复现CLIP(对比语言图像预训练)
地址:
github
简介
CLIP(对比语言-图像预训练)是一个基于多种(图像,文本)对进行训练的神经网络。它可以通过自然语言指令,根据给定图像预测最相关的文本片段,而无需直接针对任务进行优化,类似于 GPT-2 和 GPT-3 的零样本能力。我们发现,CLIP 在 ImageNet 数据集上的表现与原始 ResNet50 的“零样本”结果相当,且无需使用任何原始的 128 万个带标签样本,从而克服了计算机视觉领域的几大挑战。
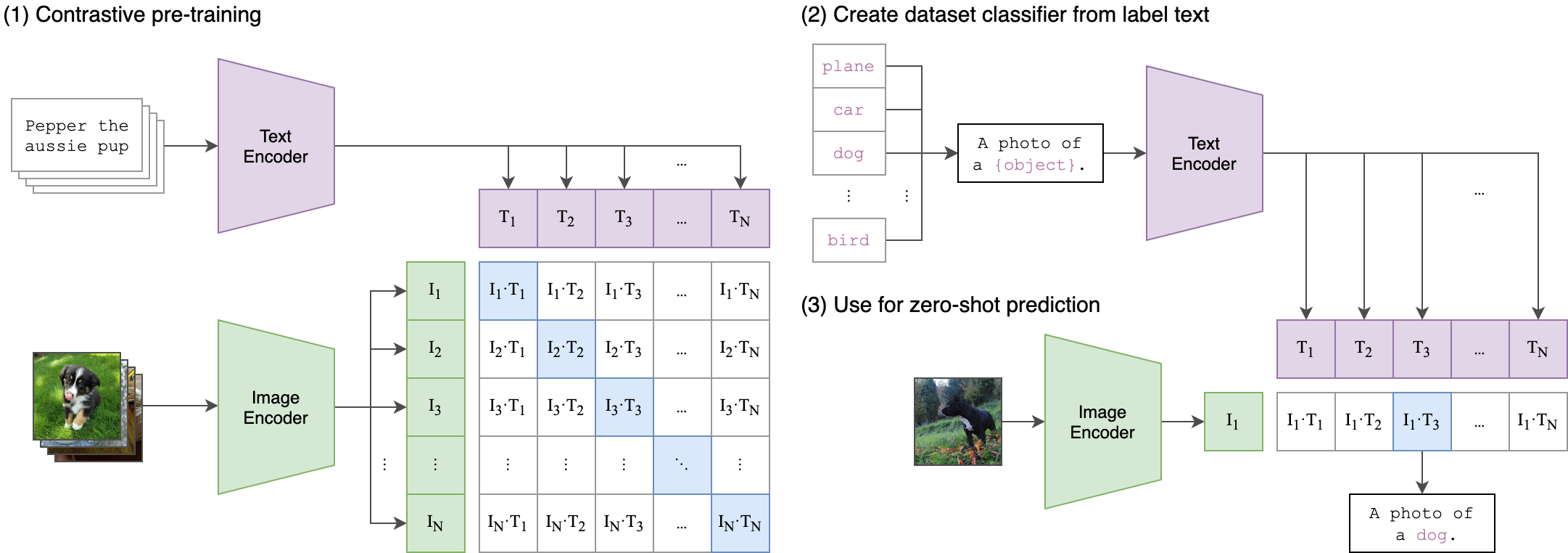
这张图展示了 基于对比预训练的零样本图像分类流程,核心是利用文本 - 图像的对齐表示,实现无需训练数据的分类(零样本学习)。可分为 3 个阶段 解析:
阶段 1:对比预训练(Contrastive pre-training)
目标:让文本编码器和图像编码器学习到文本 - 图像的对齐特征(同一内容的文本和图像在特征空间中更相似)。
输入:
- 文本侧:关于同一主题的文本(如 “Pepper the aussie pup” 的多篇描述)。
- 图像侧:同一主题的多张图像(如小狗 Pepper 的照片)。
过程:
- 文本编码器将文本编码为文本特征(T1,T2,...,TN)。
- 图像编码器将图像编码为图像特征(I1,I2,...,IN)。
- 计算文本 - 图像的相似度矩阵:矩阵中 (Ii,Tj) 表示第 i 张图像与第 j 段文本的相似度。
- 理想情况下,对角线元素(同一对的文本 - 图像,如 I1−T1、I2−T2)是正例(相似度高)。
- 非对角线元素(不同对的文本 - 图像,如 I1−T2)是负例(相似度低)。
- 对比学习的目标:拉近正例相似度,推开负例相似度,让模型学会 “文本和图像内容一致时特征更对齐”。
阶段 2:从标签文本构建数据集分类器(Create dataset classifier from label text)
目标:用类别标签的文本描述,构造分类器的 “文本侧基准特征”。
- 输入:分类任务的类别标签(如
plane、car、dog、bird)。- 过程:
- 构造文本模板:用自然语言描述类别,如
A photo of a {object}.({object} 代入类别标签)。- 文本编码器(与阶段 1 共享参数)将每个类别对应的文本(如
A photo of a dog.)编码为文本特征(T1, T2, ..., TN)。- 这些文本特征成为分类器的 “基准”:每个类别对应一个唯一的文本特征,代表该类别的语义。
阶段 3:零样本预测(Use for zero-shot prediction)
目标:用未见过的图像,基于文本 - 图像的对齐特征,实现 “零样本分类”(无需为该任务训练数据)。
- 输入:新图像(如一张狗狗的照片)。
- 过程:
- 图像编码器(与阶段 1 共享参数)将新图像编码为图像特征(I1)。
- 计算该图像特征与阶段 2 中各类别文本特征的相似度(如 (I1-T1, I1-T2, ...))。
- 选择相似度最高的文本特征对应的类别(如图中与
dog对应的特征相似度最高),输出分类结果(如A photo of a dog.)。
核心逻辑:
通过对比预训练,模型学会了 “文本语义” 和 “图像内容” 的对齐表示(文本和图像内容一致时,特征更相似)。后续分类任务中,只需用类别标签的文本描述构造特征,即可让模型通过 “图像特征与文本特征的相似度” 判断类别 ——无需为新任务标注数据,实现零样本学习。
简单说:预训练让模型 “懂” 文本和图像的对应关系,零样本时用文本描述类别,让模型 “猜” 图像属于哪个文本描述的类别。
配置
$ conda install --yes -c pytorch pytorch=1.7.1 torchvision cudatoolkit=11.0 $ pip install ftfy regex tqdm $ pip install git+https://github.com/openai/CLIP.git在notebook里
# 配置 #install ftfy regex tqdm # 安装CLIP库(如果网络正常) !pip install git+https://github.com/openai/CLIP.git
加载预训练模型
import torch import clip from PIL import Image# 检查GPU是否可用 device = "cuda" if torch.cuda.is_available() else "cpu"# 加载预训练模型(首次运行会下载模型权重) model, preprocess = clip.load("ViT-B/32", device=device)# 查看可用模型 print("可用模型:", clip.available_models())注:
下载中途失败,显示“模型下载不完整或损坏,导致 SHA256 校验失败”
->手动删除并重新下载模型
CLIP 模型默认缓存路径为(Windows 上通常是
C:\Users\你的用户名\.cache\clip)。删除损坏的文件后重新下载
图像与文本特征提取
# 加载图像 image = preprocess(Image.open("CLIP.png")).unsqueeze(0).to(device)# 定义文本提示 texts = clip.tokenize(["a diagram","a dog","a cat" ]).to(device)# 计算特征 with torch.no_grad():image_features = model.encode_image(image)text_features = model.encode_text(texts)# 计算相似度矩阵logits_per_image, logits_per_text = model(image, text)# 转换为概率分布probs = logits_per_image.softmax(dim=-1).cpu().numpy()print("Label probs:", probs)
Linear-probe evaluation
如果出现包冲突
!pip uninstall -y numpy scipy scikit-learn !pip install numpy==1.21.5 scipy==1.7.3 scikit-learn==1.0.2import numpy as np import scipy import sklearn print(f"numpy 版本: {np.__version__}") print(f"scipy 版本: {scipy.__version__}") print(f"scikit-learn 版本: {sklearn.__version__}")安装完成后,在 Notebook 中运行代码,确认库能正常导入
如果输出版本号(如
1.21.5、1.7.3、1.0.2)且无报错,则安装成功。import os import clip import torchimport numpy as np from sklearn.linear_model import LogisticRegression from torch.utils.data import DataLoader from torchvision.datasets import CIFAR100 # 导入tqdm(用于显示进度条,直观查看处理进度) from tqdm import tqdm# 确定运行设备:优先使用GPU(cuda),否则用CPU device = "cuda" if torch.cuda.is_available() else "cpu" model, preprocess = clip.load('ViT-B/32', device)# 设置数据集存储根目录(默认在用户缓存文件夹) root = os.path.expanduser("~/.cache") train = CIFAR100(root, download=True, train=True, transform=preprocess) test = CIFAR100(root, download=True, train=False, transform=preprocess)# 定义函数:提取数据集中所有图像的特征和对应标签 def get_features(dataset):all_features = []all_labels = []# 禁用梯度计算(推理阶段无需更新模型,节省内存和计算资源)with torch.no_grad():# 用DataLoader批量加载数据:每次处理100张图像,tqdm显示进度条for images, labels in tqdm(DataLoader(dataset, batch_size=100)):# 将图像批量传到设备(GPU/CPU),并用CLIP的图像编码器提取特征features = model.encode_image(images.to(device))# 收集当前批次的特征和标签all_features.append(features)all_labels.append(labels)# 将所有批次的特征和标签拼接成完整数组,并从GPU转移到CPU,转为NumPy格式(方便后续sklearn处理)return torch.cat(all_features).cpu().numpy(), torch.cat(all_labels).cpu().numpy()# 提取训练集的图像特征和标签(用预训练CLIP模型,冻结参数不更新) train_features, train_labels = get_features(train) # 提取测试集的图像特征和标签(同样用预训练CLIP模型) test_features, test_labels = get_features(test)# 初始化逻辑回归分类器 # - random_state=0:固定随机种子,保证结果可复现 # - C=0.316:正则化强度(论文中调优后的最优值) # - max_iter=1000:最大迭代次数(确保收敛) # - verbose=1:训练时打印日志 classifier = LogisticRegression(random_state=0, C=0.316, max_iter=1000, verbose=1) # 用训练集的特征和标签训练分类器(仅训练线性层,CLIP特征固定) classifier.fit(train_features, train_labels)# 用训练好的分类器对测试集特征进行预测 predictions = classifier.predict(test_features) # 计算准确率:预测标签与真实标签一致的比例,乘以100转为百分比 accuracy = np.mean((test_labels == predictions).astype(float)) * 100. # 打印最终准确率(线性探针评估的核心指标) print(f"Accuracy = {accuracy:.3f}")显示未能完全收敛,可以max_iter=5000