C++11扩展 --- 并发支持库(中)
并发支持库

C++11扩展 --- 并发支持库(上)![]() https://blog.csdn.net/Small_entreprene/article/details/149334360?sharetype=blogdetail&sharerId=149334360&sharerefer=PC&sharesource=Small_entreprene&sharefrom=mp_from_link针对上一篇,我们下面继续学习C++11提供的并发支持库的相关内容!
https://blog.csdn.net/Small_entreprene/article/details/149334360?sharetype=blogdetail&sharerId=149334360&sharerefer=PC&sharesource=Small_entreprene&sharefrom=mp_from_link针对上一篇,我们下面继续学习C++11提供的并发支持库的相关内容!
3. <mutex>
互斥锁是很重要的一个东西,首先我们来看一段程序:
#include <iostream>
#include <thread>
#include <mutex>std::mutex mtx;
int x = 0;void Print(int n)
{for (int i = 0; i < n; i++){mtx.lock();// t1 t2++x;mtx.unlock();}
}int main()
{std::thread t1(Print, 10000000);std::thread t2(Print, 20000000);t1.join();t2.join();std::cout << x << std::endl;return 0;
}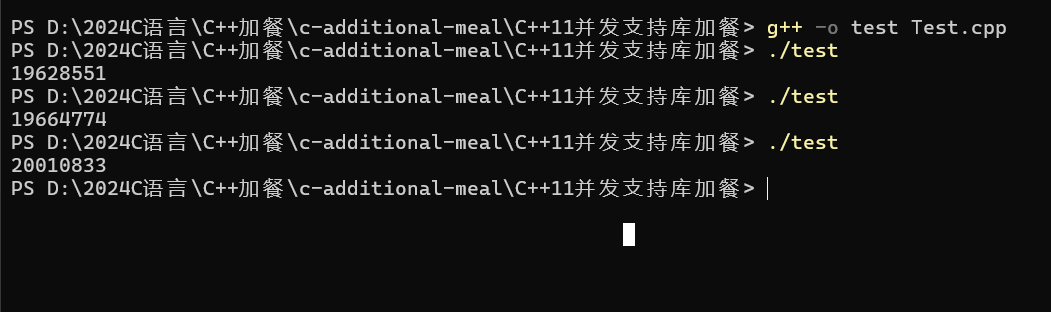
理论来说是应该为30000000的,但是输出的少了这么多!而且每次运行的还不一样!!!
提供的代码是一个 C++ 程序,其中包含两个线程 t1 和 t2,它们都调用了 Print 函数。每个线程都会对全局变量 x 进行增加操作。然而,这段代码存在下面问题:
Print 函数中的 ++x 操作不是原子操作,这意味着在多线程环境下,这个操作可能会被中断,从而导致数据不一致。代码会被编译成指令:

是将x先从内存中取到寄存器,然后再CPU进行加法运算,然后在从寄存器返回给内存的!这不是一句语句,不是原子的!!!因为CPU一般不直接访问内存的,因为CPU太快了!!!内存有点慢!
下面的链接是mutex的文档:
<mutex> - C++ Reference
-
Mutex 类型:用于保护临界区代码的互斥锁类型,包括
mutex、recursive_mutex、timed_mutex和recursive_timed_mutex。 -
Lock 类型:管理互斥锁的对象,包括
lock_guard和unique_lock。 -
其他类型:如
once_flag、adopt_lock_t、defer_lock_t和try_to_lock_t。 -
函数:如
try_lock、lock和call_once。
Mutex 类
mutex:是封装的互斥锁类,用于保护临界区的共享数据。主要提供 lock 和 unlock 两个接口函数。和我们所熟知的 pthread 一样,提供了相关的接口!只不过是以成员函数的方式提供的!
我们上面的样例代码就可以将去掉相关注释:
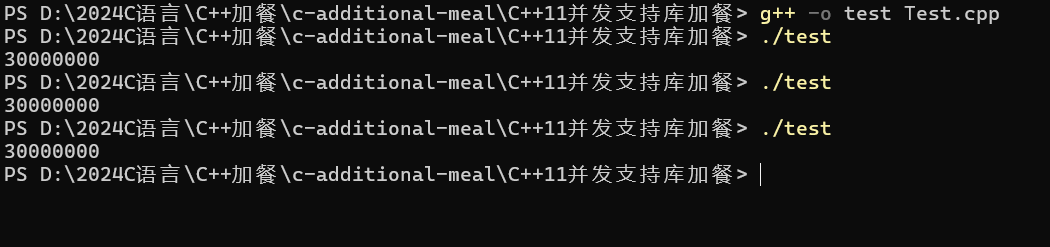
通过加锁和解锁,两个线程就可以变成串行行为了,但是效率是变低了,不过在安全性下,性能是第二位的!
但是我们可以想一想,是将加锁解锁放在for循环里面效率高,还是放在外面效率高呢?
其实在外面是效率比较高的,放在外面就是一个线程将for循环执行完了,然后换另一个!,里面就是++一次就可能换另外一个线程++了,肯定是要经过好几次加锁解锁的,效率肯定是低的!!!
提供排他性(就是只有一个线程可以进入的,剩下线程进入阻塞状态)非递归所有权语义:
-
调用方线程从成功调用
lock或try_lock开始,到调用unlock为止占有互斥锁。 -
线程占有互斥锁时,其他线程如果试图要求互斥锁的所有权,那么就会阻塞(对于
lock的调用),对于try_lock会返回false。
timed_mutex:与 mutex 完全类似,但额外提供 try_lock_for 和 try_lock_until 接口。这两个接口与 try_lock 类似,但不会马上返回,而是直接进入阻塞,直到时间条件到了或者解锁了才会唤醒试图获取锁资源的线程。
std::timed_mutex mtx;
void fireworks(int i)
{//std::cout << i;// waiting to get a lock: each thread prints "-" every 1s:while (!mtx.try_lock_for(std::chrono::milliseconds(1000))){std::cout << "-";}std::cout << i;// got a lock! - wait for 1s, then this thread prints "*"std::this_thread::sleep_for(std::chrono::milliseconds(5000));std::cout << "*\n";mtx.unlock();
}int main()
{//std::thread threads[2];vector<std::thread> threads(2);// 利用移动赋值的方式,将创建的临时对象(右值对象)移动赋值给创建好的空线程对象for (int i = 0; i < 2; ++i)threads[i] = std::thread(fireworks, i);for (auto& th : threads)th.join();return 0;
}
PS D:\2024C语言\C++加餐\c-additional-meal\C++11并发支持库加餐> g++ -o test Test.cpp
PS D:\2024C语言\C++加餐\c-additional-meal\C++11并发支持库加餐> ./test
0----*
1*这段代码通过两个线程竞争一个定时互斥锁 std::timed_mutex 来控制对共享资源的访问。每个线程在尝试获取锁时,若未能在 1 秒内成功获取,会打印一个 "-" 表示等待。一旦获取锁,线程打印其编号(0 或 1),然后等待 5 秒,最后打印一个 "*" 并释放锁。由于锁是互斥的,两个线程会交替获取锁,最终输出类似于 "-0*1*" 的结果,具体顺序取决于线程的调度和锁的获取时机。
recursive_mutex:与 mutex 完全类似,但提供排他性递归所有权语义:
-
调用方线程在从成功调用
lock或try_lock开始的时期里占有recursive_mutex。此时期之内,线程可以进行对lock或try_lock的附加调用。 -
所有权的时期在线程进行匹配次数的
unlock调用时结束。 -
线程占有
recursive_mutex时,若其他所有线程试图要求recursive_mutex的所有权,则它们将阻塞(对于调用lock)或收到false返回值(对于调用try_lock)。
mutex mtx;
//recursive_mutex mtx;//需要使用递归锁!!!
void func(int n)
{mtx.lock();//...func(n-1);//这就是一个大坑,再次进入会阻塞,因为前一个没有unlock,就会造成死锁!mtx.unlock();
}锁是不能被拷贝的,不然锁上的这些线程怎么办?!
如果互斥锁在,仍为任何线程所占有,这时候该mutex被销毁,或在占有互斥锁时线程终止,那么行为是未定义,结果是不知道了的,所以我们要保证这个锁或这些线程的生命周期是在的。
全局变量有很多的问题,比如说线程安全就是其中一个问题,还有我们定义全局变量是尽量避免全局变量含有链接属性的,全局变量通常应该避免定义在头文件(.h文件)中,因为头文件通常被包含(include)在多个源文件(.cpp文件)中。如果全局变量定义在头文件中,那么每个包含该头文件的源文件都会有该变量的一个定义,这会导致链接时的重复定义错误,是比较坑的!所以有些人就会按照下面的写法:
void Print(int n, int& rx, mutex& rmtx)
{rmtx.lock();for (int i = 0; i < n; i++){// t1 t2++rx;}rmtx.unlock();
}int main()
{int x = 0;mutex mtx;// 这里必须要用ref()传参,现成中拿到的才是x和mtx的引用,具体原因需要看下面thread源码中的分析// https://legacy.cplusplus.com/reference/functional/ref/?kw=refthread t1(Print, 1000000, ref(x), ref(mtx));thread t2(Print, 2000000, ref(x), ref(mtx));t1.join();t2.join();cout << x << endl;return 0;
}使用传参!就是定义局部变量,将其传过去。但是局部变量不是独立的吗?
我们应该要平衡的看待这个问题,下面定义的x是在主线程中的,在主线程独立,然后将其传给了两个从线程,从线程还是共享的!只要访问共享资源,就会有线程安全的问题!当然了,还需要将锁传过去!
这时候就会有“ ref ”的概念!因为需要传引用的,不然后续+的就不是同一个 x 了,没有 ref,就会没有传引用的功能,不然我们直接传引用也是没有用的,这是和其底层的实现有关系的!
那我们为什么需要通过" ref "这种形式传参才可以?
我们进行传参,感官上是直接传给Print的,但是其实不是的,x 和 mtx 这两个参数是传递给 thread 这个构造函数的,thread 是C++的一个类,他不是凭空创建线程的,而是去调用其他各个系统的相关函数!在Windows下就是去调用自己对应的创建线程的函数,如果在Linux下就是去调用pthread_create(),无论是哪一个操作系统,创建线程的逻辑都是给一个函数指针,然后这个函数指针的特点是void*的返回值,然后传void*的参数。也就是传参的时候是需要先构建一个结构体,然后将这个结构体的指针作为参数的:
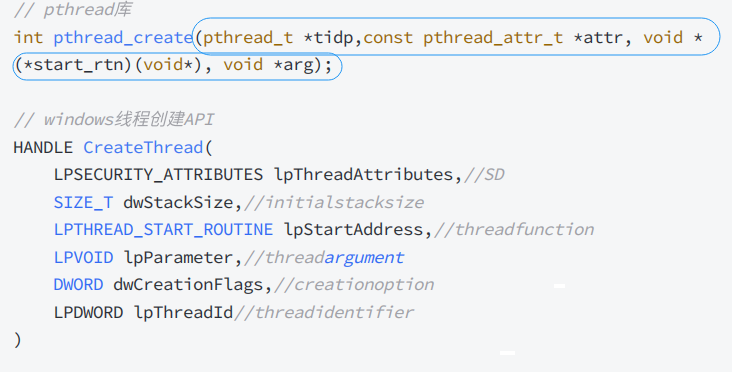
这就是内核里创建线程的相关概念了,然后让这个线程最终去执行函数指针指向的函数体了,然后再将这些参数解析出来,所以我们需要明白的第一个结论是:我们传递的参数并不是直接传递给Print的!
然后我们往thread的源码理解理解:
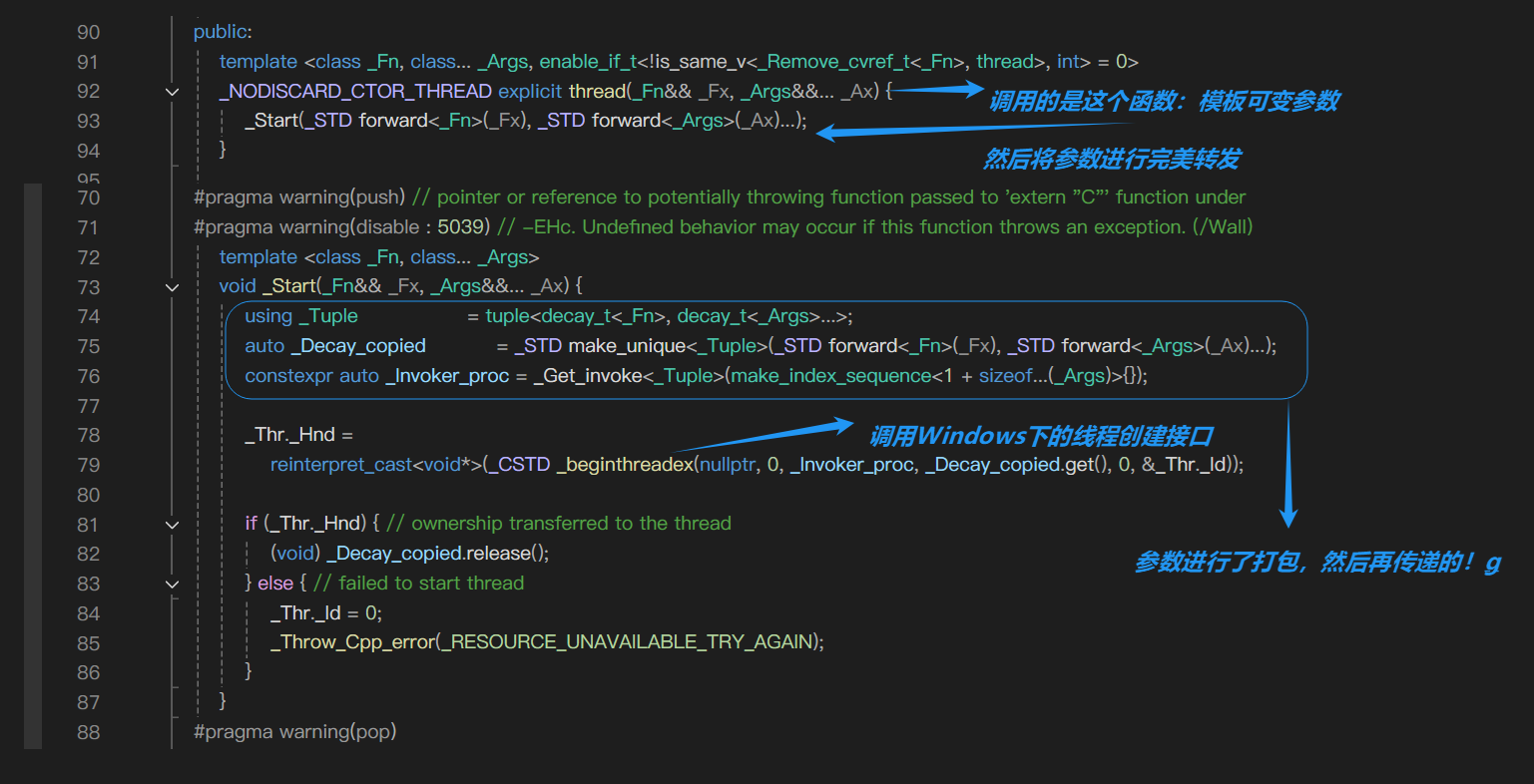
void* _Invoker_proc(void* ptr)
{_Tuple* tptr = (_Tuple*)ptr;//参数包解析Print(tptr[1], tptr[2], tptr[3]);//Print应用的其实是智能指针结构体里面的值,这些值就不是原本的x和mtx,而是拷贝了!
}如果线程对象传参给可调用对象时,使用引用方式传参,实参位置需要加上 ref(obj) 的方式。主要原因是 thread 本质还是系统库提供的线程 API 的封装,thread 构造取到参数包以后,要调用创建线程的 API,还是需要将参数包打包成一个结构体传参过去。那么打包成结构体时,参数包对象就会拷贝给结构体对象,使用 ref 传参的参数,会让结构体中的对应参数成员类型推导为引用,这样才能实现引用传参。
std::ref
我们可以看看ref的相关文档:
ref - C++ Reference
std::ref:用于构造一个 reference_wrapper 对象,以持有某个元素的引用。
template <class T> reference_wrapper<T> ref (T& elem) noexcept;template <class T> reference_wrapper<T> ref (reference_wrapper<T>& x) noexcept;template <class T> void ref (const T&&) = delete;elem:一个左值引用,其引用被存储在对象中。
x:一个 reference_wrapper 对象,将被复制。
返回值:一个 reference_wrapper 对象,用于持有类型为 T 的元素的引用。
#include <iostream> // std::cout
#include <functional> // std::ref
int main () {int foo (10);auto bar = std::ref(foo);++bar;std::cout << foo << '\n';return 0;
}输出:11
这段代码将输出 11,因为 foo 的初始值是 10,然后通过 bar(一个引用包装器)增加了 1。这里的 ++bar 直接修改了 foo 的值,因为 bar 是 foo 的引用。
针对上面的传参问题,我们还用更加方便的写法:使用lambda的捕捉列表的语法!!!
int main()
{int x = 0;mutex mtx;// 将上面的代码改成使用lambda捕获外层的对象,也就可以不用传参数,间接解决了上面的问题auto Print = [&x, &mtx](size_t n) {mtx.lock();for (size_t i = 0; i < n; i++){++x;}mtx.unlock();};thread t1(Print, 1000000);thread t2(Print, 2000000);t1.join();t2.join();cout << x << endl;return 0;
}