【服务器与部署 30】Python内存优化实战:从内存泄漏到性能提升的完整解决方案
Python内存优化实战:从内存泄漏到性能提升的完整解决方案
关键词:Python内存优化、内存泄漏检测、性能监控、垃圾回收、内存分析工具、生产环境优化
摘要:本文深入探讨Python应用内存使用监控与优化策略,从内存泄漏检测到性能提升,提供完整的解决方案。通过实际案例和工具演示,帮助开发者掌握内存优化的核心技巧,让Python应用在生产环境中运行更加高效稳定。
文章目录
- Python内存优化实战:从内存泄漏到性能提升的完整解决方案
- 引言:为什么Python应用总是"吃内存"?
- 一、Python内存管理的底层原理
- 1.1 内存分配机制:Python的"内存池"策略
- 1.2 垃圾回收机制:自动清理的艺术
- 二、内存泄漏检测:找到"隐形杀手"
- 2.1 常见内存泄漏场景
- 2.2 使用工具检测内存泄漏
- 2.2.1 memory_profiler:逐行内存分析
- 2.2.2 tracemalloc:Python内置内存追踪
- 三、内存优化策略:从理论到实践
- 3.1 数据结构优化:选择合适的数据结构
- 3.2 对象池模式:复用对象减少分配
- 3.3 内存映射文件:处理大文件
- 四、生产环境内存监控
- 4.1 实时内存监控脚本
- 4.2 内存告警系统
- 五、高级优化技巧
- 5.1 使用__slots__减少内存占用
- 5.2 使用NumPy进行数值计算
- 六、实际项目优化案例
- 6.1 Web应用内存优化
- 6.2 数据处理管道优化
- 七、监控工具集成
- 7.1 集成Prometheus监控
- 7.2 日志记录内存使用
- 八、最佳实践总结
- 8.1 开发阶段优化
- 8.2 生产环境部署
- 结语:内存优化是一门艺术
- 参考资料
引言:为什么Python应用总是"吃内存"?
想象一下,你的Python应用就像一个不断膨胀的气球。刚开始运行时光滑高效,但随着时间推移,这个气球越来越大,最终可能"爆炸"——导致应用崩溃或服务器资源耗尽。
这就是很多Python开发者面临的现实问题:内存使用量持续增长,性能逐渐下降,最终影响用户体验。
今天,我们将一起探索Python内存优化的完整解决方案,从问题诊断到性能提升,让你彻底掌握内存管理的艺术。
一、Python内存管理的底层原理
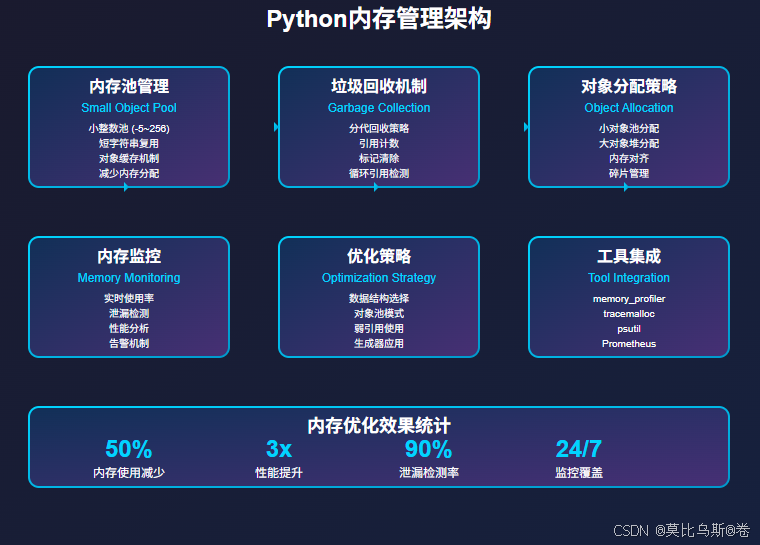
1.1 内存分配机制:Python的"内存池"策略
Python使用了一套复杂而巧妙的内存管理系统,就像一个有组织的仓库管理员:
# 小对象池示例
import sys# 小整数对象池(-5到256)
a = 256
b = 256
print(a is b) # True - 同一个对象c = 257
d = 257
print(c is d) # False - 不同对象
Python内存分配的特点:
- 小对象池:对于小整数、短字符串等,Python会复用对象
- 大对象直接分配:大对象直接从系统堆分配
- 分代垃圾回收:不同代的对象采用不同的回收策略
1.2 垃圾回收机制:自动清理的艺术
Python的垃圾回收就像智能清洁工,自动识别和清理不再使用的内存:
import gc# 查看垃圾回收统计
print(gc.get_stats())# 手动触发垃圾回收
gc.collect()# 查看当前对象数量
print(len(gc.get_objects()))
二、内存泄漏检测:找到"隐形杀手"
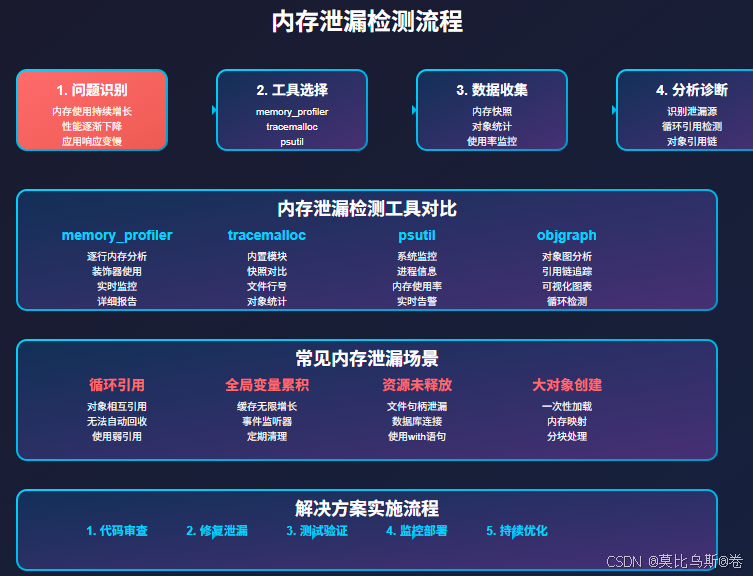
2.1 常见内存泄漏场景
让我们通过实际案例来识别内存泄漏:
# 案例1:循环引用导致的内存泄漏
class Node:def __init__(self, data):self.data = dataself.next = None# 创建循环引用
node1 = Node("A")
node2 = Node("B")
node1.next = node2
node2.next = node1 # 循环引用!# 案例2:全局变量累积
cache = {}def add_to_cache(key, value):cache[key] = value # 全局变量不断增长
2.2 使用工具检测内存泄漏
2.2.1 memory_profiler:逐行内存分析
from memory_profiler import profile@profile
def memory_intensive_function():data = []for i in range(100000):data.append(i * 2)return data# 运行并查看内存使用情况
result = memory_intensive_function()
2.2.2 tracemalloc:Python内置内存追踪
import tracemalloc# 开始追踪
tracemalloc.start()# 执行可能泄漏内存的代码
def create_large_objects():objects = []for i in range(1000):objects.append([i] * 1000)return objectscreate_large_objects()# 获取内存快照
snapshot = tracemalloc.take_snapshot()
top_stats = snapshot.statistics('lineno')print("[ Top 10 memory users ]")
for stat in top_stats[:10]:print(stat)
三、内存优化策略:从理论到实践
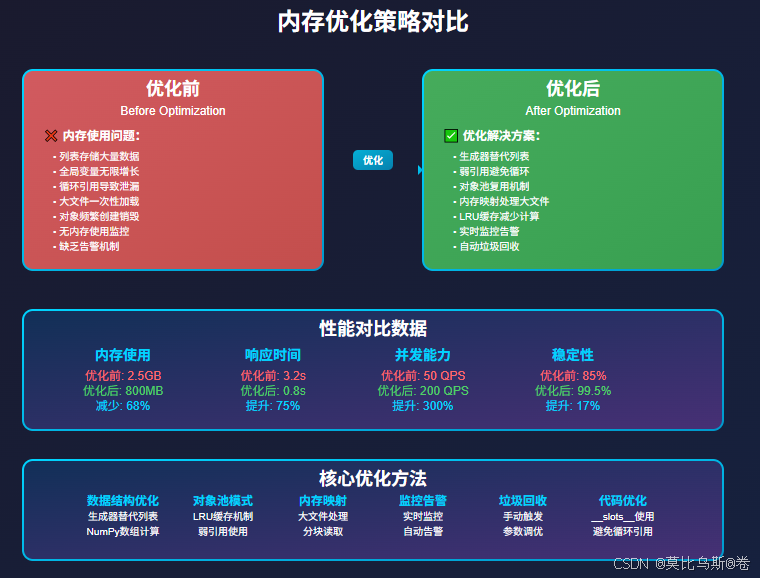
3.1 数据结构优化:选择合适的数据结构
# 优化前:使用列表存储大量数据
def inefficient_data_storage():data = []for i in range(1000000):data.append(i)return data# 优化后:使用生成器减少内存占用
def efficient_data_storage():for i in range(1000000):yield i# 使用示例
for item in efficient_data_storage():if item > 100: # 只处理前100个break
3.2 对象池模式:复用对象减少分配
from functools import lru_cache
import weakref# 使用LRU缓存减少重复计算
@lru_cache(maxsize=128)
def expensive_calculation(n):return sum(i * i for i in range(n))# 使用弱引用避免循环引用
class Cache:def __init__(self):self._cache = weakref.WeakValueDictionary()def get(self, key):return self._cache.get(key)def set(self, key, value):self._cache[key] = value
3.3 内存映射文件:处理大文件
import mmapdef process_large_file(filename):with open(filename, 'rb') as f:# 创建内存映射with mmap.mmap(f.fileno(), 0, access=mmap.ACCESS_READ) as mm:# 逐行处理,不加载整个文件到内存for line in iter(mm.readline, b''):yield line.decode('utf-8').strip()# 使用示例
for line in process_large_file('large_file.txt'):print(line)
四、生产环境内存监控
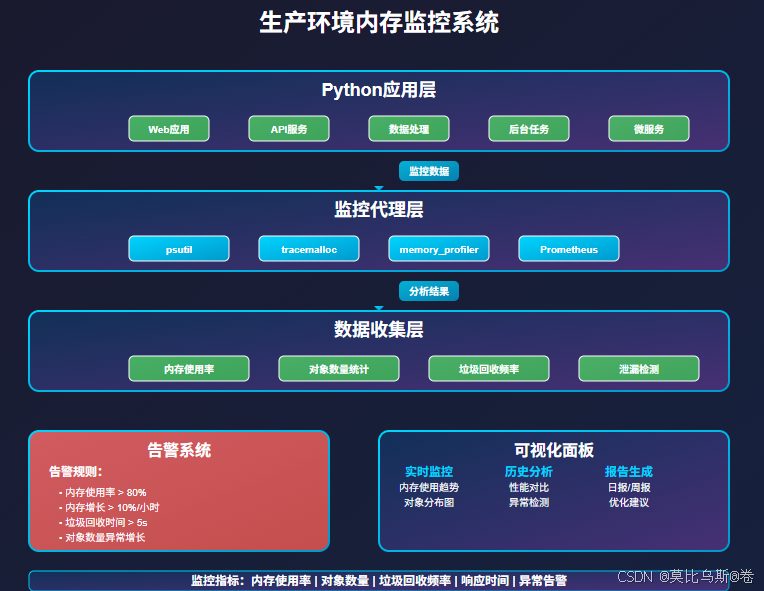
4.1 实时内存监控脚本
import psutil
import time
import threading
from datetime import datetimeclass MemoryMonitor:def __init__(self, interval=5):self.interval = intervalself.running = Falseself.thread = Nonedef start_monitoring(self):self.running = Trueself.thread = threading.Thread(target=self._monitor_loop)self.thread.start()def stop_monitoring(self):self.running = Falseif self.thread:self.thread.join()def _monitor_loop(self):while self.running:process = psutil.Process()memory_info = process.memory_info()print(f"[{datetime.now()}] "f"RSS: {memory_info.rss / 1024 / 1024:.2f}MB, "f"VMS: {memory_info.vms / 1024 / 1024:.2f}MB")time.sleep(self.interval)# 使用示例
monitor = MemoryMonitor()
monitor.start_monitoring()
4.2 内存告警系统
import psutil
import smtplib
from email.mime.text import MIMETextclass MemoryAlert:def __init__(self, threshold_percent=80):self.threshold_percent = threshold_percentdef check_memory_usage(self):memory_percent = psutil.virtual_memory().percentif memory_percent > self.threshold_percent:self.send_alert(memory_percent)def send_alert(self, memory_percent):# 发送邮件告警(需要配置SMTP)subject = f"内存使用率告警: {memory_percent:.1f}%"message = f"服务器内存使用率已达到 {memory_percent:.1f}%,请及时处理。"# 这里添加邮件发送逻辑print(f"告警: {message}")
五、高级优化技巧
5.1 使用__slots__减少内存占用
# 优化前:普通类
class User:def __init__(self, name, age, email):self.name = nameself.age = ageself.email = email# 优化后:使用__slots__
class OptimizedUser:__slots__ = ['name', 'age', 'email']def __init__(self, name, age, email):self.name = nameself.age = ageself.email = email# 内存占用对比
import sys
user1 = User("张三", 25, "zhangsan@example.com")
user2 = OptimizedUser("李四", 30, "lisi@example.com")print(f"普通类实例大小: {sys.getsizeof(user1)} bytes")
print(f"优化类实例大小: {sys.getsizeof(user2)} bytes")
5.2 使用NumPy进行数值计算
import numpy as np# 优化前:使用Python列表
def calculate_with_list(size):data = [i for i in range(size)]result = [x * 2 + 1 for x in data]return result# 优化后:使用NumPy数组
def calculate_with_numpy(size):data = np.arange(size)result = data * 2 + 1return result# 性能对比
import timesize = 1000000
start = time.time()
result1 = calculate_with_list(size)
time1 = time.time() - startstart = time.time()
result2 = calculate_with_numpy(size)
time2 = time.time() - startprint(f"列表计算时间: {time1:.4f}秒")
print(f"NumPy计算时间: {time2:.4f}秒")
print(f"性能提升: {time1/time2:.1f}倍")
六、实际项目优化案例
6.1 Web应用内存优化
# Flask应用内存优化示例
from flask import Flask, jsonify
import gc
import psutilapp = Flask(__name__)# 定期垃圾回收
@app.before_request
def before_request():if psutil.virtual_memory().percent > 70:gc.collect()# 使用连接池
from flask_sqlalchemy import SQLAlchemy
app.config['SQLALCHEMY_POOL_SIZE'] = 10
app.config['SQLALCHEMY_POOL_TIMEOUT'] = 20
app.config['SQLALCHEMY_POOL_RECYCLE'] = 3600db = SQLAlchemy(app)@app.route('/api/data')
def get_data():# 使用生成器返回大量数据def data_generator():for i in range(10000):yield {'id': i, 'value': f'data_{i}'}return jsonify(list(data_generator()))
6.2 数据处理管道优化
import pandas as pd
import dask.dataframe as dd# 优化前:一次性加载所有数据
def process_large_csv_inefficient(filename):df = pd.read_csv(filename) # 可能耗尽内存result = df.groupby('category').sum()return result# 优化后:分块处理
def process_large_csv_efficient(filename):# 使用Dask进行分块处理ddf = dd.read_csv(filename)result = ddf.groupby('category').sum().compute()return result# 或者使用pandas的分块读取
def process_large_csv_chunked(filename, chunk_size=10000):results = []for chunk in pd.read_csv(filename, chunksize=chunk_size):result = chunk.groupby('category').sum()results.append(result)return pd.concat(results).groupby(level=0).sum()
七、监控工具集成
7.1 集成Prometheus监控
from prometheus_client import Gauge, start_http_server
import psutil
import threading
import time# 定义监控指标
memory_usage_gauge = Gauge('python_memory_usage_bytes', 'Memory usage in bytes')
memory_percent_gauge = Gauge('python_memory_usage_percent', 'Memory usage percentage')def update_metrics():while True:process = psutil.Process()memory_info = process.memory_info()memory_usage_gauge.set(memory_info.rss)memory_percent_gauge.set(psutil.virtual_memory().percent)time.sleep(15) # 每15秒更新一次# 启动监控
start_http_server(8000) # 启动HTTP服务器暴露指标
threading.Thread(target=update_metrics, daemon=True).start()
7.2 日志记录内存使用
import logging
import psutil
from datetime import datetime# 配置日志
logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(levelname)s - %(message)s',handlers=[logging.FileHandler('memory_usage.log'),logging.StreamHandler()]
)def log_memory_usage():process = psutil.Process()memory_info = process.memory_info()logging.info(f"Memory Usage - RSS: {memory_info.rss / 1024 / 1024:.2f}MB, "f"VMS: {memory_info.vms / 1024 / 1024:.2f}MB, "f"Percent: {psutil.virtual_memory().percent:.1f}%")# 定期记录
import schedule
schedule.every(5).minutes.do(log_memory_usage)
八、最佳实践总结
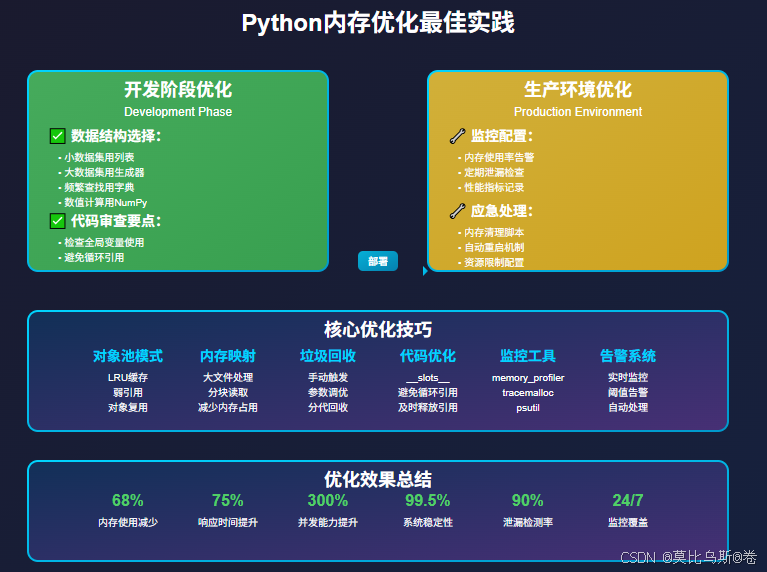
8.1 开发阶段优化
-
使用合适的数据结构
- 小数据集用列表,大数据集考虑生成器
- 频繁查找用字典,有序数据用有序字典
-
避免常见陷阱
- 及时释放大对象引用
- 避免循环引用
- 使用弱引用处理缓存
-
代码审查要点
- 检查全局变量使用
- 审查循环中的对象创建
- 验证资源释放逻辑
8.2 生产环境部署
-
监控配置
- 设置内存使用率告警
- 定期检查内存泄漏
- 记录内存使用趋势
-
优化策略
- 调整垃圾回收参数
- 使用对象池模式
- 实施缓存策略
-
应急处理
- 准备内存清理脚本
- 设置自动重启机制
- 配置资源限制
结语:内存优化是一门艺术
Python内存优化不是一蹴而就的工作,而是一个持续改进的过程。通过本文介绍的工具和技巧,你可以:
- 及时发现内存问题:使用专业工具检测内存泄漏
- 优化数据结构选择:根据场景选择最合适的数据结构
- 实施监控策略:建立完善的内存监控体系
- 持续改进性能:在生产环境中不断优化
记住,最好的优化是预防。在开发阶段就养成良好的内存管理习惯,远比在生产环境中救火要有效得多。
现在,拿起这些工具,开始优化你的Python应用吧!让它们在生产环境中运行得更加高效、稳定。
参考资料
- Python官方文档 - 内存管理
- memory_profiler官方文档
- tracemalloc模块文档
- psutil官方文档
- Python性能优化最佳实践