优化:Toc小程序猜你喜欢功能
引言:来自自创的小程序中热点接口,本小程序专为在校学生自提点餐使用
一、功能描述
该功能作为一个推荐的职责,根据用户最近行为给用户推荐用户可能喜欢去吃的店铺,可能比较简洁,但是需要设计的方面挺多的,需要有三个方面去走:
设计架构如下:
- 用户行为采集
- 冷热数据隔离
- 推荐店铺缓存的预热
- 猜你喜欢接口查询(核心)
从这些设计上就能保证在使用接口查询的时候,就不需要花很多时间去分析,保证了热点接口的响应时间处于较低的一个状态,不过对于一个热点接口,不止要保证他的高性能,还需要保证他的高可用,这就需要涉及到降级策略,这些都是一个考量的标准。
二、接口功能实现
用户行为采集
这里我使用到的技术栈有美团的mzt-Biz-Log框架做类似AOP的切面功能,保证用户进店行为日志优雅的实现,加上redis进行统计猜你喜欢服务的用户,使用rocketmq进行日志的统计,实现进店异步化,并且达到削峰限流的效果。

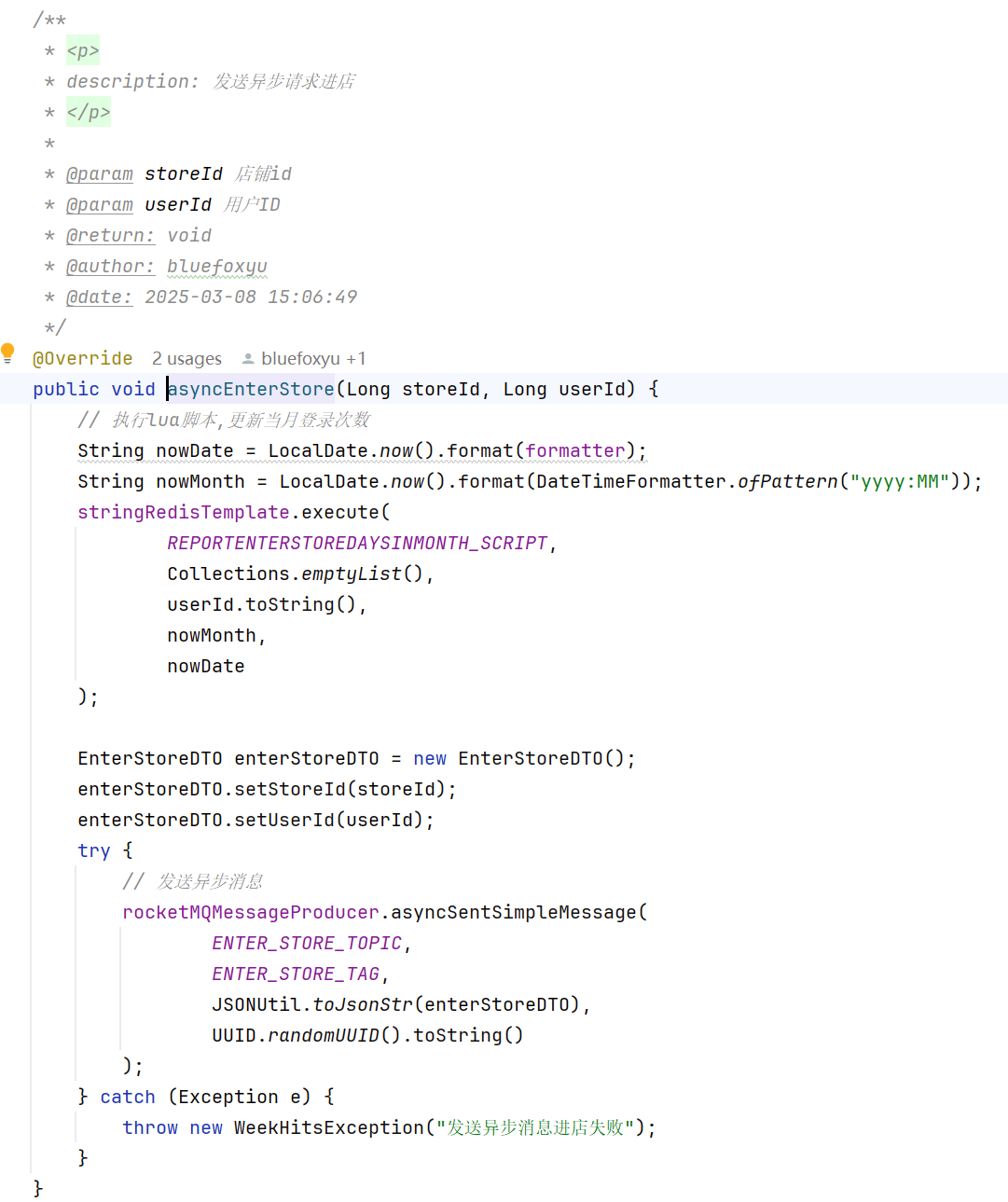
消息队列的异步化,保证了用户正常去访问一个店铺详细的体验,达到日志记录无感化。
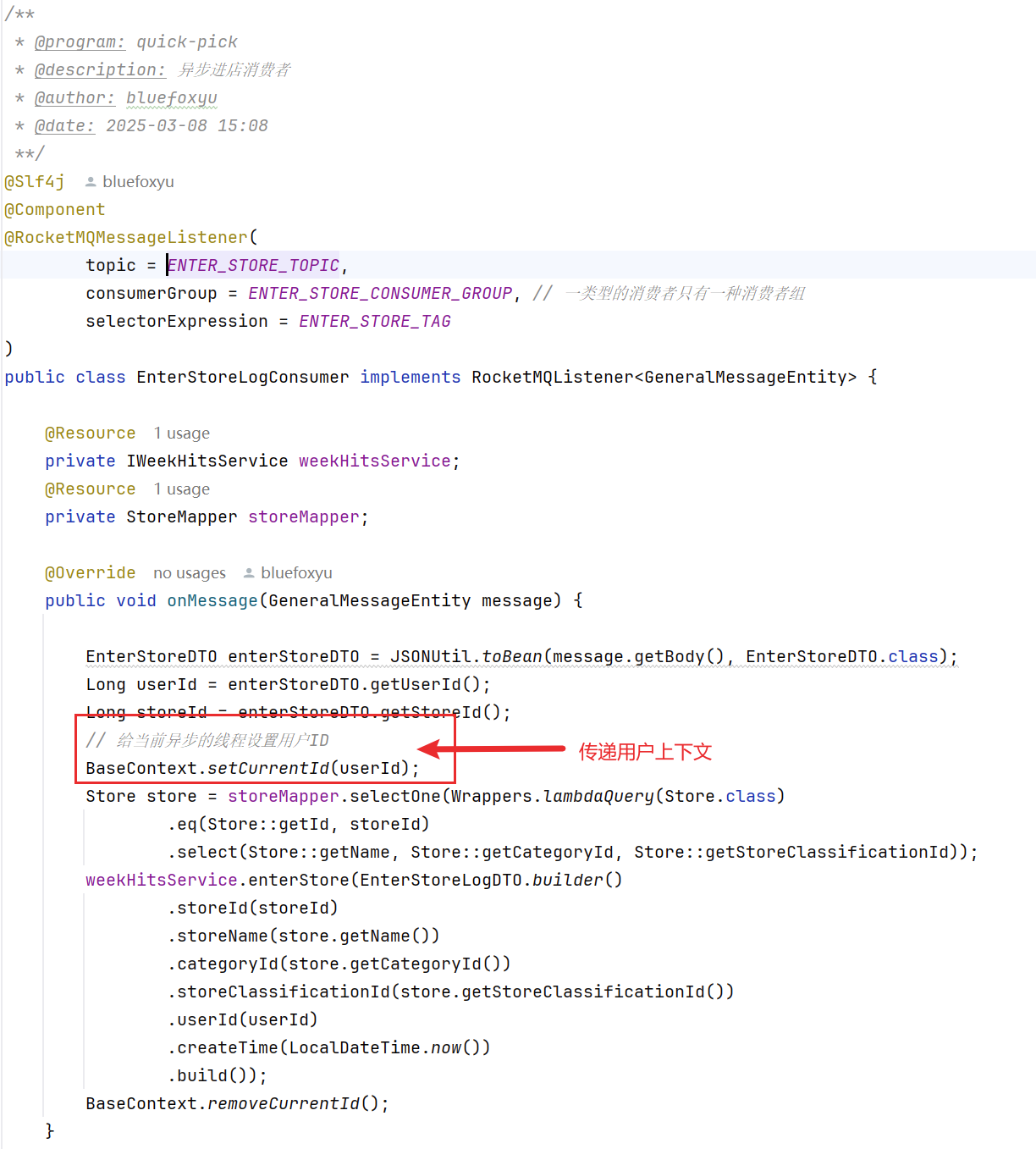
由于消息队列是异步线程去处理的,传递用户的消息过来很重要,更加方便去获取到用户线程id
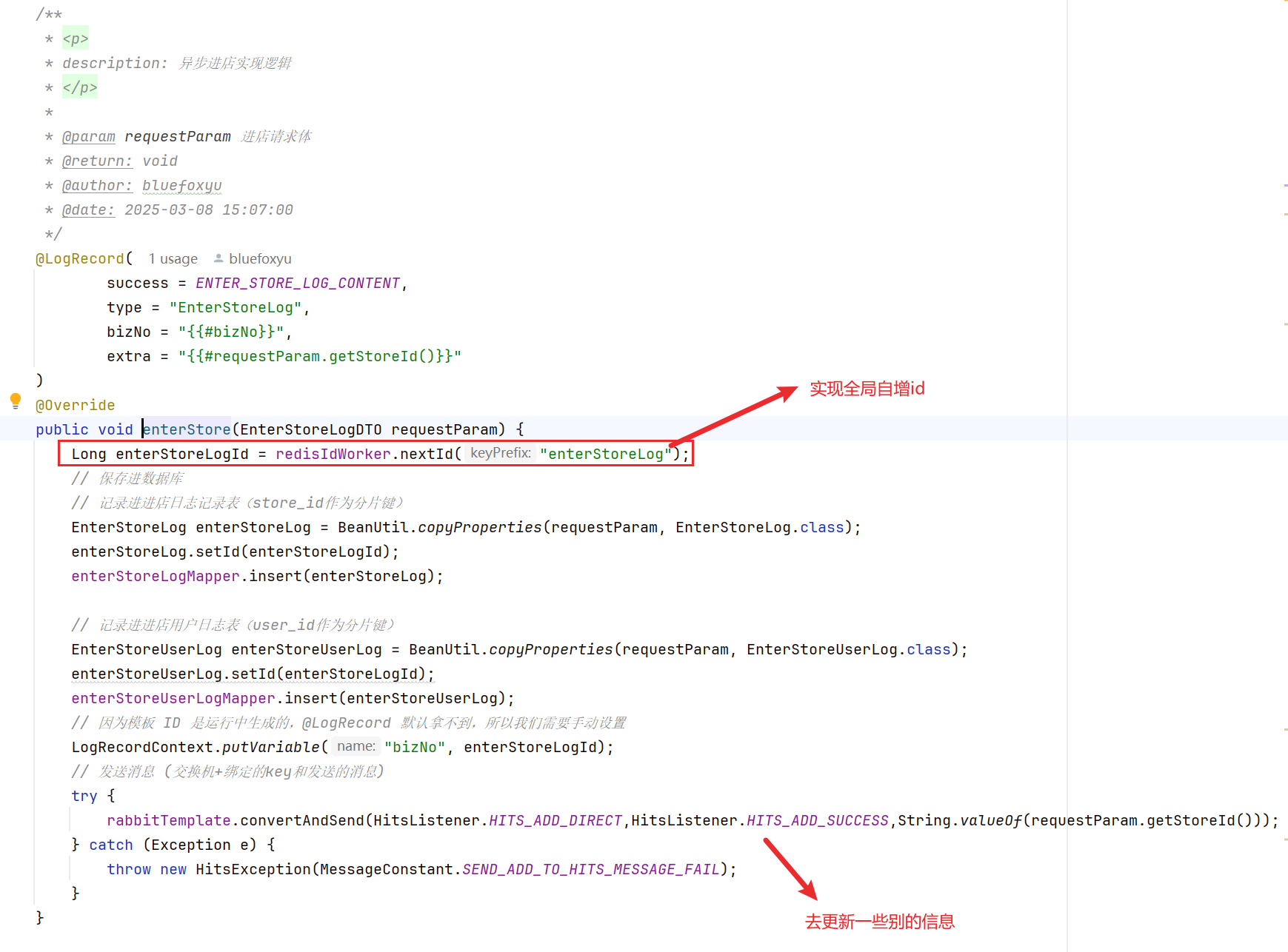
- 这里使用到的就是美团的mzt-Biz-Log框架,进行优雅的日志记录,后续可以新增一个实现类进行高内聚的做具体的日志完善逻辑
- 注意这里使用了全局唯一自增的id,后续在分表冷热隔离中会被用到进行删除数据的操作
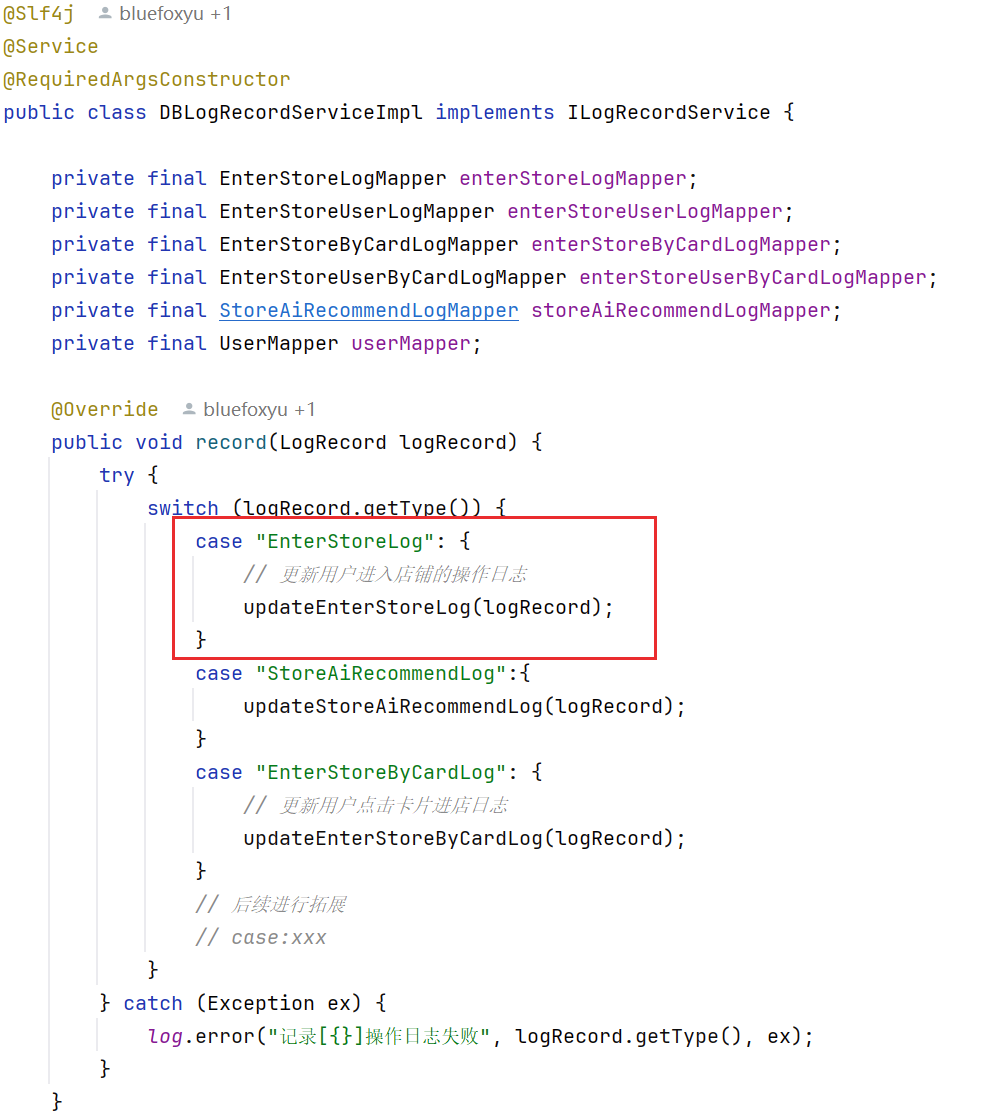
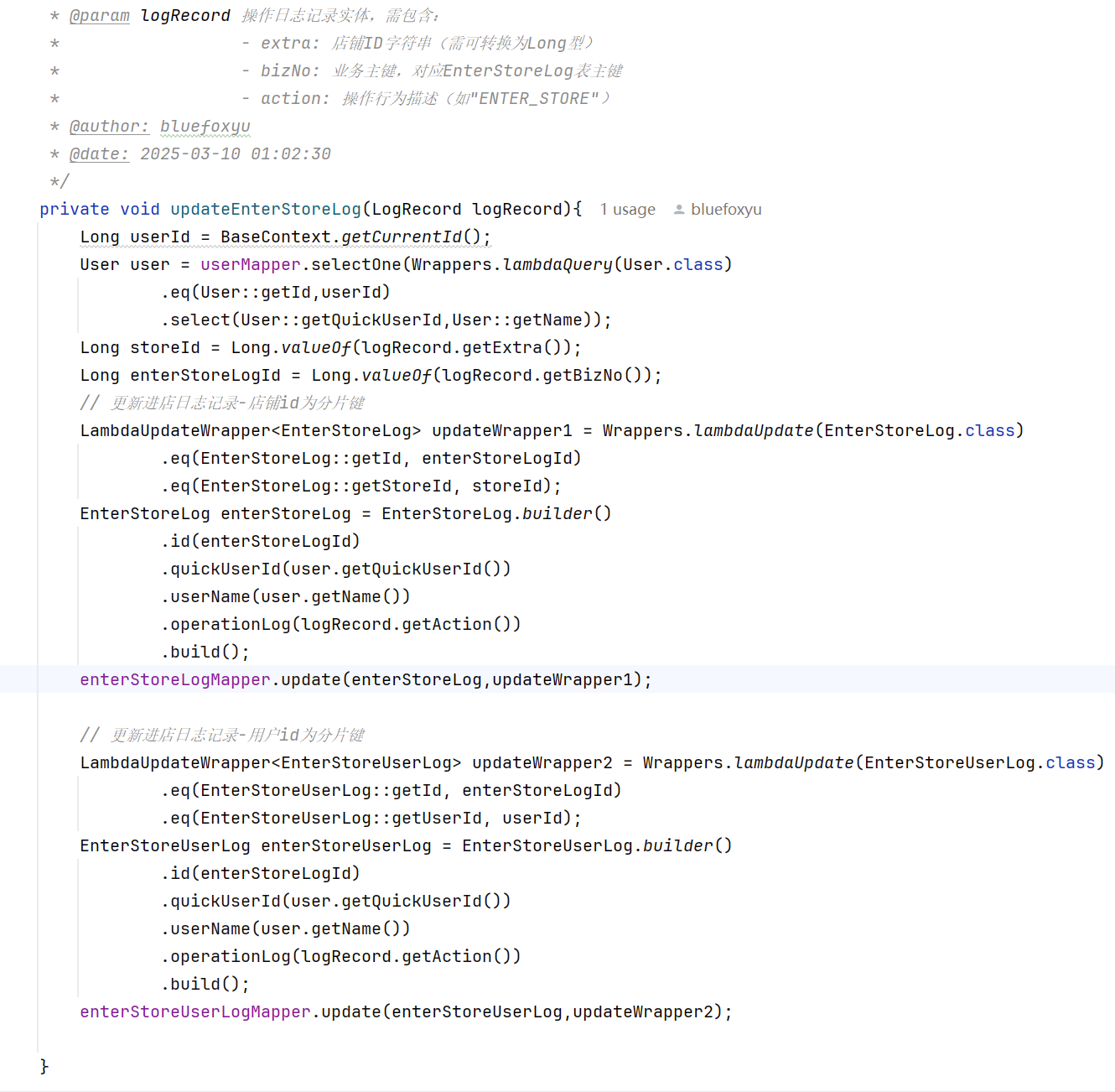
使用类似AOP的思想对日志的完善,这里我对用户数据分了16个表,保证热点查询不会聚集在单表中,具体的分表学习可以移步到我这篇文章进行学习:
SpringBoot中使用Sharding-JDBC实战(实战+版本兼容+Bug解决)_springboot shardingjdbc-CSDN博客文章浏览阅读3.2k次,点赞23次,收藏37次。这里整理的是使用SpringBoot3.2.4和ShardingSphere-JDBC5.5.0进行分表操作,里面有遇到的bug并且解决的流程,还有结合自己之前做的秒杀博客进行测试分表,很详细_springboot shardingjdbchttps://blog.csdn.net/qq_73440769/article/details/143992138?spm=1001.2014.3001.5502
冷热数据隔离
这个功能主要由另外的一个博主进行实现,欢迎参考他的文章进行详细学习:
优化:将针对单一日志表的冷热数据分离类改造成通用类-CSDN博客文章浏览阅读283次,点赞5次,收藏4次。文章介绍了店铺推荐系统中日志数据存储方案的优化过程。原方案将热数据存入Elasticsearch,现改为存储冷数据,并针对代码冗余问题进行重构。通过引入泛型机制实现通用处理类,将固定代码参数化,同时为不同日志类型提供定制化ES处理逻辑。优化后的方案提升了代码复用性,支持多日志表并行处理,并通过线程池提高执行效率。文中详细展示了改进后的代码实现,包括通用日志处理方法、任务创建机制和重试策略等核心功能模块。https://blog.csdn.net/2401_88959292/article/details/148619523?spm=1001.2014.3001.5502其实思想就是:使用定时任务进行隔离一个月之前的数据,将冷数据进行归档,保证热数据才会被用来进行分析,这样就能极大的削减db的承重,提升查询效率、释放 MySQL 压力,这里隔离的数据库可以不适用es,可以使用一些实时数仓比较合适。
- 每天凌晨执行,支持分页游标 + 泛型处理;
- 支持所有进店日志的通用迁移;
- 使用多线程 + 重试机制处理批量插入,保障稳定性。
- 每类日志各跑一个线程任务,互不干扰
对于怎么不给时间加索引也能保证比较快速的查询需要隔离的店铺,首先id是自增的,查16个表中最靠近一个月的最小的id,比这个id小的就是一定需要进行删除的,或者给时间字段加上索引也是可以的,实现也是使用类似的思想。
推荐店铺缓存的预热
目的:为了保证用户的体验,将复杂的分析过程放在了凌晨,使用定时任务进行分析,将分析好的结果放进redis,这样子用户体验感就极佳,欢迎参考这位博主的思路:
优化日志分析店铺推荐方案:用户范围的精确度以及ES与MySQL的查询效率差异-CSDN博客文章浏览阅读785次,点赞6次,收藏15次。本文针对原有店铺推荐方案的两个核心问题提出优化方案。问题一是用户范围不精确,通过Redis记录用户每月首次进店行为作为登录标识,并统计热点用户(月登录≥14天);问题二是数据处理效率低,改用MySQL存储热数据(建立用户-店铺映射),ES仅作冷备份。方案采用Lua脚本确保原子性操作,并优化了权重计算模型(店铺50%、分类30%、分区20%)。最终实现通过分批并行处理用户日志数据,结合个性化推荐与热门店铺补充机制,显著提升了10万级用户日志场景下的推荐效率和精准度。https://blog.csdn.net/2401_88959292/article/details/148618437?spm=1001.2014.3001.5502
为避免推荐实时计算带来性能瓶颈,我们采用“离线计算 + 缓存预热”方式,利用定时任务每天构建用户维度的推荐结果,缓存到 Redis 中。
- 用户分批处理(活跃用户访问≥7天),每批200人,异步线程池分析;
- 推荐维度包括:访问频率、店铺分类、分区,采用加权模型打分;
- 冷热数据分离后,在构建推荐时能快速分析历史行为;
- 最终结果缓存到 Redis 的
STORE_RECOMMEND_ONE:{userId}列表中; - 未登录用户使用通用热门推荐(Top 打分店铺)。
这里讲一下推荐维度的意义:
我们可以参考先成的推荐系统,比如抖音刷碎片,会有几个考量:
- 比如你爱刷这个人视频比较多,就会给你很多推荐;
- 比如你喜欢刷这类型视频比较多,也会给你推荐很多类似的;
- 比如你比较喜欢刷当前地区的视频,抖音也会给你推荐很多
参考上面的三点,就可以类比到我们的这些维度。我们会拿出日志,取出这些维度的数据,给每个维度进行赋分,各乘于一个百分比,最后相加得到最后得分,取出前四名的放进最后预热的结果中。
这里大家可能会想,是给所有用户进行分析吗。回答是:不是。因为热点分析的消耗成本是很大的,有些用户不是小程序常驻,只是偶尔使用,甚至只是为了体验一次,这些用户的话推荐优先级就不是最高的,所以我们会在日志记录的时候就记录需要被推荐的用户,这些用户的考量标准是:一个月内最少使用一周,这里我使用了redis的自增id进行记录有哪些用户一个月内使用了多少次,用set集合保证一个用户一天最多记录一次就好,这里就可以得到我需要分析的用户。
猜你喜欢接口查询(核心)
这里是重中之重,这里需要保证高性能并且高可用,那就需要避免走db的路线,最好是走缓存。高可用就需要准备一些降级策略,避免服务挂掉。
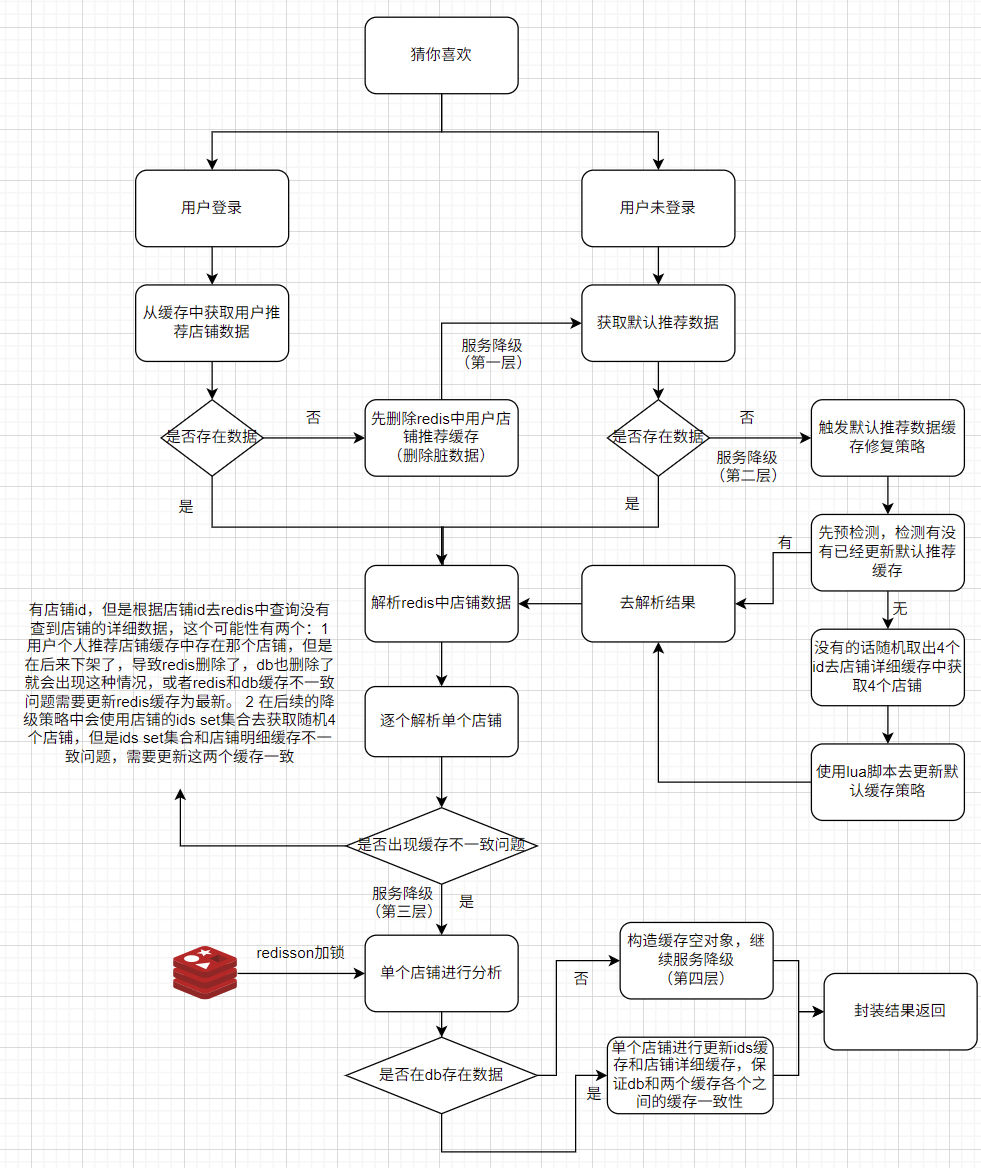
这个是我对这个接口的设计流程图,使用了多层的降级策略,保证了接口的高可用。
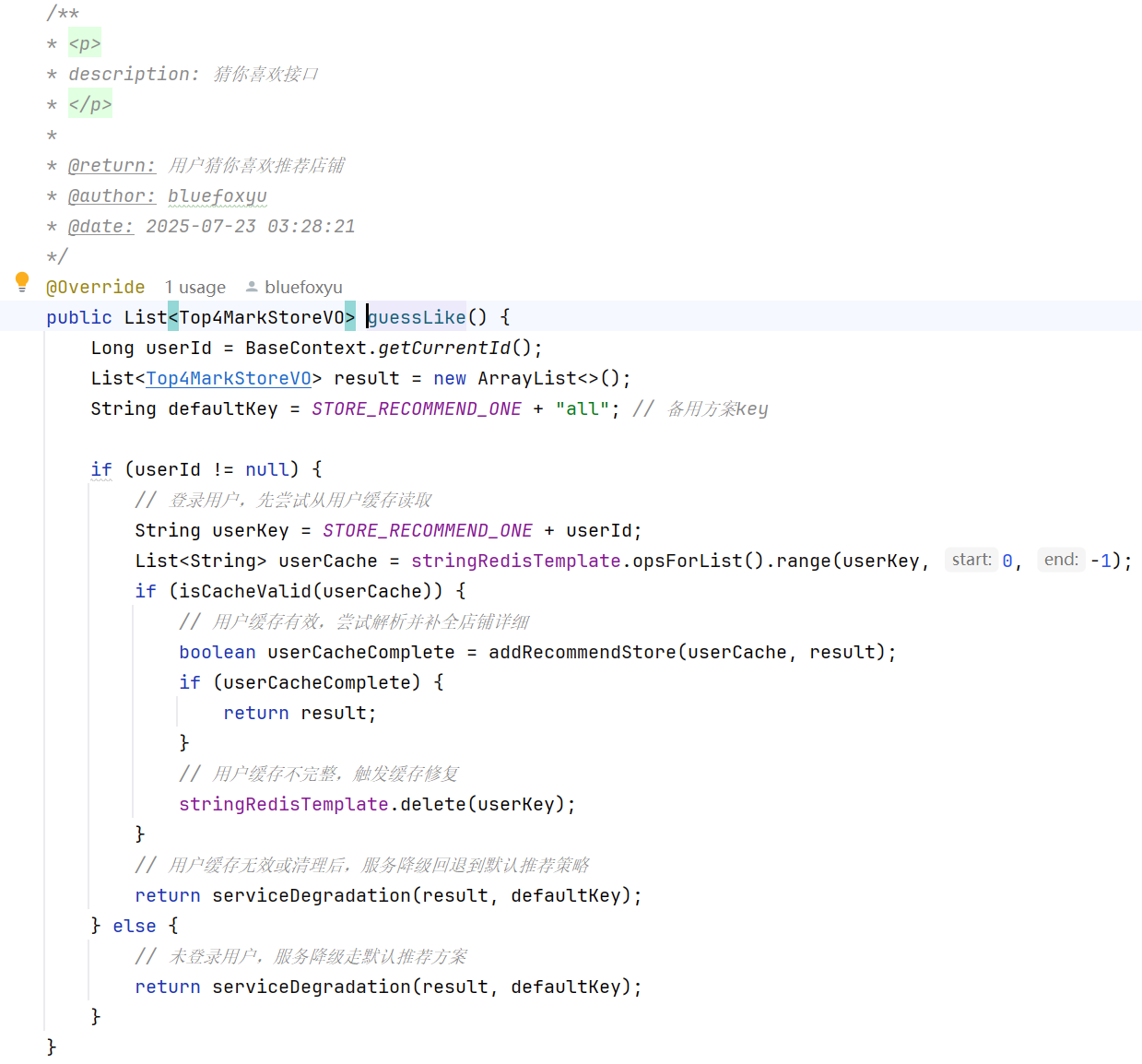
如果登录的用户没有对应的推荐缓存或者没有登录的用户,需要走降级策略:
1、第一层降级
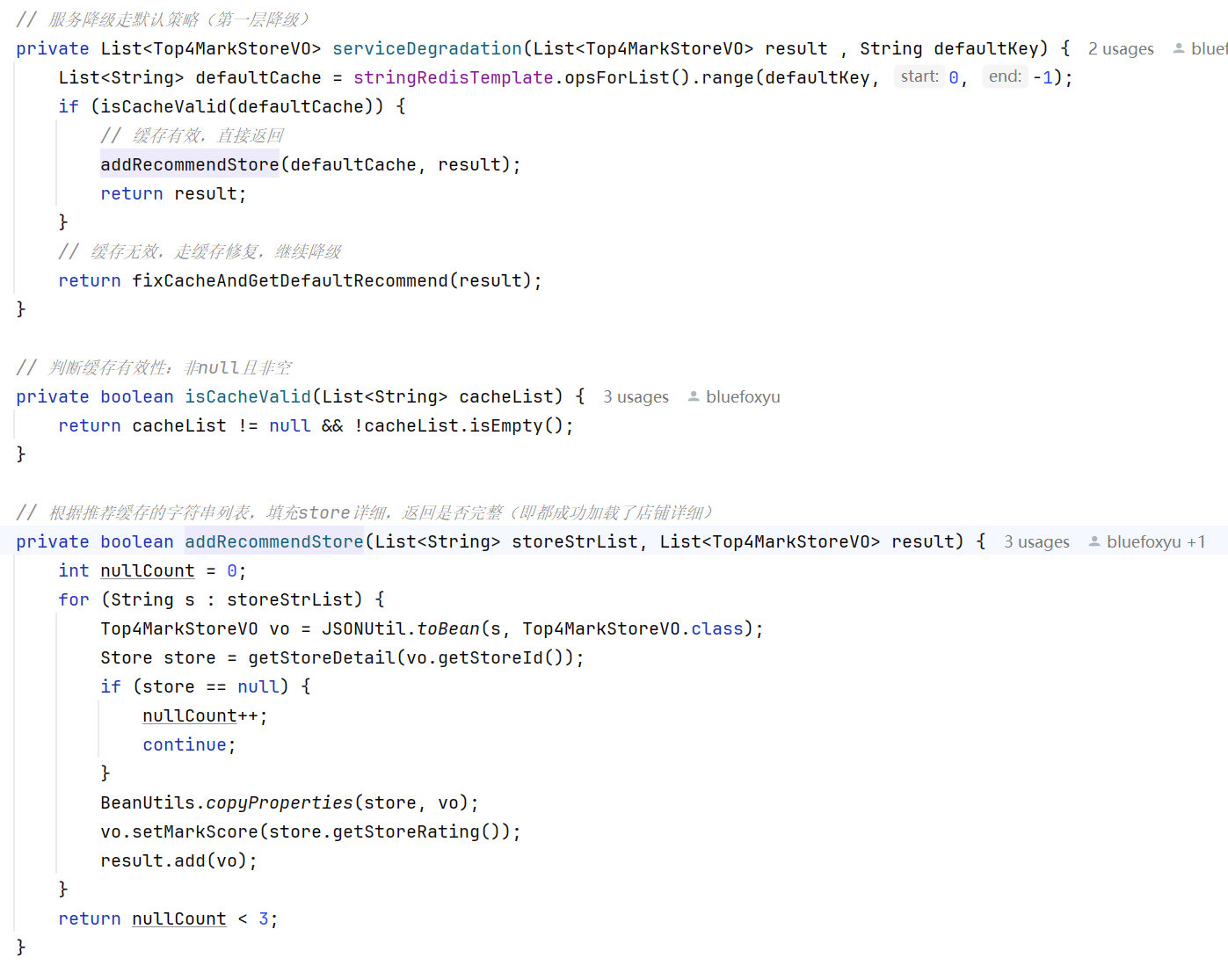
这里会取出默认策略中推荐的缓存店铺,如果有很特殊的情况导致这些缓存失效了,就需要继续服务降级去完善默认推荐的缓存店铺
2、第二层降级
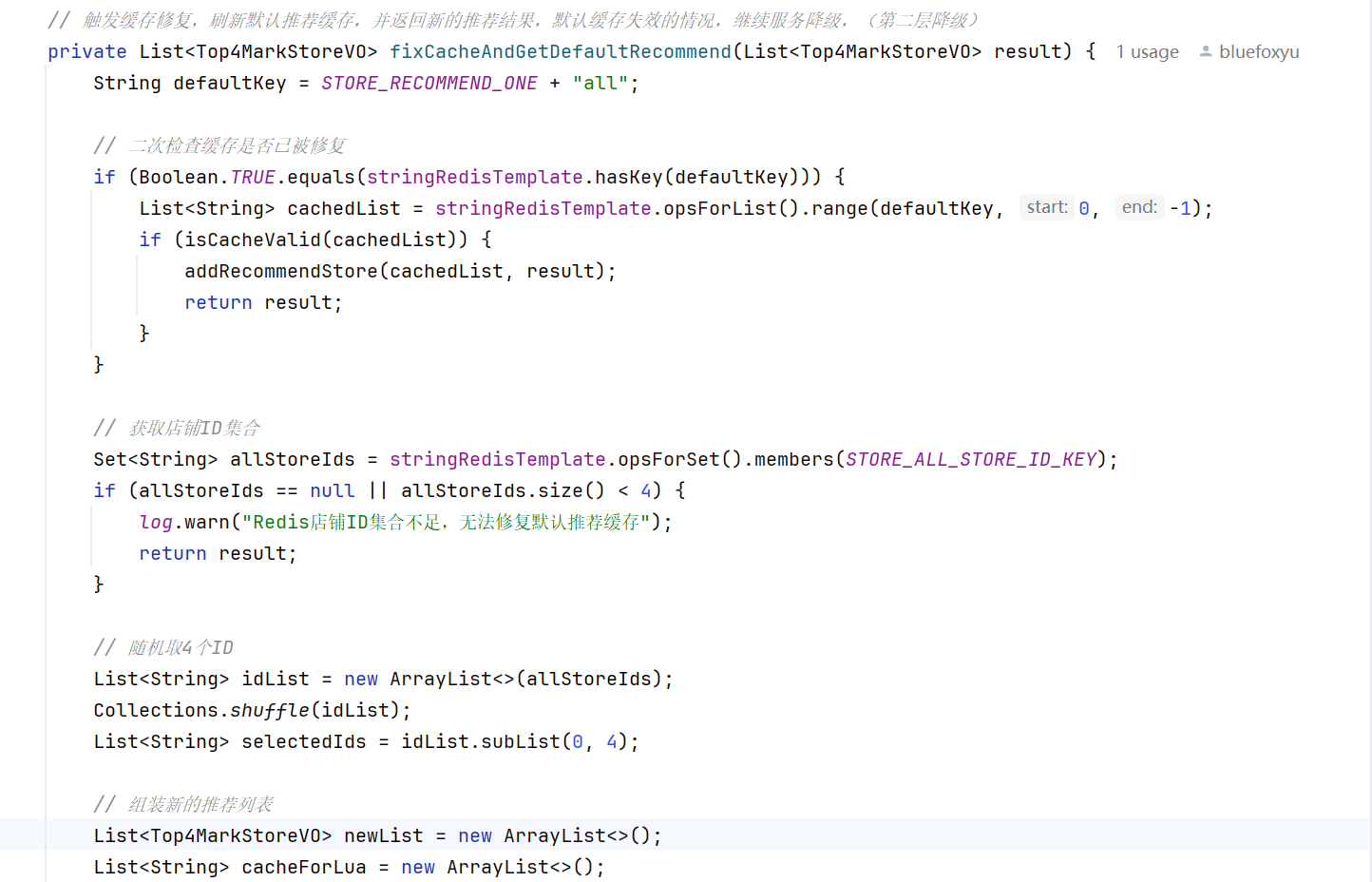
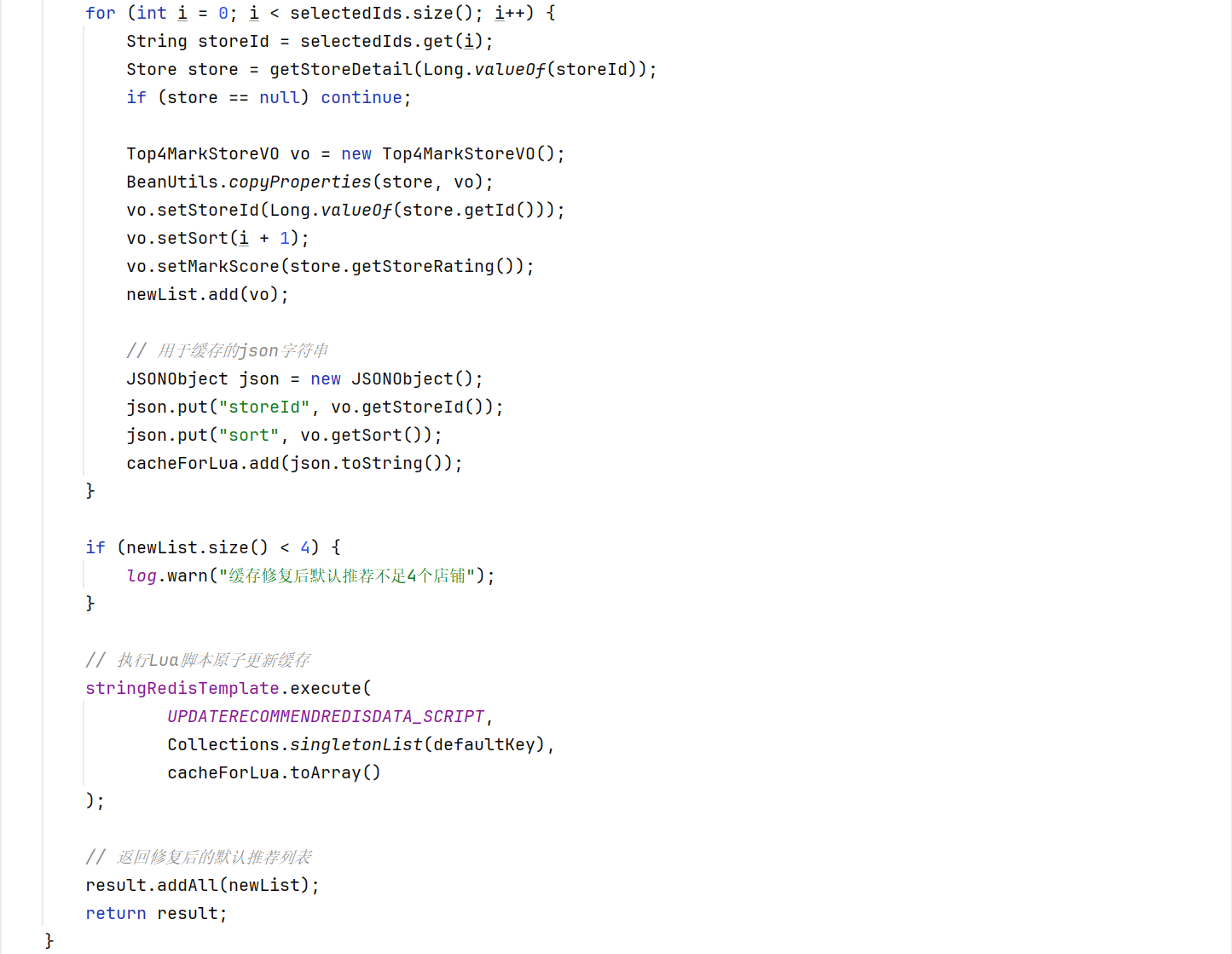
这里如果没有推荐店铺就会去redis里面去随机四个店铺进行填充,这里为啥不用分布式锁保证只有一个用户更新默认推荐店铺,可以这样子理解,在一开始有预检,一家很大程度的避免有不同推荐店铺的行为,即使在短时间内有很多线程过了这个预检测,我基于redis单线程的特性,指令在机器里面是单线程执行的特性,使用lua脚本保证各个线程执行指令的有序性,就能保证只有第一个线程的策略是实施的,后续线程的策略都不会成功,大家可能又会想,还是存在很多用户推荐店铺的数据不一致啊,再换个角度,我们这里的推荐店铺都是一个随机策略,哪怕是不同用户的推荐不同又有什么问题呢吗,下面给出lua脚本的实现:
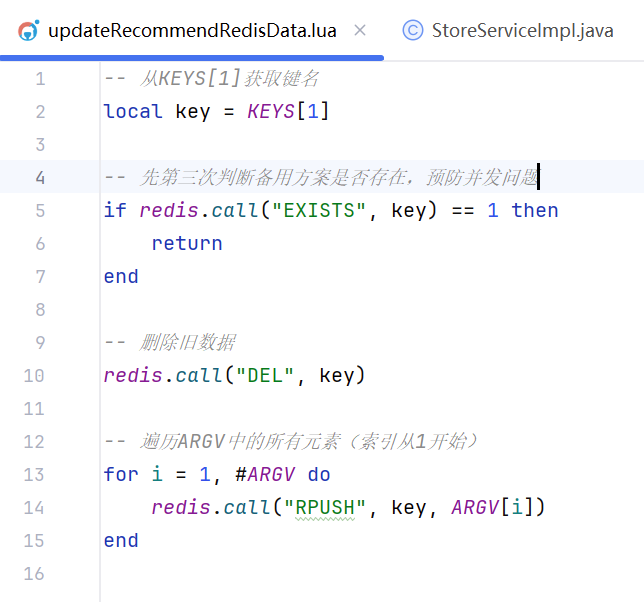
其实大家会发现,这里使用了redis进行随机,就可能极端情况下会出现缓存一致性的问题,出现这个问题,那就继续服务降级。不过有个情况是不可能出现问题的,出现也会在及其短的时间内进行避免,可以关注下面这段代码:

如果这个店铺ids集合的数据量少于4,就会导致这些线程在不断的更新默认店铺的缓存,这岂不是灾难性的,其实这个redis缓存和店铺详细缓存在小程序各个接口中多多少少都用到了,如果没有了,点开小程序,也会启动别的接口进行redis缓存的重构,对于我们目前小卡拉米小程序,还是不需要考虑这点带来的影响,并发并没美团那么高。
3、第三层降级
根据上一点讲过的缓存不一致问题,也就是和db的不一致,redis中ids缓存和店铺集合缓存不一致的问题,关于和db的不一致问题,很多方案都是加锁,然后只用一个线程进行查db更新缓存,避免缓存击穿;关于第二个不一致问题,我在那个流程图里面有做了解释,大家可以参考一下。
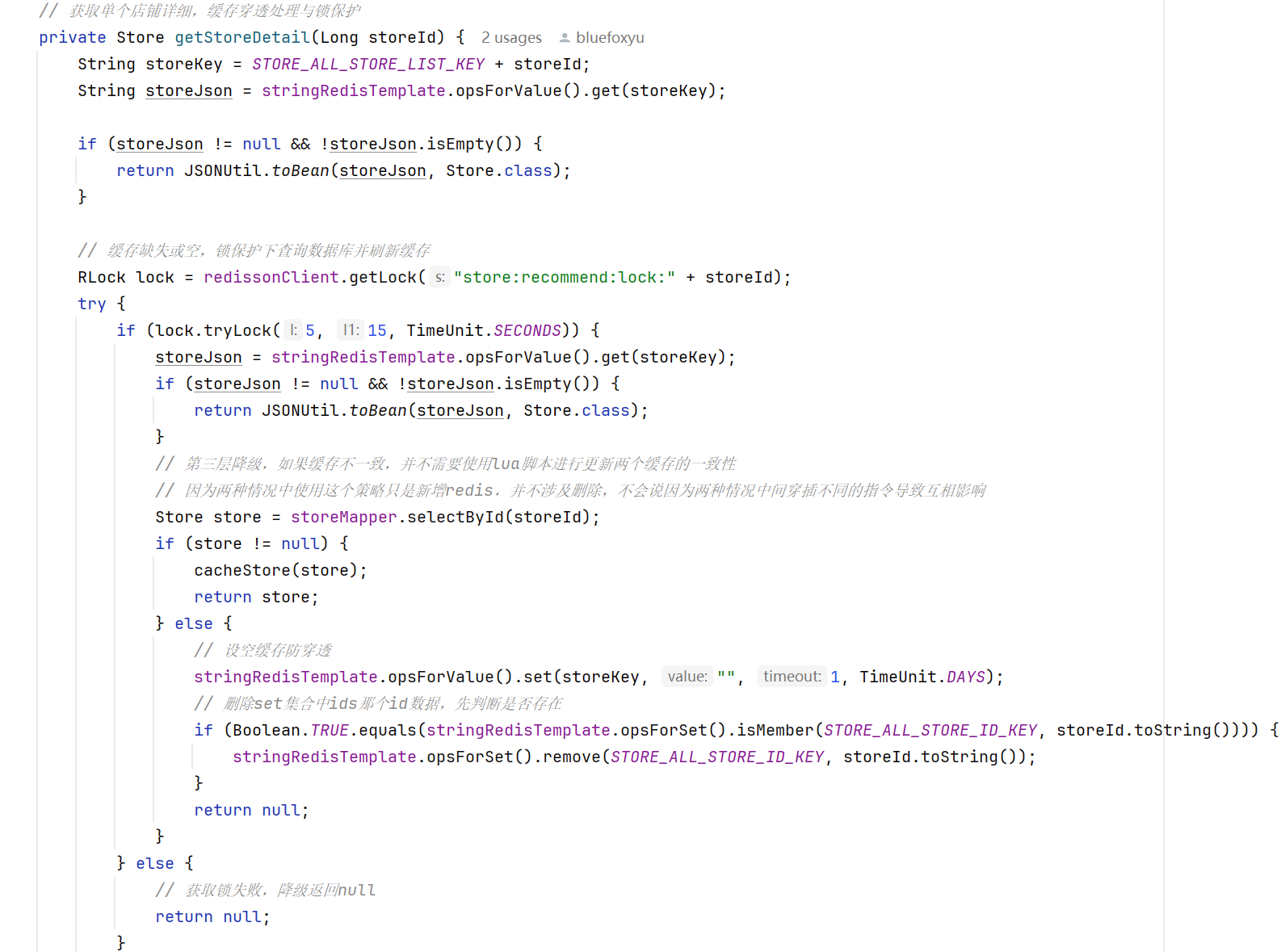

4、第四层降级
可以参考第三层降级里面,如果遇到了缓存穿透,就需要走空缓存的策略进一步一面,继续服务降级,通过上面四层的降级,我觉得整个接口处于相对比较好的高可用状态。
三、最后
欢迎大家给更多的建议,toc菜鸟希望可以得到更多好的方案进行学习,期待大家指点。
大家也可以关注一下这个博主,这个功能是由我们两个共同进行一个实现和完善:
Yilena-CSDN博客Yilena擅长八股轻松学,业务场景方案分析以及优化方案,解决方案,等方面的知识https://blog.csdn.net/2401_88959292?type=blog