Redis高可用性
Redis高可用:
Redis 实现高可用主要依赖于三种核心机制,分别是主从复制、哨兵模式、集群模式;
1、主从复制:
Redis 高可用服务的最基础的保证,配置一个主节点(Master)和一个或多个从节点(Slave)。主节点负责处理所有的写操作,并把数据变更异步地同步给所有从节点。从节点复制主节点的数据,并且可以分担读请求。
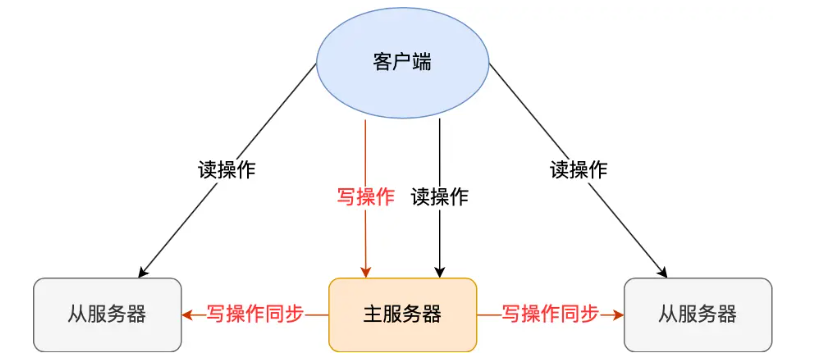
主从复制过程会有数据不一致的问题,主服务器自己在本地执行完命令后,就会向客户端返回结果了。如果从服务器还没有执行主服务器同步过来的命令,主从服务器间的数据就不一致了。所以,无法实现强一致性保证(主从数据时时刻刻保持一致),数据不一致是难以避免的。
优点:
数据备份:从节点是主节点数据的热备份,万一主节点磁盘损坏,数据不会完全丢失。
读写分离:可以让从节点处理读请求,分担主节点的压力,提升整体读性能。
高可用的局限性:主从复制本身不能实现自动故障转移。如果主节点宕机,整个系统就无法接收写请求。我们需要人工介入,手动将一个从节点提升为新的主节点,并让其他从节点指向它。这个过程会产生服务中断,所以它只是数据冗余,还不是真正的高可用。
2、哨兵模式:
为了解决主从复制无法自动故障转移的问题,Redis 提供了哨兵模式。
哨兵是一个独立的进程,监控着整个主从系统。通常我们会部署一个奇数个(如3个或5个)哨兵组成的集群来避免哨兵自身的单点问题。
监控 :哨兵集群会持续地向主、从节点发送心跳,检测它们是否正常工作。(监控和被监控之间会建立TCP长连接,通过这样的长连接,定期发送心跳包)
自动故障转移:当多数哨兵判定主节点“客观下线”后,它们会:
在哨兵内部进行一次选举,选出一个领导者哨兵。
由领导者哨兵在所有从节点中,按照一定规则(如优先级、复制偏移量等)挑选一个最优的从节点,并将其提升为新的主节点。
然后通知其他从节点,让它们去复制新的主节点。
通知 :哨兵能将故障转移的结果通知给客户端,客户端从而知道新的主节点地址。
通过哨兵模式,我们就实现了一个具备自动故障转移能力的主从架构,这是 Redis 最经典的高可用方案。
哨兵模式下自动主从切换过程:
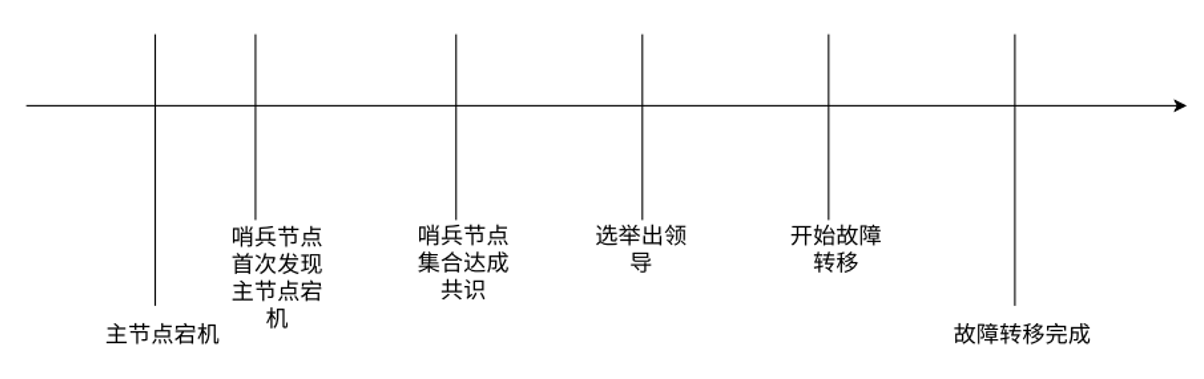
主观下线
哨兵节点会和主从节点之间通过心跳包检测是否正常,当redis-master宕机,此时 redis-master 和三个哨兵之间的心跳包就没有了,那么,在哨兵的角度看,这个主节点出现了故障,所以这三个哨兵节点会判定主节点下线了,这是主观下线(此时还不能排除网络波动的影响,因此就只能是单方面认为这个redis 节点挂了);
客观下线
哨兵 sentenal1,sentenal2,sentenal3 均会对主节点故障这件事情进行投票,当故障得票数 >= 配置的法定票数之后,意味着主节点故障是真的,就触发客观下线;
选出哨兵的leader
哨兵从剩余的 slave 中挑选出一个新的 master,这个工作不需要所有的哨兵都参与,只需要选出个代表(称为leader),由 leader 负责进行slave 升级到 master 的提拔过程
由leader挑选出合适的slave 成为新的master
上述过程中的第三步挑选哨兵的leader使用的是Raft算法:大概就是每个哨兵向其他哨兵节点主动发起拉票请求,当哨兵节点收到请求后进行投票,表示是否同意某一结点成为leader,一轮投票结束后,票数多的哨兵节点成为leader,然后进行第四步的操作。
第四步中的挑选规则:
比较优先级,优先级高的成为主节点;
比较谁复制的主节点数据多,数据多的成为主节点;(通过replication offset判断)
比较run id,谁的小谁成为主节点。
3、集群模式:
当数据量巨大,单个主节点无法承载时(比如内存限制或写压力过大),我们就需要进行分片。
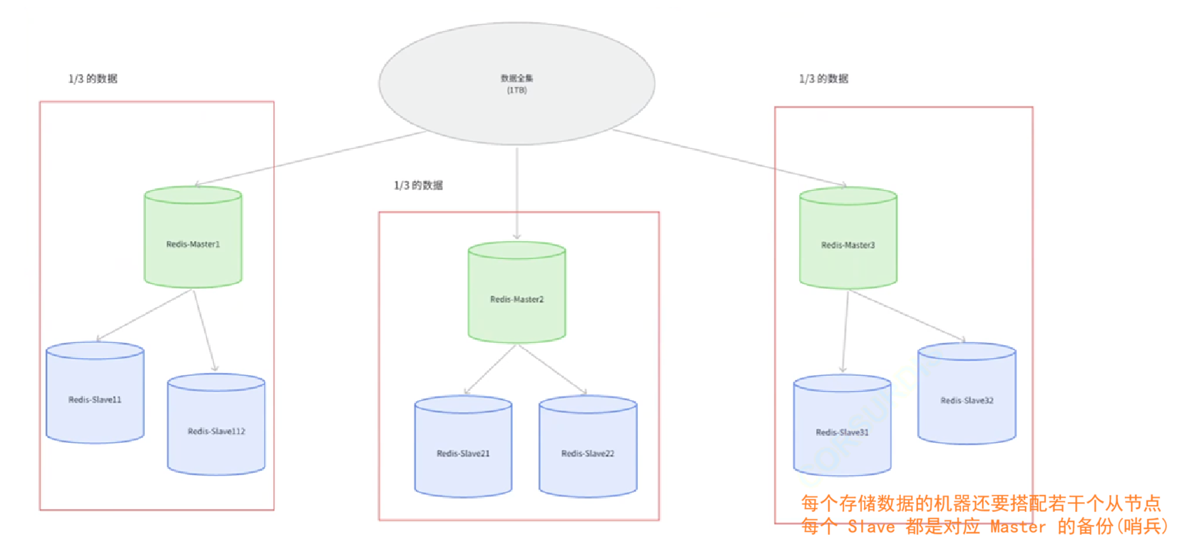
上面的每一个框都是一个分片,就是把数据分为多片,由不同的分片承担。
数据分片算法主要有:哈希求余、一致性哈希哈希槽分区算法,在Redis中使用的是哈希槽分区算法:
数据分片:Cluster (引入了哈希槽算法)将所有数据划分为 16384 个哈希槽(hash slots)。每个主节点负责一部分哈希槽。当客户端存取一个 key 时,会根据
CRC16(key) % 16384算法计算出这个 key 属于哪个槽,然后将请求路由到对应的节点。内置高可用:在 Cluster 模式中,每个主节点都可以有自己的从节点。它的高可用机制是内置的,不再需要独立的哨兵进程。集群中的节点之间通过 Gossip 协议互相通信来监控彼此的状态。如果一个主节点被发现宕机,它的从节点会在集群的协调下自动提升为新的主节点,接管原来的哈希槽。