VLA-视觉语言动作模型
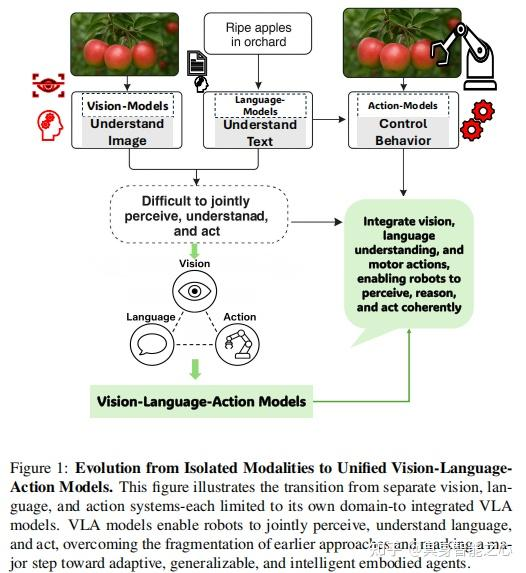
视觉 - 语言 - 动作(VLA)模型是人工智能领域的变革性进展,致力于将感知、自然语言理解和实体动作统一于一个计算框架。
应用领域多样,如仿人机器人、自动驾驶汽车、医疗和工业机器人、精准农业、增强现实导航等。主要挑战涉及实时控制、多模态动作表示、系统可扩展性、对未知任务的泛化以及道德部署风险等。
reference
---
VLA模型最新综述!近80多个VLA 模型,涉及架构、训练,实时推理等
https://zhuanlan.zhihu.com/p/1907961280112877856