graph attention network
传统 ReLU 的问题
ReLU 的定义是:
f(x) = max(0, x)
即当输入 x > 0 时,输出 x;当 x ≤ 0 时,输出 0。
但它有一个缺陷:当输入长期为负数时,ReLU 会输出 0,导致对应神经元的梯度为 0,权重无法更新,这个神经元会永久「死亡」(不再参与学习),这就是「死亡 ReLU 问题」。
Leaky ReLU 的改进
Leaky ReLU 对 ReLU 在负区间的行为做了调整,定义为:
f(x) = x, if x > 0; f(x) = α·x, if x ≤ 0
其中 α 是一个很小的常数(通常取 0.01),表示输入为负时的斜率。
核心作用:
当输入为负数时,Leaky ReLU 不再输出 0,而是保留一个微小的负值(如 x = -5 时,输出 -0.05,若 α=0.01),这样即使输入为负,神经元仍有微小的梯度流动,避免了「死亡 ReLU 问题」,让网络更容易训练,尤其适合深层网络。
优点
- 缓解「死亡 ReLU 问题」,保持负区间的梯度活性;
- 计算简单,速度快,与 ReLU 相当;
- 通常能带来更好的收敛效果,尤其在训练初期。
变体
Leaky ReLU 的变体 Parametric ReLU(PReLU)进一步将 α 设为可学习的参数(而非固定值),让模型根据数据自动调整负区间的斜率,可能在特定任务上表现更好。
总之,Leaky ReLU 是 ReLU 的实用改进版,通过在负区间保留微小梯度,解决了神经元「死亡」问题,同时保持了高效的计算特性,在卷积神经网络(CNN)、循环神经网络(RNN)等场景中被广泛使用。
Outline
torch-scatter
torch-sparse
import os
import torch
os.environ['TORCH'] = torch.__version__
print(torch.__version__)!pip install -q torch-scatter -f https://data.pyg.org/whl/torch-${TORCH}.html
!pip install -q torch-sparse -f https://data.pyg.org/whl/torch-${TORCH}.html
!pip install -q git+https://github.com/pyg-team/pytorch_geometric.gitimport numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
GATLayer
class GATLayer(nn.Module):"""Simple PyTorch Implementation of the Graph Attention layer."""def __init__(self):super(GATLayer, self).__init__()def forward(self, input, adj):print("")
forward method
Linear Transformation
h′ˉi=W⋅hˉi
\bar{h'}_i = \textbf{W}\cdot \bar{h}_i
h′ˉi=W⋅hˉi
with W∈RF′×F\textbf{W}\in\mathbb R^{F'\times F}W∈RF′×F and hˉi∈RF\bar{h}_i\in\mathbb R^{F}hˉi∈RF.
h′ˉi∈RF′ \bar{h'}_i \in \mathbb{R}^{F'} h′ˉi∈RF′
in_features = 5
out_features = 2
nb_nodes = 3W = nn.Parameter(torch.zeros(size=(in_features, out_features))) #xavier paramiter inizializator
nn.init.xavier_uniform_(W.data, gain=1.414)input = torch.rand(nb_nodes,in_features) # linear transformation
h = torch.mm(input, W)
N = h.size()[0]print(h.shape)
Attention mechanism
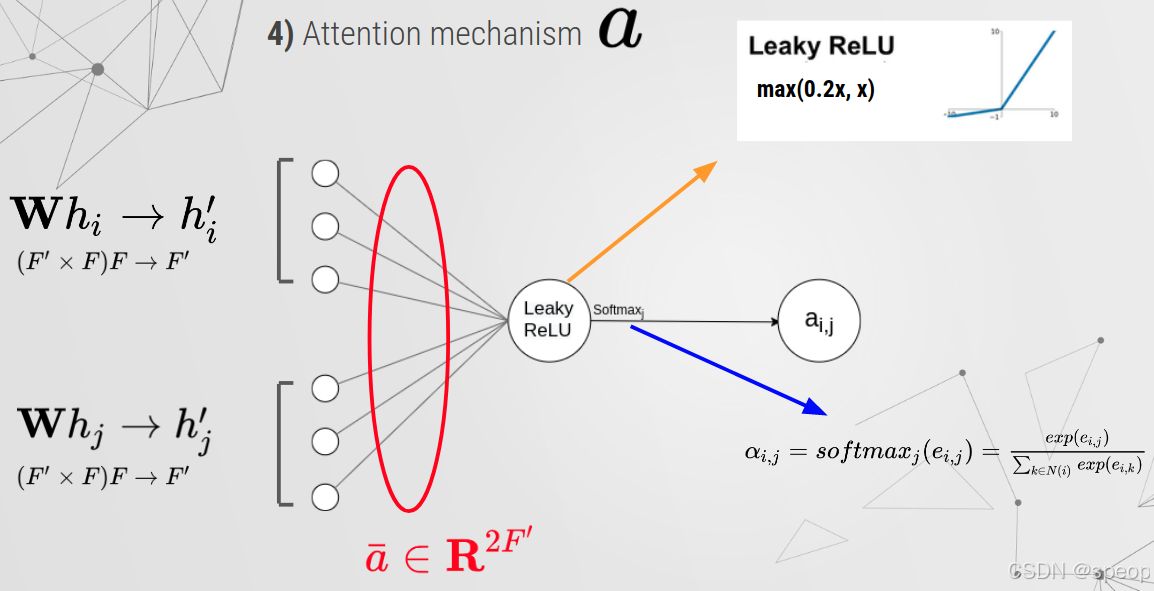
a = nn.Parameter(torch.zeros(size=(2*out_features, 1))) #xavier paramiter inizializator
nn.init.xavier_uniform_(a.data, gain=1.414)
print(a.shape)leakyrelu = nn.LeakyReLU(0.2) # LeakyReLU
a_input = torch.cat([h.repeat(1, N).view(N * N, -1), h.repeat(N, 1)], dim=1).view(N, -1, 2 * out_features)
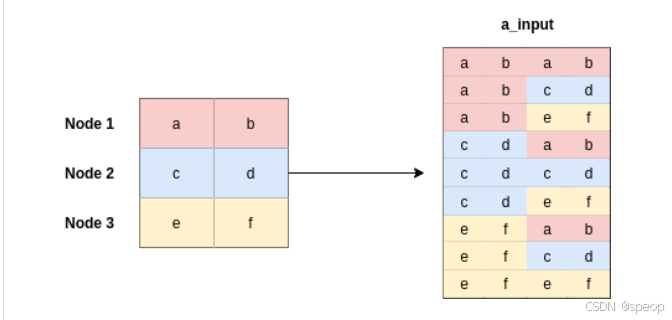
print(a_input.shape,a.shape)
print("")
print(torch.matmul(a_input,a).shape)
print("")
print(torch.matmul(a_input,a).squeeze(2).shape)
Mask Attention
# Masked Attention
adj = torch.randint(2, (3, 3))zero_vec = -9e15*torch.ones_like(e)
print(zero_vec.shape)attention = torch.where(adj > 0, e, zero_vec)
print(adj,"\n",e,"\n",zero_vec)
attention
attention = F.softmax(attention, dim=1)
h_prime = torch.matmul(attention, h)
build the layer
class GATLayer(nn.Module):def __init__(self, in_features, out_features, dropout, alpha, concat=True):super(GATLayer, self).__init__()self.dropout = dropout # drop prob = 0.6self.in_features = in_features # self.out_features = out_features # self.alpha = alpha # LeakyReLU with negative input slope, alpha = 0.2self.concat = concat # conacat = True for all layers except the output layer.# Xavier Initialization of Weights# Alternatively use weights_init to apply weights of choice self.W = nn.Parameter(torch.zeros(size=(in_features, out_features)))nn.init.xavier_uniform_(self.W.data, gain=1.414)self.a = nn.Parameter(torch.zeros(size=(2*out_features, 1)))nn.init.xavier_uniform_(self.a.data, gain=1.414)# LeakyReLUself.leakyrelu = nn.LeakyReLU(self.alpha)def forward(self, input, adj):# Linear Transformationh = torch.mm(input, self.W) # matrix multiplicationN = h.size()[0]print(N)# Attention Mechanisma_input = torch.cat([h.repeat(1, N).view(N * N, -1), h.repeat(N, 1)], dim=1).view(N, -1, 2 * self.out_features)e = self.leakyrelu(torch.matmul(a_input, self.a).squeeze(2))# Masked Attentionzero_vec = -9e15*torch.ones_like(e)attention = torch.where(adj > 0, e, zero_vec)attention = F.softmax(attention, dim=1)attention = F.dropout(attention, self.dropout, training=self.training)h_prime = torch.matmul(attention, h)if self.concat:return F.elu(h_prime)else:return h_prime
use it
from torch_geometric.data import Data
from torch_geometric.nn import GATConv
from torch_geometric.datasets import Planetoid
import torch_geometric.transforms as Timport matplotlib.pyplot as pltname_data = 'Cora'
dataset = Planetoid(root= '/tmp/' + name_data, name = name_data)
dataset.transform = T.NormalizeFeatures()print(f"Number of Classes in {name_data}:", dataset.num_classes)
print(f"Number of Node Features in {name_data}:", dataset.num_node_features)
class GAT(torch.nn.Module):def __init__(self):super(GAT, self).__init__()self.hid = 8self.in_head = 8self.out_head = 1self.conv1 = GATConv(dataset.num_features, self.hid, heads=self.in_head, dropout=0.6)self.conv2 = GATConv(self.hid*self.in_head, dataset.num_classes, concat=False,heads=self.out_head, dropout=0.6)def forward(self, data):x, edge_index = data.x, data.edge_indexx = F.dropout(x, p=0.6, training=self.training)x = self.conv1(x, edge_index)x = F.elu(x)x = F.dropout(x, p=0.6, training=self.training)x = self.conv2(x, edge_index)return F.log_softmax(x, dim=1)device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
device = "cpu"model = GAT().to(device)
data = dataset[0].to(device)optimizer = torch.optim.Adam(model.parameters(), lr=0.005, weight_decay=5e-4)model.train()
for epoch in range(1000):model.train()optimizer.zero_grad()out = model(data)loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])if epoch%200 == 0:print(loss)loss.backward()optimizer.step()本文的损失函数采用的是NLLLoss,对应的原型为torch.nn.functional.nll_loss
源码中的具体是实现是:
import torch.nn.functional as F
...
loss_train = F.nll_loss(output[idx_train], labels[idx_train])
#output[idx_train]是用于训练的样本(节点)所对应的embedding,
#labels[idx_train]是对这些embedding所对应的的真实标签。
output的每一行的的维度和标签类别的数量一致,每一行的第i个数值表示该行embedding被预测为第i类的概率的log对数(因为在GAT类的forward函数中,输出层后接的是log_softmax而不是softmax。log_softmax在数学上等价于log(softmax(x)),但做这两个单独操作速度较慢,数值上也不稳定。log_softmax函数使用另一种公式来计算)。
model.eval()
_, pred = model(data).max(dim=1)
correct = float(pred[data.test_mask].eq(data.y[data.test_mask]).sum().item())
acc = correct / data.test_mask.sum().item()
print('Accuracy: {:.4f}'.format(acc))
这段话的核心是在讲:如何让“注意力机制”真正能在“其他框架”中“学习”到有用的模式,而不是变成一个“固定不变的计算步骤”。
我们可以用一个通俗的例子来理解:
假设你想给一个已有的模型(比如一个分类器)加一个“注意力机制”,让模型学会“关注输入中更重要的部分”。比如看图片时,让模型学会关注“猫的脸”而不是“背景”。
要让这个注意力机制真正“学会”关注什么,需要满足两个关键条件:
-
注意力的“打分规则”必须是“可学习的”
计算“注意力分数”(比如“为什么这部分更重要”)的规则,不能是硬编码的固定公式(比如永远只看左上角),而需要包含“可训练的变量”(比如PyTorch中的Parameter)。这些变量就像注意力机制的“调节旋钮”,初始值是随机的,但可以通过学习调整。 -
注意力分数必须“接入模型的学习目标”
算出的注意力分数不能只是“算完就扔给其他框架用”,而必须参与到整个模型的“目标函数”(比如分类损失)的计算中。
比如:用注意力分数加权后的特征去做分类,最终的分类损失会受注意力分数的影响。
为什么这两点缺一不可?
因为深度学习的“学习”本质是:通过反向传播,用目标函数的“损失”(比如分类错了多少)来调整模型参数(让损失变小)。
- 如果注意力的变量不可训练(没有“调节旋钮”),就算损失告诉我们“注意力错了”,也没法调整,分数永远不变。
- 如果注意力分数不参与目标函数(比如只是把分数数值传给其他框架,但其他框架的损失计算和这个分数无关),那么反向传播时,损失的梯度就传不到注意力的变量上——相当于“损失不知道注意力错了”,变量还是没法调整,分数也永远不变。
简单说:
注意力机制要“活”起来(能学习),必须让它的“参数”能被调整,且调整的依据(梯度)能从最终的目标(损失)传回来。少了任何一步,注意力就会变成“死的”固定规则,学不到用的模式。
import torch
import torch.nn as nn
import torch.optim as optim# ------------------------------
# 1. 定义一个简单的文本分类模型(现有框架)
# ------------------------------
class TextClassifier(nn.Module):def __init__(self, vocab_size, embedding_dim, hidden_dim, num_classes):super().__init__()# 词嵌入层self.embedding = nn.Embedding(vocab_size, embedding_dim)# 分类器(现有框架的核心部分)self.classifier = nn.Sequential(nn.Linear(embedding_dim, hidden_dim),nn.ReLU(),nn.Linear(hidden_dim, num_classes))# 原始前向传播(无注意力)def forward_without_attention(self, x):# x形状: [batch_size, seq_len](输入文本的词索引)embed = self.embedding(x) # [batch_size, seq_len, embedding_dim]# 直接对序列维度求平均作为句子表示avg_embed = embed.mean(dim=1) # [batch_size, embedding_dim]return self.classifier(avg_embed)# ------------------------------
# 2. 给现有模型加入注意力机制
# ------------------------------
class TextClassifierWithAttention(TextClassifier):def __init__(self, vocab_size, embedding_dim, hidden_dim, num_classes):super().__init__(vocab_size, embedding_dim, hidden_dim, num_classes)# 定义注意力的可训练参数(关键:必须用nn.Parameter)# 这些参数会被优化器跟踪,参与梯度更新self.attention_weights = nn.Parameter(torch.randn(embedding_dim, 1) # 用于计算每个词的重要性分数)# 带注意力的前向传播(核心修改)def forward(self, x):embed = self.embedding(x) # [batch_size, seq_len, embedding_dim]# ------------------------------# 计算注意力分数(新加入的逻辑)# ------------------------------# 用可训练参数计算每个词的重要性# 分数形状: [batch_size, seq_len, 1]attention_scores = torch.matmul(embed, self.attention_weights)# 归一化分数(转换为0-1的权重)attention_weights = torch.softmax(attention_scores, dim=1) # [batch_size, seq_len, 1]# ------------------------------# 注意力分数参与到原有框架的计算中(关键)# ------------------------------# 用注意力权重加权词向量(元素相乘)weighted_embed = embed * attention_weights # [batch_size, seq_len, embedding_dim]# 加权求和得到句子表示(替代原来的平均操作)attended_embed = weighted_embed.sum(dim=1) # [batch_size, embedding_dim]# 传入原分类器(和原有框架衔接)return self.classifier(attended_embed)# ------------------------------
# 3. 训练过程(验证注意力参数能否被更新)
# ------------------------------
if __name__ == "__main__":# 模拟数据vocab_size = 1000embedding_dim = 128hidden_dim = 64num_classes = 2batch_size = 8seq_len = 10 # 句子长度# 随机输入和标签x = torch.randint(0, vocab_size, (batch_size, seq_len)) # 文本y = torch.randint(0, num_classes, (batch_size,)) # 标签# 初始化带注意力的模型model = TextClassifierWithAttention(vocab_size, embedding_dim, hidden_dim, num_classes)criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters()) # 优化器会包含注意力参数# 记录初始的注意力参数值initial_attention = model.attention_weights.data.clone()# 一次训练迭代optimizer.zero_grad()outputs = model(x)loss = criterion(outputs, y)loss.backward() # 反向传播:梯度从损失传到注意力参数optimizer.step() # 更新所有参数(包括注意力参数)# 检查注意力参数是否被更新(验证梯度是否生效)updated_attention = model.attention_weights.dataif not torch.allclose(initial_attention, updated_attention):print("注意力参数已成功更新!")else:print("注意力参数未更新(出现问题)")