Kettle 开源ETL数据迁移工具从入门到实战
ETL(Extract, Transform, Load)工具是用于数据抽取、转换和加载的软件工具,用于支持数据仓库和数据集成过程。Kettle作为传统的ETL工具是纯 java 开发的开源的 ETL工具,用于数据库间的数据迁移 。可以在 Linux、windows、unix 中运行。有图形界面,也有命令脚本还可以二次开发。
kettle 的官网为:
https://community.hitachivantara.com/docs/DOC-1009855
github 地址为:
https://github.com/pentaho/pentaho-kettle。
一、Kettle是什么?
Kettle 是一款开源的 ETL(Extract - Transform - Load)工具,用于数据抽取、转换和加载。它提供了一个可视化的设计环境,允许用户通过简单的拖拽和配置操作来构建复杂的数据处理工作流,能够处理各种数据源和目标之间的数据集成任务,帮助企业将来自不同数据源的数据进行整合,然后加载到数据仓库或其他目标系统中。
二、Kettle的组成部分
Kettle主要由以下几个关键部分组成:
1、转换(Transformation)
转换是Kettle的核心组件之一,主要用于对数据进行各种操作和转换。它的目的是将输入数据按照预先定义的规则进行处理,生成符合要求的输出数据。转换可以被看作是一个数据加工的流水线,数据在这个流水线上依次经过各种处理步骤。
2、作业(Job)
作业用于对一系列任务进行组织和调度。它可以包含多个转换、其他作业或者其他操作步骤,并且可以定义这些任务的执行顺序和条件。作业更侧重于数据处理流程的整体控制和自动化,比如按照时间顺序或者特定的事件触发数据处理任务。
3、存储库(Repository)
存储库是Kettle用于存储和管理对象(如转换、作业、数据库连接等)的地方。它提供了一种集中式的管理方式,方便用户在团队环境中共享和复用数据处理资源。
4、调度器(Scheduler)
调度器用于安排作业的执行时间和频率。它可以根据用户设定的时间表(如每天几点执行、每周几执行、每月几号执行等)或者特定的事件触发(如文件到达指定目录、数据库表中的数据更新等)来自动启动作业。
组成部分的具体解释可以通过官网进一步了解和学习,在这里不再赘述。
三、Kettle的优缺点
优点:
1)可视化操作界面:Kettle 提供了直观的图形化界面,用户无需编写大量的代码即可构建复杂的数据处理流程。通过简单的拖拽和配置步骤的属性,就能完成从数据抽取到加载的整个过程,大大降低了数据集成的难度,使得非技术人员也能够相对容易地进行操作。
2)丰富的组件库:它拥有众多的数据处理步骤和插件,涵盖了几乎所有常见的数据操作。例如,有用于数据过滤的步骤、数据排序步骤、数据分组步骤、各种数据格式转换步骤(如日期格式转换、字符串编码转换等),以及用于连接不同类型数据源和目标的步骤,能够满足多样化的数据集成需求。
3)可扩展性和灵活性:可以通过编写自定义插件来扩展Kettle的功能。对于一些特殊的业务需求或者特定的数据处理操作,如果现有的步骤和组件无法满足,可以开发自定义的插件并集成到 Kettle 中。同时,它可以灵活地处理不同规模的数据集成任务,从小型的部门级数据整合到大型企业级的数据仓库加载都能胜任。
4)支持多种数据源和目标:能够处理多种数据源类型。除了常见的关系型数据库,还可以处理文件类型(如文本文件、XML 文件、JSON 文件)、大数据源(如 Hadoop 分布式文件系统 HDFS)以及通过网络接口(如 RESTful API)获取的数据。在目标方面,同样可以将数据输出到多种类型的存储介质中。
缺点:
1、性能方面的局限
1)大规模数据处理效率较低 :
当处理海量数据时,Kettle 的性能可能会显著下降。由于它是基于 Java 开发的,数据处理过程中涉及大量的内存操作和中间缓存。例如,在对包含数亿条记录的大型数据库表进行复杂的转换(如多表连接、嵌套子查询转换等)和抽取操作时,可能会出现内存溢出或者处理速度极慢的情况。这是因为 Kettle 在处理数据时,需要将数据加载到内存中的某些数据结构中进行处理,随着数据量的增大,内存消耗会急剧增加。
2)资源消耗问题:
它对系统资源(如 CPU 和内存)的消耗比较大。在运行复杂的工作流时,尤其是包含多个数据密集型的转换步骤和作业任务时,可能会占用大量的 CPU 时间和内存空间。这可能导致在同一台服务器上运行的其他应用程序受到影响,甚至在资源有限的环境中,可能无法顺利完成数据处理任务。
2、功能和灵活性方面的不足
1)高级功能实现复杂:
尽管 Kettle 提供了丰富的基本数据处理步骤,但对于一些非常高级的数据分析和处理功能,实现起来比较复杂。例如,对于复杂的机器学习算法应用或者深度数据挖掘任务,虽然可以通过自定义插件等方式来实现,但这需要开发者具备较高的技术水平,包括熟练掌握 Java 编程和 Kettle的插件开发机制。
2)对实时数据处理支持有限:
在面对实时数据处理场景时,Kettle 的能力相对较弱。它主要侧重于批处理模式的数据抽取、转换和加载,对于像实时流数据的处理(如物联网设备产生的连续数据流、金融交易实时数据等),需要进行大量的定制化开发和额外的配置才能勉强满足需求,而且性能和稳定性也难以保证。
3、维护和管理的困难
1)工作流的复杂性管理:
随着数据处理任务的增加和业务逻辑的复杂化,Kettle 中构建的工作流(包括转换和作业)会变得非常复杂。当需要对这些工作流进行修改或者维护时,例如,当数据源的结构发生变化或者业务规则调整时,要准确地找到需要修改的步骤和作业,并确保修改后的工作流能够正确运行,是一项具有挑战性的任务。因为一个复杂的工作流可能包含众多相互关联的步骤和依赖关系,一处修改可能会影响到整个工作流的其他部分。
4、学习和使用成本较高
1)陡峭的学习曲线:
尽管 Kettle 有可视化的操作界面,但要熟练掌握它并能高效地构建复杂的数据处理工作流,仍然需要花费大量的时间学习。用户需要了解各种数据处理步骤的功能、参数设置,以及如何合理地组合这些步骤来实现特定的业务逻辑。对于没有ETL工具使用经验或者编程基础较弱的用户来说,学习成本会更高。
2)文档和技术支持的局限性:
开源工具的文档通常不如商业软件完善。Kettle 的文档虽然能够提供基本的功能介绍和操作指南,但对于一些复杂的场景和高级功能的解释可能不够详细。而且,在遇到问题时,由于没有像商业软件那样完善的技术支持团队,用户可能需要花费更多的时间在网上搜索解决方案或者在社区中寻求帮助,这可能会导致问题解决的效率较低。
四、Kellte安装
以 windows 下的配置为例,linux 下配置类似。
jdk 安装及配置环境变量
由于 kettle 是基于 java 的,因此需要安装 java 环境,并配置 JAVA_HOME 环境变量。
建议安装 JDK1.8 及以上,7.0以后版本的 kettle 不支持低版本 JDK。
下载 kettle
从 官网 下载 kettle ,解压到本地即可。
下载相应的数据库驱动:由于 kettle 需要连接数据库,因此需要下载对应的数据库驱动。
例如 MySQL 数据库需要下载 mysql-connector-java.jar,oracle 数据库需要下载 ojdbc.jar。下载完成后,将 jar 放入 kettle 解压后路径的 lib 文件夹中即可。
本人网盘也可下载(包括Kettle和oracle、mysql数据库驱动):通过网盘分享的文件:Kettle数据迁移工具.zip
链接: https://pan.baidu.com/s/1uH6yFx5gbxf-sUnqSuJ0tQ?pwd=u7mg 提取码: u7mg
五、实战演示
1、启动
添加完驱动后,双击程序 Spoon.bat 就能启动 kettle 。
2、转换
转换包括一个或多个步骤,步骤之间通过跳(hop)来连接。跳定义了一个单向通道,允许数据从一个步骤流向另一个步骤。在Kettle中,数据的单位是行,数据流就是数据行从一个步骤到另一个步骤的移动。
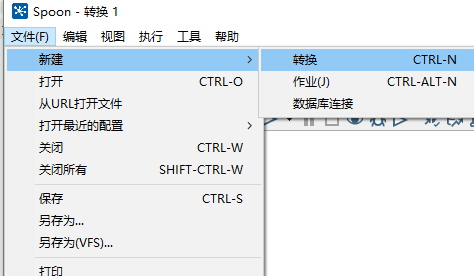
(1)打开 kettle,点击 文件->新建->转换。
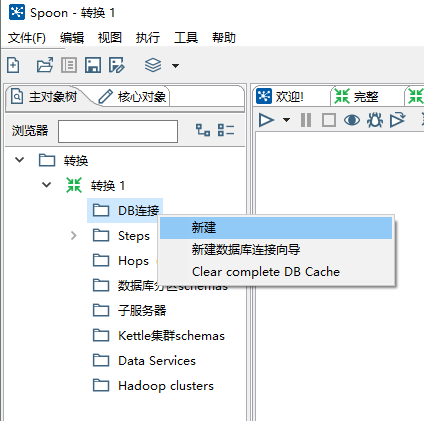
(2)在左边 DB 连接处点击新建。
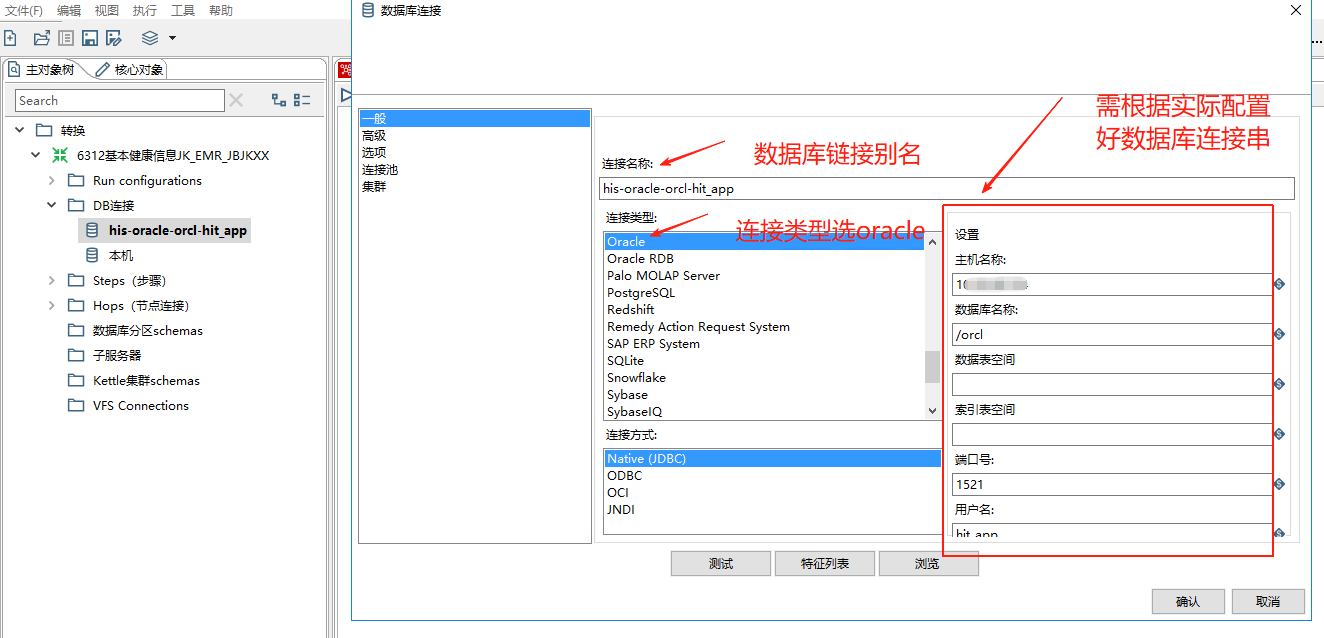
根据提示配置数据库,配置完成后可以点击测试进行验证,这边以 oracle 为例。
(3)在左侧找到表输入(核心对象->输入->表输入),拖到右方。
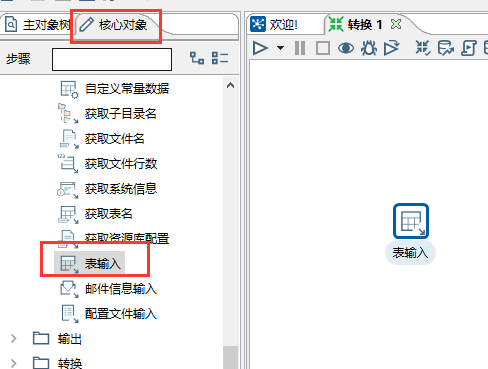
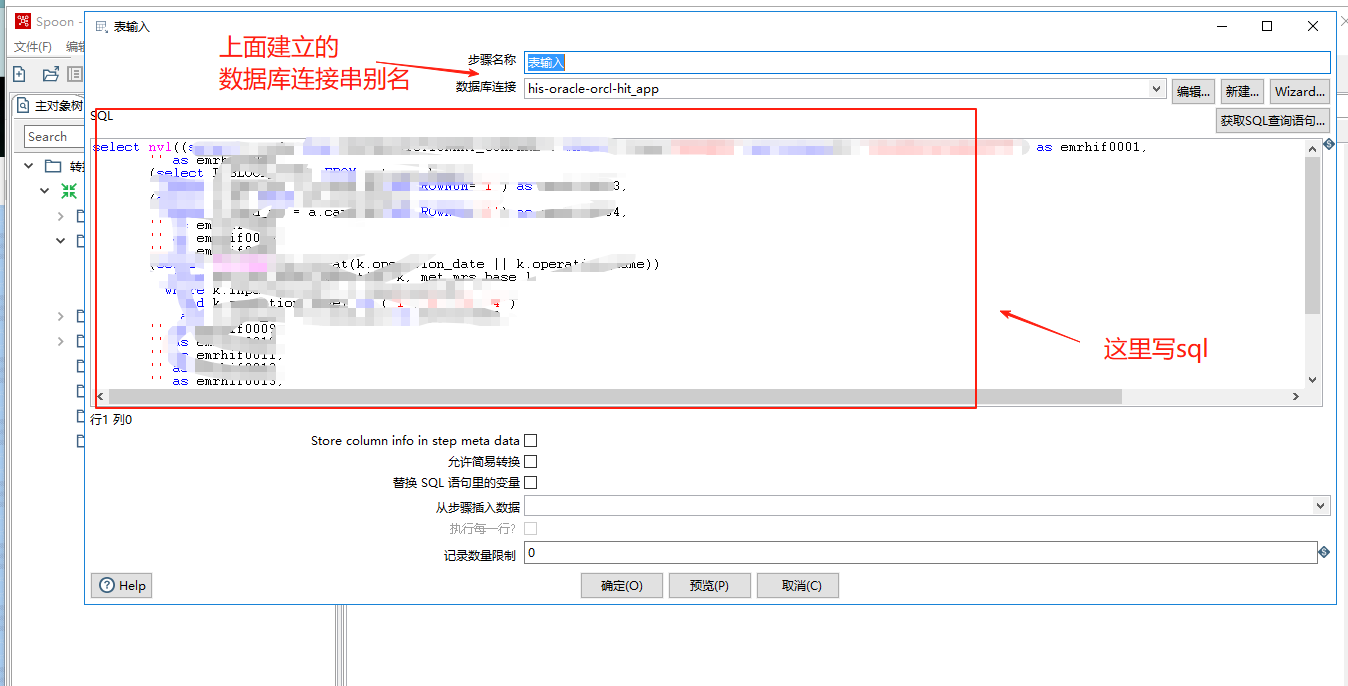
双击右侧表输入,进行配置,选择数据源,并输入 SQL。可以点击预览进行预览数据。
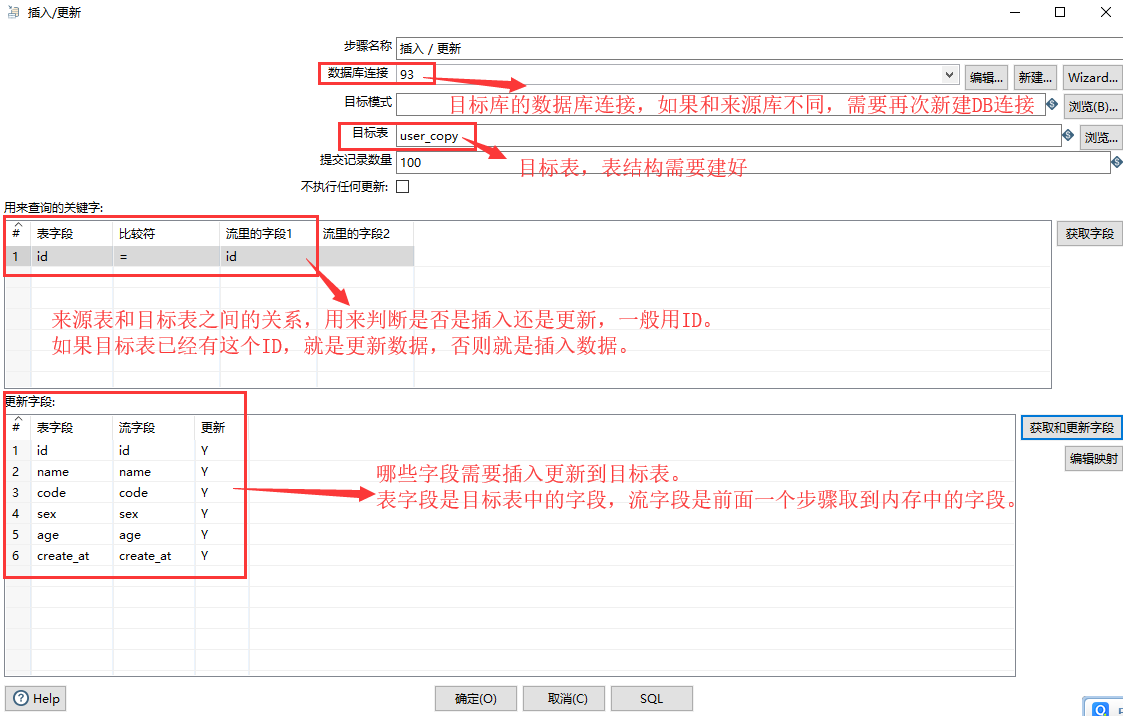
(4)在左侧找到插入/更新(核心对象->输出->插入/更新),拖到右方。也可以拖表输出到右方进行新增,这里已新增为例:
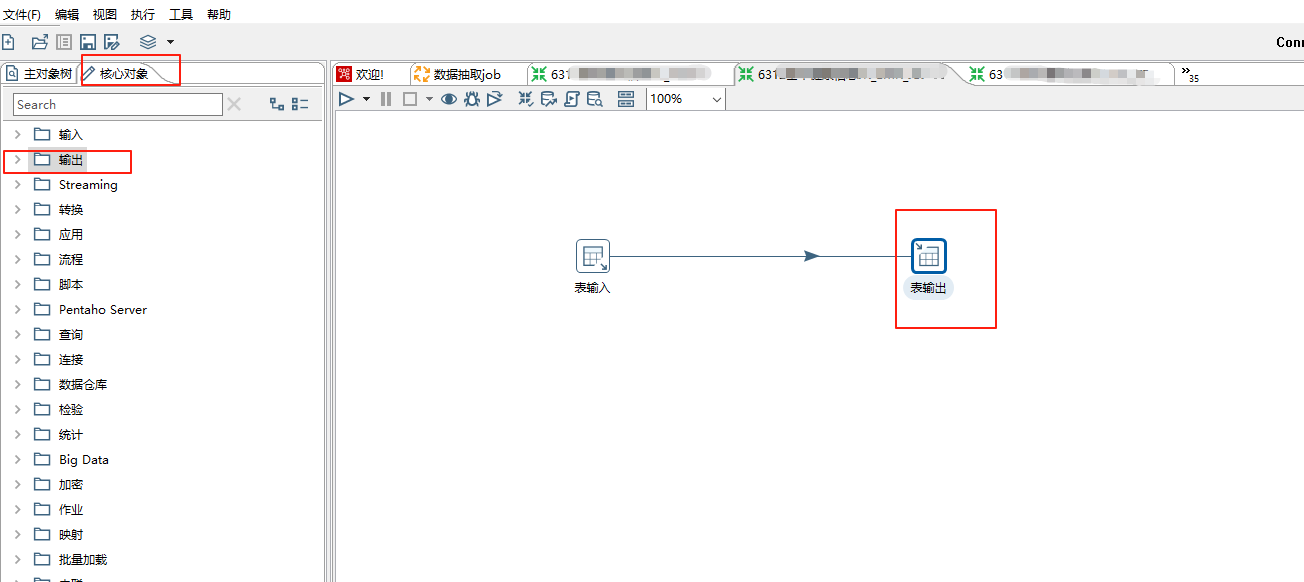
按住 Shift 键,把表输入和插入/更新用线连接起来,注意中间的线点击灰色表示禁用,蓝色表示启用。
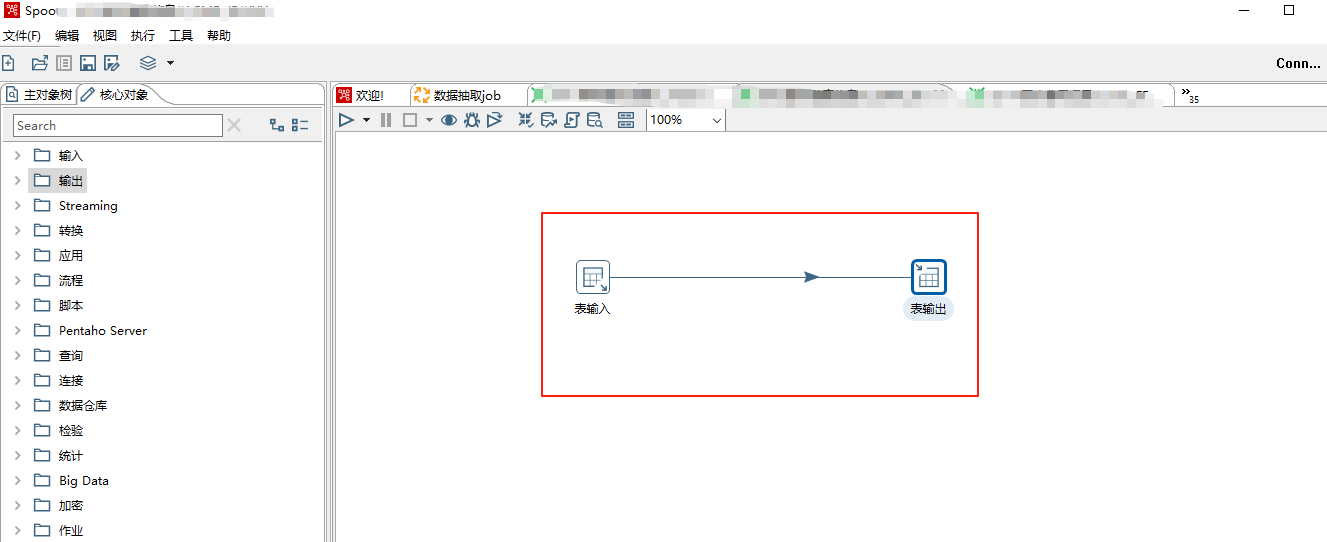
对输出表双击进行配置:
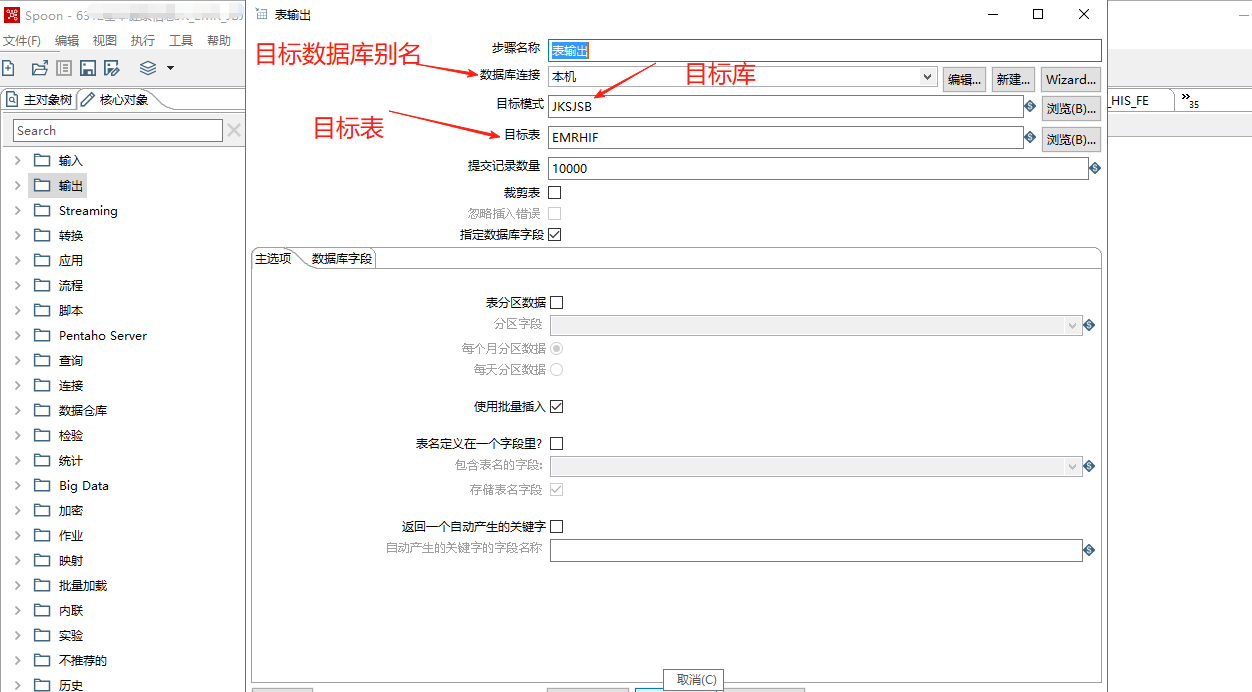
附上插入/更新的配置说明:
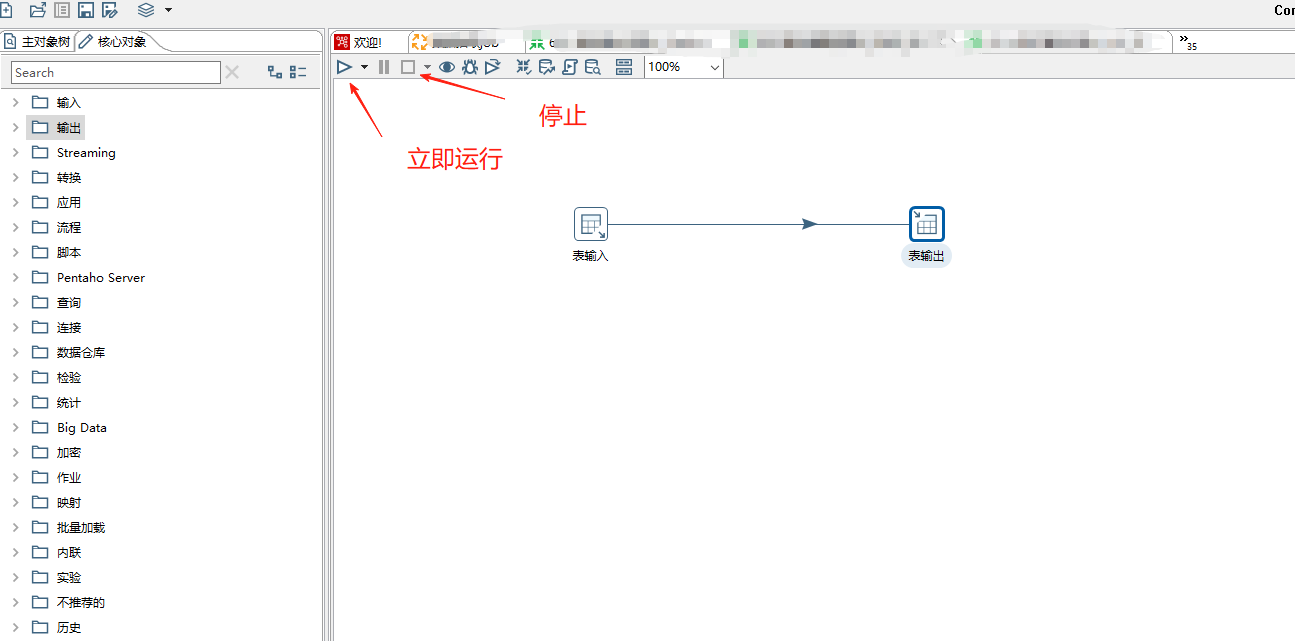
(5)点击运行,就可以运行这一个转换。
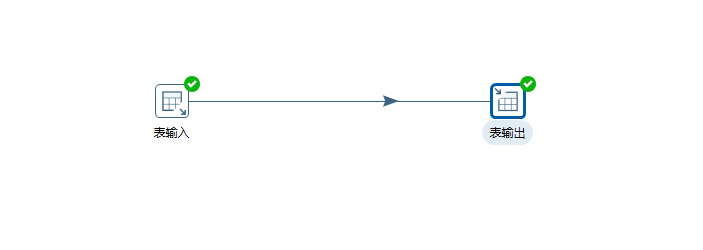
运行结束后会看到绿色对号,表示成功:
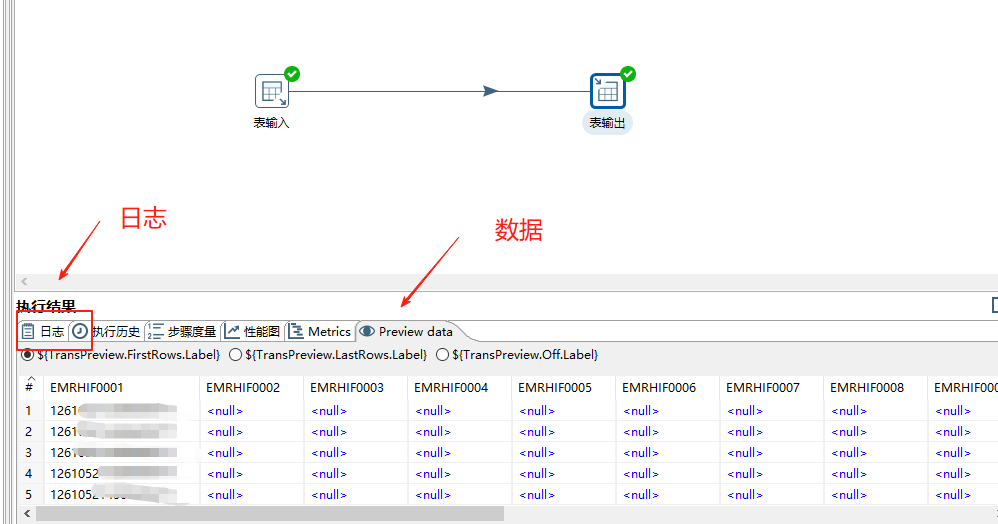
3、作业
如果想要定时运行这个转换,那么就要用到作业。
新建一个作业。
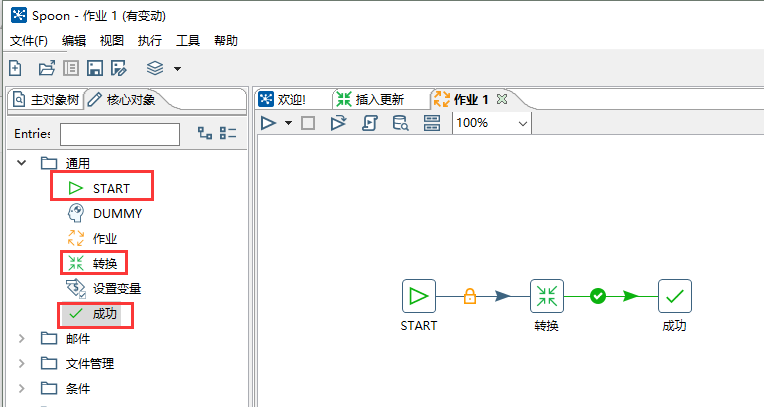
从左侧依次拖动 START 、转换、成功到右侧,并用线连接起来。
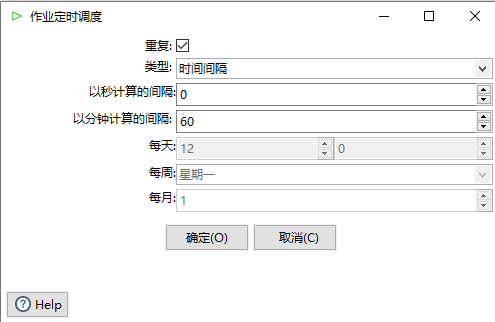
双击 START,可以配置作业的运行间隔,这边配置了每小时运行一次。
双击转换,选择之前新建的那个转换。
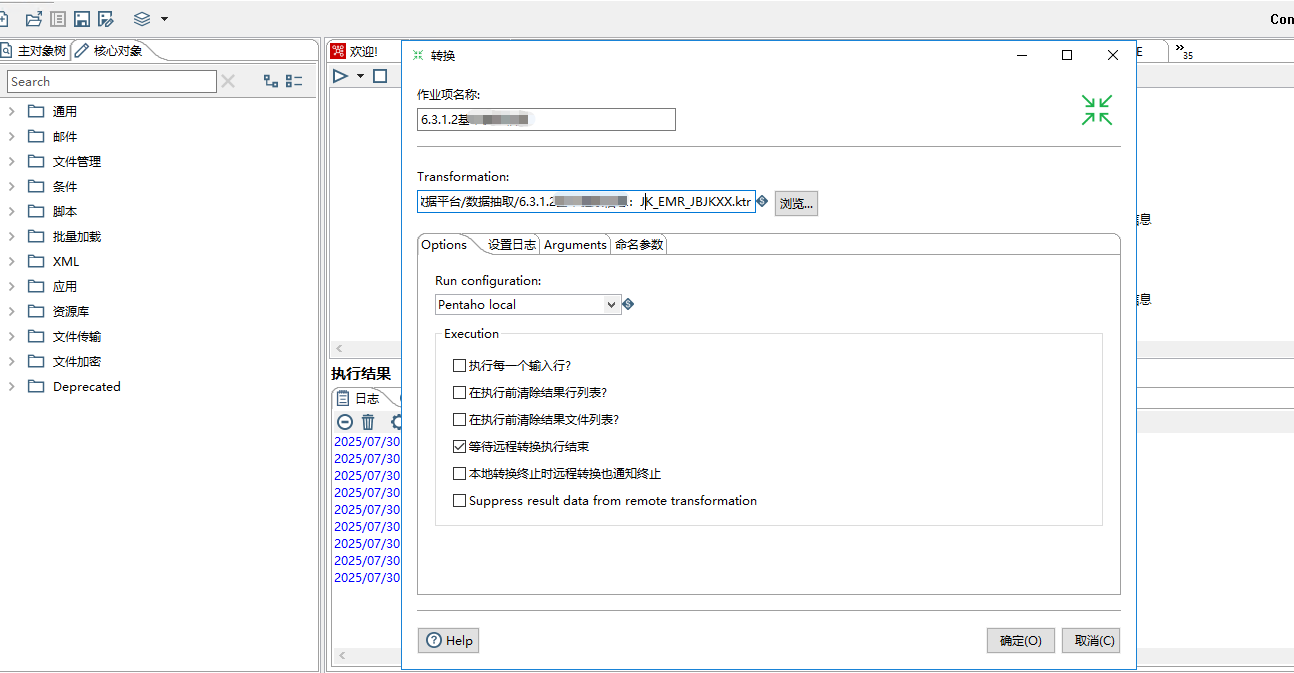
点击运行,就能运行这次作业,点击停止就能停止。在下方执行结果,可以看到运行的日志。
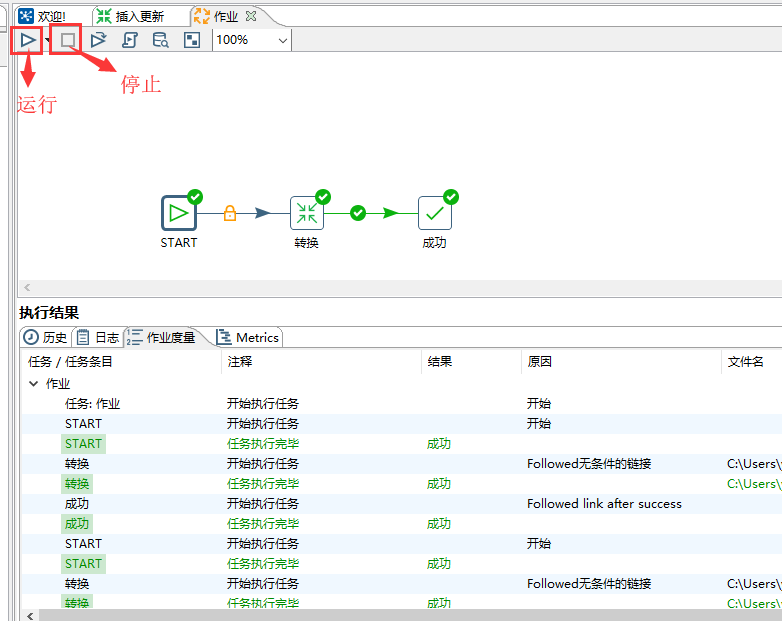
这样就完成了一个最简单的作业,每隔1小时,将源表的数据迁移到目标表。
六、实战总结
以上是本人对Kettle工具的一些基本认识和用法,Kettle工具本身也是一个非常强大的ETL工具,可以轻松通过Kettle的图形化界面完成数据的迁移,不用额外开发代码,并实现定时任务执行数据迁移,关于该工具的详细使用今天就分享到这里,希望大家能够学习和成长,也希望大家能够摸索出更好的工具分享出来。