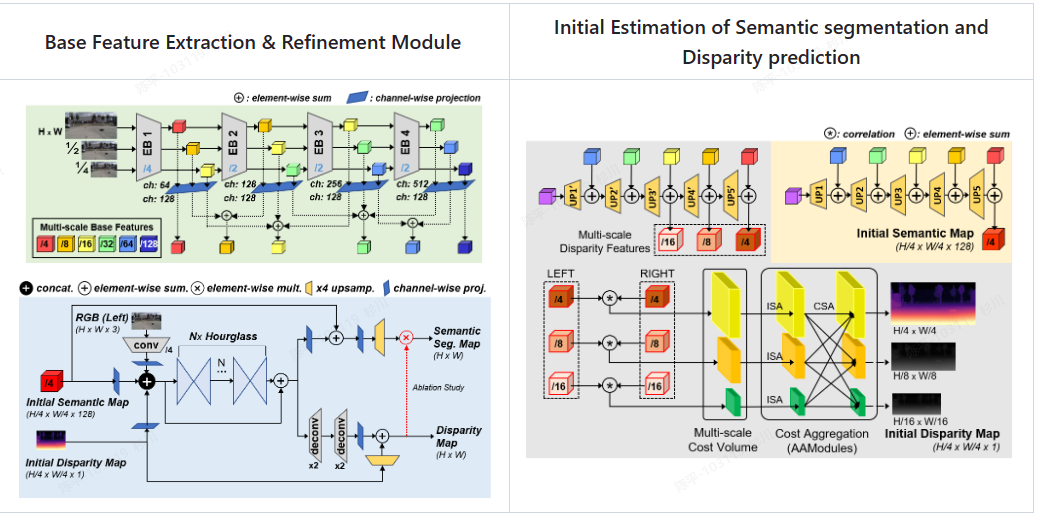
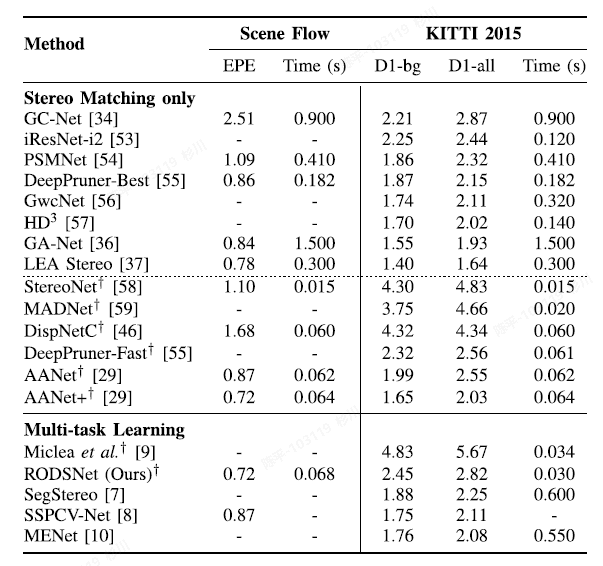
RODSNet
- 论文:https://onedrive.live.com/redir?resid=5C09C282D0C87F05!129&authkey=!AFMr9DV1F7uvc9M&ithint=file%2cpdf
- 代码:https://github.com/SAMMiCA/RODSNet
- 特点:
- 分割 + 深度估计
- 双目训练,单目预测
- architecture
 ** **
** **
- metric
Nvidia Titan X

- 可视化

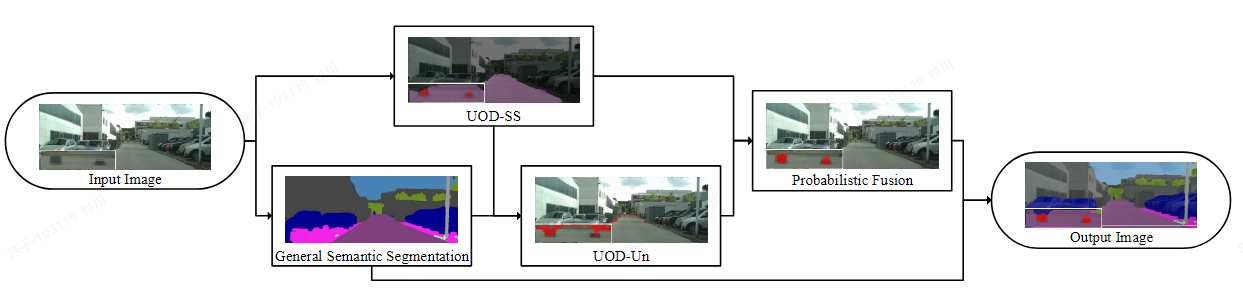
A Novel Method for Unexpected Obstacle Detection in the Traffic Environment Based on Computer Vision
- 论文:https://www.mdpi.com/2076-3417/12/18/8937
- 代码:-
- 特点:
- DeepLabV3+二次开发
- 设计了一种用于意外道路障碍物的开放集识别算法。根据已知类和未知类之间不确定性的差异,通过自适应阈值分割出UO。
- 提出了一种基于贝叶斯模型的概率融合方法
- architecture
- 评价:
- 对低分数的roi进行二次处理,来提升对于UO的识别性能
- 充分利用分类中的分布情况,(包含了更多的信息)(softmax ≠argmax),有点知识蒸馏的味道
Footprints
- 论文:https://arxiv.org/pdf/2004.06376.pdf
- 代码:https://github.com/nianticlabs/footprints
- 特点:预测障碍物的轮廓,从而可以更好的输出最终的free space,为下游的路径规划提供更有效的支撑
- 可视化:

- architecture: same with monodepth2
- 评价:
- 足点预测?在freespace的基础上,可以更有利于下游的任务;
- 全文的亮点体现在真值的制作生成和对应的loss函数的设计上;
- 在monodepth2的基础上,增加了一个mask预测结果,双路结果拼接后做监督
检测
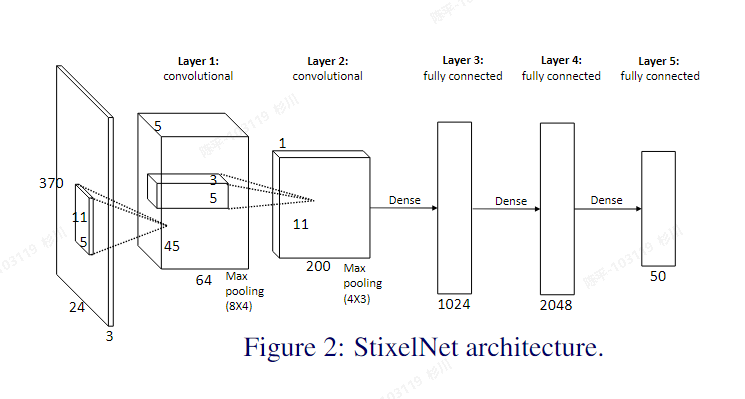
StixelNet
- 论文:https://readpaper.com/pdf-annotate/note?pdfId=4515212922032119809¬eId=2076941783993695232
- 源码:https://github.com/xmba15/obstacle_detection_stixelnet
- 特点:
- 采用column-wise的方式对障碍物进行无差别检测(有点类似车道线的row-wise),不需要对障碍物进行实例化标注
- 可视化

- architecture
- metric
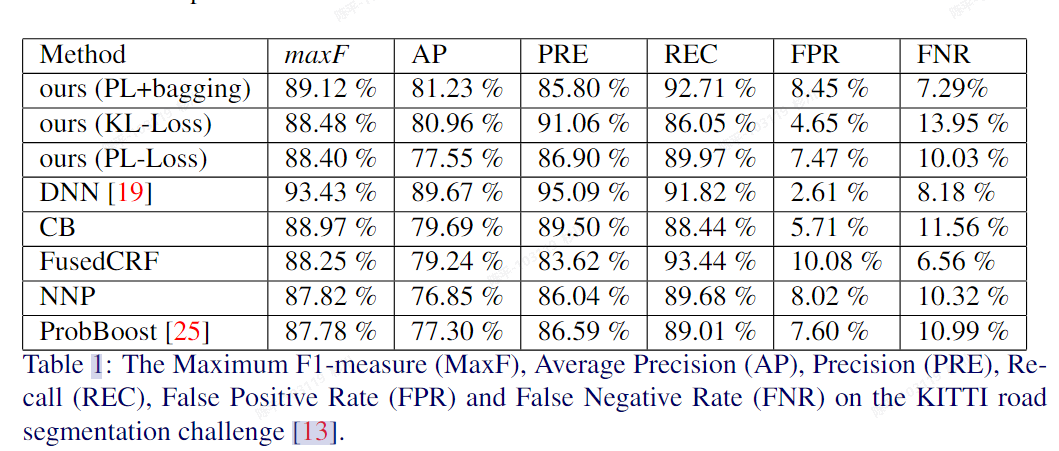
- 评价
- 很老的文章,但是好的方法都是思路创新,相当与1d分割,相较分割会有一些精度上的优势(i guess)
- 此类技术路线的文章应该也会有很多提升
- 我司的应用场景与自驾很像,类似这种方法确实可以攻玉
- 一些细节:
- 采用5个像素值进行col的划分,例如TuSimple数据集,记录障碍物的有无以及真值对应的坐标;
- 可视化显示,为了看起来更加直观,采用柱状进行显示
- 网络直接预测对应的坐标值:
- 此种预测会带来的问题:
精度误差:此种误差作者通过loss函数进行监督,即对预测结果的误差值进行监督。但另一方面,仅使用简单的类似l2loss进行回归预测,坐标的预测误差是比较大的,可能需要较长时间的拟合,且最终的效果可能不够好;学习坐标要比学习score不稳定;文中也有指出,这是一种折衷的方案:使用分类预测任务会失去对于图中障碍物预测的连续性监督(但精度是更高的)
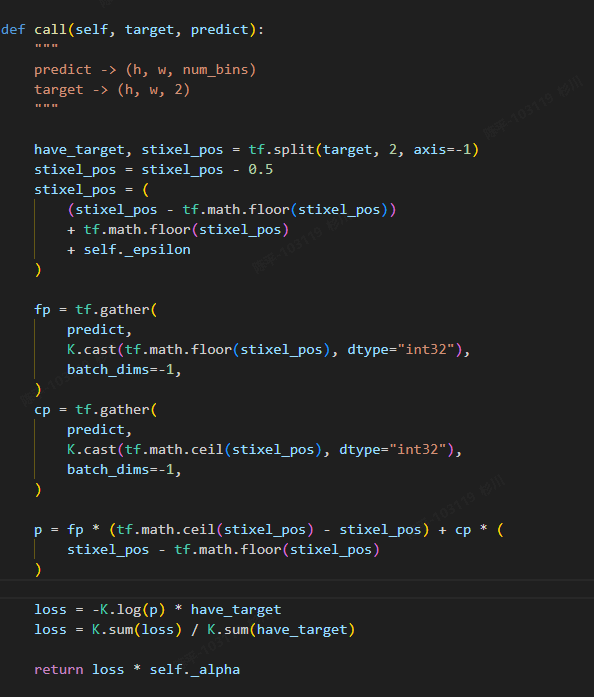
* <font style="color:#DF2A3F;">在得到预测结果后,使用CRF对输出结果进行进一步的连续性处理</font>* <font style="color:#DF2A3F;">单个col上只会预测最高的障碍物位置,模型无法很好处理障碍物的完整轮廓和大小;</font>* <font style="color:#DF2A3F;">网络的优化空间还很高,值得一试,结合onnx和rknn的相关插件的考量,整体链路打通是不成问题的;</font>* <font style="color:#DF2A3F;">为什么这个方法后续没有人研究了?</font>+ <font style="color:#DF2A3F;">因为慢,方法太早了所以很多优化都没有做,相对来说速度是比较慢的</font>+ <font style="color:#DF2A3F;">场景限制,原文是用来做自驾领域的通用障碍物检测,但对于自驾来说,识别出对应的实例依旧很重要,且精度有限,让人望而却步;</font>+ <font style="color:#DF2A3F;">其实它在以另一种形式活着,车道线检测的row-wise方案在本质上其实是相通的,并且车道线不同于检测物体,其语义上是可以离散化表示的,所以这种方法只是到了更适合它的领域;</font>
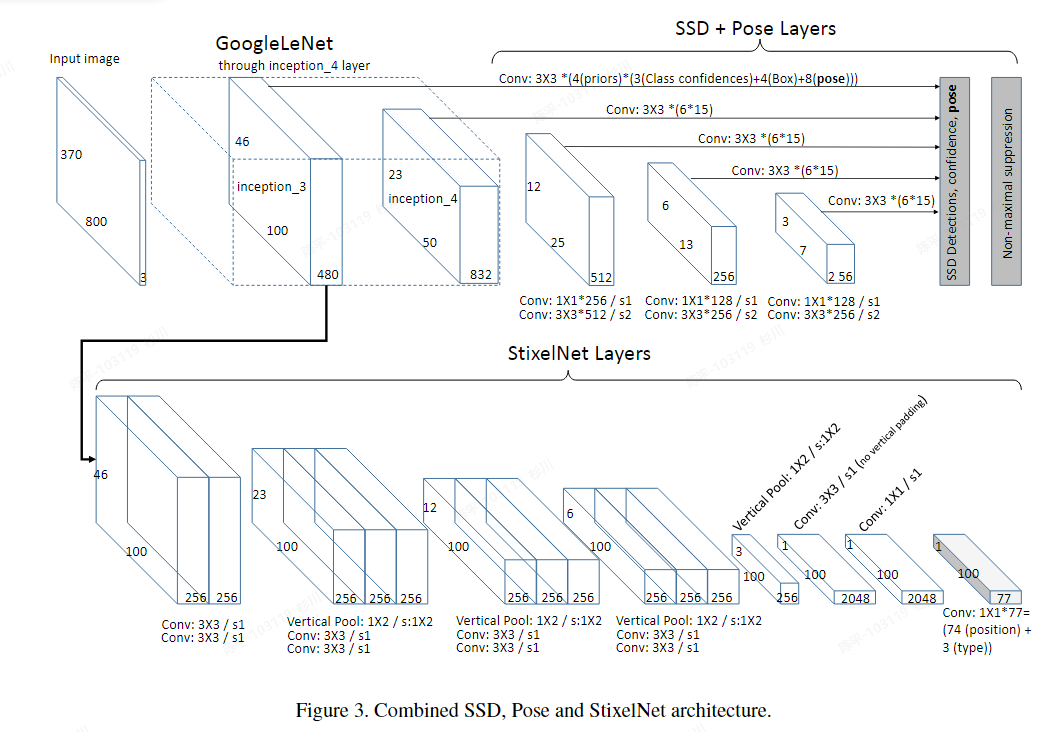
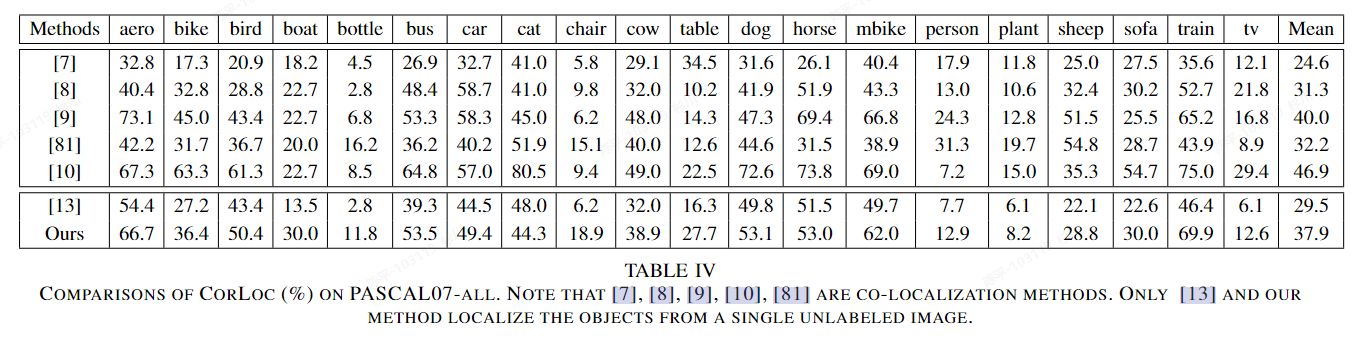
Real-time category-based and general obstacle detection for autonomous driving
- 论文:https://readpaper.com/pdf-annotate/note?pdfId=4516871595854815233¬eId=2076929048728094976
- 特点:
- 基于StixelNet的改进版,结合了ssd的目标检测和姿态估计;
- 使用kitti生成的真值进行训练
- 可视化:

- architecture
- metric
Nvidia Quadro M6000 GPU
800 × 370
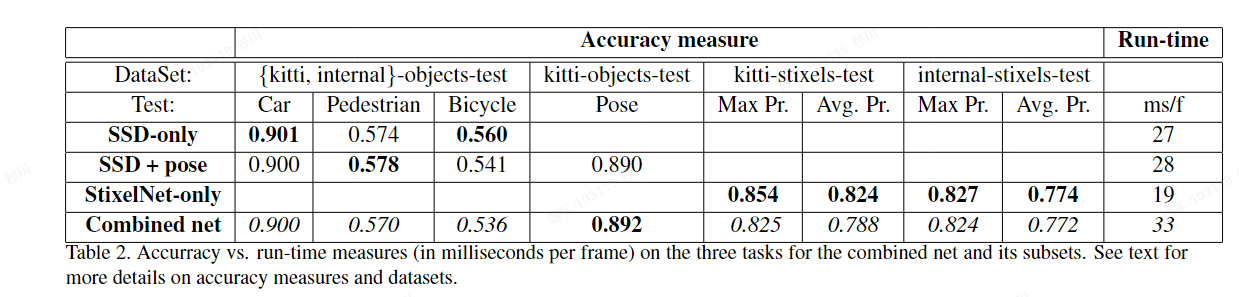
- 评价
- 多任务网络是可借鉴的,如果可以整合现有的目标检测那再好不过
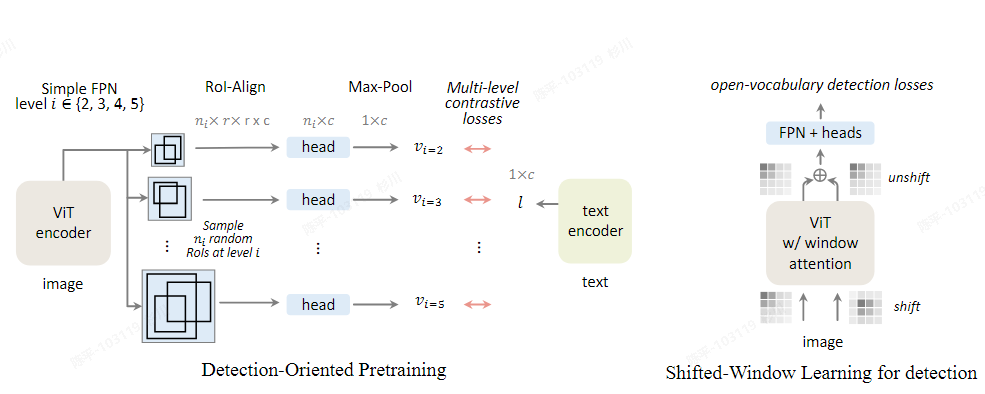
DITO
- 论文:https://arxiv.org/pdf/2310.00161.pdf
- 源码:https://github.com/google-research/google-research/tree/master/fvlm/dito
- 可视化:

- architecture
- metric(轻量化版本)
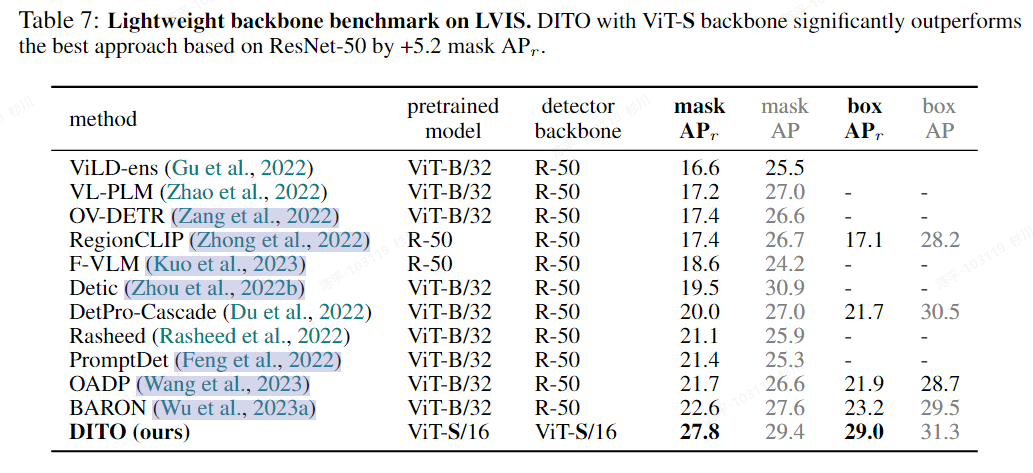
- 评价
- OPEN-VOCABULARY DETECTION(OVD)是克服人工标注数据的一个很好的方法,但模型的尺寸相对比较大,rknn模型相对会比较慢……
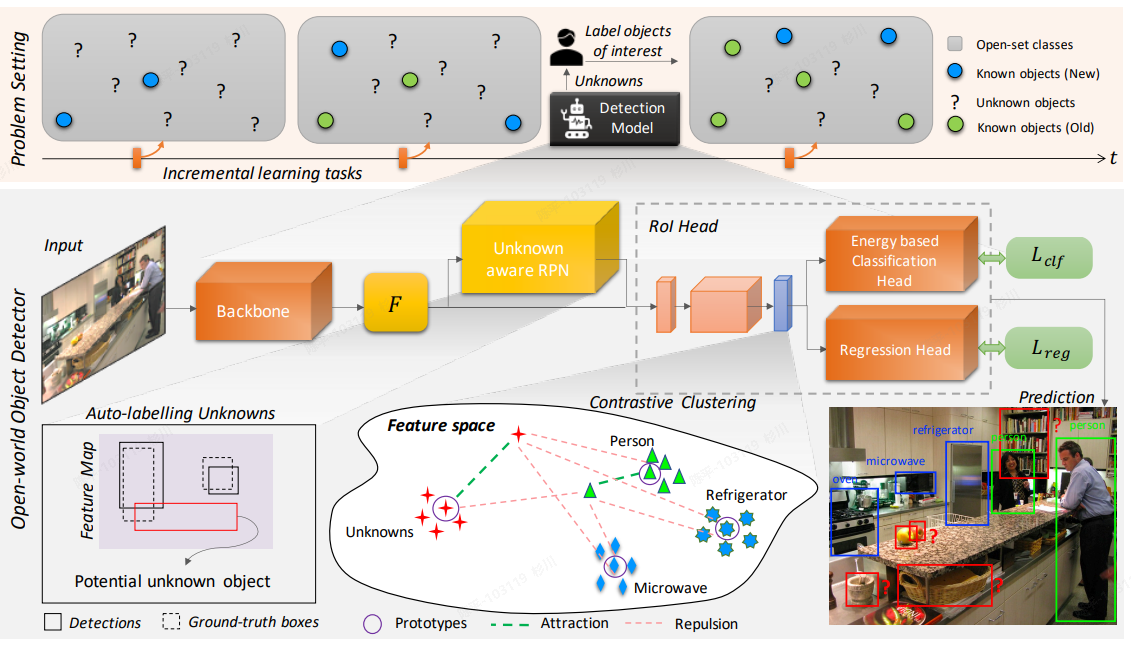
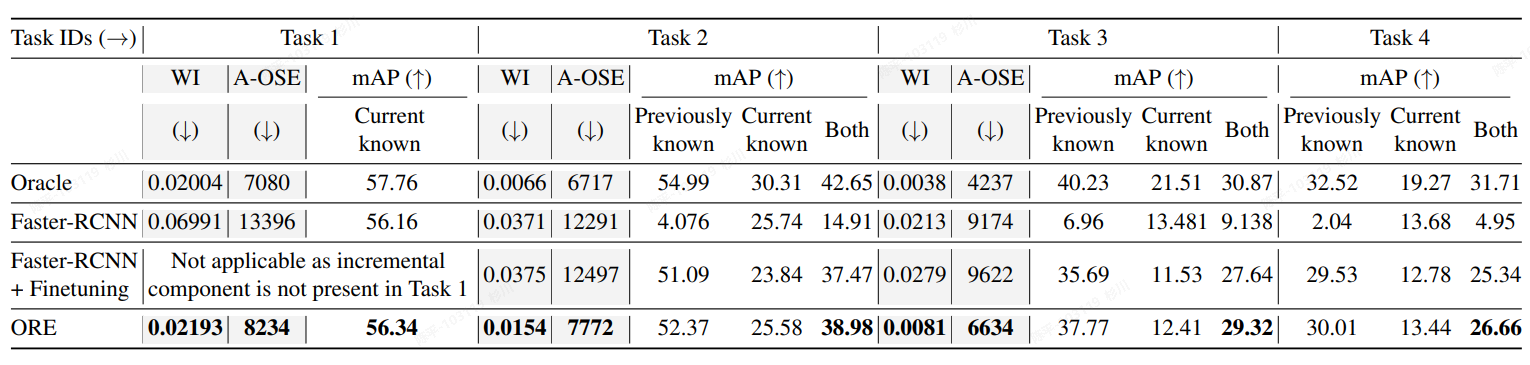
OWOD
- 论文:https://arxiv.org/pdf/2103.02603.pdf
- 代码:https://github.com/JosephKJ/OWOD
- 可视化:
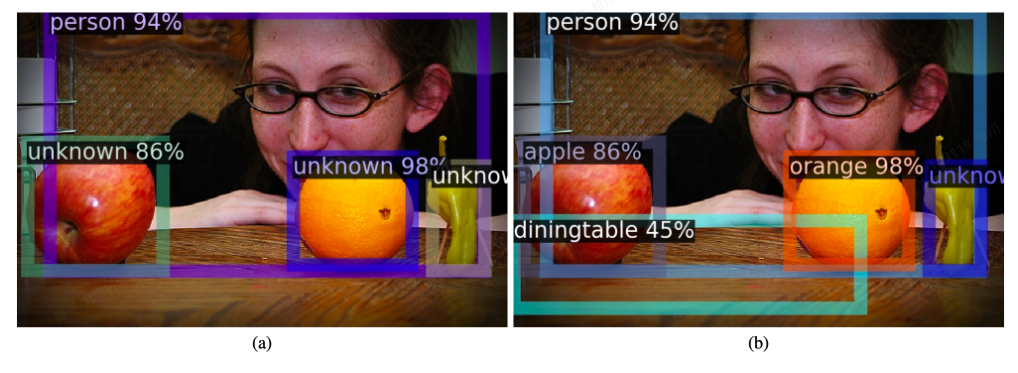
- architecture:
- metric:
- 评价
- 增量学习衍生的方法之一,得益于RPN网络和对应的聚类处理方法可以对于未知类别进行检测和有监督的训练
- 文章的主要思路不在精度提升,加之后期的优化或可以取得更优的指标
- 通过RPN网络来自动化标注出那些得分高的unknown类;
- 使用隐式空间对不同类别进行表征(有点类似CLIP),但区别在于最终会提取成一个值来使用;
- 提出了“能量函数”, 根据分类得分不同而可以得到不用的分布形式(已知类和未知类),并在其中添加了超参数温度T以调解分布差异性的大小;
- 使用对比聚类的形式,将未知类别分离出来:基于上述的潜在空间表征的向量和能量计算函数,对模型结果进行聚类,从而分离出对应的未知类检测结果(通过此处的监督来完成未知类型的训练);
- 未知类别的框是自动检测出的,但后续的增量学习中,标签是需要额外添加的;
- energy distribution的初始化学习是基于包含未知类别信息的数据集来做的(先有鸡还是先有蛋。。。);
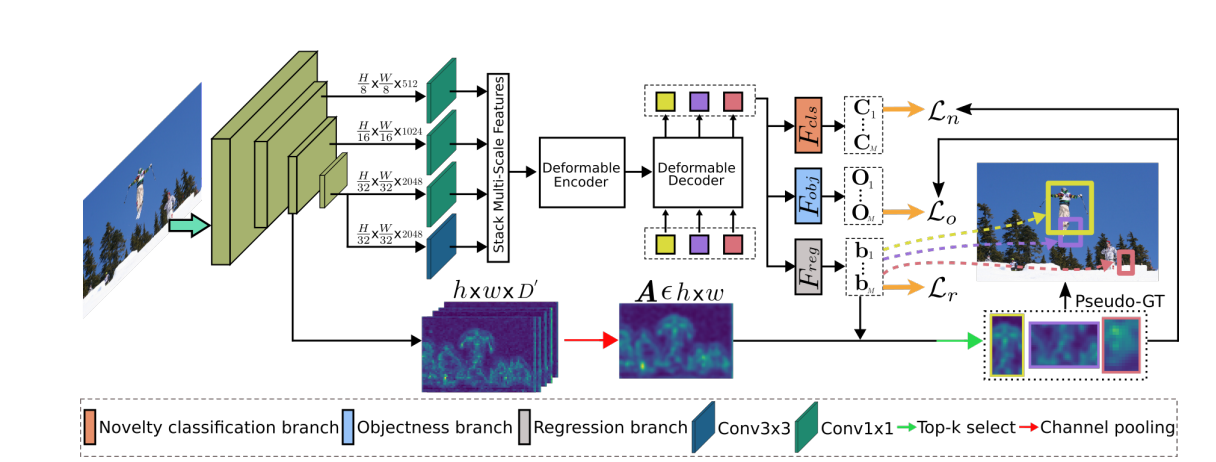
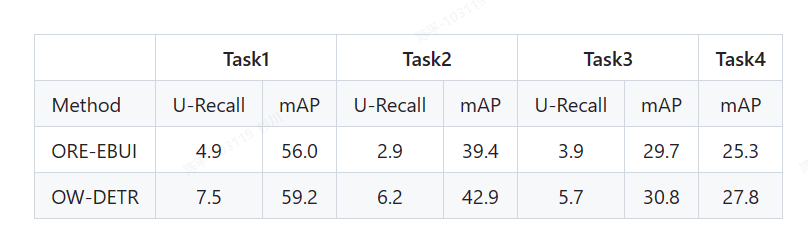
OW-DETR
-
论文:https://openaccess.thecvf.com/content/CVPR2022/papers/Gupta_OW-DETR_Open-World_Detection_Transformer_CVPR_2022_paper.pdf
-
代码:https://github.com/akshitac8/OW-DETR
-
可视化:

-
architecture:
-
metric:
-
评价:
- 指出并解决了OWOD中的数据泄露的问题,不再依赖于聚类的先验结果来对未知类别进行计算;
- 提出了基于注意力机制的伪标注来为未知类别提供监督信息,并引入了一个新的“object branch”来为未知类比的训练提供监督;
- 关键点:
- 在anchor free的路线下,如何确保输出结果的稳定性?
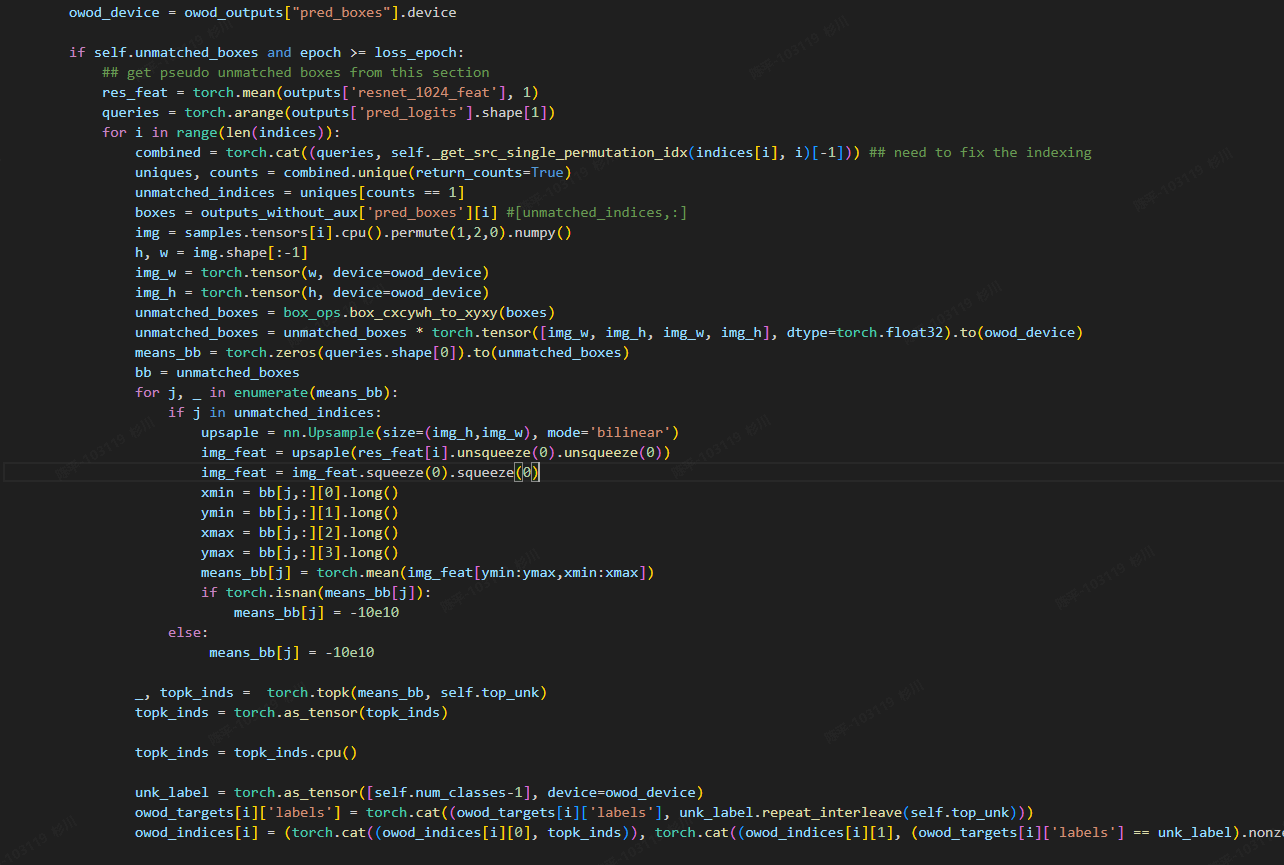
- 处理放在matcher后,在得到基础的对应结果之后,利用前面拿到的backbone的特征结果,再采用top_K的形式得到未知类别的框,从而设置对应的伪真值来进行监督计算
- 为了保证训练的稳定性,前几轮不会输出未知类,先让模型迭代几个epoch,特征图相对稳定再进行对应的提取和计算;
- 但由于未知类别的框是后添加的伪真值,所以对应的box loss天然=0,可能会对最终的预测结果有一些影响,但是由于未知类仅为类别之一,作者采用coco81类训练集,所以影响会被稀释的很小;
- 由于有作案前科,加之此文的反响并不热烈,真实性和有效性有待考察,但由于其训练集的设计过于繁琐,加之三哥的英文有些许晦涩,且detr以及脱离了我们考虑的范围,结果复现/custom dataset的训练暂时挂起
- 在anchor free的路线下,如何确保输出结果的稳定性?
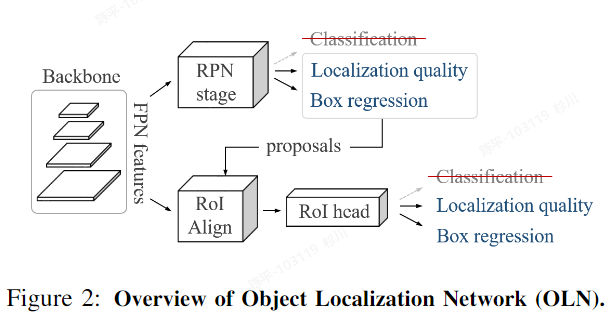
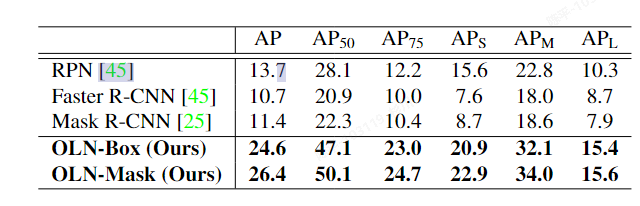
OLN
- 论文:https://arxiv.org/pdf/2108.06753.pdf
- 代码:https://github.com/mcahny/object_localization_network
- 可视化:

- architecture:
- metric:
- 评价
- RPN的极致运用,如果对于我们的任务来说,定位就够了,或者分类是次要任务的话,训练一个定位网络未尝不可。
- 在RPN部分增添了很多新的计算会对速度有所影响,当数据规模提升,场景更加复杂的情况下,其性能有待考究,不过好在我司的应用场景是很细化的,性能可能不会掉太多。
- 在原有faster-rcnn的基础上增加了一个objectness loss,其在rpn网络的原有逻辑中增加了一个(修改了超参),通过MaxIoUAssigner进行正负样本匹配,确保每个目标都有很多的框(目的还是要尽可能更多的获取前景框)
- 直接不使用分类loss,但仍然参与计算,现在的计算量是溢出的,后期可优化提速;
- 由于还是属于有监督学习,所以一开始的监督真值需要对对应的处理,将所有目标的框都尽可能的标注(可利用大模型单独生成对应的标签,再配合人工后期筛查即可)
Slot Attention
•论文:arxiv.org/pdf/2006.15055.pdf
•代码:google-research/slot_attentionat master · google-research/google-research (github.com)
•特点:
- <font style="color:black;">可以即插即用,以目标为中心;</font>
- <font style="color:black;">可用于无监督学习,直接用于无监督的目标发现;</font>
- <font style="color:black;">可用于监督学习中的预测,使用注意力机制学习突出单个对象,而无需对对象分割进行直接监督;</font>
- 可视化:
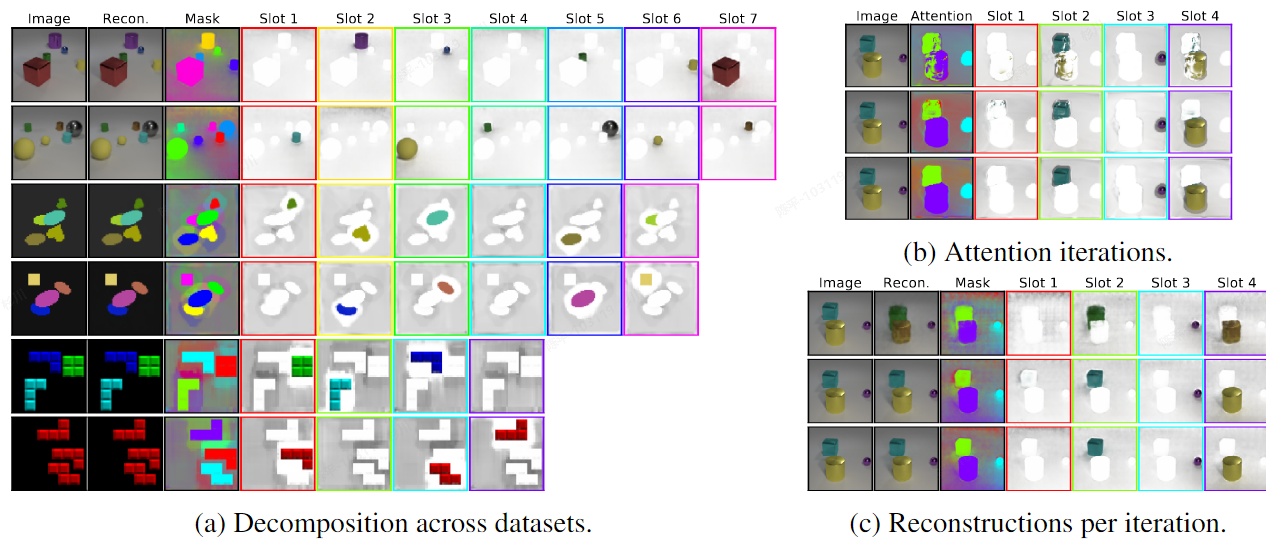
- architecture:
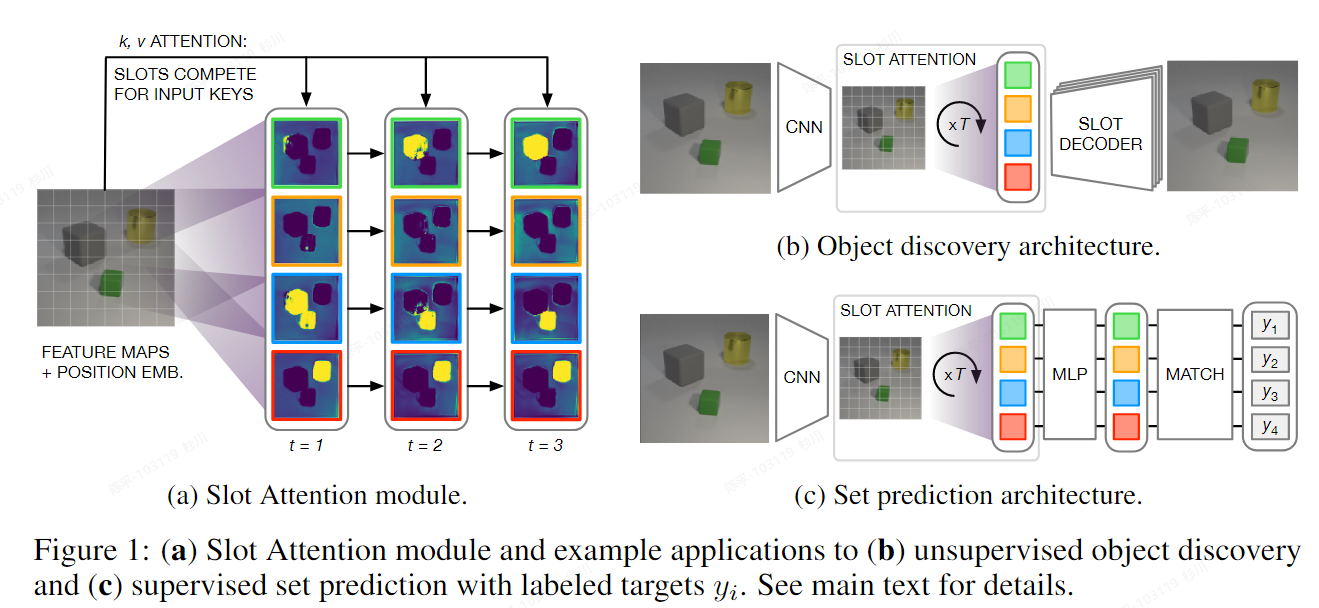
-
metric:

- 评价:
-
(i)我们引入了 Slot Attention 模块,它是感知表示(例如 CNN 的输出)和结构化为集合的表示之间的接口的简单架构组件。
-
(ii) 我们将基于 Slot Attention 的架构应用于无监督对象发现,它匹配或优于相关的最先进方法,同时内存效率更高,训练速度明显更快。
-
(iii) 我们证明了 Slot Attention 模块可用于监督对象属性预测,其中注意力机制学习突出单个对象,而无需对对象分割进行直接监督。

-
需要留意的是, 本文所使用的数据集场景比较简单. 在像现实世界一样复杂的场景中, slot attention表现不一定会非常出色. 还有一个缺点是该方法需要提前知道物体的数量.
-
Mining-Objects
- 论文:https://arxiv.org/pdf/1902.09968.pdf
- 代码:https://github.com/anandhupvr/Mining-Objects/tree/master
- 特点:
- 无监督;
- 使用预训练的CNN模型提取特征图,通过利用多尺度特征进行频繁项集挖掘。该方法通过将深度特征转化为字典集合,并利用模式挖掘技术发现有意义(频繁出现)的位置,最终将这些位置合并以生成表示物体区域的检测框。
- 可视化:
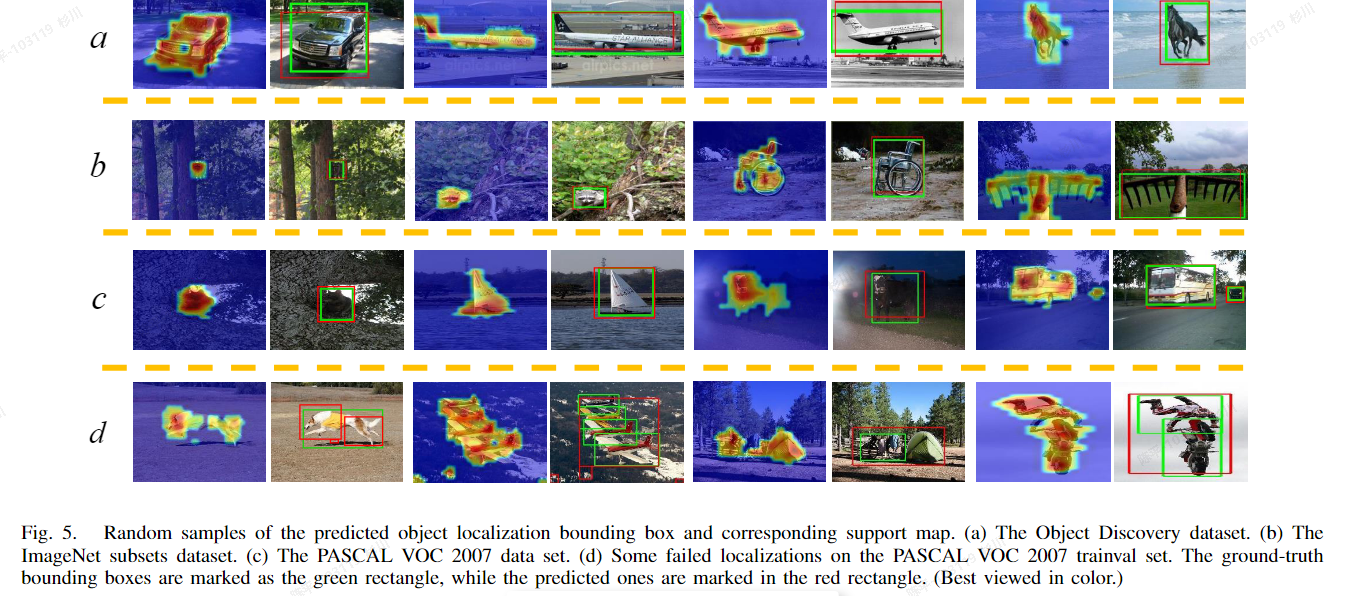
- architecture:
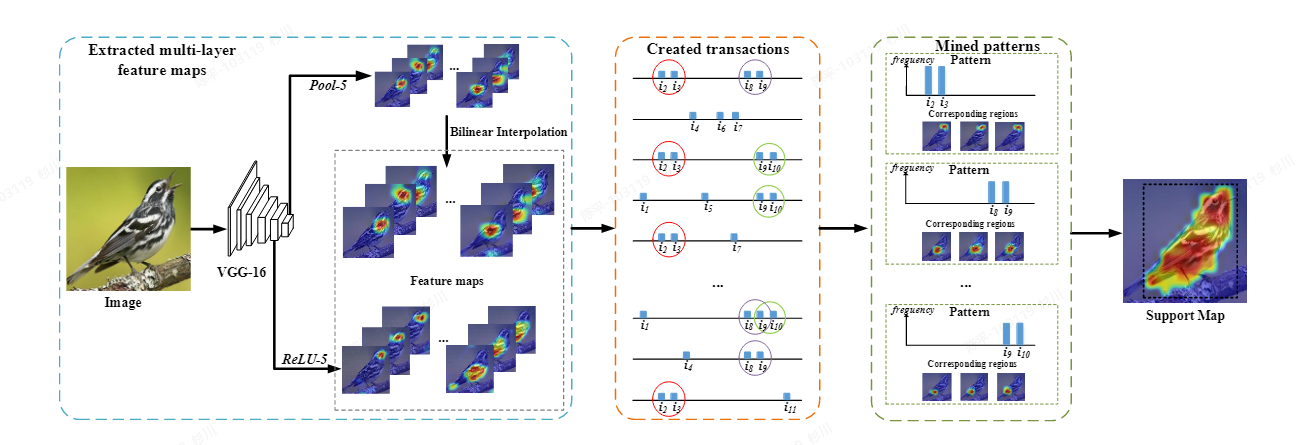
- metric:
- 评价:
- 使用自定义的 vgg16 函数提取图像特征。
- 通过遍历特征并获取特征图中每个通道的有效值及对应的索引。
- 将特征处理后的结果用于频繁模式挖掘,通过 Apriori 算法获取频繁项集。
- 计算频繁项集在特征图上的支持度。
- 生成一个二值图像 new_img,并对其进行标记和对象提取,得到对象的位置和大小。
LOST
- 论文:https://arxiv.org/pdf/2109.14279.pdf
- 代码:https://github.com/valeoai/LOST
- 特点:
- 无需标签:LOST方法不需要任何标签来定位图像中的对象,这使得它在无标签场景下具有更高的适用性。
- 高精度:尽管LOST方法非常简单,但它在定位对象方面的表现仍然优于现有的无标签对象发现方法。
- 可扩展性:由于LOST方法的复杂度与数据集大小成线性关系,因此它可以很好地应对大型数据集,具有很高的可扩展性。
- 多对象定位:LOST方法可以用于训练无监督类别不可知(Class-agnostic)和无监督类别可知(Class-aware)对象检测器,从而在图像中定位多个对象并将它们分组到相应的类别中。
- 基于自监督预训练的Transformer特征:LOST方法利用自监督预训练的Transformer特征来定位对象,这些特征在无标签场景下具有更高的准确性。
- 可视化:
 architecture:
architecture: - 使用LOST方法在图像中定位对象
- 对于每个图像,利用K-means聚类将LOST检测到的对象分为类别
- 使用聚类标签作为伪标签,训练一个传统的对象检测器
- 在评估阶段,使用匈牙利算法将伪标签与真实的类别标签进行匹配,从而为伪标签分配名称。总之,该过程通过在大量无标签图像上顺序训练DINO变换器、类别不可知前景/背景分类器和最后的分类器,实现了全无监督的对象定位和检测。
- metric:
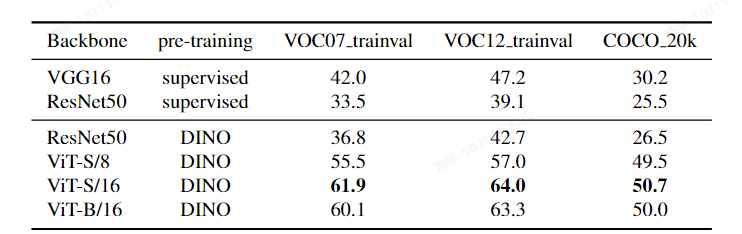
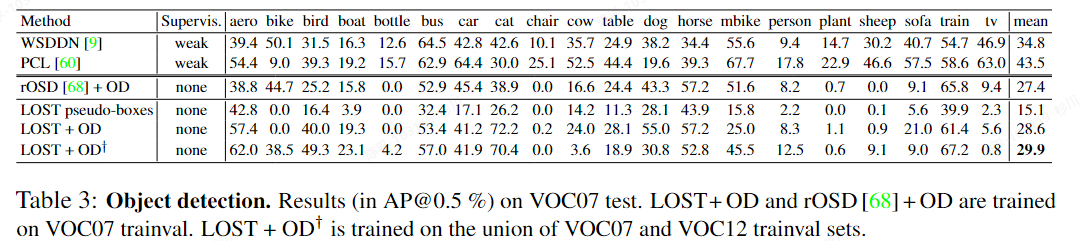
- 评价:
- 无监督才是最终的出路?
- ViT虽然很难部署,但是如果ResNet可行的话,是值得一试的
FreeSOLO
- 论文:https://arxiv.org/pdf/2202.12181.pdf
- 代码:https://github.com/NVlabs/FreeSOLO
- 特点:
- Free Mask采用自监督设计元素来促进网络注意力中的物体性质,Self-supervised SOLO则利用Free Mask中生成的粗略掩模来训练SOLO模型
- 可视化:

- architecture:

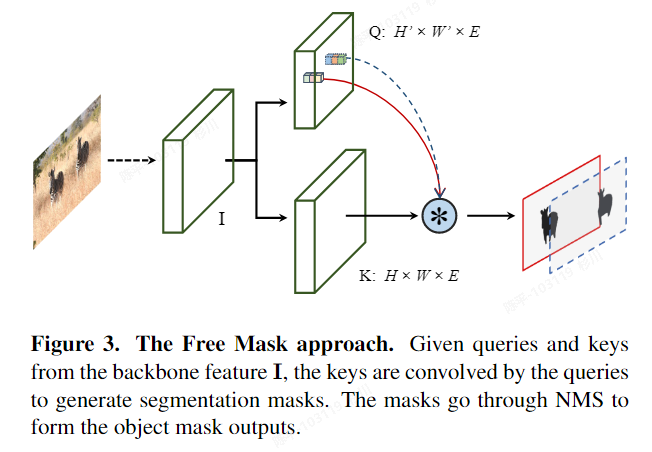
- metric:
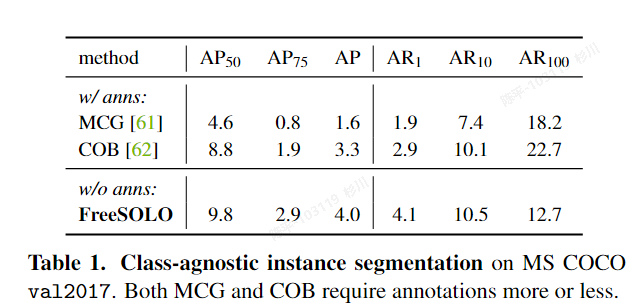
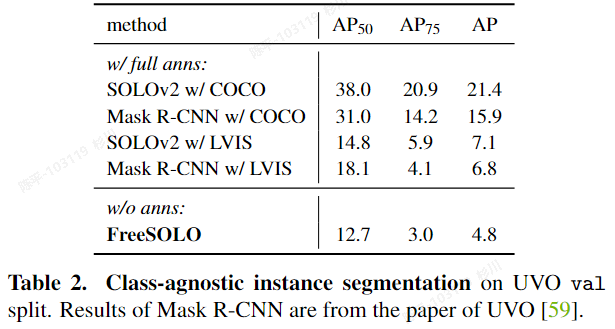
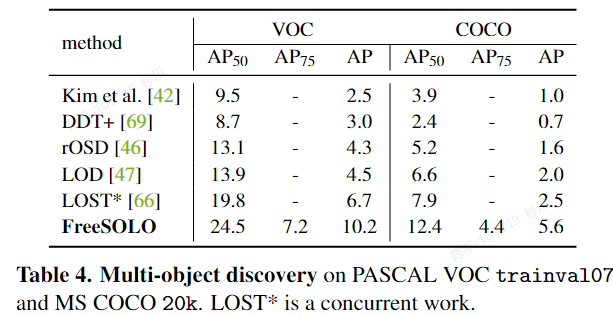
- 评价
- FreeSOLO 的两个主要组成部分分别是 Free Mask 和 Self-supervised SOLO,它们的实现方式如下:
- Free Mask:
Free Mask 用于生成来自无标签图像的对象掩码。首先,提取密集特征图 I ∈ R H×W×E 通过自监督预训练的主干网络(例如 ResNet 或其他卷积神经网络)。接下来,从特征 I 构建查询 Q 和键 K,它们共同生成粗略的分割掩码。对于每个查询,计算其与所有键的余弦相似度,从而获得得分数地图 S ∈ R H×W×N。然后,将分数地图归一化为软掩码,并计算每个软掩码的“掩码度”(maskness)得分,用于评估提取的掩码的质量。将软掩码转换为二值掩码,并通过掩码非极大值抑制(NMS)方法按照掩码度得分进行排序并去除冗余掩码。最终得到的掩码即为 Free Mask 的输出。 - Self-supervised SOLO
Self-supervised SOLO 使用 Free Mask 生成的粗略掩码和语义嵌入来训练基于 SOLO 的实例分割模型。首先,使用 Free Mask 生成的粗略掩码作为弱标注,并采用弱监督设计进行实例分割。这包括投影损失项(max x 和 max y)和平均损失项(avg x 和 avg y),以及一个成对亲和损失项(L pairwise)。接下来,进行自训练,在初始训练的实例分割器上输入无标签图像,收集预测的对象掩码,去除低置信度预测,并将剩余的掩码视为新的粗略掩码。然后,使用这些无标签图像和新的掩码再次训练实例分割器,采用如方程(4)中所述的损失函数。此外,还可以通过学习对象级别的语义表示来改进分割质量。
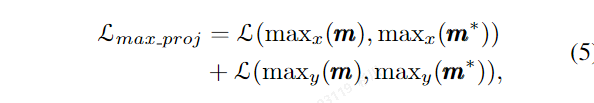
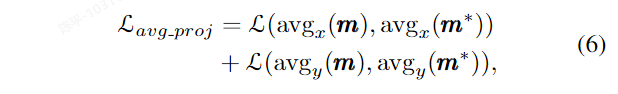
采用真值与预测值在x,y轴投影的平均值来做弱监督
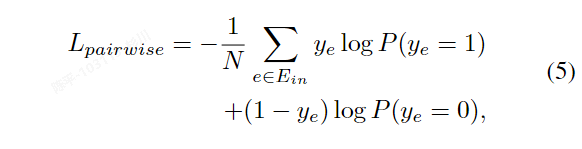
度量学习
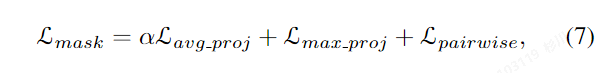
通过这两个主要组成部分,FreeSOLO 可以在无标签图像上实现自监督实例分割
- Free Mask:
- FreeSOLO 的两个主要组成部分分别是 Free Mask 和 Self-supervised SOLO,它们的实现方式如下:
Exemplar-FreeSOLO(暂时未开源)
- 论文:
- 代码:
- 特点:
- 可视化:
- architecture:
- metric:
- 评价:
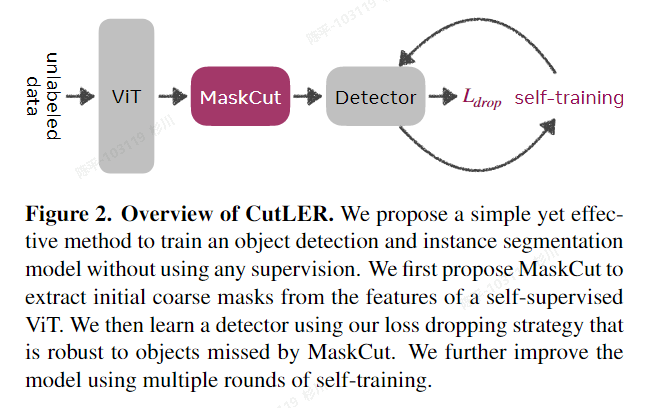
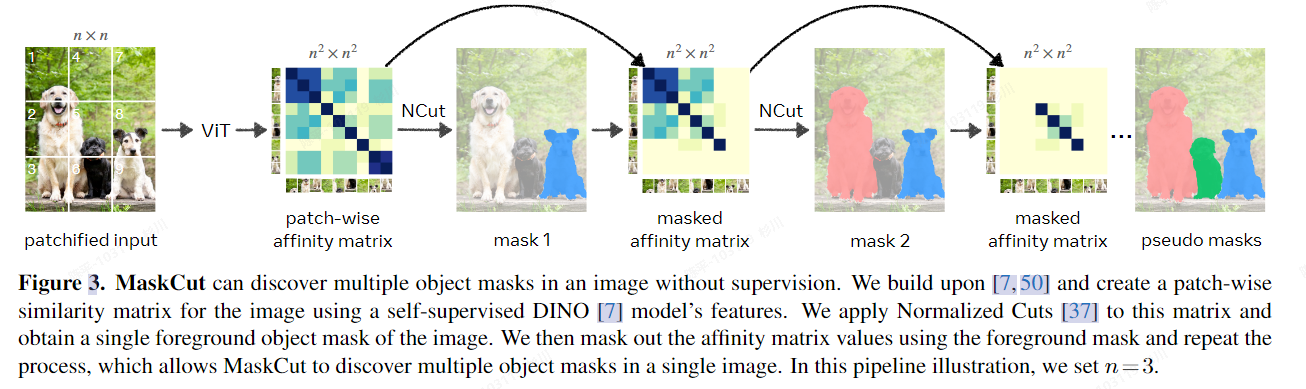
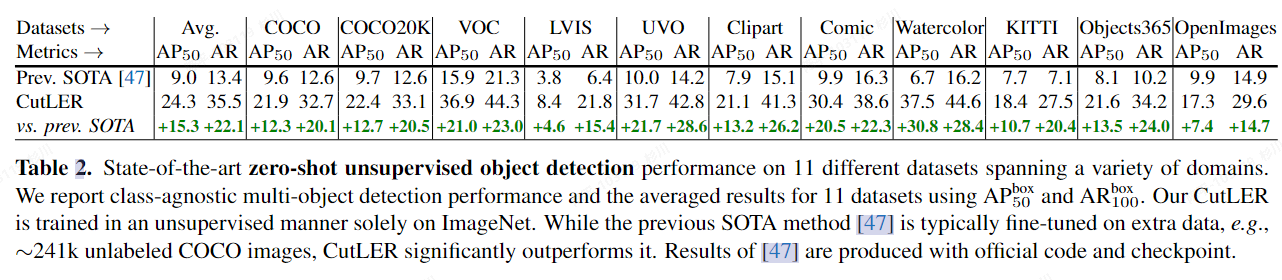
CutLER
-
论文:https://arxiv.org/pdf/2301.11320.pdf
-
代码:https://github.com/facebookresearch/CutLER
-
特点:
- 完全zero-shot,不需要任何“域内”数据集内的数据进行训练;
- 结构简单,可以方便与现有的检测、分割方法集成;
- 鲁棒性:在不同风格的各种数据集中都有不错的表现;
- 综上几点,CutLER可以作为预训练供其他few-shot的模型使用;
-
可视化:

-
architecture:
-
metric:
-
评价:
- self-supervised representations can discover objects
- DINO finds that the selfsupervised ViT can automatically learn a certain degree of perceptual grouping of image patches.
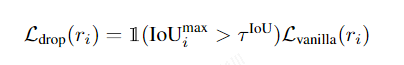
loss函数忽略没有真值监督的掩码/真值不够准确的掩码部分的损失计算
MOST(暂时未开源)
- 论文:https://arxiv.org/pdf/2304.05387.pdf
- 代码:
- 特点:
- 可视化:
- architecture:
- metric:
- 评价:
COMUS
- 论文:https://arxiv.org/pdf/2207.05027v2.pdf
- 代码:https://github.com/zadaianchuk/comus
- 特点:
- 可视化:

- architecture:
- metric:
- 评价:
OW-YOLO
- 论文: -
- 代码:https://github.com/buxihuo/OW-YOLO/tree/ow-yolo-det
- 特点:
- 网络能够学习到通用的前景信息,推理的时候,把前景信息置信度高,而分类信息置信度低的拿出来,就能在一定程度上检测未知物体
- 可视化:

- architecture:同yolov5
- metric:
- 评价:
- 0成本尝试
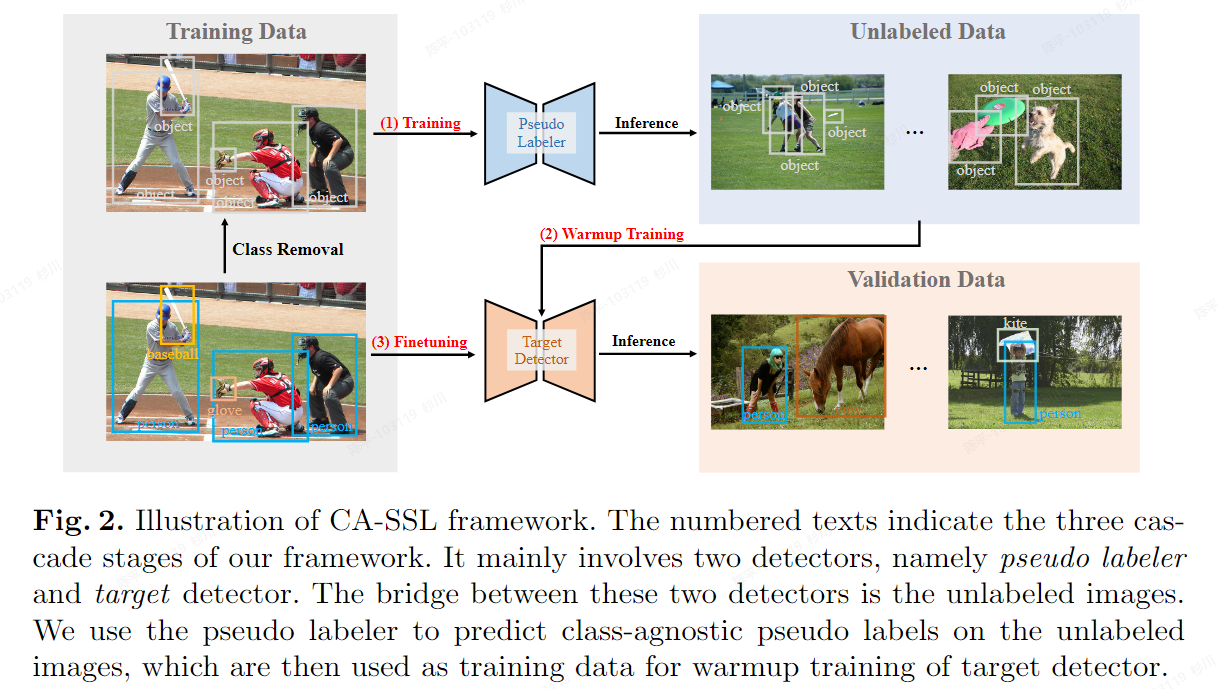
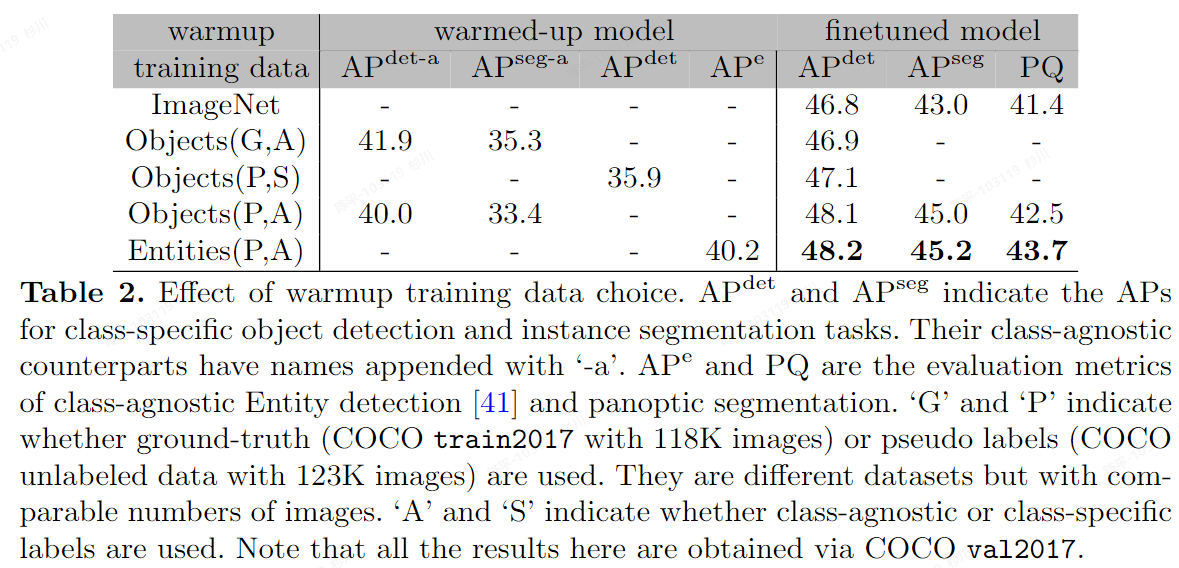
CA-SSL
- 论文:https://arxiv.org/pdf/2112.04966v2.pdf
- 代码:https://github.com/qqlu/Entity/tree/main
- 特点:
- CondInst作为base模型,重点是思路
- 可视化:
- architecture:
- metric:
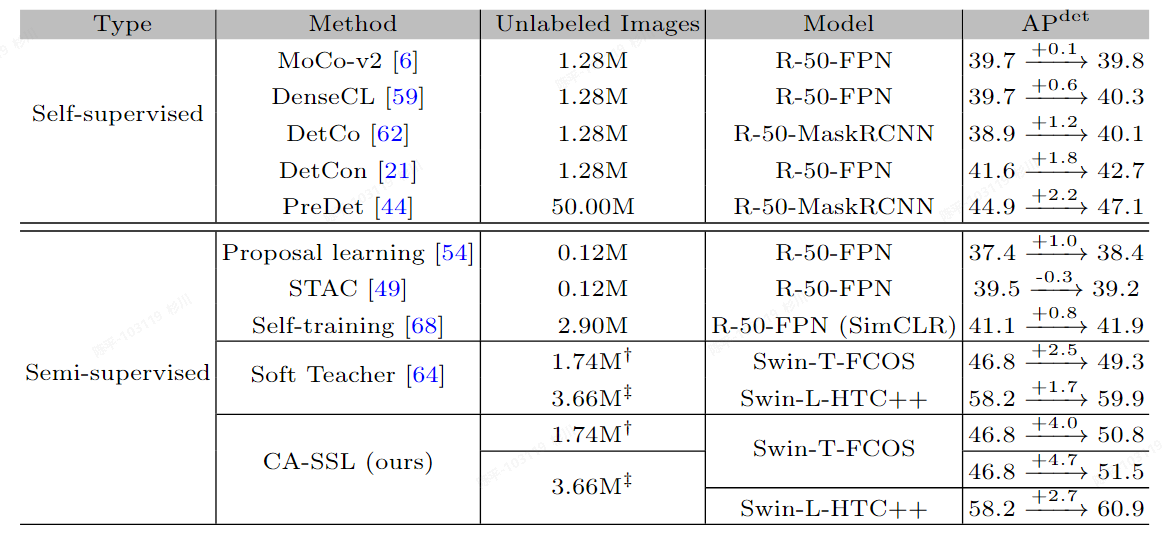
- 评价:
- 通过无类别训练,让网络学习“object-centeric”,再通过finetune得到最终的模型,但最终的模型结果依旧是有类别,有监督的(如果需要),但和free-SOLO差不多的问题就是需要通过域内的数据进行预训练或者迭代,不过最终可以输出有类别信息的数据对于我们的场景来说也是适配的,可以节省一个分类网络?
SSCOD
- 论文:https://arxiv.org/pdf/2104.12245v1.pdf
- 代码:https://github.com/cybercore-co-ltd/Single-Stage-Common-Object-Detection
- 特点:
- FPGA执行;
- 可视化:

- architecture:
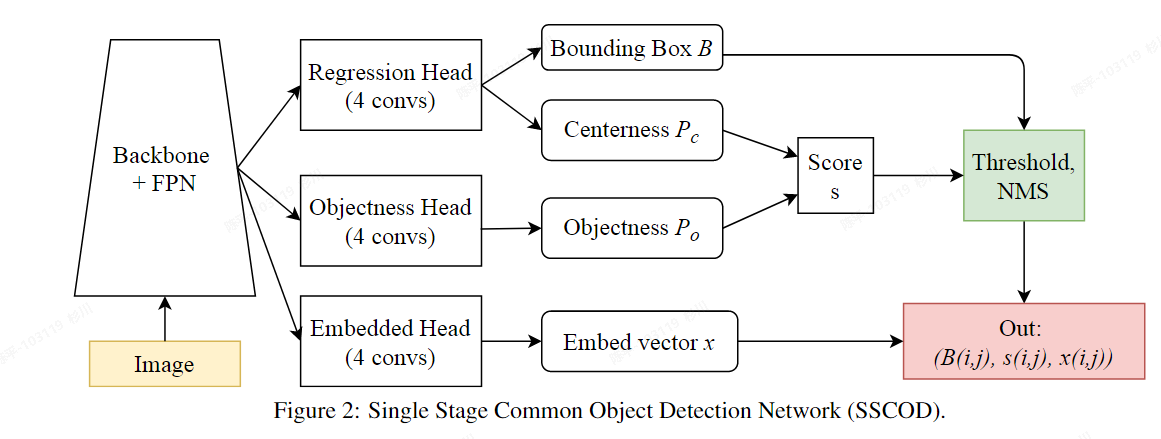
- Class-wise losses
- Pair-wise losses
- metric:
- 评价:
- SSCOD head based on the Retina Head with ATSS
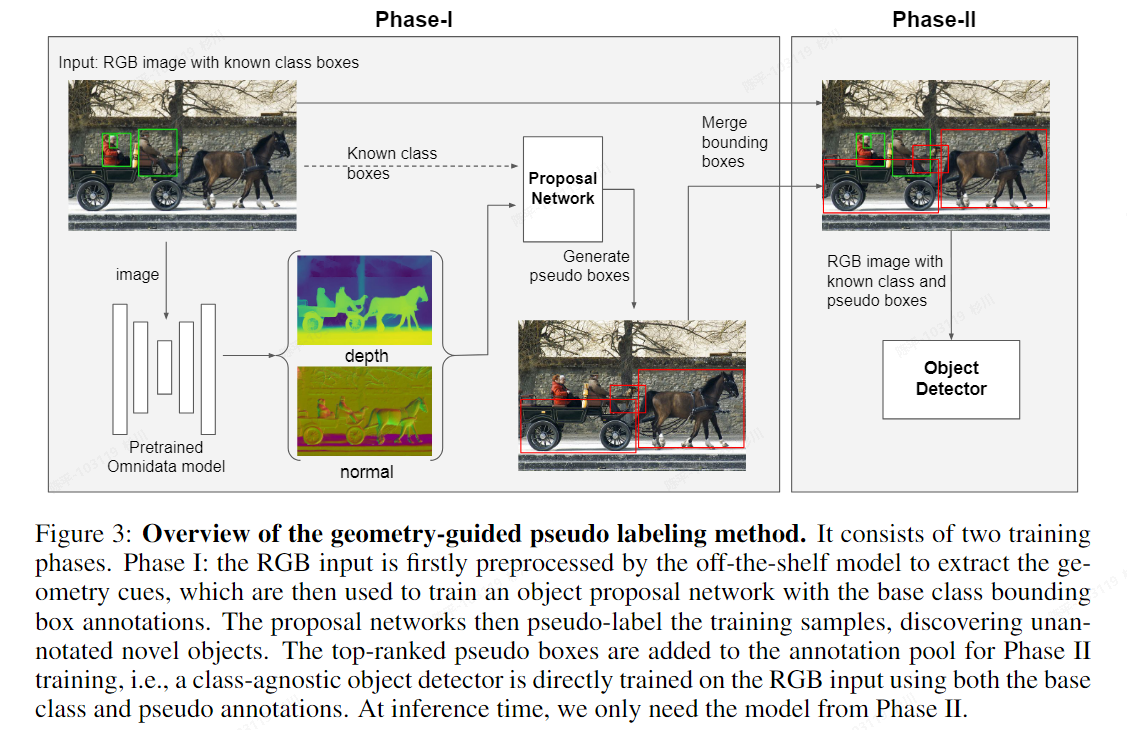
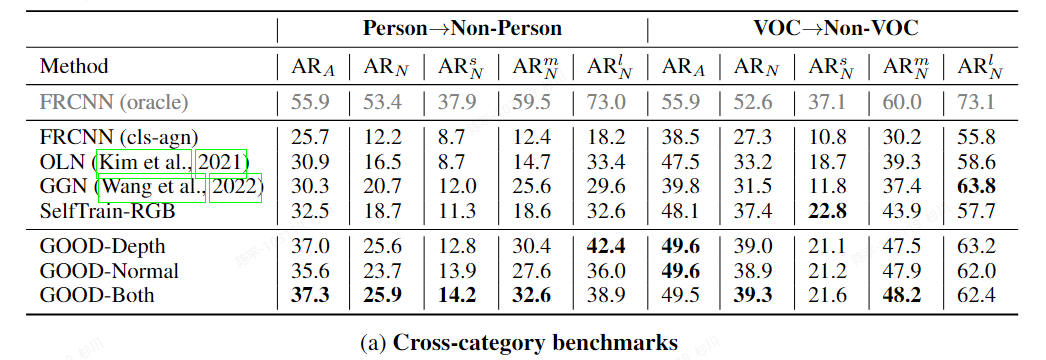
GOOD
- 论文:https://arxiv.org/pdf/2212.11720v3.pdf
- 代码:https://github.com/autonomousvision/good
- 特点:
- 通过引入几何线索(如深度和法线)来改进基于RGB图像的目标检测器。
- 可视化:


- architecture:
- metric:
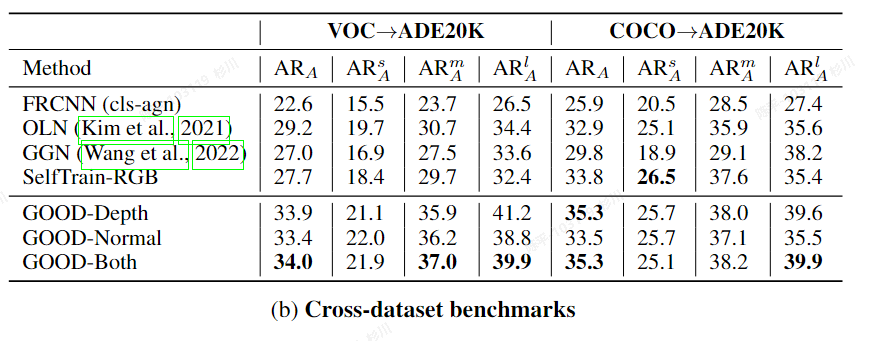
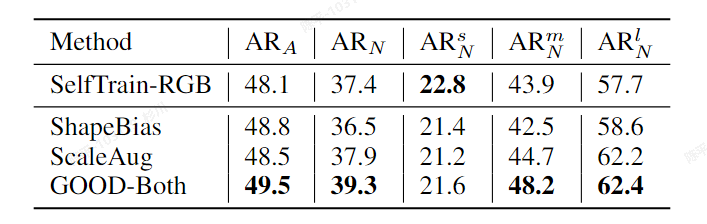
- 评价:
- there is less discrepancy between known and unknown objects in terms of geometric cues
- 在使用OLN方法生成对应的伪标签后,为所有的“标签”匹配了对应的生成结果后,将剩余的top-K(1,2,3)个框作为真值使用
- Omnidata models获取深度和法线等几何信息
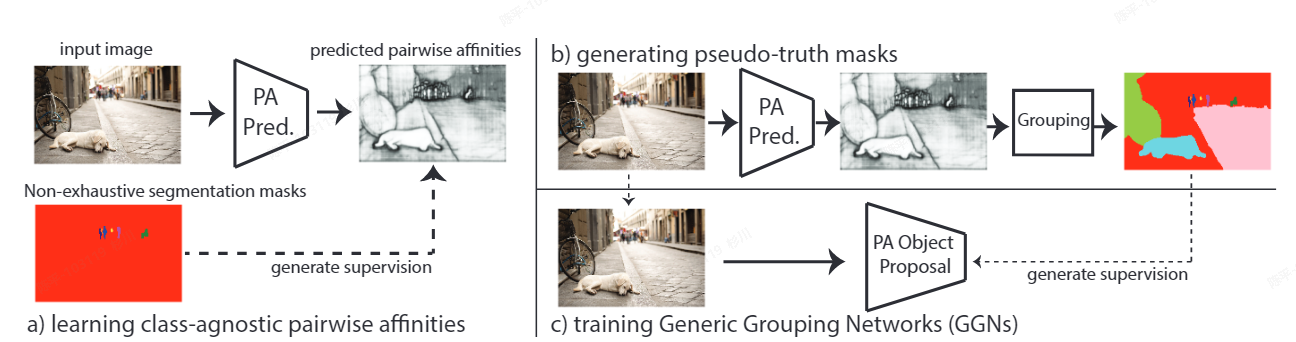
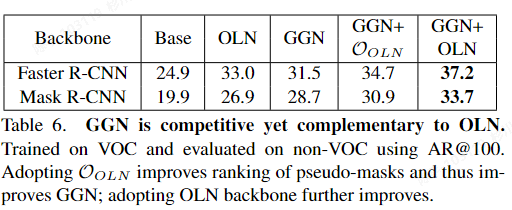
GGN
- 论文:https://arxiv.org/pdf/2204.06107.pdf
- 代码:https://github.com/facebookresearch/Generic-Grouping
- 特点:
- 提出了一个全新的通用分组网络GGN, GGN 利用从学习的像素级成对亲和力生成的额外的伪地面实况监督;
- 可视化:

- architecture:
- metric:
- 评价:
- Pairwise affinity is used in most graph-based segmentation methods as an important term defining a relation graph of pixels for segmentation.
- 使用Pairwise Affinity生成伪真值,利用图分组算法和对应的Pairwise Affinitypooling后的单值矩阵
- 论文:
- 代码:
- 特点:
- 可视化:
- architecture:
- metric:
- 评价:
数据集
1MODD
- 海上障碍物检测数据集,场景无法复用,但思路可以借鉴:
- Danger zone的设计,metric的设计上,重点关注于影响机器运行和避障的区域范围;
- 数据集的制作方法
- benchmark
- 
SA-1B(Segment Anythig)
- 论文:https://arxiv.org/pdf/2304.02643.pdf
- 源码:https://ai.facebook.com/datasets/segment-anything/
- 可视化:
- 评价:
- 1100 万张总有你想要的。。。但是可用数据筛选也是一个工作量
ImageNet-22K
- 论文:https://arxiv.org/pdf/1409.0575.pdf
- 代码:https://github.com/Alibaba-MIIL/ImageNet21K
- 可视化:

- 评价:
- 多重标签
V3Det
- 论文:https://arxiv.org/pdf/2304.03752.pdf
- 代码:https://github.com/V3Det/V3Det
- 可视化:
- 评价:
- 建立了详细的层级的类别结构,更方便筛选出我们需要的数据
- 超过 13,000 类物体,种类繁多;标注极其丰富
NYUv2 (NYU-Depth V2)
- 论文:https://cs.nyu.edu/~silberman/papers/indoor_seg_support.pdf
- 代码:https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html
- 可视化:

- 评价:
- 1449 个密集标记数据+407,024 个新的未标记帧
- 室内场景数据集(专业对口)
- 数据源包含深度图(可操作性更大)
Office-31
- 论文:https://link.springer.com/content/pdf/10.1007/978-3-642-15561-1_16.pdf
- 代码:https://faculty.cc.gatech.edu/~judy/domainadapt/
- 可视化:

- 评价:
- 办公室场景数据,异构数据,包括亚马逊商城图像、实拍图、摄像头低质数据;
- 共31 个对象类别
CORe50
+ 论文:[ http://proceedings.mlr.press/v78/lomonaco17a/lomonaco17a.pdf](http://proceedings.mlr.press/v78/lomonaco17a/lomonaco17a.pdf) + 代码:[ https://vlomonaco.github.io/core50/](https://vlomonaco.github.io/core50/) + 可视化:
- 评价:
- 10 大类 50 种家居用品:插头适配器、手机、剪刀、灯泡、罐头、眼镜、球、记号笔、杯子、和遥控器
- 包含深度信息的视频帧,虽然数据集本身是为连续对象认知设计,但目标类型是我们需要的,可以作为补充样本(为什么不呢)
Hypersim
- 论文:https://arxiv.org/pdf/2011.02523v5.pdf
- 代码:https://github.com/apple/ml-hypersim?tab=readme-ov-file
- 可视化:

- 评价:
- 生成数据,461室内场景的77,400图像;
- 包含实例分割标签和图像的相机信息
- 数据格式为.hdf5
Trans10K
- 论文:https://arxiv.org/pdf/2003.13948v3.pdf
- 代码:https://xieenze.github.io/projects/TransLAB/TransLAB.html
- 可视化:

- 评价:
- 玻璃制成的窗户和瓶子等透明物体分割数据集
- 数据集包含 10428 张图像,透明物体分为两类:(1)透明物体,如杯子、瓶子和玻璃 (2) 透明的东西如窗户、玻璃墙和玻璃门。
SUN RGB-D
- 论文:https://arxiv.org/pdf/2207.01071v2.pdf
- 代码:https://rgbd.cs.princeton.edu/challenge.html
- 可视化:

- 评价:
- 10,355 张RGB-D的图像,包含分割标注、3d框标注
- 室内场景
总结
在调研到的方法中,可以实现通用障碍物检测大致功能的包括了freespace的分割,open set/增量学习(包含类别信息),无差别检测(不包含类别信息),想要在轻量化的基础之上保障检测的精准性是一件极具挑战的事情。所以调研的更多的侧重点也放在了CNN类方法中,在分割类方法已验证无法满足要求的情况下,检测类的识别或许可以进行进一步的尝试,包括:
- col-wise的检测:
- 好处在于:
- 无差别障碍物检测,对于我们来说,检测出最近的障碍物是第一需求的话,这种技术路线很适配;
- 方法虽然比较老,但是一些通用方法的迭代发展,完全可以与之结合以提升性能;
- 但这种方法的问题也是较为明显的:
- 分辨率会降低,w sample的数量也会影响最终的结果精度;
- 离散化的结果,不会包含实例信息,完全不同的技术路线,无法与现有的检测模型合并
- 数据集监督真值需要做一些额外的调整
- 好处在于:
- RPN网络:
- 好处在于:
- 老方法潜能的挖掘,从技术路线上是有与现有方法合并的可能性的;
- 数据训练方便,单纯舍弃分类信息,模型轻量化值得保障
- 但也存在一些缺点:
- 检测精度需要进一步的试验;
- 好处在于:
- 其他可以借鉴的思路:
- 虽然分割的方法暂时不加考虑,但是调研方法中的基于贝叶斯模型的概率融合的方法以及未在文中列出,结合知识蒸馏的方法训练一个扫地机大模型也是可以尝试的方向(可用方法就千千万了)
数据集方面,包含了现有大模型数据集,量大管饱但需要从中筛选出可以使用的数据也需要一定的工作量;也包含了一些特定场景的数据集,可以直接使用或作为补充数据集。
由于时间有限,并未对文中所列方法进行进一步的指标复现和自有数据训练,本次调研旨在尽可能的涵盖所有可能性以供讨论,确立大概技术路线后,下一步则对模型本身进行进一步的研究和分析。
reference
- https://github.com/OpenDriveLab/OccNet/tree/main
- https://github.com/hlwang1124/SNE-RoadSeg
- https://github.com/chaytonmin/Off-Road-Freespace-Detection
- https://github.com/NVIDIA-AI-IOT/robot_freespace_seg_Isaac_TAO/tree/main
- https://github.com/hustvl/YOLOP
- https://github.com/CAIC-AD/YOLOPv2
- https://readpaper.com/pdf-annotate/note?pdfId=4516871595854815233¬eId=2076929048728094976
- https://github.com/xmba15/obstacle_detection_stixelnet
- https://github.com/bborja/mods_evaluation
- https://video.aiaa.org/title/4119aef8-405c-4414-a3b6-c02fb958af1e
- https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=9134735
- https://arxiv.org/pdf/1806.08007.pdf
- https://github.com/SAMMiCA/RODSNet
- https://www.mdpi.com/1424-8220/22/17/6537
- https://github.com/wzzheng/TPVFormer
- https://www.mdpi.com/2072-4292/14/15/3824
- https://github.com/misaleh/Free-space-and-obstacle-detection
- https://github.com/visualbuffer/copilot
- https://arxiv.org/pdf/2301.08390v2.pdf
- https://github.com/matejgrcic/DenseHybrid
- https://github.com/BUserName/PGL
- https://github.com/taslimisina/osr-ood-ad-methods
- https://github.com/ningkp/LfOSA
- https://arxiv.org/pdf/2207.01071v2.pdf
- https://arxiv.org/pdf/1903.11752v3.pdf
- https://arxiv.org/pdf/2101.10511.pdf