C语言中的数据结构--栈和队列(2)
前言
上一节我们学习了栈这个数据结构,那么本节我们接着来学习队列,他和栈有着异曲同工之妙,那么废话不多说,我们正式进入今天的学习

队列
队列的概念以及结构
队列与栈的性质刚好相反,它具有先进后出的性质.在一段进行插入,另外一端进行删除.执行插入操作的是队尾;执行删除操作的是队头
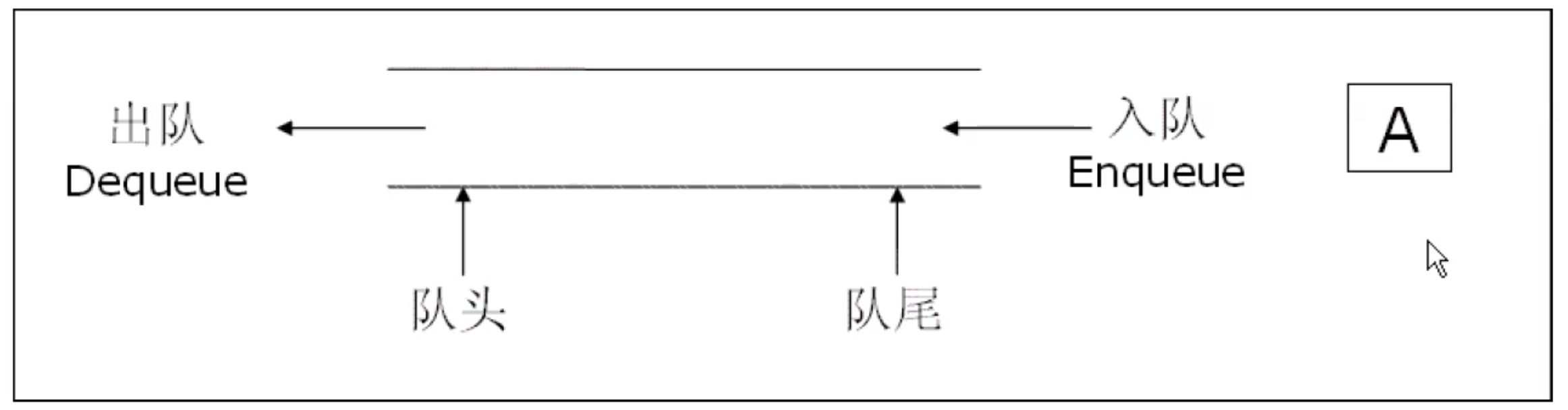
队列的入队列和出队列的顺序都是一致的,这点与栈不同,所以队列这个数据结构可以用于保持公平性,这一点具体会在后面的内容中提及;队列还可以用于二叉树中的广度优先遍历……
接下来我们来分析一下队列的结构.因为队列要求在一端入一端出,所以我们可以排除掉用数组实现,因为出队列以后会有数据的挪动,用数组实现的话效率会非常非常低.所以我们考虑用链表实现,因为双向链表是万金油,肯定能够很好的实现,所以我们在这个的基础上考虑能不能使用单链表完成任务,因为它相较于双线链表更加节省空间
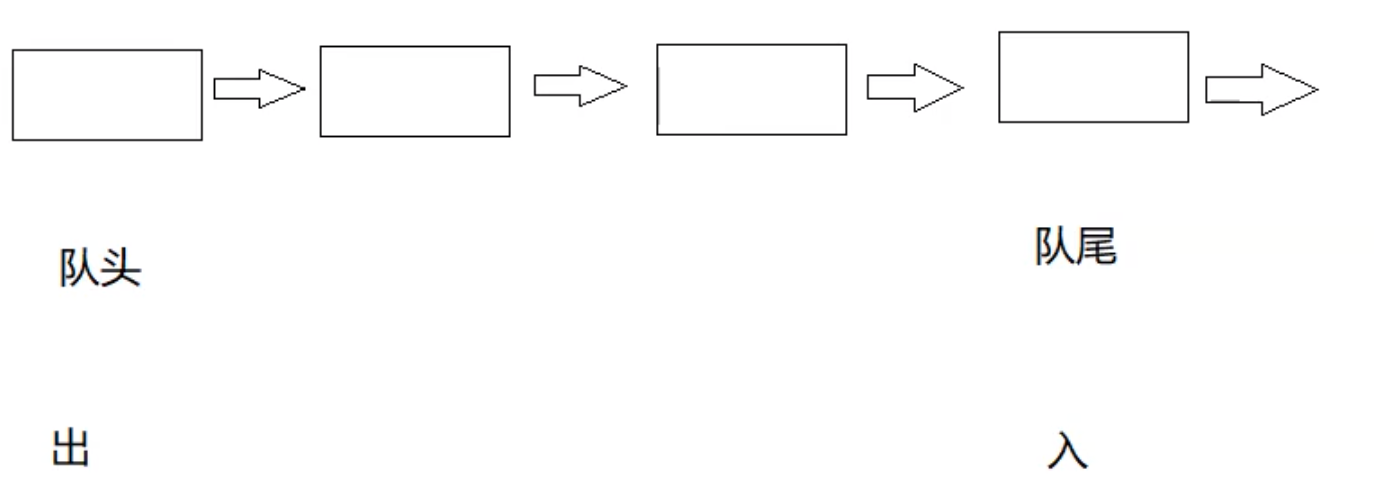
我们画出图片以后发现是可以的,这里哨兵位的头节点可要可不要,基于这些原因我们就可以确认用单链表来实现队列这个数据结构
我们可以先写出队列的基本结构:
typedef struct QueueNode
{struct QueueNode* next;QDataType val;
}QNode;队尾的初始化以及结构优化
在进行队尾插入操作时,我们每次都需要先找尾,这样非常的麻烦,假设队列很长的话还会很影响效率,那么有没有什么办法可以解决这个问题呢?答案是肯定的,我们在进行插入的时候可以传入两个指针变量,一个指针变量指向头,一个指针变量指向尾.因为这里有两指针变量,我们可以在建立一个结构体用于存入头指针和尾指针:
typedef struct Queue
{QNode* phead;QNode* ptail;
}Queue;采取这样的方法既避免了使用二级指针增加复杂程度,又避免了开哨兵位的头节点消耗空间,可谓是一举两得.
在后续实现QueueSize接口的时候,我们需要一个一个慢慢往后遍历才能知道size的大小,所以我们可以接着优化一下,在这个结构体中增加一个size成员,同于统计节点的个数,这样我们就可以把原先O(N)的时间复杂度变成O(1):
typedef struct Queue
{QNode* phead;QNode* ptail;int size;
}Queue;针对这样的结构,我们先来完成一下队列的初始化 :
void QueueInit(Queue* pq)
{assert(pq);pq->phead = NULL;pq->ptail = NULL;pq->size = 0;
}我们在学习单链表的时候之所以没有应用这样的结构是因为单链表并不像队列一样时队尾插入队头删除,应用这样的结构无法实现尾删,所以就只用了一个指针.
队列的队尾插入和队头删除
在进行队尾插入的时候,我们要分为两种情况讨论:
情况一:队列中此时没有任何的元素,此时头指针和尾指针都指向NULL,此时插入了一个元素,队头和队尾都应该指向这个刚插入的元素
情况二:此时队列中已经存在元素了,就正常的执行插入操作并且改变尾指针即可
有了这些相关的逻辑和思路,我们就可以写出代码了:
void QueuePush(Queue* pq, QDataType x)
{assert(pq);QNode* newnode = (QNode*)malloc(sizeof(QNode));if(newnode == NULL){perror("malloc fail");return;}newnode->val = x;newnode->next = NULL;if(pq->ptail == NULL){pq->phead = pq->ptail = newnode;}else{pq->ptail->next = newnode;pq->ptail = newnode;}pq->size++;
}接下来我们再来实现一下队头删除的代码:
队头删除的代码很简单,但是我们需要注意内存的释放,这里就不做过多讲解了,直接给出代码:
void QueuePop(Queue* pq)
{assert(pq);assert(pq->phead);QNode* next = pq->phead->next;free(pq->phead);pq->phead = next;pq->size--;
}这个代码在正常的情况没有问题,我们来考虑一下特殊的情况--队列中只有一个节点:
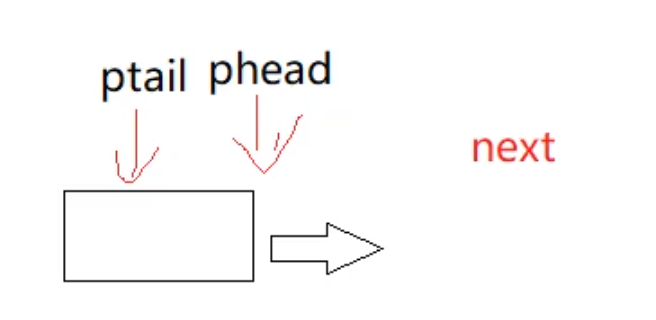
此时我们保存的next指针指向的是空,随后我们向后执行代码,free掉这个唯一的节点,并且让phead指向下一个节点:
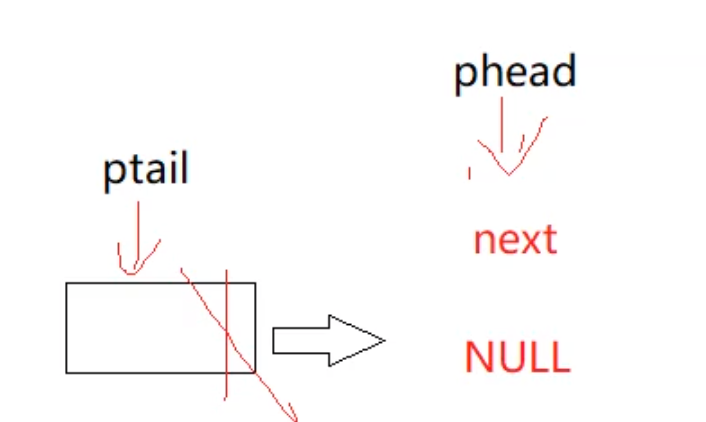
可以看到这里刚好能够满足条件,但是此时ptail就变成一个野指针了,所以我们还需要对代码进行适当的调整:
void QueuePop(Queue* pq)
{assert(pq);assert(pq->phead);QNode* next = pq->phead->next;free(pq->phead);pq->phead = next;if(pq->phead == NULL) pq->ptail = NULL;pq->size--;
}或者用if-else语句进行更改:
void QueuePop(Queue* pq)
{assert(pq);assert(pq->phead);if(pq->phead->next == NULL){free(pq->phead);pq->phead = pq->ptail = NULL;}else{QNode* next = pq->phead->next;free(pq->phead);pq->phead = next;}pq->size--;
}获取队头和队尾的数据
获取队头和队尾的数据代码实现非常的简单,这里直接给出代码:
QDataType QueueFront(Queue* pq)
{assert(pq);assert(pq->phead);return pq->phead->val;
}QDataType QueueBack(Queue* pq)
{assert(pq);assert(pq->ptail);return pq->ptail->val;
}队列的其他相关接口
首先是队列的判空接口,因为实现逻辑和之前的大致相同,所以这里直接给出代码:
bool QueueEmpty(Queue* pq)
{assert(pq);return pq->size == 0;
}接下来就是队列的释放,这里的释放逻辑和单链表是相似的,所以也不做过多讲解:
void QueueDestory(Queue* pq)
{QNode* cur = pq->phead;while(cur){QNode* next = cur->next;free(cur);cur = next;}pq->phead = pq->ptail = 0;pq->size = 0;
}接下来我们对代码进行简单的测试:
Queue q;QueueInit(&q);QueuePush(&q, 1);QueuePush(&q, 2);QueuePush(&q, 3);QueuePush(&q, 4);while(!QueueEmpty(&q)){printf("%d ",QueueFront(&q));QueuePop(&q);}
可以看到代码不存在问题,那么我们对队列的模拟实现基本就已经完成了,我们接下来做一些关于队列的题目来巩固一下理解
队列的练习题
用两个队列实现栈

我们先来对题目进行分析:
通过题目给出的信息我们知道要用两个队列实现一个栈,所以我们先定义一个结构体用于存放两个队列:
typedef struct
{Queue q1;Queue q2;
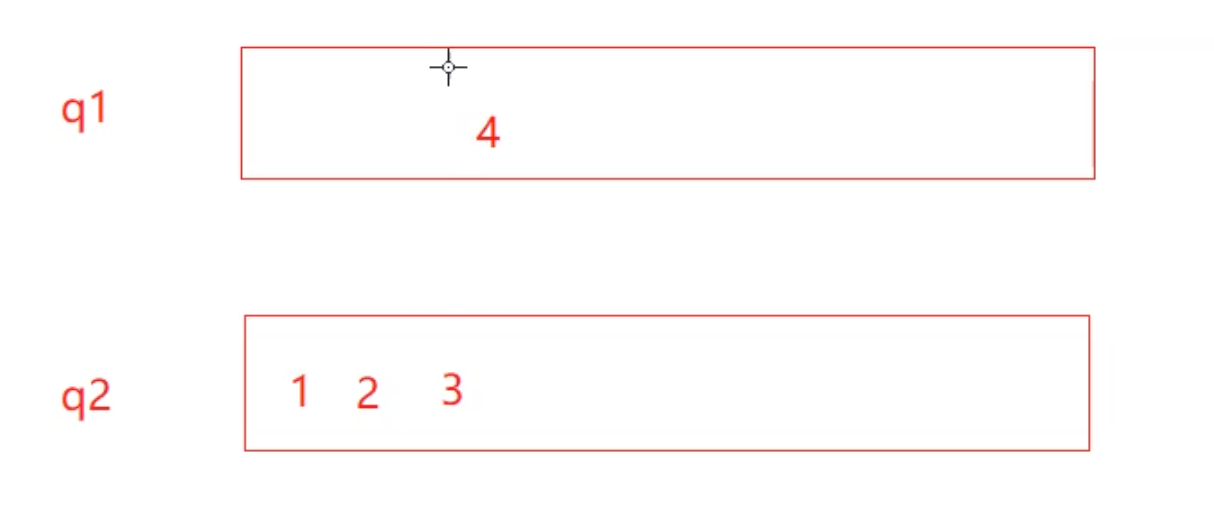
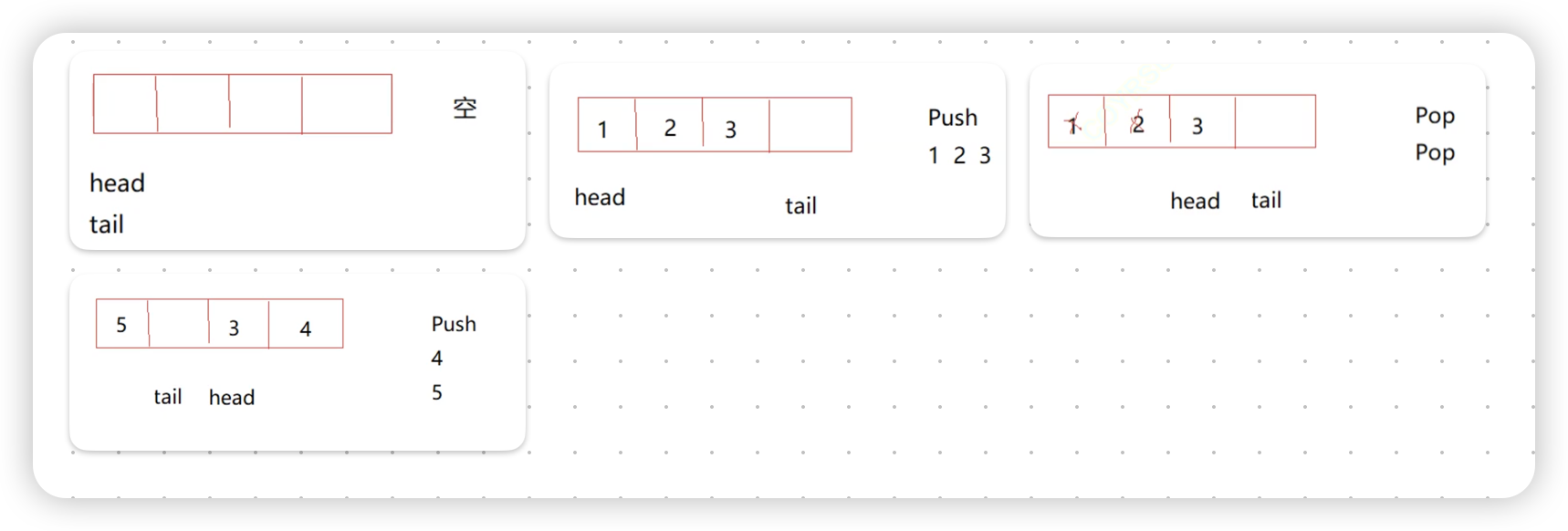
}MyStack;栈的性质是先进先出,而队列的性质是后进先出,假设我们在其中一个队列中先入数据“1、2、3、4”

因为要实现的栈是后进先出的,所以如果此时秩序pop操作,删除的数据会是4;而我们的q1是一个队列,执行pop操作删除的数据是1.
所以我们此时可能会可以采用一种特殊的逻辑,我们可以在q1中把1、2、3都取出来插入到q2中,此时队列q1中就只剩下了数据4,现在再执行pop操作就会删除数据4.
这样的操作本质是借助另外一个队列来实现数据顺序的颠倒,假设我们要入数据5、6怎么办?此时我们就不能再往q1中入数据,而是需要将5、6入到q2中去,下面我们来分析一下原因:
我们采取反证法,假设我们将5、6入到q1中:

此时如果我们执行一次pop,就会把数据5入到q2中去,然后再将q1中的数据6删除,此时的逻辑是不存在问题的.

但是如果我们再执行一次pop操作,此时需要删除的元素是数据5.要想删除数据5,只能又将下面q2的数据1、2、3移到q1中去,然后删除5
频繁的push和pop会导致逻辑的混乱,让我们不清楚栈顶的数据到底在q1中还是q2中,大大提升代码的完成难度.所以要将新来的数据插入到不为空的队列中去,避免逻辑的混乱.

此时要执行pop操作就需要把1、2、3、5移到q1中,然后删除掉6

这里统一的逻辑就是:当执行push操作的时候,判断一下哪个队列不为空就往哪个队列push;当执行pop操作时把不为空的前n-1个数据移到空的队列中去,最后删除那个剩下的数据.执行完操作的队列始终是一个为空,一个不为空
题目的逻辑整体已经呈现,接下来就是代码实现的部分:
首先是对于这个栈的初始化,我们最直接能想到的思路就是,现在初始化函数中创建一个栈,初始化结束以后返回这个栈的指针:
MyStack* myStackCreate()
{MyStack st;//...return &st;
}但其实这样的做法是不对的,因为st是一个局部的变量,出了作用域以后就会被销毁,此时返回的是一个野指针,所以此时只能用malloc申请空间,这样出了作用域才不会被销毁
(这里大家可能会想到使用全局变量,但是不推荐使用全局变量,因为如果是在做题的时候,会有多组测试用例,就会调用很多次,而作为全局变量不会被销毁,就只会在这一个上处理,导致运行报错)
MyStack* myStackCreate()
{MyStack* pst = (MyStack*)malloc(sizeof(MyStack));QueueInit(&pst->q1);QueueInit(&pst->q2);return &st;
}这里的&pst->q1涉及到潜在的优先级问题,但由于->的优先级高于&,所以这里不要加括号,也可以自行加入括号避免出现错误
接下来我们就来实现入栈的代码部分,这里我们之前已经分析过了,哪个栈不为空就往哪个栈中入数据:
void myStackPush(MyStack* obj, int x)
{if(!QueueEmpty(&pst->q1)){QueuePush(&pst->q1, x);}else{QueuePush(&pst->q2, x);}
}接下来来实现pop的代码,这里之前也提及了,pop涉及到对数据的颠倒,把不为空的前size-1个数据倒走,最后一个元素就是该删除的栈顶数据.这里我使用的是假设法,也可以使用if - else语句来完成代码:
int myStackPop(MyStack* obj)
{Queue* empty = &obj->q1;Queue* nonempty = &obj->q2;if(QueueEmpty(&obj->q2)){empty = &obj->q2;nonempty = &obj->q1;}while(QueueSize(nonempty) > 1){QueuePush(empty, QueueFront(nonempty));QueuePop(nonempty);}int top = QueueFront(nonempty);QueuePop(nonempty);return top;
}接下来是栈剩下的接口实现,因为实现起来比较简单,前面也进行过了分析,所以这里就直接给出代码了:
int myStackTop(MyStack* obj)
{if(!QueueEmpty(&obj->q1)){return QueueBack(&obj->q1);}else{return QueueBack(&obj->q2);}
}bool myStackEmpty(MyStack* obj)
{return QueueEmpty(&obj->q1) && QueueEmpty(&obj->q2);
}最后再来简单的提及一下栈的释放,这里在释放的时候不能直接free掉obj,因为obj是一个指针,指向的是一个结构体,而这个结构体里面有含有两个结构体(栈)q1和q2,而q1和q2分别含有三个值ptail、phead、size.(假设其中有三个数据1、2、3)
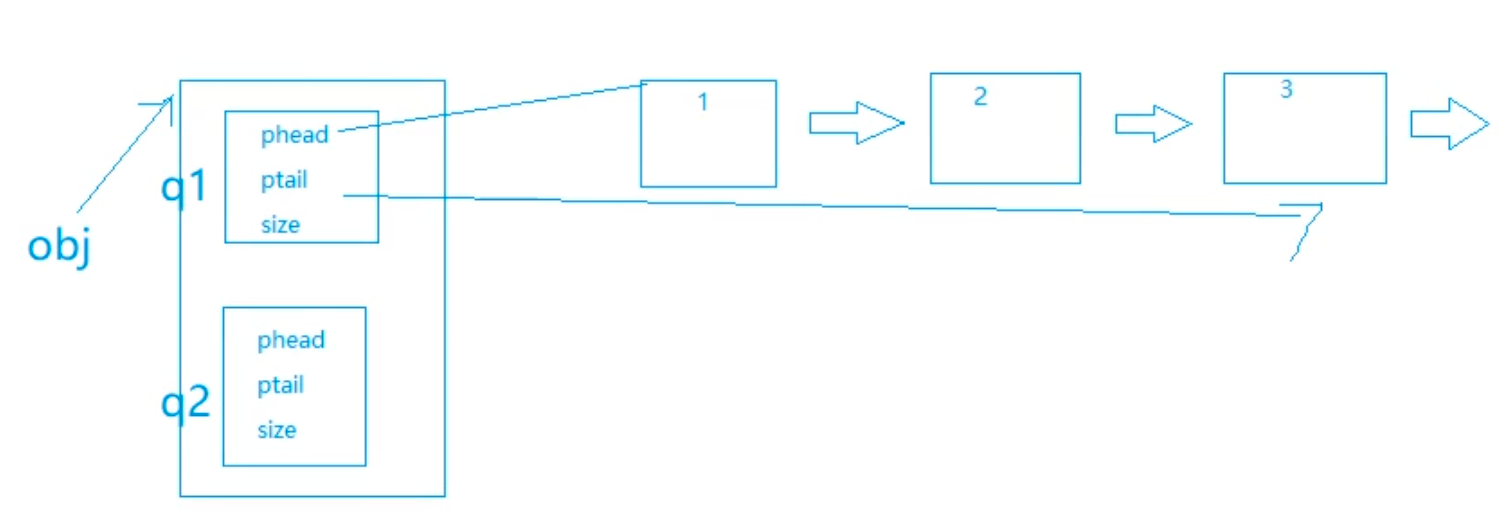
如果我们在这里只是free掉了obj,就只是free掉了mystack这个大的结构体,而链表中的节点并没有被释放,这就导致了内存泄漏
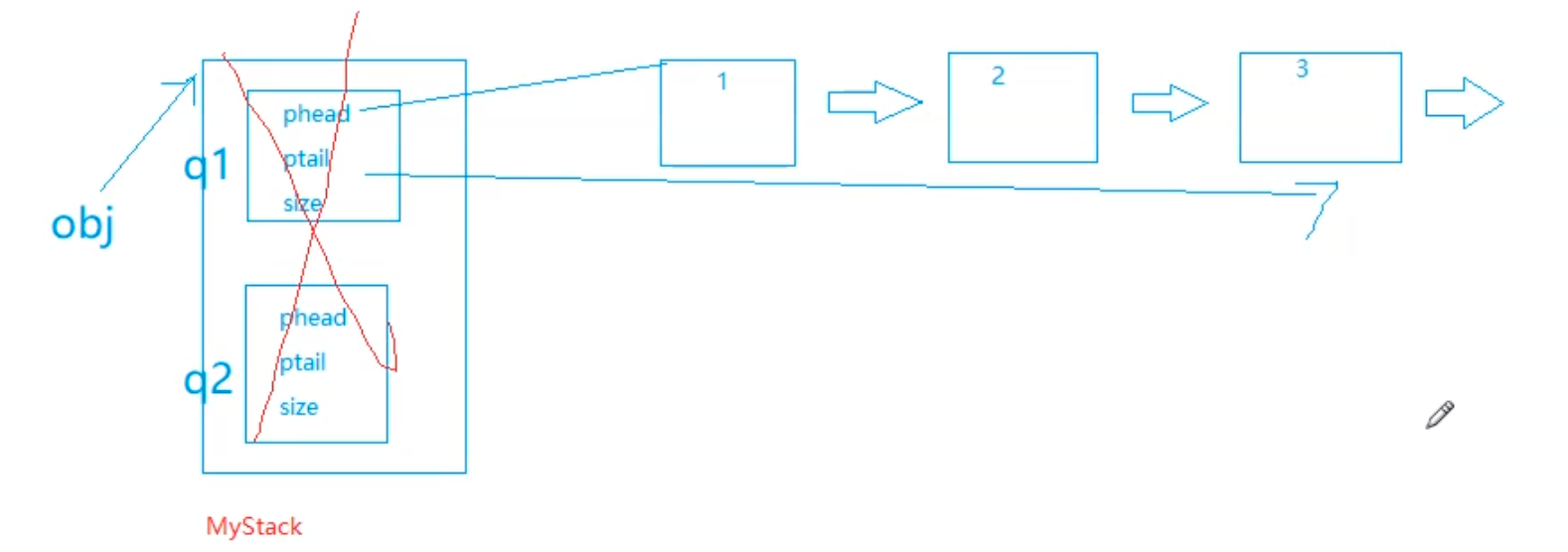
void myStackFree(MyStack* obj)
{QueueDestory(&(obj->q1));QueueDestory(&(obj->q2));free(obj);
}完整代码如下:
typedef int QDataType;typedef struct QueueNode
{struct QueueNode* next;QDataType val;
}QNode;typedef struct Queue
{QNode* phead;QNode* ptail;int size;
}Queue;void QueueInit(Queue* pq)
{assert(pq);pq->phead = NULL;pq->ptail = NULL;pq->size = 0;
}void QueueDestory(Queue* pq)
{QNode* cur = pq->phead;while(cur){QNode* next = cur->next;free(cur);cur = next;}pq->phead = pq->ptail = 0;pq->size = 0;
}//队尾插入 队头删除
void QueuePush(Queue* pq, QDataType x)
{assert(pq);QNode* newnode = (QNode*)malloc(sizeof(QNode));if(newnode == NULL){perror("malloc fail");return;}newnode->val = x;newnode->next = NULL;if(pq->ptail == NULL){pq->phead = pq->ptail = newnode;}else{pq->ptail->next = newnode;pq->ptail = newnode;}pq->size++;
}
void QueuePop(Queue* pq)
{assert(pq);assert(pq->phead);if(pq->phead->next == NULL){free(pq->phead);pq->phead = pq->ptail = NULL;}else{QNode* next = pq->phead->next;free(pq->phead);pq->phead = next;}pq->size--;
}QDataType QueueFront(Queue* pq)
{assert(pq);assert(pq->phead);return pq->phead->val;
}QDataType QueueBack(Queue* pq)
{assert(pq);assert(pq->ptail);return pq->ptail->val;
}int QueueSize(Queue* pq)
{assert(pq);return pq->size;
}bool QueueEmpty(Queue* pq)
{assert(pq);return pq->size == 0;
}typedef struct
{Queue q1;Queue q2;
}MyStack;MyStack* myStackCreate()
{MyStack* pst = (MyStack*)malloc(sizeof(MyStack));QueueInit(&(pst->q1));QueueInit(&(pst->q2));return pst;
}void myStackPush(MyStack* obj, int x)
{if(!QueueEmpty(&(obj->q1))){QueuePush(&(obj->q1), x);}else{QueuePush(&(obj->q2), x);}
}int myStackPop(MyStack* obj)
{Queue* empty = &(obj->q1);Queue* nonempty = &(obj->q2);if(!QueueEmpty(&(obj->q1))){empty = &(obj->q2);nonempty = &(obj->q1);}while(QueueSize(nonempty) > 1){QueuePush(empty, QueueFront(nonempty));QueuePop(nonempty);}int top = QueueFront(nonempty);QueuePop(nonempty);return top;
}int myStackTop(MyStack* obj)
{if(!QueueEmpty(&(obj->q1))){return QueueBack(&(obj->q1));}else{return QueueBack(&(obj->q2));}
}bool myStackEmpty(MyStack* obj)
{return QueueEmpty(&(obj->q1)) && QueueEmpty(&(obj->q2));
}void myStackFree(MyStack* obj)
{QueueDestory(&(obj->q1));QueueDestory(&(obj->q2));free(obj);
}
设计循环队列

根据题目的意思我们可以知道循环队列的空间的大小是固定的.结合题意分析,该题可以采取循环链表的基本结构,也可以用数组的方法,这里对两种基本结构都进行讲解(实际上数组的结构实现起来更简单,对链表的逻辑只是简单提及,主要分析数组的方法):
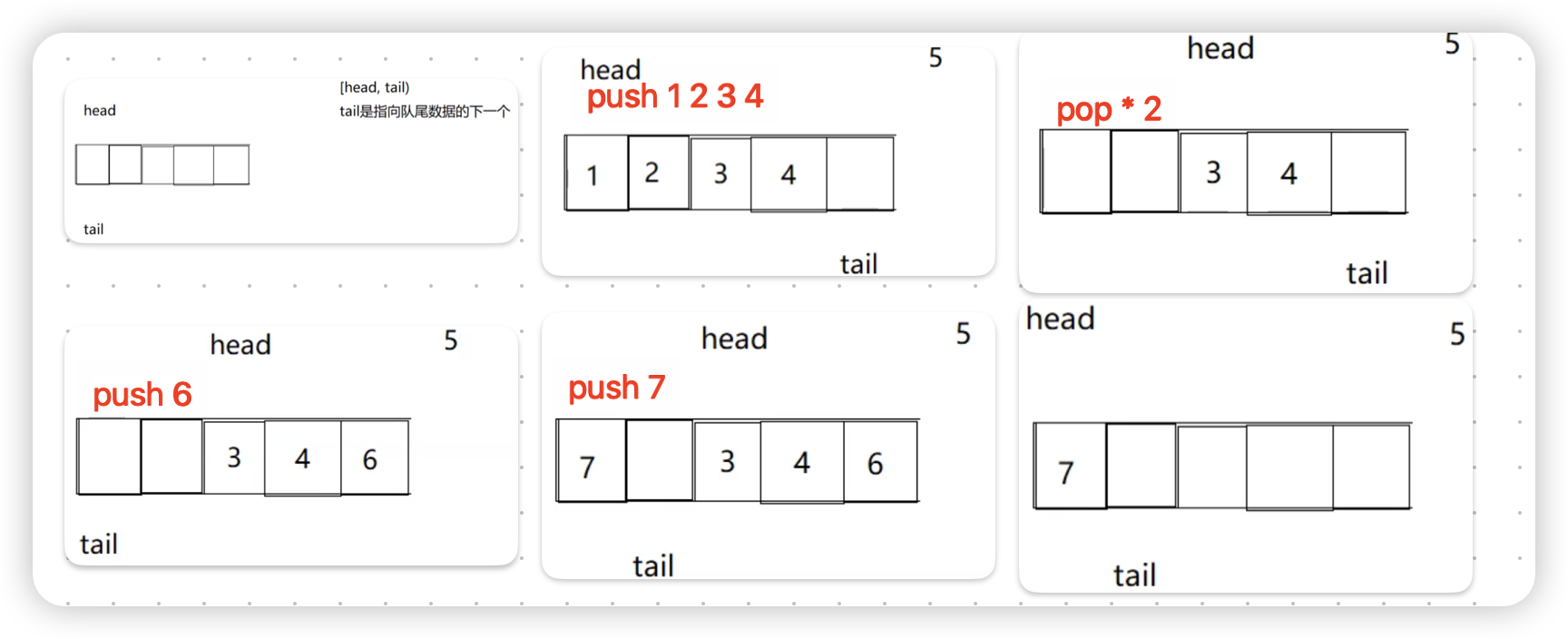
先采取数组作为基本结构:此时需要两个变量head和tail,tail用来指向队尾数据下一个数据(这里的原理和栈中的是一样的,假设指向的是当前数据,那么在没有数据的时候就要给tail赋-1)
接下来对循环队列的基本操作进行分析:
根据图片上的分析过程我们可以知道:循环队列的本质就是在有限的空间之中保证先进先出,重复使用
此时数组实现循环队列的基本逻辑已经完成了,但是还是有部分需要完善--循环队列的判空和判满条件

这里可以看到,循环队列满和空的时候的条件都是head == tail,那么我们该怎么判断二者相等的时候循环队列是空还是满呢?
方法一:增加一个变量size,当head == tail的时候,如果size == 0就是空,不为0就是满
方法二:额外再多开一个空间,在数组中间永远留一个位置不放任何的数据,解决空和满条件冲突的问题
此时空的条件是:head == tail 满的条件是:tail + 1 == head
此时再来分析一下特殊情况:
此时数组也是满的,但是tail + 1并不为head,反而还越界了,所以我们适当的修改一下判满条件:
(tail + 1) % (k + 1) 其中k是循环队列最多能存入数据的大小
现在的逻辑都已经完善好了,那么我们就正式进入写代码的环节:
我们先来定义一下循环队列的基本结构:
typedef struct
{int *a;int head;int tail;int k;
}MyCircularQueue;接下来是循环队列的创造函数:
MyCircularQueue* myCircularQueueCreate(int k)
{MyCircularQueue* obj = (MyCircularQueue*)malloc(sizeof(MyCircularQueue));if(obj == NULL){perror("malloc fail");return 0;}obj->a = malloc(sizeof(int) * (k + 1));obj->head = obj->tail = 0;obj->k = k;return obj;
}接下来就是循环队列的判空条件,这里也很简单:
bool myCircularQueueIsEmpty(MyCircularQueue* obj)
{assert(obj);return obj->head == obj->tail;
}然后就是判满条件,之前我们也进行详细的分析过,这里就直接给出:
bool myCircularQueueIsFull(MyCircularQueue* obj)
{assert(obj);return (obj->tail + 1) % (obj->k + 1) == obj->head;
}接下来就是入队列的代码,题目要求入成功就返回true,失败就返回false
我们需要额外注意下面的这种情况,此时tail++会导致越界,我们需要让tail在此时移到数组的首部去

处理完以后的代码如下:
bool myCircularQueueEnQueue(MyCircularQueue* obj, int value)
{assert(obj);if(myCircularQueueIsFull(obj)) return false;obj->a[obj->tail] = value;obj->tail++;obj->tail %= (obj->k + 1);return true;
}然后是出循环队列的代码:
bool myCircularQueueDeQueue(MyCircularQueue* obj)
{assert(obj);if(myCircularQueueIsEmpty(obj)) return false;if(obj->head == obj->tail) return false;obj->head++;obj->head %= (obj->k + 1);return true;
}接下来完成取尾数据
对于正常的情况而言:第tail - 1个数据就是尾数据,但是我们还是需要考虑一下特殊情况:

此时的tail - 1不仅不会取到尾数据,反而会导致越界,所以我们要针对这种情况执行特殊操作:
int myCircularQueueRear(MyCircularQueue* obj)
{assert(obj);if(myCircularQueueIsEmpty(obj)) return -1;return obj->a[(obj->tail - 1 + obj->k + 1) % (obj->k + 1)];
}或者有一种装逼的写法😎:
return obj->a[(obj->tail - 1 + obj->k + 1) % (obj->k + 1)];然后是取头数据的代码:
int myCircularQueueFront(MyCircularQueue* obj)
{assert(obj);if(myCircularQueueIsEmpty(obj)) return -1;return obj->a[obj->head];
}释放空间的代码:
void myCircularQueueFree(MyCircularQueue* obj)
{free(obj->a);free(obj);
}接下来我们来简单表示一下增加size变量区分空还是满的方法:
假设我们要用链表来完成这个题目,我们可能需要额外创建一个tailprev变量用于指向左后一个数据,因为单链表不能够向前寻找
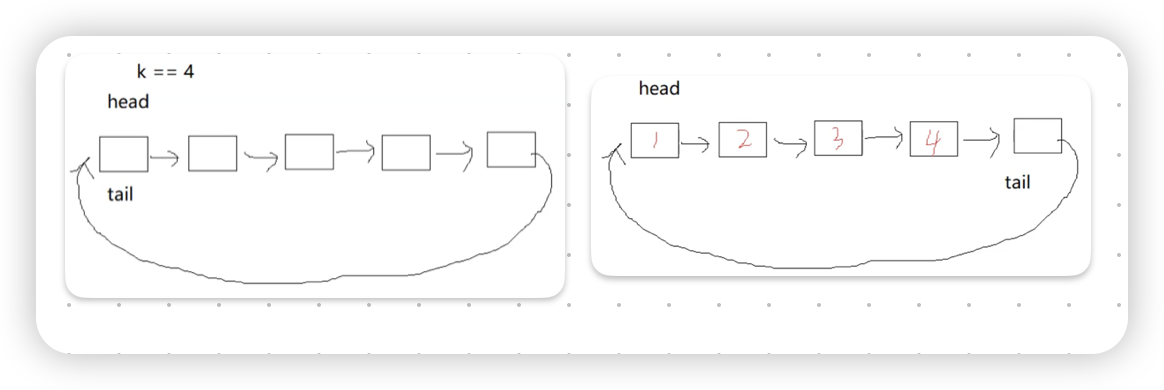
这里只对链表的方法进行大致的分析,具体的实现思路和数组相差不大.
两个栈实现一个队列

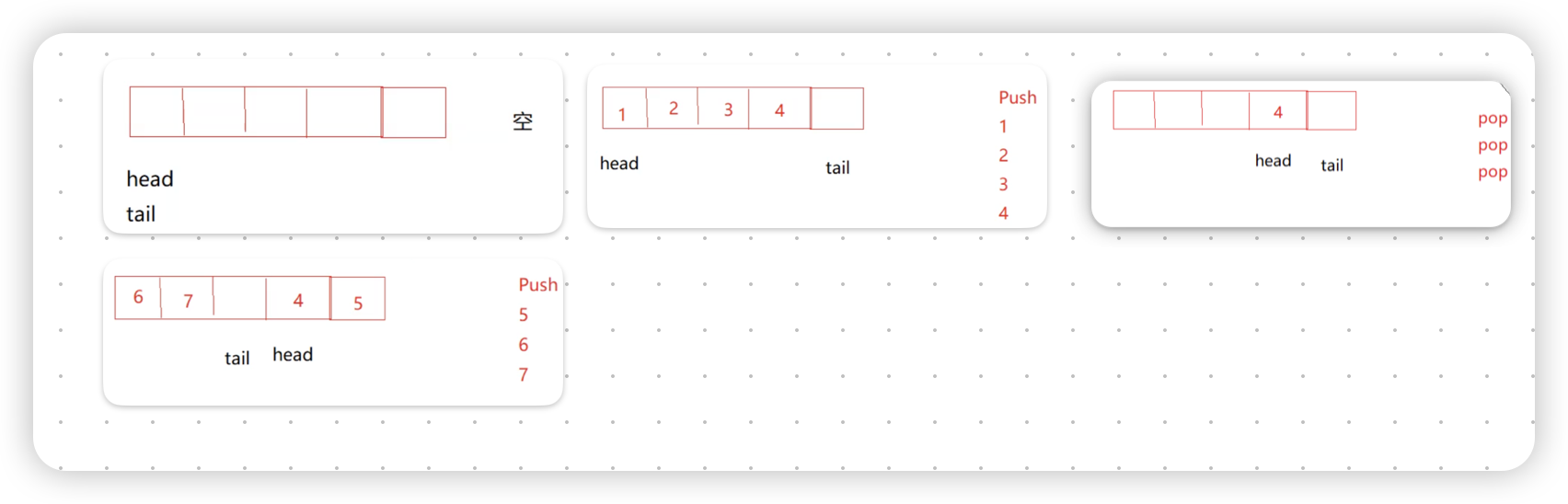
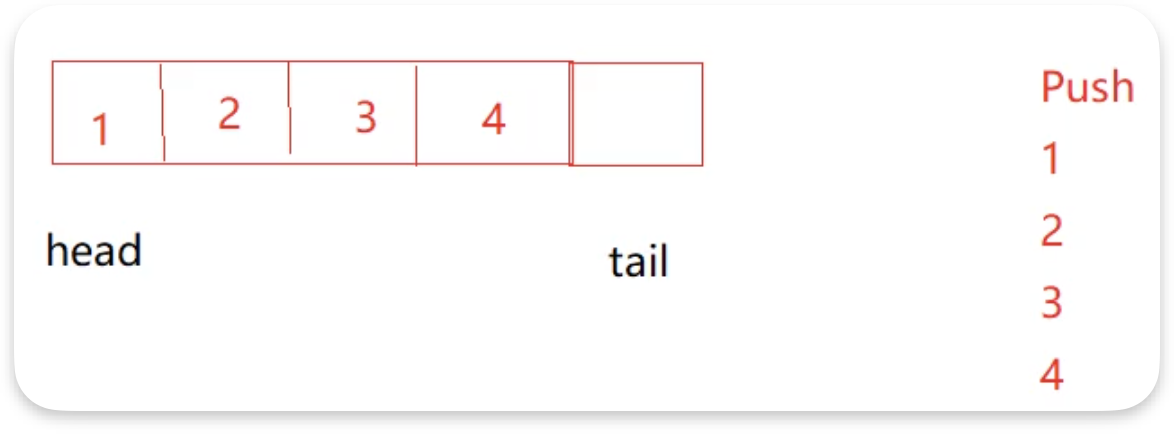
因为队列要求的条件是先进先出,而栈的性质是后进先出.假设我们此时要入数据1、2、3、4,我们此时会把这四个数据入到同一个栈中:
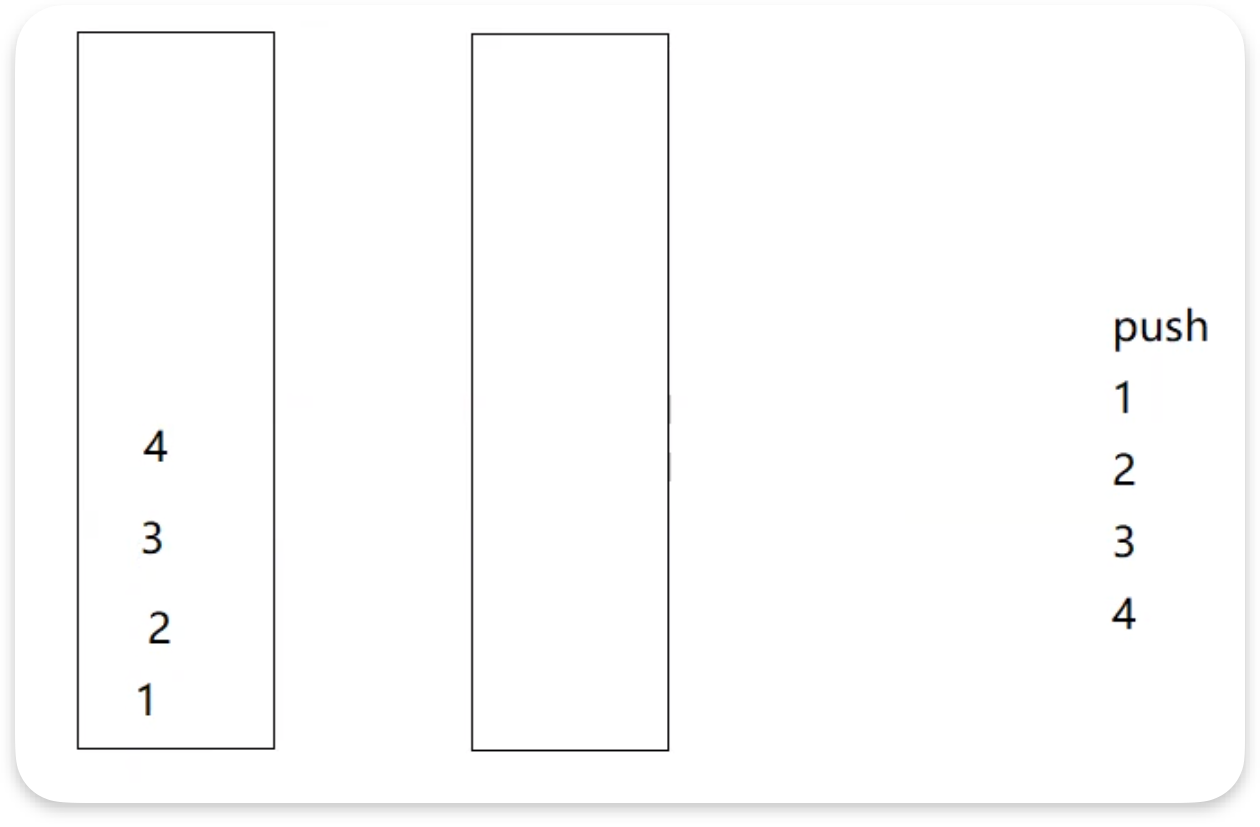
如果接着要执行pop操作,继续使用之前队列实现栈的原理我们会发现:由于栈后进先出的顺序,倒到空栈之后的数据顺序会颠倒:
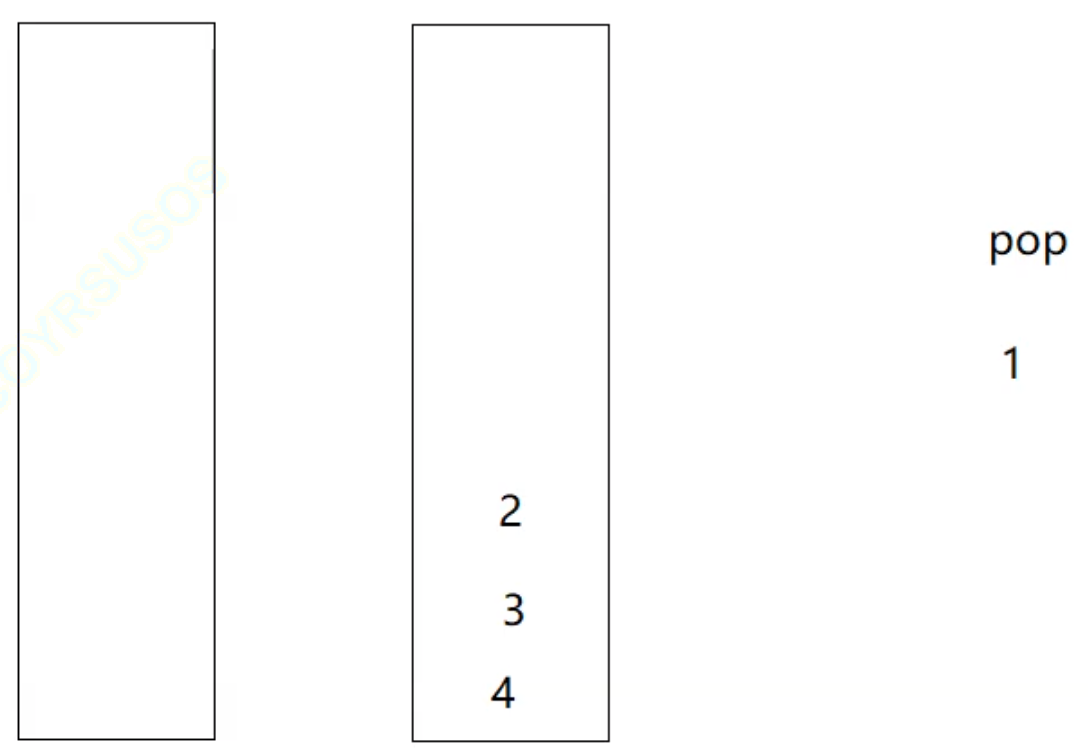
假设现在又要插入数据5和6,很多人就会认为因为顺序不同,需要把2、3、4重新倒入回第一个栈中, 然后再接着插入5和6,如下图所示:
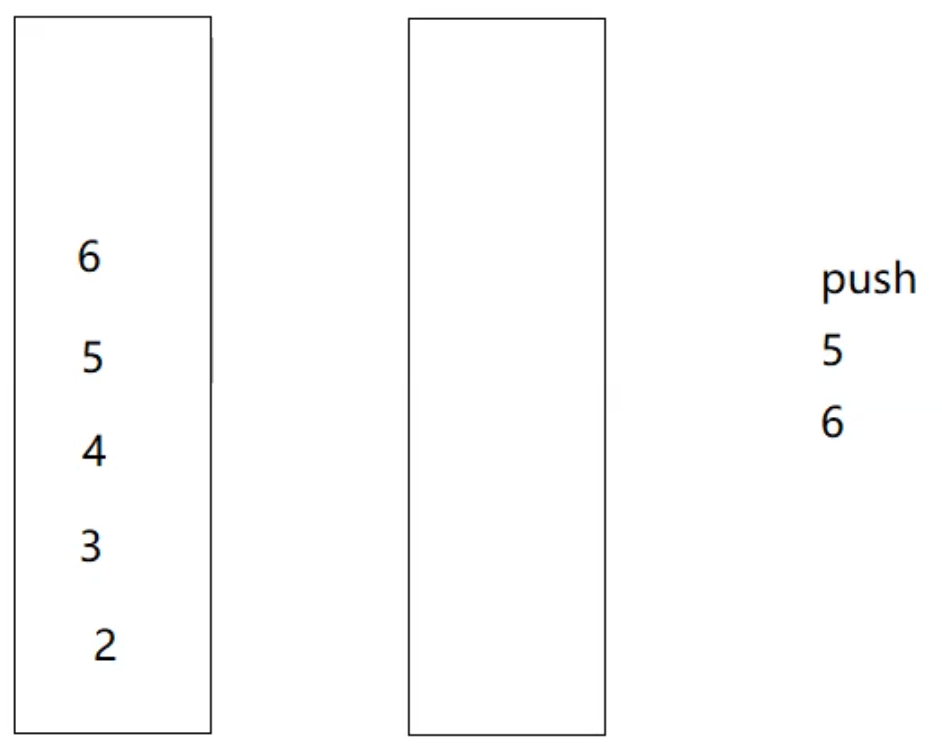
这么做固然是可以的,但是效率会比较低,我们可以采取下面这种方法:
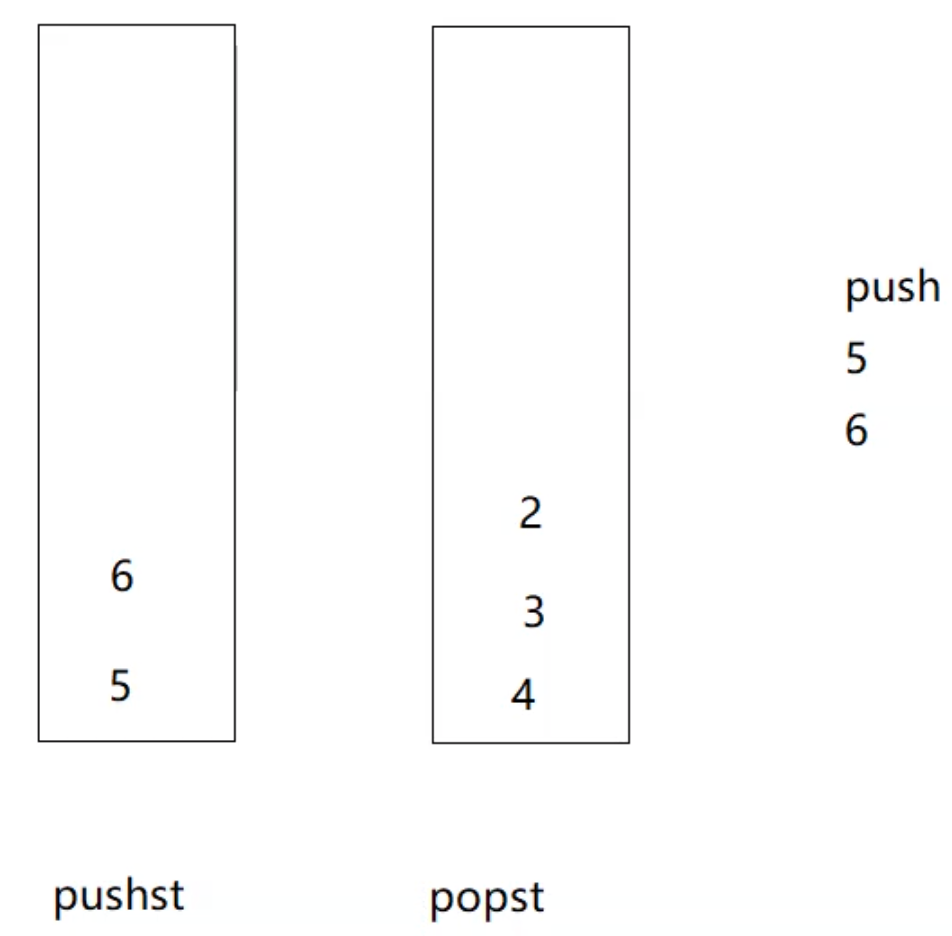
我们可以把一个栈作为入栈(pishst),一个栈作为出栈(popst),假设我们接下来还要执行pop操作时就可以直接对popst进行操作:
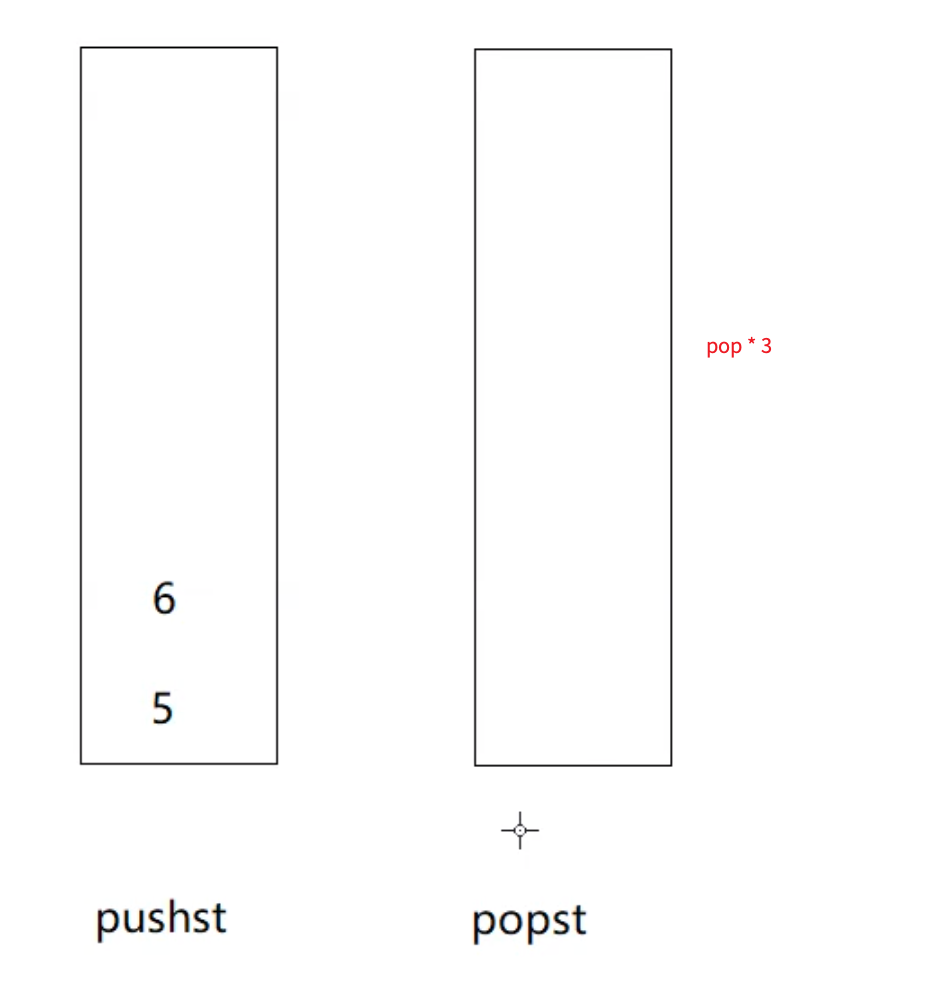
当popst为空了以后还要执行pop操作的话,就再将pushst中的数据导入popst就行:
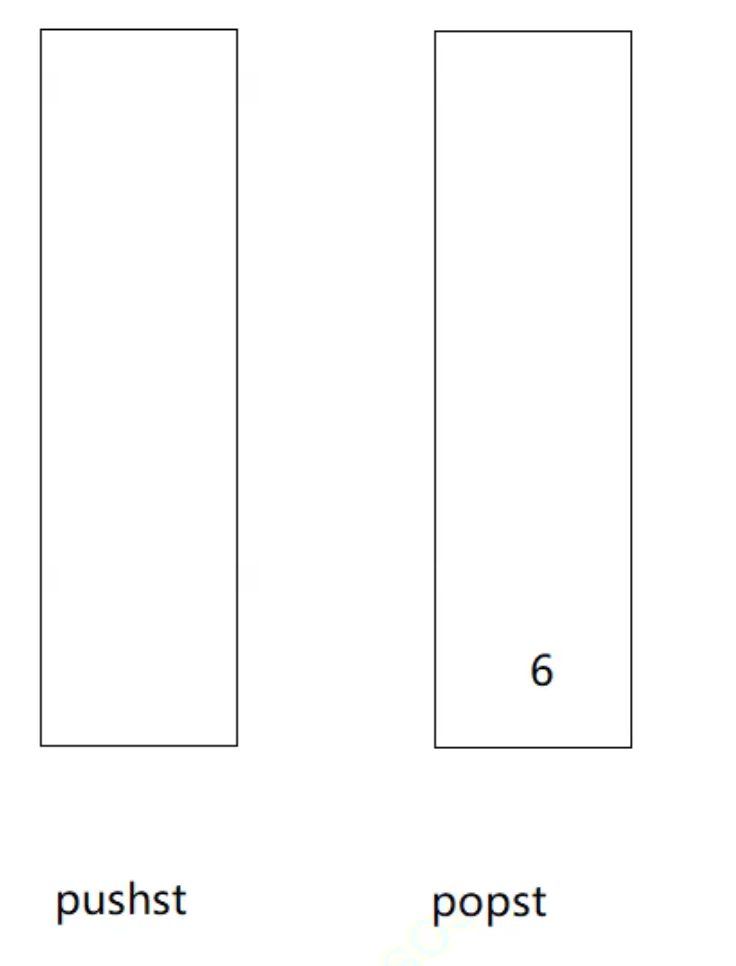
因为这里整体的逻辑和队列实现栈很相似,而且前面对题目的基本思路进行了分析,这里直接给出完成代码:
typedef int STDataType;typedef struct Stack
{STDataType* a;int top;int capacity;
}ST;// 初始化和销毁
void STInit(ST* pst);
void STDestroy(ST* pst);// 入栈 出栈
void STPush(ST* pst, STDataType x);
void STPop(ST* pst);// 取栈顶数据
STDataType STTop(ST* pst);// 判空
bool STEmpty(ST* pst);
// 获取数据个数
int STSize(ST* pst);// 初始化和销毁
void STInit(ST* pst)
{assert(pst);pst->a = NULL;// top指向栈顶数据的下一个位置pst->top = 0;// top指向栈顶数据//pst->top = -1;pst->capacity = 0;
}void STDestroy(ST* pst)
{assert(pst);free(pst->a);pst->a = NULL;pst->top = pst->capacity = 0;
}// 入栈 出栈
void STPush(ST* pst, STDataType x)
{assert(pst);// 扩容if (pst->top == pst->capacity){int newcapacity = pst->capacity == 0 ? 4 : pst->capacity * 2;STDataType* tmp = (STDataType*)realloc(pst->a, newcapacity * sizeof(STDataType));if (tmp == NULL){perror("realloc fail");return;}pst->a = tmp;pst->capacity = newcapacity;}pst->a[pst->top] = x;pst->top++;
}void STPop(ST* pst)
{assert(pst);assert(pst->top > 0);pst->top--;
}// 取栈顶数据
STDataType STTop(ST* pst)
{assert(pst);assert(pst->top > 0);return pst->a[pst->top - 1];
}// 判空
bool STEmpty(ST* pst)
{assert(pst);return pst->top == 0;
}// 获取数据个数
int STSize(ST* pst)
{assert(pst);return pst->top;
}typedef struct
{ST pushst;ST popst;
} MyQueue;void myQueuePush(MyQueue* obj, int x);
int myQueuePop(MyQueue* obj);
int myQueuePeek(MyQueue* obj);
bool myQueueEmpty(MyQueue* obj);
void myQueueFree(MyQueue* obj);MyQueue* myQueueCreate()
{MyQueue* obj = (MyQueue*)malloc(sizeof(MyQueue));STInit(&(obj->pushst));STInit(&(obj->popst));return obj;
}void myQueuePush(MyQueue* obj, int x)
{STPush(&(obj->pushst), x);}int myQueuePop(MyQueue* obj)
{int front = myQueuePeek(obj);STPop(&(obj->popst));return front;
}int myQueuePeek(MyQueue* obj)
{if(STEmpty(&(obj->popst))){//导数据while(!STEmpty(&(obj->pushst))){int top = STTop(&(obj->pushst));STPush(&(obj->popst), top);STPop(&(obj->pushst));}}return STTop(&(obj->popst));
}bool myQueueEmpty(MyQueue* obj)
{return STEmpty(&(obj->pushst)) && STEmpty(&(obj->popst));
}void myQueueFree(MyQueue* obj)
{STDestroy(&(obj->pushst));STDestroy(&(obj->popst));free(obj);
}结尾
关于栈和队列的所有内容就到此结束了,下一节我们开始学习二叉树,谢谢你的浏览,希望可以给你带来帮助!!!
