[2025CVPR-图象分类方向]CATANet:用于轻量级图像超分辨率的高效内容感知标记聚合
1. 研究背景与动机
- 问题:Transformer在图像超分辨率(SR)中计算复杂度随空间分辨率呈二次增长,现有方法(如局部窗口、轴向条纹)因内容无关性无法有效捕获长距离依赖。
- 现有局限:
- SPIN等聚类方法依赖稀疏聚类中心传播信息,导致近似粗糙且推理速度慢(需迭代更新中心)。
- ATD引入字典学习但计算负担大,不适合轻量化场景。
- 解决方案:提出 CATANet,通过内容感知令牌聚合实现高效长距离依赖建模,兼顾性能与速度。
2. 方法设计
2.1 整体架构
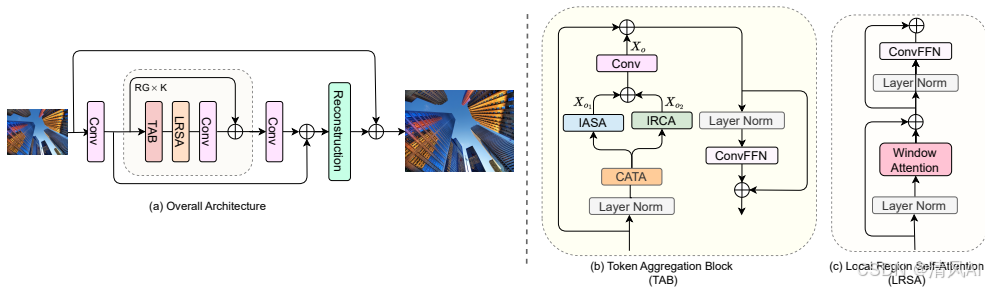
三阶段流程:
- 浅层特征提取:3×3卷积映射LR图像至高维特征。
- 深层特征提取:K个残差组(RG),每个RG包含:
- 令牌聚合块(TAB):核心创新模块。
- 局部区域自注意力(LRSA):增强局部细节。
- 3×3卷积:细化特征并学习位置嵌入。
- 图像重建:全局残差信息 + LR上采样 → 输出HR图像。
2.2 令牌聚合块(TAB)

- 四大组件:
- 内容感知令牌聚合(CATA):
- 共享全局令牌中心,仅训练阶段通过指数移动平均(EMA)更新(λ=0.999)。
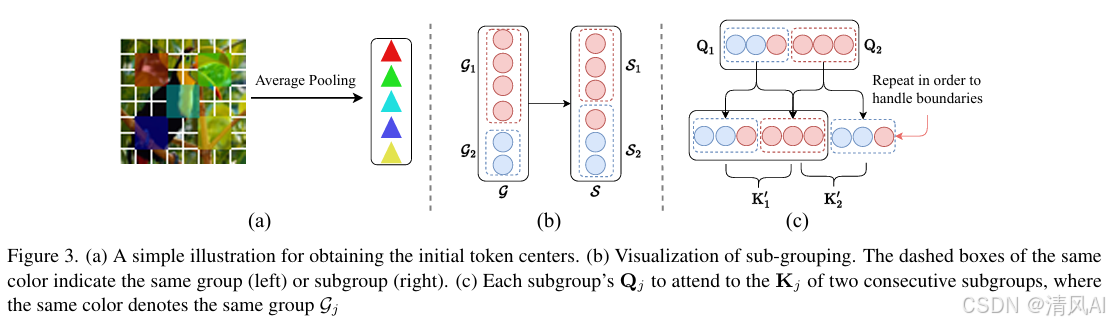
- 按相似度将令牌分组(图4),解决SPIN的推理延迟问题。
- 子组划分(S):平衡并行效率(图3b),提升速度2倍(表6)。

- 组内自注意力(IASA):
- 组内令牌交互,允许关注相邻子组(图3c),提升PSNR 0.02-0.05dB(表1)。
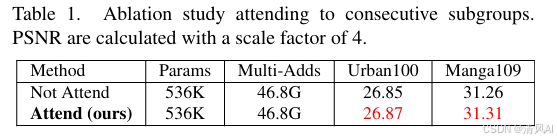
- 组内令牌交互,允许关注相邻子组(图3c),提升PSNR 0.02-0.05dB(表1)。
- 组间交叉注意力(IRCA):
- 子组与令牌中心交叉注意力,增强全局交互(M≪N控制计算量)。
- 子组与令牌中心交叉注意力,增强全局交互(M≪N控制计算量)。
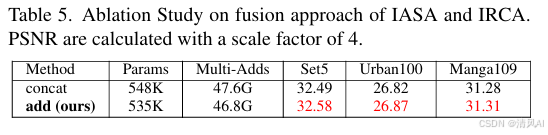
- 1×1卷积:融合IASA与IRCA输出,加法融合优于拼接(表5)。
- 内容感知令牌聚合(CATA):
2.3 局部区域自注意力(LRSA)
- 采用重叠块机制(参考HPINet),学习局部细节特征。
- 配合ConvFFN进行通道维度特征交互。
3. 实验与分析
3.1 性能对比
- 数据集:DIV2K训练,Set5/Set14/B100/Urban100/Manga109测试。
- 结果(表2):
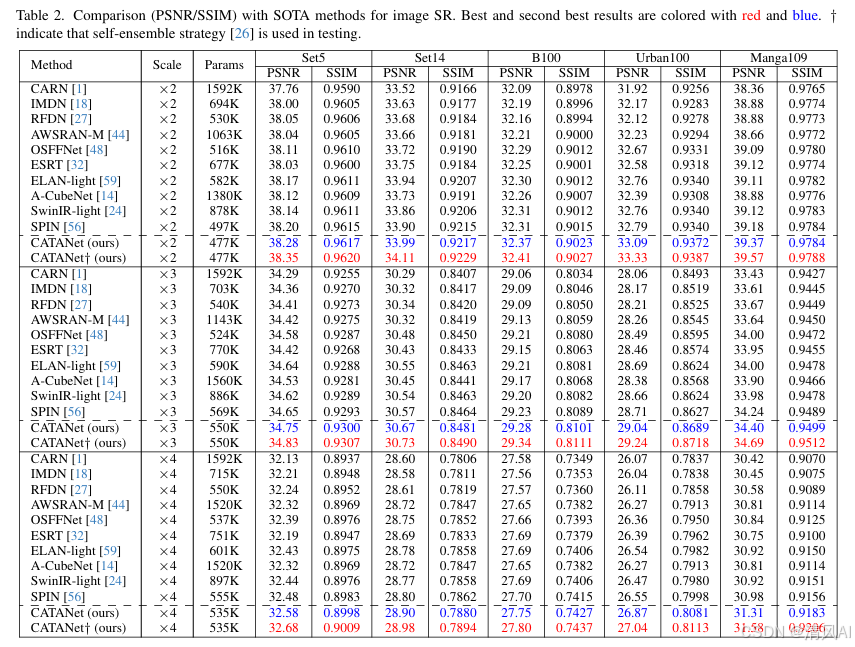
- 轻量化优势:参数量(535K)低于SPIN(555K),PSNR显著提升(×4最高+0.33dB)。
- 视觉对比:恢复边缘更清晰,伪影更少(图6)。

- 速度:推理速度达SPIN的5倍,比SwinIR快2倍。
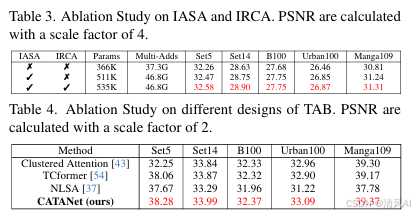
3.2 消融实验
- IASA+IRCA必要性:移除后PSNR下降0.15–0.22dB(表3)。
- CATA设计:优于Clustered Attention/NLSA等(表4)。
- 子组划分:推理速度从188ms→86ms(表6)。
3.3 可视化分析

- LAM热力图:TAB捕获更长距离依赖(图5)。
- 令牌分组:内容相似区域被精准聚合。
4. 结论与贡献
- 核心贡献:
- CATANet:首个结合内容感知令牌聚合与注意力的轻量化SR网络。
- CATA模块:仅训练阶段更新令牌中心,消除推理延迟。
- 双注意力机制:IASA实现细粒度长程交互,IRCA强化全局信息。
- 性能突破:PSNR最大提升0.60dB(自集成),推理速度翻倍,适用于移动设备。
论文地址:https://arxiv.org/pdf/2503.06896v1