嵌入式学习-土堆目标检测(4)-day28
Pytorch中加载自定义数据集 - VOC
其中需要pip install xmltodict
#voc_dataset.pyimport os
import torch
import xmltodict
from PIL import Image
from torch.utils.data import Dataset
import torchvision.transforms as transformsclass VOCDataset(Dataset): def __init__(self,img_dir,label_dir,transform,label_transform): #定义一些后面会用的参数 self.img_dir = img_dir #img地址 self.label_dir = label_dir #label文件地址 self.transform = transform #是否要做一些变换 self.label_transform = label_transform #是否要对label做一些变换self.img_names = os.listdir(self.img_dir) #os.listdir 获取文件夹下的所有文件名称,列表形式self.label_names = os.listdir(self.label_dir) #获取label文件夹下的所有文件名称 self.classes_list = ["no helmet","motor","number","with helmet"]#为了转化标记为 : 0,1,2,3def __len__(self):return len(self.img_names) #返回照片文件的个数def __getitem__(self, index):img_name = self.img_names[index] #图片列表[序号] 获取文件名img_path = os.path.join(self.img_dir, img_name) #对地址进行拼接 获取文件的路径image = Image.open(img_path).convert('RGB') #通过文件地址打开文件,转化为RGB三通道格式#new1.png -> new1.xml#new1.png -> [new1,png] -> new1 + ".xml"label_name = img_name.split('.')[0] + ".xml" #获取标注的文件名label_path = os.path.join(self.label_dir, label_name) #拼接获取标注的路径with open(label_path, 'r',encoding="utf-8") as f: #打开标注文件label_content = f.read() #读出标注文件所有的内容label_dict = xmltodict.parse(label_content) #因为内容是XML格式,xmltodict.parse 将内容转化为 dict 格式target = [] #将要返回的数组,定义总体返回容器objects = label_dict["annotation"]["object"] #获取dict里的标注对象for obj in objects: #获取每个标注里面的信息obj_name = obj["name"]obj_class_id = self.classes_list.index(obj_name) #将标注的名字(no helmet)转化为数字(0)obj_xmax = float(obj["bndbox"]["xmax"])obj_ymax = float(obj["bndbox"]["ymax"])obj_xmin = float(obj["bndbox"]["xmin"])obj_ymin = float(obj["bndbox"]["ymin"])target.extend([obj_class_id,obj_xmin,obj_ymin,obj_xmax,obj_ymax]) #将信息保存到总体返回容器target = torch.Tensor(target) #转为tensor数据类型if self.transform is not None:image = self.transform(image) #对定义对象时写的对image的操作return image,targetif __name__ == '__main__':train_dataset = VOCDataset(r"E:\HelmetDataset-VOC\train\images",r"E:\HelmetDataset-VOC\train\labels",transforms.Compose([transforms.ToTensor()]),None)print(len(train_dataset))print(train_dataset[11])Pytorch中加载自定义数据集 - YOLO
如过VOC弄懂了的话,那这个代码会非常简单
#YOLO_dataset.pyimport os
import torchfrom PIL import Image
from torch.utils.data import Dataset
import torchvision.transforms as transformsclass YOLODataset(Dataset):def __init__(self,img_dir,label_dir,transform,label_transform): #定义一些后面会用的参数self.img_dir = img_dir #img地址self.label_dir = label_dir #label文件地址self.transform = transform #是否要做一些变换self.label_transform = label_transform #是否要对label做一些变换self.img_names = os.listdir(self.img_dir) #os.listdir 获取文件夹下的所有文件名称,列表形式self.label_names = os.listdir(self.label_dir) #获取label文件夹下的所有文件名称
# self.classes_list = ["no helmet","motor","number","with helmet"]#为了转化标记为 : 0,1,2,3def __len__(self):return len(self.img_names) #返回照片文件的个数def __getitem__(self, index):img_name = self.img_names[index] #图片列表[序号] 获取文件名img_path = os.path.join(self.img_dir, img_name) #对地址进行拼接 获取文件的路径image = Image.open(img_path).convert('RGB') #通过文件地址打开文件,转化为RGB三通道格式#new1.png -> new1.xml#new1.png -> [new1,png] -> new1 + ".txt"label_name = img_name.split('.')[0] + ".txt" #获取标注的文件名label_path = os.path.join(self.label_dir, label_name) #拼接获取标注的路径with open(label_path, 'r',encoding="utf-8") as f: #打开标注文件label_content = f.read() #读出标注文件所有的内容target = []object_infos = label_content.strip().split("\n")for object_info in object_infos:info_list = object_info.strip().split(" ")class_id = float(info_list[0])center_x = float(info_list[1])center_y = float(info_list[2])width = float(info_list[3])height = float(info_list[4])target.extend([class_id,center_x,center_y,width,height])# label_dict = xmltodict.parse(label_content) #因为内容是XML格式,xmltodict.parse 将内容转化为 dict 格式# target = [] #将要返回的数组,定义总体返回容器# objects = label_dict["annotation"]["object"] #获取dict里的标注对象# for obj in objects: #获取每个标注里面的信息# obj_name = obj["name"]# obj_class_id = self.classes_list.index(obj_name) #将标注的名字(no helmet)转化为数字(0)# obj_xmax = float(obj["bndbox"]["xmax"])# obj_ymax = float(obj["bndbox"]["ymax"])# obj_xmin = float(obj["bndbox"]["xmin"])# obj_ymin = float(obj["bndbox"]["ymin"])# target.extend([obj_class_id,obj_xmin,obj_ymin,obj_xmax,obj_ymax]) #将信息保存到总体返回容器target = torch.Tensor(target) #转为tensor数据类型if self.transform is not None:image = self.transform(image) #对定义对象时写的对image的操作return image,targetif __name__ == '__main__':train_dataset = YOLODataset(r"E:\HelmetDataset-YOLO\HelmetDataset-YOLO-Train\images", r"E:\HelmetDataset-YOLO\HelmetDataset-YOLO-Train\labels", transforms.Compose([transforms.ToTensor()]), None)print(len(train_dataset))print(train_dataset[11])模型的 nn.model &模型的可视化
#model.py
import torch
import torch.nn as nn
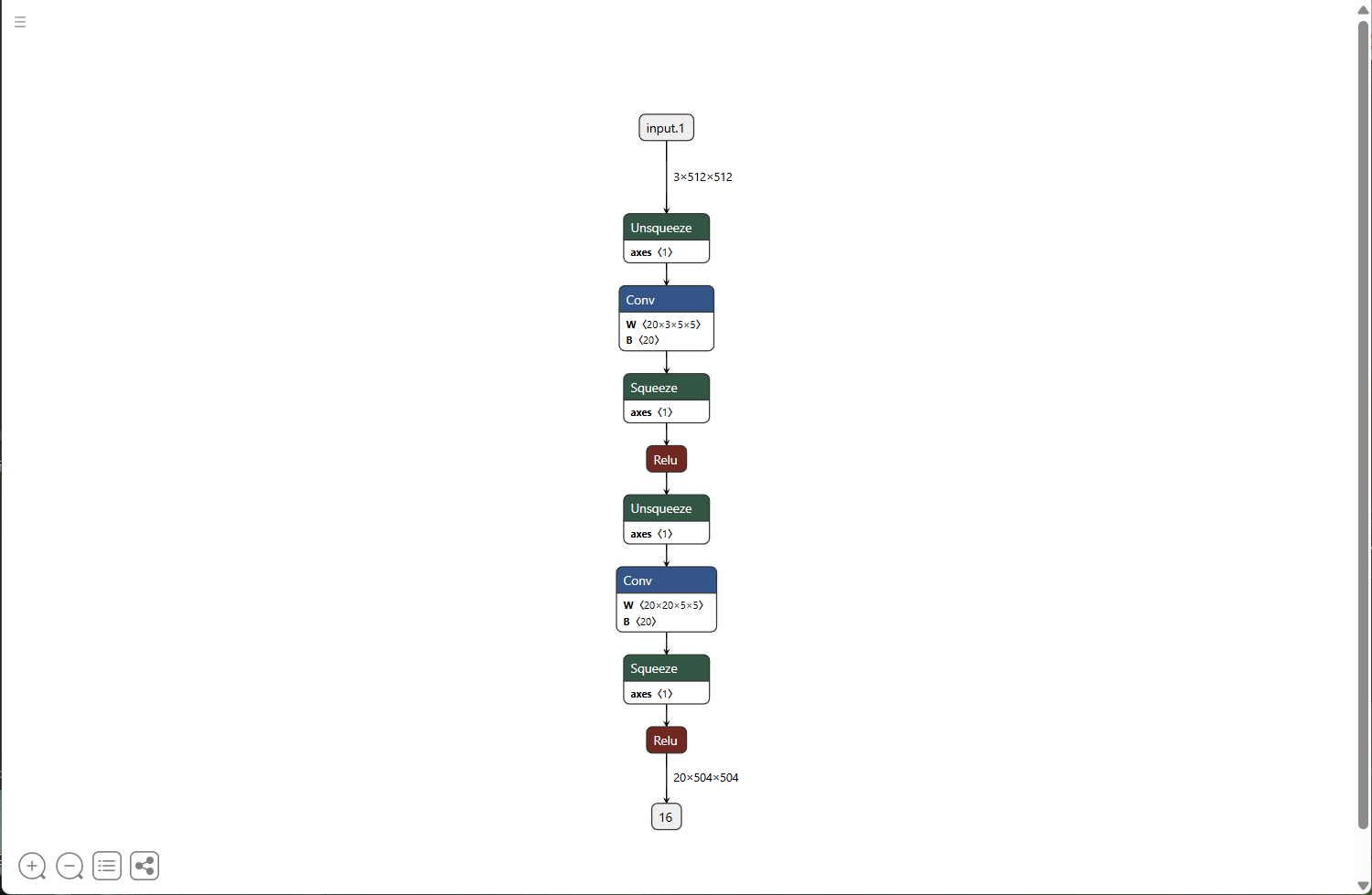
from torchvision import transformsfrom yolo_dataset import VOCDatasetclass TuduiModel(nn.Module):def __init__(self):super().__init__()self.conv1 = nn.Conv2d(in_channels=3 , out_channels=20, kernel_size=5)self.conv2 = nn.Conv2d(in_channels=20, out_channels=20, kernel_size=5)def forward(self, x):x = torch.nn.functional.relu(self.conv1(x))return torch.nn.functional.relu(self.conv2(x))if __name__ == '__main__':model = TuduiModel()dataset = VOCDataset(r"E:\HelmetDataset-VOC\train\images",r"E:\HelmetDataset-VOC\train\labels",transforms.Compose([transforms.ToTensor(),transforms.Resize((512, 512)),]),None)img,target = dataset[0]output = model(img)# print(output)# print(model)torch.onnx.export(model,img,"tudui.onnx") #模型可视化ONNX模型格式
在环境中
pip install onnx
然后
torch.onnx.export(model,img,"tudui.onnx") #(模型,图片,名字)再用浏览器打开 netron.app
把生成好的onnx文件拖进网页