一文读懂 Doris 冷热分离,优化存储与查询性能
在大数据分析领域,随着数据量的迅猛增长,如何高效管理和利用数据成为了关键问题。Doris 作为一款强大的分析型数据库,其冷热分离功能为解决这一问题提供了有力的支持。本文将深入探讨 Doris 冷热分离的相关知识,包括其重要性、原理、使用方式、最佳实践以及常见问题解答等,帮助读者全面了解并掌握这一功能。
一、为什么需要冷热分离
随着业务的发展,数据量呈爆发式增长。企业不仅需要存储海量数据,还面临着如何在保证查询性能的同时降低存储成本的挑战。在这种情况下,冷热分离技术应运而生。
在许多业务场景中,数据的访问频率具有明显的时间特征。近期产生的数据通常会被频繁查询和分析,这些数据被称为热数据。而随着时间的推移,数据的访问频率逐渐降低,这些数据则成为冷数据。如果将所有数据都存储在高性能、高成本的存储介质上,无疑会造成资源的浪费。因此,冷热分离的核心目的就是将热数据和冷数据分开存储,热数据存储在高性能的存储介质中以保证查询性能,冷数据则存储在低成本的存储介质中以降低存储成本,从而实现查询性能和存储成本的平衡。
以日志分析场景为例,新产生的日志数据对于实时监控和故障排查至关重要,需要快速查询和分析,属于热数据。而历史日志数据虽然访问频率较低,但出于合规性和偶尔的数据分析需求,仍需要长期保存,这些就是冷数据。通过冷热分离,将近期的日志数据存储在 Doris 的本地存储中,保证实时查询的高性能,而将历史日志数据存储到对象存储等低成本存储介质中,既能满足数据保存需求,又能大幅降低存储成本。
二、Doris 冷热分离原理简介
Doris 的冷热分离功能主要基于存储策略和资源管理来实现。用户可以创建不同的存储资源,如基于对象存储(如 S3 兼容模式、AZURE 模式)或 HDFS 的资源,并通过创建存储策略来指定数据何时以及如何移动到不同的存储资源上。
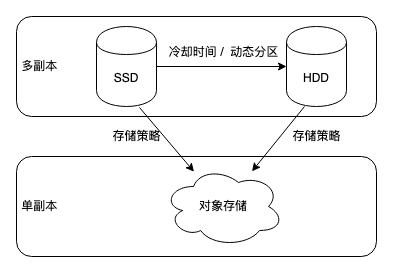
在 Doris 中,每个表或分区都可以绑定一个存储策略。当数据满足存储策略中定义的冷却条件(如达到指定的时间 TTL 或具体的冷却时间点)时,Doris 会自动将数据从本地存储迁移到指定的远程存储资源中,如对象存储。在查询时,Doris 会根据数据的存储位置,自动从相应的存储介质中读取数据。如果查询涉及到冷数据,Doris 会高效地从远程存储中获取数据并进行处理,同时结合本地缓存和优化的查询执行计划,尽量减少查询延迟,确保查询性能。
例如,创建一个存储策略,设置冷却时间为数据导入后的 1 天(即 cooldown_ttl = “1d”),并指定存储资源为一个 S3 兼容的对象存储资源。那么,在数据导入 Doris 一天后,符合条件的数据就会被自动迁移到该对象存储中。
三、使用方式
(一)基于对象存储
- S3 兼容模式:
CREATE RESOURCE "remote_s3"
PROPERTIES
("type" = "s3","s3.endpoint" = "bj.s3.com","s3.region" = "bj","s3.access_key" = "bbb","s3.secret_key" = "aaaa",-- 以下为可选属性"s3.root.path" = "prefix","s3.connection.maximum" = "50","s3.connection.request.timeout" = "3000","s3.connection.timeout" = "1000"
);
在创建 S3 兼容的存储资源时,需要指定关键的属性,如端点(s3.endpoint)、区域(s3.region)、访问密钥(s3.access_key)和秘密密钥(s3.secret_key)。可选属性如根路径(s3.root.path)可以用于在对象存储中指定一个特定的前缀路径来存储数据,连接最大数(s3.connection.maximum)等属性可以优化与对象存储的连接性能。
(1) 关于 path style:
Path style 和 Virtual hosted style:Virtual hosted style 是指将 Bucket 置于 Host Header 的访问方式。基于安全考虑,OSS 仅支持 virtual hosted 访问方式。所以在 S3 迁移至 OSS 后,客户端应用需要进行相应设置。部分 S3 工具默认使用 Path style,也需要进行相应配置,否则可能导致 OSS 报错,并禁止访问。可参考阿里云文档进行详细配置。
(2) AZURE 这类和 S3 不兼容的模式:
CREATE RESOURCE "remote_s3"
PROPERTIES
("type" = "azure","s3.endpoint" = "${ak}.blob.core.windows.net/","s3.region" = "bj","s3.access_key" = "bbb","s3.secret_key" = "aaaa",-- 以下为可选属性"s3.root.path" = "prefix","s3.connection.maximum" = "50","s3.connection.request.timeout" = "3000","s3.connection.timeout" = "1000"
);
对于 AZURE 模式,同样需要指定类型(type = “azure”)以及相关的连接和认证信息。特别要注意的是,AZURE 的 endpoint 需要按照特定格式 “${ak}.blob.core.windows.net/” 填写,并且要清楚 AZURE blob 和 S3 之间概念的对应关系,如 AK 对应 AccountName,SK 对应 AccountKey,Bucket 对应 Container,Object 对应 Blob(在 Doris/Selectdb 中只使用 BlockBlob)。
(二)基于 HDFS
使用如下语句创建基于 HDFS 的存储资源:
CREATE RESOURCE hdfs_resource PROPERTIES ("type"="hdfs","fs.defaultFS" = "hdfs://10.220.147.151:8020","hadoop.username" = "root","password"="passwd","root_path"="prefix","dfs.nameservices" = "my_ha","dfs.ha.namenodes.my_ha" = "my_namenode1, my_namenode2","dfs.namenode.rpc-address.my_ha.my_namenode1" = "nn1_host:rpc_port","dfs.namenode.rpc-address.my_ha.my_namenode2" = "nn2_host:rpc_port","dfs.client.failover.proxy.provider" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
);
在创建 HDFS 资源时,需要详细指定 HDFS 的默认文件系统地址(fs.defaultFS)、用户名(hadoop.username)、密码(password)、根路径(root_path)等信息。如果是高可用的 HDFS 集群(HA),还需要配置相关的名称服务(dfs.nameservices)、名称节点(dfs.ha.namenodes.my_ha)以及它们的 RPC 地址等,以确保 Doris 能够正确连接和使用 HDFS 存储。
(三)基于SSD 和 HDD 层级存储
Doris 支持在不同磁盘类型(SSD 和 HDD)之间进行分层存储,结合动态分区功能,根据冷热数据的特性将数据从 SSD 动态迁移到 HDD。这种方式既降低了存储成本,又在热数据的读写上保持了高性能。
通过配置动态分区参数,用户可以设置哪些分区存储在 SSD 上,以及冷却后自动迁移到 HDD 上。
- 热分区:最近活跃的分区,优先存储在 SSD 上,保证高性能。
- 冷分区:较少访问的分区,会逐步迁移到 HDD,以降低存储开销。
有关动态分区的更多信息,请参考:数据划分 - 动态分区。
基于这种做冷热分层比较简单,不需要创建存储策略,直接在建表的时候指定动态分区的策略就可以了,例如
CREATE TABLE tiered_table (k DATE)PARTITION BY RANGE(k)()DISTRIBUTED BY HASH (k) BUCKETS 5PROPERTIES("dynamic_partition.storage_medium" = "hdd","dynamic_partition.enable" = "true","dynamic_partition.time_unit" = "DAY","dynamic_partition.hot_partition_num" = "2","dynamic_partition.end" = "3","dynamic_partition.prefix" = "p","dynamic_partition.buckets" = "5","dynamic_partition.create_history_partition"= "true","dynamic_partition.start" = "-3");
(三)创建存储策略
在创建完存储资源之后,即可创建使用该资源的存储策略。例如:
CREATE STORAGE POLICY testPolicy
PROPERTIES("storage_resource" = "s3","cooldown_datetime" = "2024-06-08 00:00:00"
);
或
CREATE STORAGE POLICY testPolicy
PROPERTIES("storage_resource" = "s3","cooldown_ttl" = "1d"
);
第一个例子中,通过指定 cooldown_datetime 来设置数据在特定时间点进行冷却迁移。第二个例子则是通过设置 cooldown_ttl,让数据在导入后经过 1 天时间进行冷却迁移。在实际使用中,用户需要根据业务需求合理设置冷却条件。同时要注意,cooldown_ttl 不要设置得太短,因为每次 tablet 到达 cooldown_ttl 后都可能进行对象存储 IO,这会占据带宽且高频率的 IO 会产生费用。
而且,从最佳实践角度,建议是 tablet 做完 compaction 之后把版本 range 比较大的 rowset 上传到对象存储,否则多个冷数据 rowset 如果要做 cold compaction 则会把数据全部都下载到本地再次做 compaction 并且再次上传到对象存储,增加不必要的开销。
(四)建表时使用 STORAGE POLICY
CREATE TABLE IF NOT EXISTS create_table_use_created_policy
(k1 BIGINT,k2 LARGEINT,v1 VARCHAR(2048)
)
UNIQUE KEY(k1)
DISTRIBUTED BY HASH (k1) BUCKETS 3
PROPERTIES("enable_unique_key_merge_on_write" = "false","storage_policy" = "testPolicy"
);
注意: UNIQUE 表如果设置了 “enable_unique_key_merge_on_write” = “true” 的话,无法使用此功能。
四、常见问题解决方案
- 支持哪些存储后端:Doris 支持多种存储后端,包括 COS、BOS、OSS、MINIO、OBS 等。从 2.1 开始支持 hdfs,且从 2.1.4 rc03 开始 hdfs resource 可以支持指定 root prefix。从 3.0 开始支持 AZURE。
- 查看某个 partition 的 cooldown 设置是否工作:可以通过查询 storage policy 是否设置来判断。执行如下语句:
show proc '/dbs/10008/10013/partitions/'
返回结果中,RemoteStoragePolicy 表示绑定到 partition 的 storage policy,CooldownTime 表示 tablet 移动到冷存的时间。通过检查这些字段的值,用户可以明确 partition 的 cooldown 设置是否生效,以及数据预计何时会被迁移到冷存储中。
-
查看数据占用空间:存储空间统计来自于 BE 向 FE 的周期性汇报,所以查询 FE 得到的不是实时的情况。
了解数据占用空间情况,有助于用户合理规划存储资源,及时发现存储使用异常,避免因存储不足导致的系统故障。了解数据占用空间情况,有助于用户合理规划存储资源,及时发现存储使用异常,避免因存储不足导致的系统故障。
- 查看 table 中各 tablet 的空间占用,RemoteDataSize 是远程空间占用,可使用如下语句:
show tablets from $table_name;
- 查看 tablet 的空间占用,需要先获取 DetailCmd:
show tablet $tablet_id;
然后执行 DetailCmd,例如:
SHOW PROC '/dbs/10008/10013/partitions/10012/10014/10029';
- 查看 BE 的空间占用,DataUsedCapacity 是 BE 本地空间占用,RemoteUsedCapacity 是 BE 上的所有 tablet 在远程存储的空间占用,可使用如下语句:
show backends;
- 如何查看数据删除的日志:可以通过 grep 相关关键词来查看数据删除日志。例如:
grep "delete unused files" be.INFO | grep ${tablet_id}
grep "delete unused file" be.INFO | grep ${rowset_id}
这些日志记录了数据删除的相关信息,包括删除的文件、对应的 tablet 或 rowset 等。通过分析这些日志,用户可以了解数据删除的过程和原因,排查数据删除过程中出现的问题。
- 表和 partition 都设置了 policy,会使用哪个 policy:假设有 policy A 和 policy B,现在新建一个有 3 个分区的表:
CREATE TABLE IF NOT EXISTS ${tableName} (L_ORDERKEY INTEGER NOT NULL)DUPLICATE KEY(L_ORDERKEY, L_PARTKEY, L_SUPPKEY, L_LINENUMBER)PARTITION BY RANGE(`L_SHIPDATE`)(PARTITION `p202301` VALUES LESS THAN ("1995-12-01") ("storage_policy" = "B"),PARTITION `p202302` VALUES LESS THAN ("2017-03-01"))DISTRIBUTED BY HASH(L_ORDERKEY) BUCKETS 3PROPERTIES ("replication_num" = "1","storage_policy" = "B")
最后是按照整张表的 policy B 来设置各个 partition 的 policy B。如果需要修改 partition 的 policy,则可以手动 alter partition properties 来修改 partition 的 policy。用户在设置表和分区的存储策略时,需要明确这种优先级关系,根据实际业务需求进行合理配置,以确保数据按照预期的方式进行冷热分离存储。
-
什么情况下才能 alter table 的 policy:每个 policy 会指定一个 resource,可以理解成用户的数据会冷却到 resource 的 prefix 目录下。为了防止 resource 切换导致之前冷却的数据无法找到,Alter table policy 有以下限制:
-
如果表没有进行过冷却,那么可以更换 policy 到任意其他 policy,即使其他 policy 指向的 resource 不一样。
-
如果表已经进行冷却,只可以将 policy 更换到另一个指向相同 resource 的 policy。
-
-
Resource 的连通性如何检查:目前代码中只有 S3 resource 会去检查是否连通,hdfs resource 需要用户自己做连通性检查。如果出现了读不到或者写不了 resource 的情况,可以先检查 resource 的连通性。例如,对于 hdfs resource,用户可以使用相关的 HDFS 命令或工具来测试连通性,确保 Doris 能够正常访问存储资源,避免因资源连通性问题导致的数据存储或查询失败。
-
如何控制冷查询对 BE 的亲热性:因为冷查会访问对象存储,所以在开启 file cache 的情况下我们可能会倾向于让冷查尽量打到同一台机器这样能保证这台机器的file cache能充分命中,减少对对象存储的访问同时加快查询速度。
-
异常日志分析:
failed to cooldown:如果日志中出现failed to get file size报错,通常是非 cooldown 副本的同步问题:-
非 cooldown 副本会在达到冷却时间后,尝试同步 cooldown 副本上传的元数据(cooldown meta),若此时 cooldown 副本尚未完成元数据上传,就会出现该错误。
-
处理方式:通过
show tablet ${tablet_id}找到 cooldown 副本所在的 BE 节点,查看该节点日志(grep cooldown be.INFO | grep ${tablet_id}),确认冷却是否正常进行。若频繁报错,可能是 cooldown 副本性能不足,需排查资源瓶颈。
-
-
异常日志分析:
cooldowned version larger than that to follow with cooldown version。多副本场景下,cooldown 副本可能发生切换,导致不同副本的冷却版本不一致:-
例如:副本 B 先作为 cooldown 副本上传了版本
[0-11],后切换为副本 A 上传版本[0-7],副本 B 同步时发现本地版本(11)高于最新元数据版本(7),从而报错。 -
处理方式:该错误通常是正常的版本同步过程,无需干预。若数据已停止写入但持续报错,可通过
curl ${be_host}:${http_port}/api/compaction/show?tablet_id=${tablet_id}分析各副本的版本分布,排查是否存在副本数据不一致。
-
-
异常日志分析:
cooldowned version is not aligned with version,多副本冷却版本未对齐时触发,例如:-
副本 B 作为 cooldown 副本上传了版本
[0-11],副本 A 同步时发现本地版本无法与[0-11]对齐(如本地版本为[0-5]),则会等待后续冷却完成。 -
处理方式:无需手动干预,系统会在 cooldown 副本完成更高版本冷却后自动同步。若数据已停止写入且持续报错,需检查副本版本分布(同上一条)。
-
-
如何控制冷却任务的产生速度?
BE 的配置 generate_cooldown_task_interval_sec 可控制冷却任务的生成间隔(单位:秒),默认值根据集群规模自动调整。若冷却任务过于密集(如占用过多 IO),可适当调大该参数。
-
有哪些日志和 metric 可观察冷却进度?
-
冷却任务生成:
grep "cooldown producer get tablet num" be.INFO(查看全局任务数量); -
单个 tablet 冷却:
grep cooldown be.INFO | grep ${tablet_id}; -
rowset 冷却细节:
grep ${tablet_id} be.INFO | grep rowset(查看具体 rowset 的上传状态); -
本地数据删除:
grep ${tablet_id} be.INFO | grep "remove files in rowset"(确认本地冷数据已被回收)。
-
五、总结
Doris 的冷热分离功能通过智能区分热数据(本地存储)和冷数据(对象存储 / HDFS),在保证查询性能的同时大幅降低存储成本,尤其适合日志分析、历史数据归档等场景。通过本文的指南,相信你已掌握 Doris 冷热分离的核心用法和最佳实践,可根据业务需求灵活配置,让数据管理更高效、成本更可控!