Dify快速搭建问答系统
Dify快速搭建问答系统
简单记录下Dify系统的部署,以及可能遇到的各种问题,然后演示一下如何快速的搭建一个问答系统。
为什么用Dify
首先回答为什么用大模型的方案。在没有大模型之前,我们只能把问题和答案存储在数据库中,然后通过模糊检索的方式去检索问题。由于是模糊检索,所以检索的准确度可能不高,但是运用大模型的语义理解,就可以进一步的去理解问题,从而匹配到知识库里的内容。
然后为什么Dify,首先,这个是国产的,其次,这个可以私有化部署,而且是Apache2.0的协议,可以商用。这样做公司内部的应用就变得可行。
这个月Coze也开源了,但尚无稳定版本,而且刚开始的版本Bug还会有一些,所以也建议看一下Coze,对比下两个环境的差异。
Dify最近更新的也很频繁,到目前为止已经更新到了1.7这个版本,这个随笔也是围绕这个版本。
为了演示效果,我这里用的还是吃鸡游戏的场景,具体业务中可以替换成自己的实际场景。
此篇我用的是Macos系统,在Windows下部署也不会有太大的差异,主要是把WSL部署好,其它步骤不会差太多。
安装Docker
在MacOS下安装Docker Desktop相对简单些,直接官网下载安装包就可以。
需要注意的是Docker Desktop安装不会有任何问题,但后续的拉取可能会出现各种阻碍。
解决的方法是在docker desktop的Docker Engine的配置里,加入镜像配置。
以下是我自己用的配置。
{"builder": {"gc": {"defaultKeepStorage": "20GB","enabled": true}},"experimental": false,"registry-mirrors": ["https://registry.docker-cn.com","https://hub-mirror.c.163.com","https://docker.m.daocloud.io","https://docker.1panel.live","https://docker.mirrors.tuna.tsinghua.edu.cn"]
}
GIT拉取Dify仓库
在本地找到一个目录,用Terminal定位到这个目录,然后拉取仓库文件。
比如在我本地,我会先创建如下目录。
/User/Yourname/APP/Dify
然后在Terminal里cd到这个目录,运行以下脚本拉取仓库。
git clone https://github.com/langgenius/dify.git
通常来说到这里你会遭遇障碍,针对Github的访问,推荐用Steam++或者网易UU加速器。我自己用的是Steam++,这个是给Steam加速用的,也附带Github的加速。
启动服务
Git拉取完成后,先定位到仓库目录。
cd dify
然后运行以下命令复制配置文件。
cp .env.example .env
最后运行以下命令启动Dify服务。
docker-compose up -d
第一次运行这个命令,本地缺失的镜像会自动从github去拉取,所以这个时间可能会比较长。
在后续如果再运行这个命令的话,如果上一次的镜像没有拉取成功会继续拉取,如果都拉取成功了就直接启动各个镜像。
直到看到以下输出说明拉取和服务都启动成功了。
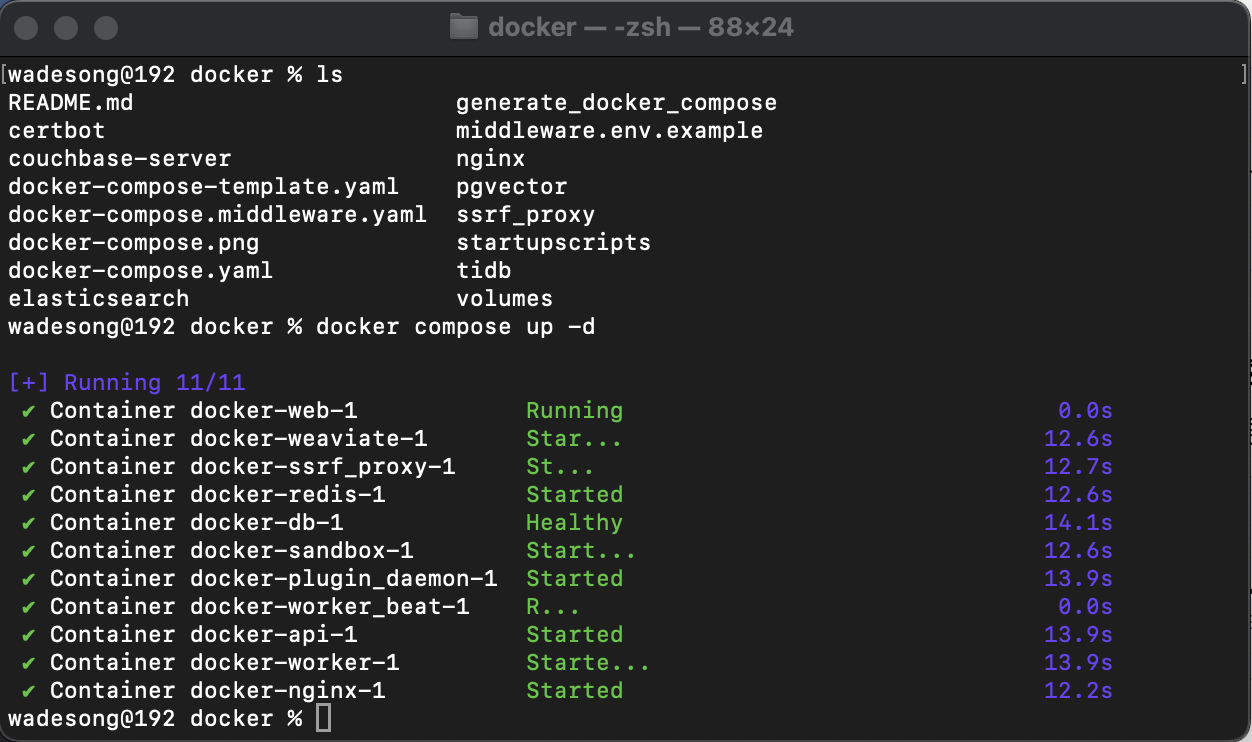
服务启动成功后,打开浏览器,直接输入localhost或者127.0.0.1就可以打开系统。系统默认用的是80端口。
首次打开系统需要注册一个账号,这个账号需要记住,后续登录可能需要提供。
配置大模型
在主页右上角点击头像,然后点击设置。
在配置大模型之前,你可以可以点击语言选项,把语言切换成中文。
然后在模型供应商里,首先安装模型供应商。
这里可以选择常用的Ollama,这样就可以访问部署在本地的大模型,这里我选择的是通义千问的。
安装完模型供应商后,需要提供在通义千问的API KEY,如何去申请这里不做介绍.
配置成功后会看到如下差不多的界面,在通义千问里,如果看到API-KEY上的绿色小点,就说明配置成功了。
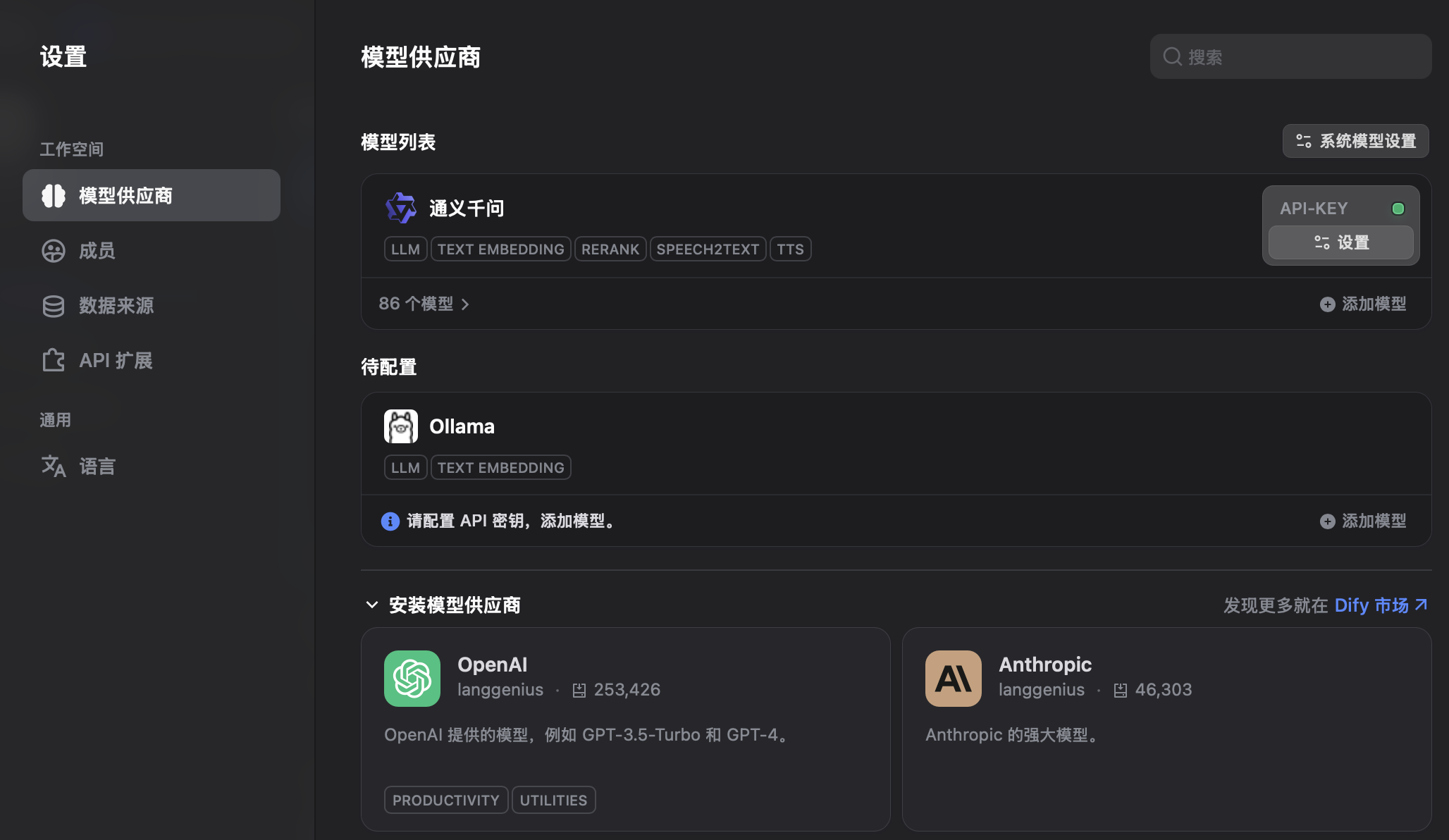
通义千问对新用户提供了一些免费的额度,所以对于学习来说是够用的。
创建知识库
首先创建测试的数据,这里我用Excel文件创建了一个问答模式的知识库,数据如下:
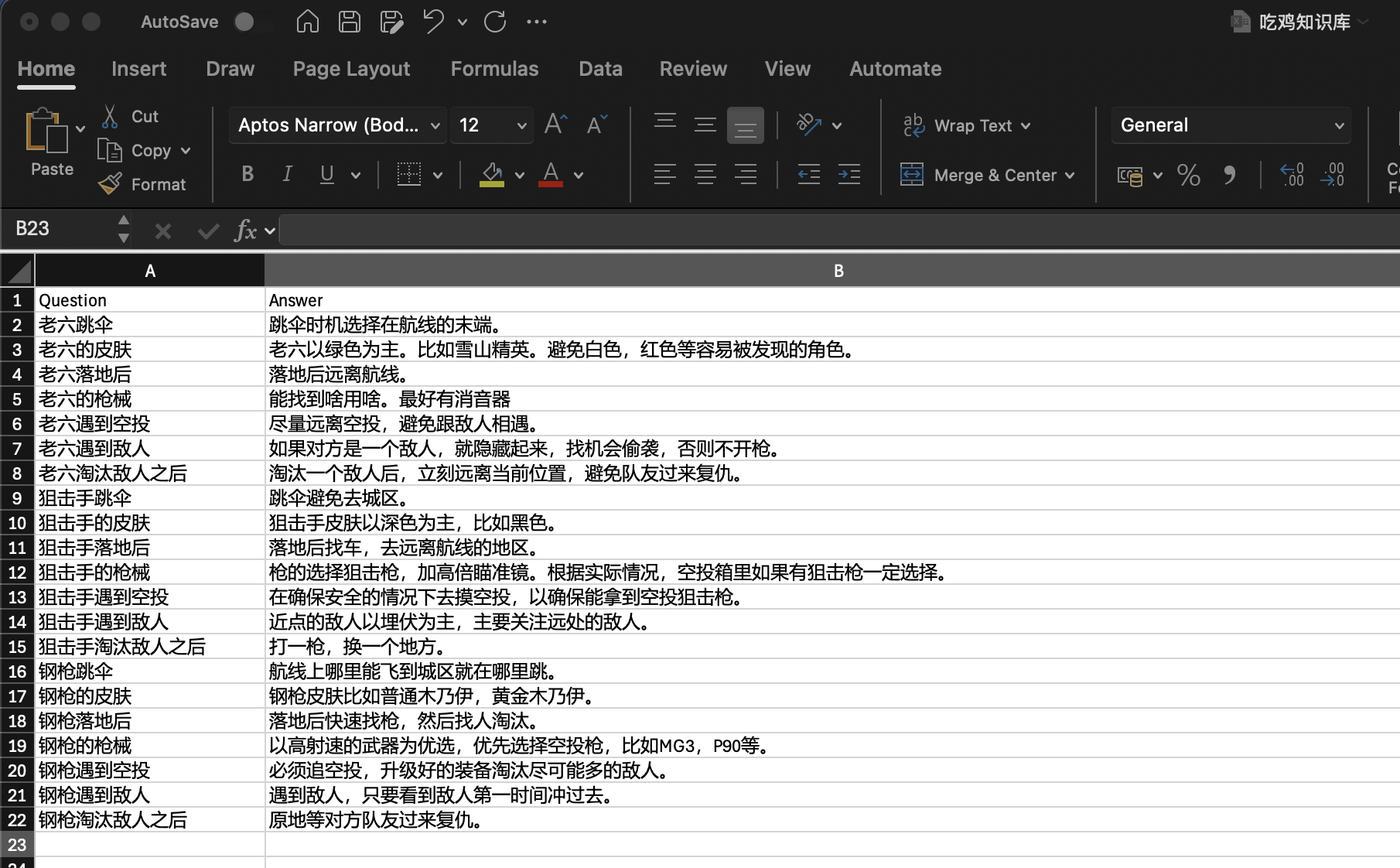
如果你查看其它资料,都是直接把一篇文章直接喂给Dify的知识库。但我发现有些资料如果这么喂的话,系统的识别会有问题,所以改成了这种问答的形式,并且进行了测试,这样看上去识别的准确度高了很多。
接下来创建知识库,点击系统顶部的知识库,然后点击创建知识库。
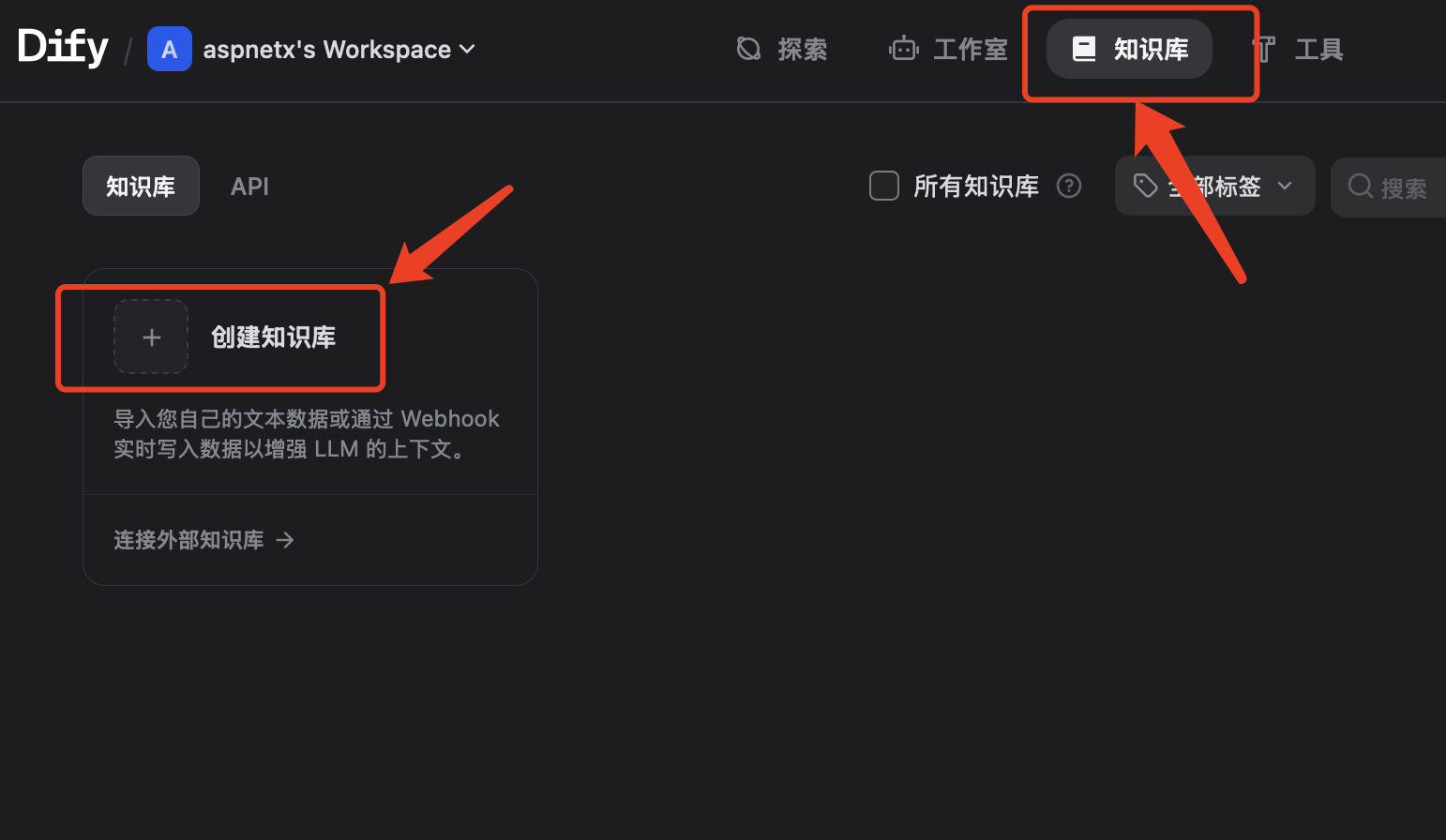
选择数据源,导入已有文本,在下面的上传里直接上传刚才创建的Excel文件。
点击下一步。
这里先不做其它设置,直接点击完成。
创建聊天助手
点击顶部的工作室,点击创建空白应用。
选择应用类型,点击聊天助手(在新手应用下面),给应用取一个名字,点击创建。
在接下来的界面中,知识库里选择刚才创建的知识库。
在提示词里参考如下提示词:
只使用知识库的内容回答问题,不要检索知识库以外的信息。
回答尽量简短。
如果在知识库里找不到答案,则回答我不知道。
在右上角的位置选择大模型,这里我选择的是qwq-plus。
然后在右侧调试与预览测试下问答。
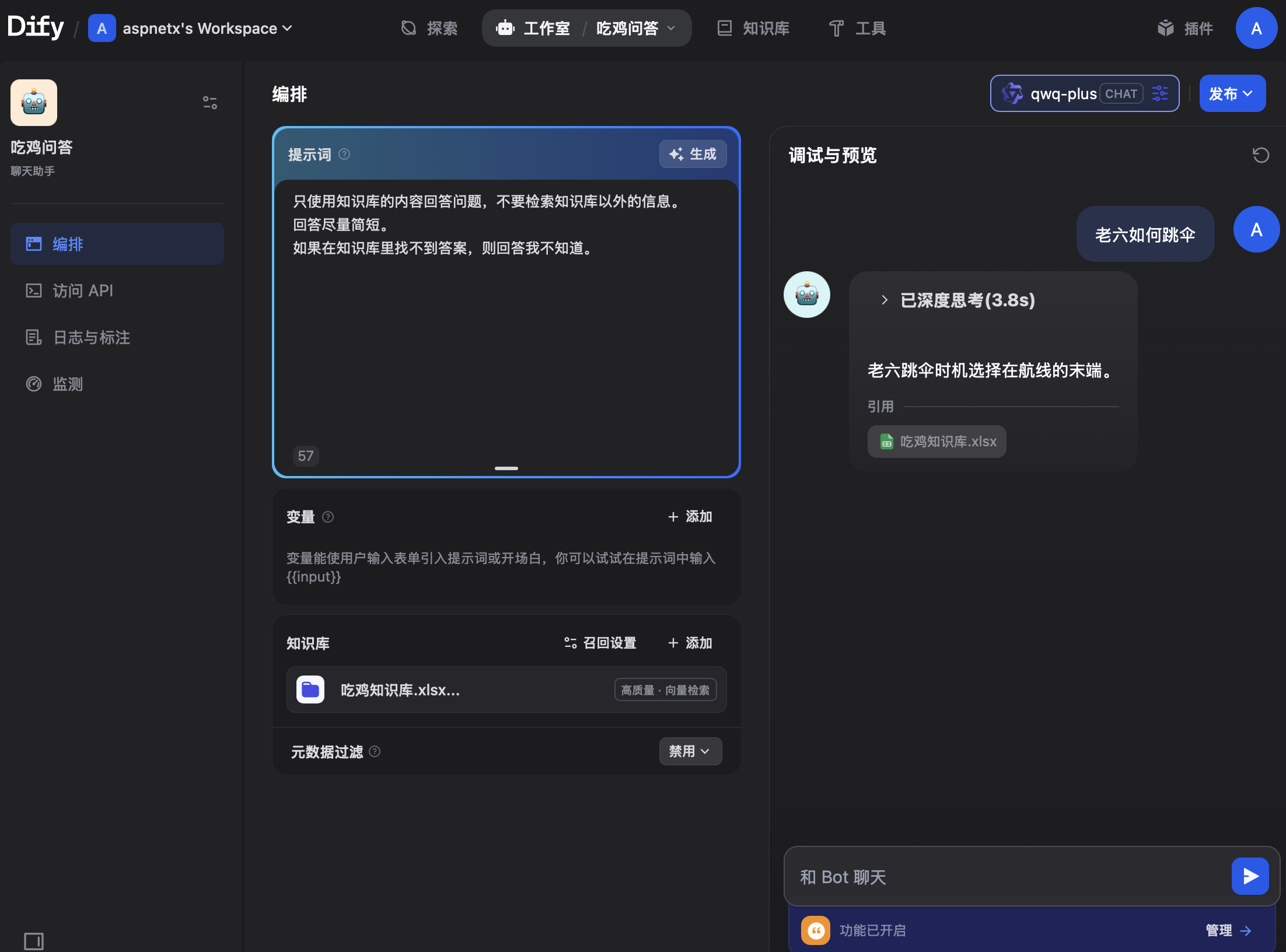
可以看到回答还是很准确的。
当然你也可以换些其它问题,比如:
老六如何选枪
跳伞直接跳城区的是哪个角色
打一枪换一个地方是哪个角色的打法
以及:
今天星期几
因为有提示词的限定,所以系统会直接回答不知道。
当然对于有些问题,比如:知识库里有多少个角色,回答的就不准确。
至此一个问答模块创建成功。
其它
你可能会问为什么不直接抛只是文件给系统,而是转换成了这种问答对的方式,有点类似模型微调。
我测试的时候,刚开始确实是这么准备的。
也就是一个角色一个文件的这种方式。
但测试的结果实在是乱七八糟,可能是吃鸡的这个场景实在是太特殊,一个简单的问题比如老六如何跳伞,好家伙直接让我跳城区去了。
但是如文中测试,有些问题回答的也不是很准确,但大多数比较浅的问题都能回答对。
这里我觉得可能是配置知识库的时候有些参数不对,我也在不断的摸索当中,如果有懂的兄弟还请给指点一下。