Python----大模型(基于Fastapi+gradio的对话机器人)
一、准备工作
1.1、魔搭社区下载大模型
通义千问2.5-7B-Instruct · 模型库
from modelscope.hub.snapshot_download import snapshot_download
llm_model_dir = snapshot_download('Qwen/Qwen2.5-7B-Instruct',cache_dir='models')1.2、启动vllm大模型
python -m vllm.entrypoints.openai.api_server --port 10222 --model /home/AI_big_model/models/Qwen/Qwen2.5-7B-Instruct --served-model-name Qwen2.5-7B-Instruct二、Fastapi后端
FastAPI 是一个用于构建API的现代化、快速(高性能)的Web框架,使用Python 3.7+的标准类型提示。它的性能媲美Node.js和Go,是基于Python的框架中最快的之 一。
主要特点:
高性能:与Starlette、Pydantic等框架深度集成,性能优异。
简洁明了:基于类型提示(Type Hints),使得代码更加简洁且具备良好的可读 性。
自动生成文档:自动生成Swagger UI和ReDoc文档,方便开发者查看和测试 API。
异步支持:原生支持Python的async和await,适合处理异步任务。
pip install fastapi
pip install uvicorn
# 导入必要的库
from fastapi import FastAPI, Body # FastAPI框架和Body请求体
from openai import AsyncOpenAI # OpenAI异步客户端
from typing import List # 类型提示
from fastapi.responses import StreamingResponse # 流式响应# 初始化FastAPI应用
app = FastAPI()# 初始化openai的客户端
api_key = "EMPTY" # 空API密钥(因为使用本地部署的模型)
base_url = "http://127.0.0.1:10222/v1" # 本地部署的模型API地址
aclient = AsyncOpenAI(api_key=api_key, base_url=base_url) # 创建异步客户端实例# 初始化对话列表(全局变量)
messages = []# 定义路由,实现接口对接
@app.post("/chat")
async def chat(query: str = Body(default='你是谁?', description="用户输入"), # 用户输入的查询文本sys_prompt: str = Body("你是一个有用的助手。", description="系统提示词"), # 系统角色设定history: List = Body([], description="历史对话"), # 历史对话记录history_len: int = Body(1, description="保留历史对话的轮数"), # 保留的历史对话轮数temperature: float = Body(0.5, description="LLM采样温度"), # 生成文本的随机性控制top_p: float = Body(0.5, description="LLM采样概率"), # 核采样概率阈值max_tokens: int = Body(default=1024, description="LLM最大token数量") # 生成的最大token数
): global messages # 使用全局的messages列表# 控制历史记录长度(只保留指定轮数的对话)if history_len > 0:history = history[-2 * history_len:] # 每轮对话包含用户和AI两条记录,所以乘以2# 清空消息列表(每次请求都重新构建)messages.clear()# 添加系统提示词messages.append({"role": "system", "content": sys_prompt})# 在message中添加历史记录messages.extend(history)# 在message中添加用户当前的查询messages.append({"role": "user", "content": query})# 发送请求到本地部署的模型response = await aclient.chat.completions.create(model="Qwen2.5-7B-Instruct", # 使用的模型名称messages=messages, # 完整的对话上下文max_tokens=max_tokens, # 最大token数temperature=temperature, # 温度参数top_p=top_p, # 核采样参数stream=True # 启用流式输出)# 定义生成响应的异步生成器函数async def generate_response():# 遍历流式响应的每个chunkasync for chunk in response:chunk_msg = chunk.choices[0].delta.content # 获取当前chunk的文本内容if chunk_msg: # 如果有内容则yieldyield chunk_msg# 返回流式响应,媒体类型为纯文本return StreamingResponse(generate_response(), media_type="text/plain")# 主程序入口
if __name__ == "__main__":import uvicorn# 启动FastAPI应用# 参数说明:# "fastapi_bot:app" - 要运行的模块和应用实例# host="0.0.0.0" - 监听所有网络接口# port=6066 - 服务端口# log_level="info" - 日志级别# reload=True - 开发模式下自动重载uvicorn.run("fastapi_bot:app", host="0.0.0.0", port=6066, log_level="info", reload=True)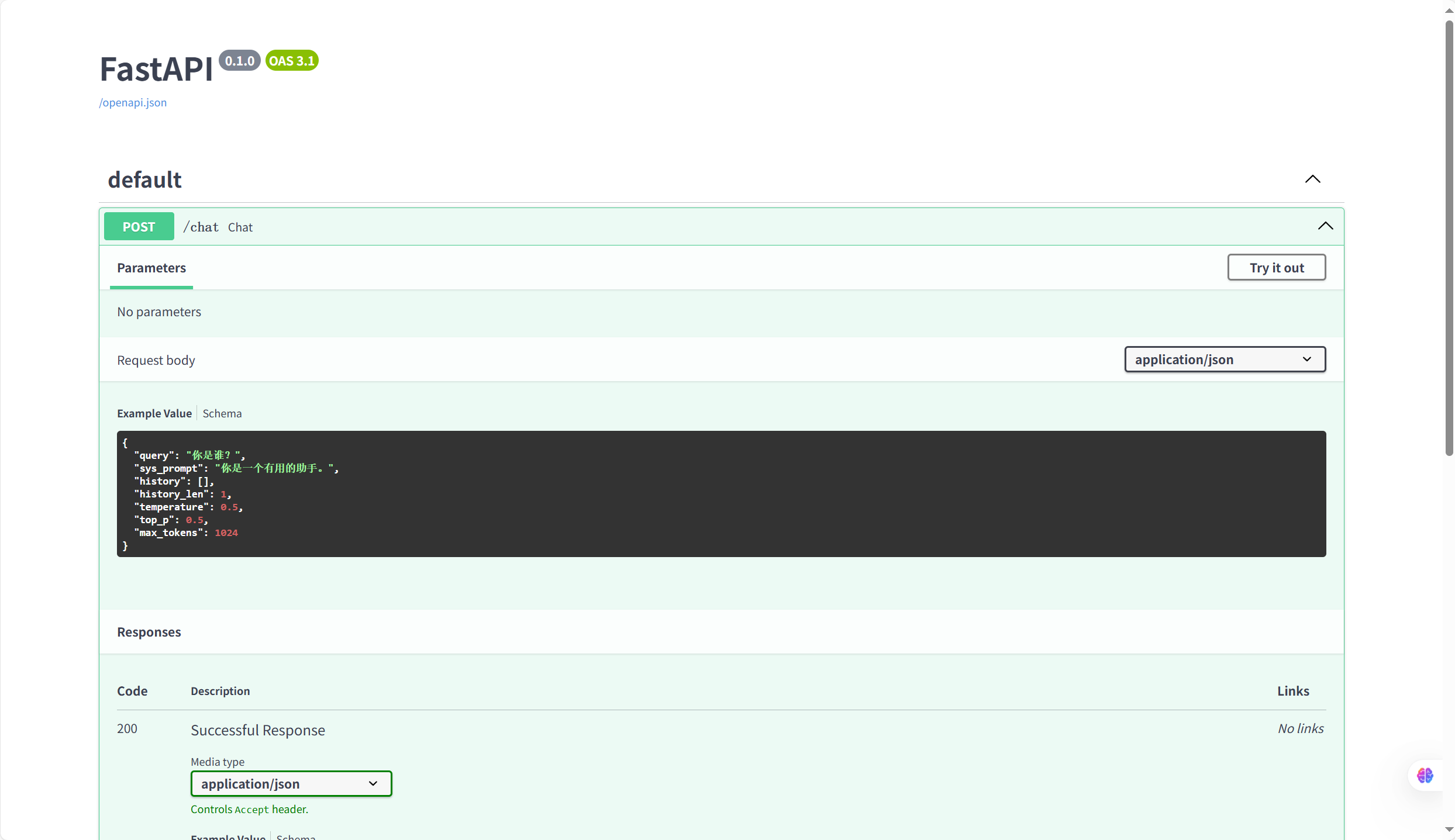
三、 gradio界面设计
Gradio 是一个简单易用的 Python 库,能够帮助开发者快速搭建用户友好的 Web 应 用,特别适合用于机器学习模型的展示。本课程将使用 Gradio 来搭建一个可以与 FastAPI 后端交互的对话机器人。
Gradio Blocks:用于组织界面布局的容器。
Slider:用于调整生成参数,如 temperature 和 top_p。
Textbox:用户输入对话的地方。
Button:发送用户输入或清空历史记录。
Chatbot:用于显示对话历史的组件。
安装:
pip install gradio==5.0.2
# 导入必要库
import gradio as gr # 用于构建Web界面
import requests # 用于发送HTTP请求# 后端API地址(本地LLM服务)
back_url = 'http://127.0.0.1:8088/chat'def chat_with_backed(prompt, history, sys_prompt, history_len, temperature, top_p, max_tokens, stream):"""与后端LLM服务交互的核心函数参数说明:- prompt: 用户当前输入的问题- history: 历史对话记录(Gradio自动维护的列表)- sys_prompt: 系统角色设定提示词- history_len: 保留的历史对话轮数- temperature: 生成随机性控制(0-2)- top_p: 核采样概率阈值(0-1)- max_tokens: 生成最大token数- stream: 是否启用流式输出"""# 转换历史记录格式(移除metadata字段)# 输入示例:# [{'role': 'user', 'metadata': None, 'content': '你好'}, # {'role': 'assistant', 'metadata': None, 'content': '你好!'}]history_none_meatdata = [{"role": h.get("role"), "content": h.get("content")} for h in history]print("处理后的历史记录:", history_none_meatdata)# 构造请求数据体data = {"query": prompt, # 当前用户问题"sys_prompt": sys_prompt, # 系统提示词"histtory": history_none_meatdata, # 清洗后的历史记录"history_len": history_len, # 历史记录保留长度"temperature": temperature, # 温度参数(控制创造性)"top_p": top_p, # 核采样参数(控制多样性)"max_tokens": max_tokens # 生成长度限制}# 发送POST请求到后端APIresp = requests.post(back_url,json=data,stream=True # 保持长连接用于流式传输)# 处理响应if resp.status_code == 200:chunks = "" # 用于累积响应内容if stream:# 流式模式:逐块返回内容for chunk in resp.iter_content(chunk_size=None, decode_unicode=True):chunks += chunkyield chunks # 实时生成器输出else:# 非流式模式:完整接收后返回for chunk in resp.iter_content(chunk_size=None, decode_unicode=True):chunks += chunkyield chunks# ==================== Gradio界面构建 ====================
with gr.Blocks(fill_height=True, fill_width=True) as demo: # 创建全屏布局with gr.Tab('🤖聊天机器人'): # 主标签页gr.Markdown("## 🤖聊天机器人") # 标题# 界面采用左右分栏布局with gr.Row():# ===== 左侧控制面板 =====with gr.Column(scale=1, variant='panel') as sidebar_left:# 系统提示词输入框sys_prompt = gr.Textbox(label="系统提示词",value="你是一个有用的机器人" # 默认提示词)# 历史记录长度滑块history_len = gr.Slider(minimum=1, maximum=10, value=1,label="保留历史对话数量")# 生成参数控制区temperature = gr.Slider(minimum=0.01, maximum=2.0, value=0.5,label="temperature(值越大输出越随机)")top_p = gr.Slider(minimum=0.01, maximum=1.0, value=0.7,label="top_p(控制生成多样性)")max_tokens = gr.Slider(minimum=512, maximum=4096, value=1024,label="最大生成长度")# 流式输出开关stream = gr.Checkbox(value=True,label="启用流式输出(实时显示)")# ===== 右侧主聊天区 =====with gr.Column(scale=10) as main:# 聊天机器人显示框(消息模式)chatbot = gr.Chatbot(type='messages', # 使用消息格式height=700 # 固定高度)# 聊天接口(自动处理用户输入和显示)chatinput = gr.ChatInterface(fn=chat_with_backed, # 绑定处理函数type='messages', # 消息格式chatbot=chatbot, # 绑定的显示组件additional_inputs=[ # 附加控制参数sys_prompt,history_len,temperature,top_p,max_tokens,stream] )# 启动Web服务
demo.launch()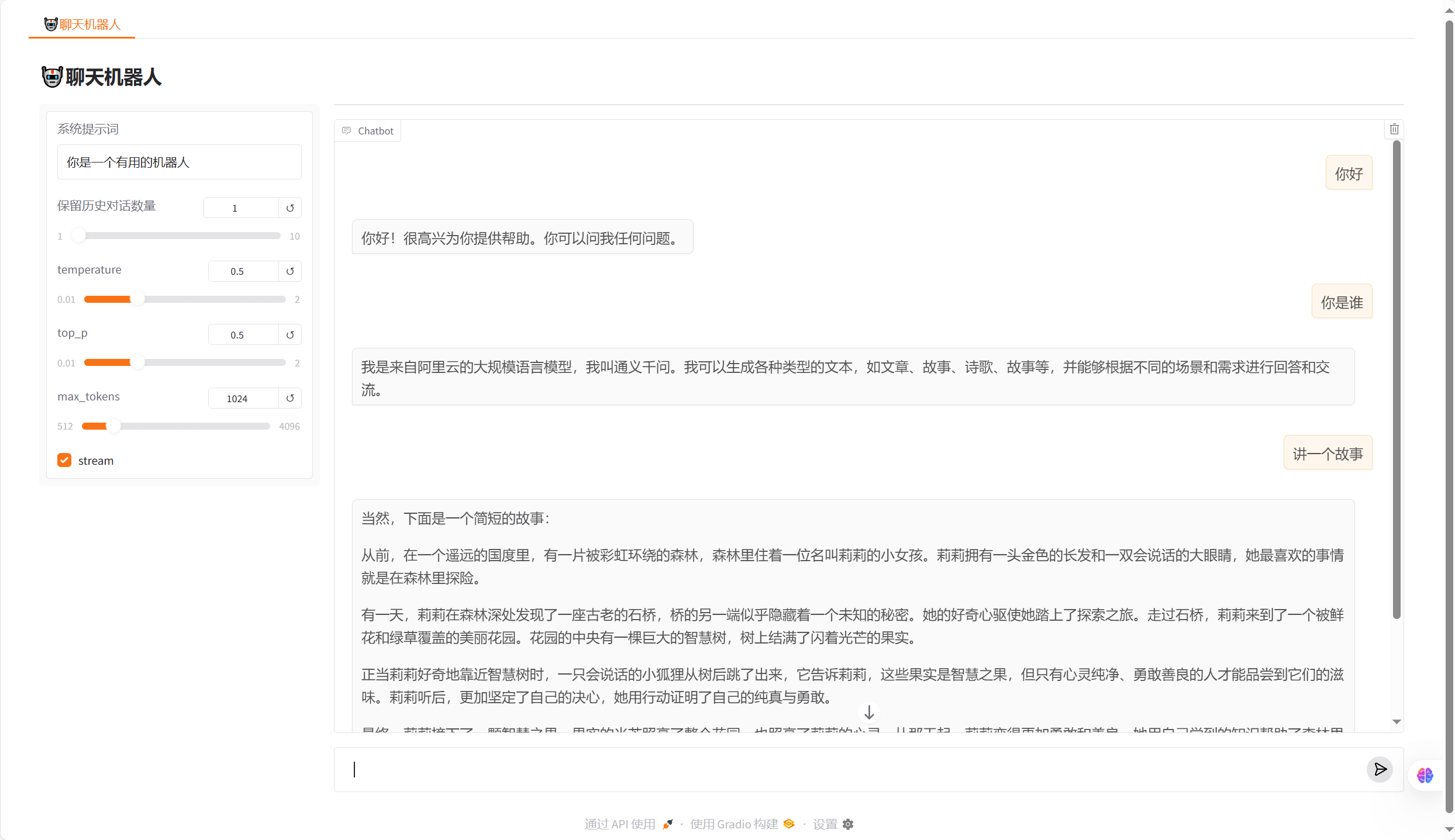
| 参数 | 类型 | 作用范围 | 推荐值 |
|---|---|---|---|
temperature | float [0.01-2.0] | 控制生成随机性 | • 创意写作:0.7-1.2 • 事实问答:0.1-0.5 |
top_p | float [0.01-1.0] | 控制词汇选择范围 | • 平衡输出:0.7-0.9 • 精确回答:0.5-0.7 |
max_tokens | int [512-4096] | 限制响应长度 | • 短回复:512-1024 • 长文生成:2048+ |
history_len | int [1-10] | 上下文记忆量 | • 简单对话:2-3 • 复杂推理:5-7 |
四、temperature和top_p介绍
在使用 AI 生成内容时,temperature 和 top_p 是两个重要的调节参数,它们可以影 响生成内容的确定性和多样性。
具体的参数设置因任务而异:
temperature:温度参数,通常控制生成内容的随机性。值越低,生成内容越确 定;值越高,生成内容越随机。
top_p:采样(top-p sampling)参数,控制生成时选择词汇的多样性。值越 高,生成结果越具多样性。
温度(temperature)与核采样(top_p)参数配置表
| 任务类型 | temperature | top_p | 任务描述 | 推荐场景扩展 |
|---|---|---|---|---|
| 代码生成 | 0.2 | 0.1 | 生成符合模式或假设的代码,输出更精确、更集中,有助于生成语法正确的代码。 | • 函数实现 • 算法复现 • 模板代码生成 注意:低值可避免生成无关代码逻辑 |
| 创意写作 | 0.7 | 0.8 | 生成具有创造性和多样性的文本,用于讲故事、内容探索等。输出具备探索性,受模式限制较少。 | • 小说创作 • 营销文案 • 诗歌生成 *建议配合max_tokens=1024+获得完整段落* |
| 聊天机器人回复 | 0.5 | 0.5 | 生成兼顾一致性和多样性的回复,输出自然且引人入胜。 | • 客服对话 • 社交聊天 *可动态调整: - 初次回复:0.5 - 后续追问:0.3~0.7* |
| 代码注释生成 | 0.1 | 0.2 | 生成的代码注释更为简洁、相关,输出准确且符合惯例。 | • 自动文档生成 • 接口说明 应与代码生成参数区分使用 |