数据建模怎么落地?从概念、逻辑到物理模型,一文讲请!
目录
一、数据建模能解决什么问题?
1.没统一语言
2.没设计标准
3.没未来视角
二、数据建模的三层落地方案
1. 概念模型:先想清楚“我们要管哪些东西”
2. 逻辑模型:把“东西”拆成具体的“字段”
3. 物理模型:让数据能“落地”到数据库里
三、数据建模的常见误区
1.跳过概念模型,直接建表
2.逻辑模型只列字段,不写规则
3.物理模型完全照抄逻辑模型
四、做分析型数据,可以考虑维度建模
1.维度建模的核心思路
2.怎么建维度模型
3.维度建模的注意事项
总结
你有没有遇到过这些头疼事:
- 当你想做用户画像时,发现同一用户的手机号在三个系统里存着三种格式;
- 当你想分析产品销量时,各门店上报的数据里“产品名称”五花八门;
- 甚至有时候,同一个部门的同事,嘴里说的“活跃用户”根本不是一回事。
问题到底出在那里?
说到底,都是数据建模没做好,或者压根没做!
别小看数据建模,它是数据的地基。地基不稳,后面的数据分析、AI应用,都是白忙活一场。
今天,我们就来掰开揉碎,把数据建模从“高大上”的概念,讲到真正能落地的实操步骤——从概念模型、逻辑模型到物理模型,一步步教你搭建清晰、好用的数据!
一、数据建模能解决什么问题?
先问个实际的问题:
你们公司数据库里有多少张表?每张表里的字段都代表什么意思?
我敢说,很多公司没人能完全说清楚。
因为:
表名可能是“test_001”“newdata_v3”,字段名是“f1”“f2”。
这样一来:
就算是老员工,查数据前也得翻半天文档。
更麻烦的是这样的情况:
- 销售说的“客户”,可能包括还在跟进的潜在客户;
- 客服说的“客户”,只算已经成交的;
- 但系统里的“客户表”,可能把两者混在一起,区分全靠一个没说明的“状态”字段。
这些数据乱象背后,其实是三个核心问题没解决:
1.没统一语言
- 业务人员说的“用户活跃”,可能是指打开过APP;
- 技术人员理解的“活跃”,可能是指完成了下单。
没有数据建模来统一定义,双方沟通根本就不在一个频道上。
2.没设计标准
系统刚上线时,表结构可能还挺清晰。但业务一调整,谁都能去加个字段、改个类型。
于是:
时间一长,表结构就乱了。
3.没未来视角
为了赶项目上线,随便用个“序号”当主键。结果业务扩展后,发现不同地区的“序号”会重复。
说白了,数据建模就是给数据定规矩:
统一大家对数据的理解,明确数据该怎么存、怎么关联,还要考虑到未来可能的变化。
所以说:
它不是一次性的工作,而是让数据从混乱到有序的全过程。
二、数据建模的三层落地方案
数据建模不是拍脑袋就能搞定的,得一步一步来。从抽象的业务概念,到具体的数据结构,最后落到数据库里。这三层环环相扣,前面的没做好,后面的肯定出问题。
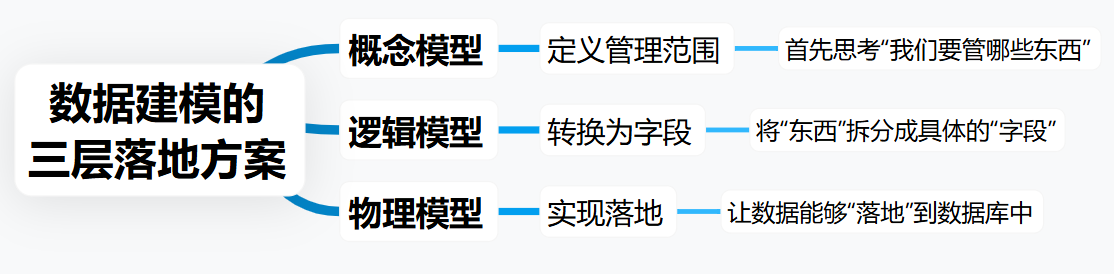
1. 概念模型:先想清楚“我们要管哪些东西”
概念模型是最顶层的设计,不用考虑技术细节,核心是:
把业务里的核心对象和它们之间的关系理清楚。
简单来说,就是回答:
我们的业务里有哪些关键角色、关键事物?它们之间有什么联系?
拿在线教育平台来说:
核心业务是“学生选课、上课,老师授课”,那概念模型就要明确这些对象:
- 学生(花钱买课的人)
- 老师(讲课的人)
- 课程(被购买的内容)
- 订单(购买课程的凭证)
- 班级(学生上课的组织形式)
然后梳理关系:
- 学生和订单:一个学生可以买多个订单,一个订单只属于一个学生;
- 订单和课程:一个订单可以包含多门课程,一门课程可以被多个订单包含;
- 课程和老师:一门课程可能由多个老师授课,一个老师可以讲多门课程;
- 班级和学生:一个班级有多个学生,一个学生可以加入多个班级。
具体怎么操作?
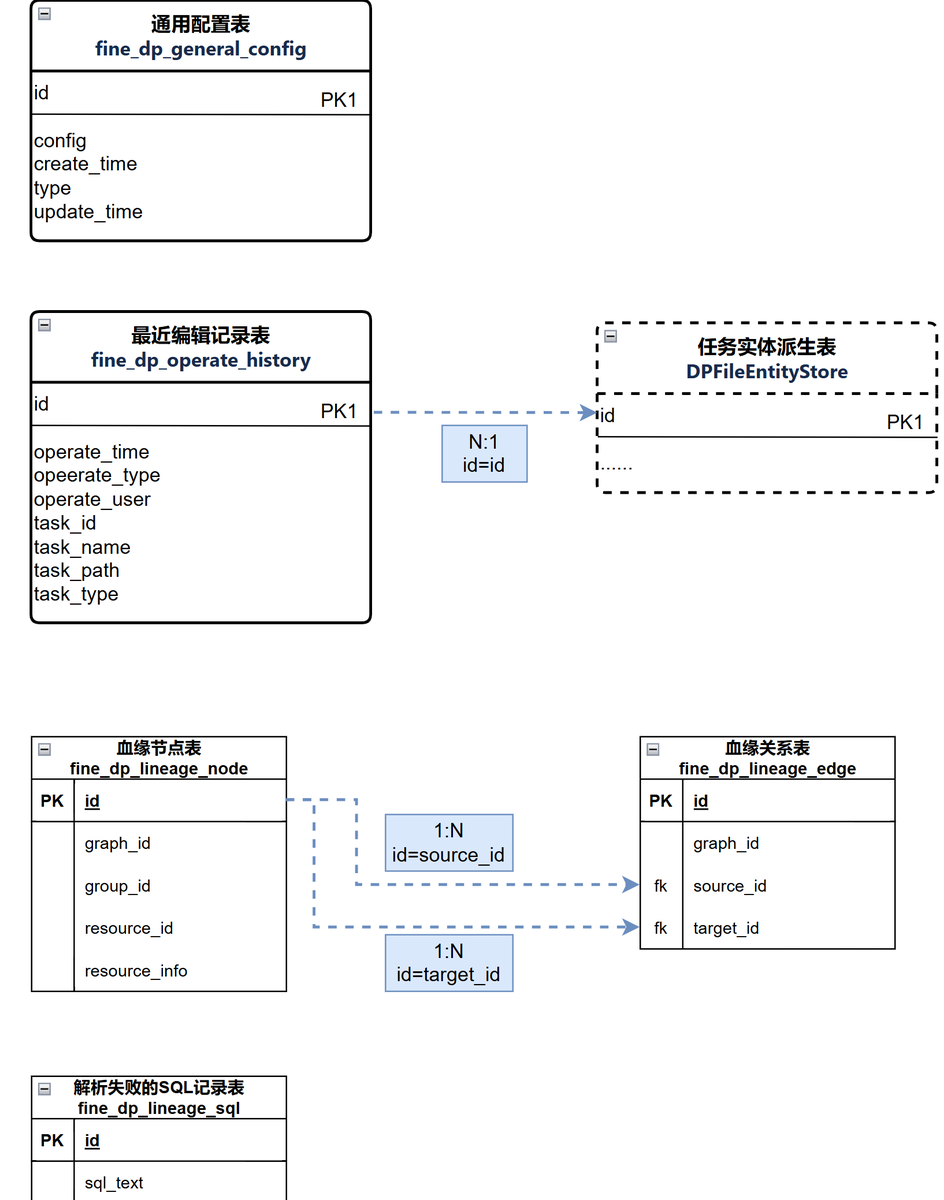
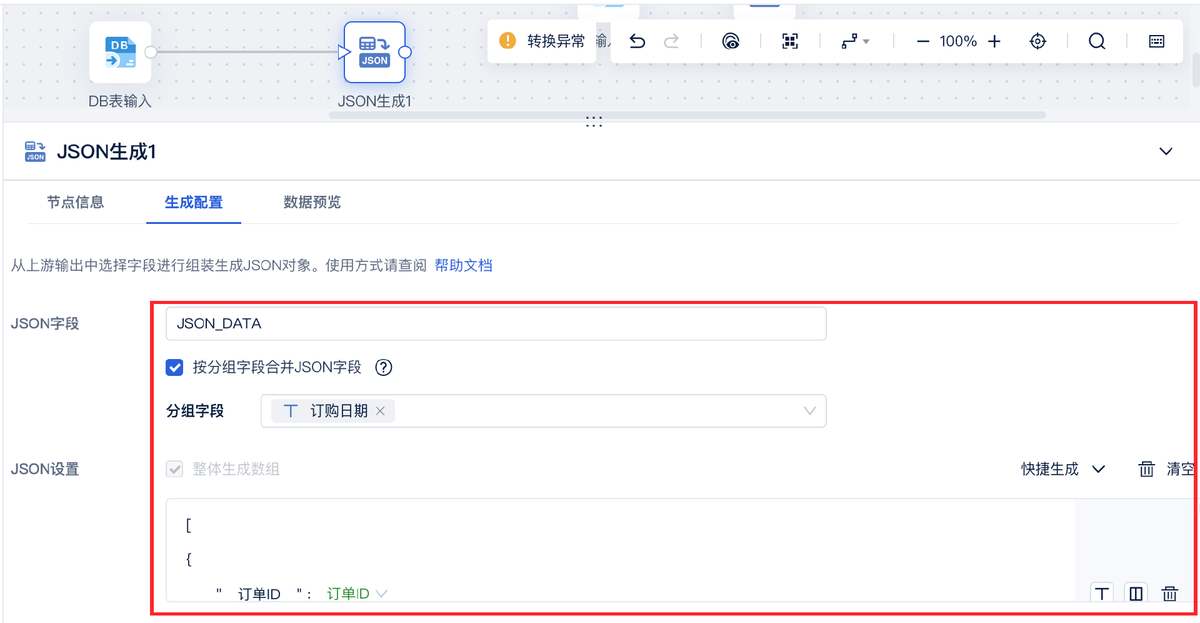
使用 API 输出,实现将 API 数据写入指定接口,将数据库或者其他形式的数据生成为 JSON 格式,以便进行数据交互。可以借助数据集成与治理一体化平台FineDataLink,使用 JSON 生成算子,生成 JSON 格式数据,满足复杂业务场景下的数据清洗、转换和同步等需求。
FineDataLink体验地址→免费试用FDL(复制到浏览器打开)
这一步不用管“订单编号用数字还是字母”“学生手机号存多长”,就是让业务、产品、技术所有人都达成共识:
我们的业务核心就是这些东西,它们之间就是这些关系。这一步做扎实了,后面就不容易跑偏。
2. 逻辑模型:把“东西”拆成具体的“字段”
概念模型确定了要管什么,逻辑模型就要细化:
- 每个对象具体有哪些属性?
- 哪些属性能唯一标识这个对象?
- 对象之间通过什么关联?
还是以在线教育平台为例,逻辑模型就要这么设计:
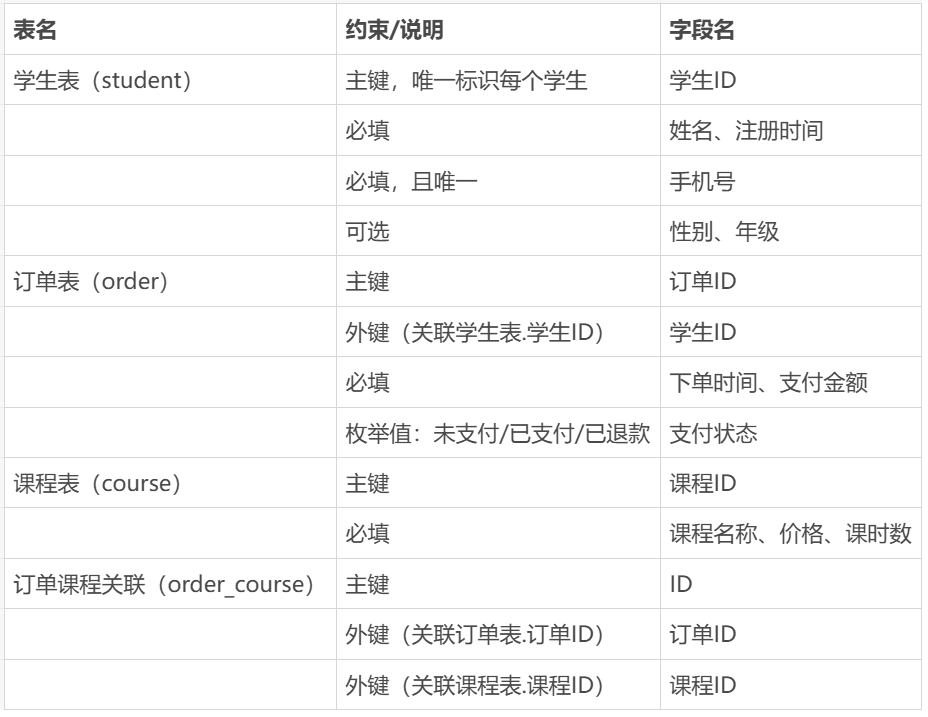
这里要明确很多规则,比如:
- 学生ID必须是唯一的
- 支付金额不能是负数
- 订单表的学生ID必须在学生表里存在
有了这些规则,数据才不会乱:
比如不会出现“支付金额是-100”这种明显错误,也不会出现“某个订单关联了不存在的学生”。
逻辑模型的作用,就是让大家清楚:
每个“东西”具体由哪些信息组成,这些信息要符合什么要求。
这样一来:
- 技术人员看了,就知道该怎么设计表;
- 业务人员看了,就知道系统里存了哪些数据,能用来做什么分析。
3. 物理模型:让数据能“落地”到数据库里
逻辑模型讲的是“应该怎么存”,物理模型就要考虑“实际怎么存”。
毕竟:
不同的数据库有不同的特性,数据量大了之后,存储和查询效率也得考虑。
比如订单表,在物理模型里就要这么设计:
- 字段类型:学生ID用CHAR(32)(固定长度,查询快),支付金额用DECIMAL(10,2)(精确到分,避免浮点误差),支付状态用TINYINT(用0、1、2分别代表未支付、已支付、已退款,节省空间);
- 索引:给“学生ID”“下单时间”建索引,因为经常需要查“某个学生的所有订单”“某段时间的订单”;
- 分区:如果订单数据量大,按“下单时间”分区,比如每个月一个分区,查“2023年10月的订单”时,就不用扫描全年的数据;
- 存储引擎:如果订单需要支持事务(比如支付和更新订单状态要同时成功或失败),就用InnoDB;如果是历史订单,只用来查询,不用频繁修改,就可以用MyISAM,查询更快。
物理模型是直接影响系统性能的:
所以这一步,必须结合具体的业务场景和数据库特性来做。
三、数据建模的常见误区
数据建模这件事,看着简单,实际做的时候很容易掉坑里。用过来人的经验告诉你,这几个误区一定要避开:
1.跳过概念模型,直接建表
很多人觉得“概念模型太虚,不如直接建表来得实在”。
结果呢?
业务说的“课程”包括直播课、录播课,技术一开始只建了一个“课程表”。
后来发现:
两者属性差异太大,不得不又建一个“直播课表”。
最后查询“所有课程”时:
必须关联两张表,还容易出错。
所以说:
概念模型看起来慢,但能帮你想清楚核心逻辑,避免后面反复改。
2.逻辑模型只列字段,不写规则
有人设计逻辑模型,就列个表名、字段名、类型,至于“这个字段能不能空”“两个字段之间有没有关联”完全不提。
结果实际用的时候:
字段里空值一大堆,或者出现“支付金额是负数”这种明显错误,数据根本没法用。
所以说:
逻辑模型一定要把规则写清楚,比如“手机号必须是11位数字”“订单状态变更时间不能早于下单时间”。
3.物理模型完全照抄逻辑模型
- 物理模型必须考虑实际的存储和查询需求,比如Hive里可以用STRING类型存ID,MySQL里可能用BIGINT更合适;
- 高频查询的字段一定要建索引,不常用的大字段可以考虑拆分。
四、做分析型数据,可以考虑维度建模
前面说的是通用的建模思路,如果你做的是数据分析相关的数据建模(比如数据仓库),那维度建模这个方法一定要了解。
它和ER模型不太一样,更侧重“怎么方便做分析”。
1.维度建模的核心思路
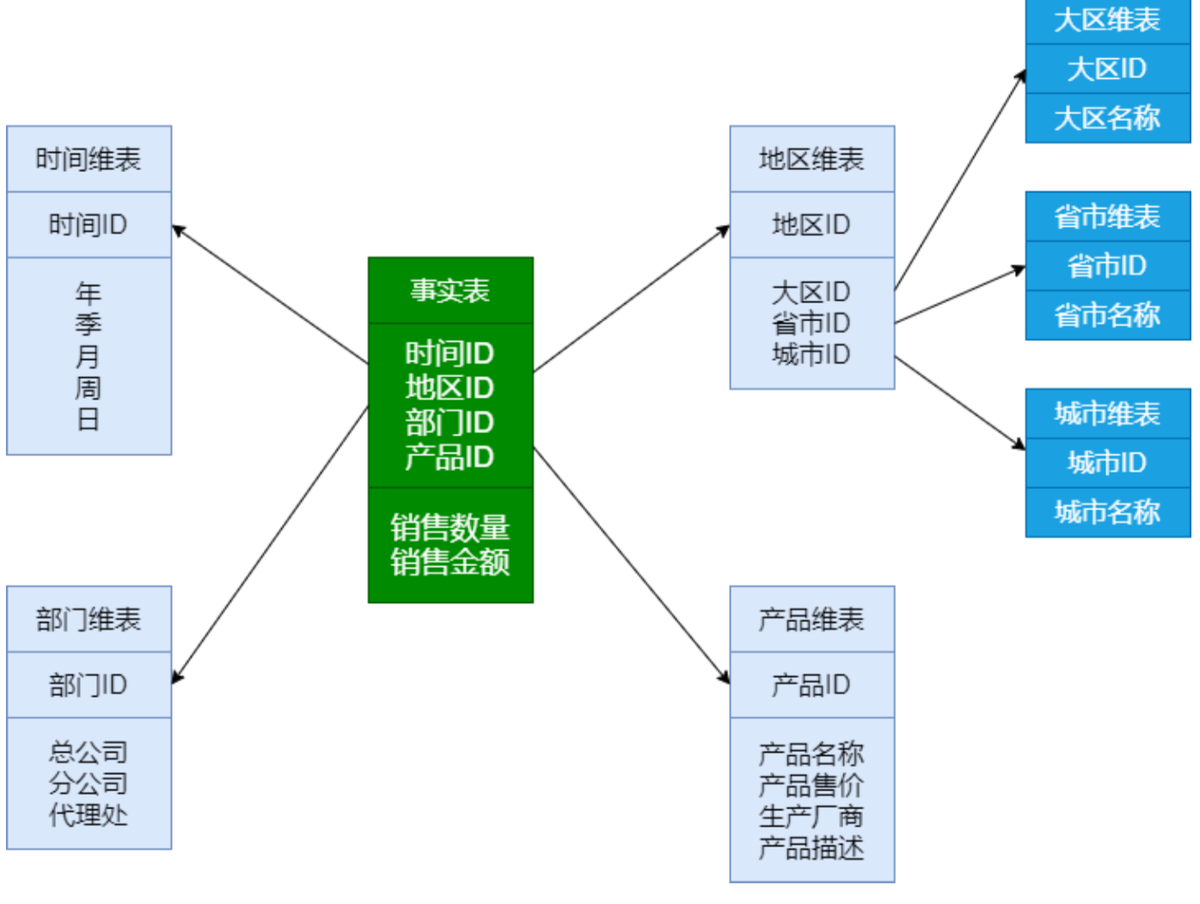
简单来说,维度建模就是围绕“业务过程”,把数据分成“事实”和“维度”两类:
- 事实:就是业务过程中产生的指标,比如“订单金额”“销售数量”;
- 维度:就是分析这些指标的角度,比如“时间”“地区”“用户类型”。
2.怎么建维度模型
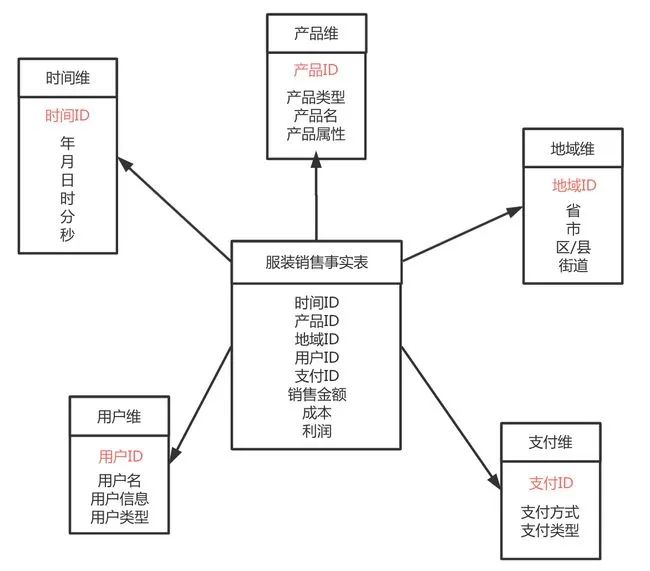
以分析“课程销售情况”为例,步骤大概是这样:
- 确定业务过程:这里就是“课程销售”这个过程;
- 确定粒度:就是事实表中一行数据代表什么。一般建议选最细的粒度,比如“每一笔订单中每一门课程的销售额”,这样既能查单门课程的销售,也能汇总成订单的总销售;
- 确定维度:就是从哪些角度分析,比如“时间维度”(年、月、日)、“用户维度”(用户等级、所在地区)、“课程维度”(课程类型、难度);
- 确定事实:就是要分析的指标,比如“销售金额”“销售数量”;
- 设计模型:最常用的是星型模型,就是一个事实表,关联多个维度表。比如“课程销售事实表”关联“时间维度表”“用户维度表”“课程维度表”。
3.维度建模的注意事项
- 维度表要属性多一点。比如“用户维度表”,可以包含用户ID、姓名、手机号、注册时间、所在地区、用户等级等,这样分析时不用再关联其他表;
- 事实表要尽量存“原子数据”,就是最细粒度的数据。比如存“每门课程的销售金额”,而不是“订单总金额”,这样可以灵活汇总;
- 维度表的属性要统一,比如“地区”统一用“省-市-区”的格式,“时间”统一用“YYYY-MM-DD”,避免混乱。
总结
数据建模这件事,急不来,是个慢功夫,但绝对值得投入。
我见过不少公司,一开始觉得“先跑起来再说,数据乱点没关系”,结果后面为了整理数据,花的时间比重新建模还多,还影响业务进展。
简单来说,数据建模就是让数据“有规矩、好理解、能复用”:
- 有了规矩,数据才不乱;
- 好理解,业务和技术才能顺畅配合;
- 能复用,后面做分析、做AI才能事半功倍。
所以,不管公司大小,抓紧把数据建模提上日程。一步一步来,先做概念模型,再做逻辑模型,最后落地成物理模型,踩过的坑记录下来,慢慢优化。时间长了,你会发现,数据真的能推动业务的增长。