JVM——内存布局、类加载机制及垃圾回收机制
一、JVM内存布局
JVM内存布局也叫做JVM运行时数据区,由以下部分组成:
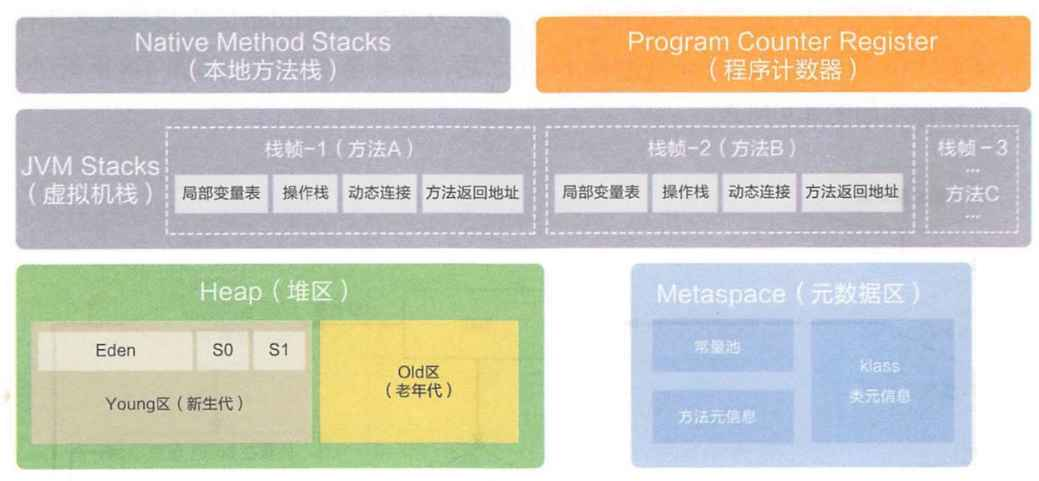
下面了解各区域的作用(重要):
1> 程序计数器:记录当前指令执行到哪个地址
2> 元数据区:保存当前类被加载好的数据(类名、方法名、方法参数个数等)
3> 栈:保存方法间的调用关系(本地方法栈保存的是本地方法间的调用关系,虚拟机栈保存的是Java方法之间的调用关系)
4> 堆:保存对象
二、JVM类加载
2.1 类加载机制
对于一个类,它的生命周期是这样的:
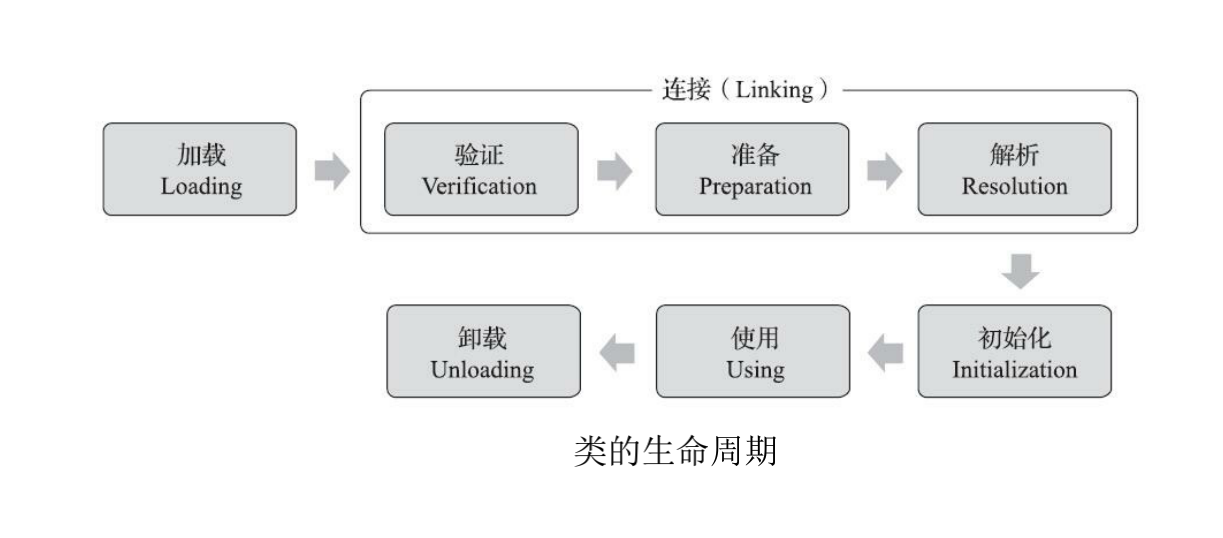
其中前5步是固定的顺序,也是类加载的流程,具体内容如下(重要):
1)加载
通过类的全限定名(包名+类名)找到.class文件并读取到内存中
2)验证
校验.class文件读取到的内容是否是合法的,并且将这里的内容转化为结构化的数据
3)准备
为类中定义的静态变量分配内存,并设置初始值
4)解析
将常量池中的符号应用改为直接引用
5)初始化
将类对象进行最终的初始化,对对象的各种属性进行填充(如果发现这个类的父类还没有加载,也会触发父类的类加载)
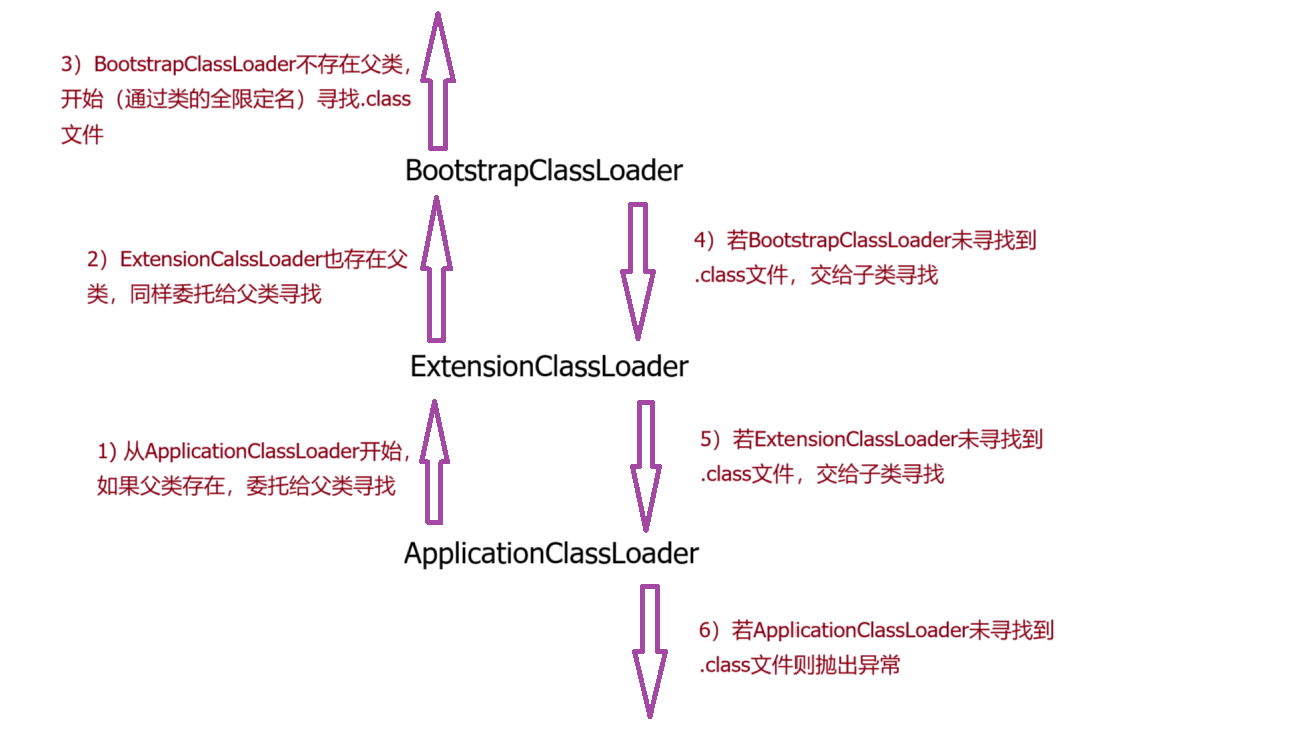
2.2 双亲委派模型
双亲委派模型应用在类加载过程中的加载步骤的,它描述了类加载器(专门用于类的加载)之间的协作关系,JVM默认提供3种类加载器,委派过程如下(重要):
三、垃圾回收机制
3.1 死亡对象的判断算法
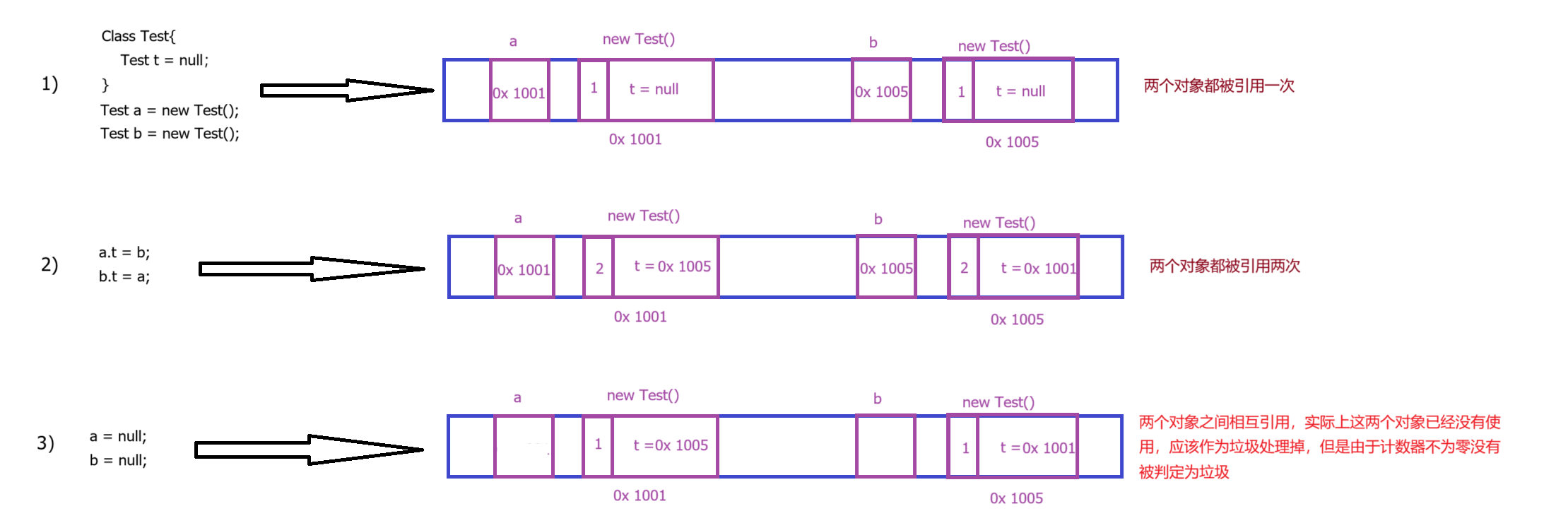
JVM中的垃圾回收,实际上是回收对象,以对象为单位,既然要回收垃圾,就需要先找到垃圾,相关算法主要有 1)引用计数算法 2)可达性分析算法
3.1.1 引用计数算法
算法思想:给对象增加一个引用计数器,每有一个地方引用,计数器+1,每有一个引用失效,计数器-1,只需要通过判断计数器中的值是否为0来判断对象为垃圾
JVM中并没有使用这种算法,主要是因为这个算法存在循环引用的问题:
3.1.2 可达性分析算法
可达性分析算法是JVM采取的死亡对象判断算法
算法思想:类似于遍历树/图,JVM会通过一系列称为“GC Root”的对象作为起点,不断向下遍历,遍历到的对象会被标记为可达,没有遍历到的对象会被标记为不可达,不可达的对象会被当作垃圾回收。
3.2 垃圾回收算法
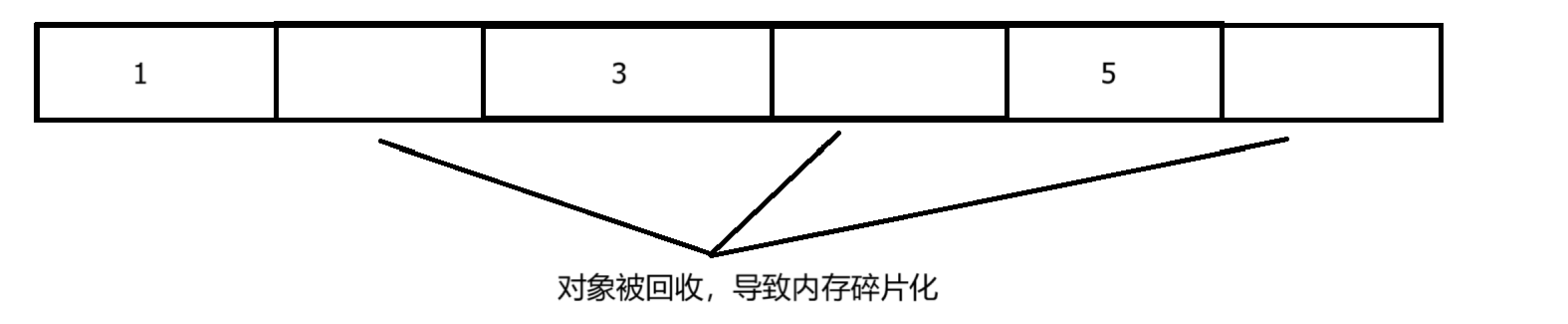
3.2.1 标记-清除算法
算法思想:算法分为“标记”和“清除”两个阶段,首先标记出所有待回收对象,标记完后统一回收所有被标记对象。
缺点:
(1)效率问题:标记和清除两个过程的效率都不高
(2)空间问题:会产生内存碎片问题,导致后续需要分配较大对象时不得不提前触发另一次垃圾收集。
3.2.2 复制算法
算法思想:将内存划分为两份,每次只使用其中一份,将不用回收的对象复制到另一份空间,再将这份空间全部释放。
缺点:
(1)空间利用率底
(2)如果不是垃圾的对象太多,复制成本很高
3.3.3 标记-整理算法
算法思想:标记出待回收对象后,将所有存活对象都向一端移动,然后直接释放端边界以外内存(和顺序表删除元素类似,存活对象移动过程中将待删除对象覆盖)
缺点:移动过程开销太大
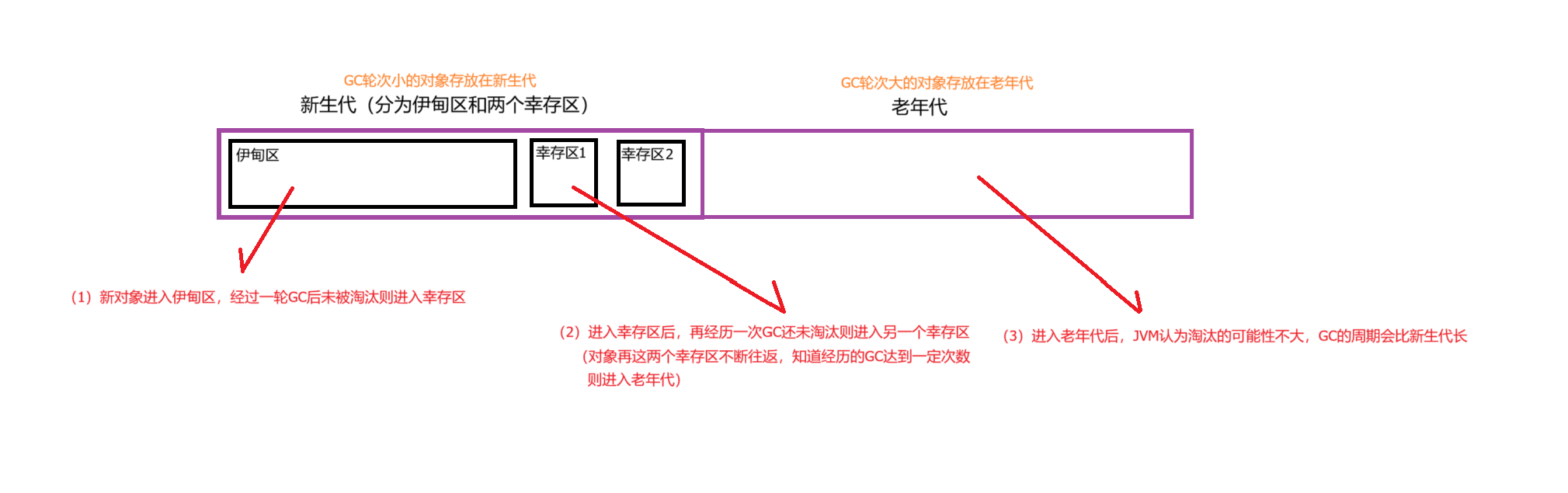
3.3.4 分代算法(JVM采取)
算法思想:将内存划分为两块,根据存活对象的周期不同(经历的GC次数)分为新生代和老年代,在新生代(Minor)中,每次垃圾回收都有大批对象死去,只有少量存活,因此我们采用复制算法;而老年代(Full)中对象存活率高、没有额外空间对它进行分配担保,就必须采用"标记-整理"算法,具体细节如下图:
优点:
(1)一般认为,新生代中的大部分对象都会快速消亡,使得每次复制开销可控
(2)老年代的对象大部分生命周期较长,使得整理的开销也可控