什么是数据集成?和数据融合有什么区别?
目录
一、数据集成:从分散到集中
1.物理集中
2.格式统一
3.质量保障
二、数据融合:从集中到可用
1.语义对齐
2.多维度关联
3.价值挖掘
三、数据集成和数据融合有什么区别?
四、为什么必须分清这两个概念?
1.只做集成不做融合,数据就成了"死资产"
2.跳过集成直接搞融合,无法落地
总结
在大数据圈子里,"数据集成"和"数据融合"这两个词出现的频率特别高。
但你要是随便抓10个做数据的人问问它们的区别,保准能得到五花八门的答案——
- 有人说集成是融合的第一步,
- 有人觉得融合是集成的高级阶段,
- 还有不少人干脆觉得这俩就是一回事。
你是不是也在做数据仓库、搭数据中台或者搞主数据管理的时候,被这两个词绕晕过?
实际上,这两个词指向的是解决数据分散问题的两个关键环节:
- 数据集成解决“数据从分散到集中”的物理连接,
- 数据融合解决“数据从集中到可用”的逻辑协同。
它们看着像,但很少有人能说清边界。理解它们的差异,才是企业释放数据价值的第一步。
一、数据集成:从分散到集中
要理解数据集成,我先给你讲个真实场景:
一家连锁超市,手里有三套系统:
- 管客户的CRM
- 管供应链的ERP
- 门店的POS销售系统
这三套系统分别存储不同数据:
- CRM里存着客户的手机号、多久来消费一次;
- ERP里记着仓库里有多少货、进货成本多少、供应商是谁;
- POS机里则是每一笔实时的交易记录。
但这三套系统各管各的:
- CRM不知道客户买了啥,
- ERP不清楚哪些货好卖,
- POS机也不了解客户以前喜欢买啥。
这种情况下:
企业最先想到的肯定是把数据"凑到一起"。
这就是数据集成的核心工作:
用技术把存在不同数据库、文件系统、业务系统里的数据,按照统一的格式和规范,弄到同一个平台上。
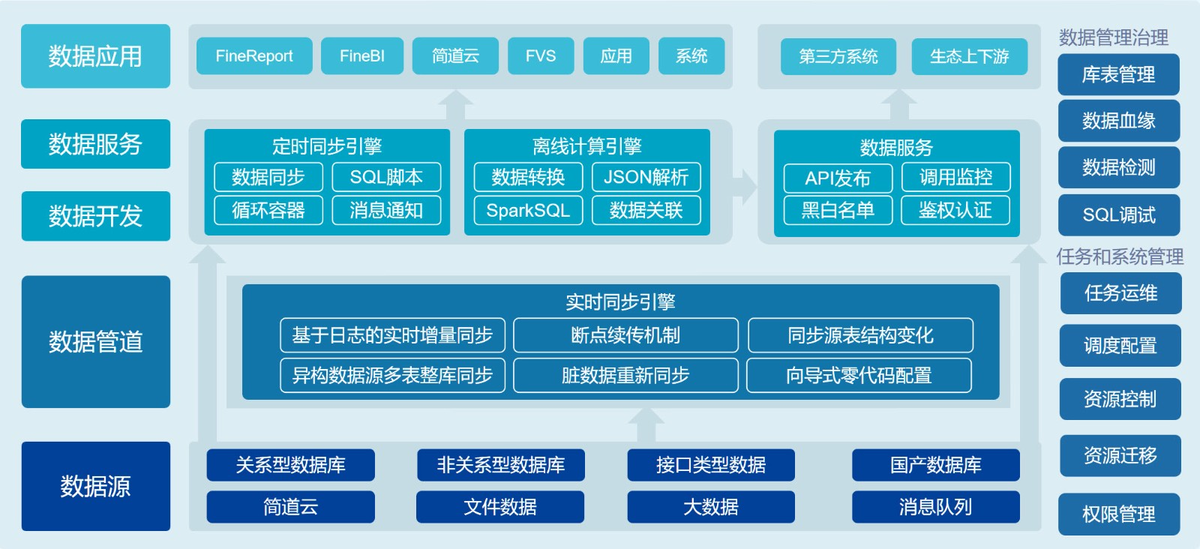
这个平台:
- 可能是数据仓库,
- 也可能是数据湖,
- 或者现在流行的湖仓一体平台。
最终形成一个"能随时调出来用的数据池"。
所以你看:
数据集成的核心目标,就是让数据能在物理层面流动起来,并且做初步的整理。
它主要关注的是技术层面的连接和搬运。
要解决的痛点也很明确:
- 数据存得太散
- 格式不一样
- 想调数据的时候接口不统一
具体来说,数据集成有三个关键动作:
1.物理集中
简单说就是把数据挪地方。
比如:
把MySQL里的订单表、Hive里的用户表、电脑本地Excel里的库存表,
- 要么复制过去,
- 要么实时同步到数据仓库。
2.格式统一
不同地方来的数据格式可能不一样,得调成一致的。比如:
- 把CSV文本文件转成结构化的表格,
- JSON里的"user_name"字段和数据库里的"user_name"字段对齐。
怎么实现?
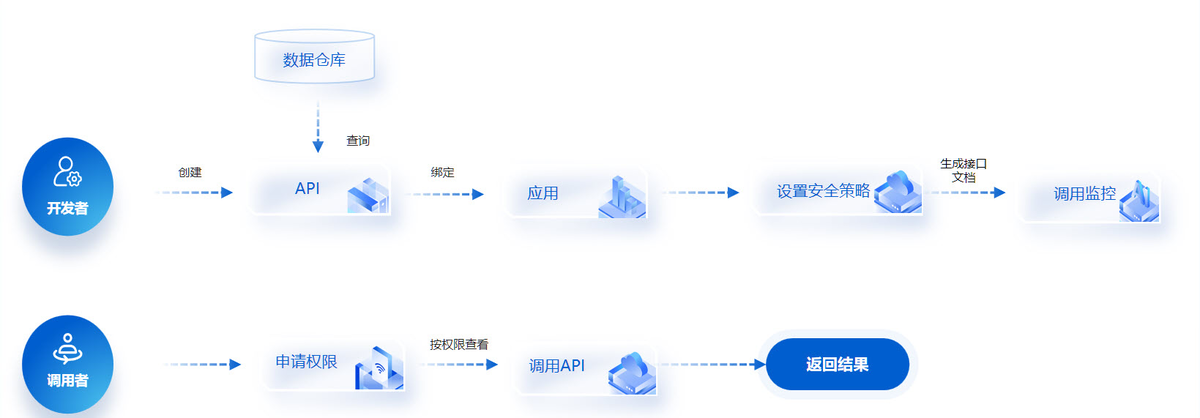
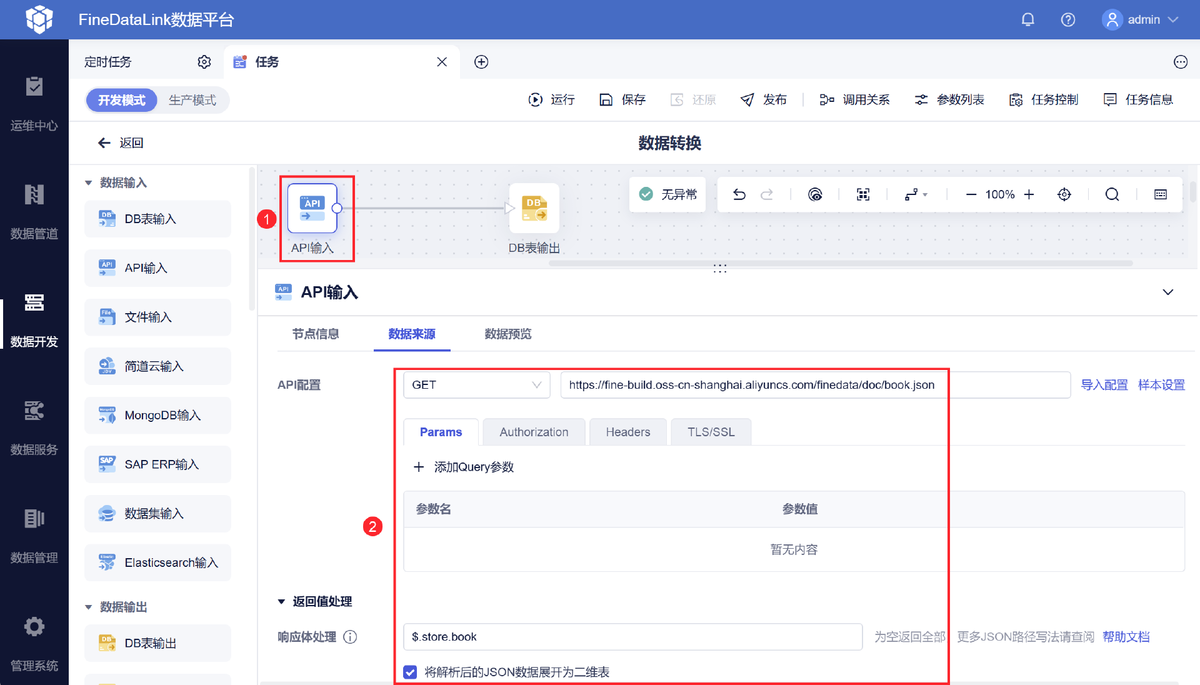
可以借助低代码/高时效的数据集成平台,比如FineDataLink,它提供了高级数据处理功能,例如数据转换、数据过滤、数据重构、数据集合等,可以减少数据连接和输出的繁琐步骤,让整个数据处理流程更加高效和便捷。
FineDataLink体验地址→免费试用FDL(复制到浏览器打开)
这里特别要注意:
解决"同名不同义"或者"同义不同名"的问题。
举个例子:
A系统里的"客单价"是总金额除以订单数,B系统里的"客单价"却是总金额除以客户数,这就必须统一清楚。
3.质量保障
数据挪过来之后,通过FineDataLink做些基础的清洗。比如:
- 去掉重复的数据
- 把空值补上
- 纠正明显错误的值
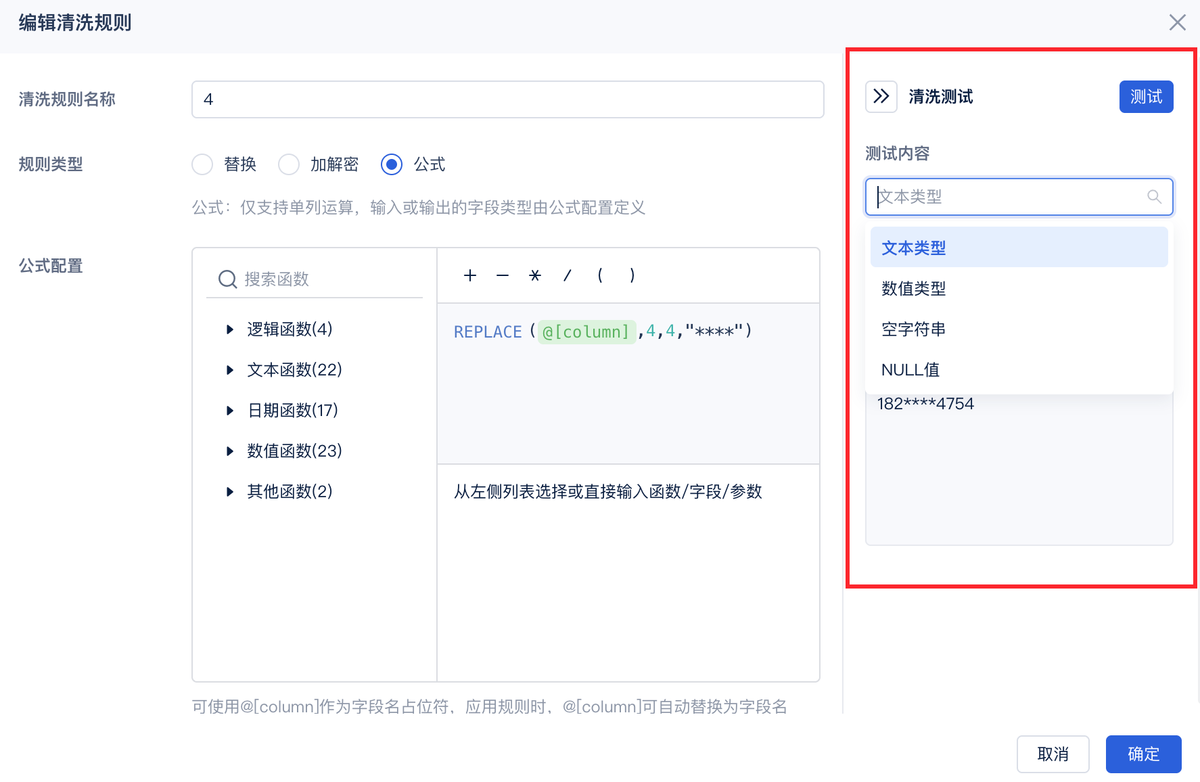
这里我得强调一句,数据集成的本质是"能用就行,不用追求完美"。
很多企业做数据集成的时候容易走弯路,总想着一下子就做到完美,结果卡在数据清洗这一步,拖了好几个月,业务部门等不及,最后项目只能黄。
其实数据集成的核心是"让数据能用起来",只要能支持基础分析,就算初期有点小问题,后面再慢慢优化就行。
二、数据融合:从集中到可用
数据集成做完了,数据是聚到一块儿了,但这并不意味着数据就能直接产生价值。
这时候就需要数据融合了。
数据融合是在数据集成的基础上,通过统一语义、关联分析、搭建模型这些手段,让不同来源的数据能协同发挥作用,产生1加1大于2的效果。
所以数据融合的目标,是消除数据之间的语义矛盾,形成统一、准确、完整的业务视角。
它是在数据集成实现"物理集中"之后,去解决更复杂的逻辑问题:
- 数据在业务含义上的不一致
- 相互冲突
- 碎片化
说白了,它关注的是数据在语义层面能不能统一,能不能产生业务价值。
数据融合也有三个关键动作:
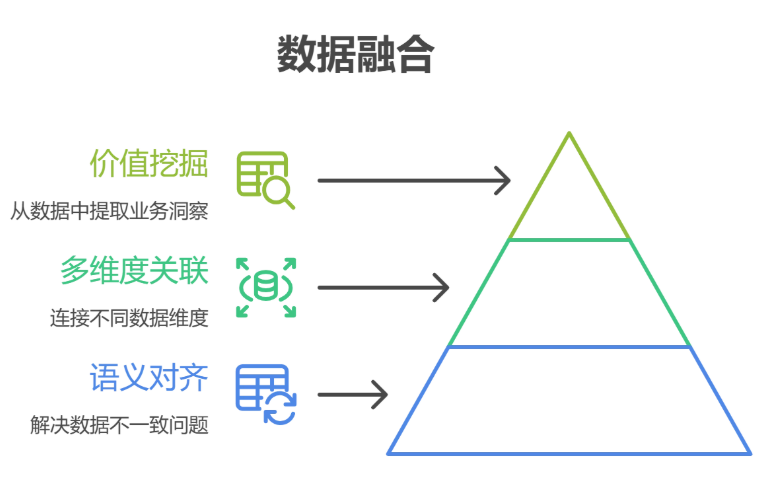
1.语义对齐
就是解决"说的不是一回事"的问题。比如:
- 市场部的CRM里把"高价值客户"定义为"一年花够1万块",
- 但会员系统里的"高价值客户"是"一年来买5次以上"。
这时候数据融合就要做的,就是:
根据业务规则,或者用聚类分析这种机器学习模型,把这些指标的标准统一起来,让不同系统的数据能"对上话"。
2.多维度关联
把不同维度的数据串成一条线。比如把:
- 用户在APP上的点击记录
- 加到购物车但没买的商品
- 实际支付的订单
- 后来的售后评价
这些数据关联起来,就能分析出"用户为啥加了购物车又没买,是不是因为物流太慢"。
3.价值挖掘
从数据里找出能指导业务的信息,帮着做决策。比如把:
- 仓库的库存
- 供应商送货需要的时间
- 市场需求
这些数据合起来,优化一下"安全库存到底设多少合适"。
这里我得强调一句,数据融合的本质是"先考虑业务问题,再选技术手段"。
用机器学习模型融合100个数据源,听起来很厉害,但如果业务部门其实就想知道"下个月哪些商品可能会缺货",那搞那么复杂的技术,反而会拖慢进度。
三、数据集成和数据融合有什么区别?
把上面说的总结一下,这两者的核心区别其实很清楚:

更重要的是,判断两者是否成功的标准也完全不一样:
- 数据集成做得好,业务部门会说"我能找到我要的数据了";
- 而数据融合做得好,业务部门会说"用这些数据,我能做出以前做不了的决策了"。
四、为什么必须分清这两个概念?
实际工作中,很多企业把这俩混为一谈,结果踩了不少坑,我给你说说最常见的两种:
1.只做集成不做融合,数据就成了"死资产"
之前一家找我咨询的零售企业,花300万搭了个数据仓库,把20多个系统的数据都导进去了,但业务部门平时就用它查"今天卖了多少钱"。
问他们为啥不做深入分析,回答:
- 要么是"不知道咋用",
- 要么是"报表里的字段太多,看着头大"。
这就是典型的"集成完了就完事了"——数据是放到仓库里了,但没人会用,跟一堆死资产没啥区别。
2.跳过集成直接搞融合,无法落地
还有些企业太着急,想直接用AI模型把数据融合起来,结果发现:
- 不同系统的数据格式乱七八糟,
- 指标定义也对不上,
- 模型跑出来的结果根本没法用。
这就跟没打地基就想盖楼一样,没有数据集成打下的物理基础,数据融合根本没法落地。
总结
回到最初的问题:数据集成和数据融合的区别是什么?
- 数据集成是把散落的数据“搬”到一起,解决“数据在哪儿”的物理集中问题;
- 数据融合是让聚在一起的数据“说上话”,解决“数据能干嘛”的逻辑协同问题。
一个是基础建设,一个是价值升级,二者缺一不可。
对企业来说:
- 如果只做集成不做融合,数据不过是存放在仓库里的“死资产”;
- 如果跳过集成直接融合,再先进的技术也无法落地。
只有先通过集成实现数据的物理集中与基础可用,再通过融合完成语义对齐与价值挖掘,数据才能真正从“成本中心”转化为“生产力”。