Facenet(MTCNN+InceptionResnetV1)人脸考勤项目(有缺点,但可用)
背景介绍
这是一个 简单的人脸识别项目,用Flask在本地实现,使用最早的Facenet进行人脸检测,效果一般,鲁棒性不好,但是基本可以满足万人规模以内的人脸考勤需求。
细节说明
1、预训练模型可以直接用于人脸识别和特征提取,基本不需要从头训练。
2、可选数据增强,对图片预处理(增强亮度、对比度、锐度),可以明显改善识别效果。
可改善
1、针对戴眼镜等遮挡情况,鲁棒性较差,基本识别不了,所以同一个人可以多拍几张,包含戴眼镜、不戴眼镜(很多公司这么干的)
2、MTCNN 本身不会自动把人脸旋转到正对方向,但它的确提供了人脸五官关键点(五点坐标),后续可以基于这些关键点进行仿射变换(人脸对齐),把人脸旋转为“正脸”方向。
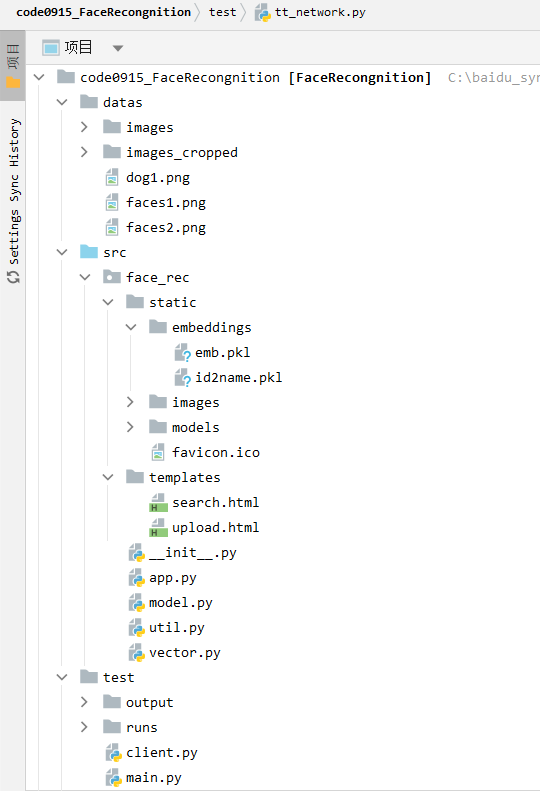
项目结构
code0915_FaceRecognition/
├── datas/ # 📂 原始数据
│ ├── images/ # 每个子文件夹是一个人的若干人脸图像(用于训练)(原始人脸照片)
│ ├── images_cropped/ # 用MTCNN裁剪后的人脸图像(已对齐)(训练模型前处理结果)
│ ├── faces.png # 测试图片
│ └── faces2.png # 测试图片
│
├── src/ # 📂 主模块(核心业务逻辑)
│ └── face_rec/
│ ├── static/ # Flask 静态文件夹(保存嵌入向量/图片)
│ │ ├── embeddings/ # 每张注册图像提取的特征向量(.npy)
│ │ ├── images/ # 裁剪后的上传的图像(原图/保存图)(原图的人脸区域的备份)
│ │ └── models/ # 模型文件(.pt)
│ ├── templates/ # Flask 模板文件(HTML页面)
│ ├── init.py # Python包初始化文件
│ ├── app.py # 🔥Flask服务主逻辑,注册路由/处理接口(比如上传图片、识别人脸等)
│ ├── model.py # 加载模型、提取特征等(MTCNN、人脸识别主网络InceptionResnetV1)
│ └── vector.py # 特征向量处理模块(匹配、相似度计算)(用欧式/余弦等)
│
├── test/ # 📂 测试模块(训练、测试用)
│ ├── output/ # 输出文件夹,存中间结果图等
│ ├── runs/ # TensorBoard日志目录
│ ├── client.py # ✅ 客户端测试代码(发起请求到服务)(验证部署的人脸识别服务是否能用)
│ ├── main.py # ✅ 启动 Flask 服务(app.py 的入口)(项目启动入口)
│ ├── tt_network.py # ✅ 测试识别特征距离(验证模型特征提取效果)(直接用 MTCNN + ResNet 提取图片向量,计算图片之间的欧式距离和余弦相似度)
│ ├── tt_training_v1.py # ✅ V1训练(使用Inception+分类器+ CrossEntropy)
│ ├── tt_training_v2.py # ✅ V2训练(自定义分类层 ClassifyLoss)
│ └── tt_training_v3.py # ✅ V3训练(使用 ArcFaceLoss = ArcMarginFaceLoss)
核心代码都放下面了
src/face_rec/model.py
"""加载模型、提取特征等(MTCNN、人脸识别主网络InceptionResnetV1)"""
# model.py
import os, random, torch
from datetime import datetimeimport numpy as np
# MTCNN 是 facenet_pytorch 中提供的唯一专门用于人脸检测的模型。
# MTCNN 通过多阶段卷积网络进行人脸检测,能够从图像中定位出人脸并提供关键点(眼睛、鼻子、嘴巴等)信息。
# InceptionResnetV1 是 facenet_pytorch 中提供的唯一的骨干网络。想使用其他骨干网路,需使用其他库(例如torchvision)来加载模型。
from facenet_pytorch import MTCNN, InceptionResnetV1class FaceRecModel:"""人脸识别模块:包括人脸检测、人脸图像裁剪、特征提取功能"""def __init__(self, root_dir):'''初始化:param root_dir: 模型文件和图像保存的根目录 src/face_rec/static'''# 指定设备(下面2句二选一)self.device = torch.device("cpu")self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化 MTCNN(人脸检测器)# 实例化 MTCNN对象时,facenet_pytorch 库已经提供了预训练好的 MTCNN 模型权重。不需要手动下载或训练它,它可以直接用于人脸检测self.mtcnn = MTCNN(image_size=160, # 输出的人脸图像大小(160x160)margin=0, # 在人脸区域外侧额外提取多少个像素点 # 在检测到的人脸区域外扩展多少像素(这里为0,不扩展)min_face_size=20, # 在当前数据集上,最小人脸尺寸,检测到的任何小于该尺寸的脸都会被忽略thresholds=[0.6, 0.7, 0.7], # 分类阈值 # MTCNN三个阶段(P→R→O)的分类阈值factor=0.709, # 图像金字塔缩放因子,用于提高检测精度(详见文档、GPT)post_process=True, # 是否进行后处理【会在检测出的人脸图像(crop 后)执行:转为 tensor → 归一化处理(标准化)】# post_process=True 时,虽然返回的张量(tensor)是经过后处理的,但保存的人脸图像并没有经过后处理,因此它是输入图像中人脸的真实表示keep_all=False, # 是否保留检测出来的所有人脸图像(True 保留所有;False,只保留一张)selection_method=None, # 这表示没有特殊的选择方法。(当 keep_all 为 False 时,会退回到 select_largest 的逻辑)select_largest=True, # 当selection_method=None时生效,True表示选择面积最大的人脸返回,False表示选择概率最大的人脸返回device=self.device # 运行设备(cuda,cpu))# 注意:keep_all=False 是 在 __call__ 或 forward() 时生效的,若是用self.mtcnn.detect的话,不会生效哦# 保存旧的 TORCH_HOME 环境变量值old_torch_home = os.environ.get('TORCH_HOME')# 设置 TORCH_HOME 路径为本地存储路径,以避免从默认位置下载预训练模型os.environ['TORCH_HOME'] = os.path.join(root_dir, 'models') # src/face_rec/static/models# 指定InceptionResnetV1 模型,指定预训练权重 'vggface2'(本地没有的话,会自动下载)# 这是加载 Facenet 的人脸识别主干网络 InceptionResnetV1,并使用已经在 VGGFace2 数据集上预训练好的权重。self.resnet = InceptionResnetV1(pretrained='vggface2').eval().to(self.device) # 并设置为推理(非训练)模式# 恢复原本的 TORCH_HOME 环境变量if old_torch_home is not None:os.environ['TORCH_HOME'] = old_torch_home# 设置保存图像的根目录(src/face_rec/static/images)self.save_root_dir = os.path.join(root_dir, "images")@torch.no_grad() # 禁用梯度计算,节省内存和加速推理def get_face_images(self, img, name, threshold=0.99-0.09):"""从图像中检测人脸,裁剪最大人脸并保存到本地,同时返回该人脸的张量表示:param img: 输入图像(PIL Image):param name: 子目录名称,用于将裁剪后的人脸图像保存到对应子文件夹:param threshold: 置信度阈值,小于该值的人脸将被忽略:return:face_tensor: 人脸的张量表示(形状为 [3, 160, 160],归一化后)save_path: 人脸图像保存路径(字符串)若未检测到人脸或置信度太低,返回 (None, None)"""save_path = None # 初始化人脸保存路径为空# 如果传入了 name(用于保存文件),准备保存路径if name is not None:save_dir = os.path.join(self.save_root_dir, name) # 构造保存目录路径 src/face_rec/static/images/nameif not os.path.exists(save_dir):os.makedirs(save_dir) # 如果目录不存在,则创建# 构造人脸文件保存的完整路径(带时间戳,避免重名)post_name = datetime.now().strftime("%Y%m%d_%H%M%S")save_path = os.path.join(save_dir, f"face_{post_name}.png")# 使用 MTCNN 对输入图像进行人脸检测,返回:# - batch_boxes: 人脸框坐标([x1, y1, x2, y2])# - batch_probs: 每张脸的置信度# - batch_points: 每张脸的关键点(眼、鼻、嘴角)batch_boxes, batch_probs, batch_points = self.mtcnn.detect(img, landmarks=True)# landmarks=True:启动关键点检测。【除了检测人脸框(bounding box)之外,还会额外返回该人脸的五个关键点的位置坐标】# detect方法会调用detect_face进行P-Net、R-Net、O-Net、预测 5 个关键点# 选择区域最大的人脸batch_boxes, batch_probs, batch_points = self.mtcnn.select_boxes(batch_boxes, batch_probs, batch_points, img, method="largest") # method="largest"表示 选择面积最大的框# mtcnn.select_boxes 方法仅仅是选择区域最大的人脸,并不会自动旋转人脸使其正面朝向。# 它的作用是返回一个人脸框(bounding box)和对应的置信度,以及人脸关键点信息。此方法本身并不涉及人脸的姿态调整或旋转。# 如果你希望对人脸进行旋转,以确保人脸是正面的,你需要在选定人脸后,使用旋转算法进行处理。# 常见的方法是使用人脸的关键点(如眼睛位置)来计算旋转角度,然后对人脸进行旋转,使其朝向正面。# 考虑到考勤系统,要求数据标准化,不允许歪脸数据,而且大家都是站立拍照打卡与信息录入,所以没问题的,节省算力# 判断是否检测成功,以及置信度是否大于设定阈值if batch_boxes is None or batch_probs < threshold: return None, None# 提取、裁剪人脸区域(输出为 Tensor),保存图像到 save_path# mtcnn.extract 用于根据检测到的人脸框(bounding boxes)从原始图片中裁剪出人脸区域,# 并对裁剪结果做后续处理:缩放指定尺寸,Tensor归一化,保存图片到save_pathface = self.mtcnn.extract(img, batch_boxes, save_path=save_path)return face, save_path # 返回裁剪后的人脸 Tensor 以及 人脸保存的路径@torch.no_grad() # 禁用梯度计算,节省内存和加速推理def get_face_features(self, face_img):"""提取人脸图像的特征向量(提取128维特征向量 face_embedding):param face_img: 输入人脸图像张量(形状必须为 [3, 160, 160] 或 [B, 3, 160, 160]):return: numpy.ndarray 类型的 128 维向量,用于人脸识别或比对"""dim = face_img.dim() # 获取输入 Tensor(人脸图像) 的维度if dim == 3:# 如果输入是单张人脸([3, 160, 160]),添加一个 batch 维度,变为 [1, 3, 160, 160]face_img = torch.unsqueeze(face_img, 0) # 等价于 face_img = face_img[None, ...]elif dim == 4:# 如果输入是批量格式([B, 3, 160, 160]),不处理face_img = face_imgelse:# 如果不是上述两种形状,说明格式错误raise ValueError("数据格式异常!")# bug修复:确保同设备,同数据类型精度face_img = face_img.to(self.device).to(dtype=torch.float32)# 将人脸输入到 InceptionResnetV1 中,提取特征向量# detach(): 从计算图中分离,避免梯度传播(毕竟人脸检测 和 人脸识别 是2个任务,不能互相影响)# numpy()[0]: 取出第一个样本的 numpy 数组(shape: [128])return self.resnet(face_img).detach().cpu().numpy()[0]
src/face_rec/vector.py
"""特征向量处理模块:用于保存人脸特征向量、建立索引、搜索匹配人脸(支持欧氏距离,余弦相似度即向量内积)"""
# vector.py
import os, pickle# conda install -c pytorch faiss-cpu 或者 pip3 install faiss-cpu
import faiss # Facebook AI 提供的快速向量索引库,支持高效相似度搜索
import numpy as npclass VectorService:"""向量服务类:用于向量的增量保存、索引构建、匹配搜索等功能"""def __init__(self, root_dir):"""模块初始化:param root_dir: 根目录路径,用于保存 embeddings 数据和映射表 src/face_rec/static"""# 向量保存的目录 src/face_rec/static/embeddingsself.root_dir = os.path.join(root_dir, "embeddings")# 若目录不存在则创建if not os.path.exists(self.root_dir):os.makedirs(self.root_dir)self.dims = 512 # 设置向量维度,默认用512(和 ArcFace 输出维度一致;如果用 Facenet 通常是128)# 向量数据保存路径(pkl 格式)self.embedding_file = os.path.join(self.root_dir, "emb.pkl") # src/face_rec/static/embeddings/emb.pklif os.path.exists(self.embedding_file):# 若向量数据存在,则加载已有向量数据(历史记录) 形状=(n,d)self.embeddings = np.asarray(self.load_pickle_data(self.embedding_file)).astype('float32')else:# 若向量数据不存在,则初始化一个空的向量矩阵(第一行为0向量,防止索引为空时报错)self.embeddings = np.zeros((1, self.dims), dtype='float32')# 创建 Faiss 向量索引对象(HNSW:层次图搜索,适合高维向量,支持快速 ANN 检索)# 使用 METRIC_INNER_PRODUCT “内积” 作为相似度的度量方式(若想用欧氏距离,可替换为 METRIC_L2)self.face_index = faiss.index_factory(self.dims, 'HNSW16', faiss.METRIC_INNER_PRODUCT)# faiss.index_factory 是 FAISS 中的一个非常方便的函数,用来快速构造各种类型的向量索引结构,无需手动设置每一步self.face_index.add(self.embeddings) # 向索引中加入已有向量 (n,d)# 加载 id 与名字之间的映射关系(方便后续 根据向量返回身份信息)self.idx_2_name_file = os.path.join(self.root_dir, 'id2name.pkl') # src/face_rec/static/embeddings/id2name.pklif os.path.exists(self.idx_2_name_file):# 若存在映射关系(字典),直接加载self.idx_2_name = self.load_pickle_data(self.idx_2_name_file)else:# 否则,创建空字典self.idx_2_name = {}# 当前索引的计数器(从已有数据的长度继续增长)self.user_idx = len(self.idx_2_name) + 1def add_embedding(self, vector, name):"""添加新的向量及其身份信息到索引库中:param vector:输入向量(1D 或 2D 均可):param name:该向量对应的身份名称(字符串):return: None"""# 向量维度检查 & 转换格式为 [1, 512]vector = np.asarray(vector, dtype='float32').reshape((1, self.dims))# 更新 embedding,存储到FAISS索引对象self.embeddings = np.concatenate([self.embeddings, vector], axis=0) # 向下追加一个向量self.face_index.add(vector) # 把新向量 添加到 向量索引对象# 保存向量到磁盘self.save_pickle_data(self.embedding_file, self.embeddings)## 映射关系的保存(更新索引与身份映射关系)self.idx_2_name[self.user_idx] = nameself.user_idx += 1self.save_pickle_data(self.idx_2_name_file, self.idx_2_name) # 持久化,保存在磁盘 pkl文件def search(self, vector, thred=0.8):"""通过相似度搜索匹配最相近的向量:param vector:查询向量(1维或2维均可):param thred:相似度阈值(越高越严格):return:若匹配成功返回身份字符串;否则返回 None"""vector = np.asarray(vector, dtype='float32').reshape((1, self.dims)) # 标准化格式# 在索引中搜索最相近的1个向量prob, idx = self.face_index.search(vector, 1) # 获取最匹配的向量对应索引以及相似度,返回两个数组# 提取相似度得分、对应索引prob = prob[0][0]idx = idx[0][0]# 阈值判断,相似度不足则判定为非同一人if prob < thred:return Noneelse:# 否则,返回匹配到的名称return self.idx_2_name[idx]@staticmethoddef load_pickle_data(path):"""从磁盘加载 pickle 文件:param path:要打开的文件路径(例如 "xxx.pkl"):return:Python 对象"""with open(path, 'rb') as r: # 'rb' 表示以 只读模式打开一个二进制文件return pickle.load(r)@staticmethoddef save_pickle_data(path, data):"""保存对象到 pickle 文件:param path:要保存的文件路径(例如 "xxx.pkl"):param data:要保存的 Python 对象(如字典、列表、numpy数组等):return:None"""with open(path, 'wb') as w: # 'wb' 表示 以二进制写入模式打开文件# 将 data 对象序列化后写入 data.pkl,原来文件的内容会被完全清空并覆盖pickle.dump(data, w)
src/face_rec/util.py
# coding=utf-8
# encoding: utf-8
"""
Author:刘源
Createtime:2025/07/09 11:35
Updatetime:
Description:工具类
"""
import cv2, os
import numpy as np
from PIL import Image, ImageEnhancedef preprocess_image(image):# 亮度和对比度增强(使用PIL)enhancer = ImageEnhance.Brightness(image)image_bright = enhancer.enhance(1.3) # 提升亮度enhancer_contrast = ImageEnhance.Contrast(image_bright)image_contrast = enhancer_contrast.enhance(1.2) # 增加对比度# 锐化处理(使用PIL)enhancer_sharp = ImageEnhance.Sharpness(image_contrast)image_sharpened = enhancer_sharp.enhance(2.0) # 提高锐度# 转换回 NumPy 数组image_sharpened = np.array(image_sharpened)return image_sharpened# 测试代码
if __name__ == "__main__":# 图像路径image_path = r'C:\baidu_sync\BaiduSyncdisk\FaceData\liuyuan1.jpg'# 检查路径if not os.path.exists(image_path):print(f"文件路径错误或文件不存在: {image_path}")# 读取图像image = Image.open(image_path)image = image.convert("RGB")# 预处理图像processed_image = preprocess_image(image,)# 显示原图和处理后的图像cv2.imshow('Original Image', np.array(image))cv2.imshow('Processed Image', processed_image)# 等待按键退出cv2.waitKey(0)cv2.destroyAllWindows()
src/face_rec/app.py
"""Flask服务主逻辑,注册路由,处理接口(比如上传图片、识别人脸等)"""
# app.py
import base64, io, os
from PIL import Image, ImageOps
from flask import Flask, request, render_template, jsonify# 加载模型类和向量服务类
from .model import FaceRecModel
from .vector import VectorService
from .util import preprocess_image # 目前都没用上# 设置静态资源目录路径(src/face_rec/static)
__static_dir_path__ = os.path.join(os.path.dirname(os.path.abspath(__file__)), "static")# 创建 Flask 应用,static_folder='static' 是默认配置
app = Flask(__name__, static_folder='static') # Flask 会使用 __name__ 的值来推断出应用程序的根路径# 服务端放宽请求体大小限制(开发调试可用)
app.config['MAX_CONTENT_LENGTH'] = 20 * 1024 * 1024 # 允许最大20MB# 实例化 人脸识别模型(MTCNN + InceptionResnetV1)
model = FaceRecModel(root_dir=__static_dir_path__)# 实例化 向量管理服务(包括保存向量、匹配查询等功能)
vector = VectorService(root_dir=__static_dir_path__)# 首页(纯文本返回)
@app.route("/")
@app.route("/index")
def index():return "欢迎使用简易人脸检索系统!" # 测试服务器是否正常运行# 定义网页加载的图标(定义 favicon 路由,避免浏览器请求时 404 报错)
@app.route("/favicon.ico")
def favicon():return app.send_static_file("favicon.ico")# ---------------------- 人脸图像上传与注册 ----------------------
@app.route("/face/image/upload", methods=['GET', 'POST'])
def upload():if request.method == 'GET':return render_template("upload.html") # 返回上传页面else:# 1. 参数提取:姓名 + 上传图像文件name = request.values.get('name')file = request.files.get('file')# 2. 参数检查if not (name and file):return render_template("upload.html", msg='not (name and file), 必须给定有效入参!')# 3. 将文件流转换为 RGB 图像(PIL 格式)img = Image.open(io.BytesIO(file.stream.read()))img = img.convert("RGB") # PIL.Image.Image# 根据图像的 EXIF Orientation 信息,自动旋转图像到照片EXIF记录的拍摄方向(即“人眼看着是正的”)img = ImageOps.exif_transpose(img) # 避免由于 EXIF 方向错误而导致的 landmark 错位问题# EXIF方向必须在加载后矫正,否则后续视觉任务都会出错,这一步是图像预处理中非常关键的一环# 4. 图像预处理(增强亮度、对比度),也可以考虑另一种逻辑:先不预处理,等图像识别失败时再捕获异常,重新预处理# img = preprocess_image(img)# 4. 针对RGB图像(img)进行人脸区域的检测、得到人脸图像:使用 MTCNN 检测并裁剪最大人脸(返回Tensor + 图像保存路径)img, save_path = model.get_face_images(img, name)# 5. 若未检测到人脸,返回前端页面if img is None:return render_template("upload.html", msg='img is None,必须给定有效人脸,当前图像没有检测出人脸区域!')# 6. 提取当前人脸的特征向量(128维)embedding = model.get_face_features(img)if embedding is None:return render_template("upload.html", msg='embedding is None, 必须给定有效人脸,当前图像没有检测出人脸区域!')# 7. 将向量、name、图像路径进行保存(实际应用中一般是保存到数据库中、同时更新向量检索服务)vector.add_embedding(embedding, name)# 8. 返回结果return jsonify({'code': 0,'msg': '添加成功!'})# ---------------------- 人脸图像比对检索 ----------------------
@app.route("/face/image/search", methods=['GET', 'POST'])
def search():if request.method == 'GET':return render_template("search.html") # 返回搜索页面else:# 1. 提取上传图像file = request.files.get('file')# 2. 参数检查if not file:return render_template("search.html", msg='not file,必须给定有效入参!')# 3. 将文件流转换为 RGB 图像(PIL 格式)img = Image.open(io.BytesIO(file.stream.read()))img = img.convert("RGB")# 根据图像的 EXIF Orientation 信息,自动旋转图像到照片EXIF记录的拍摄方向(即“人眼看着是正的”)img = ImageOps.exif_transpose(img) # 避免由于 EXIF 方向错误而导致的 landmark 错位问题# EXIF方向必须在加载后矫正,否则后续视觉任务都会出错,这一步是图像预处理中非常关键的一环# 4. 图像预处理(增强亮度、对比度),也可以考虑另一种逻辑:先不预处理,等图像识别失败时再捕获异常,重新预处理# img = preprocess_image(img)# 4. 针对RGB图像(img)进行人脸区域的检测、得到人脸图像img, _ = model.get_face_images(img, None)# 5. 若人脸图像不存在,直接传回前端if img is None:return render_template("search.html", msg='img is None,必须给定有效人脸,当前图像没有检测出人脸区域!')# 6. 提取当前人脸对应的向量:提取人脸特征embedding = model.get_face_features(img)if embedding is None:return render_template("search.html", msg='embedding is None,必须给定有效人脸,当前图像没有检测出人脸区域!')# 7. 向量检索:使用向量检索服务匹配身份name = vector.search(embedding)if name is None:return render_template("search.html", msg='name is None,当前人脸没有匹配的数据!')# 8. 返回结果return jsonify({'code': 0,'msg': 'search success!','name': name})# ---------------------- 支持 base64 图像格式的人脸识别接口 ----------------------
@app.route('/face/image/detect', methods=['POST'])
def detect():# 1. 参数提取# _args = request.values # 读取表单数据【bug修复:403,表单的单字段长度超过限制】_args = request.get_json() # 读取JSON数据【bug修复:403,表单的单字段长度超过限制】# 图像参数提取及解码转换img = _args.get('img') # base64 编码的图像字符串if img is None:return jsonify({'code': 202, 'msg': '必须给定img参数,必须是base64转换后的图像字符串。当前未给定img参数。'})# 2. base64 解码img = base64.b64decode(img)# 3. 将文件流转换为RGB图片img = Image.open(io.BytesIO(img)).convert("RGB")# 根据图像的 EXIF Orientation 信息,自动旋转图像到照片EXIF记录的拍摄方向(即“人眼看着是正的”)img = ImageOps.exif_transpose(img) # 避免由于 EXIF 方向错误而导致的 landmark 错位问题# EXIF方向必须在加载后矫正,否则后续视觉任务都会出错,这一步是图像预处理中非常关键的一环# 4. 图像预处理(增强亮度、对比度),也可以考虑另一种逻辑:先不预处理,等图像识别失败时再捕获异常,重新预处理# img = preprocess_image(img)# 4. 针对img进行人脸区域的检测、得到人脸图像: 检测人脸(最大人脸)img, _ = model.get_face_images(img, None)# 5. 若人脸图像不存在,就直接传回前端if img is None:return jsonify({'code': 203, 'msg': '当前传入的图像中不存在人脸区域,请重新传入新的图像。'})# 6. 提取当前人脸对应的向量(人脸特征)embedding = model.get_face_features(img)if embedding is None:return jsonify({'code': 203, 'msg': '当前传入的图像中不存在人脸区域,请重新传入新的图像。'})# 7. 向量检索:检索数据库中最相似的人脸name = vector.search(embedding)if name is None:return jsonify({'code': 201, 'msg': '在数据库中未找到和当前人脸匹配的用户!'})# 8. 结果返回return jsonify({'code': 200,'msg': 'search success!','name': name})
test/main.py
"""启动 Flask 服务(app.py 的入口)(项目启动入口)"""
# main.py
# 这个人脸识别系统是开放集(Open-Set)人脸识别任务:系统需要判断一个人脸是否是“已注册用户”之一,如果不是,给出“未识别”或“无匹配”的提示import os, sys# 这会让程序忽略这个冲突继续运行,但可能导致性能下降或不可预料的错误。
os.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"print(os.path.dirname(__file__)) # C:\baidu_sync\BaiduSyncdisk\PythonFiles\CV_liuyuan\code0915_FaceRecongnition\testsys.path.append(os.path.join(os.path.dirname(__file__), "..", "src"))
from face_rec.app import app# sys.path.append() 是 Python 中常用的一种动态添加模块搜索路径的方法,用于让 Python 能够找到不在默认目录下的模块(比如你的 face_rec 包)
# 运行某个脚本时,Python只会在下面的目录里找模块:当前运行脚本所在目录,标准库路径(如C:\Python3.11\Lib),环境变量 PYTHONPATH 指定的路径
# 可以用 sys.path.append() 来动态添加路径if __name__ == '__main__':# exit()# app.run("0.0.0.0", 9999, debug=True) # 可浏览器页面展示报错信息# app.run("192.168.1.100", 9999,) # 换个ipapp.run("0.0.0.0", 9999, debug=False, use_reloader=False) # 可断点调试
main.py 运行后:
1、导入并执行 app.py 的全部内容(包括初始化模型、加载服务)
app.py中的FaceRecModel被实例化,模型被加载到了内存;
app.py中的VectorService 被实例化,并作为 vector 保存在全局作用域中。
2、启动 Flask Web 服务,监听 0.0.0.0:9999,并且阻塞运行直到手动关闭(比如 Ctrl+C)
因此,app.py 中的代码就一直运行着,服务常驻内存状态。
整个 Flask 服务运行期间,vector 对象是常驻内存的单例实例。
只要 Flask 没停止,这个 vector(包括它管理的向量库)就不会释放或重置。
你后续通过 /upload 或 /search 的接口调用时,都是在和这个同一个 vector 实例打交道(单进程时)。
在并发场景1下(比如用 gunicorn + 多个 worker)(gunicorn -w 4 app:app 启动 4 个 worker),每个进程会有自己的 vector 实例。
此时全局变量不共享,每个进程都有一份拷贝,各自维护一个向量集合、一个计数器,彼此互不影响。
严重后果包括但不限于:
计数器混乱(如注册人数、访问次数);
检索数据不一致(有的进程保存了向量,有的没有);
用户A注册的向量,用户B访问时却查不到(因为走的是另一个worker)。
在并发场景1下,需要【持久化 + 共享机制】:
方案一:持久化存储 + 启动加载;
方案二:使用独立服务来管理向量(推荐)
在并发场景2下:只启用了一个 worker,但是有多个客户端“同时”访问服务(如几百人并发上传或检索)
gunicorn -w 1 app:app (一个 worker ),是个典型的【Flask 单进程 + 多并发】问题
此时虽然只有一个进程,但是 Gunicorn 使用的是 异步/多线程 或 多协程 方式处理多个客户端请求,几百人同时访问,就会同时进入这个进程排队或并发执行。
此时虽然全局变量 vector 是共享的(因为进程只有一个),但访问它是并发的!
多个请求同时在读写 vector,就有可能产生竞态条件(race condition) 或 数据覆盖、重复注册、搜索出错等问题。
即使是单 worker,多并发下你也需要:
方案1:线程锁 threading.Lock(简单粗暴)
方案2:使用队列 + 后台线程(更适合高并发、避免阻塞主线程)
方案3:使用 faiss 的 IndexIDMap 或 IndexFlat 并明确控制 add 操作(有时向量库本身支持并发,但你仍需管理元数据,如 name、id 对应表)
test/client.py
"""客户端测试代码(发起requests请求到服务)(验证部署的人脸识别服务是否能用,是否支持base64图像格式)"""
# client.py
import base64, requests, time
from io import BytesIO
from pathlib import Path
import cv2 as cv
import numpy as np
from PIL import Image, ImageOps
from datetime import datetimedef fetch_person_name(img):"""给定一张图片,调用远程人脸识别服务,返回识别到的人员姓名。:param img:输入图像(OpenCV格式,BGR):return:识别出的姓名字符串,或 None"""# NOTE: 这里可以先使用opencv的简单的人脸检测方法(基于Haar级联分类器)进行一个过滤,如果存在人脸,再调用服务器模型# OpenCV有一个经典的人脸检测方法(基于 Haar 级联分类器 Haar Cascade Classifier)。它不依赖 GPU,速度较快,适合初学者pil_img = Image.fromarray(np.asarray(img)[:, :, ::-1], "RGB") # OpenCV → PIL 图像格式转换# pil_img = Image.fromarray(cv.cvtColor(img, cv.COLOR_BGR2RGB)) # 等价写法# ✅ 将 PIL 图像保存到内存中(二进制缓冲区),格式为 PNGbuf = BytesIO()pil_img.save(buf, format='png')# ✅ 获取二进制图像数据img_data = buf.getvalue()# ✅ 将图像二进制数据进行 base64 编码,转成字符串img_data = base64.b64encode(img_data).decode('utf-8')print("base64的字符串图片的长度:", len(img_data)) # base64的字符串图片的长度:583436# ✅ 向远程服务发送 POST 请求,携带 base64 编码图像response = requests.post(# 'http://121.40.96.93:9999/face/image/detect', # 外网地址(可用来部署线上服务)'http://127.0.0.1:9999/face/image/detect', # 本地服务地址(用于开发调试)# data={'img': img_data} # 表单形式提交图像数据【bug修复:403,表单的单字段长度超过限制】json={'img': img_data}, # JSON 格式提交数据【bug修复:403,表单的单字段长度超过限制】headers={'Content-Type': 'application/json'} # 声明是JSON 格式提交数据【bug修复:403,表单的单字段长度超过限制】)# ✅ 处理响应结果if response.status_code == 200:data = response.json() # 转为 JSON 格式字典if data['code'] == 200:return data['name'] # 返回识别到的名字else:print(data) # 打印服务端返回的错误信息return Noneif __name__ == '__main__':# ✅ 本地单张图像测试(从文件中读取一张人脸照片)# img = cv.imread(fr'..\datas\images\ldh\img0.jpeg')img = cv.imread(r'..\datas\images\zxc\img0.jpeg')# ✅ 调用函数,获取识别到的人名name = fetch_person_name(img)print(name)# exit()# ✅ 如果识别成功,将姓名绘制在图像上方if name is not None:# 画图cv.putText(img, name, (5, 50), cv.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255),thickness=2) # BGR,红色255# ✅ 显示图像cv.imshow('img', img)cv.waitKey(0) # 等待任意键cv.destroyAllWindows()
说明:为什么不能直接用 OpenCV 的图像数据或 PIL 图像对象直接传给接口?为什么还要用 base64 编码?
requests 接口(特别是 HTTP POST)无法直接发送图片对象(如 numpy 或 PIL.Image),只能发送:
字节流(bytes)
字符串(如 base64 编码字符串)
文件(通过 multipart 表单上传)
OpenCV 读进来的图像是 numpy.ndarray 类型,是内存中的矩阵数据,不是一个图片文件,也不是标准的字节格式。
PIL.Image 是一个对象,不是图片的字节流,它只是一个类,包含图片像素信息和处理方法。
总结:不能直接把 cv.imread() 的 ndarray 或 Image.open() 的 PIL.Image 对象当成 requests.post() 的参数。
必须转成字符串(如 base64)或字节流(如文件)才可以。
src/face_rec/templates/search.html
<!--人脸图像检索表单页的模板-->
<!DOCTYPE html>
<html lang="zh-CN"> <!-- 设置页面语言为中文(简体) --><head><meta charset="UTF-8"> <!-- 设置网页的字符编码为 UTF-8,支持中文 --><title>人脸检索</title> <!-- 网页标题:浏览器标签页上显示 -->
</head><body><h1>员工人脸打卡系统(人脸检索)</h1><!-- 若后端传递了 msg(通常是错误或提示信息),则显示为红色加粗字体 -->{% if msg %}<strong style="color:red">{{msg}}</strong>{% endif %}<!-- 上传表单 --><!-- method="POST" 表示表单提交方式为 POST --><!-- action="/face/image/search" 表示提交到后端对应的 Flask 路由 --><!-- enctype="multipart/form-data" 表示表单中包含文件上传字段(如图像) --><form method="POST" action="/face/image/search" enctype="multipart/form-data"><!-- 文件选择框:上传图像文件 -->图像:<input type="file" name="file"/> <br/><br/><!-- 提交按钮 --><input type="submit" name="submit" value="检索"/></form>
</body>
</html>
src/face_rec/templates/upload.html
<!-- upload.html 人脸图像录入表单页的模板 --><!DOCTYPE html>
<html lang="zh-CN"> <!-- 设置页面语言为中文(简体) --><head><meta charset="UTF-8"> <!-- 设置网页的字符编码为 UTF-8,支持中文 --><title>人脸录入</title> <!-- 网页标题:浏览器标签页上显示 -->
</head><body><h1>员工人脸打卡系统(人脸录入)</h1><!-- 若后端传递了 msg(通常是错误或提示信息),则显示为红色加粗字体 -->{% if msg %}<strong style="color:red">{{msg}}</strong>{% endif %}<!-- 上传表单 --><!-- method="POST" 表示表单提交方式为 POST --><!-- action="/face/image/upload" 表示提交到后端对应的 Flask 路由 --><!-- enctype="multipart/form-data" 表示表单中包含文件上传字段(如图像) --><form method="POST" action="/face/image/upload" enctype="multipart/form-data"><!-- 文本输入框:输入姓名 -->姓名:<input type="text" name="name"/> <br/><br/><!-- 文件选择框:上传图像文件 -->图像:<input type="file" name="file"/> <br/><br/><!-- 提交按钮 --><input type="submit" name="submit" value="录入"/></form>
</body>
</html>