疏老师-python训练营-Day30模块和库的导入
@浙大疏锦行
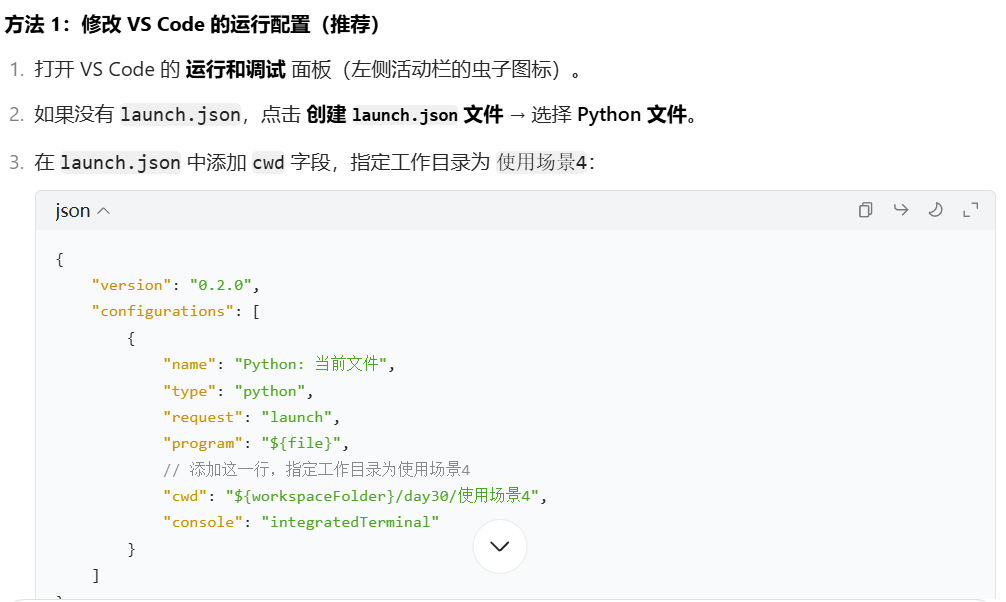
知识点回顾:
- 导入官方库的三种手段
- 导入自定义库/模块的方式
- 导入库/模块的核心逻辑:找到根目录(python解释器的目录和终端的目录不一致)
作业:自己新建几个不同路径文件尝试下如何导入
一.学习知识点
DAY30
注意今天的文件有2个 day30.ipynb 和 day30.py
一、导入官方库
我们复盘下学习python的逻辑,所谓学习python就是学习python常见的基础语法+学习你所处理任务需要用到的第三方库
| 类别 | 典型库 | 解决的问题 | 学习门槛 |
|---|---|---|---|
| 基础工具 | os、sys、json | 操作系统交互、序列化数据(如读写 JSON 文件) | 低 |
| 科学计算 | numpy、scipy | 数值计算、线性代数、信号处理 | 中 |
| 数据分析 | pandas、matplotlib | 数据清洗、转换、可视化(如绘制折线图、柱状图) | 中 |
| Web 开发 | Django、Flask | 快速搭建 Web 应用(如网站后台、API 接口) | 中高 |
| 机器学习 | scikit-learn、TensorFlow | 机器学习算法(分类、回归、深度学习) | 高 |
| 自动化脚本 | pyautogui、pytest | 自动化测试、桌面操作自动化(如模拟鼠标键盘操作) | 低 |
| 网络爬虫 | requests、Scrapy | 从网页提取数据(需注意反爬机制和法律合规) | 中 |
所以你用到什么学什么库即可。学习python本身就是个伪命题,就像你说学习科目一样,你没说清晰你学习的具体科目是什么,也没说学这个科目的哪些章节,毕竟每个科目都很大-----要有以终为始的思想。
所以我们这个训练营,正确的说法是:学习借助pythob掌握深度学习和机器学习所必备的基础知识和相关工具。
1.1 标准导入:导入整个库
这是最基本也是最常见的导入方式,直接使用import语句。
# 方式1:导入整个模块
import mathprint("方式1:使用 import math")
print(f"圆周率π的值:{math.pi}")
print(f"2的平方根:{math.sqrt(2)}\n")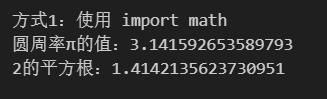
1.2 从库中导入特定项
当使用from语法从库中导入特定的函数或类时,这些函数或类就可以在您的代码中直接使用,不需要添加模块名作为前缀。因为在导入时没有包括模块的完整路径,前面也不能加上库名。
# 方式2:导入特定的函数或变量
from math import pi, sqrtprint("方式2:使用 from math import pi, sqrt")
print(f"圆周率π的值:{pi}")
print(f"2的平方根:{sqrt(2)}\n")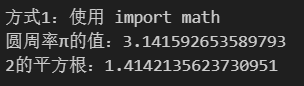
类似的写法,如sklearn库很大,直接导入sklearn库会占用电脑大量内存,所以一般只导入你需要的库,
- 如: from sklearn.model_selection import train_test_split
1.3 非标准导入:导入整个库
如下,●这将导入math模块中定义的所有公开函数和变量。 ●和上述from同理,直接调用sin()、cos()等,而无需math.前缀。
虽然 import math和 from math import *看起来都是导入了 math 模块,但它们在导入方式、作用域处理以及对命名空间的影响上有重要的区别。
-
命名空间的污染
import math:这种方法会将整个math模块导入到命名空间中,但是需要使用math.前缀来访问模块内的函数或变量。这种方式保持了命名空间的整洁,因为所有的math函数和变量都包含在math这个模块对象中。from math import *:这种方法将math模块中的所有公开的函数和变量导入到当前的命名空间中,可以直接使用这些函数和变量而无需math.前缀。这种方式可能会导致命名空间污染,特别是当有多个模块都被这样导入时,很容易发生命名冲突。 -
明确性和可维护性
import math:明确指出了函数和变量来源于math模块,这对代码的可读性和维护性都是有益的。其他阅读你代码的人可以清楚地看到每个函数的来源,这对大型项目和团队合作尤为重要。from math import *:虽然代码看起来更简洁,但这种方法减少了代码的明确性。如果没有足够的上下文,很难判断一个特定的函数是来自math模块还是其他模块,尤其是当你导入了多个模块时。
from math import *print(f"圆周率π的值:{pi}")
print(f"2的平方根:{sqrt(2)}")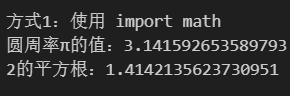
上述这些,如果是python内置库,可以直接导入,大部分第三方库都需要先用pip来安装。下面的模块,也就是.py文件,是不需要安装即可调用的。
模块、包的定义
模块(Module)
- 本质:以
.py结尾的单个文件,包含Python代码(函数、类、变量等)。 - 作用:将代码拆分到不同文件中,避免代码冗余,方便复用和维护。
包(Package)
在python里,包就是库
- 本质:有层次的文件目录结构(即文件夹),用于组织多个模块和子包。
- 核心特征:包的根目录下必须包含一个
__init__.py文件(可以为空),用于标识该目录是一个包。
使用案例
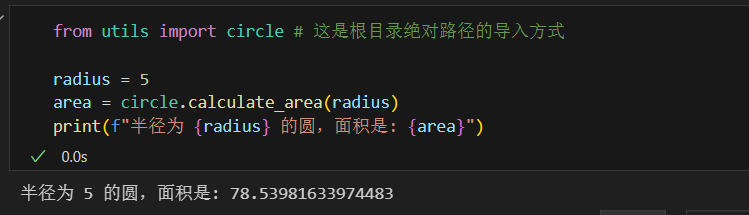
若编写一个计算圆面积的代码并保存为 circle.py,这个文件就是一个模块。
使用时通过 import circle 导入模块,调用其中的函数(如 circle.calculate_area(5))。
# circle.py
import mathdef calculate_area(radius):return math.pi * radius ** 2IDE(如 VSCode 或 PyCharm)通常会将你打开的项目文件夹设为“根目录”(或者说,运行时的工作目录)。Python 在导入模块时,会从这个根目录(以及其他一些标准位置和脚本所在的目录)开始查找。
场景1: main.py 和 circle.py 都在同一目录
目录结构:
项目根目录/
├── main.py
└── circle.py
main.py 内容:
# main.py
from circle import calculate_area
# 或者: import circle (然后用 circle.calculate_area)radius = 5
area = calculate_area(radius)
print(f"半径为 {radius} 的圆,面积是: {area}")运行方案:直接在终端python main.py
这里的终端可以通过左上角的查看-终端 打卡,默认的路径是你的项目根目录。
我觉得这是我今天最难的地方,如果是点开三角 运行,没有问题,会出现
运行,没有问题,会出现 没有问题对吧。但是,当我执行
没有问题对吧。但是,当我执行 ,发现没反应
,发现没反应![]() 。然后我看都我的终端有
。然后我看都我的终端有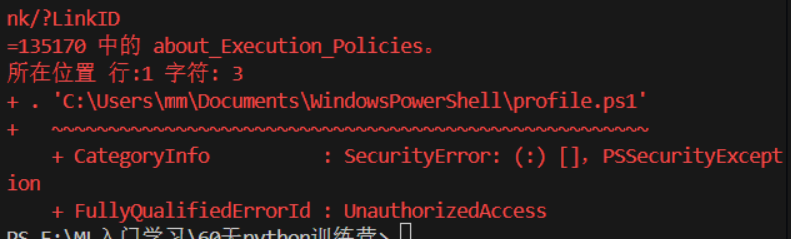 这种红色字,然后我就去问豆包,在问了14次,中间不断的用它的方案改了之后,终于第14次好了。看下图。注,nog是我anaconda中的环境。
这种红色字,然后我就去问豆包,在问了14次,中间不断的用它的方案改了之后,终于第14次好了。看下图。注,nog是我anaconda中的环境。
接下来,我把豆包最后一次(最有帮助)给我的方案分享给大家,并且,我也会实操一遍。其实我一开始进老师的复试班时就有了红字这个问题,但是当时的任务不影响,就偷懒没弄,今天既然要做这个,就要解决掉这个问题。伟大的ai,伟大的豆包,真了不起。如果大家有其他问题,比如上面目录只是到60天训练营,而不是场景一的根目录,问豆包,它会告诉你用cd命令,如下。
![]()
现在我给大家看一下,执行老师的操作(在终端输入python main.py),这个hello是我加的。

豆包方案:
从报错来看,这是 PowerShell 执行策略限制 导致 conda init 配置的脚本无法运行,进而 conda activate 失败。以下是 最简解决步骤:
1. 以管理员身份打开 PowerShell
- 关闭 VS Code 终端,从 开始菜单 找到 Windows PowerShell → 右键选择 以管理员身份运行。
2. 修改执行策略(仅需一次)
在管理员 PowerShell 中运行:
powershell
Set-ExecutionPolicy RemoteSigned -Force
- 作用:允许运行本地脚本(
conda init写入的profile.ps1属于本地脚本)。
3. 重启 VS Code 并激活环境
- 关闭所有 VS Code 窗口,重新打开项目;
- 打开 VS Code 终端(自动是 PowerShell 类型),执行:
powershell(这个nog是我的环境名,你弄你自己的)
conda activate nog
核心原因
Windows PowerShell 默认执行策略是 Restricted(限制运行脚本),导致 conda init 写入的 profile.ps1 无法加载。通过管理员权限修改执行策略为 RemoteSigned 即可解决。
我按照豆包老师的三步走:
1. 以管理员身份打开 PowerShell
要先关闭vscode
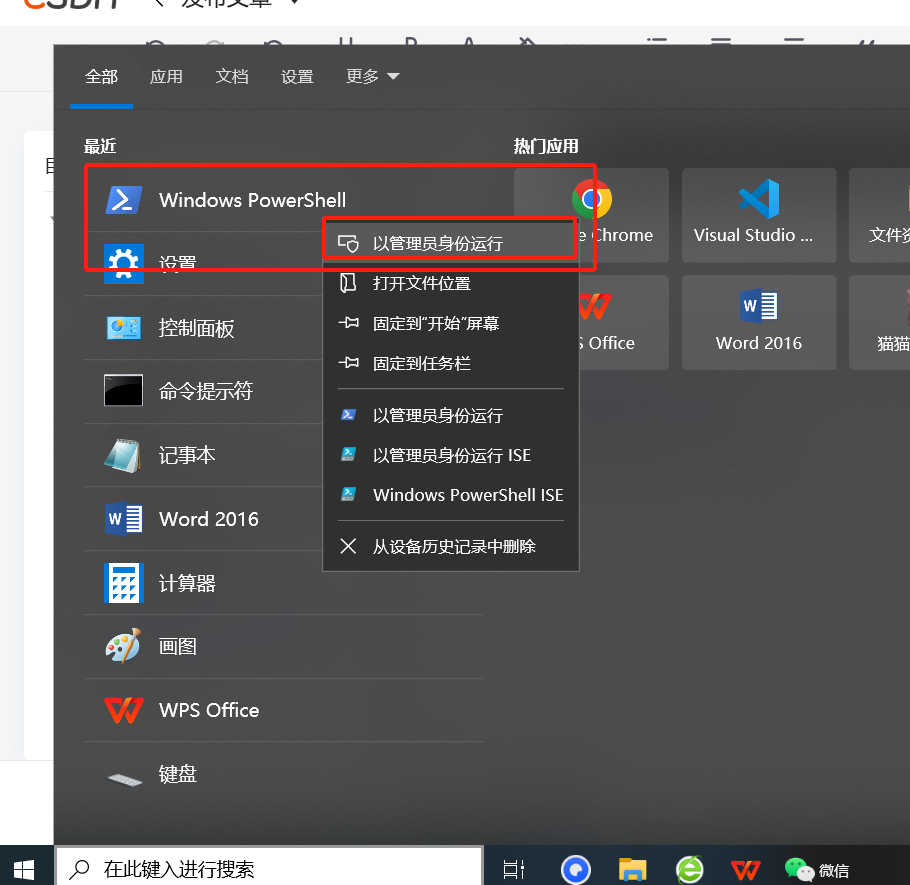
2.修改执行策略(仅需一次)
这行代码复制到图片内容中,回车。
Set-ExecutionPolicy RemoteSigned -Force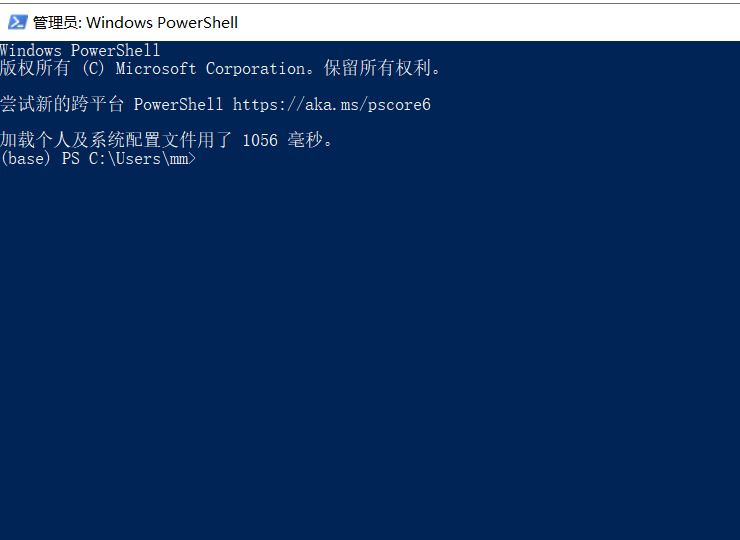
3.重启 VS Code 并激活环境
前两步你已经关闭了vscode,你完成前两部后打开vscode,输入以下代码。我的环境叫nog,你弄你自己的环境名。
conda activate nog假如出现![]() ,你就先conda init再activate。(当然我前两部做完后,没出现这个问题)
,你就先conda init再activate。(当然我前两部做完后,没出现这个问题)
场景2: main.py 和 circle.py 都在根目录的子目录 model/ 下
目录结构:
项目根目录/
└── model/├── __init__.py (推荐添加,将 model 目录标记为包)├── main.py└── circle.py
model/main.py 内容:
# model/main.py
from circle import calculate_area
# 或者: import circle (然后用 circle.calculate_area)radius = 5
area = calculate_area(radius)
print(f"半径为 {radius} 的圆,面积是: {area}")运行方案:
- 运行命令:python model/main.py
- 进入路径:cd xxx(main的相对路径),然后执行python main.py (注意如果先cd后,就不能采用第一个命令了)
首先,我们前面进入的是场景1,现在先要回退到60天训练营,回退命令如下,回退示例如图
cd ..
退出到60天训练营,再cd到使用场景2,再执行python model/main.py。

老师说的直接运行命令:python model/main.py,我这里不行,我觉得可能是老师和我的路径不一样,我的路径很复杂,好多层文件夹。
我按照老师的直接在60天训练营输入python model/main.py会报错,因为不是根目录,当然找不到文件啊。所以一定要到场景2去输入python model/main.py。


场景3: main.py 在根目录,circle.py 在子目录 model/ 下
目录结构:
项目根目录/
├── main.py
└── model/├── __init__.py (必需添加,将 model 目录标记为一个可导入的包)└── circle.py
main.py 内容:
# main.py
from model.circle import calculate_area
# 或者: from model import circle (然后用 circle.calculate_area,因为此时你是导入了整个模块)radius = 5
area = calculate_area(radius)
print(f"半径为 {radius} 的圆,面积是: {area}")运行方案:直接在终端python main.py

如果你是和我一样,边修改文件(比如场景1先往里面放py文件,场景234空的,做场景2再添场景2里面的py文件,不一下弄完的原因是github上我没看到有下载文件夹的导致我只能一个一个下,我又比较急,就边做边弄)那你可能会出现如下图的问题,只要ctrl+s保存一下就行。很好解决。
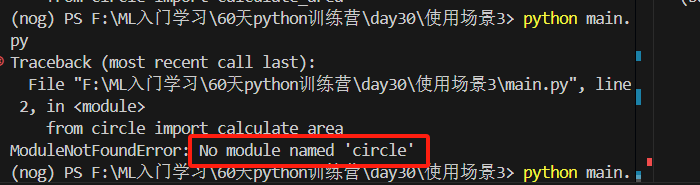
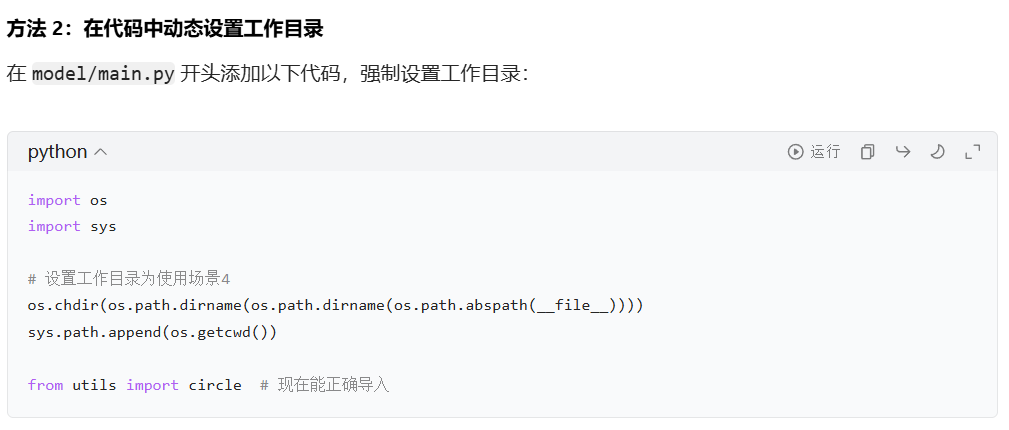
场景4:是最复杂的是包里的函数掉另一个包里的函数
项目根目录/
├── circle2.py
└── utils/├── __init__.py (必需添加,将 model 目录标记为一个可导入的包)└── circle.py
└── model/└── main.py运行方式 python -m model.main
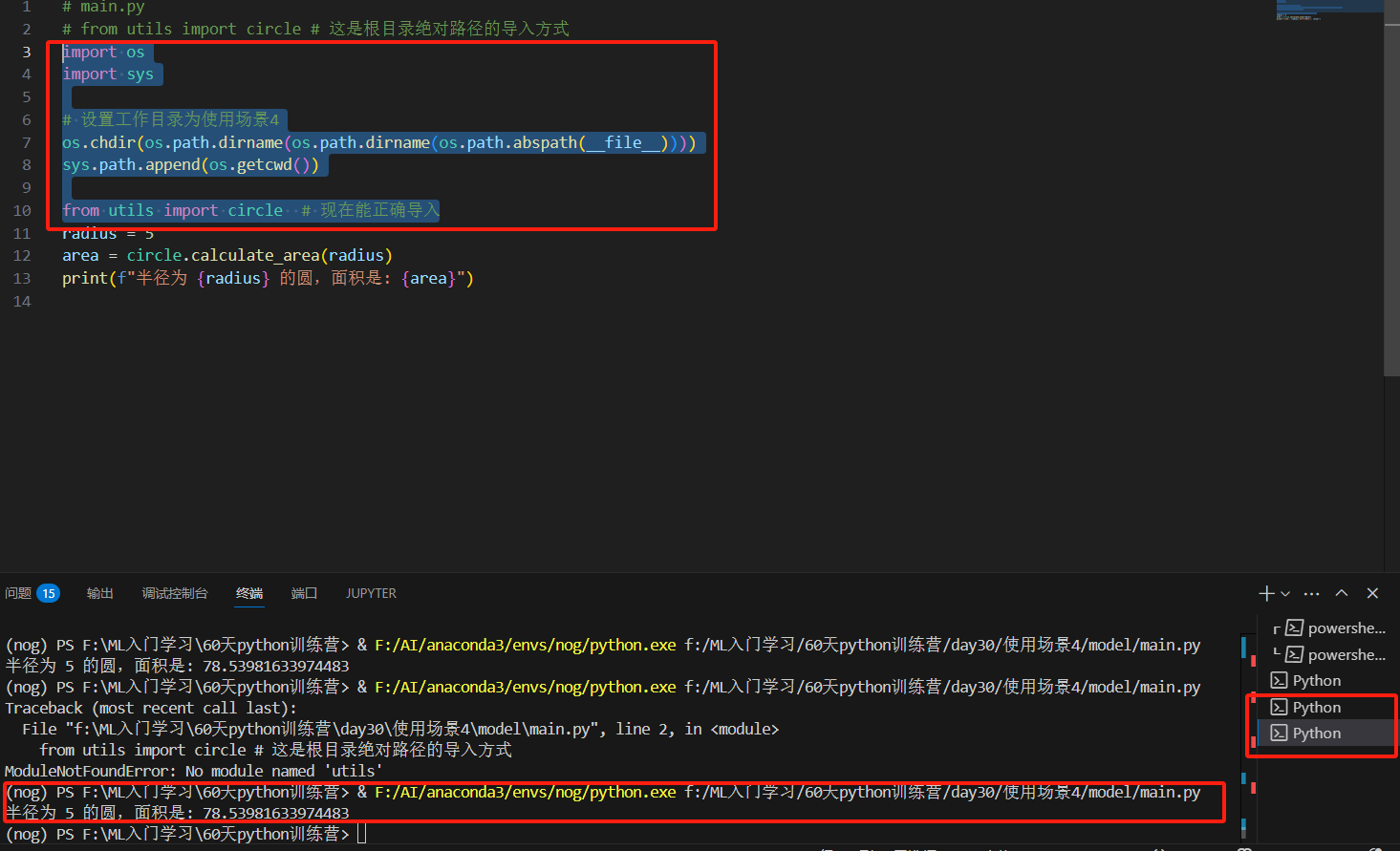
如果直接使用python model/main.py,会报错, 当使用 python -m model.main 时,Python 会将当前目录(即项目根目录)添加到 sys.path 的开头。
python model/main.py,会报错,报错如下:
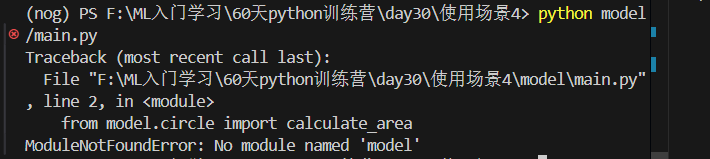
那我们去输入python -m model.main,得到结果是下图。

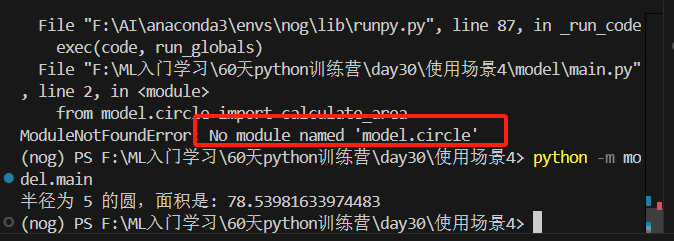
看起来好容易啊,其实一点也不,你在场景4可能经常报错,如下图。有两个解决方案1.删除 __pycache__ ,这就是个缓存文件。无论你是场景1234只要你某次出错,就删掉(4出错,我把1234的缓存全删了再保存就不报错了)。2.删完后要保存ctrl+s这一点超级重要。3.你也可以关掉重启试试。
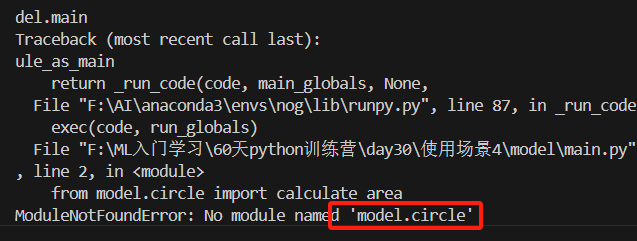
之前错了好几次了,一直都是报红框里的错误,其实我代码明明长下图这样。没有model.circle明明是utils里的circle。最后就是靠删除场景1234的缓存和保存,再执行python -m model.main才弄好。
![]()
然后我还要说一下,为什么要加M,问了豆包,理由不用看。什么时候加M知道就行。


结束了吗,哈哈还没有,场景4里还有一个文件![]() 再学习一下。这个内容是教我们如何当主函数是ipynb格式时如何调用py格式的包。因为前1234都是py导py。
再学习一下。这个内容是教我们如何当主函数是ipynb格式时如何调用py格式的包。因为前1234都是py导py。
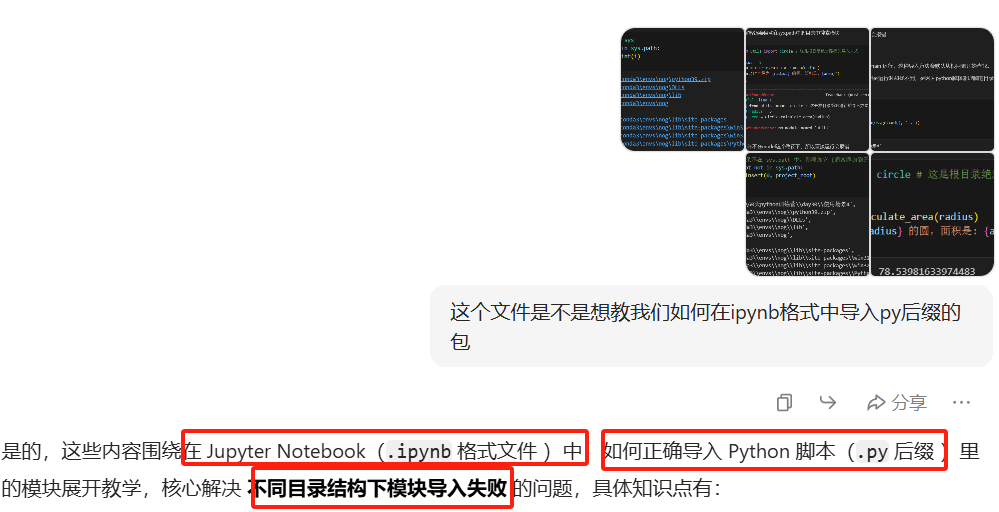
学习ipynb格式导py格式包,这个ipynb实在场景4的model包中的
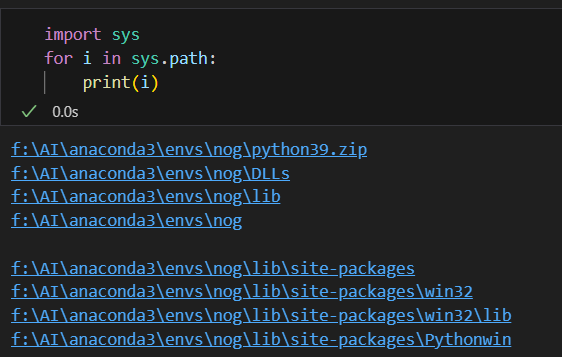
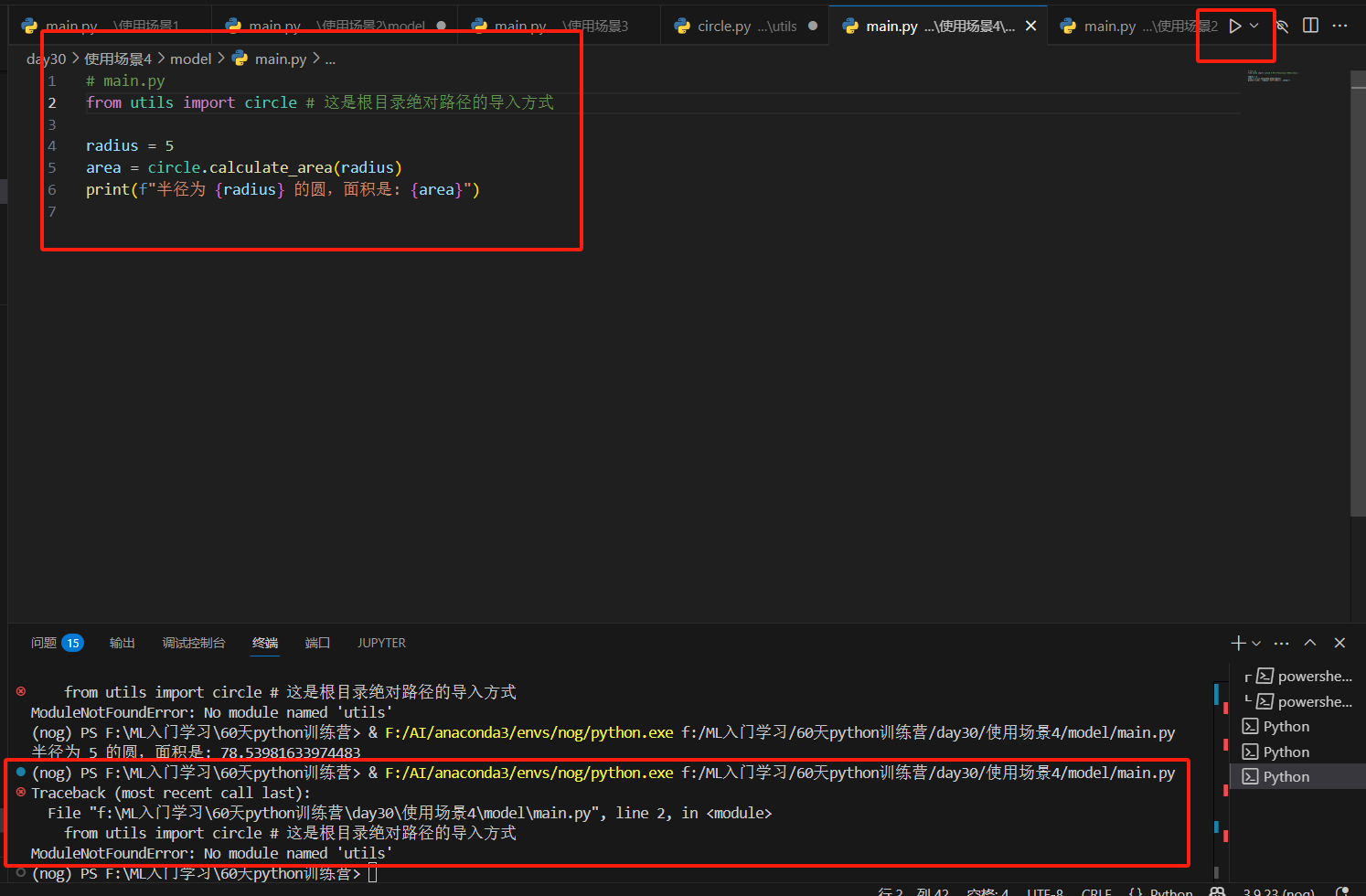
发现sys.path里没有60天训练营和场景4是吧。
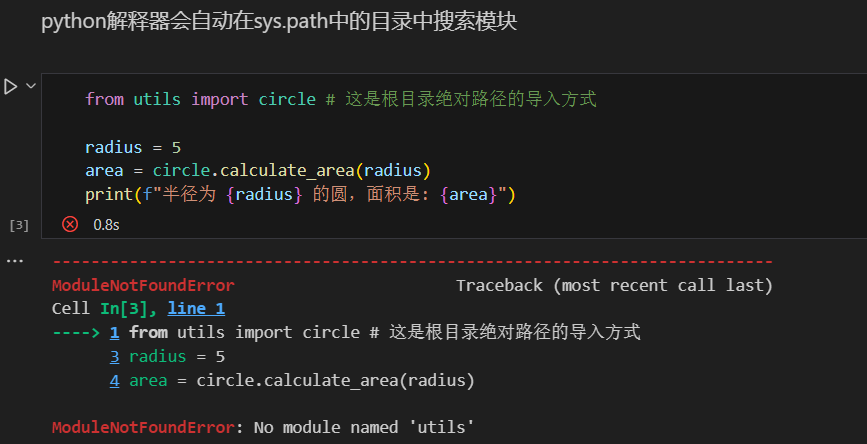
因为utils并不在model这个路径下,所以直接运行会报错
有2类策略:
- 把utils路径加入到sys.path中
- 在py文件的终端中直接用python -m model.main 运行,这种导入方法会默认从根目录开始查找。
ps:之所以你会感觉终端的命令明明是根目录,但是运行时却找不到,是因为python解释器理解的目录和终端的目录不一样,通过sys.path可以查看解释器理解的目录
第2个方法前面在场景4做过了输入python -m model.main就会从根目录(红框内)找

第一个方法看一下
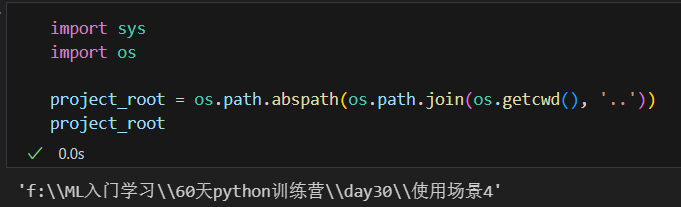
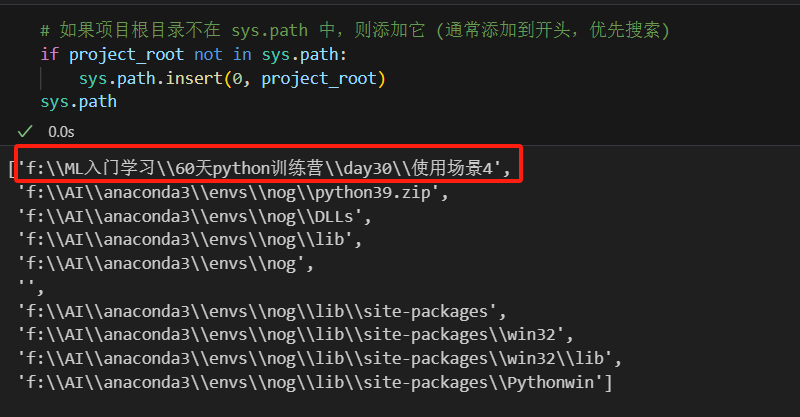
红框说明添加导sys.path了
所以导入包的核心就是找到目录,只有理解了python解释器的目录关系,才能导入包,如果py文件中导入失败,不妨多调试几次路径即可-----一点心得,经常跑别人的项目都是在这里有问题。
如果你在手欠一点,点一下场景4main.py文件的一个三角形(直接运行,非终端运行),会报错
终端运行没事
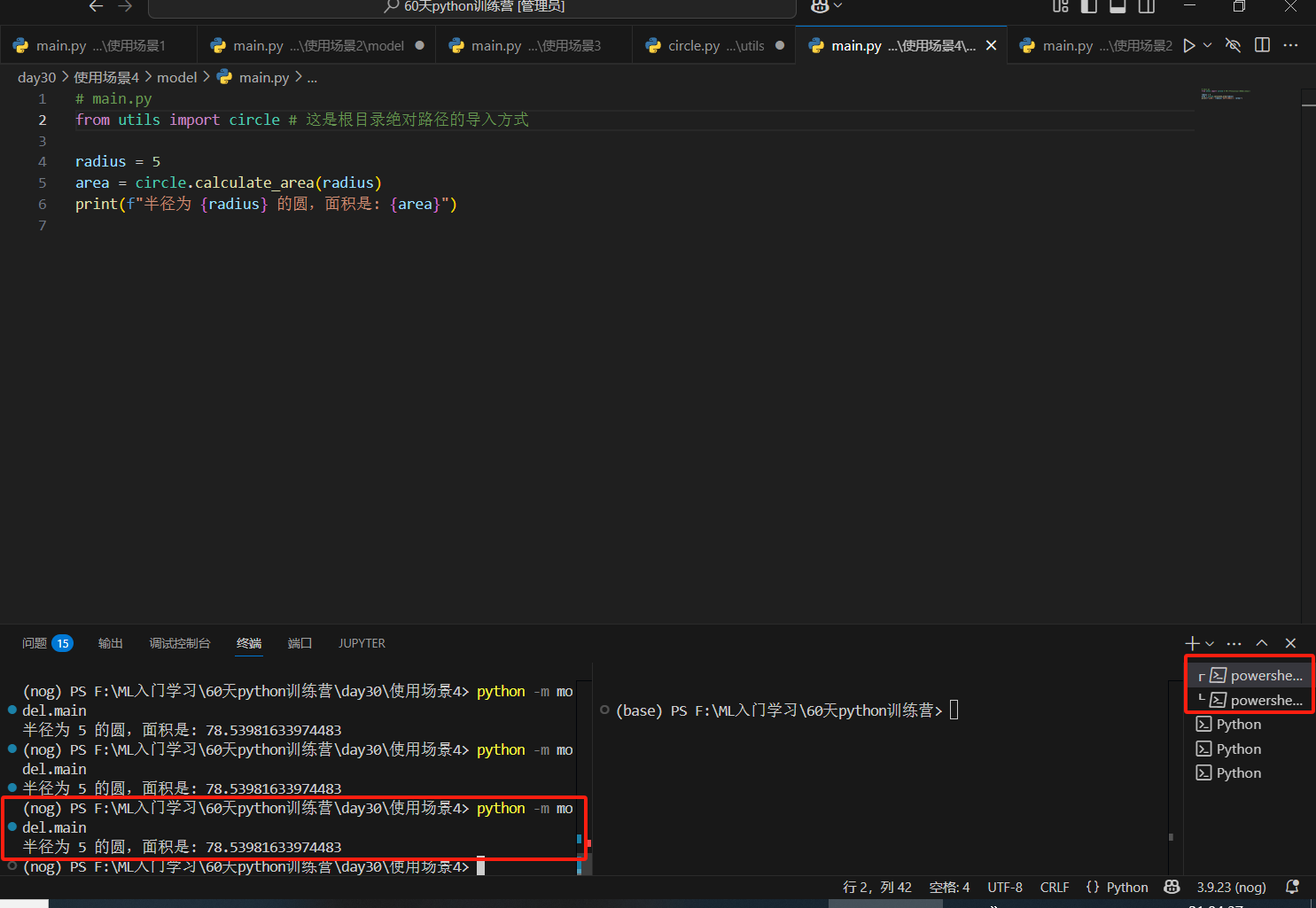
为什么看豆包,有3个方案。方案1太麻烦不做了

方案1
方案2及演示,特像ipynb导入py的操作
方案3

三、源代码的查看
如果第三方库是纯python写的,往往在函数上按住ctrl即可进入函数内部查看源代码。 但是很多第三方库为了性能,底层是用其他语言写的,这里我们计算机视觉库OpenCV为例。 OpenCV核心是用C++编写的(C++可以显著提高性能),但它通过Python等其他语言的接口(bindings)使得这些功能可以在Python环境中被调用。这些接口是通过一种叫做Python/C API的技术实现的,其中C++的功能被封装成Python模块,使得Python用户可以像使用纯Python编写的库一样使用OpenCV。 OpenCV的核心是用C++编写,并且已经编译成二进制文件,编译后的二进制文件可以在不同操作系统上运行,Python中的用户通常不能直接看到方法的源代码。
二进制文件是机器语言,处理器可以直接理解和执行无需翻译,二进制语言反汇编是很困难的,用二进制语言除了效果好外,也是让用户无法看到源代码,保护了自己的知识产权。
这意味着: ●二进制文件dll文件:当你在Python中导入OpenCV库(通import cv2),你实际上是在调用预先编译好的二进制文件。这些文件包含了实现OpenCV功能的可执行代码,而非人类可读的源代码。 ●接口封装:用户只能看到Python函数和对象的接口(即函数的定义,不包括实现的细节)。这也意味着无法从利用ctrl跳转到函数内部,pycharm的debugger功能同理也无法看到内部结构。 ●文档和源代码:尽管在Python中不能直接看到C++的源代码实现,用户可以参考官方文档来了解各个函数和方法的用法。如果需要查看实现细节,可以访问OpenCV的GitHub仓库查看C++源代码。
这就需要我们养成看文档的能力,文档就是以终为始思想的体现。文档就是api使用说明书,可能你日常买东西都不喜欢看使用说明书,但是在代码学习中,这一步是绕不开的。 你会发现很多B站视频的教学,其实远不如文档说明书细致。