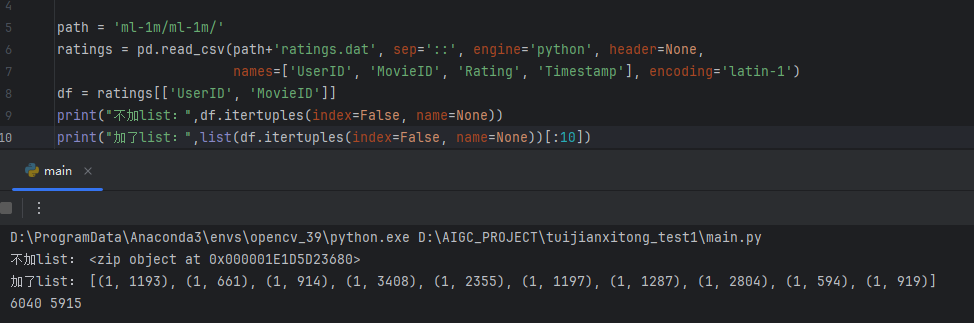
推荐系统学习
pd.read_csv返回的是dataframe,并不是一个可迭代对象,可用itertuples()或者values.tolist()函数将其转化tuple或者列表
df.itertuples()返回的是迭代器对象,转化成列表还要list(df.itertuples())
values.tolist()返回的是列表
评测指标:
1.召回率:描述有多少比例的用户—物品评分记录包含在最终的推荐列表中

2.准确率:最终 的推荐列表中有多少比例是发生过的用户—物品评分记录

3.覆盖率:最终的推荐列表中包含多大比例的物品;覆盖率反映了推荐算法发掘长尾的 能力,覆盖率越高,说明推荐算法越能够将长尾中的物品推荐给用户

4.平均流行度:在所有用户的推荐列表中,推荐的物品有多“热门”。如果系统只推荐 所有人都喜欢的热门商品,那平均流行度就会高;如果系统能推荐一些 小众但用户可能喜欢的宝藏物品,那平均流行度会低。

算法:
协同过滤算法:利用用户历史行为数据,通过用户之间或物品之间的相似性来推荐用户可能喜欢的物品。
(1)基于用户的协同过滤(User-based CF)
通过计算用户之间的相似度,找出和目标用户兴趣相似的“邻居”用户;
根据邻居用户喜欢的物品,推荐给目标用户他还未接触过的物品。
用户u和用户v的兴趣相似度
Jaccard公式: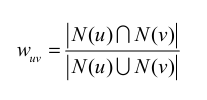

余弦相似度: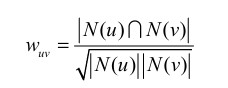

我们可以首先计算出![]() 的用户对(u,v),然后再对这种情况除以分母
的用户对(u,v),然后再对这种情况除以分母![]() 。 为此,可以首先建立物品到用户的倒排表,对于每个物品都保存对该物品产生过行为的用户 列表。令稀疏矩阵
。 为此,可以首先建立物品到用户的倒排表,对于每个物品都保存对该物品产生过行为的用户 列表。令稀疏矩阵![]() 。那么,假设用户u和用户v同时属于倒排表中K个物品对 应的用户列表,就有C[u][v]=K。从而,可以扫描倒排表中每个物品对应的用户列表,将用户列 表中的两两用户对应的C[u][v]加1,最终就可以得到所有用户之间不为0的C[u][v]。下面的代码实 现了上面提到的算法:
。那么,假设用户u和用户v同时属于倒排表中K个物品对 应的用户列表,就有C[u][v]=K。从而,可以扫描倒排表中每个物品对应的用户列表,将用户列 表中的两两用户对应的C[u][v]加1,最终就可以得到所有用户之间不为0的C[u][v]。下面的代码实 现了上面提到的算法:
用户相似度计算的改进:
两个用户对 冷门物品采取过同样的行为更能说明他们兴趣的相似度。因此,John S. Breese在论文①中提出了 如下公式,根据用户行为计算用户的兴趣相似度:
N(u)为用户u曾经有过正反馈的物品集合
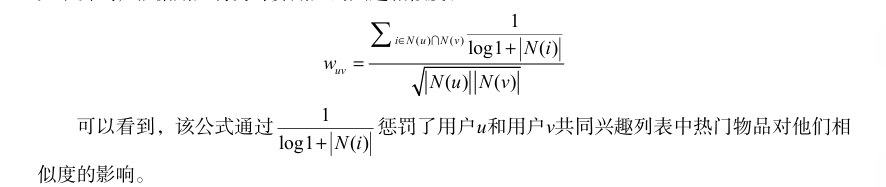
(2)基于物品的协同过滤(Item-based CF)
通过计算物品之间的相似度,找出和用户已喜欢物品相似的物品;
推荐这些相似物品给用户。