如何设计一个限流器?
一、限流器理解
限流可以在客户端、服务端,也可以在API网关
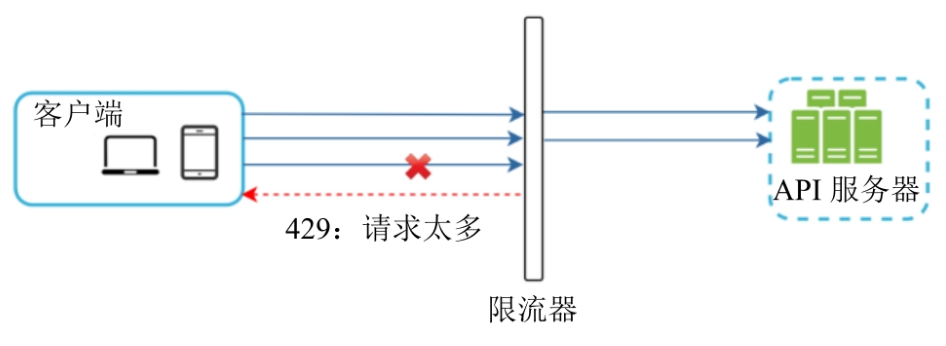
不同的限流算法有不同的优点和缺点,要结合场景使用,常见的有桶代币算法、漏桶算法、固定窗口技术器算法、滑动窗口日志算法。
二、限流算法
2.1.1 桶代币算法
桶代币是一个有预定义容量的容器,代币按照预定的速度被放如桶中,一旦桶满则不再放入。然后每个请求将会消耗一个代币,如果请求到达时没有足够的代币请求就会被丢弃。
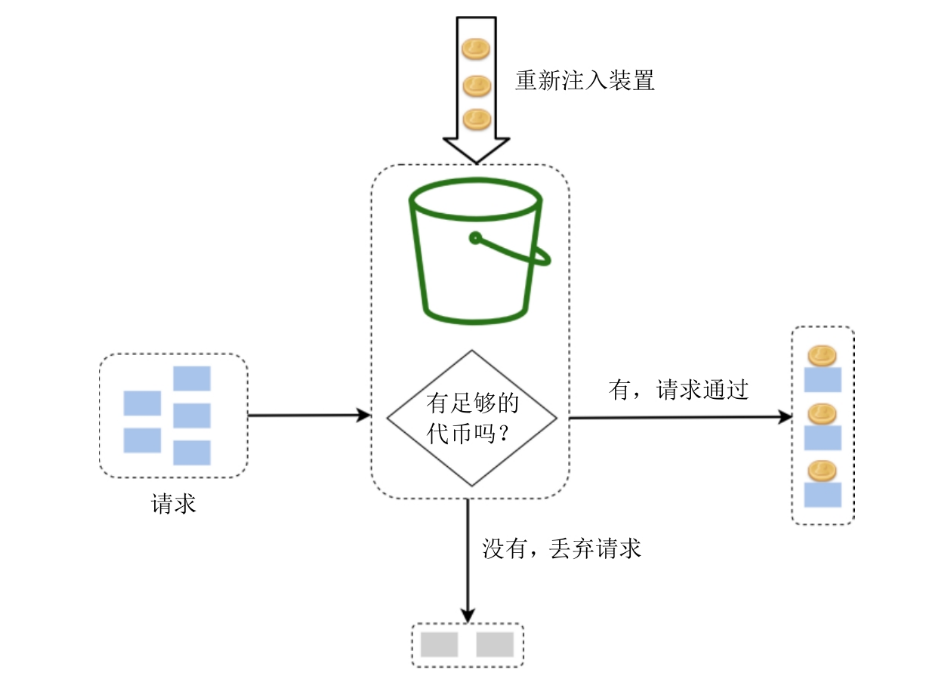
桶代币算法的两个关键参数:桶大小、重新注入代币的速度
2.1.2 漏桶算法
与桶代币算法类似,但它对请求是按照固定速率处理的。漏桶算法通常采用先进先出的队列来实现。
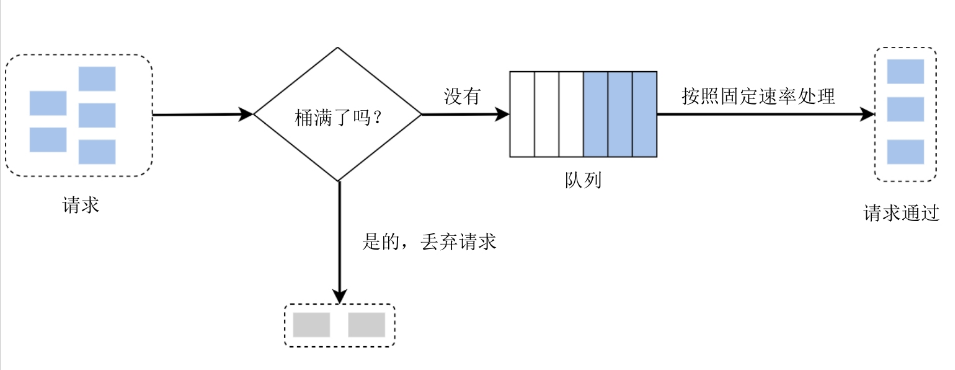
漏桶算法两个关键参数:桶大小、出栈速度
2.1.3 固定窗口计数器算法
工作原理:将时间轴分成固定大小的窗口,并给每个窗口分一个计数器。每到达一个请求,计数器就会值+1,一旦计数器达到预设的阈值,新请求就会被丢弃,直到开始一个新的时间窗口。
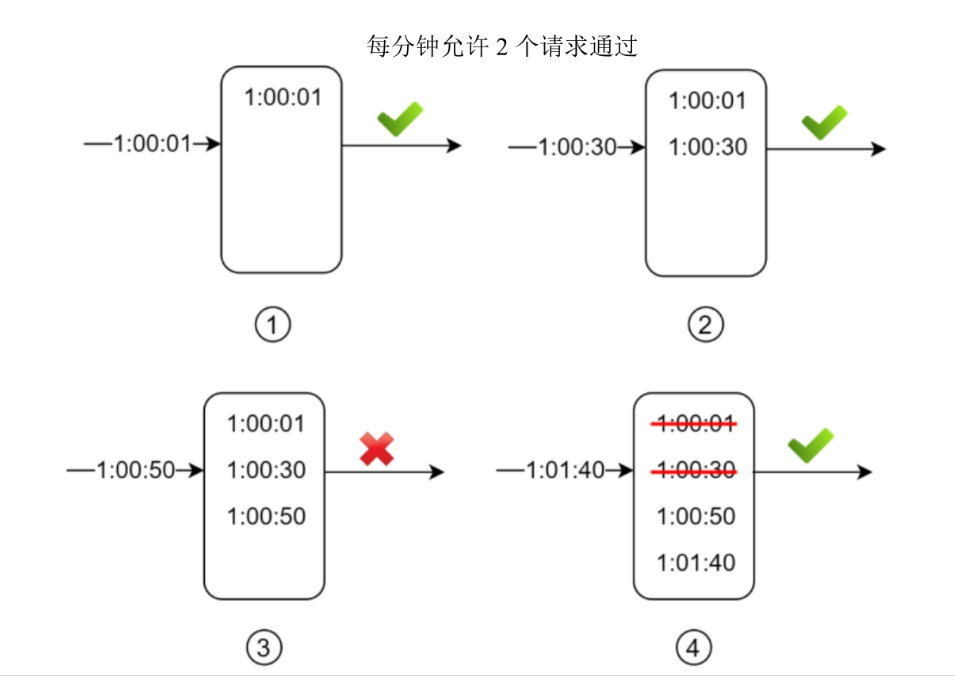
比如时间窗口1s,阈值3,则如图:
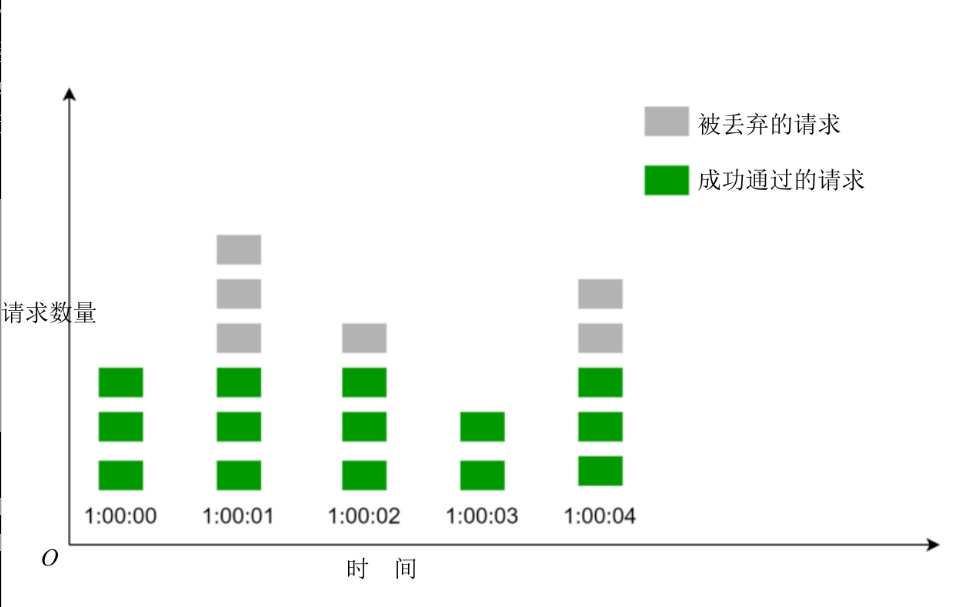
滑动窗口计数器算法缺点是:在时间窗口的边界上流量激增,会导致通过的请求数超过设定的阈值。
2.1.4 滑动窗口日志算法
工作原理:记录每个请求的时间戳(通常保存在缓存中,如Redisd的有序集合);当新请求到达时,移除所有过期时间戳(指早于当前时间窗口开始时间的时间戳),将新请求的时间戳添加到日志中,如果日志的条数小于等于允许的条数则允许请求通过:
优点是实现的流量控制非常准确,在任何滑动的时间窗口请求的数量都不睡超过阈值,内存使用很高效。但缺点是:算法是根据真实流量速率。
三、拒绝策略和设计
3.1 单体限流器设计
如果一个请求被限流,API会给客户端返回HTTP响应码429(请求过多)。根据应用场景,也有可能会把超过阈值的请求放如队列,之后再处理。下图是一个单体应用的设计示例: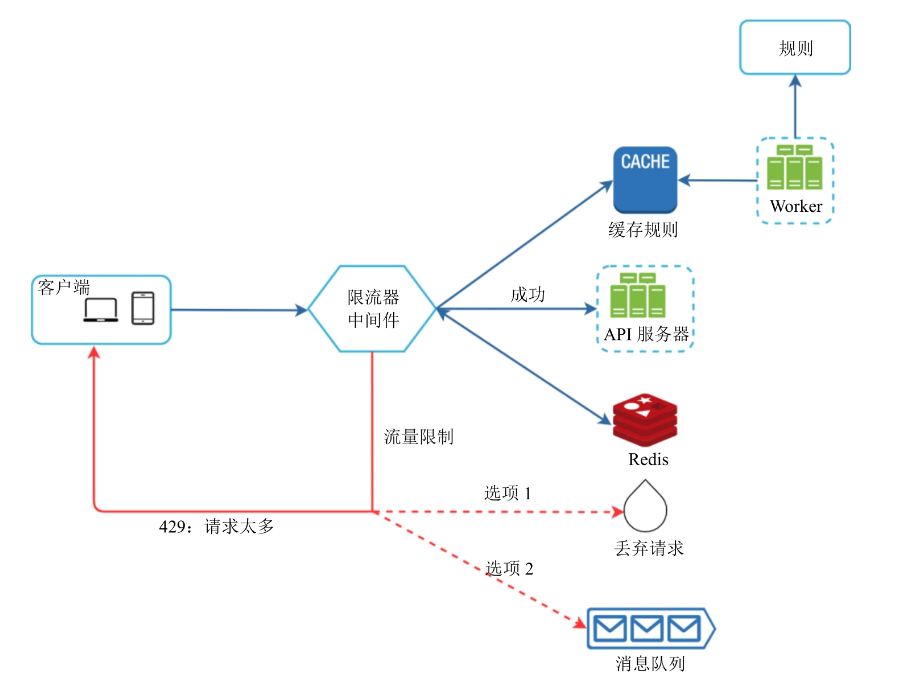
上图流程简要说明:
- 流量限制规则存储在硬盘上,工作进程经常从硬盘中获取规则并将其存储到缓存中;
- 当客户端向服务端发送请求时,请求会首先被发给限流中间件;
- 限流中间件从缓存中加载规则,它从Redis缓存中获取计数器和上一次请求的时间戳;
- 基于响应,限流中间件做出不同的决策:
- 如果没有被限流则转发请求给API
- 如果请求被限流,限流器会向客户端返回429响应码报错,同时要么丢弃请求要么被转发到队列中去。
3.2 分布式系统限流
单体服务环境中创建限流器并不难,但是要将限流器系统扩展,以支持多个服务器和并发线程,就是另一回事了,其中存在两个挑战:竞争条件 和 同步问题。
3.2.1 竞争条件
可能会发生在一个高并发的环境中,锁的竞争是最直观的解决方案,但是它会显著拖慢系统速度。
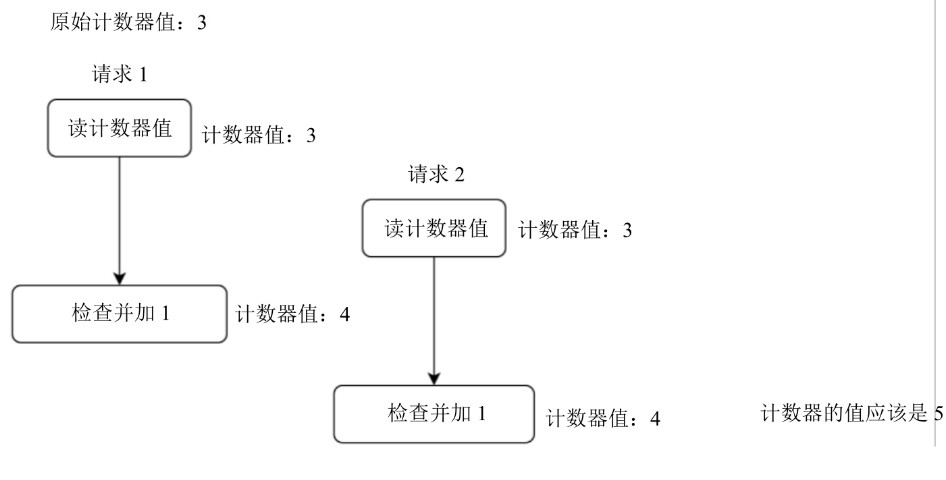
解决这个问题可以使用的方案:Lua脚本 + Redis有序集合数据结构
local tokens_key = KEYS[1] -- 令牌数Key
local timestamp_key = KEYS[2] -- 时间戳Key
local rate = tonumber(ARGV[1]) -- 速率
local capacity = tonumber(ARGV[2]) -- 容量
local now = tonumber(ARGV[3]) -- 当前时间
local requested = 1 -- 请求令牌数local last_tokens = tonumber(redis.call("GET", tokens_key)) or capacity
local last_time = tonumber(redis.call("GET", timestamp_key)) or nowlocal elapsed = now - last_time
local new_tokens = math.min(capacity, last_tokens + elapsed * rate)if new_tokens < requested thenreturn 0
elseredis.call("SET", tokens_key, new_tokens - requested, "EX", window_sec*2)redis.call("SET", timestamp_key, now, "EX", window_sec*2)return 1
end3.2.2 同步问题
在百万级量级的系统中,一个限流器不足以处理所有流量,这时使用多个限流器的话,就要解决限流器之前的同步问题。一个可行的解决方案就是使用粘性会话,允许客户端将请求总是发往同一个限流器,但是这个方案不好扩展也不灵活。更好的方法是使用中心化的数据存储,比如Redis: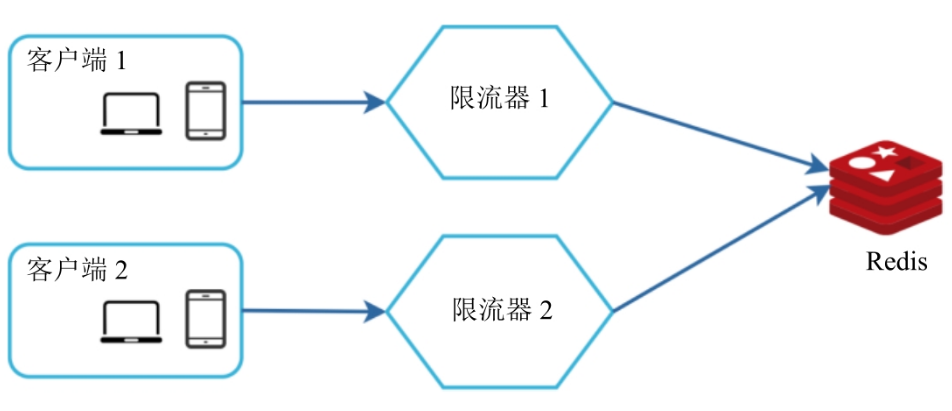
四、性能优化
上面的内容其实已经把关键点说了七七八八了,但是初步的设想肯定是存在优化空间的,而且优化问题也是面试中最为常见的主题,因此再针对两个方面进行优化:
(1)对限流器而言,设置多数据中心是至关重要的,因为离数据中心越远,响应耗时越大;
(2)通过最终一致性模型来同步数据
(3)做好流量限制算法的监控,及时发现限流算法对于使用场景的匹配性,如果发现不适合则需要切换另一种算法。
最终一致性模型扩展:
一致性模型是设计键值存储系统是需要考虑的一个重要因素,一致性模型分几种不同类型,可以根据系统需求和应用场景来选择合适的一致性模型。
- 强一致性模型:任何读操作返回的值都是最新写入的数据,客户端永远不会看见过时的数据。通常是通过强制一个副本在当前写入操作成功前不再接收新的读/写操作来实现的,所以很明显性能不会太好,不适合。
- 弱一致性模型:随后的读操作返回的可能不是最新的值;
- 最终一致性模型:这是弱一致性的一种特殊形态。经过足够长的时间后,所有的数据都会更新传播开来,并且所有副本会变得一致。可以了解一下MYSQL的隔离级别那块,通过版本控制思路来实现,或者MQ订阅方式实现。