Python——入门
目录
变量
变量类型
动态类型
注释
输出输入
运算符
算术运算符
关系运算符
逻辑运算符
赋值运算符
条件语句
循环语句
函数
函数作用域
函数嵌套调用
函数默认参数
关键字参数
列表
切片
列表遍历
新增元素
查找元素
删除元素
列表拼接
元组
字典
增删改查
遍历
合法的key
文件操作
打开和关闭
读写操作
文件管理器
查找文件
第三方库
二维码
execl
程序猿鼓励师
变量
与C++不同的是,python定义变量时不用自己写变量类型,编译器根据=后面的值推导后赋予变量类型,且语句结束不用加分号;
a = 0变量类型
整数:int,由于C++的int类型有范围,值超过限定范围会溢出,所有需要 long long 长整形来控制值;而python整数类型只有int:每次值变大都会开辟新空间储存(自动扩容)
a = 10浮点数:float,C++中有单精度浮点数float 与双精度浮点数double,在python中float就代表双精度浮点数,并没有double
a = 3.14字符串:str,使用单引号‘’或者双引号“”都可以;在字符串中如果里面字符串有包含“”,外面就用‘’进行区分;如果两种都用就用三引号‘’‘’‘’进行区分
a = ' My name is "zzj" '
b = ''' My 'name' is "zzj" '''可以使用 + 将字符串进行拼接,使用 len()函数计算字符串长度
c = a + b
print(len(c))布尔类型:bool,使用True或者False表示真假,首字母大写
动态类型
一个变量被定义出来有了类型后,后序可以根据赋值数据把它变成其它类型

有了它就能很灵活的根据需要转换变量类型进行使用;但这也带来问题:读者在阅读代码时就会很疑惑:到底这行的变量类型是什么呢?所以实际开发还是要慎用
注释
python的注释有两种:#开头的注释和开头结尾使用三引号(单双都可以)的注释;注释内容就不要精简,也不要太长:把代码的功能或者注意点说清楚即可;关于注释语言一般都是中文,实际安装公司规定来
#这是注释"""
这是文档字符串,也是注释
"""输出输入
输出使用函数print 打印如何类型的变量;但如果是混合:字符串与变量的打印,就不能进行拼接,需要使用在前加f进行former-string
a = 10
print(f"a={a}")输入使用函数input 进行获取用户输入的数据
a = input('输入数据: ')
print(a)
print(type(a))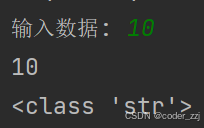
虽然输入的是int 类型,但用变量进行获取后类型变成str;如果对数据用要求用什么类型就要进行转化
a = int(a)![]()
运算符
算术运算符
在python中有 + - * / % ** // 七种算术运算符,**算的是几次方;// 除完后进行向下取整;运算顺序:先** //,再 * /,最后+ -,需要改变顺序就加括号()
print(3 // ( 2 * 10))![]()
如果使用 / 运算结果类型是浮点数float,结果是整数也是一样;使用 / 不能除0操作,否则会抛异常
print(2 / 2)
print(2 / 0)
print("result finish")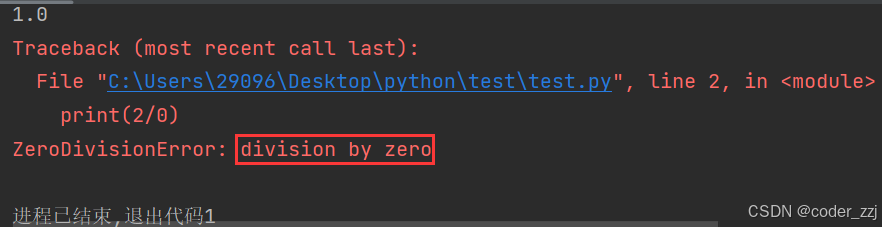
关系运算符
关系运算符有:< = > <= >= != 五种关系运算符;用来进行值之间,变量之间的比较;为真返回True,假返回为False;如果是字符比较则是比较它们的字典序,越靠后字典序越小;如果是字符串str,就从第一个开始比较,第一个比较不出来就往后找...使用== 则是比较字符串之间是否相等;而在C语言中字符串比较需要用到strcmp函数来实现,它的==比较的是字符串的首元素地址是否相等,不符合预期
a = 5
b = 10
print(a < b)
print("abc" == "abc")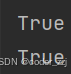
注意:如果是浮点数进行运算后进行比较,得出来的结果可能不符合预期
a = 0.1
b = 0.2
print(a + b == 0.3)![]()
原因是因为浮点数在储存规则不同,导致计算结果有误差
a = 0.1
b = 0.2
print(a + b)![]()
我们要这样来使用,在合理的误差我们忽略不计
a = 0.1
b = 0.2
c = 0.3
print(-0.000001 < (a + b - 0.3) < 0.000001)![]()
逻辑运算符
共有三种:and表示逻辑与操作(一假则假),or表示逻辑或操作(一真则真),not表示逻辑取反操作(真为假,假为真);如果使用and左边表达式为假后面的表达式就不执行了,这称为短路求值
a = 10
b = 5
print(a < b and a / 0)![]()
第一个表达式换成结果为真则就出现除0错误
print(a > b and a / 0)
赋值运算符
赋值运算符=,左边为变量,右边为常量,把常量的值赋给变量;而==是判断左右表达式是否相等,在判断时不要写错;除此之外,还有链式赋值:同一行进行多个变量的赋值
a = b = 10
print(f"a={a} b={b}")
还有逗号赋值,能够用来解决两个变量的交换
a = 10
b = 20
a, b = b, a
print(f"a={a} b={b}") 
除此之外,还有+= -= *= /= %=等复合赋值运算符,但不支持前置后置++(--);前置++可以运行但变量没有变化
a = 10
a += 1
print(a)
++a
print(a)

后置++编译就报错
a = 10
a++
print(a)
条件语句
if语句格式
if 表达式:语句案例
#牛马判断器
val = input("输入一个值:")
if(val == '1'):print("你是牛")
elif(val == '2'):print("你是马")
else:print("你是牛马")注意这里的val获取到的是一个字符串str,不能使用1进行比较而是字符‘1’
判断语句还可以继续多层嵌套
val1 = input("输入一个值:")
val2 = input("再次输入一个值:")
if(val1 == '1'):if(val2 == '2'):print("马")print("牛")
print("牛马")
使用判断语句判断输入的数是奇数还是偶数时,要进行类型转化不然str类型无法进行计算
val = int(input("输入一个值:"))
if(val % 2 == '0'):print("偶数")
else:print("奇数")在python这里负数模2是1或者0,而在C++中负数%2是-1或0;另外如果用户输入的是字符串在转化时python直接报错

如果在条件中没有什么语句要执行的话,不能空着,要使用pass表面此处是空语句
val = 1
if val != 1:pass
elseprint("Yes")循环语句
循环语句之一while语法
while 表达式:语句案例
#1到100之和
sums = 0
i = 1
while i <= 100:sums = sums + ii = i + 1
print(f"sum = {sums}")循环语句for语法
for 变量 in 可迭代对象语句案例
#1到100之和
sums = 0
for i in range(1,101):sums = sums + i
print(f"sum={sums}")range是一个函数,传入的两个参数是一个[1,101 ) 区间;它还要第三个参数表示变量i执行的步数,不传默认是1
#打印10到1
for a in range(5,0,-1):print(a)
使用continue关键字表面此次循环跳过;break关键字则是跳出循环
函数
如果需要频繁使用到相似的代码的功能但需要根据需求改变值的话就可以使用函数根据需要进行调用
def 函数名(参数列表):语句案例
def cal_sum(begin, end):sums = 0for i in range(begin, end+1):sums += iprint(f"sums = {sums}")# 1到100之和
cal_sum(1, 100)
# 1到1000之和
cal_sum(1, 1000)
函数定义要调用函数之前,因为代码是从上往下执行,在调用函数之后定义导致调用时找不到后编译器报错,所以要:先定义,再调用

有些代码下面有黄线,但是程序正常运行;这可能是要你遵守它所要的规范,不如函数名CalSum这样命名不符合它所要的规范,你要使用cal_sum来命名而不是以大写字母分隔来命名(但这样无伤大雅,只是尽量按照它的规范来,因为可以有的黄线可能影响代码的正确性,要能够识别的出就需要把那些因为错误命名规范导致的黄线给去掉(修改))
在python中函数列表有几个就要传入几个,至于类型不规定:因为有动态类型(这也就在一些场景下不同收到类型的约束从而去学习复杂的语法比如C++的模板)
上面函数没有返回值,在实际设计函数更推荐设置返回值:因为设置了返回值可以让使用者与函数之间进行解耦合(一方改变另一方不受影响)
def sum_val(a, b):return a + bresult = sum_val(2, 6)
print(result)
result = sum_val(2.0, 3.0)
print(result)

除了返回一个值,在python中还可以一次返回多个值
def get_point():x = 10y = 20return x, yx, y = get_point()
print(x, y)

如果只需要返回多个值的中一个,用_把不需要的值进行站位
_, y = get_point()
函数作用域
定义x,y变量进行接收,与函数内容定义的x,y是否是一样的呢?
不一样,因为在函数有作用域的限制,外面的人实际上是不知道函数内容有什么变量,定义的变量名字相同时各自之间是不会受影响的
a = 10def fun():a = 20print(a)fun()
print(a)

如果里面想要让外面的a进行修改,可以使用关键字global声明后进行修改
a = 10def fun():global aa = 20print(a)fun()
print(a)

而像if,else,while,for虽然也与函数一样形成代码块(里面语句需要缩进),但它们里面定义的变量再外部可以访问,也就是说没有作用域限制
if True:a = 10
print(a)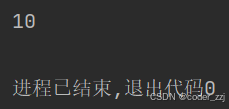
函数嵌套调用
函数的返回值可以作为下一个函数的参数进行调用,这样就不用再创建变量保存返回值;但嵌套的多了影响可读性,嵌套层数适量即可
打印两者相加之和的结果
def sum_val(a, b):return a + bprint(sum_val(10, 20))

函数默认参数
与C++一样:pyhton也支持函数参数给上默认参数:函数参数没如果有传入就使用默认的,有传参数就使用传参的;默认参数只能从右向左设置,不能从左边或者中间设置
def sum_val(a, b, debug=False, debug1=True):if debug and debug1:print(f"a={a} b={b}")return a + bprint(sum_val(10, 20))

关键字参数
默认函数参数列表与调用函数传参的顺序相同;但也可以不顺序传,使用关键字参数指定传
def test(x, y):print(f"x={x} y={y}")test(y=10, x=20)

列表
列表与元组其实是C/C++的数组,但它们有些差别;列表与元组具有相同的功能,唯一不同的是列表后面还要还可以加变量,而元组则在创建时就时固定下来的,如要更改就需要创建新的元组
表示列表的方法有两种
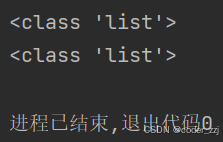
a = []
print(type(a))
b = list()
print(type(b))
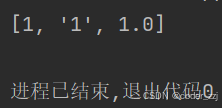
保存在列表中的变量,类型可以不同
a = [1, '1', 1.0]
print(a)
访问列表的变量,下标从0开始;也可以通过下标修改变量
a = [1, '1', 1.0]
print(a[2])
a[2] = 2.0
print(a[2])

除了len()用来计算字符串长度,也可以用来计算列表长度
a = [1, '1', 1.0]
print(len(a))

所以列表的使用下标范围 < len() ;因为python允许下标为负数,比如-1表示倒数第一个位置,-2表示倒数第二个位置....
print(a[-1])
print(a[3])
切片
列表可以通过切片操作获取子列表
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 0]
print(a[1:5])

取子列表的区间是左闭右开;切片操作只是取出列表中一部分,不涉及拷贝,因此列表长度较大时使用切片操作还是很高效
还可以省略下标进行切片
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 0]
print(a[:5])
print(a[1:])
print(a[:])

使用切片的第三个参数指定步长(可以是负数),不传默认为1
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 0]
print(a[1:5])
print(a[1:5:2])
print(a[::-1])

列表遍历
对列表每个值进行遍历,可以使用for循环或者while循环进行操作(以for循环为例)
a = [1, 2, 3]
for i in a:print(i)

这种遍历时修改变量不影响内部变量,如果要进行修改列表的变量就要用遍历下标的方式
a = [1, 2, 3]
for i in range(0, len(a)):a[i] += 10
print(a)

新增元素
可以使用append()函数或者insert()函数来新增变量
a = [1, 2, 3]
a.append(4)
a.insert(100, 5)
print(a)
insert()需要传插入的下标位置,如果超过列表长度就默认插入在最后一个位置
查找元素
使用 in 来判断是否存在列表中
a = [1, 2, 3]
print(1 in a)
print(5 in a)

使用 inodex 返回值所在的下标
a = [1, 2, 3]
print(a.index(1))

如果不存在就抛异常
print(a.index(10))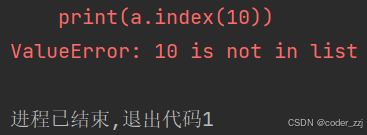
删除元素
使用pop删除默认删除最后一个变量
a = [1, 2, 3]
a.pop()
print(a)

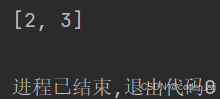
也可以指定下标删除(不存在抛异常)
a = [1, 2, 3]
a.pop(1)
print(a)

也可以使用remove()传入指定的变量进行删除(不存在抛异常)
a = [1, 2, 3]
a.remove(1)
print(a)
列表拼接
使用extend()函数进行列表之间的拼接
a = [1, 2, 3]
b = [5, 6, 7]
a.extend(b)
print(a)

也可以使用字符串拼接时的方法 + 进行拼接
a = [1, 2, 3]
b = [5, 6, 7]
a += b
print(a)

但这种原理是要先创建出一个大的临时列表来保存 a 和 b的值,再把它拷贝给 a,最后临时列表进行销毁;而 extend()是直接把b列表拼接在a 的后面,这种效率更好
元组
元组与列表上定义不同:列表用的是【】而元组用的是()且元组定义后不可被修改;使用上如果涉及修改元组(如新增,修改,删除遍历)在元组这里行不通,其它的可读操作如遍历,切片,查找元素都与列表是一样的
a = (1, 2, 3)
print(a)
print(a[0])
print(a[0:1])

函数可以返回多个变量底层就是根据元组进行返回
def get_point(x, y):return x, ya = (1, 2)
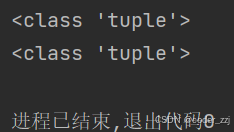
print(type(a))
print(type(get_point(5, 6)))
列表能做到元组不能做到的事,为什么还要有元组呢?
在实际协同开发时,程序猿A要开发一些功能(函数)给程序猿B使用,但程序猿B有个顾虑:如果在调用函数时把我的参数给修改导致结果是错误的,怎么办?所以在这种场景下就可以传元组,函数里面就不能进行修改啦
字典
字典中的储存是键值对:第一个变量叫做key,第二个变量叫做val;使用时通过key找到val,key的变量类型有约束而val类型则无所谓
字典的定义有两种
a = {}
b = dict()
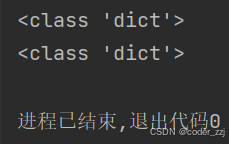
print(type(a))
print(type(b))
打印字典建议每一个键值对每隔一行写一对进行对齐,可读性高;可以是用 in(not in)判断key值是否存在
a = {"id": 1,"name": "John",12306: "Jonh"
}
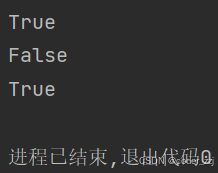
print("id" in a)
print(1 in a)
print("classed" not in a)
使用列表访问变量一样使用 [key] 找对应的val(如果key不存在就抛异常)
a = {"id": 1,"name": "John",12306: "Jonh"
}
print(a["name"])

print(a["classed"])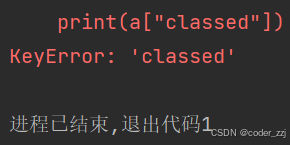
效率上使用 in(not in) 和 []查找key 和value在字典上效率都是很快,但在列表中[]查找变量快而 in反而效率不高:因为使用in 需要遍历列表一遍
增删改查
增加字段的键值对,修改key对应的val,查询key对应的val都可以使用【】来完成
a = {"id": 1,"name": "John",12306: "Jonh"
}a["score"] = 90
print(a["score"])
print(a[12306])
a[12306] = "Mike"
print(a[12306])

删除字典的键值对使用pop()函数来进行
a.pop("id")
print(a["id"])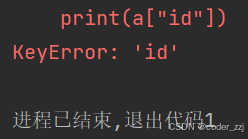
字典使用时效率达到常数级别的时间,不管数据是否变多还是变少,实践用字典也是最多的
遍历
可以使用for循环进行遍历
a = {"id": 1,"name": "John",12306: "Jon"
}
for key in a:print(a[key])

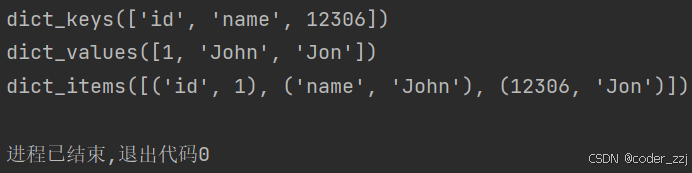
还可以使用函数 keys() values() items() 分别获取字典的key,val,键值对
a = {"id": 1,"name": "John",12306: "Jon"
}
print(a.keys())
print(a.values())
print(a.items())
合法的key
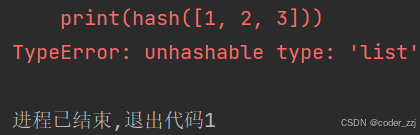
可以使用hash()函数来判断key是否合法:hash()通过称为可哈希,一般是不可变类型的变量如元组,整形,字符串;而hash()后报错则称为不可哈希,也就是不合法的key,一般是可变类型如列表,字典
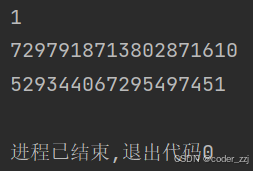
print(hash(1))
print(hash("hello"))
print(hash((1, 2, 3)))
print(hash([1, 2, 3]))
文件操作
打开和关闭
打开文件时会返回一个文件对象,通过该文件对象来进行对文件进行操作;使用完成就要对文件对象进行关闭也就是释放,因为打开一个文件时是需要效率系统资源的,使用完不关闭等到打开的文件足够多之后程序就会崩溃(内存被文件对象占满了)
f = open("C:/Users/29096/Desktop/test.txt", "w")
f.close()
opne第第一个参数传入文件路径(文件储存在系统的唯一性),第二个则是打开文件要进行什么操作:“r”:读read操作;“w”:写write操作;“a”:文件内存追加append操作
持续打开后把文件对象保存在列表中看看最多创建多少个文件对象
a = []
count = 0
while True:f = open("C:/Users/29096/Desktop/test.txt", "w")a.append(f)count += 1print(f"文件对象个数:{count}")
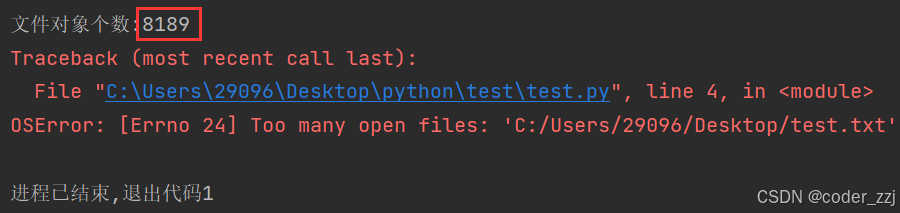
如果不保存在a列表中则可以无限创建文件对象:因为在python有垃圾回收机制:当他判断创建的文件对象不是使用时垃圾时就会给你进行回收(释放);但尽量还是要手动关闭,保不齐在判断之前就已经发生文件申请过多程序崩溃了
读写操作
写操作简单
f = open("C:/Users/29096/Desktop/test.txt", "w")
f.write("hello world")
f.close()
程序正常退出
到指定路径下看看是否有test.txt文件且内容是否符合预期
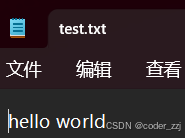
如果再次往该文件写内容且不要清空原来的内容此时打开文件时用到是‘a’操作进行写
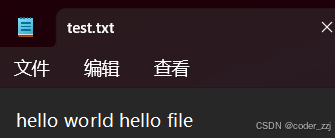
在文件中有以下内容
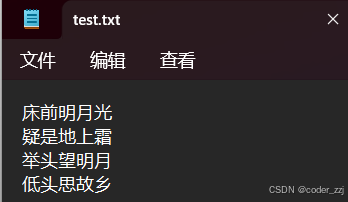
读文件内容打印到控制台有很多操作:按个数进行读,但如果只是直接读的话会报错
f = open("C:/Users/29096/Desktop/test.txt", "r")
content = f.read(3)
print(content)

原因是读操作尝试以gbk编码方式进行读取,但文件使用的是UTF8(文件右下角)
![]()
所以在打开文件时要设置编码方式
f = open("C:/Users/29096/Desktop/test.txt", "r", encoding="utf8")
content = f.read(2)
print(content)
要想按行为单位进行读取可以使用
f = open("C:/Users/29096/Desktop/test.txt", "r", encoding="utf8")
for content in f:print(content)

但是这里打印出来有空行:原因是文件每一行结尾有“\n”表示换行,而print后也要换行;所以对print进行设置让它不要换行
for content in f:print(content, end="")
既然要读取全部内容,可以使用 readlines() 来实现
f = open("C:/Users/29096/Desktop/test.txt", "r", encoding="utf8")
content = f.readlines()
print(content)

文件管理器
在进行文件操作时用户可能会忘记或者跳过文件关闭的代码,如在文件操作时由于判断条件,return 导致没能执行到关闭文件这行代码函数就结束了,所以python提供了文件管理器来自动释放打开文件时创建的文件资源
with open("C:/Users/29096/Desktop/test.txt", "w") as f:f.write("hello world")查找文件
给出的路径与文件关键词,在给出的路径下查找是存在文件
import ospath = input("输入文件路径:")
name = input("输入文件关键词:")
# 路径 当前路径目录名列表 当前路径文件名列表
for dirpath,dirname,filename in os.walk(path):for file in filename:if name in file:print(f"dirpath:{dirpath} filename:{file}")
第三方库
python能够流行大部分来源于它丰富的第三方库,怎么使用?
各种第三方库都能在 pypi.org网站上找到,一般使用 pip 工具以指令方式进行安装(按照python默认自带的)
二维码
使用搜索引擎找到是第三方库:qrcode;取 pypi.org网站上查使用文档(比较权威),现在当前python环境安装
pip install "qrcode[pil]"使用qrcode库生成二维码
import qrcoderesult = qrcode.make('python生成的二维码')
result.save("1.png")
execl
按照xlrd库,对execl格式的文件进行读,写使用 xlwd库
pip install xlrd==1.2.0需求:统计班级100的学生平均分
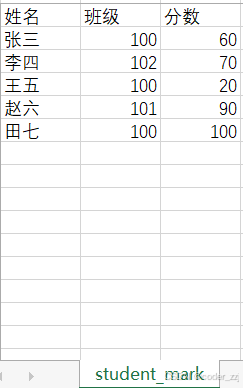
import xlrdxd = xlrd.open_workbook("C:/Users/29096/Desktop/1.xlsx")
#获取execl中名为"student_mark"的表
table = xd.sheet_by_name("student_mark")
rows = table.nrows
score = 0
count = 0
for i in range(1, rows):grade = table.cell_value(i, 1)if grade == 100:score += table.cell_value(i, 2)count += 1
print(f"班级100 平均分:{score/count}")
程序猿鼓励师
在按下若干次键盘后出现设置的随机音频进行播放效果
按照 pyuput 和 playsound 库
pip install pynput==1.6.8
pip install playsound==1.2.2在当前路径下准备好几个mp3文件放在sound文件夹中
import random
from threading import Thread
from pynput import keyboard
from playsound import playsoundsound_list = ["sound/1.mp3", "sound/2.mp3"]
count = 0def listen_release(key):global countcount += 1if count % 10 == 0:i = random.randint(0, len(sound_list) - 1)# 加线程才不会输入键盘时卡顿t = Thread(target=playsound, args=(sound_list[i],))t.start()listen = keyboard.Listener(on_release=listen_release)
listen.start()
listen.join()
以上便是全部内容,有问题欢迎在评论区指正,感谢观看!