系统学习算法:专题十五 哈希表
题目一:
算法原理:
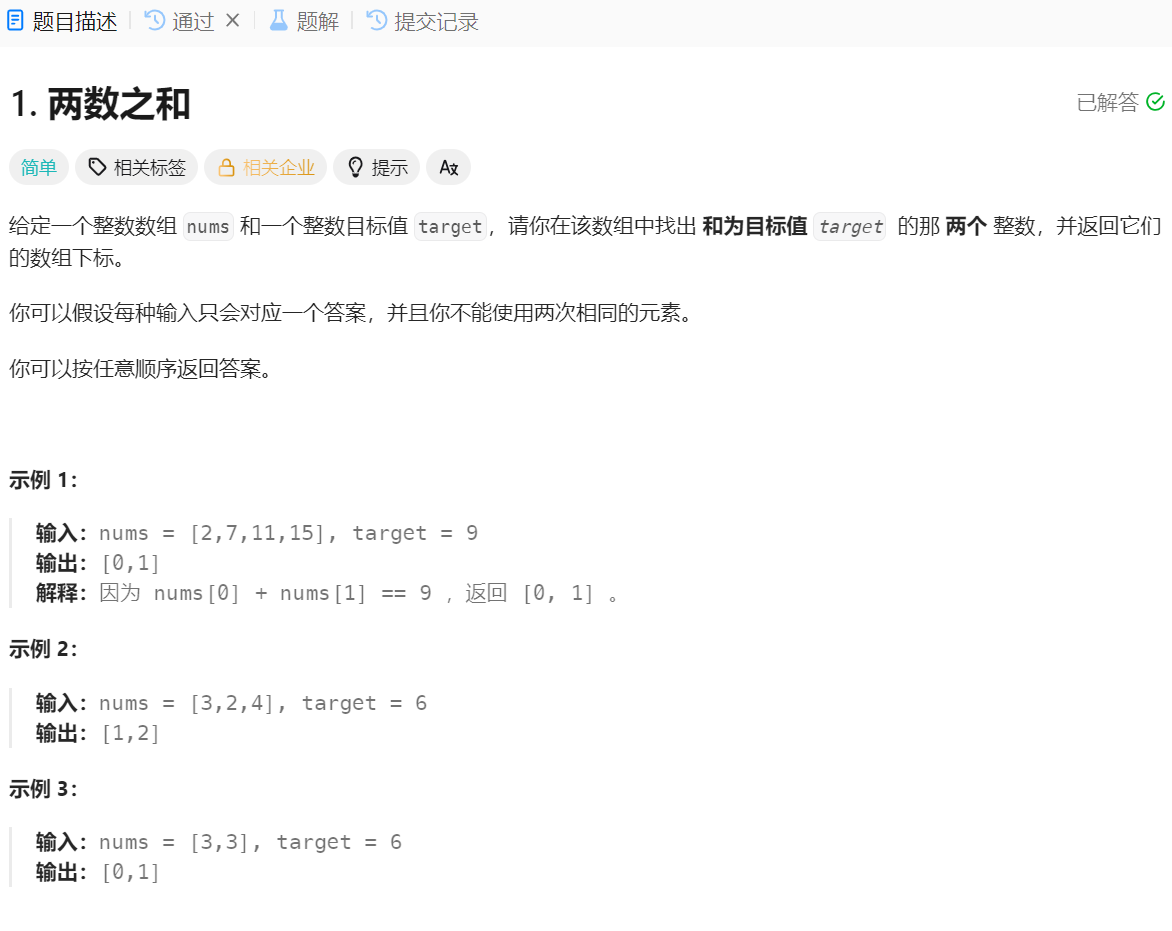
虽然是力扣的第一道题,且叫两数之和,但并不是求a+b=sum,而是找到两个数使得相加等于目标值,并返回那两个数的下标
第一想法肯定是暴力枚举,即枚举出数组中所有的两数之和,用两层for循环,第一层固定一个数,第二层去找固定的数后面的数字,如果和为目标值,则返回两层for循环此时的i,j值
这样完全可以解决问题,但时间复杂度为O(N^2)
接下来就是优化
优化之前我们再换个暴力的方法,也是两层for循环,第一层也是固定一个数,但第二层是去找固定的数前面的数字,此时要找的数字则是:目标值-固定数,如果找到了就返回两个数的下标
此时可以发现时间的消耗主要是找:“目标值-固定数”这个数,且是往前面找到,说明这些数之前已经遍历过,因此再重新往前遍历就效率很低了
所以要想快速找到之前遍历过的某个值,只需要用一个哈希表记录起来,后面再来找就能以
O(1)的时间复杂度完成,使得最终的时间复杂度为O(N),但与此同时空间复杂度为O(N)
哈希表典型的空间换时间
这时候大概率有疑问,为什么暴力那里要采用往前遍历这种逆向思想呢?
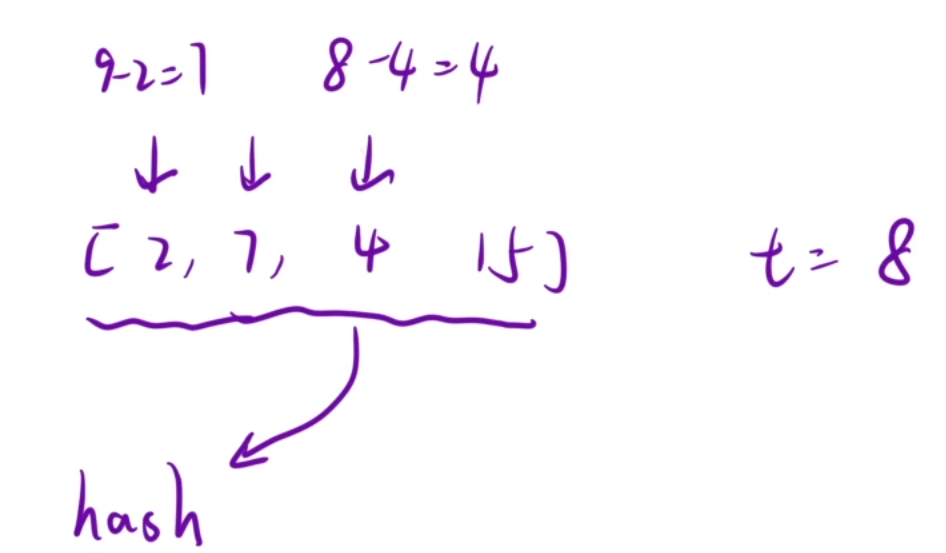
假设还是以固定一个数然后往后遍历的方法,那么此时因为后面的数都是未被遍历的,所以一开始就要将所有数都扔进哈希表中,此时就会出现自己找到自己的这种情况,比如目标值是8,然后固定到4的时候,去哈希表中找4发现找到是自己,题目又说了不能一个数重复使用,那么此时就又要去特判下标是否相等来解决这种情况,就比较复杂一点了。
而往前遍历的话,不需要一开始就遍历将全部数扔进哈希表,也不会出现找到自己的情况
代码:
class Solution {public int[] twoSum(int[] nums, int target) {//创建哈希表HashMap<Integer,Integer> map=new HashMap<>();//遍历数组for(int i=0;i<nums.length;i++){//目标值int find=target-nums[i];//如果之前出现过这个数if(map.getOrDefault(find,-1)!=-1){return new int[]{map.get(find),i};}else{//没有出现,则将该数扔进哈希表中map.put(nums[i],i);}}//照顾编译器return null;}
}题目二:
算法原理:
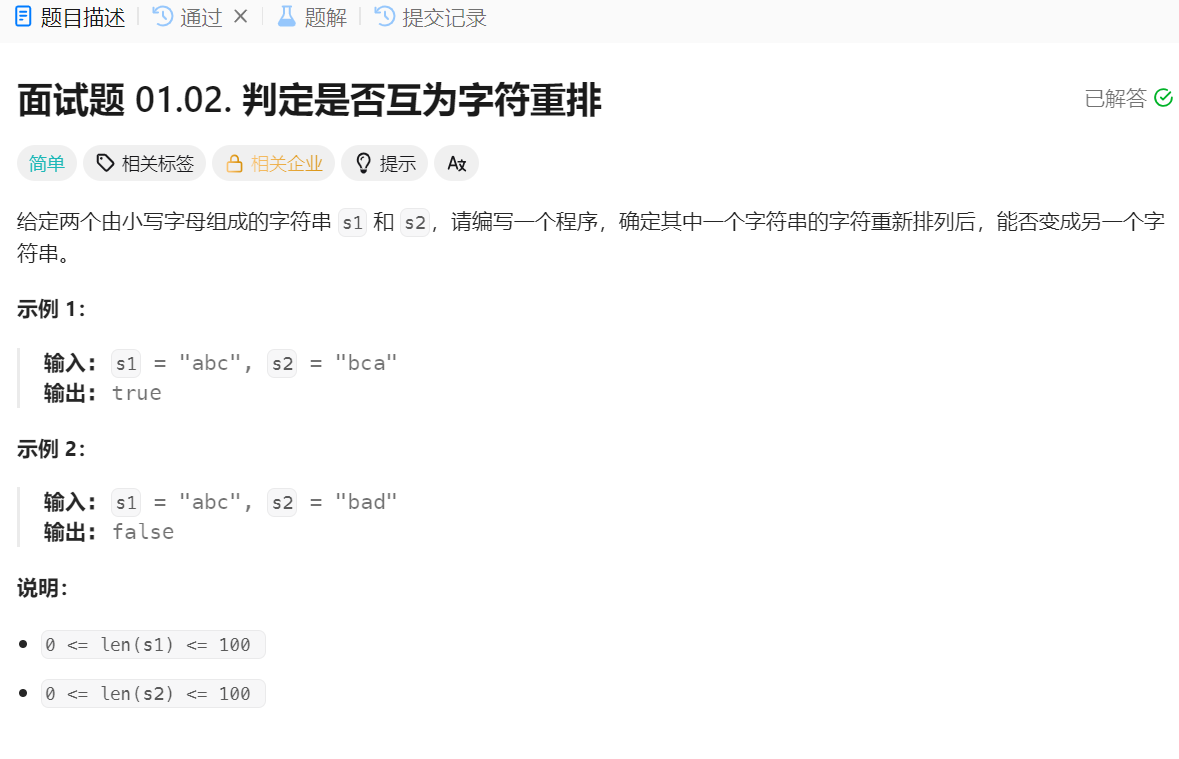
题意很简单,就是判断两个字符串是否能将一个字符串根据重排顺序变成另外一个字符串
首先还是暴力的解法,那就是将第一个字符串的所有全排列枚举出来,如果有其中一个全排列刚好等于第二个字符串,那么就说明互为字符重排
但是这个时间复杂度很高,字符串长度越长,时间复杂度就呈指数级增加
再想想,其实主要判断字符出现的个数是否相等就能知道是否互为字符重排了
那就是开两个哈希表,遍历两个字符串,将所有字符扔进去统计出现次数
最后再遍历一遍字符串,判断两个哈希表的值是否相等,不相等则说明不是互为字符重排的
同时,在一开始就可以判断如果连字符串长度都不相等,那么肯定不是互为字符重排的
遍历完,则说明所有字符的出现次数都是相等的,则返回true
代码1(哈希表):
class Solution {public boolean CheckPermutation(String s1, String s2) {int len1=s1.length(),len2=s2.length();//如果长度都不一样,肯定不是if(len1!=len2){return false;}//创建两个哈希表Map<Character,Integer> map=new HashMap<>();Map<Character,Integer> map1=new HashMap<>();//统计两个字符串的字符出现次数for(int i=0;i<len1;i++){map.put(s1.charAt(i),map.getOrDefault(s1.charAt(i),0)+1);map1.put(s2.charAt(i),map1.getOrDefault(s2.charAt(i),0)+1);}//判断两个哈希表的值是否相等for(int i=0;i<len2;i++){if(map.get(s2.charAt(i))!=map1.get(s2.charAt(i))){return false;}}//说明全部字符的出现次数一样return true;}
}又因为统计的是a-z的小写字符,那么就可以用数组模拟哈希表
同时还可以进行优化,只用一个哈希表就能够解决
代码2(数组模拟):
class Solution {public boolean CheckPermutation(String s1, String s2) {int len1=s1.length(),len2=s2.length();//如果长度都不一样,肯定不是if(len1!=len2){return false;}//用数组模拟哈希表int[] hash=new int[26];//统计第一个字符串中字符出现的次数for(int i=0;i<len1;i++){hash[s1.charAt(i)-'a']++;}//遍历第二个字符串中字符出现的次数for(int i=0;i<len2;i++){hash[s2.charAt(i)-'a']--;if(hash[s2.charAt(i)-'a']<0){return false;}}//说明所有字符出现次数相同return true;}
}题目三:
算法原理:
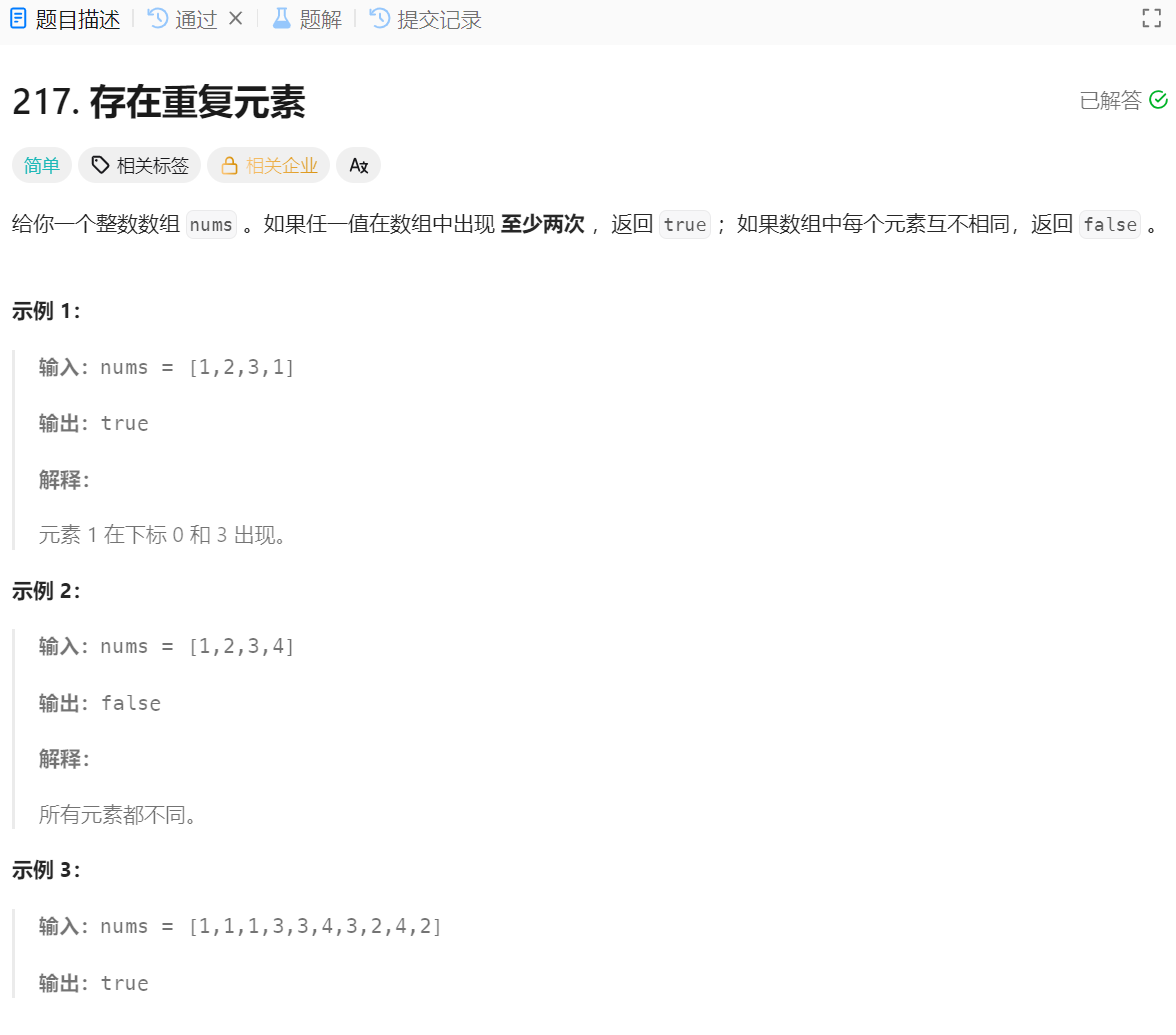
非常简单的题,全部扔进哈希表就行了,扔之前如果发现已经存在该关键字,就说明是重复元素,那么返回true ,如果全扔进去也没有返回true,那么就说明没有重复元素,返回false
这里用map或set都行,也可以用排序,通过比较相邻元素是否相等也可以解决
代码:
class Solution {public boolean containsDuplicate(int[] nums) {Map<Integer,Integer> map=new HashMap<>();//遍历数组for(int i=0;i<nums.length;i++){//如果存在该关键字if(map.containsKey(nums[i])){return true;}//没有出现过,扔进去map.put(nums[i],1);}//说明没有重复元素return false;}
}题目四:

算法原理:
题意也是很简单,就是判断当两个数相同时,这两个下标的绝对值是否小于等于k,如果是则返回true,如果整个数组都不符合,则返回false
也是用哈希表记录一下值和下标即可
唯一需要思考的就是,当出现相同数但不符合条件时,是否要覆盖
思考一下就知道,当然要覆盖,因为遍历是从前往后的,越早记录的,下标就离的越远,绝对值就越大,越不可能符合小于等于k这个条件,所以要覆盖
代码:
class Solution {public boolean containsNearbyDuplicate(int[] nums, int k) {Map<Integer,Integer> map=new HashMap<>();//从前往后遍历数组for(int i=0;i<nums.length;i++){//如果出现相同数if(map.containsKey(nums[i])){//求下标绝对值int x=i-map.get(nums[i]);//如果符合条件if(x<=k){return true;}}//覆盖map.put(nums[i],i);}//说明没有return false;}
}题目五:
算法原理:
这道题其实主要难的还是对语言容器的应用,思路都很简单,异位词可以通过哈希表判断字符出现次数,但这里换成最简单的排序来实现,异位词按照ASCII码值排完序后都是一样的,这样方便作为key值,然后value的类型可以直接用List<String>,往里面添加就行了,如果是第一次出现的key,那么就new ArrayList<>(),后面出现的直接加到这个容器里就行
最后又将value类型的容器取出来,再塞到新的List中返回即可
还是对编程语言里容器的各种方法的考察
代码:
class Solution {public List<List<String>> groupAnagrams(String[] strs) {Map<String,List<String>> map=new HashMap<>();for(String s:strs){//判断异位词char[] ch=s.toCharArray();Arrays.sort(ch);String key=new String(ch);//如果是第一次出现if(!map.containsKey(key)){map.put(key,new ArrayList<>());}//将原字符串加到容器中map.get(key).add(s);}//返回所有的异位词组合return new ArrayList<>(map.values());}
}总结:
哈希表好用且非常强大,要熟悉其常用的方法,如果key的范围有限,那么就可以考虑用数组模拟,比哈希表效率要更高些