PyTorch分布式训练:从入门到精通
1. 引言
随着深度学习模型规模的不断扩大和训练数据量的爆炸式增长,单机单卡训练已无法满足实际需求。分布式训练通过将计算任务分配到多个计算节点(可以是多GPU或多机),显著缩短了训练时间,成为大规模深度学习训练的必备技术。
PyTorch作为当前最流行的深度学习框架之一,提供了完善的分布式训练支持。本文将全面介绍PyTorch分布式训练的核心概念、实现方法、最佳实践以及性能优化技巧,帮助读者掌握这一关键技术。
2. 分布式训练基础
2.1 为什么需要分布式训练?
随着模型参数量从百万级增长到千亿甚至万亿级(如GPT-3、PaLM等),训练时间从几小时延长到数月。分布式训练通过以下方式解决这一挑战:
- 数据并行:将数据分片到多个设备上,每个设备处理一部分数据
- 模型并行:将模型分片到多个设备上,每个设备处理模型的一部分
- 流水线并行:结合数据并行和模型并行,实现更高效的训练
2.2 分布式训练的挑战
分布式训练面临的主要挑战包括:
- 通信开销:设备间数据同步带来的延迟
- 负载均衡:确保所有设备充分利用
- 容错性:处理设备故障和网络问题
- 实现复杂性:需要编写复杂的并行代码
3. PyTorch分布式训练核心概念
3.1 进程组(Process Group)
PyTorch分布式训练的基础是进程组,它定义了一组可以相互通信的进程。每个进程通常对应一个GPU设备。
graph TD
A[进程组] --> B[进程0/GPU0]
A --> C[进程1/GPU1]
A --> D[进程2/GPU2]
A --> E[进程3/GPU3]
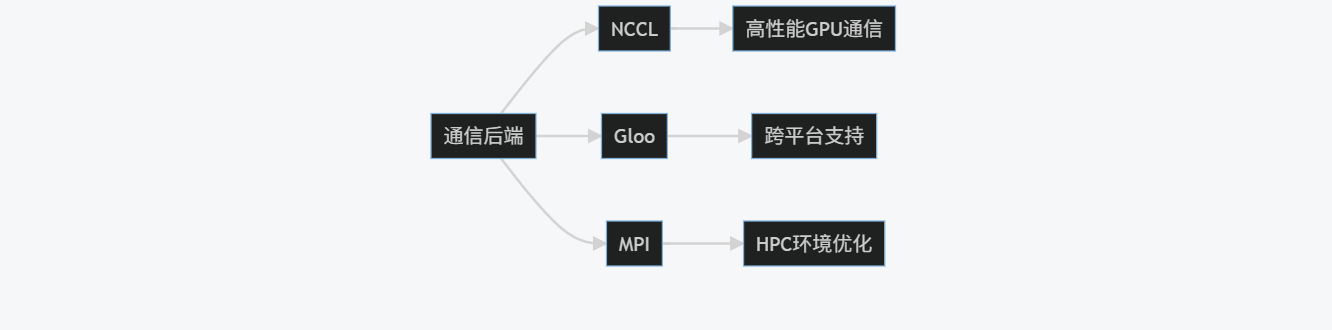
3.2 通信后端(Backend)
PyTorch支持多种通信后端:
- NCCL:NVIDIA Collective Communications Library,针对NVIDIA GPU优化,性能最佳
- Gloo:CPU和GPU通用,支持多种网络类型
- MPI:Message Passing Interface,适合高性能计算环境
graph LR
A[通信后端] --> B[NCCL]
A --> C[Gloo]
A --> D[MPI]
B --> E[高性能GPU通信]
C --> F[跨平台支持]
D --> G[HPC环境优化]
3.3 分布式训练模式
PyTorch主要支持三种分布式训练模式:
- 数据并行(DataParallel):简单易用但效率较低
- 分布式数据并行(DistributedDataParallel):高效且灵活
- RPC(Remote Procedure Call):支持模型并行和更复杂的并行策略
4. 数据并行(DataParallel)
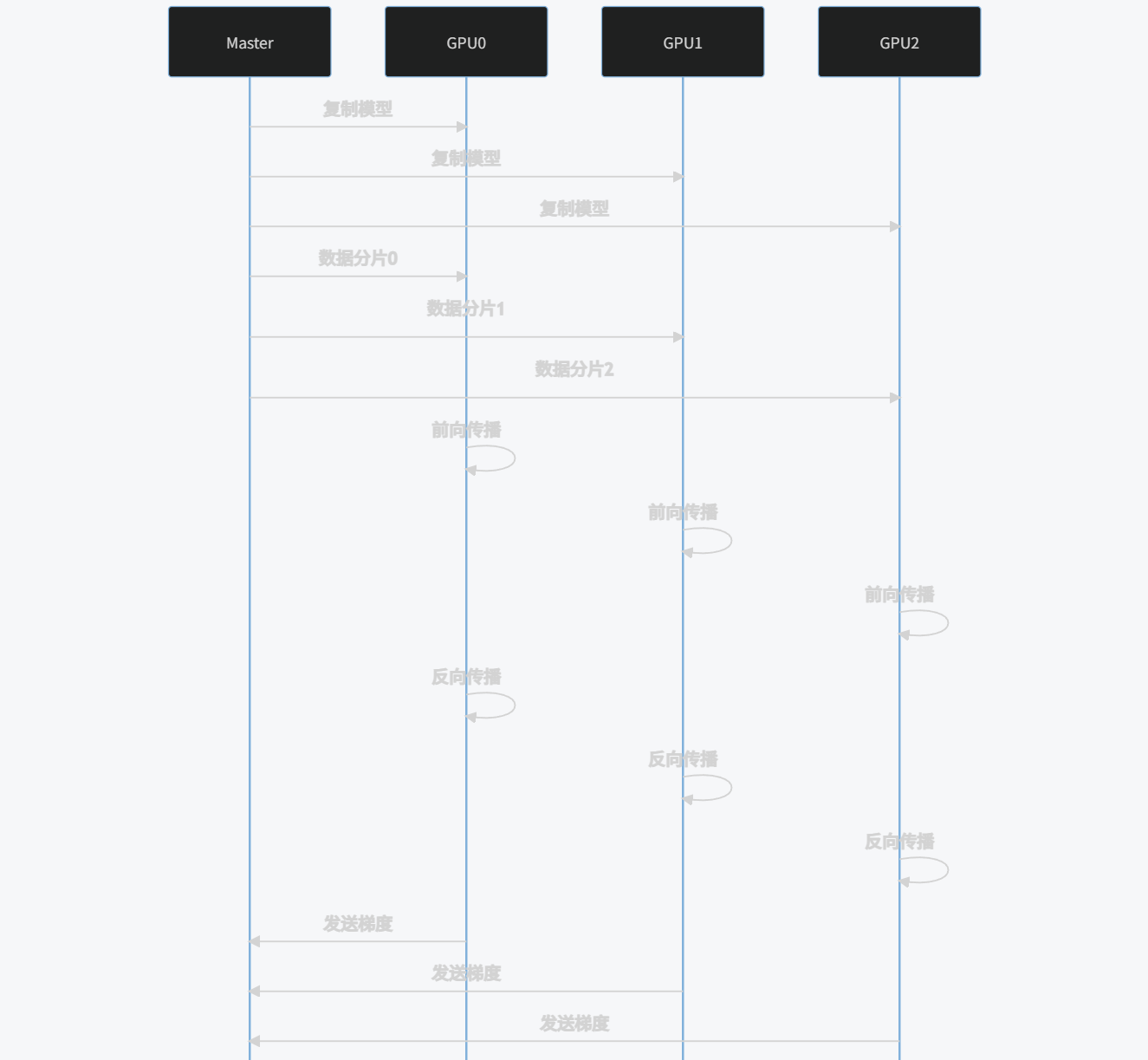
4.1 基本原理
数据并行是最简单的分布式训练方式,其工作原理如下:
- 主进程将模型复制到所有GPU
- 将输入数据分片到不同GPU
- 每个GPU独立计算前向和反向传播
- 主进程收集所有GPU的梯度并平均
- 主进程更新模型参数并广播到所有GPU
sequenceDiagram
participant Master
participant GPU0
participant GPU1
participant GPU2
Master->>GPU0: 复制模型
Master->>GPU1: 复制模型
Master->>GPU2: 复制模型
Master->>GPU0: 数据分片0
Master->>GPU1: 数据分片1
Master->>GPU2: 数据分片2
GPU0->>GPU0: 前向传播
GPU1->>GPU1: 前向传播
GPU2->>GPU2: 前向传播
GPU0->>GPU0: 反向传播
GPU1->>GPU1: 反向传播
GPU2->>GPU2: 反向传播
GPU0->>Master: 发送梯度
GPU1->>Master: 发送梯度
GPU2->>Master: 发送梯度
Master->>Master: 平均梯度
Master->>Master: 更新参数
Master->>GPU0: 广播新参数
Master->>GPU1: 广播新参数
Master->>GPU2: 广播新参数
4.2 代码实现
使用torch.nn.DataParallel实现数据并行非常简单:
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset# 定义简单模型
class SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.fc1 = nn.Linear(10, 100)self.fc2 = nn.Linear(100, 10)def forward(self, x):x = torch.relu(self.fc1(x))x = self.fc2(x)return x# 创建模拟数据集
class RandomDataset(Dataset):def __init__(self, size, length):self.len = lengthself.data = torch.randn(length, size)self.labels = torch.randint(0, 10, (length,))def __getitem__(self, index):return self.data[index], self.labels[index]def __len__(self):return self.len# 参数设置
input_size = 10
output_size = 10
batch_size = 64
data_size = 10000# 初始化模型、数据和损失函数
model = SimpleModel()
if torch.cuda.is_available():model = nn.DataParallel(model) # 包装模型以支持数据并行model.cuda()dataset = RandomDataset(input_size, data_size)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)# 训练循环
for epoch in range(10):for data, target in dataloader:if torch.cuda.is_available():data, target = data.cuda(), target.cuda()optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()print(f'Epoch {epoch}, Loss: {loss.item()}')
4.3 优缺点分析
优点:
- 实现简单,只需几行代码
- 适合快速原型开发和小规模训练
缺点:
- 主进程(GPU0)成为瓶颈,负载不均衡
- 通信效率低,所有梯度必须经过主进程
- 不支持多机训练
5. 分布式数据并行(DistributedDataParallel)
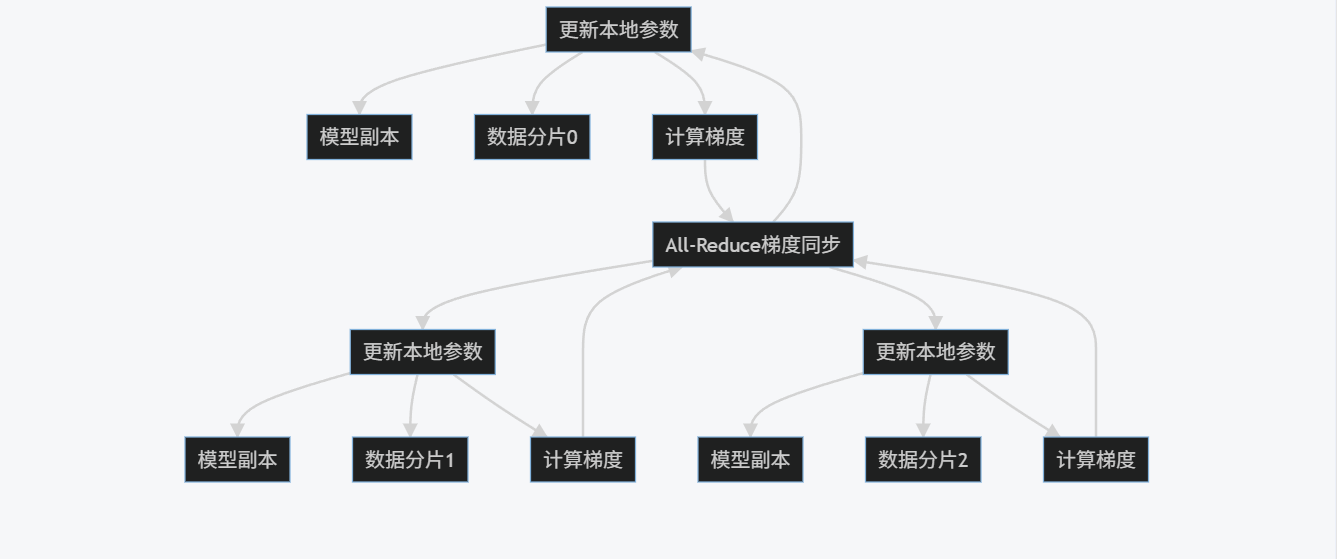
5.1 基本原理
分布式数据并行(DDP)是PyTorch推荐的高效数据并行实现方式。与DataParallel不同,DDP在每个进程上创建一个模型副本,每个进程独立处理数据分片,并通过高效的集体通信(All-Reduce)同步梯度。
graph TD
A[进程0/GPU0] --> B[模型副本]
A --> C[数据分片0]
A --> D[计算梯度]
E[进程1/GPU1] --> F[模型副本]
E --> G[数据分片1]
E --> H[计算梯度]
I[进程2/GPU2] --> J[模型副本]
I --> K[数据分片2]
I --> L[计算梯度]
D --> M[All-Reduce梯度同步]
H --> M
L --> M
M --> A[更新本地参数]
M --> E[更新本地参数]
M --> I[更新本地参数]
5.2 代码实现
使用DDP需要更多设置,但性能显著提升:
import os
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data import DataLoader, Dataset, DistributedSampler# 定义模型(与之前相同)
class SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.fc1 = nn.Linear(10, 100)self.fc2 = nn.Linear(100, 10)def forward(self, x):x = torch.relu(self.fc1(x))x = self.fc2(x)return x# 定义数据集(与之前相同)
class RandomDataset(Dataset):def __init__(self, size, length):self.len = lengthself.data = torch.randn(length, size)self.labels = torch.randint(0, 10, (length,))def __getitem__(self, index):return self.data[index], self.labels[index]def __len__(self):return self.lendef setup(rank, world_size):"""初始化进程组"""os.environ['MASTER_ADDR'] = 'localhost'os.environ['MASTER_PORT'] = '12355'# 初始化NCCL后端dist.init_process_group(backend='nccl',rank=rank,world_size=world_size)def cleanup():"""销毁进程组"""dist.destroy_process_group()def train(rank, world_size):"""训练函数,每个进程执行"""print(f"Running DDP on rank {rank}.")setup(rank, world_size)# 创建模型并移至当前设备model = SimpleModel().to(rank)ddp_model = DDP(model, device_ids=[rank])# 创建数据加载器dataset = RandomDataset(10, 10000)sampler = DistributedSampler(dataset,num_replicas=world_size,rank=rank,shuffle=True)dataloader = DataLoader(dataset,batch_size=64,sampler=sampler,num_workers=4,pin_memory=True)# 定义损失函数和优化器criterion = nn.CrossEntropyLoss().to(rank)optimizer = torch.optim.SGD(ddp_model.parameters(), lr=0.01)# 训练循环for epoch in range(10):sampler.set_epoch(epoch) # 确保每个epoch数据洗牌不同for data, target in dataloader:data, target = data.to(rank), target.to(rank)optimizer.zero_grad()output = ddp_model(data)loss = criterion(output, target)loss.backward()optimizer.step()if rank == 0: # 只在主进程打印print(f'Epoch {epoch}, Loss: {loss.item()}')cleanup()def main():world_size = torch.cuda.device_count()mp.spawn(train, args=(world_size,), nprocs=world_size, join=True)if __name__ == '__main__':main()
5.3 多机训练扩展
对于多机训练,需要修改环境变量设置:
def setup(rank, world_size):"""多机环境初始化"""# 假设使用环境变量传递主节点地址和端口os.environ['MASTER_ADDR'] = os.environ.get('MASTER_ADDR', 'localhost')os.environ['MASTER_PORT'] = os.environ.get('MASTER_PORT', '12355')# 初始化进程组dist.init_process_group(backend='nccl',rank=rank,world_size=world_size)
启动脚本示例(假设有2台机器,每台4个GPU):
# 机器1(主节点)
MASTER_ADDR=192.168.1.1 MASTER_PORT=12355 python -m torch.distributed.launch \--nproc_per_node=4 \--nnodes=2 \--node_rank=0 \--master_addr=192.168.1.1 \--master_port=12355 \train_script.py# 机器2
MASTER_ADDR=192.168.1.1 MASTER_PORT=12355 python -m torch.distributed.launch \--nproc_per_node=4 \--nnodes=2 \--node_rank=1 \--master_addr=192.168.1.1 \--master_port=12355 \train_script.py
5.4 优缺点分析
优点:
- 负载均衡,每个GPU独立工作
- 高效的梯度同步(All-Reduce)
- 支持多机多卡训练
- 更好的性能和扩展性
缺点:
- 实现更复杂,需要初始化进程组
- 需要处理数据分片和采样器
- 调试更困难
6. 模型并行
6.1 基本原理
当模型过大无法放入单个GPU时,需要使用模型并行。模型并行将模型的不同层分配到不同的GPU上,数据在GPU间流动。
graph LR
A[输入数据] --> B[GPU0: 嵌入层]
B --> C[GPU1: Transformer层1]
C --> D[GPU2: Transformer层2]
D --> E[GPU3: 输出层]
E --> F[输出结果]

6.2 代码实现
使用PyTorch的RPC框架实现简单的模型并行:
import torch
import torch.nn as nn
import torch.distributed.rpc as rpc
import torch.multiprocessing as mp
from torch.distributed.rpc import RRef, rpc_async, remoteclass EmbeddingNet(nn.Module):def __init__(self):super(EmbeddingNet, self).__init__()self.embed = nn.Embedding(10000, 1000)def forward(self, x):return self.embed(x)class TransformerNet(nn.Module):def __init__(self):super(TransformerNet, self).__init__()self.transformer = nn.Transformer(d_model=1000, nhead=10)def forward(self, x):return self.transformer(x, x)class OutputNet(nn.Module):def __init__(self):super(OutputNet, self).__init__()self.fc = nn.Linear(1000, 10)def forward(self, x):return self.fc(x)class ModelParallelNet(nn.Module):def __init__(self):super(ModelParallelNet, self).__init__()self.embed_rref = remote("worker1", EmbeddingNet)self.transformer_rref = remote("worker2", TransformerNet)self.output_rref = remote("worker3", OutputNet)def forward(self, x):x_emb = self.embed_rref.remote().forward(x)x_trans = self.transformer_rref.remote().forward(x_emb)x_out = self.output_rref.remote().forward(x_trans)return x_out.to_here()def run_worker(rank, world_size):os.environ['MASTER_ADDR'] = 'localhost'os.environ['MASTER_PORT'] = '29500'# 初始化RPCrpc.init_rpc(f"worker{rank}",rank=rank,world_size=world_size)if rank == 0: # 主进程model = ModelParallelNet()input_data = torch.randint(0, 10000, (32, 50))output = model(input_data)print(output.shape)rpc.shutdown()def main():world_size = 4mp.spawn(run_worker, args=(world_size,), nprocs=world_size, join=True)if __name__ == '__main__':main()
6.3 优缺点分析
优点:
- 可以训练超大模型
- 适合内存受限的场景
缺点:
- 实现复杂
- 通信开销大
- 负载均衡困难
- 难以扩展到多机
7. 混合并行策略
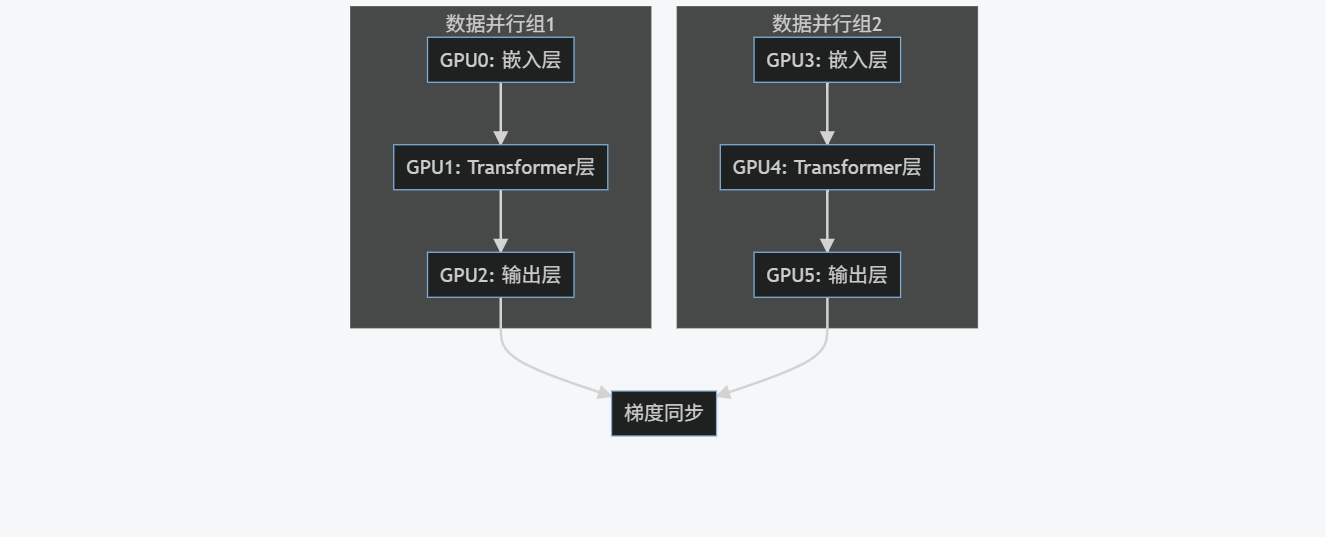
7.1 数据并行+模型并行
实际应用中,通常结合数据并行和模型并行:
graph TD
subgraph "数据并行组1"
A[GPU0: 嵌入层] --> B[GPU1: Transformer层]
B --> C[GPU2: 输出层]
end
subgraph "数据并行组2"
D[GPU3: 嵌入层] --> E[GPU4: Transformer层]
E --> F[GPU5: 输出层]
end
C --> G[梯度同步]
F --> G
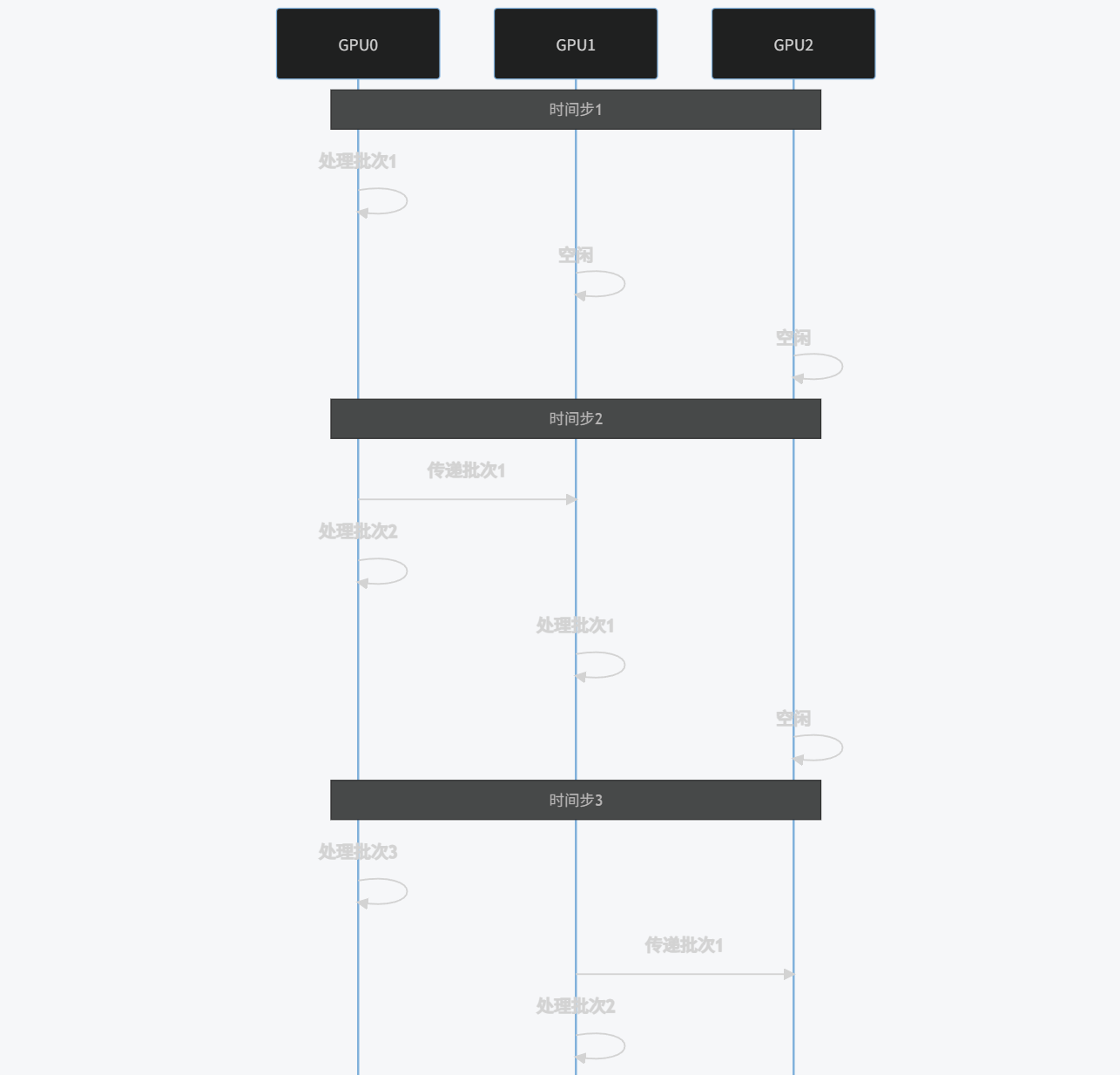
7.2 流水线并行
流水线并行将模型分成多个阶段,每个阶段在不同设备上处理不同的数据批次:
sequenceDiagram
participant GPU0
participant GPU1
participant GPU2
Note over GPU0,GPU2: 时间步1
GPU0->>GPU0: 处理批次1
GPU1->>GPU1: 空闲
GPU2->>GPU2: 空闲
Note over GPU0,GPU2: 时间步2
GPU0->>GPU1: 传递批次1
GPU0->>GPU0: 处理批次2
GPU1->>GPU1: 处理批次1
GPU2->>GPU2: 空闲
Note over GPU0,GPU2: 时间步3
GPU0->>GPU0: 处理批次3
GPU1->>GPU2: 传递批次1
GPU1->>GPU1: 处理批次2
GPU2->>GPU2: 处理批次1
7.3 PyTorch实现示例
使用PyTorch的torch.distributed.pipeline.sync.Pipe实现流水线并行:
import torch
import torch.nn as nn
from torch.distributed.pipeline.sync import Pipe# 定义模型各部分
class Layer1(nn.Module):def __init__(self):super().__init__()self.fc = nn.Linear(10, 100)def forward(self, x):return torch.relu(self.fc(x))class Layer2(nn.Module):def __init__(self):super().__init__()self.fc = nn.Linear(100, 50)def forward(self, x):return torch.relu(self.fc(x))class Layer3(nn.Module):def __init__(self):super().__init__()self.fc = nn.Linear(50, 10)def forward(self, x):return self.fc(x)# 创建模型并分片
model = nn.Sequential(Layer1(),Layer2(),Layer3()
)# 使用Pipe包装模型,指定分片位置
model = Pipe(model, chunks=8) # chunks表示微批次数量# 训练循环
input_data = torch.randn(80, 10) # 总批次大小=80
target = torch.randint(0, 10, (80,))
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss()for epoch in range(10):optimizer.zero_grad()# 前向传播output = model(input_data).local_value()# 计算损失loss = criterion(output, target)# 反向传播loss.backward()# 更新参数optimizer.step()print(f'Epoch {epoch}, Loss: {loss.item()}')
8. 性能优化技巧
8.1 混合精度训练
使用自动混合精度(AMP)可以显著提升训练速度并减少内存占用:
import torch
from torch.cuda.amp import GradScaler, autocast# 初始化梯度缩放器
scaler = GradScaler()# 训练循环
for data, target in dataloader:data, target = data.cuda(), target.cuda()optimizer.zero_grad()# 自动混合精度前向传播with autocast():output = model(data)loss = criterion(output, target)# 缩放损失并反向传播scaler.scale(loss).backward()# 缩放梯度并更新参数scaler.step(optimizer)# 更新缩放器scaler.update()
8.2 梯度累积
当内存不足以支持大批次时,可以使用梯度累积模拟大批次训练:
accumulation_steps = 4for i, (data, target) in enumerate(dataloader):data, target = data.cuda(), target.cuda()# 前向传播with autocast():output = model(data)loss = criterion(output, target) / accumulation_steps# 反向传播scaler.scale(loss).backward()# 每accumulation_steps步更新一次参数if (i + 1) % accumulation_steps == 0:scaler.step(optimizer)scaler.update()optimizer.zero_grad()
8.3 通信优化
- 梯度累积:减少通信频率
- 梯度压缩:使用量化或稀疏化减少通信量
- 重叠计算和通信:使用
DDP(find_unused_parameters=True)和torch.distributed.algorithms.ddp_comm_hooks
# 使用梯度压缩钩子
from torch.distributed.algorithms.ddp_comm_hooks import default_hooks as default_comm_hooksddp_model.register_comm_hook(state=None, hook=default_comm_hooks.fp16_compress_hook
)
8.4 数据加载优化
- 预取数据:使用
pin_memory=True和num_workers > 0 - 缓存数据集:将数据集加载到内存或SSD
- 使用更快的文件格式:如LMDB、HDF5
dataloader = DataLoader(dataset,batch_size=64,num_workers=4,pin_memory=True,persistent_workers=True,prefetch_factor=2
)
9. 性能分析与调试
9.1 性能分析工具
PyTorch提供了多种性能分析工具:
- torch.profiler:详细分析计算和通信开销
- torch.cuda.memory_summary():内存使用分析
- NVIDIA Nsight Systems:系统级性能分析
import torch.profilerwith torch.profiler.profile(activities=[torch.profiler.ProfilerActivity.CPU,torch.profiler.ProfilerActivity.CUDA],schedule=torch.profiler.schedule(wait=1, warmup=1, active=3, repeat=1),on_trace_ready=torch.profiler.tensorboard_trace_handler('./log'),record_shapes=True,profile_memory=True,with_stack=True
) as prof:for step, (data, target) in enumerate(dataloader):# 训练步骤...prof.step() # 记录每个步骤
9.2 常见问题与解决方案
| 问题 | 可能原因 | 解决方案 |
|---|---|---|
| 训练速度慢 | 通信开销大 | 增大批次大小,使用梯度累积 |
| 内存不足 | 模型或批次太大 | 使用模型并行,减小批次大小,启用梯度检查点 |
| 精度下降 | 混合精度训练 | 调整损失缩放,使用动态损失缩放 |
| 进程挂起 | 通信问题 | 检查网络连接,确保端口开放 |
| 负载不均衡 | 数据分片不均 | 使用DistributedSampler确保数据均匀分布 |
10. 实战案例:大规模语言模型训练
10.1 模型架构
我们以一个简化的Transformer模型为例,展示如何使用PyTorch进行分布式训练:
import torch
import torch.nn as nn
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data import DataLoader, DistributedSamplerclass TransformerModel(nn.Module):def __init__(self, vocab_size, d_model, nhead, num_layers):super().__init__()self.embedding = nn.Embedding(vocab_size, d_model)self.pos_encoder = PositionalEncoding(d_model)encoder_layer = nn.TransformerEncoderLayer(d_model, nhead)self.transformer = nn.TransformerEncoder(encoder_layer, num_layers)self.fc = nn.Linear(d_model, vocab_size)def forward(self, x):x = self.embedding(x) * math.sqrt(self.d_model)x = self.pos_encoder(x)x = self.transformer(x)x = self.fc(x)return xclass PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=5000):super().__init__()pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0).transpose(0, 1)self.register_buffer('pe', pe)def forward(self, x):return x + self.pe[:x.size(0), :]
10.2 分布式训练实现
def train(rank, world_size):# 初始化进程组dist.init_process_group(backend='nccl',rank=rank,world_size=world_size)# 创建模型并移至当前设备model = TransformerModel(vocab_size=50000,d_model=512,nhead=8,num_layers=6).to(rank)# 使用DDP包装模型model = DDP(model, device_ids=[rank])# 创建数据加载器dataset = TextDataset(...) # 自定义文本数据集sampler = DistributedSampler(dataset,num_replicas=world_size,rank=rank,shuffle=True)dataloader = DataLoader(dataset,batch_size=32,sampler=sampler,num_workers=4,pin_memory=True)# 定义优化器和损失函数optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)criterion = nn.CrossEntropyLoss(ignore_index=0)# 初始化混合精度训练scaler = GradScaler()# 训练循环for epoch in range(100):sampler.set_epoch(epoch)for batch_idx, (data, target) in enumerate(dataloader):data, target = data.to(rank), target.to(rank)optimizer.zero_grad()# 混合精度训练with autocast():output = model(data)loss = criterion(output.view(-1, output.size(-1)), target.view(-1))# 梯度缩放和反向传播scaler.scale(loss).backward()# 梯度裁剪scaler.unscale_(optimizer)torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)# 更新参数scaler.step(optimizer)scaler.update()if batch_idx % 100 == 0 and rank == 0:print(f'Epoch {epoch}, Step {batch_idx}, Loss: {loss.item()}')# 保存模型(只在主进程)if rank == 0:torch.save(model.state_dict(), 'transformer_model.pt')dist.destroy_process_group()def main():world_size = torch.cuda.device_count()mp.spawn(train, args=(world_size,), nprocs=world_size, join=True)if __name__ == '__main__':main()
10.3 性能优化
- 激活检查点:减少内存使用
from torch.utils.checkpoint import checkpointclass CheckpointedTransformer(nn.Module):def __init__(self, transformer_layer):super().__init__()self.transformer_layer = transformer_layerdef forward(self, x):return checkpoint(self.transformer_layer, x)# 在模型中使用
encoder_layer = nn.TransformerEncoderLayer(d_model, nhead)
checkpointed_layer = CheckpointedTransformer(encoder_layer)
- 梯度累积:模拟大批次训练
accumulation_steps = 4for batch_idx, (data, target) in enumerate(dataloader):with autocast():output = model(data)loss = criterion(output, target) / accumulation_stepsscaler.scale(loss).backward()if (batch_idx + 1) % accumulation_steps == 0:scaler.step(optimizer)scaler.update()optimizer.zero_grad()
- 使用更快的优化器:如AdamW、LAMB
from torch.optim import AdamWoptimizer = AdamW(model.parameters(),lr=1e-4,weight_decay=0.01,betas=(0.9, 0.999),eps=1e-8
)
11. 总结与展望
11.1 关键要点总结
- **数据并行(DDP)**是PyTorch分布式训练的首选方法,具有高效性和良好的扩展性
- 模型并行适用于超大模型训练,但实现复杂且通信开销大
- 混合并行策略(数据+模型+流水线)是大规模训练的最佳实践
- 性能优化技术(混合精度、梯度累积、通信优化)对提升训练效率至关重要
- 工具链(torch.profiler、TensorBoard)帮助分析和调试分布式训练
11.2 未来发展趋势
- 自动化并行:如PyTorch的
torch.distributed.fsdp(完全分片数据并行) - 更高效的通信算法:如3D并行、张量并行
- 云原生分布式训练:与Kubernetes等容器编排系统深度集成
- 异构计算支持:更好地利用CPU、GPU、TPU等不同计算单元
- 联邦学习:分布式训练在隐私保护场景的应用
11.3 最佳实践建议
- 从小规模开始:先在单机多卡上验证,再扩展到多机
- 监控资源使用:定期检查GPU利用率、内存占用和网络带宽
- 版本控制:确保所有节点使用相同的PyTorch和CUDA版本
- 容错设计:实现检查点保存和恢复机制
- 持续优化:根据性能分析结果不断调整并行策略和超参数
PyTorch分布式训练是一个强大而灵活的工具,掌握它将使你能够训练更大、更复杂的模型,推动深度学习应用的边界。随着PyTorch生态系统的不断发展,分布式训练将变得更加易用和高效,为AI研究和应用提供强大支持。