地震成果数据在线可视化功能实现之高级篇
大家知道,大部分工区的二三维地震数据经过采集处理完成后的叠后数据大小都是几十、几百GB,甚至TB以上,格式主要是SEGY文件,为了支持在客户端浏览器高效快速显示,如果直接打开该工区的地震数据,由于文件比较大,导致加载速度慢,显示速度更慢,交互体验非常差,存在无效加载情况等问题。主要将之前文章中的技术原理进行详细设计开发,设计并实现了一种高效显示地震数据的索引构建方法和工具,该工具能够将20G的数据直接压缩到40M的索引文件,相当于500倍压缩比,而且基于该索引文件,根据默认或用户交互情况加载关注的数据道,提升了数据加载速度,显示速度也加快,用户交互反馈也大大提升,目前主要基于python或java实现,索引文件主要针对三维,二维数据直接利用后端服务进行数据获取和显示即可。供大家参考,具体如下。
一、地震数据SEGY格式分析
对于SEGY地震数据,存储方式详见《SEGY规范.doc》,具体如下。
一块地震数据包括卷头(3200+400字节)+道头(240字节)+每一道的采样数据体,见下图。
采样数据体大小主要与采样率和深度/时间有关,也叫做采样点。
总体计算逻辑如下
# 如下数字的单位都是字节
sgy文件大小=卷头(文本卷头3200+二进制卷头400)+[每一道道头(240)+每一道采样数据*数据占用字节数(一般为4字节)]*总道数
# 说明:每一道采样数据=每一道深度或时间/采样率
示例1:xxx.sgy文件分析,一般都是4字节存储。
通过卷头、道头分析,得出数据如下
inline:范围为2281-3321,间隔为2,数量为(3321-2281)/2+1=521,存储位置在道头的41-44 或 189-192
x-line:范围为1240-1880,间隔为1,数量为(1880-1240)+1=641,存储位置在道头的45-48
深度/时间: 一般来源于卷头,如Time Length : 4998,或者输入,比如本示例中的5000ms
采样率: 一般来源于卷头,如Sample Interval (uS): 2000,或者输入,比如本示例中的2000us=2ms
采样点:一般来源于卷头,如Trace Samples=2500,本示例存储位置在道头的113-116,如果通过上面两个参数计算,公式为:采样数据量=深度或时间/采样率,注意每个数据占用4字节。
因此,文件大小计算如下。
# 道数和采样数据量,可以通过卷头得到,如下。
# Traces : 333961
# Trace Samples : 2500
File-Size=3200+400+(240+(5000/2)*4)*333961=3,419,764,240
反过来,根据文件总大小和前面卷头给的信息,也可以自动计算出总道数,具体如下
Trace-Count=(3419764240-3200-400)/(240+(5000/2)*4)=333961
注意:这里的3419764240问文件大小。
二、索引工具设计
主要分为六大块:1200字节(索引构建配置信息,卷头/道头基础数据,道头位置信息,采样点统计量和采样信息),文件全路径信息,inline/xline线信息等。
同时,索引构建过程中,没有特殊说明的情况下,输出数据都是32为整数,即占用4字节。
(一).索引构建配置信息
1.强制卷头FTRL:1=强制卷头, 2=强制道头,0=错出
2.索引方式:1:由距离计算三维线号-5000,2:由角度计算三维线号,3:由三维inline线号道头位置-如189),目前是固定值,都是3
3.模式constantValue:写入固定值0,4字节,保留字
4.零值处理:写入固定值0,4字节,保留字
(二).卷头/道头基础数据
5.总道数:存放地震数据体的总道数,调用总道数获取或计算函数获得
6.inlineNum:存放inline数量
7.xypos_start_inline:开始存放每条inline线xy坐标数据时在inx的开始位置
后续四部分省略......
三、索引工具实现
该索引构建工具采取python/java实现,主要实现了从SEGY文件中读取卷头和道头信息,构建INX索引文件,索引文件中主要包括索引构建配置信息,卷头/道头基础数据,道头位置信息,采样点统计量和采样信息,文件全路径信息,inline/xline线信息等。大大提升了地震剖面显示效率,INX文件大小相较SEGY文件减少了500倍。
索引构建工具整体架构设计
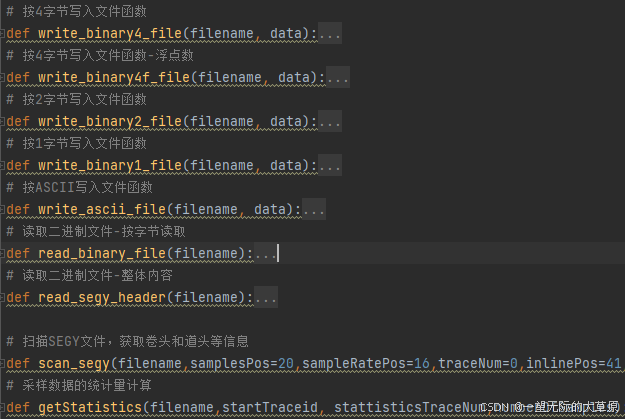
索引构建工具主体包括如下函数,详见下图。
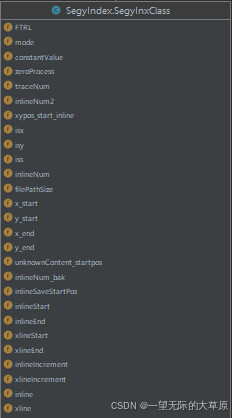
Segy索引类设计详见下图。
四、地震数据高效显示的后端服务
结合前端的GeoToolkit INT组件,实现了任意三维地震叠后数据的高效显示,这部分内容是后端读取索引文件和地震数据的接口服务设计实现。需要配合前端的app才能完整实现地震数据的高效显示和交互操作。目前主要针对SEGY格式。后续再考虑道集的SEGD数据。
地震数据服务目前主要有两种实现方式:java和nodejs。3D数据的主要类关系图如下。
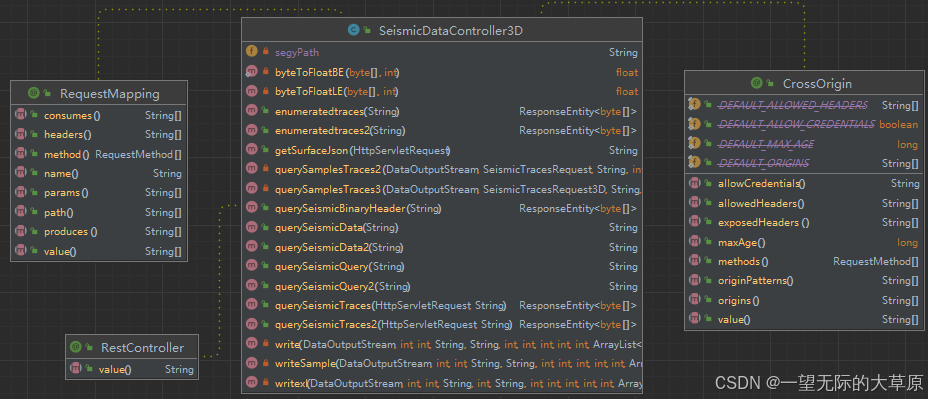
主要是SeismicDataController3D类中querySeismicData、querySeismicQuery、querySeismicTraces、enumeratedtraces、querySamplesTraces2、querySamplesTraces3、writeSample、write和writexl等方法。
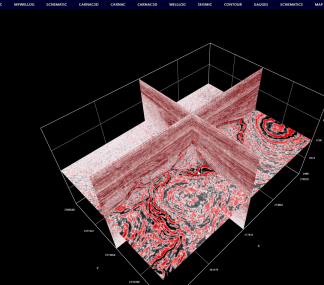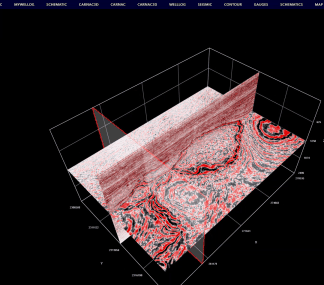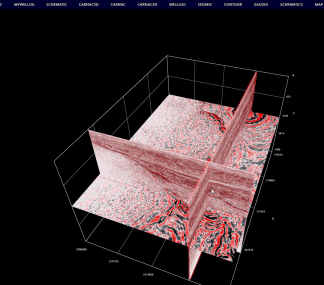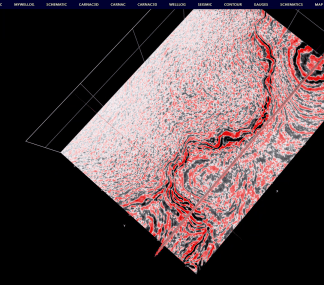
五、三维地震数据的在线显示效果图
主要基于上述索引工具构建的索引和地震数据,实现三维地震剖面、时间切片的高效显示和交互操作。三维显示的交互操作效果详见下图。