I/O 控制方式
I/O 控制方式的演进目标是减少 CPU 干预,提升 I/O 与 CPU 的并行度,以下是四种方式的对比分析:
1. 程序直接控制方式(轮询)
原理:
- CPU 发送 I/O 指令后,循环查询设备状态(如
while (device.busy);)。 - 例:从磁盘读 1 字节 → CPU 不断问“好了没?”,直到设备准备好。
- 流程图:
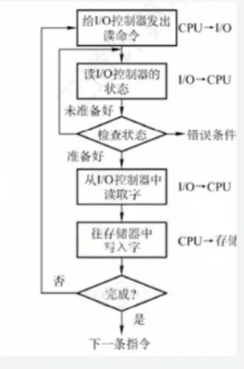
CPU → 发读命令 → 轮询设备状态 → 读数据 → 继续(全程独占 CPU)优缺点:
✅ 简单易实现(无硬件中断支持时可用)。
❌ CPU 利用率极低(大部分时间浪费在等待)。
❌ 设备与 CPU 串行(设备慢则 CPU 空转)。
2. 中断驱动方式
原理:
- CPU 发 I/O 指令后,转去执行其他任务(进程阻塞/换出--主动打断CPU运行请求服务,从而解放CPU)。
- 设备就绪(如数据读入控制器),发中断通知 CPU。
- CPU 响应中断,处理数据(从设备→内存)。
- 流程图:
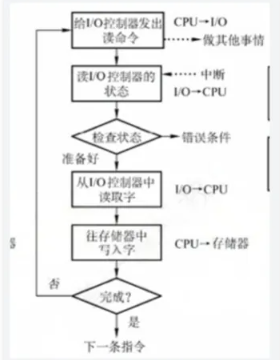
CPU → 发读命令 → 执行其他任务 → 设备中断 → CPU 处理中断(读数据)→ 恢复进程优缺点:
✅ CPU 利用率提升(等待时不阻塞,可做其他事)。
✅ 设备与 CPU 并行(数据准备阶段 CPU 忙,完成时中断处理)。
❌ 仍以字节/字为单位处理(如读 1MB 需 1M 次中断,开销大)。
❌ 数据需经 CPU 寄存器中转(设备→CPU→内存)。
3. DMA(直接存储器存取)方式
原理:
- 硬件(DMA 控制器)接管数据块传输(如磁盘读扇区到内存)。
- CPU 初始化 DMA(设置 MAR(内存地址)、DC(字数)、CR(命令))。
- DMA 控制器直接操作总线,设备⇨内存(无需 CPU 干预,仅块开始/结束中断)。
- 流程图:
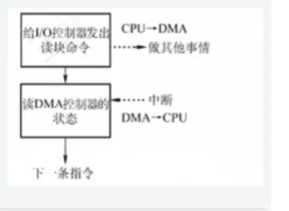
CPU → 发 DMA 命令(设 MAR=0x1000, DC=1024)→ DMA 读设备 → 直存内存 0x1000 → 完成中断特点:
- 数据块传输(例:一次读 512 字节扇区)。
- 无 CPU 中转(设备⇔内存直达)。
- 少量 CPU 干预(仅块开始(初始化)、结束(中断处理))。
优缺点:
✅ 大幅提升 I/O 速率(块传输减少中断次数,如 1MB 只需 1 次 DMA 中断 vs 1M 次中断驱动)。
✅ CPU 效率高(初始化后可继续运算)。
❌ 需专用硬件(DMA 控制器)。
❌ 灵活性受限(CPU 需指定块大小、内存位置)。
4. 通道控制方式
原理:
- 专属 I/O 处理器(通道),执行通道程序(存于内存,类似 CPU 指令)。
- CPU 发通道指令(如“执行通道程序 0x2000,操作磁盘”)。
- 通道独立管理多设备 I/O(例:同时读磁盘、写磁带),完成后中断。
与 DMA 对比:
对比项 | DMA | 通道 |
控制粒度 | 块(需 CPU 告知大小、位置) | 程序(通道自行决定) |
设备数量 | 单设备(1 控制器→1 设备) | 多设备(1 通道→多设备) |
指令类型 | 简单(读、写块) | 丰富(类似 CPU 指令集) |
缺点:
- ✅ 最高并行度:CPU、通道、多设备可并行工作(例:CPU 计算,通道读磁盘+写网卡)。
- ✅ 灵活(通道程序可定制复杂 I/O 逻辑)。
- ❌ 硬件成本高(需通道处理器)。
- ❌ 编程复杂(需写通道程序)。
核心对比表
方式 | CPU 干预度 | 数据单位 | 传输路径 | 中断频率 | 适用场景 |
程序直接控制 | 高(全程轮询) | 字/字节 | 设备→CPU→内存 | 无(轮询) | 简单低速设备(如早期终端) |
中断驱动 | 中(仅中断时) | 字/字节 | 设备→CPU→内存 | 高(每字中断) | 中低速设备(如键盘) |
DMA | 低(块首尾) | 数据块(扇区) | 设备⇨内存(直达) | 低(每块中断) | 高速块设备(磁盘、SSD) |
通道 | 极低(指令级) | 自定义(程序) | 多设备并行 | 极低(程序完) | 大型主机多设备并发(IBM zSeries) |
总结
I/O 控制方式的进化是硬件复杂度与软件效率的平衡:
- 简单设备(键盘)用中断驱动(性价比高)。
- 磁盘等高速块设备用 DMA(块传输减少开销)。
- 大型系统(服务器)用 通道(多设备并行,释放 CPU)。
理解每种方式的数据单位、CPU 干预时机、硬件需求,能准确分析 I/O 性能瓶颈(如“系统中断数过高→是否该用 DMA?”)。
✨ 一句话记忆:轮询忙等待,中断省 CPU,DMA 传块快,通道管多台! ✨