循环神经网络——动手学深度学习7
环境:PyCharm + python3.8
👉【循环神经网络】(recurrent neural network,RNN)
RNN通过
- 引入状态变量存储过去的信息和当前的输入,从而可以确定当前的输出。
- 状态变量捕捉序列的时序依赖,是处理文本、时间序列等数据的基石,
- 但其梯度问题推动了更先进的架构(如LSTM、Transformer)的发展。
数据类型的差异与模型适配
- 表格数据:结构化数据,传统机器学习模型(如线性回归、决策树)可直接处理。
- 图像数据:具有空间局部性(像素位置敏感),需通过卷积神经网络(CNN)利用局部特征(如边缘、纹理)和层级抽象(从低级到高级特征)。
- 序列数据(如文本、视频、音频、时间序列):
- 顺序依赖性:数据元素间存在时序或逻辑关联(如单词顺序决定句子含义)。
- 非独立同分布(independently and identically distributed,i.i.d.):样本间存在依赖关系,传统模型(如MLP)无法捕捉。
- 需求:需模型能记忆历史信息并理解上下文。
CNN vs RNN的核心差异:
| 特性 | CNN | RNN |
|---|---|---|
| 数据类型 | 图像(空间数据) | 序列(时序/逻辑数据) |
| 核心操作 | 卷积(局部连接+权重共享) | 循环(状态传递+权重共享) |
| 信息利用 | 局部特征→全局特征 | 历史状态→当前输出 |
| 典型任务 | 分类、检测、分割 | 预测、生成、翻译 |
| 训练挑战 | 参数多、过拟合 | 梯度消失/爆炸、长期依赖 |
1. 序列模型
序列数据的动态性与模型挑战
1. 电影评分的时间依赖性
- 评分非静态:用户对电影的评价随时间、外部事件及个人体验变化,典型现象包括:
- 锚定效应:受他人评价或外部事件(如奥斯卡获奖)影响,导致评分系统性偏差(如评分提升0.5分以上)。
- 享乐适应:用户对连续优质内容产生适应性,导致对后续普通内容的评价降低(如“由奢入俭难”)。
- 季节性:内容与时间背景的匹配度影响评价(如圣诞电影在8月评分低)。
- 外部事件冲击:导演/演员丑闻或内容争议导致评分突变(如道德因素覆盖质量评价)。
- 小众效应:极端质量(如极差)导致电影被特定群体关注,形成非典型评分分布(如“烂片”文化)。
- 模型启示:需引入时间动力学(如时间衰减因子、事件嵌入)捕捉评分漂移,而非依赖静态用户-物品矩阵。
2. 用户行为的时空模式
- 习惯驱动的序列性:
- 周期性行为:用户活动与日常/周期事件强相关(如学生放学后使用社交媒体、股市开盘时交易软件活跃)。
- 场景化需求:工具类应用(如地图、外卖)使用频率受地理位置、时间(如工作日/周末)影响。
- 模型启示:需结合时间特征(小时/日/周粒度)与上下文特征(位置、事件)构建混合模型(如时序+图神经网络)。
3. 预测任务的难度差异
- 外推法(Extrapolation) vs 内插法(Interpolation):
- 外推法:预测未来或未知范围数据(如明日股价),需模型理解长期趋势与突变(如政策、黑天鹅事件)。
- 内插法:在已知范围内估计(如填充缺失评分),可依赖局部模式(如用户偏好相似性)。
- 挑战:外推法需处理不确定性与非平稳性(如数据分布随时间变化),传统模型(如ARIMA)易失效。
4. 序列的连续性与语义敏感性
- 顺序决定意义:
- 文本/语音:词序颠倒导致语义完全改变(如“狗咬人” vs “人咬狗”)。
- 视频/音乐:帧/音符顺序破坏叙事或旋律(如电影剪辑错乱)。
- 模型要求:需捕捉局部依赖(如N-gram)与全局结构(如注意力机制),避免独立假设(如词袋模型失效)。
5. 自然现象的时空相关性
- 地震序列:
- 余震模式:大地震后余震强度更高、时间/空间更集中(如“主震-余震”序列符合幂律分布)。
- 预测难点:需联合建模时间衰减与空间传播(如ETAS模型)。
- 模型启示:需引入时空图神经网络(STGNN)或点过程模型(如霍克斯过程)捕捉事件间依赖。
6. 人类互动的连续性
- 社交媒体动态:
- 争吵/辩论演化:用户回复形成树状结构,情绪随时间累积(如愤怒升级、冷静消退)。
- 信息传播:谣言与事实的扩散速度差异体现序列影响力(如转发链分析)。
- 模型要求:需结合文本内容与交互时序(如RNN处理对话历史)或图结构(如传播路径建模)。
7. 序列数据的共性挑战与模型方向
挑战 典型场景 模型需求 非平稳性 电影评分、股价 时间自适应权重、在线学习 长程依赖 文本生成、用户行为链 注意力机制、记忆网络 高维稀疏性 用户-物品交互矩阵 嵌入降维、图嵌入 多模态融合 视频评论、社交媒体帖子 跨模态注意力、联合编码 实时性要求 金融交易、地震预警 流式计算、轻量化模型(如TinyML) 8. 关键结论
- 序列数据是动态系统:其统计特性(如均值、方差)随时间变化,需放弃i.i.d.假设。
- 上下文即特征:时间、空间、社交关系等元数据是序列建模的核心输入。
- 从预测到解释:现代模型(如Transformer)需平衡预测性能与可解释性(如注意力权重分析)。
1.1. 统计工具
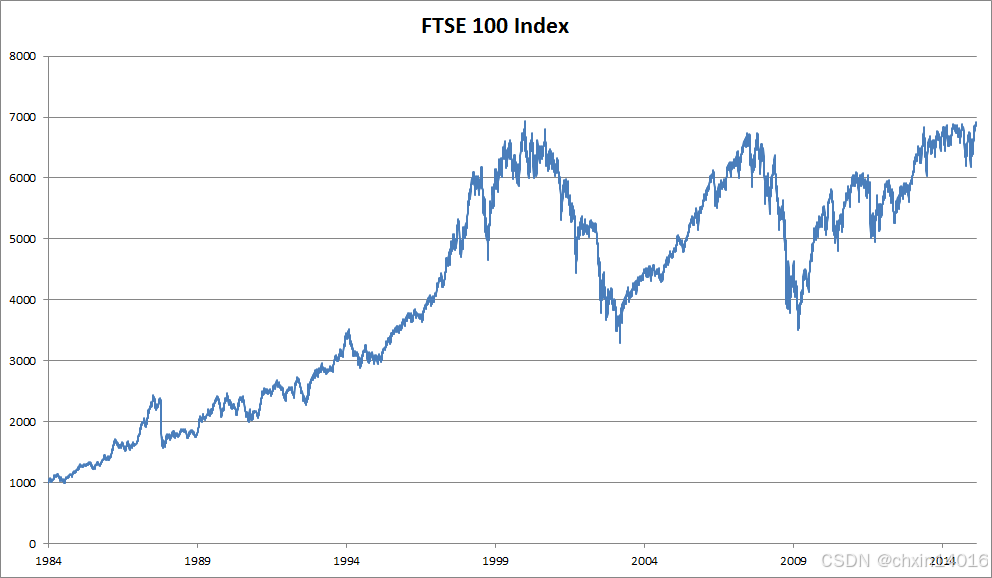
处理序列数据需要统计工具和新的深度神经网络架构。 为了简单起见,以 图8.1.1所示的股票价格(富时100指数)为例。
- 其中,
表示价格,即在时间步(time step)
时,观察到的价格
- 注意,
对于本文中的序列通常是离散的,并在整数或其子集上变化。
- 假设一个交易员想在
![]()
- P(A∣B):条件概率分布,表示“在给定某些条件B下,某事件A发生的概率”
- 条件分布【B已发生的条件下,A发生的概率】
:
当前数据点 为条件的概率分布中采样得到的。即:
“当前状态依赖于过去所有状态的联合作用”
1.1.1. 自回归模型
核心问题:输入数据的动态性
要实现这个预测,交易员可以使用回归模型, 例如在(线性回归实现 & softmax回归实现—— 动手学深度学习3.2~3.7_自己动手写线性回归-CSDN博客中的 线性回归的简洁实现)中训练的模型。
但序列预测任务中,有个主要问题:(输入数据的动态性)
- 输入数据的数量,输入
本身因
- 即 输入数据的长度(历史观测窗口)会随着遇到的数据量的增加而增加 (随时间动态变化)。
- 计算不可行性:直接使用全历史序列(如所有历史股价)作为输入,参数数量随数据量指数增长。
- 模型训练困难:深度网络需要固定尺寸的输入,而动态长度破坏这一前提。
- 因此需要一个近似方法来使这个计算变得容易处理。
两种主流解决策略
本章后面的大部分内容将围绕着如何有效估计 展开。 简单地说,它归结为以下两种主流解决策略:
策略一:自回归模型(autoregressive models)
- 假设在现实情况下长序列
的时间跨度即可, 即 使用观测序列
。当下获得的最直接的好处就是参数数量恒定, 至少在
时如此,这样即可训练深度网络。 这种模型是对自己执行回归。
- 核心思想:假设长序列依赖不必要,仅使用固定长度的历史窗口(如最近 k 个时间步)作为输入。
- 关键优势:
- 参数恒定:输入尺寸固定为 k,模型复杂度不随数据增长。
- 可训练性:可直接应用深度网络(如RNN、Transformer)处理定长输入。
- 典型应用:
- 股价预测:用过去30天的价格预测下一天价格。
- 语言模型:用前 n 个词预测下一个词(如GPT的滑动窗口)。
- 局限性:
- 信息丢失:若长程依赖关键(如经济周期对股价的影响),固定窗口会截断有用信号。
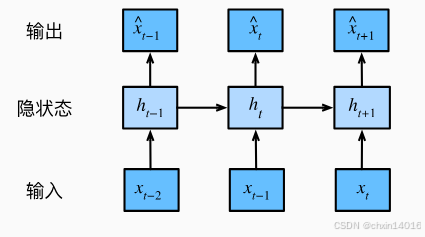
策略二:隐变量自回归模型(latent autoregressive models)。
- 如 图8.1.2所示, 是保留一些对过去观测的总结
, 并同时更新预测
和总结
估计
更新的模型。 由于
- 核心思想:
引入隐状态(latent state) - 数学表达:
- 预测更新:
- 隐状态更新:
(其中 f 和 g 为可学习函数,如LSTM的细胞状态更新)
- 预测更新:
- 关键优势:
- 动态信息压缩:隐状态
- 处理长程依赖:通过隐状态的递归更新传递长期信息(如RNN的隐藏层)。
- 动态信息压缩:隐状态
- 典型应用:
- 时间序列:LSTM/GRU预测气温、交易量。
- 强化学习:状态-动作值函数依赖隐历史(如DQN)。
- 挑战:
- 隐状态可解释性:黑盒更新可能导致调试困难。
- 训练复杂性:需通过BPTT(随时间反向传播)优化,计算成本高。
训练数据生成方法
以上两种情况都有一个显而易见的问题:如何生成训练数据?
- 一个经典方法是使用历史观测来预测下一个未来观测。
- (通用范式****:历史观测 → 预测未来观测)
- 滑动窗口法:用
预测
,滚动生成训练样本(如时间序列交叉验证)。
假设基础:
- 序列动力学静止性(Stationarity):
- 虽然特定值可能会改变, 但是序列本身的动力学不会改变。
- 即 数据生成机制(如市场规律)不变,仅具体值变化。
- 合理性:新动力学需新数据,无法从历史中预测(如政策突变影响股价)。
统计学家称不变的动力学为静止的(stationary)。 因此,整个序列的估计值都将通过以下的方式获得:
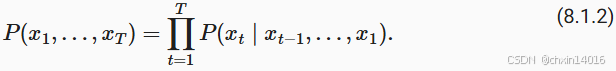
注意:(离散数据适配)
- 若
为离散对象(如单词),而不是连续的数字,则上述的考虑仍然有效。
- 差别在于,离散对象 需替换回归模型为分类器(如Softmax输出概率分布)来估计
。
策略对比与选择指南
| 维度 | 自回归模型 | 隐变量自回归模型 |
|---|---|---|
| 输入长度 | 固定窗口 k | 动态压缩至隐状态 ht |
| 信息保留 | 依赖窗口选择,可能丢失长程信号 | 通过递归更新保留长期依赖 |
| 计算效率 | 高(矩阵运算固定尺寸) | 低(需BPTT,隐状态更新复杂) |
| 适用场景 | 短程依赖任务(如语音识别片段) | 长程依赖任务(如视频剧情预测) |
| 典型模型 | CNN、Transformer(局部注意力) | RNN、LSTM、GRU、Transformer-XL |
1.1.2. 马尔可夫模型
回想一下,在自回归模型的近似法中, 使用 而不是
来估计
。 只要这种是近似精确的,就说序列满足马尔可夫条件(Markov condition)。 特别是,如果
,得到一个 一阶马尔可夫模型(first-order Markov model),
由下式给出:
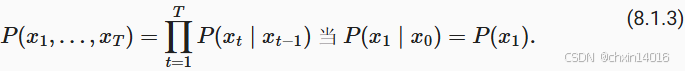
当假设 仅是离散值时,这样的模型特别棒, 因为在这种情况下,使用动态规划可以沿着马尔可夫链精确地计算结果。 例如,我们可以高效地计算
:
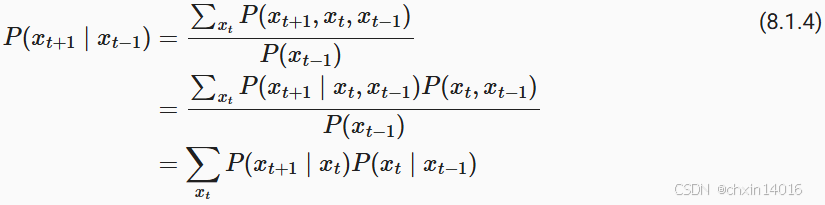
利用这一事实,我们只需要考虑过去观察中的一个非常短的历史: 。 隐马尔可夫模型中的动态规划超出了本节的范围 (我们将在 9.4节双向循环神经网络再次遇到), 而动态规划这些计算工具已经在控制算法和强化学习算法广泛使用。
1.1.3. 因果关系
原则上,将 倒序展开也没什么问题。毕竟,基于条件概率公式,总是可以写出:
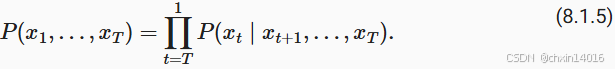
- 基于马尔可夫模型,可得到 反向条件概率分布。
- 然而,许多情况下,数据存在时间上的前进方向。未来的事件不能影响过去。
- 因此,若改变
- 因此,解释
应该比解释
更容易。
- 例如,在某些情况下,对于某些可加性噪声
,显然可以找到
(能找到顺着时间方向的因果关系), 而反之则不行 (Hoyer et al., 2009)。而这个向前推进的方向恰好也是我们通常感兴趣的方向。
- 彼得斯等人 (Peters et al., 2017) 对该主题的更多内容做了详尽的解释,而上述讨论只是其中的冰山一角。
1.2. 训练
开始实践:
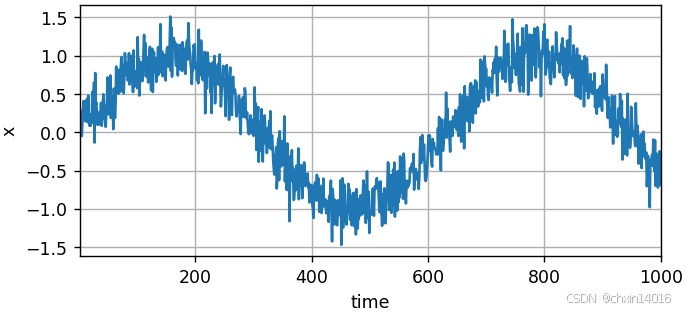
1)首先生成一些数据,并可视化:
- 使用正弦函数和一些可加性噪声来生成序列数据,时间步为 1,2, ...,1000 。
import torch
from torch import nn
import common# 1. 数据生成及可视化
# 生成含噪声的周期性时间序列数据(正弦波+噪声)
T = 1000 # 总共产生1000个点
time = torch.arange(1, T + 1, dtype=torch.float32) # 时间步 [1, 2, ..., 1000]
# (T,) 是表示张量形状(shape)的元组,用于指定生成的高斯噪声(正态分布)的维度(指定生成一维张量,长度为T)
x = torch.sin(0.01 * time) + torch.normal(0, 0.2, (T,)) # 生成正弦信号 + 高斯噪声
print(f"x的形状:{x.shape}")
common.plot(time, [x], 'time', 'x', xlim=[1, 1000], figsize=(6, 3)) # 绘制时间序列![]()
2)将序列转换为 模型的特征-标签(feature-label)对(构造特征与标签)。
- 基于嵌入维度,将数据映射为数据对
和
。
- 这比我们提供的数据样本少了
- 解决办法1:若拥有足够长的序列就丢弃这几项;
- 解决办法2:用零填充序列。
用过去4个时间步预测下一个时间步,即:
- 标签为当前的值,其对应有4个特征,分别是他往前4个时间步的值。
- 最开始的4个时间步的值由于缺少特征或没有特征,则被丢弃或用0填充确实特征。
这里的代码选择将前τ项丢弃,即 前4项丢弃。
# 2. 构造特征与标签
# 将时间序列转换为监督学习问题(用前4个点预测第5个点
tau = 4 # 用过去4个时间步预测下一个时间步
features = torch.zeros((T - tau, tau)) # 特征矩阵形状: (996, 4)(总共996个有效样本,每个样本对应4个特征)
for i in range(tau):features[:, i] = x[i: T - tau + i] # 滑动窗口填充特征
labels = x[tau:].reshape((-1, 1)) # 标签形状: (996, 1) (前4项丢弃)3)创建数据迭代器,支持批量训练
这里仅使用前600个“特征-标签”对进行训练:
# 3. 数据加载器
# 创建数据迭代器,支持批量训练
batch_size, n_train = 16, 600 # 批量大小16,训练集600样本
# 将前n_train个样本用于训练
train_iter = common.load_array((features[:n_train], labels[:n_train]),batch_size, is_train=True) # 创建数据迭代器,支持批量训练4)网络初始化:
这里训练模型使用的架构相当简单:
- 一个拥有两个全连接层的多层感知机,
- ReLU激活函数和平方损失。
# 4. 网络初始化
# 初始化网络权重的函数
def init_weights(m):if type(m) == nn.Linear:nn.init.xavier_uniform_(m.weight) # Xavier初始化权重# 定义一个简单的多层感知机(MLP)
def get_net():net = nn.Sequential(nn.Linear(4, 10), # 输入层(4) → 隐藏层(10)nn.ReLU(), # 激活函数nn.Linear(10, 1)) # 隐藏层(10) → 输出层(1)net.apply(init_weights) # 应用初始化return net# 平方损失。注意:MSELoss计算平方误差时不带系数1/2
# reduction='none' 返回每个样本的损失,后续需手动 .sum() 或 .mean()
loss = nn.MSELoss(reduction='none') # 均方误差损失,不自动求和/平均现在准备训练模型。实现下面的训练代码的方式与前面几节 (如线性回归实现 & softmax回归实现—— 动手学深度学习3.2~3.7_自己动手写线性回归-CSDN博客中的 线性回归的简洁实现) 中的循环训练基本相同。
# 对模型进行训练和测试
def evaluate_loss(net, data_iter, loss): #@save"""评估给定数据集上模型的损失"""metric = common.Accumulator(2) # 损失的总和,样本数量for X, y in data_iter:out = net(X) # 模型预测输出结果y = y.reshape(out.shape) # 将实际标签y的形状调整为与模型输出out一致l = loss(out, y) # 模型输出out与实际标签y之间的损失metric.add(l.sum(), l.numel()) # 将损失总和 和 样本总数 累加到metric中return metric[0] / metric[1] # 损失总和/预测总数,即平均损失def train(net, train_iter, loss, epochs, lr):trainer = torch.optim.Adam(net.parameters(), lr) # Adam优化器for epoch in range(epochs):for X, y in train_iter:trainer.zero_grad() # 梯度清零l = loss(net(X), y) # 计算损失(形状[batch_size, 1])l.sum().backward() # 反向传播(对所有样本损失求和)trainer.step() # 更新参数# 打印训练损失(假设evaluate_loss是自定义函数)print(f'epoch {epoch + 1}, 'f'loss: {evaluate_loss(net, train_iter, loss):f}')net = get_net() # 初始化网络
train(net, train_iter, loss, 5, 0.01) # 训练5个epoch,学习率0.01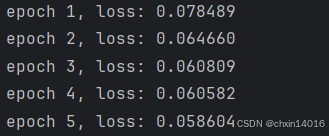
【此处开始往后未整理】1.3. 预测
由于训练损失很小,因此期望模型能有很好的工作效果。让我们看看这在实践中意味着什么。
首先检查模型预测下一个时间步的能力,也就是 单步预测(one-step-ahead prediction)。
- 单步预测:模型预测下一个时间步的能力。
# 单步预测:模型预测下一时间步的能力
onestep_preds = net(features)
common.plot([time, time[tau:]],[x.detach().numpy(), onestep_preds.detach().numpy()], 'time','x', legend=['data', '1-step preds'], xlim=[1, 1000],figsize=(6, 3))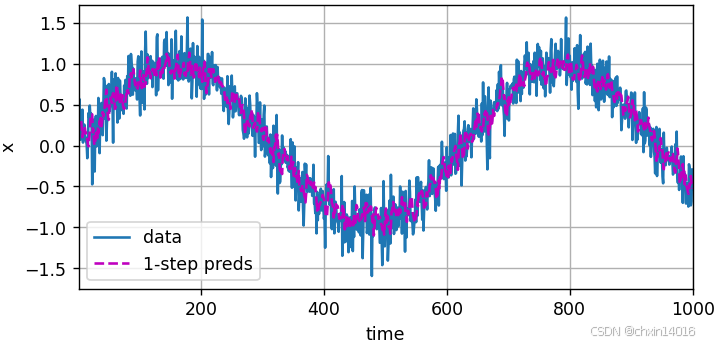
如图所示,单步预测效果不错 即使这些预测的时间步超过了 600+4(n_train + tau), 其结果看起来仍然是可信的。然而有一个小问题:若数据观察序列的时间步只到604,我们需要一步一步地向前迈进:

通常,对于直到 的观测序列,其在时间步
处的预测输出
称为 k步预测(k-step-ahead-prediction)。由于观察已经到了
,它的步预测是
。 换句话说,我们必须使用我们自己的预测(而不是原始数据)来进行多步预测。 下面看看效果:
- 简单的 K步预测:使用预测 来进行后面的K步预测。(递归预测)
- 是严格的递归预测,每个新预测都基于之前的预测。
- 潜在问题:递归预测的误差会累积,因为每个预测都基于之前的预测。
# 简单的K步预测:使用预测 来进行K步预测(递归预测)
# 是严格的递归预测,每个新预测都基于之前的预测
# 潜在问题:递归预测的误差会累积,因为每个预测都基于之前的预测
multistep_preds = torch.zeros(T) # 初始化预测结果张量
multistep_preds[: n_train + tau] = x[: n_train + tau] # 用真实值填充前面已知的真实值
for i in range(n_train + tau, T): # 递归预测# 使用前tau个预测值作为输入,预测下一个值multistep_preds[i] = net(multistep_preds[i - tau:i].reshape((1, -1)))common.plot([time, time[tau:], time[n_train + tau:]],[x.detach().numpy(), onestep_preds.detach().numpy(),multistep_preds[n_train + tau:].detach().numpy()], 'time','x', legend=['data', '1-step preds', 'multistep preds'],xlim=[1, 1000], figsize=(6, 3))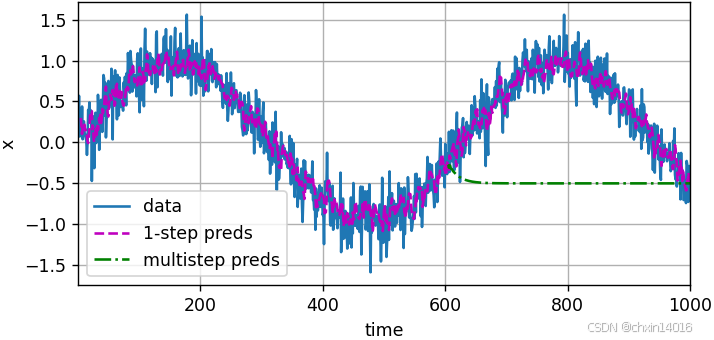
如上面的例子所示,绿线的预测显然并不理想。 经过几个预测步骤之后,预测的结果很快就会衰减到一个常数。算法效果这么差是由于错误的累积:
- 假设在步骤1之后,我们积累了一些错误
。
- 于是,步骤2的输入被扰动了
,结果积累的误差是依照次序的
,其中c为某个常数,后面的预测误差依此类推。
- 因此误差可能会相当快地偏离真实的观测结果。
例如,未来24小时的天气预报往往相当准确, 但超过这一点,精度就会迅速下降。本章及后续章节中会讨论如何改进这一点。
基于 k= 1, 4, 16, 64,通过对整个序列预测的计算,让我们更仔细地看一下k步预测的困难:
- 多步预测:同时获得多个未来时间步的预测(序列预测)
- 是序列预测,可以同时获得多个未来时间步的预测(虽然这些中间预测也基于之前的预测)。
- 潜在问题:虽然能一次预测多个步长,但长期预测仍然依赖中间预测结果。
# 多步预测(序列预测)
# 是序列预测,可以同时获得多个未来时间步的预测(虽然这些中间预测也基于之前的预测)
# 潜在问题:虽然能一次预测多个步长,但长期预测仍然依赖中间预测结果
max_steps = 64 # 最大预测步数# 初始化特征张量,(要预测的样本数,特征数),其中
# 前 tau 列:存储真实历史数据(作为输入)
# 后 max_steps 列:存储模型预测的未来值
# T-tau-max_steps+1是可计算的时间窗口数量,特征数(tau列真实数据 + max_steps列预测数据)
features = torch.zeros((T - tau - max_steps + 1, tau + max_steps))# 前tau列用真实值填充
# 列i(i<tau)是来自x的观测(实际真实值),其时间步从(i)到(i+T-tau-max_steps+1)
print(f"真实值填充:{x[i: i + T - tau - max_steps + 1].shape}")
for i in range(tau):features[:, i] = x[i: i + T - tau - max_steps + 1]# 对于 i=0,features[:, 0] = x[0 : 0 + 927](即 x[0] 到 x[926])# 对于 i=1,features[:, 1] = x[1 : 1 + 927](即 x[1] 到 x[927])# ...# 对于 i=9,features[:, 9] = x[9 : 9 + 927](即 x[9] 到 x[935])# 后max_steps列用模型预测填充
# 列i(i>=tau)是来自(i-tau+1)步的预测,其时间步从(i)到(i+T-tau-max_steps+1)
for i in range(tau, tau + max_steps):features[:, i] = net(features[:, i - tau:i]).reshape(-1) # .reshape(-1)展平为一维向量steps = (1, 4, 16, 64) # 要展示的预测步数
common.plot([time[tau + i - 1: T - max_steps + i] for i in steps],[features[:, (tau + i - 1)].detach().numpy() for i in steps], 'time', 'x',legend=[f'{i}-step preds' for i in steps], xlim=[5, 1000],figsize=(6, 3))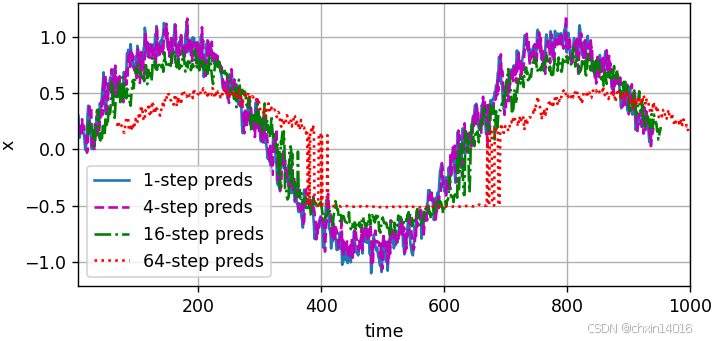
- 上例清楚地说明了当试图预测更远的未来时,预测的质量会急速下降。
- 虽然“步预测”看起来仍然不错,但超过这个跨度的任何预测几乎都是无用的
1.4. 小结
内插法和外推法在实践的难度上差别很大。因此,对于所拥有的序列数据,训练时要尊重其时间顺序,即最好不要基于未来的数据进行训练。
内插法:在现有观测值之间进行估计
外推法:对超出已知观测范围进行预测
序列模型的估计需要专门的统计工具,两种较流行的选择是
自回归模型 和
隐变量自回归模型。
对于时间是向前推进的因果模型,正向估计通常比反向估计更容易。
对于直到时间步的观测序列,其在时间步的预测输出是“步预测”。随着对预测时间值的增加,会造成误差的快速累积和预测质量的极速下降。
2. 文本预处理
- 对于序列数据处理问题,数据存在多种形式,文本是最常见例子之一。
- 例如,一篇文章可以被简单地看作一串单词序列,甚至是一串字符序列。
文本的常见预处理步骤 通常包括:
- 将文本作为字符串加载到内存中。
- 将字符串拆分为词元(如单词和字符)。
- 建立一个词表,将拆分的词元映射到数字索引。
- 将文本转换为数字索引序列,方便模型操作。
import collections
import re
from d2l import torch as d2l2.1. 读取数据集
首先,从H.G.Well的时光机器中加载文本。
- 这是一个相当小的语料库,只有30000多个单词,但足够我们小试牛刀。
- 而现实中的文档集合可能会包含数十亿个单词。
下面的函数:
- 将数据集读取到由多条文本行组成的列表中,
- 其中每条文本行都是一个字符串。
- 这里忽略了标点符号和字母大写。
#@save
d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt','090b5e7e70c295757f55df93cb0a180b9691891a')def read_time_machine(): #@save"""将时间机器数据集加载到文本行的列表中"""with open(d2l.download('time_machine'), 'r') as f:lines = f.readlines()return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]lines = read_time_machine()
print(f'# 文本总行数: {len(lines)}')
print(lines[0])
print(lines[10])2.2. 词元化
tokenize函数:
- 输入:文本行列表(
lines),- 列表中的每个元素是一个文本序列(如一条文本行)。
- 每个文本序列又被拆分成一个词元列表,词元(token)是文本的基本单位。
- 返回:一个由词元列表组成的列表,其中的每个词元都是一个字符串(string)。
def tokenize(lines, token='word'): #@save"""将文本行拆分为单词或字符词元"""if token == 'word':return [line.split() for line in lines]elif token == 'char':return [list(line) for line in lines]else:print('错误:未知词元类型:' + token)tokens = tokenize(lines)
for i in range(11):print(tokens[i])2.3. 词表
- 词元的类型是字符串,而模型需要的输入是数字,因此这种类型不方便模型使用。
- 词表(vocabulary):字典类型,用来将字符串类型的词元映射到从0开始的数字索引中。
- 先将训练集中的所有文档合并在一起,对它们的唯一词元进行统计,得到的统计结果称之为语料(corpus)。
- 然后根据每个唯一词元的出现频率,为其分配一个数字索引。
- 很少出现的词元通常被移除,这可以降低复杂性。
- 另外,语料库中不存在或已删除的任何词元都将映射到一个特定的未知词元“<unk>”。
- 我们可以选择增加一个列表,用于保存那些被保留的词元, 例如:填充词元(“<pad>”); 序列开始词元(“<bos>”); 序列结束词元(“<eos>”)。
class Vocab: #@save"""文本词表"""def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):if tokens is None:tokens = []if reserved_tokens is None:reserved_tokens = []# 按出现频率排序counter = count_corpus(tokens)self._token_freqs = sorted(counter.items(), key=lambda x: x[1],reverse=True)# 未知词元的索引为0self.idx_to_token = ['<unk>'] + reserved_tokensself.token_to_idx = {token: idxfor idx, token in enumerate(self.idx_to_token)}for token, freq in self._token_freqs:if freq < min_freq:breakif token not in self.token_to_idx:self.idx_to_token.append(token)self.token_to_idx[token] = len(self.idx_to_token) - 1def __len__(self):return len(self.idx_to_token)def __getitem__(self, tokens):if not isinstance(tokens, (list, tuple)):return self.token_to_idx.get(tokens, self.unk)return [self.__getitem__(token) for token in tokens]def to_tokens(self, indices):if not isinstance(indices, (list, tuple)):return self.idx_to_token[indices]return [self.idx_to_token[index] for index in indices]@propertydef unk(self): # 未知词元的索引为0return 0@propertydef token_freqs(self):return self._token_freqsdef count_corpus(tokens): #@save"""统计词元的频率"""# 这里的tokens是1D列表或2D列表if len(tokens) == 0 or isinstance(tokens[0], list):# 将词元列表展平成一个列表tokens = [token for line in tokens for token in line]return collections.Counter(tokens)首先使用时光机器数据集作为语料库来构建词表,然后打印前几个高频词元及其索引。
vocab = Vocab(tokens)
print(list(vocab.token_to_idx.items())[:10])现在将每一条文本行转换成一个数字索引列表:
for i in [0, 10]:print('文本:', tokens[i])print('索引:', vocab[tokens[i]])2.4. 整合所有功能
在使用上述函数时,我们将所有功能打包到load_corpus_time_machine函数中, 该函数返回corpus(词元索引列表)和vocab(时光机器语料库的词表)。 我们在这里所做的改变是:
- 为了简化后面章节中的训练,我们使用字符(而不是单词)实现文本词元化;
- 时光机器数据集中的每个文本行不一定是一个句子或一个段落,还可能是一个单词,因此返回的
corpus仅处理为单个列表,而不是使用多词元列表构成的一个列表。
def load_corpus_time_machine(max_tokens=-1): #@save"""返回时光机器数据集的词元索引列表和词表"""lines = read_time_machine()tokens = tokenize(lines, 'char')vocab = Vocab(tokens)# 因为时光机器数据集中的每个文本行不一定是一个句子或一个段落,# 所以将所有文本行展平到一个列表中corpus = [vocab[token] for line in tokens for token in line]if max_tokens > 0:corpus = corpus[:max_tokens]return corpus, vocabcorpus, vocab = load_corpus_time_machine()
len(corpus), len(vocab)
小结
文本是序列数据的一种最常见的形式之一。
为了对文本进行预处理,我们通常将文本拆分为词元,构建词表将词元字符串映射为数字索引,并将文本数据转换为词元索引以供模型操作。
3. 语言模型和数据集
在 8.2节中, 我们了解了如何将文本数据映射为词元, 以及将这些词元可以视为一系列离散的观测,例如单词或字符。 假设长度为的文本序列中的词元依次为 。 于是,
(
) 可以被认为是文本序列在时间步处的观测或标签。 在给定这样的文本序列时,语言模型(language model)的目标是估计序列的联合概率
![]()
例如,只需要一次抽取一个词元 , 一个理想的语言模型就能够基于模型本身生成自然文本。 与猴子使用打字机完全不同的是,从这样的模型中提取的文本 都将作为自然语言(例如,英语文本)来传递。 只需要基于前面的对话片断中的文本, 就足以生成一个有意义的对话。 显然,我们离设计出这样的系统还很遥远, 因为它需要“理解”文本,而不仅仅是生成语法合理的内容。
尽管如此,语言模型依然是非常有用的。 例如,短语“to recognize speech”和“to wreck a nice beach”读音上听起来非常相似。 这种相似性会导致语音识别中的歧义,但是这很容易通过语言模型来解决, 因为第二句的语义很奇怪。 同样,在文档摘要生成算法中, “狗咬人”比“人咬狗”出现的频率要高得多, 或者“我想吃奶奶”是一个相当匪夷所思的语句, 而“我想吃,奶奶”则要正常得多。
3.1. 学习语言模型
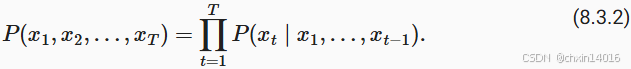
例如,包含了四个单词的一个文本序列的概率是:
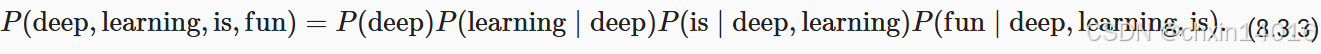
为了训练语言模型,我们需要计算单词的概率, 以及给定前面几个单词后出现某个单词的条件概率。 这些概率本质上就是语言模型的参数。
这里,我们假设训练数据集是一个大型的文本语料库。 比如,维基百科的所有条目、 古登堡计划, 或者所有发布在网络上的文本。 训练数据集中词的概率可以根据给定词的相对词频来计算。 例如,可以将估计值 计算为任何以单词“deep”开头的句子的概率。 一种(稍稍不太精确的)方法是统计单词“deep”在数据集中的出现次数, 然后将其除以整个语料库中的单词总数。 这种方法效果不错,特别是对于频繁出现的单词。 接下来,我们可以尝试估计
![]()
其中 和
分别是单个单词和连续单词对的出现次数。 不幸的是,由于连续单词对“deep learning”的出现频率要低得多, 所以估计这类单词正确的概率要困难得多。 特别是对于一些不常见的单词组合,要想找到足够的出现次数来获得准确的估计可能都不容易。 而对于三个或者更多的单词组合,情况会变得更糟。 许多合理的三个单词组合可能是存在的,但是在数据集中却找不到。 除非我们提供某种解决方案,来将这些单词组合指定为非零计数, 否则将无法在语言模型中使用它们。 如果数据集很小,或者单词非常罕见,那么这类单词出现一次的机会可能都找不到。
一种常见的策略是执行某种形式的拉普拉斯平滑(Laplace smoothing), 具体方法是在所有计数中添加一个小常量。 用n表示训练集中的单词总数,用m表示唯一单词的数量。 此解决方案有助于处理单元素问题,例如通过:
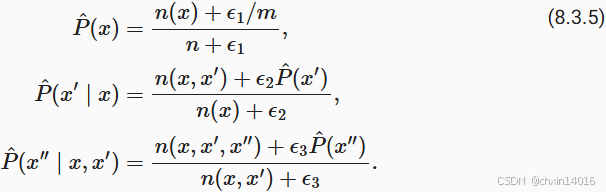
其中, 和
是超参数。 以为
例:当
时,不应用平滑; 当
接近正无穷大时,
接近均匀概率分布 1/m。 上面的公式是 (Wood et al., 2011) 的一个相当原始的变形。
然而,这样的模型很容易变得无效,原因如下: 首先,我们需要存储所有的计数; 其次,这完全忽略了单词的意思。 例如,“猫”(cat)和“猫科动物”(feline)可能出现在相关的上下文中, 但是想根据上下文调整这类模型其实是相当困难的。 最后,长单词序列大部分是没出现过的, 因此一个模型如果只是简单地统计先前“看到”的单词序列频率, 那么模型面对这种问题肯定是表现不佳的。
3.2. 马尔可夫模型与元语法
在讨论包含深度学习的解决方案之前,我们需要了解更多的概念和术语。 回想一下我们在 8.1节中对马尔可夫模型的讨论, 并且将其应用于语言建模。 如果 , 则序列上的分布满足一阶马尔可夫性质。 阶数越高,对应的依赖关系就越长。 这种性质推导出了许多可以应用于序列建模的近似公式:
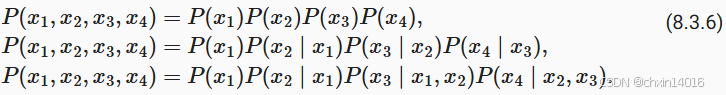
通常,涉及一个、两个和三个变量的概率公式分别被称为 一元语法(unigram)、二元语法(bigram)和三元语法(trigram)模型。 下面,我们将学习如何去设计更好的模型。
3.3. 自然语言统计
我们看看在真实数据上如果进行自然语言统计。 根据 8.2节中介绍的时光机器数据集构建词表, 并打印前个最常用的(频率最高的)单词。
![]()
等价于:
![]()
其中α是刻画分布的指数,c是常数。 这告诉我们想要通过计数统计和平滑来建模单词是不可行的, 因为这样建模的结果会大大高估尾部单词的频率,也就是所谓的不常用单词。 那么其他的词元组合,比如二元语法、三元语法等等,又会如何呢? 我们来看看二元语法的频率是否与一元语法的频率表现出相同的行为方式。
3.4. 读取长序列数据
由于序列数据本质上是连续的,因此我们在处理数据时需要解决这个问题。 在 8.1节中我们以一种相当特别的方式做到了这一点: 当序列变得太长而不能被模型一次性全部处理时, 我们可能希望拆分这样的序列方便模型读取。
在介绍该模型之前,我们看一下总体策略。 假设我们将使用神经网络来训练语言模型, 模型中的网络一次处理具有预定义长度 (例如个时间步)的一个小批量序列。 现在的问题是如何随机生成一个小批量数据的特征和标签以供读取。
首先,由于文本序列可以是任意长的, 例如整本《时光机器》(The Time Machine), 于是任意长的序列可以被我们划分为具有相同时间步数的子序列。 当训练我们的神经网络时,这样的小批量子序列将被输入到模型中。 假设网络一次只处理具有个时间步的子序列。 图8.3.1画出了 从原始文本序列获得子序列的所有不同的方式, 其中,并且每个时间步的词元对应于一个字符。 请注意,因为我们可以选择任意偏移量来指示初始位置,所以我们有相当大的自由度。

因此,我们应该从 图8.3.1中选择哪一个呢? 事实上,他们都一样的好。 然而,如果我们只选择一个偏移量, 那么用于训练网络的、所有可能的子序列的覆盖范围将是有限的。 因此,我们可以从随机偏移量开始划分序列, 以同时获得覆盖性(coverage)和随机性(randomness)。 下面,我们将描述如何实现随机采样(random sampling)和 顺序分区(sequential partitioning)策略。
3.4.1. 随机采样
3.4.2. 顺序分区
3.5. 小结
语言模型是自然语言处理的关键。
n元语法通过截断相关性,为处理长序列提供了一种实用的模型。
长序列存在一个问题:它们很少出现或者从不出现。
齐普夫定律支配着单词的分布,这个分布不仅适用于一元语法,还适用于其他n元语法。
通过拉普拉斯平滑法可以有效地处理结构丰富而频率不足的低频词词组。
读取长序列的主要方式是随机采样和顺序分区。在迭代过程中,后者可以保证来自两个相邻的小批量中的子序列在原始序列上也是相邻的。
4. 循环神经网络
在 8.3节中, 我们介绍了n元语法模型, 其中单词 在时间步t的条件概率仅取决于前面 n-1个单词。 对于时间步 t-(n-1)之前的单词, 如果我们想将其可能产生的影响合并到
上, 需要增加n,然而模型参数的数量也会随之呈指数增长, 因为词表
需要存储
个数字, 因此与其将
模型化, 不如使用隐变量模型:
![]()
其中 是隐状态(hidden state), 也称为隐藏变量(hidden variable), 它存储了到时间步 t-1 的序列信息。 通常,我们可以基于当前输入
和先前隐状态
来计算时间步t处的任何时间的隐状态:
![]()
对于 (8.4.2)中的函数,隐变量模型不是近似值。 毕竟
是可以仅仅存储到目前为止观察到的所有数据, 然而这样的操作可能会使计算和存储的代价都变得昂贵。
回想一下,我们在 4节中 讨论过的具有隐藏单元的隐藏层。 值得注意的是,隐藏层和隐状态指的是两个截然不同的概念。 如上所述,隐藏层是在从输入到输出的路径上(以观测角度来理解)的隐藏的层, 而隐状态则是在给定步骤所做的任何事情(以技术角度来定义)的输入, 并且这些状态只能通过先前时间步的数据来计算。
循环神经网络(recurrent neural networks,RNNs) 是具有隐状态的神经网络。 在介绍循环神经网络模型之前, 我们首先回顾 4.1节中介绍的多层感知机模型。
4.1. 无隐状态的神经网络
让我们来看一看只有单隐藏层的多层感知机。 设隐藏层的激活函数为Φ, 给定一个小批量样本 , 其中批量大小为n,输入维度为d, 则隐藏层的输出
通过下式计算:
![]()
![]()
4.2. 有隐状态的循环神经网络
4.3. 基于循环神经网络的字符级语言模型
4.4. 困惑度(Perplexity)
4.5. 小结
对隐状态使用循环计算的神经网络称为循环神经网络(RNN)。
循环神经网络的隐状态可以捕获直到当前时间步序列的历史信息。
循环神经网络模型的参数数量不会随着时间步的增加而增加。
我们可以使用循环神经网络创建字符级语言模型。
我们可以使用困惑度来评价语言模型的质量。