CIFAR10实战
文章目录
- 初尝试
- 模型优化
- 最优化方法比较
- 初步完整训练测试代码
- 增强数据预处理
- 模型结构微改进
- AdamW 优化器+权重衰减
- 增加Dropout层+增大epochs
- 再次删除Dropout
- 模型结构增强
- 完整代码
- ResNet模型尝试+GPU
- 总代码
初尝试
import torch
import torchvision
from torch.nn import Sequential, CrossEntropyLoss
from torch.optim import SGD
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import torch.nn as nn#下载数据集
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize([0.5],[0.5])
])train_datasets = torchvision.datasets.CIFAR10('..data',train=True,transform=transform,download=True)
test_datasets = torchvision.datasets.CIFAR10('..data',train=False,transform=transform,download=True)#数据长度
print('train_datasets:',len(train_datasets))
print('test_datasets:',len(test_datasets))#从加载器中获取数据
train_dl = DataLoader(train_datasets,batch_size=32,shuffle=True,num_workers=0,drop_last=False)
test_dl = DataLoader(test_datasets,batch_size=32,shuffle=True,num_workers=0,drop_last=False)#用tensorboard查看图片
writer = SummaryWriter('CIFAR10')step = 0for batch_idx,(imgs, tragets) in enumerate(train_dl):writer.add_images('train_datasets_02', imgs, step, dataformats='NCHW')step += 1writer.close()#构造模型
class Model(nn.Module):def __init__(self):super(Model,self).__init__()self.model1 = Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,padding=2),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,padding=2),nn.MaxPool2d(kernel_size=2),nn.Flatten(),nn.Linear(in_features=64*4*4,out_features=64),nn.Linear(in_features=64,out_features=10))def forward(self,input):output = self.model1(input)return output#模型训练
epochs = 10
model = Model()loss_fn = CrossEntropyLoss()
writer = SummaryWriter('train_data')
optim = SGD(model.parameters(),lr = 0.01)for epoch in range(epochs):train_acc = 0.0train_loss = 0.0for img,target in train_dl:output = model(img)loss = loss_fn(output,target)optim.zero_grad()loss.backward()optim.step()train_loss = train_loss + losstrain_acc += (output.argmax(axis=1) == target).sum().item()print("epoch:",epoch + 1,"train_loss:",train_loss.item()/len(train_dl))print("epoch:", epoch + 1, "train_acc:", train_acc/len(train_datasets))writer.add_scalar('train_loss',train_loss.item()/len(train_dl),epoch+1)writer.add_scalar('train_acc',train_acc/len(train_datasets),epoch+1)writer.close()

对于CIFAR10这个数据集,73%的正确率是比较低的,接下来进行一步步的优化
模型优化
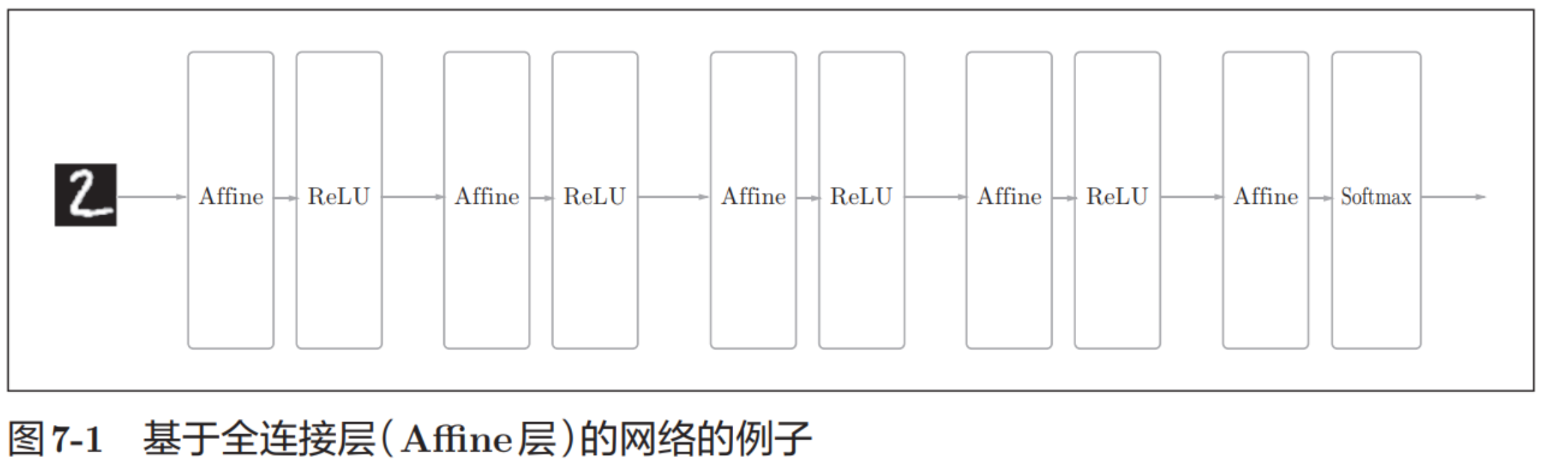
Batch Norm有以下优点。
• 可以使学习快速进行(可以增大学习率)。
• 不那么依赖初始值(对于初始值不用那么神经质)。
• 抑制过拟合(降低Dropout等的必要性)。
import torch
import torchvision
from torch.nn import Sequential, CrossEntropyLoss
from torch.optim import SGD, Adamax
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import torch.nn as nn#下载数据集
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize([0.5],[0.5])
])train_datasets = torchvision.datasets.CIFAR10('..data',train=True,transform=transform,download=True)
test_datasets = torchvision.datasets.CIFAR10('..data',train=False,transform=transform,download=True)#数据长度
print('train_datasets:',len(train_datasets))
print('test_datasets:',len(test_datasets))#从加载器中获取数据
train_dl = DataLoader(train_datasets,batch_size=32,shuffle=True,num_workers=0,drop_last=False)
test_dl = DataLoader(test_datasets,batch_size=32,shuffle=True,num_workers=0,drop_last=False)#用tensorboard查看图片
writer = SummaryWriter('CIFAR10')step = 0for batch_idx,(imgs, tragets) in enumerate(train_dl):writer.add_images('train_datasets_02', imgs, step, dataformats='NCHW')step += 1writer.close()#构造模型
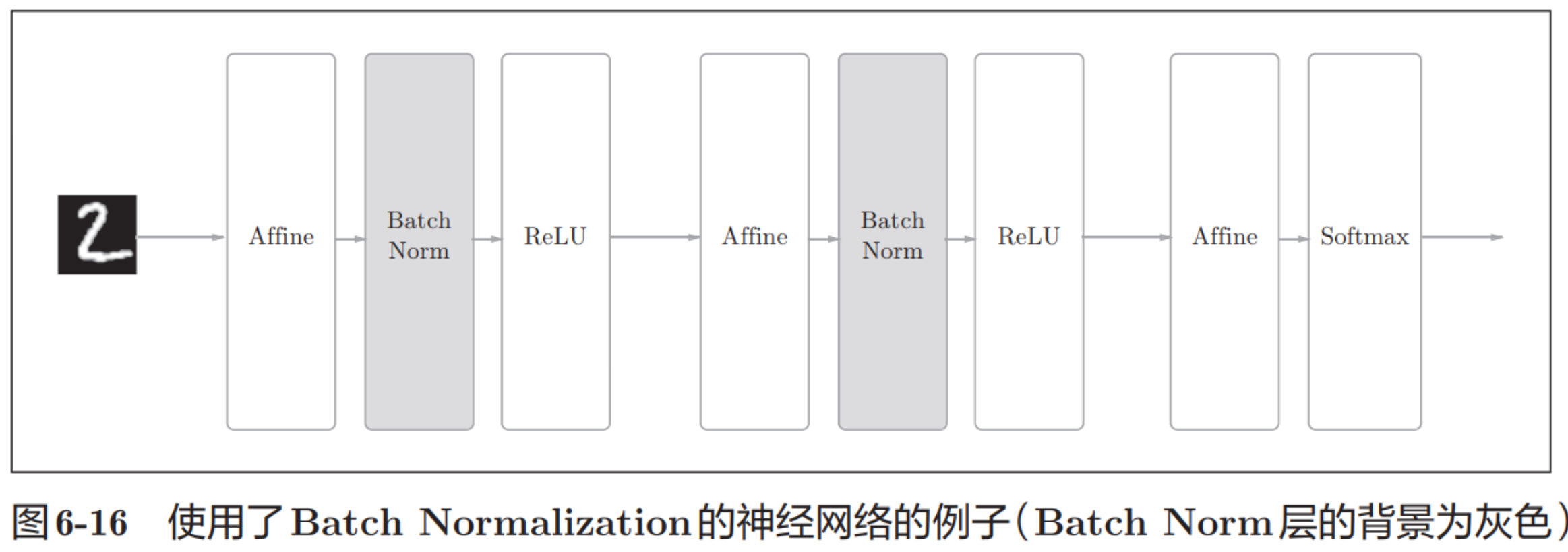
class Model(nn.Module):def __init__(self):super(Model,self).__init__()self.model1 = Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,padding=2),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,padding=2),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Flatten(),nn.Linear(in_features=64*4*4,out_features=64),nn.Linear(in_features=64,out_features=10))def forward(self,input):output = self.model1(input)return output#模型训练
epochs = 10
model = Model()loss_fn = CrossEntropyLoss()
writer = SummaryWriter('train_data')
optim = SGD(model.parameters(),lr = 0.01)for epoch in range(epochs):train_acc = 0.0train_loss = 0.0for img,target in train_dl:output = model(img)loss = loss_fn(output,target)optim.zero_grad()loss.backward()optim.step()train_loss = train_loss + losstrain_acc += (output.argmax(axis=1) == target).sum().item()print("epoch:",epoch + 1,"train_loss:",train_loss.item()/len(train_dl))print("epoch:", epoch + 1, "train_acc:", train_acc/len(train_datasets))writer.add_scalar('train_loss',train_loss.item()/len(train_dl),epoch+1)writer.add_scalar('train_acc',train_acc/len(train_datasets),epoch+1)writer.close()
训练效果有一点的提升。
最优化方法比较
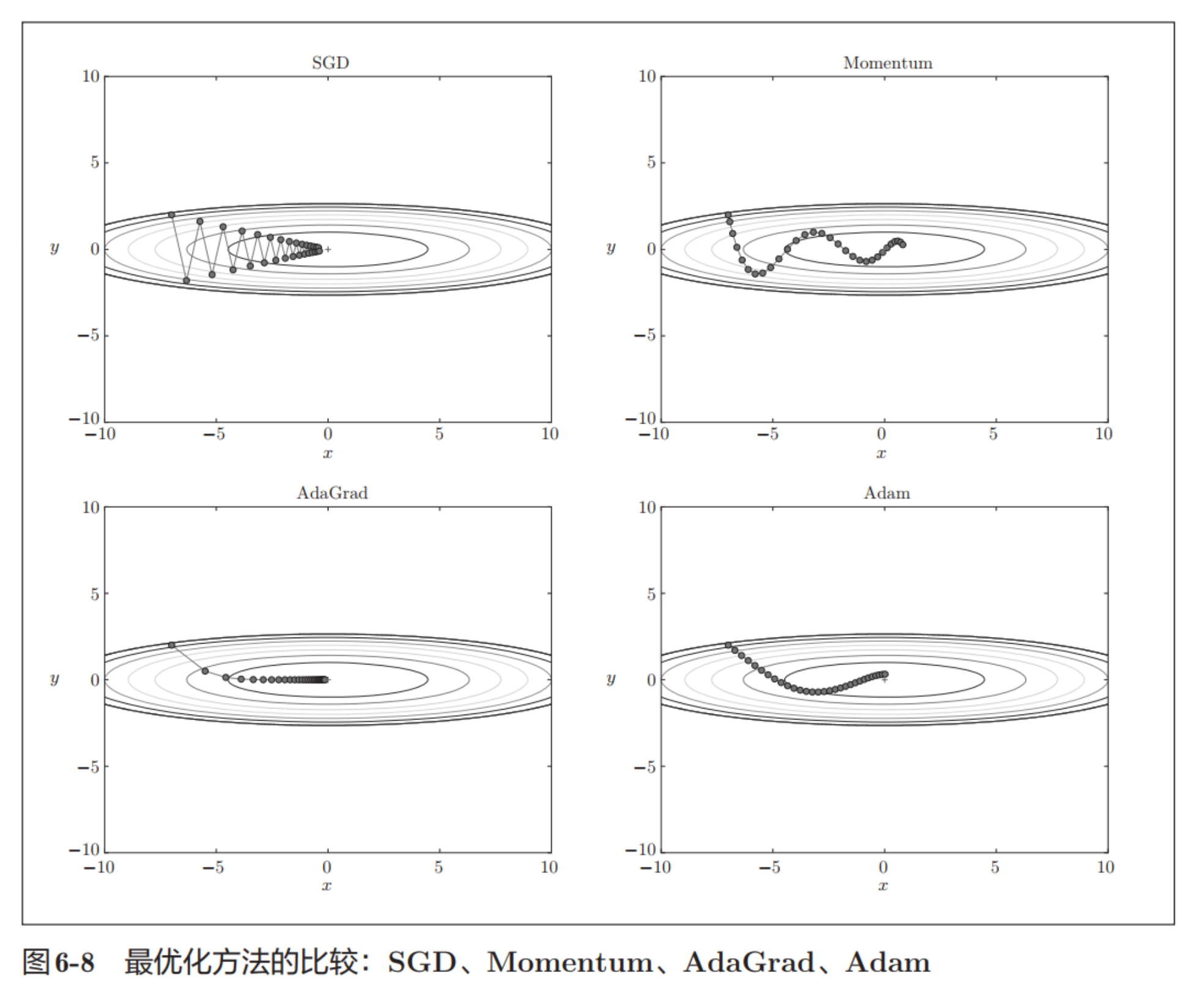
由图可见,后两者效果比较好。
import torch
import torchvision
from torch.nn import Sequential, CrossEntropyLoss
from torch.optim import SGD, Adamax
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import torch.nn as nn#下载数据集
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize([0.5],[0.5])
])train_datasets = torchvision.datasets.CIFAR10('..data',train=True,transform=transform,download=True)
test_datasets = torchvision.datasets.CIFAR10('..data',train=False,transform=transform,download=True)#数据长度
print('train_datasets:',len(train_datasets))
print('test_datasets:',len(test_datasets))#从加载器中获取数据
train_dl = DataLoader(train_datasets,batch_size=32,shuffle=True,num_workers=0,drop_last=False)
test_dl = DataLoader(test_datasets,batch_size=32,shuffle=True,num_workers=0,drop_last=False)#用tensorboard查看图片
writer = SummaryWriter('CIFAR10')step = 0for batch_idx,(imgs, tragets) in enumerate(train_dl):writer.add_images('train_datasets_02', imgs, step, dataformats='NCHW')step += 1writer.close()#构造模型
class Model(nn.Module):def __init__(self):super(Model,self).__init__()self.model1 = Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,padding=2),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,padding=2),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Flatten(),nn.Linear(in_features=64*4*4,out_features=64),nn.Linear(in_features=64,out_features=10))def forward(self,input):output = self.model1(input)return output#模型训练
epochs = 10
model = Model()loss_fn = CrossEntropyLoss()
writer = SummaryWriter('train_data')
#optim = SGD(model.parameters(),lr = 0.01)
optim = Adamax(model.parameters(),lr = 2e-3)for epoch in range(epochs):train_acc = 0.0train_loss = 0.0for img,target in train_dl:output = model(img)loss = loss_fn(output,target)optim.zero_grad()loss.backward()optim.step()train_loss = train_loss + losstrain_acc += (output.argmax(axis=1) == target).sum().item()print("epoch:",epoch + 1,"train_loss:",train_loss.item()/len(train_dl))print("epoch:", epoch + 1, "train_acc:", train_acc/len(train_datasets))writer.add_scalar('train_loss',train_loss.item()/len(train_dl),epoch+1)writer.add_scalar('train_acc',train_acc/len(train_datasets),epoch+1)writer.close()
optim = Adamax(model.parameters(),lr = 2e-3)
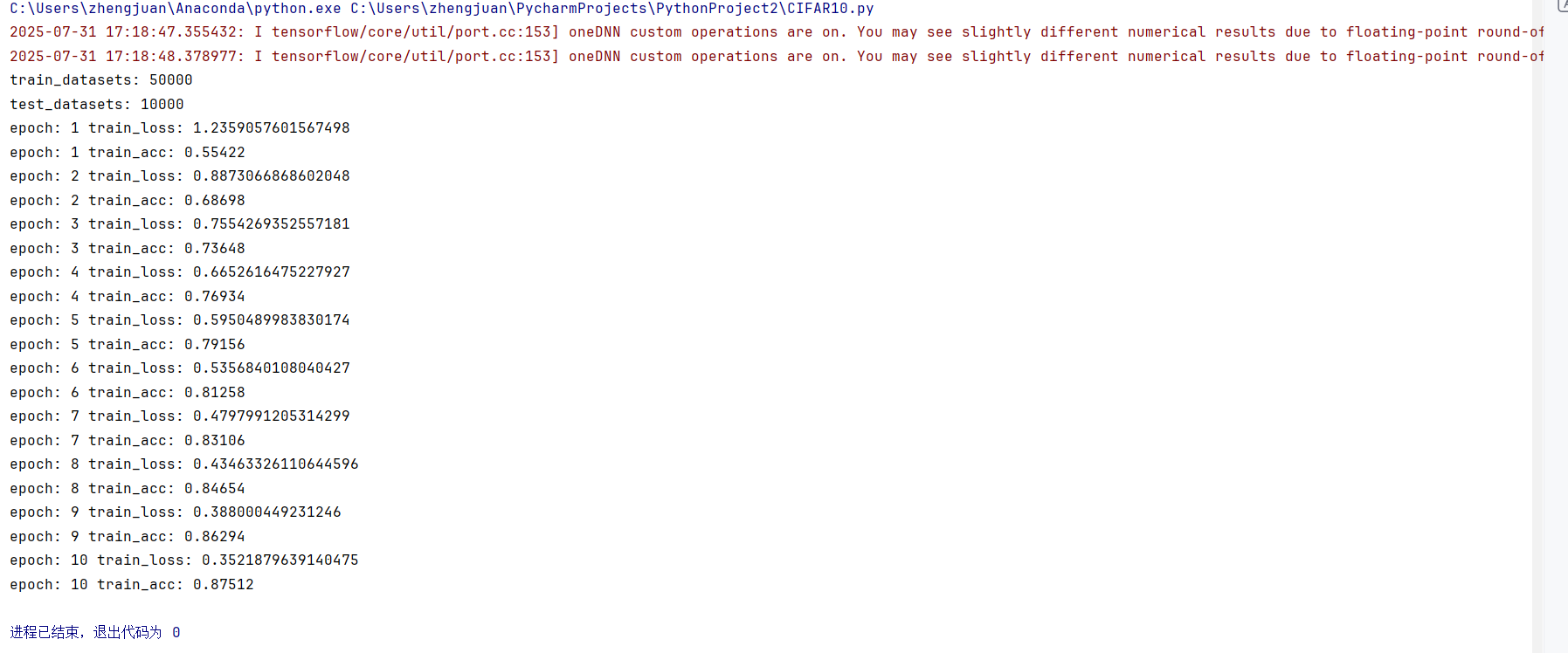
optim = Adagrad(model.parameters(),lr=1e-2)
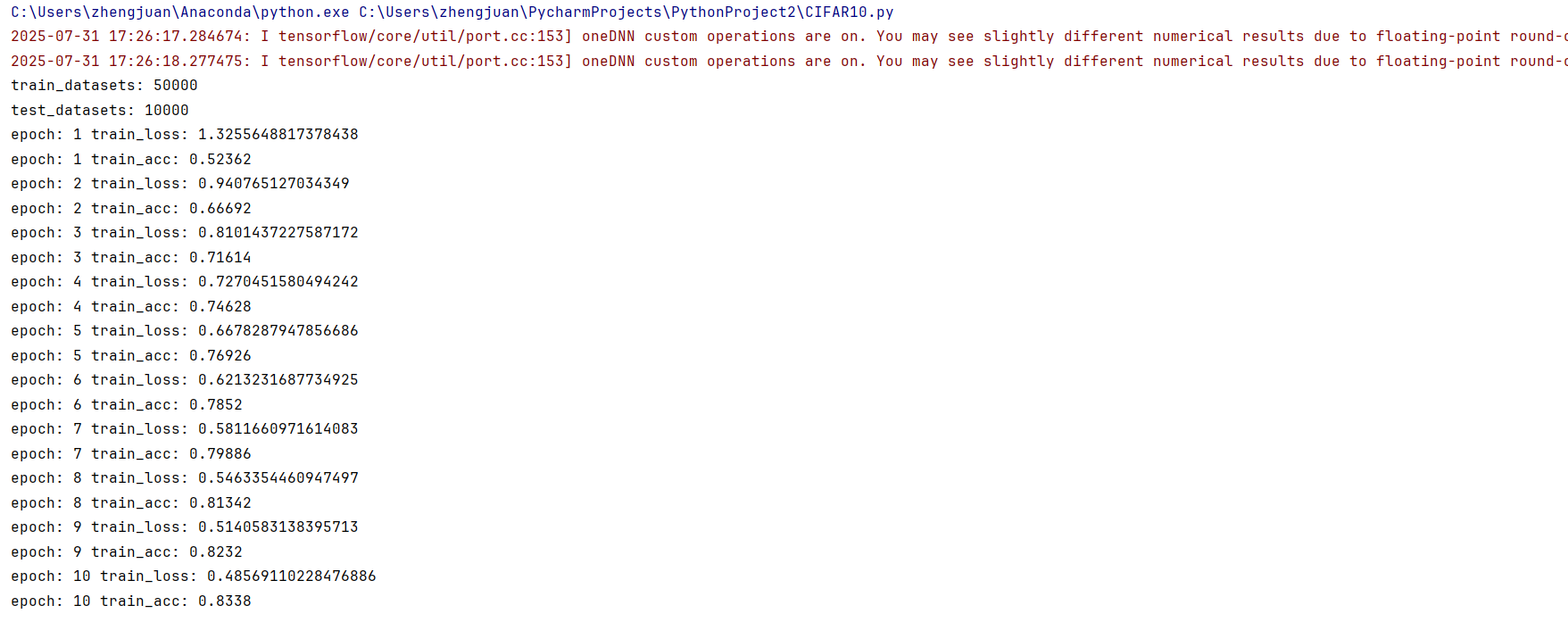
效果更一般。
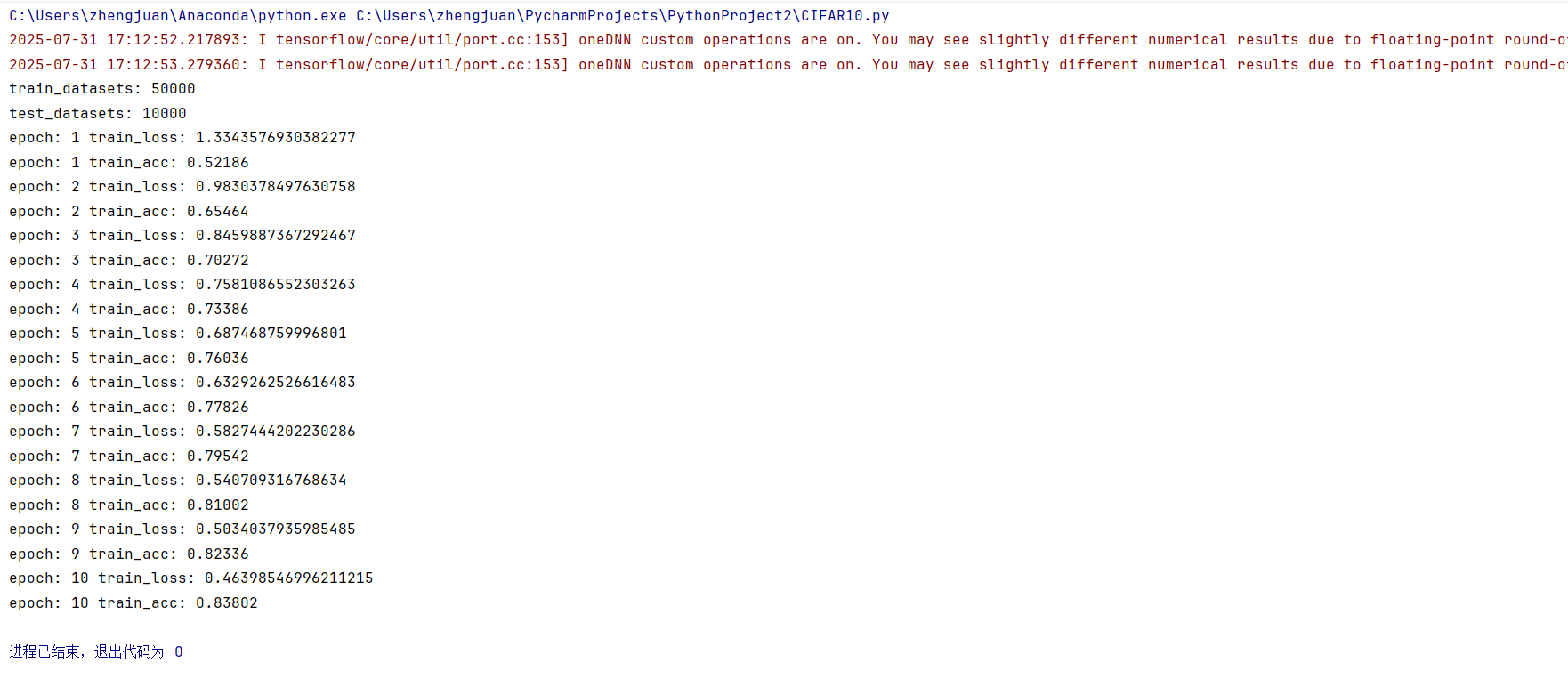
初步完整训练测试代码
import torch
import torchvision
from torch.nn import Sequential, CrossEntropyLoss
from torch.optim import SGD, Adamax, Adagrad
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import torch.nn as nn#下载数据集
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor(),torchvision.transforms.Normalize([0.5],[0.5])
])train_datasets = torchvision.datasets.CIFAR10('..data',train=True,transform=transform,download=True)
test_datasets = torchvision.datasets.CIFAR10('..data',train=False,transform=transform,download=True)#数据长度
print('train_datasets:',len(train_datasets))
print('test_datasets:',len(test_datasets))#从加载器中获取数据
train_dl = DataLoader(train_datasets,batch_size=32,shuffle=True,num_workers=0,drop_last=False)
test_dl = DataLoader(test_datasets,batch_size=32,shuffle=True,num_workers=0,drop_last=False)#用tensorboard查看图片
writer = SummaryWriter('CIFAR10')step = 0for batch_idx,(imgs, tragets) in enumerate(train_dl):writer.add_images('train_datasets_02', imgs, step, dataformats='NCHW')step += 1writer.close()#构造模型
class Model(nn.Module):def __init__(self):super(Model,self).__init__()self.model1 = Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,padding=2),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,padding=2),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Flatten(),nn.Linear(in_features=64*4*4,out_features=64),nn.Linear(in_features=64,out_features=10))def forward(self,input):output = self.model1(input)return output#模型训练
epochs = 10
model = Model()loss_fn = CrossEntropyLoss()
writer = SummaryWriter('train_data')
#optim = SGD(model.parameters(),lr = 0.01)
optim = Adamax(model.parameters(),lr = 2e-3)
#optim = Adagrad(model.parameters(),lr=1e-2)for epoch in range(epochs):train_acc = 0.0train_loss = 0.0for img,target in train_dl:output = model(img)loss = loss_fn(output,target)optim.zero_grad()loss.backward()optim.step()train_loss = train_loss + losstrain_acc += (output.argmax(axis=1) == target).sum().item()print("epoch:",epoch + 1,"train_loss:",train_loss.item()/len(train_dl))print("epoch:", epoch + 1, "train_acc:", train_acc/len(train_datasets))writer.add_scalar('train_loss',train_loss.item()/len(train_dl),epoch+1)writer.add_scalar('train_acc',train_acc/len(train_datasets),epoch+1)writer.close()#模型测试
for epoch in range(epochs):test_loss = 0.0test_acc = 0.0with torch.no_grad():for imgs,targets in test_dl:output = model(imgs)loss = loss_fn(output,targets)test_loss += losstest_acc += (output.argmax(axis=1) == targets).sum().item()print("epoch:",epoch+1,"train_loss:",test_loss/len(test_dl))print("epoch:",epoch+1,"train_acc:",test_acc/len(test_datasets))
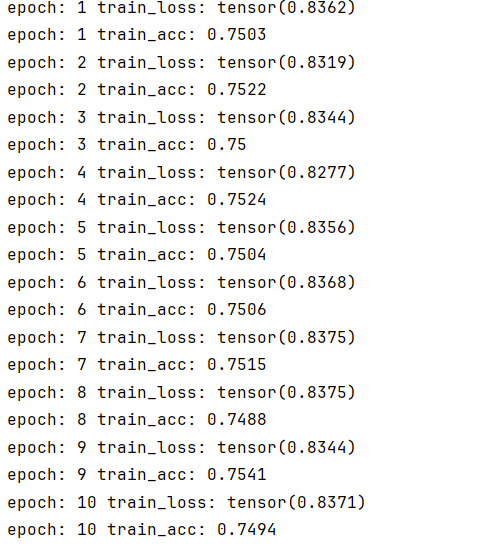
test_loss很高,而且test_acc也不是很高(上面图的train_acc跟train_loss写错了,是test_loss,test_acc),有点过拟合。
增强数据预处理
transform = torchvision.transforms.Compose([torchvision.transforms.RandomHorizontalFlip(), #随机翻转torchvision.transforms.RandomCrop(32,padding=4), #随机裁剪+填充torchvision.transforms.ToTensor(),torchvision.transforms.Normalize([0.4914,0.4822,0.4465],[0.2470,0.2435,0.2616])
])模型结构微改进
#构造模型
class Model(nn.Module):def __init__(self):super(Model,self).__init__()self.model1 = Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,padding=2),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,padding=2),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Dropout(),nn.Flatten(),nn.Linear(in_features=64*4*4,out_features=64),nn.Linear(in_features=64,out_features=10))def forward(self,input):output = self.model1(input)return output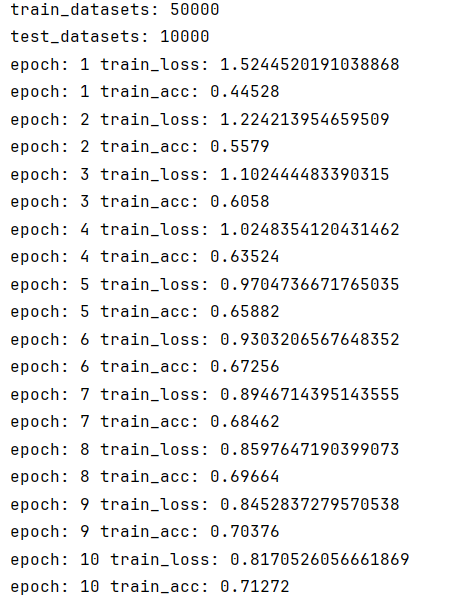
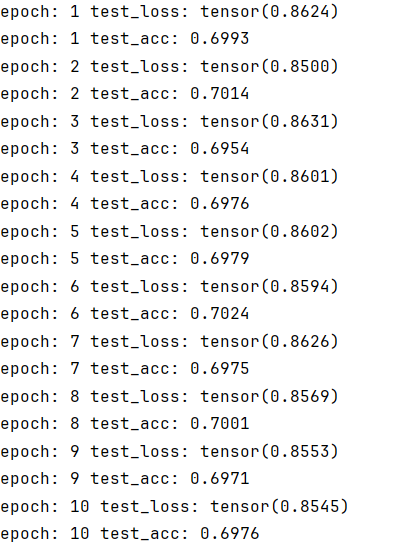
哈哈哈更低了
我试了一下把Dropout()删除,重新跑,正确率还更高了一点
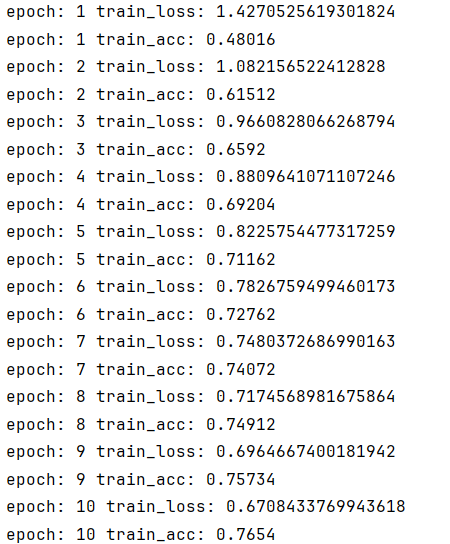
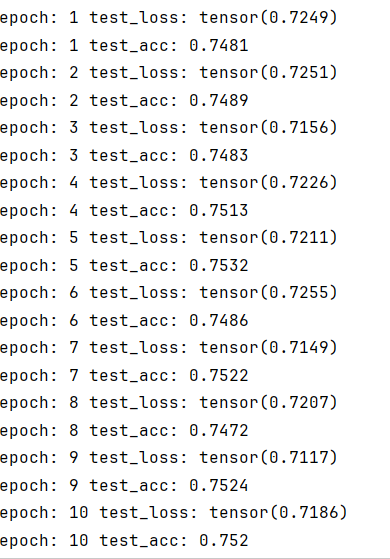
没有过拟合问题了,但是数据都还是比较低的
AdamW 优化器+权重衰减
对于现代深度学习模型,优先使用AdamW而不是Adam,因为它的权重衰减实现更符合理论预期。
optim = AdamW(model.parameters(),lr=1e-3,weight_decay=1e-2) #AdamW优化器 + 权重衰减
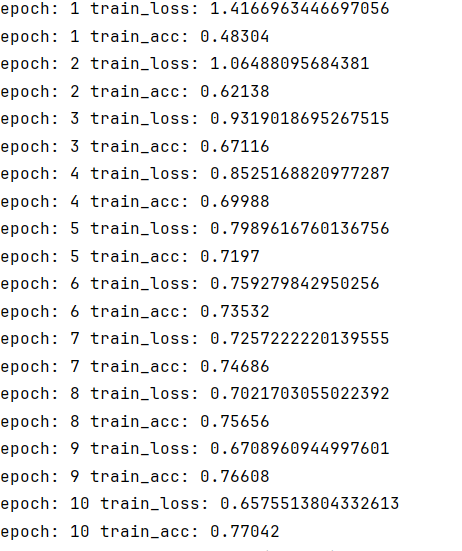

也很一般,差不多
增加Dropout层+增大epochs
class Model(nn.Module):def __init__(self):super(Model,self).__init__()self.model1 = Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Dropout(0.25),nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,padding=2),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Dropout(0.25),nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,padding=2),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Dropout(0.25),nn.Flatten(),nn.Linear(in_features=64*4*4,out_features=64),nn.Linear(in_features=64,out_features=10))def forward(self,input):output = self.model1(input)return outputepochs = 20
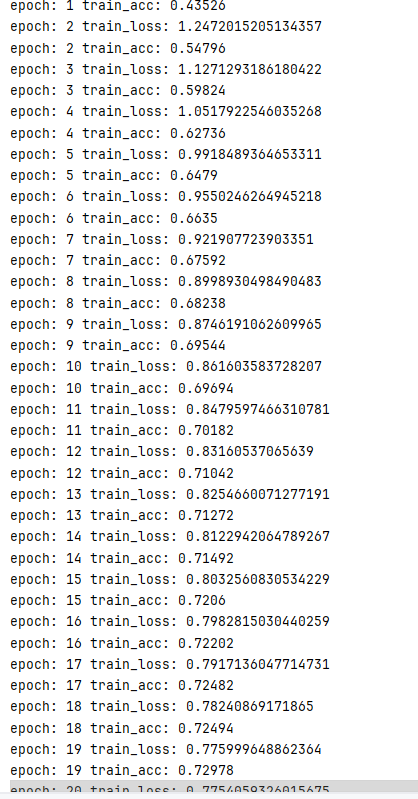
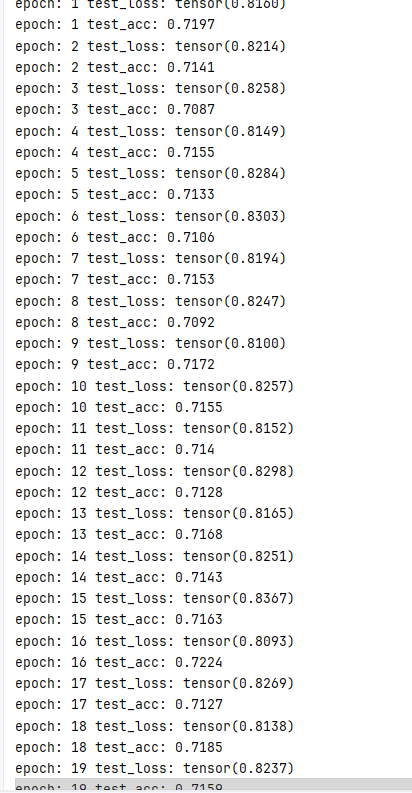
再次删除Dropout
class Model(nn.Module):def __init__(self):super(Model,self).__init__()self.model1 = Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,padding=2),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,padding=2),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Flatten(),nn.Linear(in_features=64*4*4,out_features=64),nn.Linear(in_features=64,out_features=10))def forward(self,input):output = self.model1(input)return output
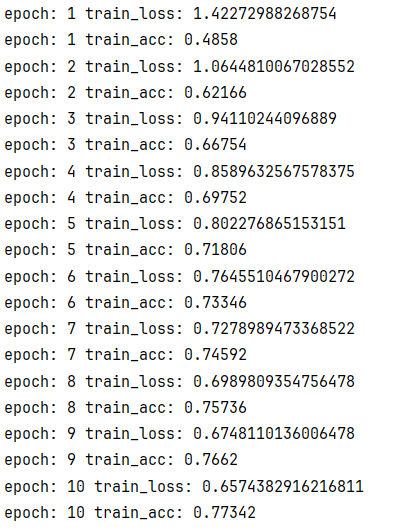
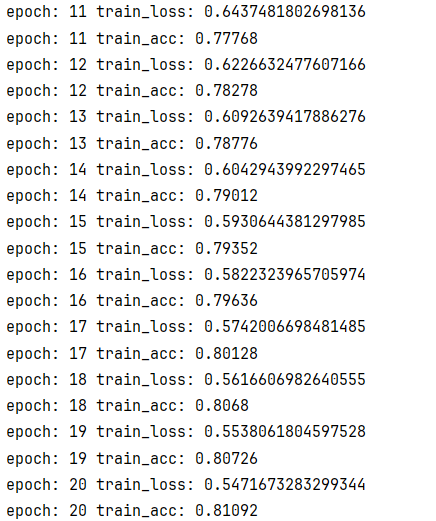
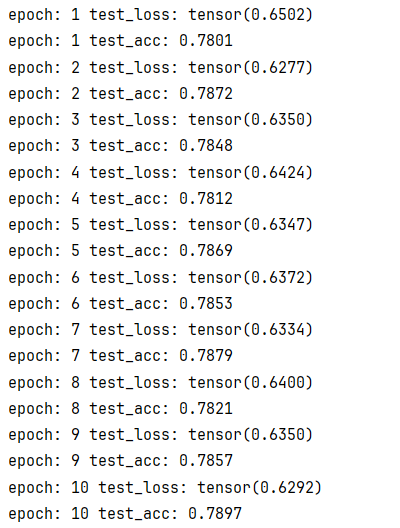

好了一点点,全靠epochs增大了算是
模型结构增强
class EnhancedModel(nn.Module):def __init__(self):super().__init__()self.features = nn.Sequential(# 第一组卷积nn.Conv2d(3, 64, 3, padding=1),nn.BatchNorm2d(64),nn.ReLU(),nn.Conv2d(64, 64, 3, padding=1),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(2),nn.Dropout(0.25), # 新增Dropout# 第二组卷积nn.Conv2d(64, 128, 3, padding=1),nn.BatchNorm2d(128),nn.ReLU(),nn.Conv2d(128, 128, 3, padding=1),nn.BatchNorm2d(128),nn.ReLU(),nn.MaxPool2d(2),nn.Dropout(0.25),# 第三组卷积nn.Conv2d(128, 256, 3, padding=1),nn.BatchNorm2d(256),nn.ReLU(),nn.MaxPool2d(2),)self.classifier = nn.Sequential(nn.Linear(256*4*4, 512),nn.BatchNorm1d(512),nn.ReLU(),nn.Dropout(0.5), # 更高的Dropoutnn.Linear(512, 10))def forward(self, x):x = self.features(x)x = torch.flatten(x, 1)x = self.classifier(x)return x
完整代码
import torch
import torchvision
from torch.nn import Sequential, CrossEntropyLoss
from torch.optim import SGD, Adamax, Adagrad, AdamW
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import torch.nn as nn#下载数据集
transform = torchvision.transforms.Compose([torchvision.transforms.RandomHorizontalFlip(), #随机翻转torchvision.transforms.RandomCrop(32,padding=4), #随机裁剪+填充torchvision.transforms.ToTensor(),torchvision.transforms.Normalize([0.4914,0.4822,0.4465],[0.2470,0.2435,0.2616])
])train_datasets = torchvision.datasets.CIFAR10('..data',train=True,transform=transform,download=True)
test_datasets = torchvision.datasets.CIFAR10('..data',train=False,transform=transform,download=True)#数据长度
print('train_datasets:',len(train_datasets))
print('test_datasets:',len(test_datasets))#从加载器中获取数据
train_dl = DataLoader(train_datasets,batch_size=32,shuffle=True,num_workers=0,drop_last=False)
test_dl = DataLoader(test_datasets,batch_size=32,shuffle=True,num_workers=0,drop_last=False)#用tensorboard查看图片
writer = SummaryWriter('CIFAR10')step = 0for batch_idx,(imgs, tragets) in enumerate(train_dl):writer.add_images('train_datasets_02', imgs, step, dataformats='NCHW')step += 1writer.close()#构造模型
class Model(nn.Module):def __init__(self):super(Model,self).__init__()self.model1 = Sequential(nn.Conv2d(in_channels=3,out_channels=32,kernel_size=5,padding=2),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=32,kernel_size=5,padding=2),nn.BatchNorm2d(32),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Conv2d(in_channels=32,out_channels=64,kernel_size=5,padding=2),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(kernel_size=2),nn.Flatten(),nn.Linear(in_features=64*4*4,out_features=64),nn.Linear(in_features=64,out_features=10))def forward(self,input):output = self.model1(input)return outputclass EnhancedModel(nn.Module):def __init__(self):super().__init__()self.features = nn.Sequential(# 第一组卷积nn.Conv2d(3, 64, 3, padding=1),nn.BatchNorm2d(64),nn.ReLU(),nn.Conv2d(64, 64, 3, padding=1),nn.BatchNorm2d(64),nn.ReLU(),nn.MaxPool2d(2),nn.Dropout(0.25), # 新增Dropout# 第二组卷积nn.Conv2d(64, 128, 3, padding=1),nn.BatchNorm2d(128),nn.ReLU(),nn.Conv2d(128, 128, 3, padding=1),nn.BatchNorm2d(128),nn.ReLU(),nn.MaxPool2d(2),nn.Dropout(0.25),# 第三组卷积nn.Conv2d(128, 256, 3, padding=1),nn.BatchNorm2d(256),nn.ReLU(),nn.MaxPool2d(2),)self.classifier = nn.Sequential(nn.Linear(256 * 4 * 4, 512),nn.BatchNorm1d(512),nn.ReLU(),nn.Dropout(0.5), # 更高的Dropoutnn.Linear(512, 10))def forward(self, x):x = self.features(x)x = torch.flatten(x, 1)x = self.classifier(x)return x#模型训练
epochs = 10
model = Model()
model1 = EnhancedModel()loss_fn = CrossEntropyLoss()
writer = SummaryWriter('train_data')
#optim = SGD(model.parameters(),lr = 0.01)
#optim = Adamax(model.parameters(),lr = 2e-3,weight_decay=1e-4) #设置了权重衰减参数
#optim = Adagrad(model.parameters(),lr=1e-2)
optim = AdamW(model1.parameters(),lr=1e-3,weight_decay=1e-2) #AdamW优化器 + 权重衰减for epoch in range(epochs):train_acc = 0.0train_loss = 0.0for img,target in train_dl:output = model1(img)loss = loss_fn(output,target)optim.zero_grad()loss.backward()optim.step()train_loss = train_loss + losstrain_acc += (output.argmax(axis=1) == target).sum().item()print("epoch:",epoch + 1,"train_loss:",train_loss.item()/len(train_dl))print("epoch:", epoch + 1, "train_acc:", train_acc/len(train_datasets))writer.add_scalar('train_loss',train_loss.item()/len(train_dl),epoch+1)writer.add_scalar('train_acc',train_acc/len(train_datasets),epoch+1)writer.close()#模型测试
for epoch in range(epochs):test_loss = 0.0test_acc = 0.0with torch.no_grad():for imgs,targets in test_dl:output = model1(imgs)loss = loss_fn(output,targets)test_loss += losstest_acc += (output.argmax(axis=1) == targets).sum().item()print("epoch:",epoch+1,"test_loss:",test_loss/len(test_dl))print("epoch:",epoch+1,"test_acc:",test_acc/len(test_datasets))
卷积核要小一点 55 对于3232来说太大了,改为3*3
搭配新增的Dropout
好多了
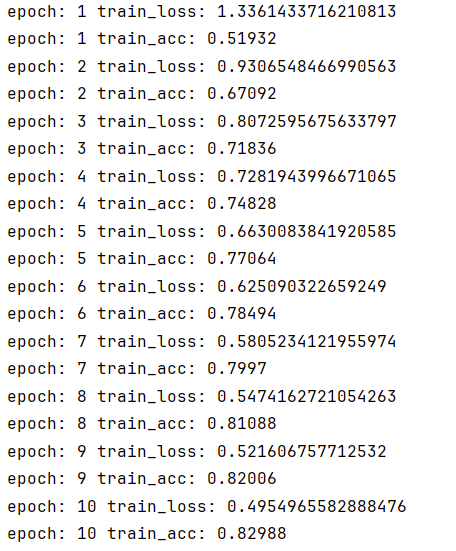

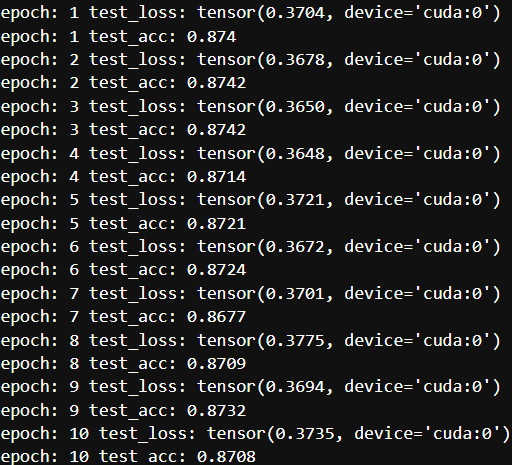
ResNet模型尝试+GPU
import torchvision.models as models# 直接调用(ImageNet预训练)
model = models.resnet18(pretrained=True) # 输出1000类# 针对CIFAR-10的调整:
# 修改第一层卷积(原为7x7 stride=2,适合224x224输入)
model.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
# 移除第一个MaxPool(CIFAR-32尺寸太小)
model.maxpool = nn.Identity()
# 修改输出层
model.fc = nn.Linear(512, 10) # CIFAR-10只有10类
总代码
import torch
import torchvision
from torch.nn import Sequential, CrossEntropyLoss
from torch.optim import SGD, Adamax, Adagrad, AdamW
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import torch.nn as nn
import torchvision.models as modelsdevice = torch.device("cuda")
#下载数据集
transform = torchvision.transforms.Compose([torchvision.transforms.RandomHorizontalFlip(), #随机翻转torchvision.transforms.RandomCrop(32,padding=4), #随机裁剪+填充torchvision.transforms.ToTensor(),torchvision.transforms.Normalize([0.4914,0.4822,0.4465],[0.2470,0.2435,0.2616])
])train_datasets = torchvision.datasets.CIFAR10('data',train=True,transform=transform,download=True)
test_datasets = torchvision.datasets.CIFAR10('data',train=False,transform=transform,download=True)#数据长度
print('train_datasets:',len(train_datasets))
print('test_datasets:',len(test_datasets))测试集需要固定顺序以评估模型真实性能
修正:shuffle=False

#从加载器中获取数据
train_dl = DataLoader(train_datasets,batch_size=32,shuffle=True,num_workers=0,drop_last=False)
test_dl = DataLoader(test_datasets,batch_size=32,shuffle=False,num_workers=0,drop_last=False)#构造模型
#模型训练
epochs = 10
#model = Model()
#model1 = EnhancedModel()
model2 = models.resnet18(num_classes=10)
# 适配CIFAR-10的32x32输入
model2.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
model2.maxpool = nn.Identity() # 移除第一个maxpool
model2 = model2.to(device)
loss_fn = CrossEntropyLoss()
loss_fn = loss_fn.to(device)writer = SummaryWriter('train_data')
#optim = SGD(model.parameters(),lr = 0.01)
#optim = Adamax(model.parameters(),lr = 2e-3,weight_decay=1e-4) #设置了权重衰减参数
#optim = Adagrad(model.parameters(),lr=1e-2)
optim = AdamW(model2.parameters(),lr=1e-3,weight_decay=1e-2) #AdamW优化器 + 权重衰减
for epoch in range(epochs):train_acc = 0.0train_loss = 0.0model2.train()for img,target in train_dl:img = img.to(device)target = target.to(device)output = model2(img)loss = loss_fn(output,target)optim.zero_grad()loss.backward()optim.step()train_loss = train_loss + losstrain_acc += (output.argmax(axis=1) == target).sum().item()print("epoch:",epoch + 1,"train_loss:",train_loss.item()/len(train_dl))print("epoch:", epoch + 1, "train_acc:", train_acc/len(train_datasets))writer.add_scalar('train_loss',train_loss.item()/len(train_dl),epoch+1)writer.add_scalar('train_acc',train_acc/len(train_datasets),epoch+1)writer.close()
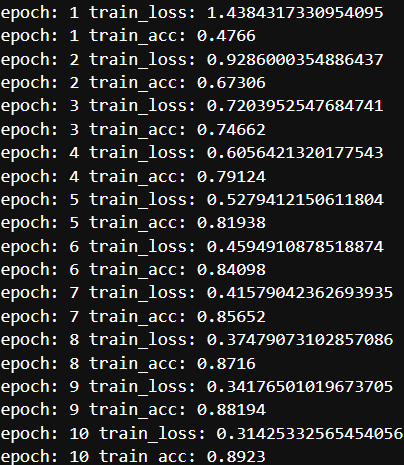
#模型测试
model2.eval()for epoch in range(epochs):test_loss = 0.0test_acc = 0.0with torch.no_grad():for imgs,targets in test_dl:imgs = imgs.to(device)targets = targets.to(device)output = model2(imgs)loss = loss_fn(output,targets)test_loss += losstest_acc += (output.argmax(axis=1) == targets).sum().item()print("epoch:",epoch+1,"test_loss:",test_loss/len(test_dl))print("epoch:",epoch+1,"test_acc:",test_acc/len(test_datasets))