binlog与Maxwell 与 慢查询
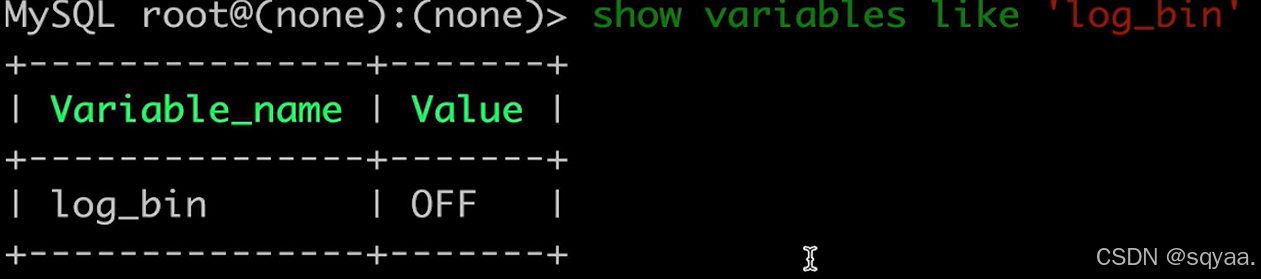
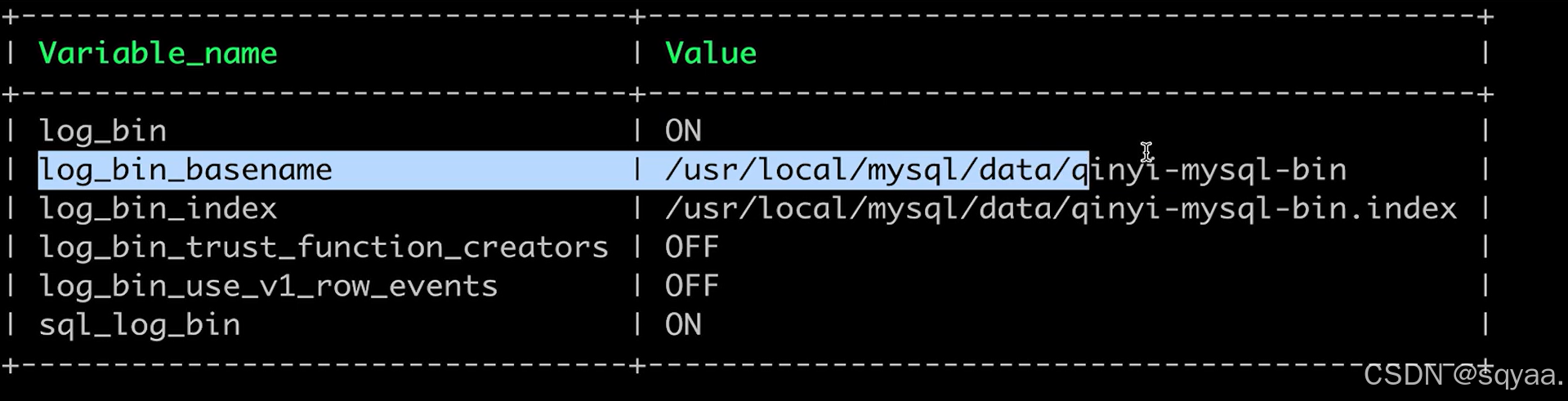
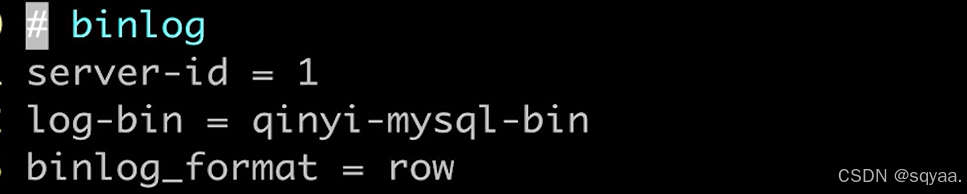
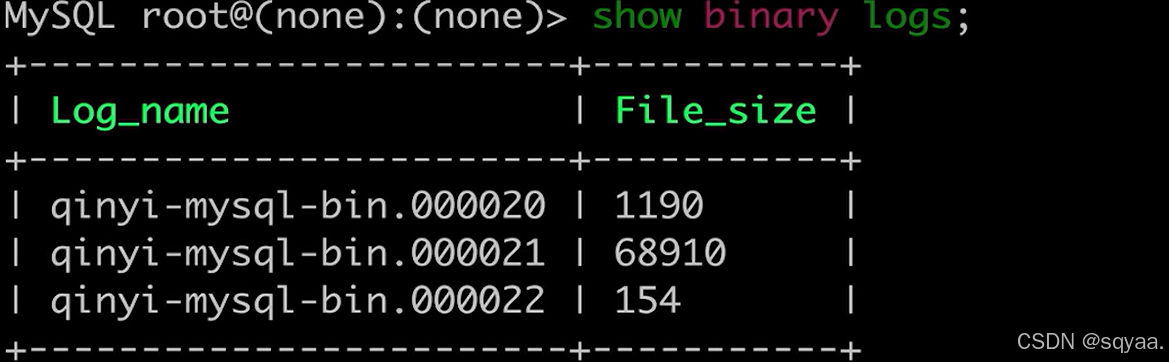
mysql默认不开启binlog,以事件形式保存
Binlog 基础概念
Binlog(二进制日志)是 MySQL 服务器的一个重要功能,binlog是Server层日志,用于复制和恢复,它记录:(表结构变更,表数据修改)
所有数据库和表结构的修改
所有数据修改操作(INSERT、UPDATE、DELETE)
但不会记录 SELECT 或 SHOW 这类查询操作
Binlog 的三种记录模式
| 模式 | 特点 |
|---|---|
| Statement | 记录造成数据变更的SQL语句 速度性能高可能会导致数据不一致。比如randomuuid每次值都不一样 |
| Row | 记录每一行数据的变更细节 占用大量磁盘空间效率低,比如对全表进行updata,需要记录全表数据,但是statement只需要记录一条update |
| Mixed | 混合模式,根据操作自动选择使用Statement或Row模式 一般语句使用statement来提高性能,无法重放的话就使用row |
Maxwell 的安装与使用
安装配置步骤
从官网 Maxwell's Daemon 下载 Maxwell
解压:
tar -xvf maxwell-1.41.0.tar.gz设置 Maxwell 数据库和用户权限:
-- 创建maxwell元数据库 CREATE DATABASE maxwell;-- 创建maxwell用户 CREATE USER 'maxwell'@'%';-- 设置密码 ALTER USER 'maxwell'@'%' IDENTIFIED WITH mysql_native_password BY 'maxwell';-- 授予必要权限 GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'maxwell'@'%'; GRANT ALL PRIVILEGES ON maxwell.* TO 'maxwell'@'%';
启用自动提交功能
修改 MySQL 配置文件
/etc/my.cnf:[mysqld] autocommit = 1然后重启 MySQL 服务。
启动 Maxwell
启动前开启mysql的自动提交功能
bin/maxwell --user='maxwell' --password='maxwell' --host='127.0.0.1' --producer=stdoutBinlog 应用场景
系统级应用:
主从复制
数据恢复
业务级应用:
数据收集与分析
实时数据同步
主库写binlog,从库I/O线程拉取,SQL线程重放。
大事务对binlog可能导致复制延迟,解决方案包括拆分事务、调整参数等。基于binlog的数据同步方案Maxwell等中间件原理,Kafka作为消息队列,消费者处理逻辑。
典型的数据流架构:
tMySQL → Maxwell → Kafka → 业务服务(Service A, Service B...)
Maxwell 作为生产者将 binlog 转换为 JSON 格式发送到 Kafka,各业务服务作为消费者处理这些数据变更。
慢查询
前言
优化接口那些活,造成接口延迟很大一部分原因就是慢查询。通过定位就可以找到。慢查询危害就是慢查询会消耗CPU与内存资源影响数据库的整体性能;也会把暴漏在外的ftp接口拖慢速度导致用户体验较差;很多慢查询是由于行锁升级成表锁会造成dml操作阻塞(查询更新插入)
(常见ddl操作是指create创建表索引数据库之类 alter修改表结构 drop删除表索引或者数据库, 也就是创建删除修改数据库中的表 索引 视图等对象)
什么情况行锁会升级成表锁
| 危害类型 | 具体影响 |
|---|---|
| CPU & 内存资源消耗 | 长时间运行的 SQL 会持续占用 CPU 和内存,导致其他查询变慢,甚至触发 OOM(内存溢出)。 |
| I/O 压力增大 | 慢查询可能涉及全表扫描或大量数据读取,导致磁盘 I/O 飙升,影响整个数据库的吞吐量。 |
| 锁竞争加剧 | 某些慢查询可能持有行锁较长时间,甚至升级为表锁,阻塞其他 DML(增删改)操作。 |
| DDL 阻塞风险 | 长时间运行的查询可能阻塞 ALTER TABLE 等 DDL 操作,导致表结构变更失败或超时。 |
| 接口响应变慢 | 如果业务接口依赖数据库查询,慢查询会导致 HTTP/FTP/RPC 接口延迟,用户体验下降。 |
| 连接池耗尽 | 慢查询占用数据库连接时间过长,可能导致连接池被占满,新请求无法获取连接而报错。 |
前置工作:mysql默认不开启慢查询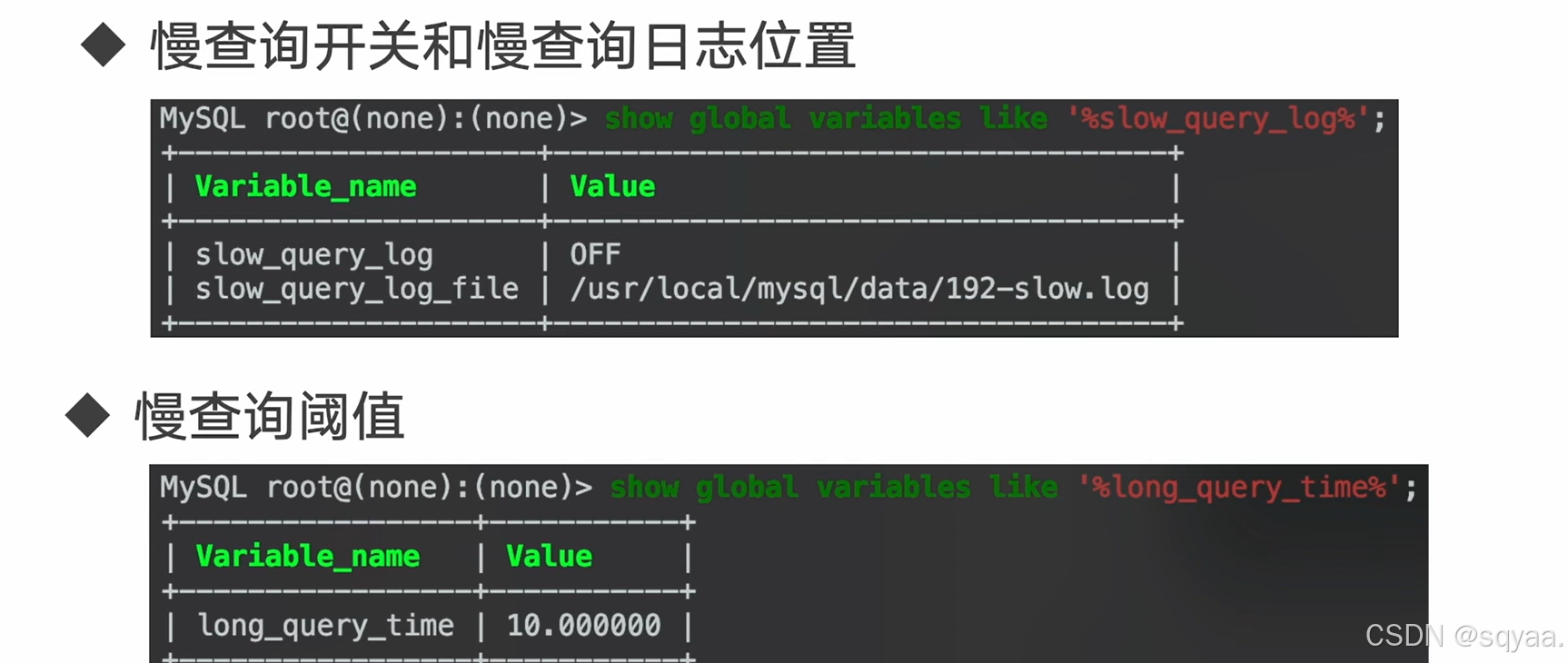
| 参数名 | 值 | 含义与用途 |
|---|---|---|
slow_query_log | 1 | 启用慢查询日志功能,MySQL 会记录执行时间超过 long_query_time 的查询。 |
long_query_time | 0.2 | 定义慢查询的时间阈值(单位:秒),执行时间超过 0.2 秒的查询会被记录到慢查询日志。 |
log_queries_not_using_indexes | 1 | 记录未使用索引的查询,即使它们的执行时间未超过 long_query_time 也会被记录。 |
具体 操作
✅单表数据量太大普通查询或者limit深分页较慢
深分页是指从很后面进行分页,分页的·深度很高。大量回表带来的消耗,很难优化,最好从业务场景,比如最多只能查看最近三个月的数据从而控制分页深度或者直接分区分表。
1.优化传统OFFSET分页的方法:快速定位到起始ID,然后只读取需要的10条记录
SELECT * FROM articles ORDER BY id LIMIT 10000, 10;MySQL需要先读取10010条记录(10000+10),然后排序这些记录,最后只返回第10001-10010条记录,前10000条记录被白白读取和丢弃,浪费大量I/O和CPU资源
SELECT * FROM articles WHERE id >= (SELECT id FROM articles ORDER BY id LIMIT 10000, 1) LIMIT 10;2.键值分页
处理深分页问题时候也可以采用键值分页来解决,比如按照时间来排序,就以时间戳为键值,每次查询只查询大于这个值的部分数据,这样就不需要全表扫描。
-- 第一页 SELECT * FROM users WHERE status = 'active' ORDER BY created_at DESC LIMIT 10;-- 后续页 (假设上一页最后一条记录的created_at是 '2023-05-15 14:30:00') SELECT * FROM users WHERE status = 'active' AND created_at < '2023-05-15 14:30:00' ORDER BY created_at DESC LIMIT 10;
✅无法使用索引进行orderby就会成为filesort,排序缓冲区大小,如果小于这个大小,就会走内存快排序,否则是文件的归并排序涉及文件的磁盘交换。排序缓冲区大小决定了排序操作是在内存中完成还是需要使用磁盘临时文件。
出现filesort主要是因为:
💡排序字段没加索引;
💡使用多字段进行排序,由于规则不同既有升序又有倒序,比如排行榜先按照积分最高在安装参与时间最小的进行排序,这种很难进行优惠,解决方法就算不进行实时更新,每天或者半天更新一次,后台根据大数据进行,不直接使用orderby
查询字段没有添加索引或者没有利用好索引导致全表扫描,这可以使用explian去看。。
覆盖索引(一个索引包含满足查询所需要的所有列,这样查询的时候数据库引擎只需要在索引中查找数据不用回表读取其他列的数据,能加快查询速度),把查询中经常用到的列都放进索引里面,查询时候直接从索引拿到数据,不用回表进行查询。也就是在数据库字段设计层面降低慢查询概率,其次还有避免大字段(很长文本大图片数据等等占用大量内存与io)还有冗余字段